Qué es el sharding (y qué no es)
Sharding (también llamado particionado horizontal) consiste en presentar a tu aplicación lo que parece una base de datos y repartir sus datos entre múltiples máquinas, llamadas shards. Cada shard contiene solo un subconjunto de las filas, pero en conjunto representan el dataset completo.
Una tabla lógica, muchos lugares físicos
Un modelo mental útil es la diferencia entre estructura lógica y colocación física.
- Lógico: sigues teniendo una tabla “Users” (mismas columnas, mismo significado).
- Físico: las filas de esa tabla están almacenadas en distintos sitios—por ejemplo, usuarios con IDs 1–1.000.000 en el shard A y el siguiente millón en el shard B.
Desde el punto de vista de la app quieres ejecutar consultas como si fuera una sola tabla. Bajo el capó, el sistema debe decidir a qué shard(s) hablar.
No es replicación, ni "comprar una máquina más grande"
El sharding es diferente a la replicación. La replicación crea copias de los mismos datos en varios nodos, principalmente para alta disponibilidad y escalado de lecturas. El sharding divide los datos para que cada nodo tenga registros distintos.
También es distinto al escalado vertical, donde mantienes una sola base de datos pero la mueves a una máquina más grande (más CPU/RAM/discos). El escalado vertical puede ser más simple, pero tiene límites prácticos y puede volverse caro rápidamente.
Lo que el sharding no arregla mágicamente
El sharding aumenta capacidad, pero no convierte automáticamente tu base de datos en “fácil” ni acelera todas las consultas.
- Joins pueden volverse caros si filas relacionadas viven en shards distintos.
- Transacciones entre shards son más difíciles; las actualizaciones "todo o nada" pueden requerir coordinación.
- Complejidad operativa aumenta: enrutamiento, reequilibrio, depuración y gestión de fallos entran en el alcance del sistema.
Así que el sharding se entiende mejor como una forma de escalar almacenamiento y throughput—no como una mejora gratuita en todos los aspectos del comportamiento de la base de datos.
Por qué los equipos shardean: los problemas que intenta resolver
Rara vez el sharding es la primera opción. Los equipos suelen llegar a él después de que un sistema exitoso choca con límites físicos—or tras dolores operativos que ya no se pueden ignorar. La motivación es menos “queremos sharding” y más “necesitamos seguir creciendo sin que una base de datos sea un único punto de fallo y coste”.
Puntos de dolor que empujan hacia el sharding
Un único nodo de base de datos puede quedarse sin capacidad de varias maneras:
- Límites de almacenamiento: tablas e índices crecen hasta que el disco se ajusta, los backups se vuelven lentos y las operaciones de mantenimiento son riesgosas.
- Límites de throughput de escrituras: CPU, WAL/redo o contención de locks capan cuántas escrituras por segundo puedes sostener.
- Límites de throughput de lectura: incluso con cachés y réplicas, algunas cargas desbordan el primario (o las réplicas resultan caras para escalar).
- Vecinos ruidosos: un tenant, cliente o patrón de carga monopoliza recursos y degrada al resto.
Cuando estos problemas aparecen con regularidad, el problema suele ser que una máquina carga con demasiada responsabilidad.
Los objetivos: escalar horizontalmente, aislar y controlar costes
El sharding reparte datos y tráfico entre múltiples nodos para que la capacidad crezca añadiendo máquinas en lugar de escalar verticalmente una sola. Bien hecho, también puede aislar cargas (para que el pico de un tenant no arruine la latencia para otros) y controlar costes evitando instancias premium cada vez más grandes.
Señales tempranas de que estás cerca del límite
Patrones recurrentes incluyen latencias p95/p99 en subida durante picos, mayor lag de replicación, backups/restores que exceden ventanas aceptables y cambios de esquema “pequeños” que se convierten en eventos mayores.
Por qué el sharding suele ser el último recurso
Antes de comprometerse, los equipos suelen agotar opciones más simples: índices y arreglos de consultas, caché, réplicas de lectura, particionado dentro de una sola base de datos, archivado de datos antiguos y mejoras de hardware. El sharding puede resolver la escala, pero añade coordinación, complejidad operativa y nuevos modos de fallo—así que la barra debe ser alta.
