Qué significan consistencia y disponibilidad en la práctica
Cuando una base de datos está repartida en varias máquinas (réplicas), ganas velocidad y resiliencia, pero también introduces periodos en los que esas máquinas no están perfectamente de acuerdo o no pueden comunicarse con fiabilidad.
Consistencia (significado simple)
Consistencia significa: después de una escritura exitosa, todo el mundo lee el mismo valor. Si actualizas el correo de tu perfil, la siguiente lectura—sin importar qué réplica responda—devuelve el nuevo correo.
En la práctica, los sistemas que priorizan la consistencia pueden retrasar o rechazar algunas peticiones durante fallos para evitar responder con respuestas en conflicto.
Disponibilidad (significado simple)
Disponibilidad significa: el sistema responde a cada petición, incluso si algunos servidores están caídos o desconectados. Puede que no obtengas los datos más recientes, pero obtienes una respuesta.
En la práctica, los sistemas que priorizan la disponibilidad pueden aceptar escrituras y servir lecturas incluso mientras las réplicas discrepan, y luego conciliar las diferencias más tarde.
Qué significa el intercambio para aplicaciones reales
Un intercambio significa que no puedes maximizar ambos objetivos al mismo tiempo en todos los escenarios de fallo. Si las réplicas no pueden coordinarse, la base de datos debe o bien:
- Esperar/fallar algunas peticiones para proteger una verdad única acordada (favorecer la consistencia), o
- Seguir respondiendo a los usuarios aunque corra el riesgo de datos obsoletos o en conflicto (favorecer la disponibilidad)
Un ejemplo simple: carrito de compras vs transferencia bancaria
- Carrito de compras: Si el recuento del carrito está brevemente desfasado en otro dispositivo, es molesto pero normalmente tolerable. Muchos equipos prefieren mayor disponibilidad y conciliarán después.
- Transferencia bancaria: Si mueves $500 y tu saldo muestra temporalmente dos respuestas distintas, eso es un problema serio. Aquí, una consistencia más fuerte justifica a menudo fallos ocasionales con “inténtalo de nuevo”.
No hay una única mejor elección
El balance correcto depende de qué errores puedes tolerar: un breve corte o un corto periodo de datos equivocados/antiguos. La mayoría de sistemas reales elige un punto intermedio y hace explícito el intercambio.
Por qué la distribución cambia las reglas
Una base de datos es “distribuida” cuando almacena y sirve datos desde múltiples máquinas (nodos) que coordinan a través de una red. Para una aplicación, puede seguir pareciendo una única base de datos; pero en el fondo, las peticiones pueden ser atendidas por nodos distintos en lugares distintos.
Replicación: la razón para añadir nodos
La mayoría de bases de datos distribuidas replican datos: el mismo registro se almacena en varios nodos. Los equipos hacen esto para:
- mantener el servicio en marcha si una máquina muere
- reducir la latencia sirviendo a los usuarios desde un nodo cercano
- escalar lecturas (y a veces escrituras) en más hardware
La replicación es poderosa, pero plantea inmediatamente una pregunta: si dos nodos tienen copia del mismo dato, ¿cómo garantizas que siempre estén de acuerdo?
El fallo parcial es normal, no excepcional
En un único servidor, “caído” suele ser obvio: la máquina está arriba o no lo está. En un sistema distribuido, el fallo suele ser parcial. Un nodo puede estar vivo pero lento. Un enlace de red puede perder paquetes. Una rack entera puede perder conectividad mientras el resto del clúster sigue funcionando.
Esto importa porque los nodos no pueden saber al instante si otro nodo está realmente caído, temporalmente inalcanzable o simplemente retrasado. Mientras esperan averiguarlo, deben decidir qué hacer con las lecturas y escrituras entrantes.
Las garantías cambian cuando la comunicación no está garantizada
Con un servidor, hay una única fuente de verdad: cada lectura ve la última escritura exitosa.
