Qué significa búsqueda semántica (sin jerga)
La búsqueda semántica es una forma de buscar que se centra en lo que quieres decir, no solo en las palabras exactas que escribes.
Si alguna vez buscaste algo y pensaste “la respuesta está aquí — ¿por qué no la encuentra?”, has notado los límites de la búsqueda por palabras clave. La búsqueda tradicional empareja términos. Eso funciona cuando la redacción de tu consulta y la del contenido coinciden.
La búsqueda por palabras clave tiene problemas con:
- Sinónimos y redacción: “cancelar” vs “cerrar” vs “terminar” una cuenta.
- Intención: “¿cómo evito que me facturen?” en realidad trata sobre cancelar una suscripción.
- Contexto: “apple charger” (marca) vs “apple tree charger” (sin sentido, pero entiendes la idea).
También puede dar demasiado peso a palabras repetidas, devolviendo resultados que parecen relevantes en la superficie mientras ignoran la página que realmente responde la pregunta con un lenguaje distinto.
Un ejemplo simple
Imagina un centro de ayuda con un artículo titulado “Pausar o cancelar tu suscripción”. Un usuario busca:
“detener mis pagos el próximo mes”
Un sistema de palabras clave podría no clasificar ese artículo alto si no contiene “detener” o “pagos”. La búsqueda semántica está diseñada para entender que “detener mis pagos” está muy relacionado con “cancelar suscripción”, y llevar ese artículo arriba — porque el significado coincide.
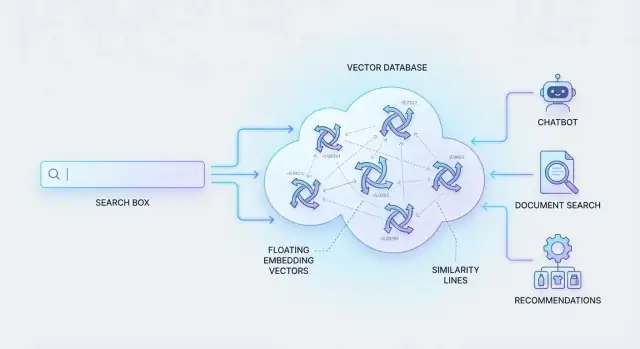
Dónde encajan las bases de datos vectoriales
Para que esto funcione, los sistemas representan contenido y consultas como “huellas de significado” (números que capturan similitud). Luego deben buscar entre millones de estas huellas rápidamente.
Para eso se crean las bases de datos vectoriales: almacenar estas representaciones numéricas y recuperar las coincidencias más parecidas de manera eficiente, para que la búsqueda semántica sea instantánea incluso a gran escala.
Incrustaciones: convertir el contenido en vectores significativos
Una incrustación es una representación numérica del significado. En lugar de describir un documento con palabras clave, lo representas como una lista de números (un “vector”) que captura de qué trata el contenido. Dos piezas de contenido con significados parecidos terminan con vectores cercanos en ese espacio numérico.
Cómo es en realidad una incrustación
Piensa en una incrustación como una coordenada en un mapa de muy alta dimensión. Normalmente no leerás los números directamente; no están pensados para humanos. Su valor está en su comportamiento: si “cancelar mi suscripción” y “¿cómo dejo de pagar mi plan?” producen vectores próximos, el sistema puede tratarlos como relacionados aun compartiendo pocas (o ninguna) palabras.
Texto, imágenes y audio también pueden convertirse en vectores
Las incrustaciones no se limitan al texto.
- Incrustaciones de texto representan oraciones, párrafos, tickets de soporte, descripciones de producto y más.
- Incrustaciones de imagen representan similitud visual y conceptos (p. ej., “zapatillas rojas para correr”).
- Incrustaciones de audio pueden representar oradores, tono, o el significado de palabras habladas cuando se combinan con modelos de voz.
Así una única base de datos vectorial puede soportar “buscar con una imagen”, “encontrar canciones similares” o “recomendar productos parecidos”.
Generadas por modelos — no escritas a mano
Los vectores no salen de etiquetado manual. Los produce el aprendizaje automático con modelos entrenados para comprimir significado en números. Envías contenido a un modelo de incrustaciones (alojado por ti o un proveedor) y devuelve un vector. Tu app almacena ese vector junto al contenido original y los metadatos.
