21 sept 2025·8 min
Cómo C y C++ siguen impulsando núcleos de SO, bases de datos y motores de juego
Descubre cómo C y C++ siguen formando el núcleo de sistemas operativos, bases de datos y motores de juego —por control de memoria, velocidad y acceso de bajo nivel.
Por qué C y C++ siguen importando entre bastidores
“Bajo el capó” es todo aquello de lo que depende tu aplicación pero que rara vez toca directamente: núcleos de sistemas operativos, controladores de dispositivos, motores de almacenamiento de bases de datos, pilas de red, runtimes y bibliotecas críticas para el rendimiento.
En cambio, lo que muchos desarrolladores de aplicaciones ven día a día es la superficie: frameworks, APIs, runtimes gestionados, gestores de paquetes y servicios en la nube. Esas capas están diseñadas para ser seguras y productivas, incluso cuando ocultan la complejidad intencionadamente.
Por qué algunas capas deben estar cerca del hardware
Algunos componentes de software tienen requisitos que son difíciles de cumplir sin control directo:
- Rendimiento y latencia previsibles (por ejemplo, programar tiempo de CPU, manejar interrupciones, transmitir activos)
- Control preciso de la memoria (disposición, alineación, comportamiento en caché, evitar pausas)
- Acceso directo al hardware (registros, DMA, controladores, sistemas de archivos y dispositivos de bloque)
- Binarios pequeños y portables que puedan ejecutarse temprano en el arranque o en entornos con recursos limitados
C y C++ siguen siendo habituales aquí porque compilan a código nativo con sobrecarga mínima en tiempo de ejecución y ofrecen a los ingenieros control fino sobre la memoria y las llamadas al sistema.
Dónde son más comunes hoy C y C++
A alto nivel, encontrarás C y C++ impulsando:
- Núcleos de sistemas operativos y bibliotecas de bajo nivel
- Controladores y firmware embebido
- Motores de bases de datos (ejecución de consultas, almacenamiento, indexación)
- Motores de juego y subsistemas en tiempo real (renderizado, física, audio)
- Compiladores, toolchains y runtimes de lenguajes de los que dependen otros lenguajes
Qué cubrirá (y qué no) este artículo
Este artículo se centra en la mecánica: qué hacen estos componentes “entre bastidores”, por qué se benefician del código nativo y qué compromisos conlleva ese poder.
No afirmará que C/C++ sean la mejor opción para todos los proyectos, ni será una guerra de lenguajes. El objetivo es una comprensión práctica de dónde estos lenguajes siguen justificando su uso —y por qué las pilas de software modernas continúan construyéndose sobre ellos.
Qué hace que C y C++ encajen en el software de sistemas
C y C++ se usan ampliamente en software de sistemas porque permiten programas “cerca del metal”: pequeños, rápidos e integrados estrechamente con el SO y el hardware.
Compilan a código nativo (en palabras sencillas)
Cuando el código C/C++ se compila, se convierte en instrucciones de máquina que la CPU puede ejecutar directamente. No hay un runtime obligatorio que traduzca instrucciones mientras el programa se ejecuta.
Eso importa para componentes de infraestructura —núcleos, motores de bases de datos, motores de juego— donde incluso pequeñas sobrecargas pueden acumularse bajo carga.
Rendimiento predecible para la infraestructura central
El software de sistemas suele necesitar tiempos consistentes, no solo buena velocidad media. Por ejemplo:
- Un planificador del sistema operativo debe responder rápidamente bajo carga.
- Una base de datos debe mantener la latencia estable mientras muchos usuarios realizan consultas a la vez.
- Un motor de juego debe cumplir un presupuesto de fotogramas (por ejemplo, ~16 ms para 60 FPS).
C/C++ ofrecen control sobre el uso de CPU, la disposición de la memoria y las estructuras de datos, lo que ayuda a los ingenieros a orientar el rendimiento predecible.
