25 jul 2025·8 min
Cómo los LLMs convierten ideas en inglés simple en apps full-stack
Cómo los LLMs convierten ideas en inglés simple en apps web, móviles y backend: requisitos, flujos de UI, modelos de datos, APIs, pruebas y despliegue.
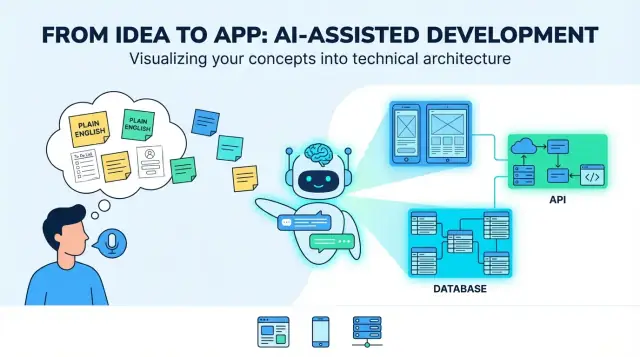
De la idea a la app: qué significa realmente “traducir”
Una “idea de producto en inglés simple” suele comenzar como una mezcla de intención y esperanza: a quién va dirigida, qué problema resuelve y qué aspecto tiene el éxito. Puede ser un par de frases (“una app para agendar paseadores de perros”), un flujo aproximado (“cliente solicita → paseador acepta → pago”), y un par de requisitos indispensables (“notificaciones push, valoraciones”). Eso basta para hablar de una idea, pero no para construirla de forma consistente.
Cuando la gente dice que un LLM puede “traducir” una idea a una app, el sentido útil es este: convertir objetivos difusos en decisiones concretas y comprobables. La “traducción” no es solo reescribir: es añadir estructura para que puedas revisar, desafiar e implementar.
Qué puede generar el LLM (rápido)
Los LLMs son buenos produciendo un primer borrador de los bloques constructores principales:
- Roles de usuario y recorridos centrales (p. ej., cliente, proveedor, admin)
- Listas de funcionalidades y criterios de aceptación (“un usuario puede restablecer la contraseña por email”)
- Inventarios de pantallas y flujos de UI para web y móvil
- Arquitectura sugerida (apps frontend, servicios backend, integraciones)
- Modelos de datos (tablas/colecciones, relaciones)
- Esquemas de API (endpoints, formas de request/response)
El “resultado” típico parece un plano para un producto full-stack: una UI web (a menudo para admins o tareas de escritorio), una UI móvil (para usuarios en movimiento), servicios backend (auth, lógica de negocio, notificaciones) y almacenamiento de datos (base de datos más almacenamiento de archivos/medios).
Qué sigue requiriendo decisiones humanas
Los LLMs no pueden elegir de forma fiable las compensaciones de tu producto, porque las respuestas correctas dependen del contexto que quizá no hayas escrito:
- ¿Qué cuenta como “éxito” y qué métricas importan?
- ¿Qué restricciones existen (presupuesto, cronograma, cumplimiento, herramientas existentes)?
- ¿Qué casos límite te importan (y cuáles puedes posponer)?
- ¿Cuál es la versión más simple que a los usuarios les seguirá encantando?
Trata al modelo como un sistema que propone opciones y valores por defecto, no como una verdad final.
Riesgos clave a vigilar
Los modos de fallo más habituales son previsibles:
- Ambigüedad: palabras como “rápido”, “seguro” o “fácil” no se pueden implementar sin definiciones.
- Falta de casos límite: cancelaciones, reintentos, modo offline, reembolsos, duplicados, abuso.
- Exceso de confianza: las salidas pueden sonar seguras aun cuando las suposiciones son frágiles.
El objetivo real de la “traducción” es hacer visibles las suposiciones, para que puedas confirmarlas, revisarlas o rechazarlas antes de que se conviertan en código.
Paso 1: Aclarar el brief del producto
Antes de que un LLM pueda convertir “Construye una app para X” en pantallas, APIs y modelos de datos, necesitas un brief de producto lo bastante específico como para diseñar sobre él. Este paso trata de convertir la intención difusa en un objetivo compartido.
Empieza con el problema y cómo medirás el éxito
Escribe la declaración del problema en una o dos frases: quién tiene la dificultad, con qué y por qué importa. Después añade métricas de éxito observables.