Con múltiples nodos, “lo último” depende de la coordinación. Si una escritura tiene éxito en el nodo A pero el nodo B no puede alcanzarse, ¿debe la base de datos:
- bloquear la escritura hasta que B la confirme (protegiendo la consistencia), o
- aceptar la escritura de todos modos (protegiendo la disponibilidad)?
Esa tensión—hecha real por redes imperfectas—es por qué la distribución cambia las reglas.
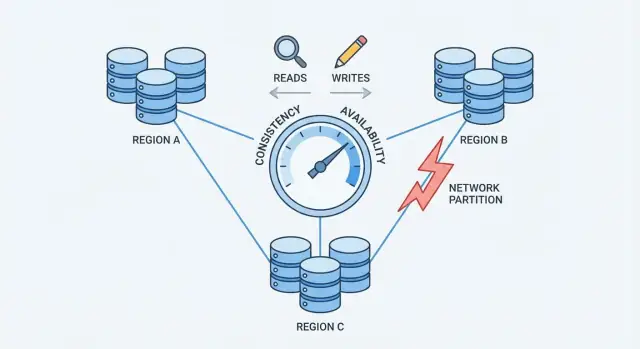
Particiones de red: el problema central
Una partición de red es una ruptura en la comunicación entre nodos que deberían funcionar como una sola base de datos. Los nodos pueden seguir ejecutándose y estar saludables, pero no pueden intercambiar mensajes de forma fiable—debido a un switch fallido, un enlace sobrecargado, un cambio de enrutamiento, una regla de firewall mal configurada o incluso un “vecino ruidoso” en una red en la nube.
Por qué las particiones son inevitables a escala
Una vez que un sistema se extiende por múltiples máquinas (a menudo entre racks, zonas o regiones), ya no controlas cada salto entre ellas. Las redes pierden paquetes, introducen retardos y a veces se dividen en “islas”. A pequeña escala estos eventos son raros; a gran escala son rutinarios. Incluso una breve interrupción es suficiente para importar, porque las bases de datos necesitan coordinación constante para ponerse de acuerdo sobre lo que ocurrió.
Cómo las particiones crean datos “más recientes” en conflicto
Durante una partición, ambos lados siguen recibiendo peticiones. Si los usuarios pueden escribir en ambos lados, cada lado puede aceptar actualizaciones que el otro no ve.
Ejemplo: el nodo A actualiza la dirección de un usuario a “Calle Nueva”. Al mismo tiempo, el nodo B la actualiza a “Calle Vieja Apt 2”. Cada lado cree que su escritura es la más reciente—porque no tiene forma de comparar notas en tiempo real.
Síntomas visibles para el usuario
Las particiones no aparecen como mensajes de error ordenados; aparecen como comportamientos confusos:
- Timeouts: la base de datos espera a que otro nodo confirme una escritura o lectura.
- Lecturas obsoletas: actualizas y aún ves datos antiguos porque has consultado una réplica que no recibió las actualizaciones.
- Comportamiento split-brain: distintos usuarios ven diferentes “verdades”, según a qué lado accedan.
Este es el punto de presión que fuerza una elección: cuando la red no puede garantizar comunicación, una base de datos distribuida debe decidir si prioriza ser consistente o estar disponible.
Teorema CAP sin la jerga
CAP es una forma compacta de describir lo que ocurre cuando una base de datos se distribuye entre varias máquinas.
Los tres términos (en cristiano)
- Consistencia (C): después de escribir un valor, cualquier lectura posterior devuelve ese mismo valor.
- Disponibilidad (A): cada solicitud obtiene una respuesta no errónea, incluso si algunos servidores tienen problemas.
- Tolerancia a particiones (P): el sistema sigue operando aunque la red se divida y los servidores no puedan comunicarse de forma fiable.
La idea clave
Cuando no hay partición, muchos sistemas pueden parecer tanto consistentes como disponibles.