Acceso directo a memoria y punteros
Los punteros permiten trabajar con direcciones de memoria directamente. Ese poder puede sonar intimidante, pero desbloquea capacidades que muchos lenguajes de alto nivel abstraen:
- Allocadores personalizados afinados para cargas de trabajo específicas
- Formatos compactos en memoria (útiles en bases de datos y caches)
- Patrones de E/S sin copias donde los datos no se duplican repetidamente
Usado con cuidado, este nivel de control puede ofrecer ganancias de eficiencia dramáticas.
Compromisos: seguridad, complejidad y tiempo de desarrollo
La misma libertad también es el riesgo. Los compromisos habituales incluyen:
- Seguridad: los errores pueden causar fallos, corrupción de datos o vulnerabilidades.
- Complejidad: la gestión manual de memoria y el comportamiento indefinido requieren disciplina.
- Tiempo de desarrollo: las pruebas, revisiones y herramientas se vuelven innegociables para la fiabilidad.
Un enfoque común es mantener el núcleo crítico para el rendimiento en C/C++, y rodearlo con lenguajes más seguros para las funcionalidades de producto y la experiencia de usuario.
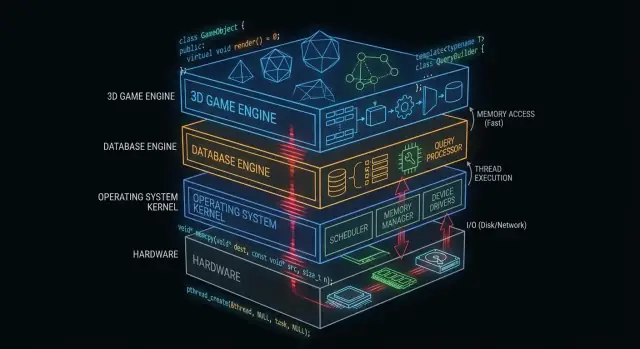
C/C++ en núcleos de sistemas operativos
El núcleo del sistema operativo está lo más cerca posible del hardware. Cuando tu portátil despierta, tu navegador se abre o un programa solicita más memoria, el núcleo coordina esas peticiones y decide qué sucede.
Qué hace realmente un núcleo
A nivel práctico, los núcleos gestionan unas cuantas tareas centrales:
- Planificación: decidir qué programa (y qué hilo) obtiene tiempo de CPU y durante cuánto.
- Gestión de memoria: repartir memoria a procesos, mantenerlas aisladas y recuperar memoria de forma segura.
- Gestión de dispositivos: comunicarse con hardware mediante controladores (disco, red, teclado, GPU, etc.).
- Límites de seguridad: aplicar permisos para que un programa no pueda leer o corromper los datos de otro.
Por estar en el centro del sistema, el código del núcleo es a la vez sensible al rendimiento y crítico en corrección.
Por qué el control estricto favorece a C (y a veces C++)
Los desarrolladores de núcleos necesitan control preciso sobre:
- Disposición de memoria: estructuras de tamaño fijo, alineación y comportamiento predecible en la asignación.
- Instrucciones de CPU y convenciones de llamada: interactuar con interrupciones, cambios de contexto y sincronización de bajo nivel.
- Registros de hardware: leer/escribir direcciones específicas y manejar modos especiales de la CPU.
C sigue siendo un “lenguaje de núcleo” común porque mapea de forma clara a conceptos de máquina manteniendo legibilidad y portabilidad entre arquitecturas. Muchos núcleos también dependen de ensamblador para las partes más pequeñas y específicas del hardware, dejando a C la mayor parte del trabajo.
C++ puede aparecer en núcleos, pero normalmente en un estilo restringido (características de runtime limitadas, políticas estrictas sobre excepciones y reglas estrictas sobre asignación). Donde se usa, suele ser para mejorar la abstracción sin perder el control.