Por qué la elección del modelo de incrustaciones afecta calidad y coste
El modelo de incrustaciones que elijas influye mucho en los resultados. Modelos más grandes o especializados suelen mejorar la relevancia pero cuestan más (y pueden ser más lentos). Modelos pequeños pueden ser más baratos y rápidos, pero perder matices—especialmente para lenguaje específico de un dominio, múltiples idiomas o consultas cortas. Muchos equipos evalúan varios modelos al principio para encontrar el mejor trade-off antes de escalar.
Cómo almacenan datos las bases de datos vectoriales
Una base de datos vectorial se basa en una idea simple: almacenar el “significado” (un vector) junto con la información que necesitas para identificar, filtrar y mostrar resultados.
El modelo de datos básico
La mayoría de los registros se parecen a esto:
- ID: un identificador único que controlas (p. ej.,
doc_18492 o un UUID)
- Vector (incrustación): un array de números que representa el significado del contenido
- Metadatos: campos clave–valor como title, URL, tags, author, language, created_at o tenant_id
Por ejemplo, un artículo del centro de ayuda podría almacenar:
- ID:
kb_123
- Vector: 768 números de punto flotante (para un modelo de incrustaciones común)
- Metadatos:
{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }
El vector es lo que potencia la similitud semántica. El ID y los metadatos hacen que los resultados sean utilizables.
Los metadatos hacen dos trabajos:
- Filtrado antes/después de la búsqueda vectorial: “Mostrar solo resultados del producto X”, “solo inglés”, “solo documentos que el usuario puede ver”, o “solo ítems más recientes de 90 días”. Esto es esencial para relevancia y control de acceso.
- Presentación y acciones: Cuando presentas un resultado, los usuarios no quieren un vector: quieren un title, un snippet y un link (URL). Los metadatos dan los detalles que necesita tu UI.
Sin buenos metadatos puedes recuperar el significado correcto pero aún así mostrar el contexto equivocado.
Tamaños comunes de vectores e implicaciones de almacenamiento
El tamaño de la incrustación depende del modelo: 384, 768, 1024 y 1536 dimensiones son frecuentes. Más dimensiones pueden captar más matices, pero también aumentan:
- Almacenamiento (cada registro guarda más números)
- Presión de memoria para búsquedas rápidas
- Tiempo de construcción del índice (especialmente con indexación ANN)
Como intuición: duplicar dimensiones suele subir coste y latencia a menos que lo compenses con opciones de indexado o compresión.
Patrones de actualización: inserciones, cambios y borrados
Los datasets reales cambian, así que las bases de datos vectoriales suelen soportar:
- Insert: añadir nuevo contenido con su incrustación y metadatos
- Update: cambiar metadatos (p. ej., tags) o reemplazar el vector si el contenido cambió
- Delete: eliminar contenido obsoleto o revocado
- Re-embed: recalcular vectores cuando cambias de modelo de incrustaciones, la fragmentación o editas mucho el texto
Planear las actualizaciones temprano evita un problema de “conocimiento obsoleto” donde la búsqueda devuelve contenido que ya no coincide con lo que ven los usuarios.
Búsqueda por similitud: encontrar el “significado más cercano” rápido
Una vez que tu texto, imágenes o productos se convierten en incrustaciones (vectores), la búsqueda se vuelve un problema de geometría: “¿Qué vectores están más cerca de este vector de consulta?” Esto se llama búsqueda de vecinos más cercanos. En lugar de emparejar palabras clave, el sistema compara significados midiendo qué tan cerca están dos vectores.
Vecinos más cercanos en palabras sencillas
Imagina cada pieza de contenido como un punto en un enorme espacio multidimensional. Cuando un usuario busca, su consulta se convierte en otro punto. La búsqueda por similitud devuelve los ítems cuyos puntos están más cerca: tus “vecinos más cercanos”. Esos vecinos probablemente compartan intención, tema o contexto, aun cuando no compartan palabras exactas.
Métricas de similitud comunes
Las bases de datos vectoriales suelen soportar unas cuantas formas estándar de puntuar “cercanía”:
- Similitud coseno: compara el ángulo entre vectores (útil cuando te importa la dirección/significado más que la magnitud).
- Producto punto: relacionado con el coseno, pero también influido por la longitud del vector; se usa a menudo con incrustaciones normalizadas.
- Distancia euclidiana: la distancia en línea recta entre puntos (útil en algunos modelos y dominios).
Diferentes modelos de incrustaciones se entrenan con una métrica en mente, así que es importante usar la recomendada por el proveedor del modelo.
