Por qué los frameworks backend importan más allá de “elegir una stack”
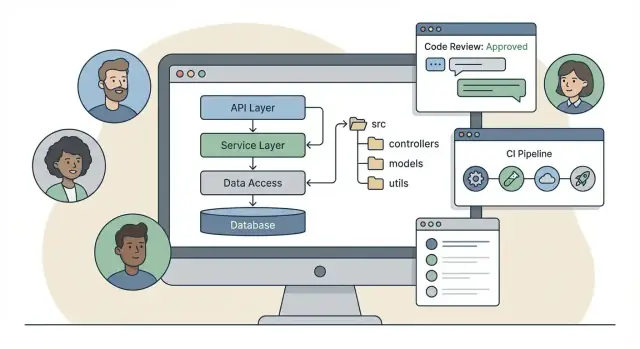
Un framework backend es más que un conjunto de librerías. Las librerías te ayudan a hacer tareas concretas (routing, validación, ORM, logging). Un framework añade una forma opinionada de trabajar: una estructura de proyecto por defecto, patrones comunes, herramientas integradas y reglas sobre cómo se conectan las piezas.
Los frameworks moldean decisiones cotidianas
Una vez que hay un framework en marcha, guía cientos de pequeñas decisiones:
- Dónde debe vivir el código nuevo (features, módulos, servicios)
- Cómo se mueven las peticiones por la app (controladores, middleware, handlers)
- Cómo manejas preocupaciones transversales como auth, validación y errores
- Cómo los equipos nombran cosas, escriben tests y revisan pull requests
Por eso dos equipos que construyen “la misma API” pueden acabar con bases de código muy diferentes —incluso si usan el mismo lenguaje y base de datos. Las convenciones del framework se convierten en la respuesta por defecto a “¿cómo lo hacemos aquí?”
Velocidad y consistencia vs. flexibilidad
Los frameworks suelen intercambiar flexibilidad por una estructura predecible. La ventaja es incorporación más rápida, menos debates y patrones reutilizables que reducen la complejidad accidental. La desventaja es que las convenciones del framework pueden sentirse restrictivas cuando tu producto necesita flujos inusuales, ajustes de rendimiento o arquitecturas no estándar.
Una buena decisión no es “usar framework o no”, sino cuánta convención quieres —y si tu equipo está dispuesto a pagar el coste de la personalización con el tiempo.
Quién debería preocuparse
- Ingenieros: menos tiempo reinventando patrones, más tiempo entregando features
- Tech leads: estándares más claros para arquitectura, pruebas y revisiones
- Equipos de producto: entregas más previsibles y menos regresiones de calidad a medida que crece la base de código
Los defaults del framework que definen la estructura del proyecto
La mayoría de equipos no empiezan con una carpeta vacía —empiezan con el layout “recomendado” del framework. Esos defaults deciden dónde se pone el código, cómo se nombran las cosas y qué se siente “normal” en las revisiones.
Las dos mentalidades por defecto más comunes
Algunos frameworks empujan una estructura por capas clásica: controllers / services / models. Es fácil de aprender y mapea de forma clara al manejo de peticiones:
/src
/controllers
/services
/models
/repositories
Otros frameworks se inclinan por módulos por funcionalidad: agrupar todo lo de una feature junto (handlers HTTP, reglas de dominio, persistencia). Eso fomenta el razonamiento local —cuando trabajas en “Billing”, abres una sola carpeta:
/src
/modules
/billing
/http
/domain
/data
Ninguna es automáticamente mejor, pero cada una moldea hábitos. Las estructuras en capas pueden facilitar la centralización de estándares transversales (logging, validación, manejo de errores). Las estructuras por módulos pueden reducir el “scroll horizontal” a través del código conforme crece.
Las herramientas de scaffolding crean patrones duraderos
Los generadores CLI (scaffolding) son pegajosos. Si el generador crea un par controller + service para cada endpoint, la gente seguirá haciéndolo —incluso cuando una función más simple bastaría. Si genera un módulo con límites claros, los equipos tenderán a respetar esos límites bajo presión de tiempo.