Código adyacente al núcleo a menudo escrito en C/C++
Incluso cuando el núcleo es conservador, muchos componentes cercanos son C/C++:
- Controladores de dispositivos (especialmente los críticos en rendimiento)
- Bibliotecas estándar y runtimes (partes de libc, hilos de bajo nivel)
- Bootloaders y código de arranque temprano
- Servicios del sistema que necesitan velocidad nativa (por ejemplo, ayudantes de red o almacenamiento)
Para más sobre cómo los controladores conectan software y hardware, ver /blog/device-drivers-and-hardware-access.
Controladores de dispositivos y acceso al hardware
Los controladores traducen entre un sistema operativo y el hardware físico —tarjetas de red, GPUs, controladores SSD, dispositivos de audio y más. Cuando haces clic en “reproducir”, copias un archivo o te conectas a Wi‑Fi, un controlador suele ser el primer código que debe responder.
Como los controladores están en el camino caliente de la E/S, son extremadamente sensibles al rendimiento. Unos cuantos microsegundos extra por paquete o por petición de disco pueden sumar rápidamente en sistemas muy activos. C y C++ siguen siendo comunes aquí porque pueden llamar directamente a las APIs del núcleo, controlar la disposición de la memoria con precisión y ejecutarse con sobrecarga mínima.
Interrupciones, DMA y por qué importan las APIs de bajo nivel
El hardware no espera educadamente su turno. Los dispositivos señalan a la CPU mediante interrupciones —notificaciones urgentes de que algo pasó (llegó un paquete, terminó una transferencia). El código del controlador debe manejar estos eventos rápida y correctamente, a menudo bajo restricciones estrictas de tiempo y concurrencia.
Para alto rendimiento, los controladores también dependen de DMA (Direct Memory Access), donde los dispositivos leen/escriben la memoria del sistema sin que la CPU copie cada byte. Configurar DMA suele implicar:
- Preparar buffers en el formato y alineación correctos
- Proporcionar al dispositivo direcciones físicas o descriptores mapeados
- Sincronizar la propiedad de la memoria entre dispositivo y CPU
Estas tareas requieren interfaces de bajo nivel: registros mapeados en memoria, flags de bits y un orden cuidadoso de lecturas/escrituras. C/C++ hacen práctico expresar esta lógica “cerca del metal” manteniendo portabilidad entre compiladores y plataformas.
La estabilidad no es negociable
A diferencia de una app normal, un bug en un controlador puede bloquear todo el sistema, corromper datos o abrir agujeros de seguridad. Ese riesgo modela cómo se escribe y revisa el código de controladores.
Los equipos reducen el peligro usando estándares de codificación estrictos, comprobaciones defensivas y revisiones en capas. Prácticas comunes incluyen limitar el uso inseguro de punteros, validar entradas del hardware/firmware y ejecutar análisis estático en CI.
Gestión de memoria: poder y trampas
Experimenta sin miedo
Usa instantáneas y retrocesos para probar cambios de forma segura mientras iteras rápidamente.
La gestión de memoria es una de las mayores razones por las que C y C++ siguen dominando partes de sistemas operativos, bases de datos y motores de juego. También es uno de los lugares más fáciles para crear bugs sutiles.
Qué significa “gestión de memoria”
A nivel práctico, la gestión de memoria incluye:
- Asignar memoria (obtener un bloque para almacenar datos)
- Liberarla (devolverla cuando ya no se necesita)
- Manejar la fragmentación (huecos que dificultan o ralentizan futuras asignaciones)
En C, esto suele ser explícito (malloc/free). En C++, puede ser explícito (new/delete) o envuelto en patrones más seguros.
Por qué el control manual puede ser una ventaja
En componentes críticos para el rendimiento, el control manual puede ser una característica:
- Puedes evitar pausas impredecibles de recolección de basura.
- Puedes elegir dónde y cómo se asigna la memoria (por ejemplo, allocators por pool o arena), mejorando la consistencia.
- Puedes adaptar patrones de asignación a cargas reales (muchos objetos pequeños frente a grandes buffers contiguos).
Esto importa cuando una base de datos debe mantener latencia constante o un motor de juego debe cumplir un presupuesto de tiempo por frame.