Búsqueda exacta vs aproximada (ANN)
Una búsqueda exacta compara con cada vector para encontrar los verdaderos vecinos más cercanos. Es precisa, pero se vuelve lenta y cara al escalar a millones de ítems.
La mayoría usa approximate nearest neighbor (ANN). ANN utiliza estructuras de índice inteligentes para reducir la búsqueda a los candidatos más prometedores. Normalmente obtienes resultados “suficientemente cercanos” al mejor match verdadero — y mucho más rápido.
El trade-off entre latencia y recall
ANN es popular porque te permite ajustar según tus necesidades:
- Menor latencia (respuestas más rápidas) buscando menos candidatos.
- Mayor recall (encontrar más de los verdaderos mejores matches) buscando más.
Ese ajuste es la razón por la que la búsqueda vectorial funciona bien en apps reales: puedes mantener respuestas ágiles y aun así devolver resultados muy relevantes.
Flujo de trabajo de búsqueda semántica de extremo a extremo
La búsqueda semántica es más fácil de entender como una canalización simple: conviertes texto en significado, buscas significado similar y presentas los matches más útiles.
1) Incrustar la consulta
Un usuario escribe una pregunta (por ejemplo: “¿Cómo cancelo mi plan sin perder datos?”). El sistema pasa ese texto por un modelo de incrustaciones y produce un vector: un array de números que representa el significado de la consulta en lugar de sus palabras exactas.
2) Buscar en la base de datos vectorial
Ese vector de consulta se envía a la base de datos vectorial, que realiza una búsqueda por similitud para encontrar los vectores “más cercanos” entre tu contenido almacenado.
La mayoría devuelve los top-K matches: los K fragmentos/documentos más similares.
- Por qué K es configurable: un K más pequeño es más rápido y a menudo suficiente (p. ej., K=5).
- Un K mayor aumenta el recall (es menos probable que pierdas la respuesta correcta), pero puede incluir más resultados “casi relevantes” (p. ej., K=50).
3) (Opcional) Reordenar para precisión
La búsqueda por similitud está optimizada para velocidad, así que el top-K inicial puede contener falsos positivos. Un reranker es un segundo modelo que examina la consulta y cada candidato juntos y los reordena por relevancia.
Piensa en ello así: la búsqueda vectorial te da una buena lista corta; el reranker elige el mejor orden.
4) Devolver resultados (o pasarlos a un sistema downstream)
Finalmente devuelves los mejores matches al usuario (como resultados de búsqueda), o los pasas a un asistente de IA (por ejemplo, un sistema RAG) como el contexto “fundamentador”.
Si construyes este flujo en una app, plataformas como Koder.ai pueden ayudarte a prototipar rápido: describes la experiencia de búsqueda semántica o RAG en una interfaz de chat, luego iteras sobre el front-end en React y el backend en Go/PostgreSQL, manteniendo la canalización de recuperación (incrustar → búsqueda vectorial → rerank opcional → respuesta) como parte central del producto.
Un ejemplo rápido “palabras clave vs semántica”
Si tu artículo del centro de ayuda dice “terminar suscripción” y el usuario busca “cancelar mi plan”, la búsqueda por palabras clave puede fallar porque “cancelar” y “terminar” no coinciden. La búsqueda semántica normalmente lo recuperará porque la incrustación captura que ambas frases expresan la misma intención. Añade reranking y los resultados superiores suelen volverse no solo “similares”, sino directamente útiles para la pregunta del usuario.
Elige el plan adecuado
Pasa de Free a Pro o Business cuando aumenten tu uso y las necesidades del equipo.
La búsqueda puramente vectorial es excelente para captar “significado”, pero los usuarios no siempre buscan por significado. A veces necesitan una coincidencia exacta: un nombre completo, un SKU, un ID de factura o un código de error copiado de un log. La búsqueda híbrida combina señales semánticas (vectores) con señales léxicas (búsqueda tradicional como BM25).
Qué hace realmente la “búsqueda híbrida”
Una consulta híbrida suele ejecutar dos caminos en paralelo:
- Búsqueda vectorial: encuentra contenido conceptualmente similar, aun si la redacción difiere.
- Búsqueda por palabras clave / BM25: encuentra contenido que comparte los mismos tokens, premiando términos exactos y palabras raras.
El sistema luego combina esos candidatos en una lista rankeada.