Por ejemplo: “Reducir el tiempo que tarda una clínica en agendar citas de seguimiento.” Las métricas podrían incluir tiempo medio de agendado, tasa de no presentación o % de pacientes que reservan por autoservicio.
Define usuarios objetivo y casos de uso principales
Lista los tipos de usuario primarios (no todo el que pueda tocar el sistema). Da a cada uno una tarea principal y un escenario corto.
Un prompt útil: “Como [rol], quiero [hacer algo] para [beneficio].” Apunta a 3–7 casos de uso centrales que describan el MVP.
Captura las restricciones desde temprano (dan forma a todo)
Las restricciones son la diferencia entre un prototipo limpio y un producto enviable. Incluye:
- Plataformas: web, iOS, Android (y necesidades offline)
- Cronograma y presupuesto: qué compensaciones son aceptables
- Cumplimiento/privacidad: HIPAA, GDPR, residencia de datos, logs de auditoría
- Integraciones: pagos, calendarios, SSO, CRM, proveedores de email/SMS
Define “hecho”: MVP vs posteriores
Sé explícito sobre lo que entra en la primera versión y lo que se pospone. Una regla simple: las funcionalidades del MVP deben soportar los casos de uso primarios de principio a fin sin soluciones manuales.
Si quieres, captura esto en un brief de una página y úsalo como “fuente de verdad” para los siguientes pasos (requisitos, flujos de UI y arquitectura).
Paso 2: Convertir inglés simple en requisitos
Una idea en lenguaje natural es normalmente una mezcla de objetivos (“ayudar a la gente a reservar clases”), suposiciones (“los usuarios iniciarán sesión”) y alcance vago (“hazlo simple”). Un LLM es útil aquí porque puede convertir la entrada desordenada en requisitos que puedas revisar, corregir y aprobar.
Convierte afirmaciones en historias de usuario
Empieza reescribiendo cada frase como una historia de usuario. Esto fuerza claridad sobre quién necesita qué y por qué:
- Como usuario nuevo, quiero registrarme con email o Google para empezar rápidamente.
- Como usuario recurrente, quiero ver mis reservas próximas para poder planificar mi semana.
Si una historia no nombra un tipo de usuario o beneficio, probablemente sigue siendo demasiado vaga.
Crea una lista de funcionalidades y establece prioridades
Luego, agrupa historias en funcionalidades y etiqueta cada una como must-have o nice-to-have. Esto ayuda a prevenir la deriva de alcance antes de que diseño e ingeniería empiecen.
Ejemplo: “notificaciones push” puede ser nice-to-have, mientras que “cancelar una reserva” suele ser must-have.
Escribe criterios de aceptación que el modelo pueda comprobar
Añade reglas simples y comprobables bajo cada historia. Buenos criterios de aceptación son específicos y observables:
- Dado que ingreso un email inválido, cuando envío el formulario, entonces veo un error inline y la cuenta no se crea.
- Dado que cancelo dentro de 24 horas, cuando confirmo la cancelación, entonces mi plaza se libera y recibo un mensaje de confirmación.
Lista casos límite desde temprano
Los LLMs tienden a dar por hecho el “camino feliz”, así que pide explícitamente casos límite como:
- Modo offline o red pobre (acciones en cola, comportamiento de reintento)
- Entradas inválidas (campos vacíos, tipos de archivo no soportados)
- Cancelaciones y envíos dobles (idempotencia, prompts de confirmación)
Este paquete de requisitos se convierte en la fuente de verdad que usarás para evaluar salidas posteriores (flujos de UI, APIs y pruebas).
Paso 3: Diseñar flujos de UI para web y móvil
Una idea en lenguaje natural es construible cuando se convierte en trayectos de usuario y pantallas conectadas por una navegación clara. En este paso no eliges colores: defines qué puede hacer la gente, en qué orden y qué significa el éxito.
Mapea los recorridos clave de usuario
Empieza listando las rutas que más importan. Para muchos productos puedes estructurarlas como:
- Onboarding: creación de cuenta, verificación de email/teléfono, configuración inicial
- Tarea central: el trabajo principal que la app ayuda a hacer (crear, buscar, reservar, rastrear, compartir)
- Pago: vista de precios, checkout, recibos, gestión de suscripciones (si aplica)
- Soporte: FAQ, formulario de contacto, reportar un problema
- Ajustes: perfil, notificaciones, controles de privacidad, cerrar sesión, eliminar cuenta
El modelo puede redactar estos flujos como secuencias paso a paso. Tu trabajo es confirmar qué es opcional, qué es obligatorio y dónde los usuarios pueden salir y volver sin problema.