Cuando sí hay una partición, debes elegir qué priorizar:
- Elegir Consistencia: rechazar o retrasar algunas peticiones hasta que los servidores puedan ponerse de acuerdo.
- Elegir Disponibilidad: aceptar peticiones en cada lado de la división, incluso si las respuestas pueden discrepar temporalmente.
Una línea temporal simple que puedes imaginar
- 10:00 Cliente escribe
balance = 100 en el Servidor A.
- 10:01 Partición de red: el Servidor A no puede alcanzar al Servidor B.
- 10:02 Cliente lee desde el Servidor B.
- Si priorizas Consistencia, el Servidor B debe negarse o esperar.
- Si priorizas Disponibilidad, el Servidor B responde, pero podría decir todavía
balance = 80.
Concepto erróneo común
CAP no significa “elige solo dos” como regla permanente. Significa durante una partición, no puedes garantizar tanto Consistencia como Disponibilidad al mismo tiempo. Fuera de las particiones, a menudo puedes acercarte mucho a ambas—hasta que la red se porta mal.
Elegir Consistencia: lo que ganas y lo que pierdes
Elegir consistencia significa que la base de datos prioriza “todos ven la misma verdad” sobre “responder siempre”. En la práctica, esto suele apuntar a consistencia fuerte, a menudo descrita como comportamiento linearizable: una vez que una escritura es reconocida, cualquier lectura posterior (desde cualquier lugar) devuelve ese valor, como si hubiese una única copia actualizada.
Qué ocurre durante una partición
Cuando la red se divide y las réplicas no pueden comunicarse de forma fiable, un sistema fuertemente consistente no puede aceptar de forma segura actualizaciones independientes en ambos lados. Para proteger la corrección, típicamente:
- Bloquea peticiones mientras espera coordinación, o
- Rechaza peticiones (devuelve errores/timeouts) si no puede alcanzar las réplicas/leader requeridas.
Desde la perspectiva del usuario, esto puede parecer una caída aunque algunas máquinas sigan funcionando.
Lo que ganas
El beneficio principal es razonamiento más simple. El código de la aplicación puede comportarse como si hablara con una única base de datos, no con varias réplicas que podrían discrepar. Esto reduce momentos “raros” como:
- Leer datos antiguos justo después de una actualización exitosa
- Ver dos valores distintos para el mismo registro según la réplica que consultes
- Perder invariantes (por ejemplo, sobreventa de inventario) por escrituras concurrentes y en conflicto
También obtienes modelos mentales más limpios para auditoría, facturación y cualquier cosa que deba ser correcta a la primera.
Lo que pierdes
La consistencia tiene costes reales:
- Mayor latencia: muchas operaciones deben esperar coordinación (a menudo entre máquinas o regiones).
- Más errores durante fallos: particiones, réplicas lentas o problemas del líder pueden traducirse en timeouts o “vuelve a intentarlo más tarde”.
Si tu producto no puede tolerar peticiones fallidas durante cortes parciales, la consistencia fuerte puede resultar cara—aunque sea la opción correcta para la corrección.
Elegir Disponibilidad: lo que ganas y lo que pierdes
Prueba cambios sin miedo
Experimenta con comportamientos tipo quórum y revierte cuando los resultados no sean los deseados.
Elegir disponibilidad significa optimizar por una promesa simple: el sistema responde, incluso cuando partes de la infraestructura están poco saludables. En la práctica, “alta disponibilidad” no es “sin errores nunca”: es que la mayoría de las peticiones aún obtienen respuesta durante fallos de nodo, réplicas sobrecargadas o enlaces rotos.
Qué ocurre durante una partición de red
Cuando la red se divide, las réplicas no pueden hablar de forma fiable entre sí. Una base de datos que prioriza la disponibilidad típicamente sigue atendiendo tráfico desde el lado alcanzable:
- Lecturas se responden localmente con los datos que la réplica tenga.