Esta misma dinámica aparece en flujos de trabajo “vibe-coding”: si los defaults de tu plataforma producen un layout predecible y costuras de módulo claras, los equipos tienden a mantener la coherencia a medida que crece la base de código. Por ejemplo, Koder.ai genera apps full-stack desde prompts de chat, y el beneficio práctico (más allá de la velocidad) es que tu equipo puede estandarizar estructuras y patrones consistentes temprano —luego iterar sobre ellos como cualquier otro código (incluyendo exportar el código fuente cuando quieres control total).
Evitar “controladores gordos”
Los frameworks que ponen a los controladores en el centro pueden tentar a los equipos a meter reglas de negocio en los handlers de petición. Una regla práctica: los controladores traducen HTTP → llamada a la aplicación, y nada más. Pon la lógica de negocio en una capa de servicio/use-case (o en la capa de dominio del módulo), para que pueda testearse sin HTTP y reutilizarse en jobs o tareas CLI.
Un chequeo rápido para tu estructura
Si no puedes responder “¿Dónde vive la lógica de pricing?” en una frase, los defaults de tu framework podrían estar peleando con tu dominio. Ajusta pronto —las carpetas son fáciles de cambiar; los hábitos no.
Flujo de peticiones: convenciones de routing, controladores y middleware
Un framework backend no es solo un conjunto de librerías —define cómo debe viajar una petición por tu código. Cuando todos siguen el mismo camino de petición, las features se entregan más rápido y las revisiones dejan de ser sobre estilo y pasan a ser sobre corrección.
Routing: el mapa público de tu sistema
Las rutas deberían leerse como la tabla de contenidos de tu API. Los buenos frameworks incentivan rutas que son:
- Declarativas (puedes escanear y entender qué está expuesto)
- Consistentes (mismos patrones de URL y verbos HTTP en todo el código)
- Cerca del borde (la configuración de rutas no debería contener reglas de negocio)
Una convención práctica es mantener los archivos de rutas centrados en el mapeo: GET /orders/:id -> OrdersController.getById, no “si el usuario es VIP, haz X.”
Controladores/handlers: traductores delgados de peticiones
Los controladores funcionan mejor como traductores entre HTTP y tu lógica central:
- Leer inputs (params, headers, body)
- Llamar a un servicio/use-case
- Devolver una respuesta
Cuando los frameworks proporcionan helpers para parseo, validación y formateo de respuesta, los equipos se sienten tentados a acumular lógica en los controladores. El patrón más sano es “controladores delgados, servicios gruesos”: deja preocupaciones de request/response en los controladores y decisiones de negocio en una capa separada que no conozca HTTP.
Middleware/filters: un lugar para preocupaciones transversales
El middleware (o filtros/interceptores) define dónde poner comportamientos repetidos como autenticación, logging, rate limiting y request IDs. La convención clave: el middleware debe enriquecer o proteger la petición, no implementar reglas de producto.
Por ejemplo, el middleware de auth puede adjuntar req.user, y los controladores pueden pasar esa identidad a la lógica core. El middleware de logging puede estandarizar qué se registra sin que cada controlador lo reimplemente.
Convenciones de nombres que reducen fricción en las revisiones
Acordad nombres previsibles:
OrdersController, OrdersService, CreateOrder (use-case)authMiddleware, requestIdMiddlewarevalidateCreateOrder (schema/validator)
Cuando los nombres codifican intención, las revisiones se centran en el comportamiento, no en dónde “debería ir” algo.
Capas y límites: dónde vive la lógica de negocio
Un framework backend no solo te ayuda a publicar endpoints —empuja a tu equipo hacia una determinada “forma” de código. Si no defines límites pronto, la gravedad por defecto suele ser: controladores llaman al ORM, el ORM llama a la BD, y las reglas de negocio se esparcen por todas partes.
Una arquitectura por capas práctica
Una separación simple y durable se ve así:
- Capa de presentación: preocupaciones HTTP (routing, controladores, middleware de auth). Convierte requests en comandos de la app y devuelve respuestas.
- Capa de aplicación: use-cases (por ejemplo,
CreateInvoice, CancelSubscription). Orquesta el trabajo y las transacciones, pero se mantiene poco dependiente del framework.
- Capa de dominio: reglas y conceptos de negocio (entidades, políticas, domain services). Debe leerse como el negocio, no como SQL.
- Capa de datos: repositorios, modelos/mappers del ORM, queries, migraciones.
