Por qué Kubernetes cambió las operaciones del día a día
Kubernetes no solo introdujo una nueva herramienta: cambió cómo se ven las “operaciones diarias” cuando gestionas docenas (o cientos) de servicios. Antes de la orquestación, los equipos a menudo hilaban scripts, runbooks manuales y conocimiento tribal para responder las mismas preguntas recurrentes: ¿Dónde debería ejecutarse este servicio? ¿Cómo desplegamos un cambio de forma segura? ¿Qué pasa si un nodo muere a las 2 a.m.?
Qué soluciona realmente la “orquestación"
En su núcleo, la orquestación es la capa de coordinación entre tu intención (“ejecuta este servicio así”) y la realidad desordenada de máquinas que fallan, tráfico que cambia y despliegues continuos. En lugar de tratar cada servidor como una pieza única, la orquestación trata la capacidad de cómputo como un pool y las cargas de trabajo como unidades programables que pueden moverse.
Kubernetes popularizó un modelo donde los equipos describen lo que quieren y el sistema trabaja continuamente para que la realidad coincida con esa descripción. Ese cambio importa porque convierte las operaciones en procesos repetibles en lugar de en heroísmos.
Kubernetes estandarizó los resultados operativos que la mayoría de los equipos de servicio necesitan:
- Despliegue: una manera consistente de declarar qué debe ejecutarse, actualizarlo y verificar que esté sano.
- Escalado: una vía práctica de uno a muchos sin rediseñar el servicio ni aprovisionar máquinas manualmente.
- Operaciones de servicio: formas estables para que los servicios se encuentren, enruten tráfico y sigan funcionando a medida que las instancias cambian.
Nota sobre alcance y fuentes
Este artículo se centra en las ideas y patrones asociados con Kubernetes (y líderes como Brendan Burns), no en una biografía personal. Y cuando hablamos de “cómo empezó” o “por qué se diseñó así”, esas afirmaciones deben basarse en fuentes públicas: charlas de conferencias, documentos de diseño y documentación upstream, para que la historia sea verificable y no mitológica.
Brendan Burns en la historia de origen de Kubernetes (visión general)
Brendan Burns es ampliamente reconocido como uno de los tres cofundadores originales de Kubernetes, junto a Joe Beda y Craig McLuckie. En los primeros trabajos de Kubernetes en Google, Burns ayudó a dar forma tanto a la dirección técnica como a la forma en que el proyecto se explicaba a los usuarios—especialmente en torno a “cómo operas software” en lugar de solo “cómo ejecutas contenedores”. (Fuentes: Kubernetes: Up & Running, O’Reilly; listados de AUTORES/mantenedores del repositorio de Kubernetes)
La colaboración open source moldeó el diseño
Kubernetes no fue simplemente “lanzado” como un sistema interno terminado; se construyó en público con un conjunto creciente de contribuyentes, casos de uso y restricciones. Esa apertura empujó al proyecto hacia interfaces que pudieran sobrevivir en distintos entornos:
- APIs claras y versionadas en lugar de detalles internos ocultos
- comportamientos portables entre proveedores cloud y entornos on-prem
- puntos de extensión para que el núcleo se mantuviera relativamente pequeño pero soportara muchas necesidades
Esta presión colaborativa importa porque influyó en lo que Kubernetes optimizó: primitivas compartidas y patrones repetibles con los que muchos equipos pudieran alinearse, aunque discrepasen en herramientas.
Qué significa realmente “estandarizar” aquí
Cuando la gente dice que Kubernetes “estandarizó” despliegue y operaciones, normalmente no quiere decir que todos los sistemas se hicieran idénticos. Quiere decir que proporcionó un vocabulario común y un conjunto de flujos de trabajo que pueden repetirse entre equipos:
- “deployment”, “service”, “ingress”, “job”, “namespace” como términos compartidos
- un modelo consistente para declarar lo que quieres (y dejar que el sistema lo alcance)
- formas previsibles de desplegar cambios, escalar y recuperarse de fallos
Ese modelo compartido facilitó que documentación, herramientas y prácticas de equipo se transfirieran de una empresa a otra.