- Escrituras se aceptan localmente y se encolan/replican más tarde cuando vuelve la conectividad.
Esto mantiene las aplicaciones en marcha, pero significa que distintas réplicas pueden aceptar “verdades” temporales.
Lo que ganas
Obtienes mejor tiempo de actividad: los usuarios aún pueden navegar, añadir items al carrito, publicar comentarios o registrar eventos aunque una región esté aislada.
También logras una experiencia de usuario más suave bajo estrés. En lugar de timeouts, tu app puede continuar con comportamiento razonable (“tu actualización está guardada”) y sincronizar después. Para muchas cargas de trabajo de consumo y analítica, ese intercambio merece la pena.
Lo que pierdes
El precio es que la base de datos puede devolver lecturas obsoletas. Un usuario puede actualizar un perfil en una réplica y, acto seguido, leer desde otra y ver el valor antiguo.
También arriesgas conflictos de escritura. Dos usuarios (o el mismo usuario en dos ubicaciones) pueden actualizar el mismo registro en distintos lados de la partición. Cuando la partición sana, el sistema debe reconciliar historiales divergentes. Según las reglas, una escritura puede “ganar”, los campos pueden fusionarse o el conflicto puede requerir lógica de aplicación.
El diseño orientado a disponibilidad acepta el desacuerdo temporal para que el producto siga respondiendo—y luego invierte en cómo detectar y reparar la discrepancia.
Quórums y votación: un punto medio
Los quórums son una técnica práctica de “votación” que muchas bases de datos replicadas usan para equilibrar consistencia y disponibilidad. En lugar de confiar en una réplica, el sistema pide a suficientes réplicas que estén de acuerdo.
La idea (N, R, W)
A menudo verás quórums descritos con tres números:
- N: cuántas réplicas existen para un dato
- W: cuántas réplicas deben confirmar una escritura antes de considerarla exitosa
- R: cuántas réplicas se consultan para una lectura
Una regla práctica es: si R + W > N, entonces cada lectura se solapa con la última escritura exitosa en al menos una réplica, lo que reduce la posibilidad de leer datos obsoletos.
Ejemplos intuitivos
Si tienes N=3 réplicas:
- Enfoque de réplica única (R=1, W=1): rápido y muy disponible, pero puedes leer fácilmente una réplica desactualizada.
- Votación por mayoría (R=2, W=2): una escritura debe alcanzar 2 réplicas y una lectura consulta 2 réplicas. Esto aumenta las probabilidades de ver el valor más reciente porque los conjuntos de lectura y escritura se solapan.
Algunos sistemas usan W=3 (todas las réplicas) para mayor consistencia, pero eso puede causar más fallos de escritura cuando cualquier réplica está lenta o caída.
Qué hacen los quórums durante particiones
Los quórums no eliminan los problemas de partición: definen quién puede avanzar. Si la red se divide 2–1, el lado con 2 réplicas aún puede satisfacer R=2 y W=2, mientras que la réplica aislada no puede. Eso reduce actualizaciones en conflicto, pero significa que algunos clientes verán errores o timeouts.
Los trade-offs
Los quórums suelen implicar mayor latencia (más nodos a contactar), mayor coste (más tráfico entre nodos) y comportamientos de fallo más matizados (los timeouts pueden parecer indisponibilidad). El beneficio es un término medio ajustable: puedes girar R y W hacia lecturas más frescas o más éxito en escrituras según lo que importe.
Consistencia eventual y anomalías comunes
Consistencia eventual significa que las réplicas pueden estar temporalmente desincronizadas, siempre que converjan al mismo valor más adelante.
Una analogía concreta
Piensa en una cadena de cafeterías que actualiza un cartel compartido de “agotado” para un pastel. Una tienda lo marca como agotado, pero la actualización llega a las demás tiendas unos minutos después. Durante ese intervalo, otra tienda puede aún mostrar “disponible” y vender el último. El sistema no está “roto”: las actualizaciones simplemente se están poniendo al día.