Los frameworks que generan “controller + service + repository” pueden ser útiles —si los tratas como un flujo direccional, no como la obligación de que cada feature necesite cada capa.
Cómo ORMs y repositorios influyen en los límites
Un ORM tienta a pasar modelos de base de datos por todas partes porque son convenientes y ya vienen “medianamente validados”. Los repositorios ayudan ofreciendo una interfaz más estrecha (“get customer by id”, “save invoice”), para que tu aplicación y dominio no dependan de detalles del ORM.
Para evitar diseños donde “todo depende de la base de datos”:
- No devuelvas entidades ORM directamente desde controladores.
- Mantén las formas de las queries en la capa de datos; deja las reglas en el dominio.
- Prefiere entradas/salidas amigables al dominio para los use-cases.
Cuándo introducir una capa de servicios (y cuándo no)
Añade una capa de servicio/aplicación cuando la lógica se reuse entre endpoints, requiera transacciones o deba imponer reglas consistentemente. Evítala para CRUD simples que realmente no tienen comportamiento de negocio —añadir una capa allí puede crear ceremonia sin claridad.
Inyección de dependencias y hábitos de diseño modular
La Inyección de Dependencias (DI) es uno de esos defaults de framework que entrena a todo tu equipo. Cuando está integrada, dejas de “newear” servicios en cualquier lugar y empiezas a tratar dependencias como algo que se declara, registra y reemplaza a propósito.
Lo que DI fomenta (y lo que puede complicar)
DI empuja a los equipos hacia componentes pequeños y enfocados: un controlador depende de un servicio, un servicio depende de un repositorio, y cada parte tiene un rol claro. Eso suele mejorar la testabilidad y facilita reemplazar implementaciones (por ejemplo, pasas de un gateway de pagos real a un mock).
La desventaja es que la DI puede ocultar complejidad. Si cada clase depende de cinco otras, se vuelve más difícil entender qué se ejecuta en una petición. Contenedores mal configurados también provocan errores que parecen lejanos al código que editabas.
Inyección por constructor y diseño orientado a interfaces
La mayoría de frameworks fomentan la inyección por constructor porque hace explícitas las dependencias y evita patrones de “service locator”.
Un hábito útil es emparejar la inyección por constructor con diseño orientado a interfaces: el código depende de un contrato estable (como EmailSender) en lugar de un cliente de un proveedor concreto. Eso mantiene los cambios localizados cuando cambias proveedores o refactorizas.
Módulos cohesivos sin dependencias circulares
DI funciona mejor cuando tus módulos son cohesivos: un módulo posee una porción de funcionalidad (orders, billing, auth) y expone una superficie pública pequeña.
Las dependencias circulares son un modo común de fallo. Suelen indicar que los límites no están claros —dos módulos comparten conceptos que merecen su propio módulo, o un módulo hace demasiado.
Acordar dónde ocurre el wiring
Los equipos deberían acordar dónde se registran las dependencias: una raíz de composición única (startup/bootstrap), más wiring a nivel de módulo para internas del módulo.
Mantener el wiring centralizado facilita las revisiones: los reviewers pueden ver nuevas dependencias, confirmar que están justificadas y prevenir el “container sprawl” que convierte la DI en un misterio.
De código a producción
Lanza tu backend rápidamente con despliegue y hosting integrados cuando estés listo.
Un framework backend influye en lo que tu equipo considera “una buena API”. Si la validación es una característica de primera clase (decoradores, esquemas, pipes, guards), la gente diseña endpoints alrededor de inputs y outputs claros —porque es más fácil hacer lo correcto que saltárselo.
Cuando la validación vive en el límite (antes de la lógica de negocio), los equipos empiezan a tratar los payloads como contratos, no como “lo que sea que mande el cliente”. Eso suele llevar a:
- Campos explícitos requeridos vs opcionales (y menos debates de “null significa desconocido”)
- Reglas claras de formato (fechas, IDs, enums) y restricciones (min/max, longitud)
- Rechazo temprano de requests inválidos, manteniendo el código de servicio enfocado en negocio
Aquí es también donde los frameworks promueven convenciones compartidas: dónde se define la validación, cómo se exponen los errores y si se permiten campos desconocidos.