Kubernetes como proyecto vs. ecosistema
Es útil separar Kubernetes (el proyecto open source) del ecosistema Kubernetes.
El proyecto es la API central y los componentes del plano de control que implementan la plataforma. El ecosistema es todo lo que creció alrededor: distribuciones, servicios gestionados, add-ons y proyectos CNCF adyacentes. Muchas “funcionalidades de Kubernetes” que la gente usa en producción (stacks de observabilidad, motores de políticas, herramientas GitOps) viven en ese ecosistema, no en el núcleo del proyecto.
La idea central: estado deseado declarativo
La configuración declarativa es un cambio simple en cómo describes sistemas: en lugar de enumerar los pasos a seguir, declaras lo que quieres como resultado.
En términos de Kubernetes, no le dices a la plataforma “arranca un contenedor, luego abre un puerto, luego reinícialo si se cae.” Declara “deben ejecutarse tres copias de esta app, accesible en este puerto, usando esta imagen de contenedor.” Kubernetes se responsabiliza de hacer que la realidad coincida con esa descripción.
Estado deseado vs. scripts imperativos
Las operaciones imperativas son como un runbook: una secuencia de comandos que funcionó la vez anterior y se ejecuta de nuevo cuando algo cambia.
El estado deseado es más parecido a un contrato. Registras el resultado pretendido en un archivo de configuración y el sistema trabaja continuamente para alcanzarlo. Si algo se desvía—una instancia muere, un nodo desaparece, se cuela un cambio manual—la plataforma detecta la discrepancia y la corrige.
Antes/después: comandos de runbook vs. YAML
Antes (pensamiento imperativo de runbook):
- SSH a un servidor
- Bajar la nueva imagen del contenedor
- Parar el proceso viejo
- Iniciar el proceso nuevo
- Actualizar una regla de load balancer
- Si sube el tráfico, repetir en más servidores
Este enfoque funciona, pero es fácil terminar con servidores “snowflake” y una larga lista de verificación que solo unos pocos confían.
Después (estado deseado declarativo):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Cambias el archivo (por ejemplo, actualizas image o replicas), lo aplicas y los controladores de Kubernetes trabajan para reconciliar lo que está corriendo con lo que se declaró.
Por qué reduce el esfuerzo y la deriva
El estado deseado declarativo reduce la carga operacional al convertir “haz estos 17 pasos” en “mantenlo así”. También disminuye la deriva de configuración porque la fuente de verdad es explícita y revisable—a menudo en control de versiones—por lo que las sorpresas son más fáciles de detectar, auditar y revertir de forma consistente.
Controladores y reconciliación: el sistema que mantiene la verdad
Kubernetes parece “autogestionado” porque se construyó alrededor de un patrón simple: describes lo que quieres y el sistema trabaja continuamente para que la realidad coincida con esa descripción. El motor de ese patrón es el controlador.
Qué es un controlador (en términos sencillos)
Un controlador es un bucle que vigila el estado actual del clúster y lo compara con el estado deseado que declaraste en YAML (o mediante una llamada API). Cuando detecta una diferencia, actúa para reducirla.
No es un script de una sola ejecución ni espera a que un humano pulse un botón. Se ejecuta repetidamente—observar, decidir, actuar—por lo que puede responder al cambio en cualquier momento.
Reconciliación: cómo Kubernetes “mantiene las cosas verdaderas”
Ese comportamiento repetido de comparar y corregir se llama reconciliación. Es el mecanismo detrás de la promesa común de “auto-reparación”. El sistema no evita mágicamente las fallas; las detecta y las corrige.