Modos comunes de fallo (y por qué son graves)
La misma libertad crea problemas clásicos:
- Fugas de memoria: olvidar liberar memoria, haciendo que el uso crezca hasta degradar el rendimiento o provocar un crash.
- Desbordamientos de buffer: escribir más allá del fin de un array, corrompiendo datos o permitiendo exploits.
- Uso después de liberar: usar un puntero tras liberarlo, provocando fallos difíciles de reproducir.
Estos bugs pueden ser sutiles porque el programa puede “parecer estar bien” hasta que una carga específica desencadena el fallo.
Cómo ayudan las prácticas modernas
El C++ moderno reduce el riesgo sin renunciar al control:
- RAII (Resource Acquisition Is Initialization) liga la vida de recursos al alcance, de modo que la limpieza ocurre automáticamente.
- Smart pointers (como
std::unique_ptrystd::shared_ptr) hacen explícita la propiedad y evitan muchas fugas. - Sanitizers (AddressSanitizer, UndefinedBehaviorSanitizer) y análisis estático detectan problemas temprano, a menudo en CI.
Usadas bien, estas herramientas mantienen C/C++ rápidos mientras hacen menos probable que los bugs de memoria lleguen a producción.
Concurrencia y rendimiento en multi-núcleo
Las CPUs modernas no están ganando mucho en velocidad por núcleo: están ganando más núcleos. Eso desplaza la pregunta de rendimiento de “¿qué tan rápido es mi código?” a “¿qué tan bien puede ejecutarse mi código en paralelo sin interferencias?” C y C++ son populares aquí porque permiten control de bajo nivel sobre hilos, sincronización y comportamiento de memoria con muy poca sobrecarga.
Hilos, núcleos y planificación
Un hilo es la unidad que usa tu programa para hacer trabajo; un núcleo de CPU es donde ese trabajo se ejecuta. El planificador del sistema operativo asigna hilos ejecutables a núcleos disponibles, tomando decisiones continuamente.
Los detalles de planificación importan en código crítico: pausar un hilo en el momento equivocado puede bloquear una tubería, crear colas o producir comportamiento intermitente. Para trabajo intensivo en CPU, mantener hilos activos aproximadamente alineados con el número de núcleos suele reducir el thrashing.
Conceptos básicos de bloqueo: mutexes, atomics y contención
- Mutexes son fáciles de razonar, pero el acceso compartido intenso crea contención —tiempo esperando en lugar de trabajando.
- Atomics pueden ser más rápidos para actualizaciones pequeñas de estado compartido, pero requieren diseño cuidadoso para evitar bugs sutiles de corrección.
La meta práctica no es “nunca bloquear”. Es: bloquear menos, y bloquear con inteligencia —mantener secciones críticas pequeñas, evitar locks globales y reducir el estado mutable compartido.
Por qué importan los picos de latencia
Las bases de datos y los motores de juego no solo se preocupan por la velocidad media: se preocupan por las pausas en el peor caso. Un convoy de locks, una falta de página o un trabajador parado puede causar tartamudeo visible o una consulta lenta que viola un SLA.
Patrones comunes en C/C++
Muchos sistemas de alto rendimiento se apoyan en:
- Pools de hilos para reutilizar trabajadores y mantener la planificación predecible.
- Colas de work-stealing para balancear carga entre núcleos.
- Colas lock-free (en rutas calientes seleccionadas) para reducir bloqueos —usadas con cuidado porque la corrección es más difícil de probar.
Estos patrones buscan rendimiento sostenido y latencia consistente bajo presión.
Motores de bases de datos: dónde C/C++ entregan velocidad
Un motor de base de datos no es solo “almacenar filas”. Es un bucle ajustado de trabajo de CPU y E/S que se ejecuta millones de veces por segundo, donde pequeñas ineficiencias suman rápido. Por eso muchos motores y componentes centrales siguen escritos mayoritariamente en C o C++.