Cuándo la híbrida es la mejor opción por defecto
La búsqueda híbrida destaca cuando tus datos incluyen cadenas que deben coincidir obligatoriamente:
- Nombres de producto con modificadores específicos (p. ej., “Pro Max”, “Gen 2”)
- IDs (números de pedido, IDs de tickets, números de pieza)
- Códigos de error (“E0421”, “ORA-00933”) y flags de comandos
- Términos de dominio raros donde los sinónimos serían riesgosos
La búsqueda semántica sola puede devolver páginas relacionadas en general; la búsqueda de palabras clave sola puede perder respuestas redactadas de forma distinta. Híbrida cubre ambos modos de fallo.
Los filtros de metadatos restringen la recuperación antes del ranking (o junto a él), mejorando relevancia y velocidad. Filtros comunes incluyen:
- Idioma (devolver solo documentos en inglés)
- Rango de fechas (política más reciente, notas de la última versión)
- Categoría o fuente (docs vs tickets; “facturación” vs “seguridad”)
- Etiquetas de control de acceso (solo lo que este usuario puede ver)
Cómo funciona el scoring (a alto nivel)
La mayoría usa una mezcla práctica: ejecutar ambas búsquedas, normalizar puntajes para que sean comparables y aplicar pesos (p. ej., “apoya más en keywords para IDs”). Algunos productos también reordenan la lista combinada con un modelo ligero o reglas, mientras que los filtros aseguran que estás rankeando el subconjunto correcto desde el inicio.
RAG: usar bases de datos vectoriales para fundamentar respuestas de LLM
Retrieval-Augmented Generation (RAG) es un patrón práctico para obtener respuestas más fiables de un LLM: primero recuperar información relevante, luego generar una respuesta ligada a ese contexto recuperado.
La idea de RAG en una frase
En lugar de pedir al modelo que “recuerde” tus documentos de empresa, almacenas esos documentos (como incrustaciones) en una base de datos vectorial, recuperas los fragmentos más relevantes al momento de la consulta y los pasas al LLM como contexto de apoyo.
Por qué una base de datos vectorial ayuda a reducir las alucinaciones
Los LLM son excelentes escribiendo, pero completan con confianza cuando no tienen los hechos necesarios. Una base de datos vectorial facilita traer los pasajes de significado más cercano de tu base de conocimiento y suministrarlos en el prompt.
Ese grounding cambia al modelo de “inventar una respuesta” a “resumir y explicar estas fuentes”. También facilita auditar respuestas porque puedes rastrear qué fragmentos se recuperaron y opcionalmente mostrar citas.
Fundamentos de fragmentación (para que la recuperación funcione)
La calidad de RAG a menudo depende más de la fragmentación que del modelo.
- Tamaño del fragmento: Apunta a fragmentos que contengan un pensamiento completo (a menudo una sección corta). Demasiado pequeños pierden significado; demasiado grandes incorporan ruido.
- Solapamiento: Añade un pequeño solapamiento para que detalles importantes en los límites no se separen de su contexto.
- Mantener contexto: Conserva títulos, encabezados e identificadores (nombre del doc, sección, fecha) como metadatos para que los resultados sean comprensibles y filtrables.
Diagrama simple de pipeline RAG (descripción)
Imagina este flujo:
Pregunta del usuario → Incrustar pregunta → Vector DB recupera top-K fragmentos (+ filtros opcionales de metadatos) → Construir prompt con los fragmentos recuperados → LLM genera respuesta → Devolver respuesta (y fuentes).
La base de datos vectorial se sitúa en el medio como la “memoria rápida” que aporta la evidencia más relevante para cada petición.
Casos de uso comunes impulsados por bases de datos vectoriales
Aprovecha al máximo tus créditos
Crea contenido sobre Koder.ai o recomienda a compañeros para extender tu tiempo de desarrollo.
Las bases de datos vectoriales no solo hacen la búsqueda “más inteligente”: habilitan experiencias de producto donde los usuarios describen lo que quieren en lenguaje natural y aun así obtienen resultados relevantes. A continuación algunos casos prácticos recurrentes.
Soporte al cliente: encontrar respuestas más allá de palabras clave
Los equipos de soporte suelen tener una base de conocimientos, tickets antiguos, transcripciones de chat y notas de lanzamiento: la búsqueda por palabras clave falla con sinónimos, paráfrasis y descripciones vagas.