Una base de datos shardeda no es una sola cosa—es un pequeño sistema de partes que cooperan. La razón por la que el sharding puede sentirse “difícil de razonar” es que la corrección y el rendimiento dependen de cómo estas piezas interactúan, no solo del motor de base de datos.
Shards: particiones independientes (con sus propios índices)
Un shard es un subconjunto de los datos, normalmente almacenado en su propio servidor o clúster. Cada shard suele tener su propio:
- almacenamiento (ficheros de datos)
- índices (para que las consultas sean rápidas dentro de ese shard)
- límites locales (CPU, memoria, disco, conexiones)
Desde la vista de la aplicación, un setup shardedo suele intentar parecer una base de datos lógica única. Pero bajo el capó, una consulta que sería “una búsqueda de índice” en una base de datos de un solo nodo puede convertirse en “encuentra el shard correcto, luego haz la búsqueda”.
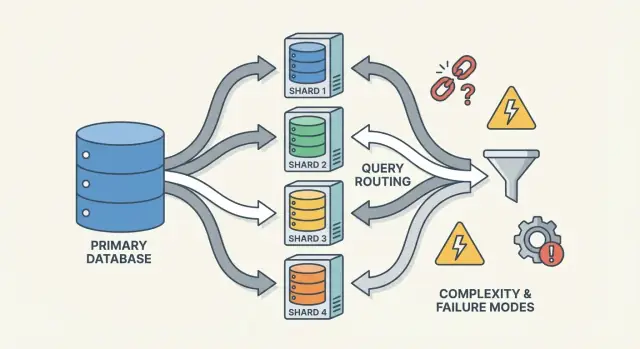
Routers/coordinadores: cómo las solicitudes alcanzan el shard correcto
Un router (a veces llamado coordinador, query router o proxy) es el control de tráfico. Responde a la pregunta práctica: dada esta petición, ¿qué shard debe manejarla?
Hay dos patrones comunes:
- Enrutamiento en el cliente: la librería de la aplicación conoce el mapa de shards y conecta directamente al shard correcto.
- Proxy: la app conecta a un servicio router, que reenvía la petición.
Los routers reducen la complejidad en la app, pero también pueden convertirse en un cuello de botella o un nuevo punto de fallo si no se diseñan con cuidado.
El sharding depende de metadata—una fuente de verdad que describe:
- el mapa de shards (qué shard posee qué rango/buckets/hash/IDs)
- propiedad (especialmente durante migraciones, cuando la propiedad puede solaparse temporalmente)
- salud y membresía (qué nodos están arriba, roles primario/replica, estado de drenado)
Esta información suele vivir en un servicio de configuración (o una pequeña "plataforma de control"). Si la metadata está obsoleta o inconsistente, los routers pueden enviar tráfico al lugar equivocado—aunque cada shard esté perfecto.
Jobs en segundo plano: balanceo, migraciones y backups
Finalmente, el sharding depende de procesos en segundo plano que mantienen el sistema usable con el tiempo:
- reequilibrio de datos cuando un shard crece más rápido que otros
- migraciones al mover propiedad entre shards
- backups/restores que funcionen a través de muchos shards (y cumplan tus objetivos de recuperación)
Estos trabajos son fáciles de ignorar al principio, pero son donde ocurren muchas sorpresas en producción—porque cambian la forma del sistema mientras sigue sirviendo tráfico.
Elegir la clave de shard: el primer gran trade-off
Una clave de shard es el campo (o combinación de campos) que tu sistema usa para decidir en qué shard se almacena una fila/documento. Esa elección única determina en silencio el rendimiento, el coste e incluso qué características serán “fáciles” después—porque controla si las solicitudes pueden enrutar a un shard o deben difundirse a muchos.
Qué hace buena a una clave de shard
Una buena clave suele tener:
- Alta cardinalidad: muchos valores posibles (p. ej.,
user_id en lugar de país).
- Distribución pareja: valores que reparten escrituras y lecturas entre shards en vez de amontonarse en uno.
- Patrones de acceso estables: coincide con cómo consultas más a menudo hoy y cómo esperas consultarlo en el próximo trimestre.