La deriva puede ocurrir por razones mundanas:
- un proceso se cae
- un nodo desaparece
- alguien escala algo hacia arriba o abajo
- se actualiza un despliegue
La reconciliación significa que Kubernetes trata esos eventos como señales para volver a comprobar tu intención y restablecerla.
Los resultados que la gente realmente valora
Los controladores se traducen en resultados operativos familiares:
- Reemplazar pods fallidos: si un pod muere, un controlador nota que aún lo quieres y programa uno nuevo.
- Mantener conteos de réplicas: si pediste 5 réplicas y solo hay 4, Kubernetes creará la faltante.
- Mantener el progreso del rollout: durante actualizaciones, los controladores mueven el sistema hacia la nueva versión manteniendo la disponibilidad deseada.
La clave es que no estás persiguiendo manualmente los síntomas. Declaras el objetivo y los bucles de control hacen el trabajo continuo de “mantenerlo así”.
Por qué esto escala más allá de una característica
Este enfoque no se limita a un tipo de recurso. Kubernetes usa la misma idea de controlador y reconciliación en muchos objetos: Deployments, ReplicaSets, Jobs, Nodes, endpoints y más. Esa consistencia es una gran razón por la que Kubernetes se convirtió en plataforma: una vez entiendes el patrón, puedes predecir el comportamiento del sistema al añadir nuevas capacidades (incluyendo recursos personalizados que siguen el mismo bucle).
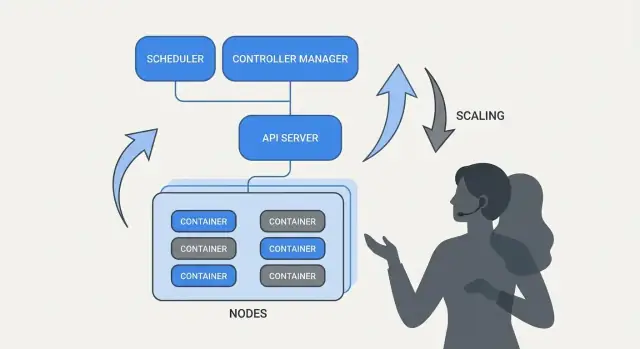
El scheduling como característica de producto, no tarea manual
Construye desde una especificación declarativa
Convierte una especificación lista para operaciones en una app real que puedes desplegar e iterar rápidamente.
Si Kubernetes solo hiciera “ejecutar contenedores”, todavía dejaría a los equipos con lo más difícil: decidir dónde debe ejecutarse cada workload. El scheduler es el sistema integrado que coloca Pods en los nodos correctos automáticamente, según necesidades de recursos y reglas que defines.
Eso importa porque las decisiones de colocación afectan directamente la disponibilidad y el coste. Una API web alojada en un nodo saturado puede volverse lenta o fallar. Un job batch colocado junto a servicios sensibles a la latencia puede crear problemas de vecino ruidoso. Kubernetes convierte esto en una capacidad de producto repetible en lugar de una rutina en hojas de cálculo y SSH.
Qué optimiza el scheduler
A nivel básico, el scheduler busca nodos que puedan satisfacer las requests de tu Pod.
- Requests de CPU/memoria: las requests reservan capacidad para las decisiones de colocación. Si pides 500m CPU y 1Gi de memoria, Kubernetes solo considerará nodos con suficiente capacidad disponible.
Este hábito único—establecer requests realistas—suele reducir la inestabilidad “aleatoria” porque los servicios críticos dejan de competir con todo lo demás.
Restricciones comunes que los equipos usan
Más allá de los recursos, la mayoría de clústeres de producción se apoyan en unas reglas prácticas:
- Affinity / anti-affinity: “coloca estos juntos” (para localidad de cache) o “mantenlos separados” (para evitar que una falla de nodo afecte todas las réplicas).
- Taints y tolerations: marca ciertos nodos como de propósito especial (nodos GPU, nodos del sistema, nodos para cumplimiento) y permite que solo cargas autorizadas aterricen allí.