Errores centralizados crean expectativas consistentes para clientes
Los frameworks que soportan filtros/manejadores de excepciones globales hacen posible la consistencia. En lugar de que cada controlador invente sus respuestas, puedes estandarizar:
- Envelope de error (por ejemplo,
code, message, details, traceId)
- Mapeo de status HTTP (validación → 400, auth → 401/403, not found → 404)
- Logging y correlation IDs para que soporte pueda depurar una única petición fallida
Una forma de error consistente reduce la lógica condicional en el frontend y hace que la documentación de la API sea más fiable.
DTOs y view models protegen tus internos
Muchos frameworks te empujan hacia DTOs (input) y modelos de vista (output). Esa separación es saludable: evita la exposición accidental de campos internos, evita acoplar clientes a esquemas de BD y hace los refactors más seguros. Una regla práctica: los controladores hablan en DTOs; los servicios hablan en modelos de dominio.
Versionado y compatibilidad hacia atrás básica
Incluso APIs pequeñas evolucionan. Las convenciones de routing del framework a menudo determinan si el versionado es por URL (/v1/...) o por headers. Sea cual sea la opción, establece lo básico pronto: nunca elimines campos sin un periodo de deprecación, añade campos de forma compatible hacia atrás y documenta cambios en un lugar (por ejemplo, /docs o /changelog).
Estrategia de pruebas influenciada por las herramientas del framework
Un framework backend no solo te ayuda a entregar features; dicta cómo las pruebas son más fáciles de escribir. El runner de tests integrado, utilidades de bootstrapping y el contenedor DI suelen determinar qué es lo sencillo —y eso se vuelve lo que tu equipo realmente hace.
Helpers del framework: unit vs integración vs end-to-end
Muchos frameworks proporcionan un "test app" que puede levantar el contenedor, registrar rutas y ejecutar requests en memoria. Eso empuja a los equipos hacia tests de integración pronto —porque sólo son unas líneas más que un unit test.
Una división práctica:
- Unit tests para lógica de negocio pura (sin boot del framework, sin BD).
- Integration tests para módulos/servicios cableados a través del contenedor del framework.
- End-to-end tests para comportamiento real HTTP (routing, middleware, auth, mapping de errores).
Una pirámide de tests adecuada para servicios backend
Para la mayoría de servicios, la velocidad importa más que la pureza perfecta de la “pirámide”. Una buena regla: muchos tests unitarios pequeños, un conjunto focalizado de tests de integración alrededor de los límites (BD, colas), y una capa E2E delgada que pruebe el contrato.
Si tu framework hace barata la simulación de requests, puedes inclinarte un poco más hacia tests de integración —siempre aislando la lógica de dominio para que los unit tests sigan siendo estables.
Mocking que encaje con DI y tiempo de ejecución
La estrategia de mocks debe seguir cómo el framework resuelve dependencias:
- Prefiere sobrescribir bindings DI (intercambiar un cliente de email real por un fake) en lugar de monkey-patching de imports.
- Usa adaptadores en memoria cuando sea posible (por ejemplo, repositorios en memoria) para evitar mocks frágiles.
- Mockea en el límite de módulo, no dentro de la lógica de negocio, para que los refactors no rompan tests.
Tests rápidos y fiables para CI
El tiempo de arranque del framework puede dominar la CI. Mantén tests ágiles cacheando setups costosos, ejecutando migraciones una vez por suite y usando paralelismo solo donde la aislamiento esté garantizado. Haz que las fallas sean fáciles de diagnosticar: seed consistente, relojes deterministas y hooks de limpieza estrictos superan a “reintentar al fallar”.
Escalar la base de código: módulos, paquetes y código compartido
Planifica tu arquitectura primero
Mapea módulos, límites y flujo de peticiones antes de generar código con el Modo de Planificación de Koder.ai.
Los frameworks no solo te ayudan a lanzar la primera API —moldean cómo crece tu código cuando el “servicio único” se convierte en docenas de features, equipos e integraciones. Los mecanismos de módulos y paquetes que el framework facilita suelen convertirse en tu arquitectura a largo plazo.
Patrones de modularidad que los frameworks fomentan
La mayoría de frameworks te empujan hacia la modularidad por diseño: apps, plugins, blueprints, módulos, feature folders o paquetes. Cuando eso es el default, los equipos tienden a añadir capacidades como “un módulo más” en vez de esparcir nuevos archivos por todo el proyecto.