Anomalías comunes que notarás
Cuando los datos aún se propagan, los clientes pueden observar comportamientos que parecen sorprendentes:
- Lecturas obsoletas: lees datos antiguos de una réplica que no recibió la última escritura.
- Gaps “leer tus propias escrituras”: escribes una actualización y luego, inmediatamente, lees desde otra réplica (o tras un failover) y no ves tu cambio.
- Actualizaciones fuera de orden: dos actualizaciones llegan en secuencias distintas a distintas réplicas, produciendo vistas inconsistentes brevemente.
Técnicas que ayudan a que las réplicas converjan
Los sistemas de consistencia eventual suelen añadir mecanismos en segundo plano para reducir las ventanas de inconsistencia:
- Read repair: si una lectura detecta réplicas descoincidentes, el sistema actualiza las réplicas obsoletas en segundo plano.
- Hinted handoff: si una réplica está caída, otra almacena temporalmente “pistas” de escrituras para reenviarlas cuando vuelva.
- Anti-entropy (sync): reconciliación periódica (a menudo con árboles de Merkle o checksums) para encontrar y corregir desviaciones.
Cuándo funciona bien la consistencia eventual
Es adecuada cuando la disponibilidad importa más que estar perfectamente al día: feeds de actividad, contadores de vista, recomendaciones, perfiles en caché, logs/telemetría y otros datos no críticos donde “correcto en un momento” es aceptable.
Resolución de conflictos: cómo se reconcilian escrituras divergentes
Construye y comparte para obtener créditos
Comparte lo que creas con Koder.ai y gana créditos mientras enseñas a otros.
Cuando una base de datos acepta escrituras en varias réplicas, puede acabar con conflictos: dos (o más) actualizaciones al mismo ítem que ocurrieron independientemente en distintas réplicas antes de que pudieran sincronizarse.
Un ejemplo clásico es un usuario que actualiza su dirección de envío en un dispositivo mientras cambia su número de teléfono en otro. Si cada actualización llega a una réplica distinta durante un desconecte temporal, el sistema debe decidir cuál es el registro “verdadero” cuando las réplicas intercambian datos otra vez.
Última escritura gana (LWW): simple, pero arriesgado
Muchos sistemas empiezan con última escritura gana: la actualización con la marca de tiempo más reciente sobrescribe las demás.
Es atractivo porque es fácil de implementar y rápido de calcular. La desventaja es que puede perder datos en silencio. Si gana lo “más nuevo”, una actualización más antigua pero importante se descarta—incluso si las dos escribieron campos distintos.
También asume que los relojes son fiables. La deriva de reloj entre máquinas (o clientes) puede hacer que la actualización “incorrecta” gane.
Guardar historial: vectores de versión y ideas afines
Un manejo más seguro de conflictos suele requerir rastrear historial causal.
A nivel conceptual, los vectores de versión (y variantes más simples) adjuntan un pequeño metadato a cada registro que resume “qué réplica ha visto qué actualizaciones”. Cuando las réplicas intercambian versiones, la base de datos puede detectar si una versión incluye a otra (sin conflicto) o si han divergido (conflicto que necesita resolución).
Algunos sistemas usan relojes lógicos (por ejemplo, relojes de Lamport) o relojes lógicos híbridos para reducir la dependencia del tiempo de pared manteniendo una pista de orden.
Fusionar en vez de sobrescribir
Una vez detectado el conflicto, hay opciones:
- Fusiones a nivel de aplicación: tu aplicación decide cómo combinar campos, pedir al usuario o conservar ambas versiones para revisión.
- CRDTs (Conflict-Free Replicated Data Types): estructuras de datos diseñadas para fusionar automáticamente y de forma determinista (útiles para contadores, conjuntos, texto colaborativo, etc.). Evitan a menudo el comportamiento de “un ganador se lo lleva todo” y permiten alta disponibilidad.