Cómo esto reduce los cortes
Las funcionalidades de scheduling ayudan a los equipos a codificar la intención operativa:
- dispersar réplicas entre nodos para sobrevivir a fallos de nodo
- aislar jobs con picos lejos de servicios orientados al cliente
- evitar que nodos caros (como GPU) sean consumidos por cargas equivocadas
La lección práctica clave: trata las reglas de scheduling como requisitos de producto—escríbelas, revísalas y aplícalas de forma consistente—para que la fiabilidad no dependa de que alguien recuerde el “nodo correcto” a las 2 a.m.
Escalado: de una instancia a miles sin reescribir
Una de las ideas más prácticas de Kubernetes es que el escalado no debería requerir cambiar el código de la aplicación ni inventar un nuevo enfoque de despliegue. Si la app puede ejecutarse como un contenedor, la misma definición de workload suele crecer a cientos o miles de copias.
El escalado tiene dos capas
Kubernetes separa el escalado en dos decisiones relacionadas:
- Cuántos pods ejecutar (más copias de tu app para más throughput o redundancia).
- Cuánta capacidad de clúster tienes (suficientes nodos—y del tamaño correcto—para colocar esos pods).
Esa separación importa: puedes pedir 200 pods, pero si el clúster solo tiene espacio para 50, “escalar” se convierte en una cola de trabajo pendiente.
Autoscaling, conceptualmente (HPA, VPA, Cluster Autoscaler)
Kubernetes usa comúnmente tres autoscalers, cada uno centrado en una palanca distinta:
- Horizontal Pod Autoscaler (HPA): cambia el número de pods según señales como uso de CPU, memoria o métricas personalizadas de la app.
- Vertical Pod Autoscaler (VPA): ajusta requests/limits de los pods para que cada pod obtenga más (o menos) CPU/memoria.
- Cluster Autoscaler: añade o elimina nodos para que el scheduler tenga suficiente espacio para colocar los pods que pediste.
Usados juntos, esto convierte el escalado en política: “mantener la latencia estable” o “mantener la CPU alrededor de X%”, en lugar de una rutina manual que despierta a alguien.
De qué depende el “buen escalado”
El escalado solo funciona tan bien como las entradas:
- Métricas: la CPU es fácil pero no siempre significativa; tasa de peticiones, profundidad de colas y latencia suelen reflejar mejor la carga real.
- Requests/limits: dicen al scheduler qué necesita un pod. Sin ellos, la colocación y decisiones de autoscaling son conjeturas.
- Patrones de carga: picos, warm-ups lentos y jobs pesados en background cambian la rapidez con que el escalado debe reaccionar.
Errores comunes
Dos errores aparecen repetidamente: escalar por la métrica equivocada (la CPU baja mientras las peticiones fallan) y falta de requests (los autoscalers no pueden predecir capacidad, los pods se apilan y el rendimiento se vuelve inconsistente).
Despliegues seguros: rollouts, probes y rollbacks
Un gran cambio que Kubernetes popularizó es tratar “desplegar” como un problema de control continuo, no como un script único que ejecutas un viernes a las 5 p.m. Los rollouts y rollbacks son comportamientos de primera clase: declaras la versión que quieres y Kubernetes mueve el sistema hacia ella mientras comprueba continuamente si el cambio es realmente seguro.
Rollouts como transición controlada
Con un Deployment, un rollout es una sustitución gradual de Pods viejos por nuevos. En lugar de parar todo y volver a arrancar, Kubernetes puede actualizar por pasos—manteniendo capacidad disponible mientras la versión nueva demuestra que puede manejar tráfico real.
Si la versión nueva empieza a fallar, el rollback no es una emergencia: es una operación normal; puedes revertir a un ReplicaSet anterior (la última versión buena conocida) y dejar que el controlador restaure el estado antiguo.