Genera un listado de pantallas (web + móvil) con navegación
Pide dos entregables: un inventario de pantallas y un mapa de navegación.
- Web suele favorecer una barra lateral superior/izquierda con más opciones visibles.
- Móvil típicamente usa pestañas y pantallas apiladas, con menos opciones por vista.
Un buen resultado nombra las pantallas consistentemente (p. ej., “Order Details” vs “Order Detail”), define puntos de entrada e incluye estados vacíos (sin resultados, sin elementos guardados).
Formularios y reglas de validación
Convierte los requisitos en campos de formulario con reglas: requerido/opcional, formatos, límites y mensajes de error amigables. Ejemplo: reglas de contraseña, formatos de dirección de pago o “la fecha debe ser en el futuro”. Asegura validación inline (mientras el usuario escribe) y en el envío.
Conceptos básicos de accesibilidad para incorporar
Incluye tamaños de texto legibles, contraste claro, soporte completo de teclado en web y mensajes de error que expliquen cómo arreglar el problema (no solo “Entrada inválida”). Asegura además que cada campo de formulario tenga una etiqueta y que el orden de enfoque tenga sentido.
Paso 4: Proponer una arquitectura de la app
Una “arquitectura” es el plano de la app: qué partes existen, cuál es la responsabilidad de cada una y cómo se comunican. Cuando un LLM propone una arquitectura, tu trabajo es asegurarte de que sea lo bastante simple para construir ahora y lo bastante clara para evolucionar después.
Empieza con un valor por defecto: ¿monolito o modular?
Para la mayoría de productos nuevos, un backend único (monolito) es la opción correcta para comenzar: un código, un despliegue, una base de datos. Es más rápido de construir, más fácil de depurar y más barato de operar.
Un monolito modular suele ser el punto óptimo: todavía un despliegue, pero organizado en módulos (Auth, Billing, Projects, etc.) con límites claros. Retrasas la separación en servicios hasta que haya una presión real—como tráfico alto, un equipo que necesita despliegues independientes o una parte del sistema que escala de otro modo.
Si el LLM sugiere de inmediato “microservicios”, pídele que justifique esa elección con necesidades concretas, no hipotéticas futuras.
Define los componentes centrales (y mantenlos sencillos)
Un buen esquema arquitectónico nombra lo esencial:
- Auth y gestión de usuarios: registro/login, roles, sesiones/tokens.
- Capa de lógica de negocio: reglas del producto (precios, aprobaciones, límites).
- Acceso a datos: cómo lee/escribe la app en la base de datos.
- Trabajos en background: procesos largos (imports, generación de informes, tareas programadas).
- Notificaciones: email/push/in-app, plantillas y preferencias.
El modelo también debería especificar dónde vive cada pieza (backend vs móvil vs web) y definir cómo interactúan los clientes con el backend (normalmente REST o GraphQL).
Haz explícitas las suposiciones sobre el stack tecnológico
La arquitectura sigue ambigua a menos que fijes lo básico: framework de backend, base de datos, hosting y enfoque móvil (nativo vs multiplataforma). Pide al modelo que escriba esto como “Suposiciones” para que todos sepan contra qué se está diseñando.
Planifica la escalabilidad sin sobreingeniería
En lugar de grandes reescrituras, prefiere pequeñas “vías de escape”: cacheo para lecturas calientes, una cola para trabajos en background y servidores de aplicación sin estado para poder añadir instancias. Las mejores propuestas explican estas opciones manteniendo v1 sencilla.
Paso 5: Modelar los datos
Diseña APIs listas para producción
Convierte acciones de usuarios en endpoints claros con errores coherentes y versionado.
Un producto está lleno de sustantivos: “usuarios”, “proyectos”, “tareas”, “pagos”, “mensajes”. Modelar datos es el paso donde un LLM convierte esos sustantivos en una imagen compartida de lo que la app debe almacenar y cómo se conectan las cosas.
Convierte sustantivos en entidades y relaciones
Empieza listando las entidades clave y preguntando: ¿qué pertenece a qué?
Por ejemplo:
- Un Usuario crea muchos Proyectos
- Un Proyecto contiene muchas Tareas
- Una Tarea puede tener muchos Comentarios
Luego define relaciones y restricciones: ¿puede existir una tarea sin proyecto?, ¿se pueden editar los comentarios?, ¿se pueden archivar proyectos?, ¿qué pasa con las tareas cuando se elimina un proyecto?