Con búsqueda semántica, un agente (o un chatbot) puede recuperar tickets pasados que significan lo mismo aunque la redacción sea distinta. Eso acelera la resolución, reduce trabajo duplicado y ayuda a nuevos agentes a subir la curva más rápido. Combinar búsqueda vectorial con filtros de metadatos (línea de producto, idioma, tipo de incidencia, rango de fechas) mantiene los resultados enfocados.
Descubrimiento de producto: buscar catálogos como habla la gente
Los compradores rara vez conocen nombres exactos de producto. Buscan intenciones como “mochila pequeña que entre un portátil y sea elegante”. Las incrustaciones capturan esas preferencias—estilo, función, restricciones—así que los resultados parecen más cercanos a un asistente humano.
Esto funciona para catálogos retail, listados de viajes, inmobiliaria, bolsas de empleo y marketplaces. También puedes mezclar relevancia semántica con restricciones estructuradas como precio, tamaño, disponibilidad o ubicación.
Recomendaciones: “ítems similares” y descubrimiento de contenido
Una característica clásica es “encontrar cosas parecidas”. Si un usuario ve un ítem, lee un artículo o mira un vídeo, puedes recuperar otros contenidos con significado o atributos similares—aunque las categorías no coincidan exactamente.
Útil para:
- Módulos “Más como esto”
- Artículos relacionados y sugerencias en la base de conocimientos
- Detección de duplicados o casi-duplicados (moderación de contenido o limpieza)
Búsqueda interna con permisos: políticas, docs, notas de reuniones
Dentro de las empresas, la información está dispersa en docs, wikis, PDFs y notas. La búsqueda semántica ayuda a empleados a preguntar naturalmente (“¿Cuál es nuestra política de reembolso para congresos?”) y encontrar la fuente correcta.
La parte innegociable es el control de acceso: los resultados deben respetar permisos—a menudo filtrando por equipo, propietario del documento, nivel de confidencialidad o una lista ACL—para que los usuarios solo recuperen lo que pueden ver.
Si quieres ir más allá, esta misma capa de recuperación es lo que alimenta sistemas de preguntas fundamentadas (cubierto en la sección RAG).
Pipelines de datos: ingestión, fragmentación y actualizaciones
Un sistema de búsqueda semántica solo es tan bueno como la canalización que lo alimenta. Si los documentos llegan de forma inconsistente, se fragmentan mal o nunca se re-incrustan tras ediciones, los resultados se alejan de lo que los usuarios esperan.
Un flujo de ingestión simple (que funciona)
La mayoría sigue una secuencia repetible:
- Recolectar datos (docs, PDFs, tickets, logs de chat, páginas de wiki, datos de producto).
- Limpiar (quitar boilerplate, arreglar encoding, normalizar espacios, extraer texto principal).
- Fragmentar (dividir en pasajes manejables que los usuarios querrían recuperar).
- Incrustar (generar vectores con el modelo elegido).
- Upsert (escribir vectores + metadatos en la base de datos vectorial, reemplazando cuando sea necesario).
El paso de “fragmentar” es donde muchos pipelines ganan o pierden. Fragmentos demasiado grandes diluyen el significado; demasiado pequeños pierden contexto. Un enfoque práctico es fragmentar por estructura natural (encabezados, párrafos, pares de preguntas y respuestas) y mantener un pequeño solapamiento para continuidad.
Mantener las incrustaciones actualizadas
El contenido cambia constantemente—políticas se actualizan, precios cambian, artículos se reescriben. Trata las incrustaciones como datos derivados que deben regenerarse.
Tácticas comunes:
- Guarda un ID del documento fuente, ID del fragmento y un hash del contenido. Si el hash cambia, vuelve a incrustar ese fragmento.
- Usa borrados suaves (marcar fragmentos antiguos como inactivos) para evitar resultados fantasma.
- Reconstruir selectivamente en lugar de re-incrustar todo.
Actualizaciones por lotes vs streaming
- Batch encaja con backfills grandes, sincronizaciones nocturnas y contenido predecible (documentación, bases de conocimiento).
- Streaming es para fuentes de cambios rápidos (tickets de soporte, contenido generado por usuarios, inventario). Reduce obsolescencia pero requiere más monitorización y control de costes.
Múltiples idiomas y múltiples modelos
Si sirves varios idiomas, puedes usar un modelo multilingüe (más simple) o modelos por idioma (a veces de mayor calidad). Si experimentas con modelos, versiona tus incrustaciones (p. ej., embedding_model=v3) para ejecutar pruebas A/B y revertir sin romper la búsqueda.