Un ejemplo común es shardear por tenant_id en una app multi-tenant: la mayoría de lecturas y escrituras de un tenant permanecen en un shard, y hay suficientes tenants para repartir la carga.
Qué hace mala a una clave de shard (y por qué duele)
Algunas claves casi garantizan dolor:
- Claves monotónicas basadas en tiempo (timestamps, IDs auto-incrementales): los datos nuevos se agrupan en el shard “más reciente”, creando un hotspot de escrituras.
- Campos de baja cardinalidad (status, plan_tier, país): pocos valores distintos implican que pocos shards hagan la mayor parte del trabajo.
- Identificadores cambiantes (email, usernames mutables): si la clave cambia, mover datos entre shards se vuelve caro y arriesgado.
Aunque una clave de baja cardinalidad parezca conveniente para filtrar, suele convertir consultas rutinarias en consultas scatter-gather, porque las filas coincidentes pueden estar en cualquier shard.
El trade-off real: conveniencia de consulta vs calidad de distribución
La mejor clave para balancear carga no siempre es la mejor para las consultas del producto.
- Elige una clave alineada a tu patrón de acceso principal (p. ej.,
user_id) y algunas consultas “globales” (p. ej., reporting de admins) se vuelven más lentas o requieren pipelines separados.
- Elige una clave alineada al reporting (p. ej.,
region) y arriesgas hotspots y capacidad desigual.
La mayoría de equipos diseñan alrededor de ese trade-off: optimizan la clave de shard para las operaciones más frecuentes y sensibles a latencia, y manejan el resto con índices, desnormalización, réplicas o tablas analíticas dedicadas.
Estrategias comunes de sharding (rango, hash, directorio)
No hay una única forma “mejor” de shardear. La estrategia que elijas determina cuán fácil es enrutar consultas, cómo se distribuyen los datos y qué patrones de acceso van a perjudicarte.
Range sharding
Con range sharding, cada shard posee un segmento contiguo del espacio de claves—por ejemplo:
- Shard A: customer_id 1–1.000.000
- Shard B: customer_id 1.000.001–2.000.000
El enrutamiento es directo: mira la clave y elige el shard.
El problema son los hotspots. Si los usuarios nuevos siempre obtienen IDs crecientes, el shard “final” se convierte en el cuello de botella de escrituras. El range sharding también es sensible al crecimiento desigual (un rango se vuelve popular y otro permanece tranquilo). La ventaja: las consultas por rango (“todos los pedidos de Oct 1–Oct 31”) pueden ser eficientes porque los datos están agrupados físicamente.
Hash sharding
El hash sharding aplica la clave de shard a una función hash y usa el resultado para escoger un shard. Esto suele repartir los datos de forma más uniforme, ayudando a evitar el problema de “todo a la shard más nueva”.
El trade-off: las consultas por rango se vuelven problemáticas. Una consulta como “customers con IDs entre X e Y” ya no mapea a un pequeño conjunto de shards; puede tocar muchos.
Un detalle práctico que se subestima es el hashing consistente. En lugar de mapear directamente al número de shards (lo que reubica todo al añadir shards), muchos sistemas usan un anillo hash con “nodos virtuales” para que añadir capacidad mueva solo una porción de las claves.
Directory (lookup) sharding
El directory sharding almacena un mapeo explícito (una tabla/servicio de lookup) de clave → ubicación del shard. Es la opción más flexible: puedes ubicar tenants específicos en shards dedicados, mover un cliente sin mover a todos y soportar tamaños de shard desiguales.
La desventaja es una dependencia extra. Si el directorio es lento, obsoleto o no está disponible, el enrutamiento sufre—aunque los shards estén sanos.
Claves compuestas y sub-sharding
Los sistemas reales suelen mezclar enfoques. Una clave compuesta (p. ej., tenant_id + user_id) aísla tenants mientras distribuye carga dentro de un tenant. El sub-sharding es similar: primero enrutas por tenant y luego haces hash dentro del grupo de shards del tenant para evitar que un tenant grande domine un shard.
Cómo funcionan las consultas: enrutamiento vs scatter-gather
Valida como en producción
Despliega tu prototipo para ver cómo se comportan el enrutamiento y la latencia tail bajo tráfico real.