Borrador de tablas/colecciones y campos relevantes
A continuación, el modelo propone un esquema de primera pasada (tablas SQL o colecciones NoSQL). Manténlo simple y enfocado en decisiones que afectan comportamiento.
Un borrador típico podría incluir:
- users: id, email, name, password_hash/identity_provider_id, created_at
- projects: id, owner_user_id, name, status, created_at
- project_members: project_id, user_id, role
- tasks: id, project_id, title, description, status, due_date, assignee_user_id
Importante: captura campos de “status”, timestamps y restricciones únicas temprano (como email único). Esos detalles impulsan filtros de UI, notificaciones e informes.
Propiedad, permisos y separación multi-tenant
La mayoría de las apps reales necesitan reglas claras sobre quién puede ver qué. Un LLM debería hacer explícita la propiedad (owner_user_id) y modelar el acceso (membresías/roles). Para productos multi-tenant (muchas empresas en un sistema), introduce una entidad tenant/organization y adjunta tenant_id a todo lo que debe aislarse.
También define cómo se aplican los permisos: por rol (admin/miembro/visor), por propiedad, o ambos.
Retención, eliminación y registro de auditoría
Finalmente, decide qué debe registrarse y qué debe eliminarse. Ejemplos:
- Eventos de auditoría: “tarea creada”, “permiso cambiado”, “exportación realizada”
- Reglas de retención: borrar datos personales bajo solicitud, mantener facturas X años
- Borrado suave vs borrado completo: conservar registros recuperables o eliminar completamente
Estas elecciones evitan sorpresas desagradables cuando aparecen requisitos de cumplimiento, soporte o facturación.
Paso 6: Generar APIs backend
Las APIs backend son donde las promesas de la app se convierten en acciones reales: “guardar mi perfil”, “mostrar mis pedidos”, “buscar listados”. Una buena salida parte de las acciones de usuario y las convierte en un conjunto pequeño de endpoints claros.
Parte de las acciones de usuario → CRUD + búsqueda
Lista las cosas principales con las que interactúan los usuarios (p. ej., Projects, Tasks, Messages). Para cada una define lo que el usuario puede hacer:
- Create: añadir un nuevo ítem
- Read: obtener uno o una lista
- Update: cambiar campos
- Delete: eliminar/deshabilitar
- Search/filter: encontrar ítems por palabra clave, estado, fecha, etc.
Eso suele mapearse a endpoints como:
POST /api/v1/tasks(create)GET /api/v1/tasks?status=open&q=invoice(list/search)GET /api/v1/tasks/{taskId}(read)PATCH /api/v1/tasks/{taskId}(update)DELETE /api/v1/tasks/{taskId}(delete)
Ejemplos de request/response (lenguaje natural + JSON)
Crear una tarea: el usuario envía título y fecha de vencimiento.
POST /api/v1/tasks
{
"title": "Send invoice",
"dueDate": "2026-01-15"
}
La respuesta devuelve el registro guardado (incluyendo campos generados por el servidor):
201 Created
{
"id": "tsk_123",
"title": "Send invoice",
"dueDate": "2026-01-15",
"status": "open",
"createdAt": "2025-12-26T10:00:00Z"
}
Manejo de errores que las apps móviles puedan tolerar
Haz que el modelo produzca errores consistentes:
- 400 errores de validación (con mensajes por campo)
- 401/403 problemas de autenticación/permisos
- 404 no encontrado
- 409 conflicto (duplicado, actualización obsoleta)
- 429 demasiadas peticiones (decir a los clientes cuándo reintentar)
- 500 errores inesperados (mensaje genérico + id de petición)
Para reintentos, prefiere claves de idempotencia en POST y orientación clara como “reintentar después de 5 segundos”.
Versionado y compatibilidad hacia atrás
Los clientes móviles se actualizan despacio. Usa una ruta base versionada (/api/v1/...) y evita cambios rompientes:
- Añade nuevos campos opcionales en lugar de renombrar/eliminar
- Mantén campos antiguos por una ventana de deprecación
- Documenta cambios en un changelog corto (p. ej.,
GET /api/version)
Paso 7: Seguridad y privacidad por defecto
Controla tu base de código
Mantén el control de tu repositorio exportando el código fuente generado en cualquier momento.