El trabajo principal del motor: parsear, planear, ejecutar
Cuando envías SQL, el motor:
- Lo parsea (convierte texto en una representación estructurada)
- Lo planifica (elige una forma eficiente de responder la consulta)
- Lo ejecuta (escaneos, búsquedas en índices, joins, ordenaciones, agregaciones y devuelve filas)
Cada etapa se beneficia del control cuidadoso de memoria y tiempo de CPU. C/C++ permiten analizadores rápidos, menos asignaciones durante la planificación y una ruta caliente de ejecución ligera —a menudo con estructuras de datos personalizadas diseñadas para la carga de trabajo.
Motores de almacenamiento: páginas, índices, buffering
Bajo la capa SQL, el motor de almacenamiento gestiona los detalles menos glamorosos pero esenciales:
- Páginas: los datos se leen y escriben en bloques de tamaño fijo, no fila por fila.
- Índices: B-trees, LSM-trees y estructuras relacionadas deben actualizarse eficientemente.
- Buffering: un pool de buffers decide qué permanece en memoria, qué se expulsa y cómo agrupar lecturas/escrituras.
C/C++ encajan bien aquí porque estos componentes dependen de una disposición de memoria predecible y control directo sobre los límites de E/S.
Estructuras de datos amigables con la caché (por qué importa)
El rendimiento moderno a menudo depende más de las cachés de CPU que de la velocidad bruta del CPU. Con C/C++, los desarrolladores pueden agrupar campos usados con frecuencia, almacenar columnas en arrays contiguos y minimizar el “pointer chasing” —patrones que mantienen los datos cerca de la CPU y reducen stalls.
Dónde aparecen lenguajes de mayor nivel
Incluso en bases de datos dominadas por C/C++, los lenguajes de alto nivel suelen impulsar herramientas de administración, backups, monitorización, migraciones y orquestación. El núcleo crítico por rendimiento se mantiene nativo; el ecosistema circundante prioriza la velocidad de iteración y la usabilidad.
Almacenamiento, caché y E/S en bases de datos
Planifica la arquitectura
Usa el Modo de Planificación para mapear componentes, límites y compensaciones antes de generar código.
Las bases de datos parecen instantáneas porque trabajan mucho para evitar el disco. Incluso en SSDs rápidos, leer del almacenamiento es órdenes de magnitud más lento que leer de RAM. Un motor de base de datos escrito en C o C++ puede controlar cada paso de esa espera —y a menudo evitarla.
Pool de buffers y caché de páginas en términos cotidianos
Piensa en los datos en disco como cajas en un almacén. Recuperar una caja (lectura de disco) lleva tiempo, así que mantienes los objetos más usados sobre una mesa (RAM).
- Pool de buffers: el “escritorio” de la base de datos, que guarda páginas usadas recientemente (fragmentos de tablas e índices).
- Caché de páginas: el “escritorio” del sistema operativo, que cachea datos de archivos leídos recientemente.
Muchas bases de datos gestionan su propio pool de buffers para predecir qué debe permanecer caliente y evitar competir con el SO por memoria.
Por qué el disco es lento —y cómo lo oculta la caché
El almacenamiento no solo es lento; también es impredecible. Picos de latencia, encolamiento y acceso aleatorio añaden retrasos. La caché lo mitiga mediante:
- Servir lecturas desde RAM la mayor parte del tiempo
- Agrupar escrituras en operaciones de E/S más grandes y menos frecuentes
- Prefetching de páginas probables de necesitarse a continuación (por ejemplo, durante escaneos de índice)
Decisiones de diseño que se benefician del control de bajo nivel
C/C++ permite a los motores de bases de datos tunear detalles que importan a alto rendimiento: lecturas alineadas, E/S directa vs E/S con buffer, políticas de expulsión personalizadas y disposiciones en memoria cuidadosas para índices y buffers de logs. Estas decisiones pueden reducir copias, evitar contención y mantener las cachés de CPU alimentadas con datos útiles.