Una base de datos shardeda tiene dos rutas de consulta muy diferentes. Entender en cuál estás explica la mayoría de las sorpresas en rendimiento—y por qué el sharding puede sentirse impredecible.
Consultas a un solo shard: la vía rápida
El resultado ideal es enrutar una consulta a exactamente un shard. Si la petición incluye la clave de shard (o algo que el router puede mapear), el sistema la puede enviar directamente al lugar correcto.
Por eso los equipos se obsesionan con hacer lecturas comunes “conscientes de la clave de shard”. Un solo shard implica menos saltos de red, ejecución más simple, menos locks y mucha menos coordinación. La latencia es principalmente la base de datos haciendo el trabajo, no el clúster discutiendo quién debe hacerlo.
Lecturas scatter-gather: fan-out y latencia tail
Cuando una consulta no puede enrutar exactamente (por ejemplo, filtra por un campo que no es clave de shard), el sistema puede broadcastearla a muchos o todos los shards. Cada shard ejecuta la consulta localmente y luego el router (o coordinador) combina resultados—ordenando, deduplicando, aplicando límites y combinando agregados parciales.
Este fan-out amplifica la latencia tail: aunque 9 shards respondan rápido, un shard lento puede retener toda la petición. También multiplica la carga: una petición de usuario puede convertirse en N peticiones a shards.
Joins y agregaciones entre shards
Los joins entre shards son costosos porque datos que se habrían juntado dentro de una sola base tienen que viajar entre shards (o al coordinador). Incluso agregaciones simples (COUNT, SUM, GROUP BY) pueden requerir un plan en dos fases: calcular parciales en cada shard y luego mezclarlos.
Limitaciones de índices: locales vs globales
La mayoría de sistemas usan índices locales: cada shard indexa solo sus propios datos. Son baratos de mantener, pero no ayudan al enrutamiento—así que las consultas aún pueden dispersarse.
Los índices globales permiten enrutamiento dirigido en campos que no son clave de shard, pero añaden sobrecarga de escritura, coordinación extra y sus propios problemas de escalado y consistencia.
Escrituras y transacciones entre shards
Las escrituras son donde el sharding deja de sentirse “solo escalado” y empieza a cambiar el diseño de las funcionalidades. Una escritura que toca un shard puede ser rápida y simple. Una escritura que abarca shards puede ser lenta, propensa a fallos y sorprendentemente difícil de hacer correcta.
Escrituras a un solo shard: la senda feliz
Si cada petición se puede enrutar a exactamente un shard (típicamente vía la clave de shard), la base de datos puede usar su maquinaria transaccional normal. Obtienes atomicidad e aislamiento dentro de ese shard, y la mayoría de problemas operativos parecen problemas de un solo nodo—solo que repetidos N veces.
Escrituras multi-shard: donde la complejidad se dispara
En el momento en que necesitas actualizar datos en dos shards en una sola acción lógica (p. ej., transferir dinero, mover un pedido entre clientes, actualizar un agregado almacenado en otro sitio), entras en territorio de transacciones distribuidas.
Las transacciones distribuidas son difíciles porque requieren coordinación entre máquinas que pueden ser lentas, particionadas o reiniciadas en cualquier momento. Protocolos al estilo two-phase commit añaden viajes extra, pueden bloquear por timeouts y hacen que los fallos sean ambiguos: ¿aplicó el shard B el cambio antes de que el coordinador muriera? Si el cliente reintenta, ¿duplicas la escritura? Si no reintentas, ¿la pierdes?
Patrones para evitar escrituras entre shards
Algunas tácticas comunes reducen la frecuencia de transacciones multi-shard:
- Localidad de datos: co-loca registros relacionados en el mismo shard (p. ej., todo lo de un cliente).
- Enrutamiento de solicitud: asegura que una operación sea “propiedad” de un shard y trata a los demás como inputs de solo lectura.
- Desnormalización: duplica pequeños trozos de datos para que las actualizaciones no tengan que repartirse.
Idempotencia y seguridad ante reintentos
En sistemas shardedos, los reintentos no son opcionales—son inevitables. Haz las escrituras idempotentes usando IDs de operación estables (p. ej., una clave de idempotencia) y que la base de datos almacene marcadores de “ya aplicado”. Así, si ocurre un timeout y el cliente reintenta, el segundo intento es un no-op en lugar de un cargo doble, pedido duplicado o contador inconsistente.