Probes: prevenir releases “malos pero en ejecución”
Las comprobaciones de salud convierten los rollouts de “esperanza” a medibles.
- Readiness probes determinan si un Pod debe recibir tráfico. Un contenedor puede estar en ejecución pero no listo (calentando caches, esperando dependencias). La readiness impide enviar usuarios a una instancia que no puede responder correctamente.
- Liveness probes detectan cuando un contenedor está atascado o enfermo y necesita reinicio. Esto evita modos de fallo lentos donde un proceso está vivo pero roto.
Usadas correctamente, las probes reducen los falsos éxitos—deploys que parecen bien porque los Pods arrancaron, pero en realidad fallan en las peticiones.
Estrategias de despliegue: rolling, blue/green, canary
Kubernetes soporta una actualización rolling por defecto, pero los equipos suelen añadir patrones encima:
- Blue/green: mantener dos entornos completos y cambiar el tráfico del viejo (blue) al nuevo (green) una vez que green está verificado.
- Canary: enviar un pequeño porcentaje de tráfico a la versión nueva, observar métricas y luego ampliar gradualmente.
Seguridad que puedes medir (y automatizar)
Los despliegues seguros dependen de señales: tasa de errores, latencia, saturación e impacto al usuario. Muchos equipos conectan las decisiones de rollout a SLOs y presupuestos de error—si un canary consume demasiado presupuesto, la promoción se detiene.
El objetivo son triggers automáticos de rollback basados en indicadores reales (readiness fallida, aumento de 5xx, picos de latencia), para que el “rollback” sea una respuesta predecible del sistema y no un momento heroico a medianoche.
Operaciones de servicio: descubrimiento, enrutamiento y red estable
Extiende a móvil más tarde
Añade una app móvil en Flutter cuando la necesites, sin reiniciar el proyecto.
Una plataforma de contenedores solo parece “automática” si otras partes del sistema aún pueden encontrar tu app después de que se mueva. En clústeres reales de producción, los pods se crean, eliminan, reprograman y escalan constantemente. Si cada cambio requiriera actualizar direcciones IP en configuraciones, las operaciones se convertirían en trabajo constante y los fallos serían rutina.
Por qué importa el descubrimiento de servicios
El descubrimiento de servicios es la práctica de dar a los clientes una forma fiable de alcanzar un conjunto cambiante de backends. En Kubernetes, el cambio clave es que dejas de dirigirte a instancias individuales (“llama a 10.2.3.4”) y empiezas a llamar a un servicio nombrado (“llama a checkout”). La plataforma gestiona qué pods atienden actualmente ese nombre.
Services, selectors y endpoints (en palabras simples)
Un Service es una puerta de entrada estable para un grupo de pods. Tiene un nombre consistente y una dirección virtual dentro del clúster, incluso cuando los pods subyacentes cambian.
Un selector es cómo Kubernetes decide qué pods están “detrás” de esa puerta. Normalmente coincide con labels, por ejemplo app=checkout.
Las Endpoints (o EndpointSlices) son la lista viva de IPs de pods que actualmente coinciden con el selector. Cuando los pods escalan, se despliegan o se reprograman, esa lista se actualiza automáticamente—los clientes siguen usando el mismo nombre de Service.
Direcciones estables, balanceo y enrutamiento de tráfico
Operativamente, esto proporciona:
- Direcciones estables: las apps hablan a un nombre DNS del Service en lugar de perseguir IPs de pods.
- Balanceo de carga: el tráfico se distribuye entre pods sanos detrás del Service.
- Enrutamiento predecible: puedes separar “quién debe recibir tráfico” (labels/selectors) de “dónde están corriendo los pods”.
Para tráfico norte–sur (desde fuera del clúster), Kubernetes suele usar un Ingress o el más nuevo Gateway. Ambos proporcionan un punto de entrada controlado donde puedes enrutar por hostname o path y suelen centralizar TLS. La idea importante es la misma: mantener el acceso externo estable mientras los backends cambian debajo.