Compresión y checksums pueden estar ligados a CPU
La caché reduce la E/S, pero aumenta el trabajo de CPU. Descomprimir páginas, calcular checksums, encriptar logs y validar registros pueden convertirse en cuellos de botella. Como C y C++ ofrecen control sobre patrones de acceso a memoria y bucles SIMD-friendly, se usan a menudo para exprimir más trabajo por núcleo.
Motores de juego: restricciones en tiempo real
Los motores de juego operan bajo expectativas estrictas de tiempo real: el jugador mueve la cámara, pulsa un botón y el mundo debe responder de inmediato. Esto se mide en tiempo por frame, no en rendimiento medio.
Presupuestos por frame: por qué importan los milisegundos
A 60 FPS tienes alrededor de 16,7 ms para producir un frame: simulación, animación, física, mezcla de audio, culling, envío de renderizado y, a menudo, transmisión de activos. A 120 FPS, ese presupuesto baja a 8,3 ms. No cumplirlo se percibe como tartamudeo, latencia en la entrada o ritmo inconsistente.
Por eso la programación en C y la programación en C++ siguen siendo comunes en los núcleos de motores: rendimiento predecible, sobrecarga baja y control fino sobre memoria y CPU.
Subsistemas centrales frecuentemente escritos en C/C++
La mayoría de motores usan código nativo para lo pesado:
- Renderizado (recorrido de escena, construcción de draw-calls, gestión de recursos GPU)
- Física (detección de colisiones, restricciones, cuerpos rígidos)
- Animación (mezcla esquelética, IK, evaluación de poses)
- Audio (mezcla en tiempo real, espacialización)
Estos sistemas se ejecutan cada frame, así que pequeñas ineficiencias se multiplican rápido.
Bucles ajustados y disposición de datos
Gran parte del rendimiento en juegos se reduce a bucles ajustados: iterar entidades, actualizar transformaciones, probar colisiones, skinning de vértices. C/C++ facilitan estructurar la memoria para eficiencia de caché (arrays contiguos, menos asignaciones, menos indireccionamientos virtuales). La disposición de datos puede importar tanto como la elección algorítmica.
Dónde encaja el scripting (y dónde no)
Muchos estudios usan lenguajes de scripting para la lógica de juego —misiones, reglas de UI, triggers— porque la velocidad de iteración importa. El núcleo del motor normalmente permanece nativo, y los scripts llaman a sistemas en C/C++ mediante bindings. Un patrón común: los scripts orquestan; C/C++ ejecuta las partes costosas.
Compiladores, toolchains e interoperabilidad
Lanza la primera versión rápido
Convierte tu idea en una app web funcional sin montar toda la cadena de herramientas.
C y C++ no solo “se ejecutan”: se integran en binarios nativos que coinciden con una CPU y un sistema operativo específicos. Esa canalización de compilación es una razón importante por la que estos lenguajes siguen siendo centrales en núcleos, bases de datos y motores de juego.
Qué sucede realmente durante una compilación
Una compilación típica tiene varias etapas:
- Compilador: convierte el código fuente C/C++ en archivos objeto específicos de la máquina.
- Linker: enlaza objetos con bibliotecas para producir un ejecutable o una biblioteca compartida.
- Salida binaria: el artefacto final que el SO puede cargar directamente (a menudo con símbolos de depuración separados).
La etapa de enlace es donde surgen muchos problemas reales: símbolos faltantes, versiones de biblioteca incompatibles o ajustes de compilación dispares.
Por qué importan los toolchains y el soporte de plataforma
Un toolchain es el conjunto completo: compilador, linker, biblioteca estándar y herramientas de build. Para software de sistemas, la cobertura de plataformas suele ser decisiva:
- SDKs de consolas y móviles pueden requerir compiladores y linkers específicos.
- Bases de datos y software backend necesitan builds estables en distribuciones Linux y tipos de CPU diversos.
- Trabajo en SO y controladores puede requerir cross-compilers, flags estrictos y disciplina ABI.
Los equipos a menudo eligen C/C++ en parte porque los toolchains son maduros y están disponibles en muchos entornos —desde dispositivos embebidos hasta servidores.