Consistencia y replicación: mantener los datos correctos
Modela shards multi-tenant
Crea una pequeña app multi-tenant y observa cómo el sharding por tenant_id cambia tus consultas.
El sharding reparte tus datos entre máquinas, pero no elimina la necesidad de redundancia. La replicación es lo que mantiene un shard disponible cuando un nodo muere—y también lo que complica la respuesta a “¿qué es verdad ahora mismo?”.
Replicación dentro de cada shard
La mayoría de sistemas replican dentro de cada shard: un primario (leader) acepta escrituras y una o más réplicas copian esos cambios. Si el primario falla, el sistema promueve una réplica (failover). Las réplicas también pueden servir lecturas para reducir carga.
El trade-off es temporalidad. Una réplica de lectura puede estar algunos milisegundos—o segundos—por detrás. Esa brecha es normal, pero importa cuando los usuarios esperan “lo acabo de actualizar y debería verlo”.
Modelos de consistencia en términos simples
- Consistencia fuerte: después de que una escritura tiene éxito, las lecturas la reflejarán (desde el punto de vista que el sistema promete). Esto suele implicar leer del líder o esperar confirmación de réplicas.
- Consistencia eventual: el sistema convergerá, pero una lectura puede devolver datos viejos temporalmente.
En setups shardedos, a menudo terminas con consistencia fuerte dentro de un shard y garantías más débiles entre shards, especialmente cuando hay operaciones multi-shard.
“Fuente única de verdad” cuando los datos están divididos
Con sharding, “fuente única de verdad” típicamente significa: para cada fragmento de datos existe un lugar autoritativo para escribirlo (normalmente el líder del shard). Pero globalmente no hay una máquina que pueda confirmar instantáneamente el último estado de todo. Tienes muchas verdades locales que deben mantenerse sincronizadas mediante replicación.
Restricciones globales: unicidad, claves foráneas, contadores
Las restricciones son complicadas cuando los datos que necesitan ser comprobados viven en shards distintos:
- Unicidad (p. ej., username): imponer “sin duplicados en ninguna parte” puede requerir un índice centralizado, un "shard" dedicado para la restricción o un flujo de reserva a nivel de aplicación.
- Claves foráneas: si filas padre e hijo están en shards distintos, la base de datos no puede hacer cumplir la integridad referencial fácilmente sin coordinación entre shards.
- Contadores (totales globales, IDs secuenciales): los enfoques ingenuos crean un cuello de botella. Las soluciones comunes incluyen rangos por shard, batching o aceptar cuentas aproximadas.
Estas decisiones no son solo detalles de implementación—definen qué significa “correcto” para tu producto.
Reequilibrio y resharding sin downtime
El reequilibrio es lo que mantiene una base de datos shardeda usable a medida que la realidad cambia. Los datos crecen de forma desigual, una clave balanceada deriva hacia sesgo, añades nuevos nodos por capacidad o necesitas retirar hardware. Cualquiera de estas cosas puede convertir un shard en el cuello de botella—incluso si el diseño original parecía perfecto.
Por qué es difícil
A diferencia de una base de datos única, el sharding incorpora la ubicación de los datos en la lógica de enrutamiento. Cuando mueves datos no solo copias bytes—cambias dónde deben llegar las consultas. Eso significa que reequilibrar es tanto metadata y comportamiento de clientes como almacenamiento.
El patrón de migración en línea (copiar → solapamiento → cutover)
La mayoría de equipos aspiran a un flujo online que evite una gran ventana de "parar el mundo":
- Copiar: backfill en el/los shard(s) destino desde el shard origen mientras el sistema está en vivo.
- Escritura dual (a veces lectura dual): durante la transición, escribe los cambios nuevos en ubicación vieja y nueva. Las lecturas pueden consultar ambas (o aplicar una regla de “gana la nueva”) hasta estar confiados.
- Cutover: actualiza el mapa de shards para que routers/clients envíen tráfico a la nueva ubicación.
- Limpieza: para las escrituras duales, elimina la copia antigua y libera espacio.