Auto-reparación: qué significa realmente en producción
“Auto-reparación” en Kubernetes no es magia. Son reacciones automatizadas al fallo: reiniciar, reprogramar y reemplazar. La plataforma vigila lo que dijiste que querías (tu estado deseado) y empuja la realidad de vuelta hacia ello.
Reiniciar: cuando un contenedor se cae
Si un proceso sale o un contenedor se vuelve poco sano, Kubernetes puede reiniciarlo en el mismo nodo. Esto normalmente se rige por:
- Liveness probes: “¿sigue funcionando este contenedor?” Si no, reinícialo.
- Políticas de reinicio: reglas sobre cuándo deben ocurrir reinicios.
Un patrón común en producción: un contenedor se cae → Kubernetes lo reinicia → tu Service solo enruta a Pods sanos.
Reprogramar y reemplazar: cuando un nodo falla
Si un nodo entero cae (falla de hardware, kernel panic, pérdida de red), Kubernetes marca el nodo como no disponible y comienza a mover trabajo a otro lado. A grandes rasgos:
- El nodo se marca como unhealthy/not ready.
- Los Pods que estaban ahí se consideran perdidos.
- Los controladores crean Pods de reemplazo en otros nodos sanos para restaurar el recuento deseado.
Esto es auto-reparación a nivel de clúster: el sistema reemplaza capacidad en lugar de esperar a que un humano haga SSH.
Observabilidad: cómo sabes que se está reparando
La auto-reparación solo importa si puedes verificarla. Los equipos suelen vigilar:
- Logs (logs de la app y eventos de la plataforma) para ver qué se reinició y por qué
- Métricas como contadores de reinicios, probes fallidas y readiness de nodos
- Alertas cuando la reparación falla (p. ej., CrashLoopBackOff repetido, escasez de réplicas o demasiadas evicciones)
Configuraciones erróneas que rompen la auto-reparación
Incluso con Kubernetes, la “reparación” puede fallar si los guardrails son incorrectos:
- Probes de liveness/readiness malas o ausentes (falsos positivos o Pods que nunca están listos)
- Falta de requests/limits, llevando a scheduling impredecible u OOM kills
- Demasiadas pocas réplicas (un solo Pod no da continuidad)
- Timings de probes demasiado agresivos que provocan tormentas de reinicio
- Workloads que dependen de estado local de nodo sin estrategia de almacenamiento duradero
Cuando la auto-reparación está bien calibrada, los incidentes son más pequeños y cortos—y, lo que es más importante, medibles.
Aduéñate del código
Toma el código fuente y aplica tus patrones de Kubernetes en tu propia pipeline.
Kubernetes no ganó solo porque pudiera ejecutar contenedores. Ganó porque ofreció APIs estándar para las necesidades operativas más comunes: desplegar, escalar, conectar en red y observar workloads. Cuando los equipos acuerdan la misma “forma” de objetos (como Deployments, Services, Jobs), las herramientas se pueden compartir entre organizaciones, la formación es más sencilla y las transferencias entre dev y ops dejan de depender del conocimiento tribal.
Por qué las APIs estándar cambian flujos de trabajo
Una API consistente significa que tu pipeline de despliegue no tiene que conocer las peculiaridades de cada app. Puede aplicar las mismas acciones—crear, actualizar, revertir y comprobar salud—usando los mismos conceptos de Kubernetes.
También mejora la alineación: equipos de seguridad pueden expresar guardrails como políticas; SREs pueden estandarizar runbooks alrededor de señales comunes de salud; desarrolladores pueden razonar sobre releases con un vocabulario compartido.
Extender Kubernetes: CRDs y Operators
El cambio hacia plataforma se hace evidente con las Custom Resource Definitions (CRDs). Una CRD te permite añadir un nuevo tipo de objeto al clúster (por ejemplo, Database, Cache o Queue) y gestionarlo con los mismos patrones de API que los recursos integrados.