La seguridad no es una tarea “para después”. Cuando un LLM convierte tu idea en especificaciones de app, quieres que los valores seguros por defecto sean explícitos—para que la primera versión generada no quede accidentalmente abierta al abuso.
Autenticación: cómo los usuarios demuestran quiénes son
Pide al modelo que recomiende un método de login principal y un fallback, además de qué ocurre cuando algo falla (pérdida de acceso, inicio sospechoso). Elecciones comunes:
- Email + contraseña (familiar, pero hay que gestionar resets, reglas de fortaleza y riesgos de filtración)
- Magic links / códigos de un solo uso (menos riesgo de contraseñas, pero requiere buena entregabilidad y tokens de corta expiración)
- Social login (onboarding rápido, pero dependencia de terceros y reglas de vinculación de cuentas)
Especifica manejo de sesiones (tokens de acceso de corta vida, refresh tokens, cierre de sesión por dispositivo) y si soportas autenticación multifactor.
Autorización: qué pueden hacer los usuarios
La autenticación identifica; la autorización limita el acceso. Anima al modelo a elegir un patrón claro:
- Roles (p. ej., Admin, Member, Viewer) para apps simples
- Permisos (acciones fines como
project:edit,invoice:export) para productos flexibles - Acceso a nivel de objeto (crítico): los usuarios solo pueden leer/escribir ítems que poseen o que se comparten explícitamente
Una buena salida incluye reglas de ejemplo: “Solo los propietarios del proyecto pueden eliminarlo; los colaboradores pueden editar; los espectadores pueden comentar.”
Comprobaciones de seguridad que quieres en el plan generado
Haz que el modelo liste salvaguardas concretas, no promesas genéricas:
- Validación y sanitización de entradas en cada endpoint (no confíes en el cliente)
- Limitación de tasa para login, solicitudes de OTP/magic-link y endpoints caros
- Manejo de secretos: mantener llaves fuera del código, rotar credenciales, no loguear tokens
Pide además una checklist de amenazas básica: protecciones CSRF/XSS, cookies seguras y cargas de archivos seguras si aplica.
Privacidad básica: recoge menos, explica más
Por defecto, recolecta lo mínimo necesario: solo lo que la funcionalidad requiere y por el menor tiempo posible.
Pide al LLM que redacte en lenguaje claro:
- Qué datos recoges (y por qué)
- Cuánto tiempo los conservas
- Cómo los usuarios pueden borrar o exportar sus datos
Si añades analytics, exige una opción para darse de baja (o opt-in donde sea requerido) y documenta esto claramente en ajustes y páginas de política.
Paso 8: Estrategia de pruebas que el modelo pueda producir
Un buen LLM puede convertir tus requisitos en un plan de pruebas usable—si le fuerzas a anclar todo a criterios de aceptación, no a afirmaciones vagas.
Mapea pruebas directamente a criterios de aceptación
Empieza dándole al modelo tu lista de funcionalidades y criterios de aceptación, y pídele que genere pruebas por criterio. Una salida sólida incluye:
- Unit tests para reglas de negocio (p. ej., cálculo de precios, validación, chequeos de permisos)
- Integration tests para comportamiento API + BD (p. ej., crear un pedido persiste las filas correctas)
- End-to-end tests para recorridos críticos (p. ej., signup → onboarding → completar la primera tarea)
Si una prueba no puede vincularse a un criterio específico, probablemente es ruido.
Datos de prueba y fixtures basados en escenarios reales
Los LLMs también pueden proponer fixtures que imiten cómo la gente realmente usa la app: nombres desordenados, campos faltantes, zonas horarias, textos largos y registros casi idénticos.
Pide:
- Conjuntos de datos semilla (pequeño, mediano) con casos límite
- Factories/fixtures reutilizables para usuarios, roles y objetos comunes
- Un dataset “camino dorado” usado en E2E para consistencia
Comprobaciones específicas de móvil que se olvidan
Haz que el modelo añada una checklist móvil dedicada:
- Modo offline (solo lectura vs escrituras en cola, resolución de conflictos)
- Backgrounding/foregrounding (restauración de estado, peticiones en vuelo)
- Prompts de permisos (cámara, ubicación, notificaciones) y flujos cuando se niegan
Usar LLMs para generar pruebas—y cómo revisarlas
Los LLMs son excelentes redactando esqueletos de pruebas, pero debes revisar:
- Aserciones: ¿verifican resultados, no detalles de implementación?