Una regla práctica: trata cada módulo como un mini-producto con su propia superficie pública (rutas/handlers, interfaces de servicio), internas privadas y tests. Si tu framework soporta auto-discovery (p. ej., module scanning), úsalo con cuidado —las importaciones explícitas suelen hacer las dependencias más fáciles de razonar.
Módulos de dominio core vs módulos de infraestructura
A medida que la base de código crece, mezclar reglas de negocio con adaptadores se vuelve caro. Una división útil es:
- Módulos de dominio core: reglas de negocio, políticas, domain services y modelos de dominio (cosas que deberían sobrevivir a un cambio de base de datos)
- Módulos de infraestructura: clientes de BD, modelos ORM, brokers de mensajes, clientes HTTP, caches, proveedores de auth
Las convenciones del framework influyen en esto: si el framework fomenta “clases service”, coloca domain services en módulos core y deja el wiring específico del framework (controladores, middleware, providers) en los bordes.
Librerías compartidas vs copy-paste: reglas de decisión
Los equipos suelen compartir demasiado pronto. Prefiere copiar código pequeño hasta que sea estable, y extrae cuando:
- dos o más equipos mantienen la misma lógica
- hay que aplicar un hotfix en varios lugares
- puedes definir una API clara y versionarla
Si extraes, publica paquetes internos (o librerías en workspace) con propiedad estricta y disciplina de changelog.
Prepararse para modular monolith → microservices (más adelante)
Un monolito modular suele ser la mejor opción intermedia. Si los módulos tienen límites claros y pocas importaciones cruzadas, puedes después convertir un módulo en servicio con menos fricción. Diseña módulos alrededor de capacidades de negocio, no de capas técnicas. Para una estrategia más profunda, mira /blog/modular-monolith.
Configuración, entornos y preparación operativa
El modelo de configuración del framework moldea cuán consistentes (o caóticos) son tus despliegues. Cuando la config está esparcida entre archivos ad-hoc, variables de entorno aleatorias y “solo esta constante”, los equipos acaban depurando diferencias en lugar de construir features.
Estilo de configuración = consistencia
La mayoría de frameworks te empuja hacia una fuente de la verdad primaria: archivos de config, variables de entorno o config basada en código (módulos/plugins). Sea cual sea la vía, estandarízala pronto:
- Archivos funcionan bien para desarrollo local y defaults claros (p. ej.,
config/default.yml).
- Variables de entorno son geniales para diferencias en tiempo de despliegue y plataformas de contenedores.
- Config en código puede ser poderosa, pero es fácil esconder ajustes importantes tras lógica.
Una convención útil: defaults viven en archivos de config versionados, las variables de entorno sobreescriben por entorno y el código lee desde un único objeto de config tipado. Eso mantiene obvio “dónde cambiar un valor” durante incidentes.
Secrets: trátalos como una categoría separada
Los frameworks a menudo dan helpers para leer env vars, integrar secret stores o validar config en el arranque. Usa esa herramienta para que los secretos sean difíciles de manejar mal:
- Nunca comites secretos en el repo (incluyendo claves “temporales”).
- Mantén secretos fuera de logs y páginas de error.
- Prefiere inyección en tiempo de ejecución (CI/CD, orquestador de contenedores o un secret manager) sobre
.env local dispersos.
El hábito operativo que buscas es simple: los desarrolladores pueden ejecutar localmente con placeholders seguros, mientras que las credenciales reales solo existen en el entorno que las necesita.
Paridad de entornos: dev, staging, production
Los defaults del framework pueden fomentar paridad (mismo proceso de arranque en todas partes) o crear casos especiales (“producción usa un entrypoint distinto”). Apunta al mismo comando de arranque y al mismo esquema de config en todos los entornos, cambiando solo valores.
Staging debe ser tratado como un ensayo: mismas feature flags, mismo path de migraciones, mismos jobs en background —solo menor escala.