Un Operator empareja esos objetos personalizados con un controlador que reconcilia continuamente la realidad con el estado deseado—gestionando tareas que antes eran manuales, como backups, failovers o upgrades de versión. El beneficio clave no es una automatización mágica; es reutilizar el mismo bucle de control que Kubernetes aplica a todo lo demás.
Encaje con GitOps, CI/CD y checks de políticas
Porque Kubernetes es impulsado por API, se integra bien con flujos modernos:
- GitOps: el estado deseado vive en Git; los cambios se revisan como código.
- CI/CD: pipelines que aplican manifests, esperan readiness y promueven versiones.
- Checks de políticas: admission controllers que pueden bloquear configuraciones riesgosas antes de que lleguen a producción.
Si quieres más guías prácticas de despliegue y operaciones basadas en estas ideas, navega por /blog.
Qué pueden aplicar los equipos hoy (incluso fuera de Kubernetes)
Las grandes ideas de Kubernetes—muchas asociadas a la formulación temprana de Brendan Burns—traducen bien incluso si ejecutas VMs, serverless o una instalación de contenedores más pequeña.
Patrones que mejoran las operaciones diarias
Escribe el “estado deseado” y deja que la automatización lo haga cumplir. Ya sea Terraform, Ansible o una pipeline CI, trata la configuración como la fuente de verdad. El resultado es menos pasos manuales de despliegue y muchas menos sorpresas de “en mi máquina funcionaba”.
Usa reconciliación, no scripts de una sola ejecución. En lugar de scripts que se ejecutan una vez y esperan lo mejor, crea bucles que verifiquen continuamente propiedades clave (versión, config, número de instancias, salud). Así obtienes operaciones repetibles y recuperación predecible después de fallos.
Haz que el scheduling y el escalado sean características de producto. Define cuándo y por qué agregas capacidad (CPU, profundidad de colas, SLOs de latencia). Incluso sin autoscaling de Kubernetes, los equipos pueden estandarizar reglas de escala para que el crecimiento no requiera reescribir la app ni despertar a alguien.
Estandariza los rollouts. Actualizaciones rolling, comprobaciones de salud y procedimientos rápidos de rollback reducen el riesgo de cambios. Puedes implementarlos con load balancers, feature flags y pipelines de despliegue que condicionen releases a señales reales.
Checklist de adopción segura
- Define el estado deseado de un servicio: versión, config, dependencias y número mínimo de instancias
- Añade endpoints de salud (equivalentes a liveness y readiness) y conéctalos al balanceador o pipeline de despliegue
- Automatiza pasos de rollout: desplegar, verificar, redirigir tráfico y revertir si hay fallos
- Crea un pequeño “reconciliador”: comprobaciones programadas que corrijan la deriva (config errónea, instancias faltantes)
- Añade disparadores de escalado con límites claros (máx. de instancias, cooldowns, reglas de aprobación)
Qué no soluciona por sí solo
Estos patrones no arreglan por sí solos el mal diseño de la app, migraciones de datos inseguras o control de costes. Sigues necesitando APIs versionadas, planes de migración, presupuestos/límites y observabilidad que relacione despliegues con impacto al cliente.
Próximos pasos
Elige un servicio orientado al cliente e implementa el checklist de extremo a extremo; luego expande.
Si estás creando nuevos servicios y quieres llegar a “algo desplegable” más rápido, Koder.ai puede ayudarte a generar una app web/backend/móvil completa a partir de una especificación conversacional—normalmente React en frontend, Go con PostgreSQL en backend y Flutter en móvil—y luego exportar el código fuente para que puedas aplicar los mismos patrones de Kubernetes tratados aquí (configuraciones declarativas, rollouts repetibles y operaciones con reversión). Para equipos que evalúan coste y gobernanza, también puedes revisar /pricing.