Mapas de shards y comportamiento del cliente
Un cambio en el mapa de shards es un evento rompedizo si los clientes cachean decisiones de enrutamiento. Los buenos sistemas tratan la metadata de enrutamiento como configuración: la versionan, la refrescan con frecuencia y son explícitos sobre qué pasa cuando un cliente ataca una clave movida (redirección, reintento o proxy).
Riesgos operativos para planear
El reequilibrio suele causar dips temporales en rendimiento (escrituras extra, churn de caché, carga de copia en segundo plano). Las migraciones parciales son comunes—algunas ranges migran antes que otras—por lo que necesitas buena observabilidad y un plan de rollback (por ejemplo, revertir el mapa y drenar escrituras duales) antes del cutover.
Hotspots y sesgo: cuando el “corte parejo” falla
El sharding asume que el trabajo se distribuirá. La sorpresa es que un clúster puede parecer “parejo” en papel (mismo número de filas por shard) mientras se comporta de forma muy desigual en producción.
Particiones calientes (hot keys)
Un hotspot ocurre cuando una pequeña porción del espacio de claves recibe la mayor parte del tráfico—piensa en una cuenta de celebridad, un producto popular, un tenant ejecutando un job pesado o una clave basada en tiempo donde “hoy” atrae todas las escrituras. Si esas claves mapean a un shard, ese shard será el cuello de botella aunque los otros estén ociosos.
Sesgo: tamaño de datos vs tráfico
“Sesgo” no es una sola cosa:
- Sesgo de datos: un shard tiene más bytes/filas (presión de almacenamiento, backups más largos, scans más lentos).
- Sesgo de tráfico: un shard maneja más QPS o consultas más pesadas (CPU saturada, encolamiento, picos de latencia).
No siempre coinciden. Un shard con menos datos aún puede ser el más caliente si posee las claves más solicitadas.
Cómo detectarlo rápido
No necesitas trazado sofisticado para detectar sesgo. Comienza con dashboards por shard:
- p95 de latencia por shard (que el p95 de un shard diverja es una señal)
- QPS (y write QPS) por shard
- Almacenamiento usado / tamaño de tabla por shard
Si la latencia de un shard sube con su QPS mientras los demás se mantienen, probablemente hay un hotspot.
Mitigaciones
Las soluciones suelen sacrificar simplicidad por balance:
- Elige una clave de shard que reparta tráfico, no solo registros.
- Añade bucketing/salting para claves calientes (dividir una clave lógica en múltiples buckets físicos).
- Usa caching para ítems calientes y de lectura intensiva.
- Aplica rate limits o cuotas por tenant para proteger el clúster.
- Divide shards calientes (o mueve rangos calientes) cuando uno no se puede enfriar.
Modos de fallo y depuración en un sistema shardedo
Crea un sandbox de sharding
Genera un backend en Go y PostgreSQL para probar enrutamiento, metadatos y consultas fan-out.
El sharding no solo añade más servidores—añade más formas de fallar y más lugares donde mirar cuando algo falla. Muchos incidentes no son “la base de datos está caída”, sino “un shard está caído” o “el sistema no sabe dónde vive un dato”.
Modos de fallo comunes
Algunos patrones recurrentes:
- Un shard no está disponible (crash, disco lleno, pausas GC largas), causando outages parciales: algunos clientes funcionan, otros fallan.
- Router enrutando mal, a menudo tras un cambio de config o un deploy defectuoso. Lecturas pueden devolver silenciosamente resultados vacíos si se envían al shard equivocado.
- Metadata obsoleta o inconsistente (p. ej., mapa de shards). Durante moves o splits, componentes distintos pueden enrutar la misma clave a lugares diferentes.
- Problemas de red parciales: timeouts entre routers y un subconjunto de shards pueden parecer errores “aleatorios” y disparar reintentos que amplifican la carga.
Cómo cambia la depuración
En una base de datos de un solo nodo, sigues un log y miras un conjunto de métricas. En un sistema shardedo necesitas observabilidad que siga una petición a través de shards.
Usa correlation IDs en cada petición y propágalos desde la capa API a través de routers hasta cada shard. Combínalo con tracing distribuido para que una consulta scatter-gather muestre qué shard fue lento o falló. Las métricas deben estar desglosadas por shard (latencia, profundidad de colas, tasa de errores), de otro modo un shard caliente se pierde dentro de promedios del conjunto.