- Cobertura: ¿incluyen casos de fallo (401/403, 422, timeouts)?
- Riesgos de flakiness: esperas basadas en tiempo, dependencias de red, selectores inestables
Trata al modelo como un autor rápido de pruebas, no como el criterio final de QA.
Paso 9: Despliegue, releases y monitorización
Un modelo puede generar mucho código, pero los usuarios solo se benefician cuando se entrega con seguridad y puedes ver qué pasa después del lanzamiento. Este paso trata de lanzamientos repetibles: los mismos pasos cada vez, con la menor sorpresa.
Básicos de CI (qué automatizar)
Configura una pipeline de CI simple que corra en cada pull request y en cada merge a la rama principal:
- Linting/formateo para atrapar inconsistencias y errores comunes temprano.
- Tests automáticos (unitarios + un pequeño número de E2E “camino feliz”).
- Pasos de build para cada superficie:
- Build de la web
- Build móvil (Android/iOS)
- Build/paquete del backend
Aunque el LLM haya escrito el código, CI te dice si sigue funcionando tras un cambio.
Entornos: dev, staging, producción
Usa tres entornos con propósitos claros:
- Dev: iteración rápida, BDs locales, logging de depuración.
- Staging: configuración similar a producción para la verificación final.
- Producción: usuarios reales, acceso estricto, mínimo ruido en logs.
La configuración debe manejarse vía variables de entorno y secretos (no hardcoded). Una regla útil: si cambiar un valor requiere cambiar código, probablemente está mal configurado.
Esquema de despliegue
Para una app full-stack típica:
- Hosting del backend: despliega un contenedor o servicio gestionado y ejecuta health checks.
- Migraciones de base de datos: versiona migraciones, ejecútalas durante el deploy y hazlas reversibles cuando sea posible.
- Releases móviles: publica builds internos primero (TestFlight / pruebas internas), luego rollout por fases en App Store/Play Store.
Monitorización y flujo de incidencias
Planifica tres señales:
- Logs (qué pasó), métricas (con qué frecuencia) y alertas (qué requiere atención ahora).
- Regla de on-call ligera: las alertas deben ser accionables, no ruidosas.
- Un camino visible para que los usuarios reporten problemas (link in-app o /support), alimentando una cola de triage con severidad, pasos de reproducibilidad y un plan de rollback.
Aquí es donde el desarrollo asistido por IA se vuelve operativo: no solo generas código, sino que gestionas un producto.
Dónde fallan las salidas de los LLMs (y cómo arreglarlo)
Pasa de la idea al MVP
Redacta roles de usuario, recorridos y criterios de aceptación, y luego genera la primera versión de tu app.
Los LLMs pueden convertir una idea vaga en algo que parece un plan completo—pero la prosa pulida puede ocultar huecos. Los fallos más comunes son previsibles, y puedes prevenirlos con unos hábitos repetibles.
Por qué fallan los prompts
La mayoría de las salidas débiles se rastrea hasta cuatro problemas:
- Contexto faltante: el modelo no conoce tus usuarios, restricciones (presupuesto, cronograma, habilidades del equipo), necesidades de cumplimiento o lo que ya existe.
- Requisitos en conflicto: “Hazlo simple” junto con “soporta todos los casos límite” produce especificaciones confusas.
- Suposiciones ocultas: el modelo puede asumir que el login es email/contraseña, que “tiempo real” significa WebSockets o que “admin” implica acceso total a datos.
- Prioridades no declaradas: sin trade-offs (velocidad vs coste vs calidad) obtendrás respuestas genéricas que no encajan en tu situación.
Cómo pedir mejores salidas
Dale al modelo material concreto:
- Ejemplos: “Como Calendly pero para servicios on-site” más 2–3 historias de usuario de muestra.
- Restricciones: “Debe usar Postgres, desplegar en AWS y soportar 10k MAU.”
- Forzar la visibilidad del razonamiento: pídele que liste suposiciones, preguntas abiertas y alternativas: “Muestra tu trabajo: decisiones + por qué.”
Añade una “Definición de Hecho” para reducir retrabajo
Pide checklists por entregable. Por ejemplo, los requisitos no están “hechos” hasta que incluyen criterios de aceptación, estados de error, roles/ permisos y métricas de éxito medibles.