La mejor aproximación depende de qué significa “correcto” para tus datos—a veces perder una escritura es aceptable, y a veces es un error crítico para el negocio.
Cómo elegir para tu caso de uso
Escoger una postura de consistencia/disponibilidad no es un debate filosófico: es una decisión de producto. Empieza preguntándote: ¿cuál es el coste de estar equivocado por un momento, y cuál es el coste de decir “vuelve a intentarlo más tarde”?
Mapea el riesgo del negocio a las necesidades de consistencia
Algunos dominios necesitan una respuesta única y autorizada en el momento de la escritura porque “casi correcto” sigue siendo incorrecto:
- Dinero y facturación: cargos dobles, descubiertos y reembolsos suelen exigir consistencia fuerte.
- Identidad y permisos: inicio de sesión, restablecimiento de contraseñas, control de acceso y cambios de roles deben evitar comportamientos split-brain.
- Inventario y capacidad: si la sobreventa es inaceptable (entradas, stock limitado), opta por consistencia o diseña reservas explícitas.
Si el impacto de un desfase temporal es bajo o reversible, normalmente puedes inclinarte por mayor disponibilidad.
Decide cuánta antigüedad de datos puedes tolerar
Muchas experiencias de usuario funcionan con lecturas algo antiguas:
- Feeds y timelines: que una publicación aparezca unos segundos después suele ser aceptable.
- Analíticas y dashboards: números por lotes o retrasados son comunes y esperados.
- Caches e índices de búsqueda: los usuarios aceptan “no actualizado aún” si es rápido y estable.
Sé explícito sobre cuánto atraso está bien: segundos, minutos u horas. Ese presupuesto de tiempo guía tus elecciones de replicación y quórum.
Elige el modo de fallo que los usuarios odiarán menos
Cuando las réplicas no pueden ponerse de acuerdo, normalmente acabas con uno de tres resultados de UX:
- Spinner / espera (prioriza corrección, puede sentirse lento)
- Error / reintento (honesto, pero disruptivo)
- Resultado obsoleto (suave, pero ocasionalmente sorprendente)
Elige la opción menos dañina por característica, no de forma global.
Lista rápida
Inclínate por C (consistencia) si: resultados equivocados generan riesgo financiero/legal, problemas de seguridad o acciones irreversibles.
Inclínate por A (disponibilidad) si: los usuarios valoran la capacidad de respuesta, los datos obsoletos son tolerables y los conflictos pueden resolverse con seguridad después.
En caso de duda, divide el sistema: mantén registros críticos con consistencia fuerte y deja que vistas derivadas (feeds, caches, analítica) optimicen para disponibilidad.
Patrones de diseño para reducir el dolor del intercambio
Despliega y observa más rápido
Envía un prototipo funcional a un entorno alojado y prueba su comportamiento bajo carga.
Rara vez tienes que elegir una única “configuración de consistencia” para todo el sistema. Muchas bases de datos distribuidas modernas permiten elegir la consistencia por operación, y las aplicaciones inteligentes aprovechan eso para mantener la experiencia de usuario sin pretender que el intercambio no existe.
Usa niveles de consistencia por operación
Trata la consistencia como un dial que giras según lo que el usuario está haciendo:
- Actualizaciones críticas (pagos, decrementos de inventario, cambios de contraseña): usa consistencia más fuerte (por ejemplo, escrituras con quórum/linearizables).
- Lecturas no críticas (feeds, dashboards, “última vez visto”): permite lecturas más débiles (local/una réplica/eventual) para velocidad y resiliencia.
Así evitas pagar el coste de la máxima consistencia para todo, protegiendo solo las operaciones que realmente lo necesitan.
Mezcla fuerte y débil en un mismo flujo
Un patrón común es fuerte para escrituras, más débil para lecturas:
- Escribe con un nivel estricto para que el sistema tenga un registro autorizado.