Documenta la configuración como si fuera una API
Cuando la configuración no está documentada, el equipo adivina —y las conjeturas causan outages. Mantén una referencia corta y actualizada en el repo (por ejemplo, /docs/configuration) listando:
- cada clave de config y qué controla
- tipo/formato esperado (string, URL, integer)
- valor por defecto y ejemplos seguros
- qué entornos deben definirla
Muchos frameworks pueden validar config en el arranque. Combínalo con documentación y reducirás “funciona en mi máquina” a una excepción rara en vez de un tema recurrente.
Estándares de observabilidad definidos por el framework
Un framework backend establece la base para entender tu sistema en producción. Cuando la observabilidad está integrada (o fuertemente incentivada), los equipos dejan de tratar logs y métricas como “trabajo futuro” y comienzan a diseñarlos como parte de la API.
Logging, tracing y métricas: qué obtienes “gratis”
Muchos frameworks se integran con herramientas comunes para logging estructurado, tracing distribuido y recolección de métricas. Esa integración influye en la organización del código: tiendes a centralizar preocupaciones transversales (middleware de logging, interceptores de tracing, colectores de métricas) en lugar de dispersar print statements por controladores.
Un buen estándar es definir un pequeño conjunto de campos requeridos que cada línea de log relacionada con una petición incluya:
correlation_id (o request_id) para conectar logs entre serviciosroute y method para saber qué endpoint está implicadouser_id o account_id (cuando esté disponible) para investigaciones de soporteduration_ms y status_code para rendimiento y fiabilidad
Las convenciones del framework (como objetos de contexto de petición o pipelines de middleware) facilitan generar y pasar correlation IDs consistentemente, para que los desarrolladores no reinventen el patrón por feature.
Health checks y endpoints de readiness
Los defaults del framework suelen determinar si los health checks son de primera clase o un afterthought. Endpoints estándar como /health (liveness) y /ready (readiness) pasan a ser parte de la definición de “done” del equipo, y empujan a límites más limpios:
- liveness: “¿está corriendo el proceso?”
- readiness: “¿puede servir tráfico?” (p. ej., DB conectada, migraciones aplicadas)
Cuando esos endpoints se estandarizan pronto, los requisitos operativos dejan de filtrarse en código de features aleatorio.
Usar la observabilidad para guiar refactors
Los datos de observabilidad también son herramienta para decidir refactors. Si los traces muestran que un endpoint gasta repetidamente tiempo en la misma dependencia, es una señal clara para extraer un módulo, añadir caching o rediseñar una query. Si los logs revelan formas de error inconsistentes, es un empujón para centralizar el manejo de errores. En otras palabras: los hooks de observabilidad del framework no solo ayudan a depurar —te dan confianza para reorganizar la base de código.
Flujo de trabajo del equipo: convenciones, herramientas y revisiones
Construye y gana créditos
Gana créditos compartiendo lo que construyes en Koder.ai o invitando a otros a probarlo.
Un framework backend no solo organiza código —establece las “reglas de la casa” sobre cómo trabaja el equipo. Cuando todos siguen las mismas convenciones (ubicación de archivos, nombres, cómo se enlazan dependencias), las revisiones son más rápidas y la incorporación es más sencilla.
Generación de código y scaffolds: úsalos, no los adores
Las herramientas de scaffolding pueden estandarizar endpoints, módulos y tests en minutos. La trampa es dejar que los generadores dicten tu modelo de dominio.
Usa scaffolds para crear shells coherentes (rutas/controladores, DTOs, stubs de tests), luego edita inmediatamente la salida para ajustarla a las reglas arquitectónicas. Una buena política: los generadores están permitidos, pero el código final debe leerse como un diseño pensado —no como un volcado de plantilla.
Si usáis un flujo asistido por IA, aplicad la misma disciplina: tratad el código generado como scaffolding. En plataformas como Koder.ai, podéis iterar rápido vía chat mientras aún imponéis convenciones del equipo (límites de módulo, patrones DI, shapes de error) mediante revisiones —porque la velocidad solo ayuda si la estructura sigue siendo predecible.
Guías de estilo alineadas con los índices del framework
Los frameworks suelen implicar una estructura idiomática: dónde vive la validación, cómo se lanzan errores, cómo se nombran servicios. Captura esas expectativas en una guía de estilo breve que incluya:
- Convenciones de nombres que casen con primitivos del framework (p. ej., Controller, Service, Module)
- Límites de carpetas (qué está permitido en un controlador vs. en una capa de dominio/servicio)
- Ejemplos de una implementación de endpoint “buena”
Manténla ligera y accionable; enlázala desde /contributing.