Mantén una única fuente de verdad
Las salidas del LLM se desvían cuando las specs, notas de API e ideas de UI viven en hilos separados. Mantén un documento vivo (aunque sea un markdown simple) que enlace:
- la especificación de producto,
- el contrato de API (endpoints + esquemas),
- y notas de diseño (flujos clave y casos límite).
Cuando vuelvas a solicitar algo al LLM, pega el último extracto y di: “Actualiza solo las secciones X e Y; deja todo lo demás sin cambios.”
Si implementas sobre la marcha, también ayuda usar un flujo que soporte iteración rápida sin perder trazabilidad. Por ejemplo, la función de “planning mode” de Koder.ai encaja bien: puedes bloquear la spec (suposiciones, preguntas abiertas, criterios de aceptación), generar el scaffolding web/móvil/backend desde un solo hilo de chat y confiar en snapshots/rollback si un cambio introduce regresiones. La exportación de código es especialmente útil cuando quieres que la arquitectura generada y tu repo se mantengan alineados.
Un recorrido práctico y puntos de revisión humana
Esto es cómo puede verse la “traducción por LLM” de extremo a extremo—más los puntos de control donde un humano debe frenar y tomar decisiones reales.
Un ejemplo corto: idea → pantallas, datos, APIs
Idea en lenguaje natural: “Un marketplace de cuidado de mascotas donde los dueños publican solicitudes, los cuidadores aplican y los pagos se liberan después del trabajo.”
Un LLM puede convertir esto en un primer borrador como:
- Pantallas: Sign up/login, Crear Solicitud, Detalle de Solicitud (con aplicantes), Aplicar a Solicitud, Chat in-app, Checkout, Finalización del Trabajo, Valoraciones, Admin (disputas).
- Modelo de datos: Users (rol: owner/sitter), PetProfiles, Requests (fechas, ubicación, estado), Applications, Messages, Payments, Reviews.
- APIs:
POST /requests,GET /requests/{id},POST /requests/{id}/apply,GET /requests/{id}/applications,POST /messages,POST /checkout/session,POST /jobs/{id}/complete,POST /reviews.
Eso es útil—pero no está “hecho”. Es una propuesta estructurada que necesita validación.
Dónde revisan los humanos (y por qué importa)
Decisiones de producto: ¿Qué hace válida una “aplicación”? ¿Puede un dueño invitar directamente a un cuidador? ¿Cuándo se considera una solicitud “completada”? Estas reglas afectan cada pantalla y API.
Revisión de seguridad y privacidad: Confirma acceso por roles (los dueños no pueden leer chats de otros dueños), protege los pagos y define retención de datos (p. ej., borrar chats tras X meses). Añade controles de abuso: límites de tasa, prevención de spam, logs de auditoría.
Compensaciones de rendimiento: Decide qué debe ser rápido y escalable (búsquedas/filtrado, chat). Esto influye en cacheo, paginación, índices y trabajos en background.
Bucle de iteración: feedback → requisitos → código
Después de un piloto, los usuarios podrían pedir “repetir una solicitud” o “cancelar con reembolso parcial”. Alimenta eso como requisitos actualizados, regenera o parchea los flujos afectados y vuelve a ejecutar pruebas y chequeos de seguridad.
Qué documentar para mantenibilidad
Captura el “por qué”, no solo el “qué”: reglas de negocio clave, matriz de permisos, contratos de API, códigos de error, migraciones de base de datos y un runbook corto para releases e incidentes. Esto es lo que mantiene el código generado entendible seis meses después.
Preguntas frecuentes
¿Qué significa “traducción” cuando se dice que un LLM puede traducir una idea a una app?
En este contexto, “traducción” significa convertir una idea difusa en decisiones específicas y comprobables: roles, recorridos de usuario, requisitos, datos, APIs y criterios de éxito.
No es solo parafrasear: es hacer explícitas las suposiciones para que puedas confirmarlas o rechazarlas antes de construir.
¿Qué resultados debería esperar que genere rápidamente un LLM para un producto nuevo?
Un primer borrador práctico incluye:
- Roles de usuario y recorridos principales
- Lista de funcionalidades con prioridades (imprescindible vs deseable)
- Historias de usuario con criterios de aceptación
- Inventario de pantallas + mapa de navegación (web y móvil)
- Modelo de datos (entidades, relaciones, restricciones)
- Esquema de API (endpoints, esquemas, errores)
Trátalo como un plano inicial que debes revisar, no como una especificación final.
¿Qué decisiones aún requieren intervención humana, incluso con buenas salidas del LLM?