- Lee con un nivel más laxo y, si detectas algo “raro” (elemento faltante, contador obsoleto), refresca con una lectura más fuerte o muestra un aviso de “aún actualizándose”.
En algunos casos funciona al revés: escrituras rápidas (encoladas/eventuales) más lecturas fuertes al confirmar un resultado (“¿Se ha realizado mi pedido?”).
Diseña para reintentos: idempotencia
Cuando las redes vacilan, los clientes reintentan. Haz que los reintentos sean seguros con idempotency keys de modo que “enviar pedido” ejecutado dos veces no cree dos pedidos. Guarda y reutiliza el primer resultado si la misma clave aparece otra vez.
Flujos largos: sagas y compensación
Para acciones en varios pasos entre servicios, usa una saga: cada paso tiene una acción compensatoria correspondiente (reembolso, liberar reserva, cancelar envío). Esto mantiene el sistema recuperable incluso cuando partes discrepan o fallan temporalmente.
Pruebas y observabilidad para consistencia vs disponibilidad
No puedes gestionar el intercambio de consistencia/disponibilidad si no puedes verlo. Los problemas en producción suelen parecer “fallos aleatorios” hasta que añades las medidas y pruebas adecuadas.
Qué medir (y por qué)
Empieza con un conjunto pequeño de métricas que se mapeen directamente al impacto usuario:
- Latencia (p50/p95/p99): vigila picos durante failovers, cambios de líder o reintentos de quórum.
- Tasa de errores: separa errores “duros” (timeouts, 5xx) de errores “blandos” (servidos desde fallback, resultados parciales).
- Tasa de lecturas obsoletas: porcentaje de lecturas que devuelven datos más antiguos que tu objetivo (por ejemplo, más de 2 segundos).
- Tasa de conflictos: con qué frecuencia las escrituras concurrentes requieren reconciliación (incluyendo sobrescrituras LWW).
Si puedes, etiqueta métricas por modo de consistencia (quórum vs local) y por región/zona para detectar dónde diverge el comportamiento.
Prueba particiones a propósito
No esperes a que ocurra el fallo real. En staging, ejecuta experimentos de caos que simulen:
- paquetes perdidos y alta latencia entre réplicas
- una región inaccesible
- particiones parciales donde solo algunos nodos se comunican
Verifica no solo “el sistema sigue funcionando”, sino qué garantías se mantienen: ¿las lecturas siguen frescas, las escrituras bloquean, los clientes obtienen errores claros?
Alertas que detectan el intercambio temprano
Añade alertas para:
- lag de replicación que exceda tu ventana de obsolescencia tolerada
- fallos de quórum (no se alcanzan suficientes réplicas) y aumento de reintentos
- incremento en conflictos de escritura o acumulación de reconciliación
Por último, documenta explícitamente las garantías: qué promete tu sistema durante la operación normal y durante particiones, y forma a producto y soporte en qué pueden ver los usuarios y cómo responder.
Prototipar elecciones CAP más rápido (sin reconstruir todo)
Si exploras estos intercambios en un producto nuevo, ayuda validar las suposiciones pronto—especialmente sobre modos de fallo, comportamiento de reintentos y cómo se ve lo “obsoleto” en la UI.
Un enfoque práctico es prototipar una versión pequeña del flujo (ruta de escritura, ruta de lectura, reintento/idempotencia y un job de reconciliación) antes de comprometerte con una arquitectura completa. Con Koder.ai, los equipos pueden poner en marcha apps web y backends mediante un flujo guiado por chat, iterar rápido en modelos de datos y APIs, y probar distintos patrones de consistencia (por ejemplo, escrituras estrictas + lecturas relajadas) sin la sobrecarga de un pipeline de construcción tradicional. Cuando el prototipo se ajusta al comportamiento deseado, puedes exportar el código fuente y evolucionarlo hacia producción.