Cómo evaluar calidad y rendimiento
La búsqueda semántica puede sentirse “bien” en una demo y aun así fallar en producción. La diferencia es la medición: necesitas métricas claras de relevancia y objetivos de velocidad, evaluadas con consultas que parezcan comportamiento real de usuarios.
Métricas de relevancia que reflejan satisfacción
Empieza con un conjunto pequeño de métricas y consérvalas en el tiempo:
- Precision / Recall: Precision indica cuántos resultados devueltos son realmente relevantes; recall indica cuántos ítems relevantes lograste recuperar. Úsalos cuando tengas una definición clara de “relevante”.
- MRR (Mean Reciprocal Rank): Ideal cuando el usuario espera una “mejor” respuesta. Premia poner el documento correcto cerca de la cima.
- nDCG: Útil cuando varios resultados pueden ser relevantes en diferentes niveles (muy relevante vs algo relevante).
- Latencia (p50/p95): Supervisa tanto la mediana como la cola. Un p50 rápido con un p95 lento todavía se siente lento para los usuarios.
Construye un conjunto de pruebas confiable
Crea un set de evaluación a partir de:
- Consultas reales de logs de búsqueda o tickets (anonimizadas).
- Documentos esperados (labels gold) acordados por expertos del dominio.
- Casos límite: consultas cortas (“reembolso”), preguntas largas, términos ambiguos, nombres de producto raros y consultas de “sin resultados” donde el comportamiento correcto es decir “no hay resultados”.
Mantén el set versionado para comparar resultados entre lanzamientos.
Pruebas A/B y bucles de retroalimentación
Las métricas offline no capturan todo. Ejecuta A/B tests y recoge señales ligeras:
- Pulgares arriba/abajo en resultados
- Click-through y tiempo de permanencia
- Eventos de “refinar búsqueda”
Usa ese feedback para actualizar juicios de relevancia y detectar patrones de fallo.
Monitorizar deriva con el tiempo
El rendimiento puede cambiar cuando:
- Cambias modelos de incrustaciones o la forma de fragmentar contenido.
- Tu corpus cambia (nuevos productos, cambios de políticas, términos estacionales).
Vuelve a ejecutar tu suite de pruebas tras cualquier cambio, monitoriza métricas semanalmente y configura alertas para caídas bruscas en MRR/nDCG o picos en latencia p95.
Seguridad, privacidad y control de acceso
Despliega tu app de IA
Pasa de una idea local a una app alojada que puedas compartir con tu equipo.
La búsqueda vectorial cambia cómo se recupera la información, pero no debe cambiar quién puede verla. Si tu sistema semántico o RAG puede “encontrar” el fragmento correcto, también puede devolver un fragmento al que el usuario no está autorizado—a menos que diseñes permisos y privacidad en la etapa de recuperación.
Control de acceso: aplicarlo en el momento de la recuperación
La regla más segura es simple: un usuario solo debería recuperar contenido que pueda leer. No confíes en que la app “oculte” resultados después de que la base de datos vectorial los devuelva—porque para entonces el contenido ya salió de tu almacenamiento.
Enfoques prácticos:
- ACLs por documento (o por fragmento): almacena campos de permiso junto a cada vector para que cada consulta pueda aplicarlos.
- Aislamiento por tenant: en apps multi-tenant, separa datos por tenant (particiones lógicas, namespaces o índices separados) para evitar fugas entre tenants.
Muchas bases de datos vectoriales soportan filtros basados en metadatos (p. ej., tenant_id, department, project_id, visibility) que se ejecutan junto con la búsqueda por similitud. Usados correctamente, son una forma limpia de aplicar permisos durante la recuperación.
Un detalle crucial: asegura que el filtro sea obligatorio y server-side, no lógica opcional en el cliente. También ten cuidado con la “explosión de roles” (demasiadas combinaciones). Si tu modelo de permisos es complejo, considera precomputar “grupos de acceso efectivos” o usar un servicio de autorización dedicado para emitir un token de filtro en tiempo de consulta.
PII y datos sensibles: decidir qué nunca incrustar
Las incrustaciones pueden codificar significado del texto original. Eso no revela automáticamente PII cruda, pero puede aumentar el riesgo (p. ej., hechos sensibles que se vuelven más fáciles de recuperar).