Automatiza estándares. Configura formatters y linters para reflejar convenciones del framework (imports, decoradores/anotaciones, patrones async). Hazlos obligatorios vía pre-commit y CI, para que las revisiones se centren en diseño en lugar de espacio en blanco y nombres.
Plantillas de PR y checklists de revisión ligados a la arquitectura
Un checklist basado en el framework previene la deriva lenta hacia la inconsistencia. Añade una plantilla de PR que pida a los reviewers confirmar cosas como:
- Los nuevos endpoints siguen convenciones de routing/controlador
- Validación y respuestas de error coinciden con el estándar del equipo
- Límites de dependencias respetados (no llamadas directas a BD desde controladores, etc.)
- Tests siguen patrones recomendados por el framework
Con el tiempo, estos pequeños guardrails de workflow son lo que mantienen una base de código mantenible a medida que el equipo crece.
Elegir y evolucionar un framework sin reescrituras dolorosas
Las elecciones de framework tienden a fijar patrones —layout de directorios, estilo de controladores, DI e incluso cómo la gente escribe tests. El objetivo no es elegir el framework perfecto; es elegir uno que encaje con cómo tu equipo entrega software, y mantener la posibilidad de cambiar cuando los requisitos cambien.
Empieza por tus restricciones de entrega, no por checklists de features. Un equipo pequeño suele beneficiarse de convenciones fuertes, herramientas incluidas y onboarding rápido. Equipos grandes suelen necesitar límites de módulo más claros, puntos de extensión estables y patrones que dificulten el coupling oculto.
Haz preguntas prácticas:
- ¿Puedes hacer cumplir estructura consistente con mínima vigilancia en las revisiones?
- ¿El framework facilita lo correcto (validación, manejo de errores, logging), o cada equipo inventa su propia solución?
- ¿Las actualizaciones son predecibles (changelogs claros, paths de deprecación) y el ecosistema es lo bastante maduro?
Señales de alarma que anuncian reescrituras
Una reescritura suele ser el resultado final de pequeños dolores ignorados. Vigila:
- Límites poco claros: lógica de negocio que deriva a controladores, middleware o modelos ORM
- Tests lentos: tests de integración que tardan minutos y empujan a los equipos a saltárselos
- Upgrades frágiles: cambios rompientes frecuentes, dependencia de APIs internas o soluciones de la comunidad que se vuelven normales
Patrones de refactor incremental que mantienen la entrega
Puedes evolucionar sin parar el trabajo de features introduciendo cosidos:
- Enfoque estrangulador: enruta un pequeño conjunto de endpoints a través de un módulo nuevo mientras el sistema viejo sigue funcionando
- Capas adaptadoras: envuelve primitivas específicas del framework detrás de tus propias interfaces (request context, logger, repositorios)
- Límites “ports and adapters”: mueve la lógica de dominio a módulos planos con mínimas importaciones del framework y luego conéctalos en los bordes
Checklist de adopción y siguientes pasos
Antes de comprometerte (o antes de la próxima gran actualización), haz un ensayo corto:
- Construye un endpoint real de punta a punta: auth, validación, respuestas de error y logging.
- Escribe dos tests: uno unitario rápido para lógica de dominio y uno de integración para la capa HTTP.
- Simula un cambio: añade un campo, versiona una respuesta y refactoriza un módulo.
- Revisa las notas de la última versión mayor —¿te habría afectado?
Si quieres una forma estructurada de evaluar opciones, crea un RFC ligero y guárdalo con la base de código (por ejemplo, /docs/decisions) para que los equipos futuros entiendan por qué elegisteis lo que elegisteis —y cómo cambiarlo con seguridad.
Una lente extra a considerar: si tu equipo experimenta con bucles de build más rápidos (incluyendo desarrollo guiado por chat), evalúa si vuestro flujo aún produce los mismos artefactos arquitectónicos —módulos claros, contratos aplicables y defaults operativos. Las mejores aceleraciones (ya vengan de un CLI del framework o de una plataforma como Koder.ai) son las que reducen el tiempo de ciclo sin erosionar las convenciones que mantienen un backend mantenible.