Porque un LLM no puede conocer de forma fiable tus restricciones y compensaciones del mundo real sin que tú las declares. Los humanos deben seguir decidiendo:
- Qué significa “éxito” (métricas)
- Restricciones de presupuesto/tiempo y riesgos aceptables
- Qué casos límite importan ahora frente a después
- Cuál es el MVP más simple que guste a los usuarios
Usa el modelo para proponer opciones y luego elige deliberadamente.
¿Cómo escribo un brief de producto que un LLM pueda usar de verdad?
Dale contexto suficiente para diseñar contra él:
- Una frase que describa el problema + 2–3 métricas de éxito medibles
- 3–7 casos de uso del MVP (“Como [rol], quiero…”)
- Plataformas (web/iOS/Android), necesidades offline e integraciones
- Restricciones de cumplimiento/privacidad (p. ej., HIPAA/GDPR)
- Lista explícita de MVP vs características posteriores
Si no podrías darle esto a un compañero y obtener la misma interpretación, no está listo.
¿Cómo convierto ideas en lenguaje natural en requisitos sin obtener especificaciones vagas?
Céntrate en convertir objetivos en historias de usuario + criterios de aceptación.
Un paquete sólido normalmente incluye:
- Historias de usuario agrupadas por funcionalidades
- Etiquetas de prioridad (must-have/nice-to-have)
- Criterios de aceptación escritos como “Dado/Cuando/Entonces”
- Casos límite explícitos (cancelaciones, reintentos, duplicados, reembolsos)
Esto se convierte en tu “fuente de verdad” para UI, APIs y pruebas.
¿Cuál es la mejor manera de usar un LLM para flujos de UI sin obtener diseños “bonitos pero inútiles”?
Pide dos entregables:
- Inventario de pantallas (todas las pantallas que hay que construir)
- Mapa de navegación (cómo se mueven los usuarios entre pantallas)
Luego verifica:
- Cada recorrido principal puede completarse de extremo a extremo
- Existen estados vacíos y estados de error
- Los patrones web vs móvil tienen sentido (sidebar/top nav vs pestañas/stack)
- Los formularios tienen reglas de validación y errores amigables
Estás diseñando comportamiento, no apariencia.
¿Debo empezar con un monolito, un monolito modular o microservicios?
Para la mayoría de los productos v1, empieza con un monolito o un monolito modular.
Cuestiona al modelo si propone microservicios: pide razones concretas (tráfico, necesidad de despliegues independientes, partes que escalan distinto). Prefiere “salidas de emergencia” en lugar de una arquitectura compleja desde el inicio:
- Cola de trabajos en background
- Cacheo para lecturas frecuentes
- Servidores de aplicación stateless para escalado horizontal
Mantén v1 fácil de lanzar y de depurar.
¿Qué debo buscar en un modelo de datos generado por LLM para evitar reescrituras dolorosas más adelante?
Haz que el modelo deje claro:
- Entidades y relaciones (qué pertenece a qué)
- Propiedad y control de acceso (owner_user_id, membresías, roles)
- Restricciones (email único, campos obligatorios, enums de estado)
- Reglas de borrado (soft vs hard delete) y eventos de auditoría
- Aislamiento multi-tenant (tenant/organization + tenant_id donde sea necesario)
Las decisiones de datos afectan filtros de UI, notificaciones, reporting y seguridad.
¿Cómo evalúo si un diseño de API generado por LLM es usable en aplicaciones reales?
Exige consistencia y comportamiento apto para móviles:
- Ruta base versionada (p. ej.,
/api/v1/...) - Endpoints CRUD + búsqueda/filtro claros
- Formas de petición/respuesta estables con ejemplos
- Formato de error estándar cubriendo 400/401/403/404/409/429/500
- Claves de idempotencia para
POSTreintentados
Evita cambios incompatibles; añade campos opcionales y mantén una ventana de deprecación.
¿Cómo puedo usar LLMs para producir una estrategia de pruebas que no sea solo plantilla?
Usa el modelo para redactar un plan y luego compáralo con los criterios de aceptación:
- Tests unitarios para reglas de negocio y permisos
- Tests de integración para comportamiento API + BD
- Tests end-to-end para recorridos críticos
- Comprobaciones específicas móviles (offline, backgrounding, permisos)
Exige datos de prueba reales: zonas horarias, textos largos, casi-duplicados, redes inestables. Trata las pruebas generadas como punto de partida, no como el QA final.