Buenas prácticas:
- Evitar incrustar campos altamente sensibles (SSNs, detalles de pago, identificadores médicos) cuando sea posible.
- Redactar antes de incrustar si el texto debe ser buscable (reemplazar valores exactos por placeholders).
- Almacenar originales por separado y recuperarlos solo tras comprobaciones de permiso.
Necesidades operativas: backups, retención y auditoría
Trata tu índice vectorial como datos de producción:
- Backups y recuperación: los índices pueden ser caros de reconstruir; planifica snapshots o una ruta de reconstrucción desde los datos fuente.
- Políticas de retención: elimina vectores cuando los documentos fuente expiran o un usuario solicita borrado.
- Auditabilidad: registra quién consultó qué (al menos contexto de la consulta e IDs de documentos devueltos) para soportar investigaciones y cumplimiento.
Hecho correctamente, estas prácticas hacen que la búsqueda semántica parezca mágica para los usuarios—sin convertirse en una sorpresa de seguridad más adelante.
Trampas, costes y una lista de comprobación práctica
Las bases de datos vectoriales pueden parecer “plug-and-play”, pero la mayoría de las decepciones vienen de decisiones colaterales: cómo fragmentas datos, qué modelo de incrustaciones eliges y cuánto cuidas mantener todo actualizado.
Modos de fallo comunes (y cómo detectarlos)
Mala fragmentación es la causa nº1 de resultados irrelevantes. Fragmentos demasiado grandes diluyen significado; fragmentos demasiado pequeños pierden contexto. Si los usuarios dicen a menudo “encontró el documento correcto pero el pasaje equivocado”, probablemente tu estrategia de fragmentación necesita ajuste.
El modelo de incrustaciones incorrecto se nota como desajuste semántico constante: resultados fluidos pero fuera de tema. Ocurre cuando el modelo no es adecuado para tu dominio (legal, médico, tickets de soporte) o tu tipo de contenido (tablas, código, texto multilingüe).
Datos obsoletos generan desconfianza rápido: los usuarios buscan la política más reciente y obtienen la versión del trimestre pasado. Si tu fuente cambia, tus incrustaciones y metadatos deben actualizarse (y los borrados deben borrar realmente).
Manejo de arranque en frío y resultados vacíos
Al principio puede haber poco contenido, pocas consultas o poco feedback para afinar la recuperación. Planifica:
- Fallbacks: búsqueda por palabras clave o respuestas curadas cuando los resultados semánticos son débiles.
- UX para resultados vacíos: mostrar categorías relacionadas, hacer una pregunta aclaratoria o ampliar filtros.
- Consultas de calentamiento: prueba con un conjunto pequeño de preguntas representativas antes del lanzamiento.
Drivers de coste a presupuestar
Los costes suelen venir de cuatro sitios:
- Cómputo para incrustaciones (backfill inicial + actualizaciones continuas)
- Almacenamiento (vectores, metadatos e índices)
- Volumen de consultas (lecturas, egress de red y concurrencia)
- Reranking (opcional pero potente; puede añadir coste por consulta con modelos)
Si comparas proveedores, pide una estimación mensual simple usando tu conteo esperado de documentos, tamaño medio de fragmento y QPS pico. Muchas sorpresas aparecen tras indexar y durante picos de tráfico.
Lista de comprobación práctica para seleccionar una base de datos vectorial
Usa este checklist corto para elegir una base de datos vectorial que encaje:
- Calidad de búsqueda: ¿soporta búsqueda híbrida (keywords + vectores) y filtros de metadatos? ¿Puedes añadir reranking?
- Rendimiento: opciones de indexado ANN, latencia predecible en picos y escalado sencillo.
- Operaciones de datos: upserts, deletes, re-indexado, versionado y backfills sin downtime.
- Observabilidad: logs de consulta, métricas de recall/latencia y herramientas para depurar “por qué este resultado”.
- Seguridad: cifrado, aislamiento por tenant, control de acceso por roles y patrones de filtrado por permisos.
- Integración: SDKs, lenguajes soportados y conectores a tu almacenamiento (S3, bases de datos, docs).
- Coste total: precios transparentes para almacenamiento, escrituras, lecturas y cualquier cómputo gestionado.
Elegir bien tiene menos que ver con perseguir el tipo de índice más nuevo y más con la fiabilidad: ¿puedes mantener los datos frescos, controlar el acceso y sostener la calidad a medida que crecen tu contenido y tráfico?