Incidentes de corrección de datos
Los fallos del sharding suelen aparecer como bugs de corrección:
- Duplicados tras reintentos o escrituras no idempotentes.
- Filas faltantes cuando una migración movió datos pero el enrutamiento aún apunta al lugar antiguo.
- Writes split-brain si dos vistas de metadata aceptan escrituras para el mismo rango.
Backup, restore y recuperación de desastres
“Restaurar la base de datos” se convierte en “restaurar muchas partes en el orden correcto.” Puede que necesites restaurar metadata primero, luego cada shard y verificar que fronteras y reglas de enrutamiento coincidan con el punto en el tiempo restaurado. Los planes de DR deben incluir ensayos que prueben que puedes recomponer un clúster consistente—no solo recuperar máquinas individuales.
Cuándo no shardear: alternativas prácticas y una lista de verificación
El sharding suele verse como el “interruptor de escala”, pero también es un aumento permanente de la complejidad del sistema. Si puedes alcanzar tus objetivos de rendimiento y fiabilidad sin dividir datos entre nodos, normalmente obtendrás una arquitectura más simple, depuración más fácil y menos casos borde operativos.
Alternativas prácticas que suelen dar mucho margen
Antes de shardear, prueba opciones que preserven una sola base lógica:
- Mejor indexado + optimización de consultas: arregla primero los caminos lentos—índices faltantes, consultas sin límites, joins caros y patrones N+1.
- Caché: pon respuestas de lectura intensiva y estables detrás de una caché (caché a nivel de app, CDN para contenido público o memoria en la aplicación para claves calientes).
- Réplicas de lectura: descarga tráfico de lectura sin cambiar el camino de escritura (aceptando lag donde sea OK).
- Particionado de tablas en un solo nodo: muchas bases soportan particionado que mejora mantenimiento y rendimiento sin enrutamiento entre nodos.
Dónde ayudan las herramientas: prototipar servicios conscientes del shard sin comprometerse
Una forma práctica de reducir riesgos es prototipar la plomería (límites de enrutamiento, idempotencia, workflows de migración y observabilidad) antes de comprometer la base de datos de producción.
Por ejemplo, con Koder.ai puedes levantar rápidamente un servicio pequeño y realista desde un chat—a menudo una UI admin en React más un backend en Go con PostgreSQL—y experimentar con APIs conscientes de la clave de shard, claves de idempotencia y comportamientos de cutover en un sandbox seguro. Como Koder.ai soporta modo de planificación, snapshots/rollback y exportación de código, puedes iterar en decisiones de diseño relacionadas con sharding (como enrutamiento y forma de la metadata) y luego llevar el código y los runbooks al stack principal cuando estés confiado.
Cuándo encaja el sharding (y cuándo no)
El sharding encaja mejor cuando tu dataset o throughput de escrituras claramente excede los límites de un solo nodo y tus patrones de consulta pueden usar de forma fiable una clave de shard (pocas joins entre shards, mínimo scatter-gather).
No encaja bien cuando tu producto necesita muchas consultas ad-hoc, transacciones frecuentes entre entidades, restricciones de unicidad globales o cuando el equipo no puede soportar la carga operativa (reequilibrio, resharding, respuesta a incidentes).
Una lista de verificación rápida
Pregúntate:
- Carga: ¿el cuello de botella es CPU, I/O, memoria o contención de locks—y puede arreglarse sin sharding?
- Patrones de consulta: ¿puede el 90%+ de consultas críticas enrutar por una clave de shard?
- Capacidad del equipo: ¿quién se encarga del mapa de shards, runbooks on-call y comportamiento de transacciones cruzadas?
- SLOs: ¿puedes tolerar degradación parcial (un shard caído) y latencias tail más largas?
Planificar crecimiento, no solo un diagrama
Aunque demores el sharding, diseña una ruta de migración: elige identificadores que no bloqueen una futura clave de shard, evita hardcodear suposiciones de nodo único y ensaya cómo moverías datos con mínima interrupción. El mejor momento para planear resharding es antes de que lo necesites.