Interfaz con otros lenguajes (FFI)
C se trata comúnmente como el “adaptador universal”. Muchos lenguajes pueden llamar funciones C mediante FFI, así que los equipos suelen poner la lógica crítica en rendimiento en una librería C/C++ y exponer una API pequeña al código de mayor nivel. Por eso Python, Rust, Java y otros frecuentemente envuelven componentes C/C++ existentes en lugar de reescribirlos.
Depuración y profiling: qué miden los equipos
Los equipos C/C++ suelen medir:
- Tiempo de CPU (funciones calientes, pilas de llamadas)
- Uso de memoria (asignaciones, fugas, fragmentación)
- Latencia (tiempo por frame en juegos, tiempo de consulta en bases de datos)
- Comportamiento de E/S (fallos de caché, lecturas de disco, syscalls)
El flujo de trabajo es consistente: encontrar el cuello de botella, confirmarlo con datos y optimizar la pieza más pequeña que importa.
Elegir C/C++ hoy: guía práctica de decisión
C y C++ siguen siendo excelentes herramientas —cuando construyes software donde unos pocos milisegundos, unos pocos bytes o una instrucción CPU específica importan de verdad. No son la mejor opción por defecto para cada característica o equipo.
Cuándo C/C++ es la elección correcta
Elige C/C++ cuando el componente sea crítico para el rendimiento, necesite control estricto de la memoria o deba integrarse estrechamente con el SO o el hardware.
Encajan típicamente en:
- Rutas calientes donde la latencia es visible (parseo, compresión, renderizado, ejecución de consultas)
- Módulos de bajo nivel que deben ser predecibles (allocators, planificadores, primitivas de red)
- Librerías multiplataforma donde el código nativo es el producto (SDKs, engines, embebidos)
- Situaciones donde la portabilidad entre compiladores/toolchains es un requisito duro
Cuándo preferir otros lenguajes
Elige un lenguaje de más alto nivel cuando la prioridad sea seguridad, velocidad de iteración o mantenibilidad a escala.
Suele ser más sensato usar Rust, Go, Java, C#, Python o TypeScript cuando:
- El equipo es grande y se espera rotación (menos “pistolas de mano” importa)
- La funcionalidad cambia frecuentemente y la corrección pesa más que exprimir ciclos
- Necesitas garantías fuertes de seguridad de memoria
- La productividad del desarrollador y el pool de contratación son restricciones mayores que la velocidad bruta
En la práctica, la mayoría de productos son mixtos: librerías nativas para la ruta crítica y servicios/UI de alto nivel para el resto.
Nota práctica para equipos de aplicaciones (donde encaja Koder.ai)
Si construyes principalmente funciones web, backend o móviles, a menudo no necesitas escribir C/C++ para beneficiarte de él: lo consumes a través del SO, la base de datos, el runtime y las dependencias. Plataformas como Koder.ai aprovechan esa división: puedes producir rápidamente apps React, backends Go + PostgreSQL o apps Flutter mediante un flujo guiado por chat, integrando componentes nativos cuando se necesita (por ejemplo, llamando a una librería C/C++ existente mediante un FFI). Así mantienes la mayor parte del producto en código de rápida iteración, sin ignorar dónde el código nativo es la herramienta adecuada.
Lista de comprobación práctica (componente por componente)
Haz estas preguntas antes de comprometerte:
- ¿Está esto en la ruta crítica? Mide primero; no supongas.
- ¿Cuáles son los modos de fallo? La corrupción de memoria en C/C++ puede ser catastrófica.
- ¿Cuál es el límite de interfaz? ¿Puedes aislar el código nativo detrás de una API pequeña?
- ¿Tienes la experiencia? Revisión, pruebas y habilidades de profiling son innegociables.
- ¿Cuál es el objetivo de despliegue? Consolas, embebidos, núcleos y controladores suelen favorecer C/C++.
- ¿Cómo lo probarás y perfilarás? Planea herramientas y CI desde el día uno.
Lecturas sugeridas
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing