10 ago 2025·8 min
Cómo los LLM manejan reglas empresariales y el razonamiento de flujos de trabajo
Aprende cómo los LLM interpretan reglas empresariales, rastrean el estado de flujos de trabajo y verifican decisiones usando prompts, herramientas, pruebas y revisión humana —no solo código.
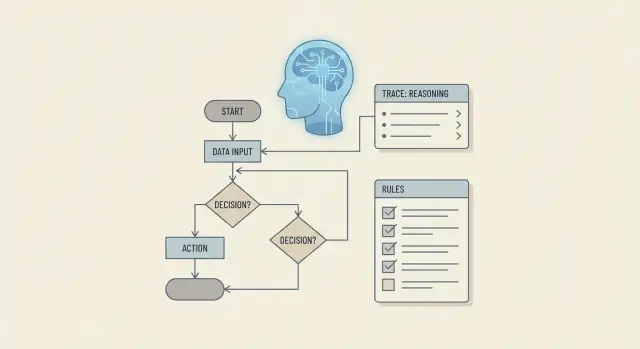
Por qué el razonamiento sobre reglas empresariales es más que generación de código
Cuando la gente pregunta si un LLM puede “razonar sobre reglas empresariales”, por lo general se refieren a algo más exigente que “¿puede escribir un if/else?”. El razonamiento sobre reglas empresariales es la capacidad de aplicar políticas de forma consistente, explicar decisiones, manejar excepciones y mantenerse alineado con el paso actual del flujo de trabajo —especialmente cuando las entradas son incompletas, desordenadas o cambian.
Razonamiento vs. emitir código
La generación de código trata sobre producir sintaxis válida en un lenguaje objetivo. El razonamiento sobre reglas trata sobre preservar la intención.
Un modelo puede generar código perfectamente válido que aun así produzca el resultado empresarial equivocado porque:
- El texto de la política es ambiguo (“cliente reciente”, “alto riesgo”, “documentación aprobada”).
- Las reglas entran en conflicto y la precedencia no está clara.
- No se enuncian los casos límite (reembolsos parciales, duplicados, fines de semana/feriados).
- El estado del flujo de trabajo cambia lo que debe ocurrir a continuación (ingreso vs. revisión vs. aprobación final).
En otras palabras, la corrección no es “¿compila?” sino “¿coincide con lo que el negocio decidiría, cada vez, y podemos demostrarlo?”.
Qué esperar de los LLM
Los LLM pueden ayudar a traducir políticas en reglas estructuradas, sugerir rutas de decisión y redactar explicaciones para humanos. Pero no saben automáticamente qué regla es la autorizada, qué fuente de datos es de confianza o en qué paso está el caso. Sin restricciones, pueden elegir con confianza una respuesta plausible en lugar de la gobernada.
Así que la meta no es “dejar que el modelo decida”, sino darle estructura y comprobaciones para que pueda asistir de forma fiable.
Qué hará el resto de este artículo
Un enfoque práctico se parece a una canalización:
- Convertir el texto de la política en representaciones de regla utilizables.
- Rastrear el estado del flujo de trabajo para que las decisiones sean consistentes entre pasos.
- Usar patrones de prompt para hacer cumplir prioridades, excepciones y explicaciones.
- Respaldar decisiones con herramientas y recuperación (usando solo datos aprobados).
- Restringir salidas con esquemas para reducir la ambigüedad.
- Validar, probar y monitorear para que los errores se detecten antes del despliegue.
Esa es la diferencia entre un fragmento de código ingenioso y un sistema que puede soportar decisiones empresariales reales.
Reglas empresariales y flujos de trabajo: un repaso sencillo en lenguaje llano
Antes de hablar de cómo un LLM maneja el “razonamiento”, conviene separar dos cosas que los equipos suelen mezclar: reglas empresariales y flujos de trabajo.
¿Qué son las reglas empresariales?
Reglas empresariales son las declaraciones de decisión que tu organización quiere aplicar de forma consistente. Aparecen como políticas y lógica como:
- Elegibilidad: ¿Quién califica para un beneficio, plan o funcionalidad?
- Precios: ¿Qué descuento aplica y cuándo?
- Aprobaciones: ¿Cuándo se necesita la revisión de un gerente?
- Cumplimiento: ¿Qué debe registrarse, redactarse o bloquearse?
Las reglas suelen formularse como “SI X, ENTONCES Y” (a veces con excepciones), y deberían producir un resultado claro: aprobar/denegar, precio A/precio B, solicitar más información, etc.
¿Qué son los flujos de trabajo?
Un flujo de trabajo es el proceso que mueve el trabajo del inicio al fin. Se trata menos de decidir qué está permitido y más de qué ocurre después. Los flujos de trabajo suelen incluir:
- Estados: enviado → en revisión → aprobado/denegado → completado
- Pasos y traspasos: atención al cliente → finanzas → cliente
- Eventos temporales: recordatorios, SLAs, cancelación automática después de 14 días
- Artefactos: formularios, adjuntos, códigos de motivo, notas de auditoría
Un pequeño ejemplo: solicitudes de reembolso
Imagina una solicitud de reembolso.
Fragmento de regla: “Los reembolsos están permitidos dentro de los 30 días de la compra. Excepción: las descargas digitales no son reembolsables una vez accedidas. Excepción: los contracargos deben escalarse.”
Fragmento de flujo de trabajo:
- El cliente envía la solicitud (estado: enviado).
- El sistema verifica la fecha de compra y el tipo de producto (estado: en revisión).
- Si es elegible, emitir reembolso y notificar al cliente (estado: completado).
- Si hay contracargo, derivar a finanzas para investigación (estado: escalado).
Por qué las reglas son más complejas de lo que parecen
Las reglas se complican cuando conflictan (“los clientes VIP siempre obtienen reembolso” vs. “las descargas digitales nunca”), dependen de contexto faltante (¿se accedió a la descarga?) o esconden casos límite (paquetes, reembolsos parciales, leyes regionales). Los flujos de trabajo añaden otra capa: las decisiones deben ser consistentes con el estado actual, acciones previas y plazos.
Cómo “razonan” los LLM: coincidencia de patrones con estructura útil
Los LLM no “entienden” las reglas empresariales como lo haría una persona. Generan la siguiente palabra más probable basada en patrones aprendidos de grandes cantidades de texto. Por eso un LLM puede sonar convincente incluso cuando está adivinando —o cuando completa silenciosamente detalles faltantes que no se proporcionaron.
Esa limitación importa para flujos de trabajo y lógica de decisión. Un modelo puede aplicar una regla que suena correcta (“los empleados siempre necesitan aprobación del gerente”) aunque la política real tenga excepciones (“solo por encima de $500” o “solo para contratistas”). Este es un modo de fallo común: aplicación confiada pero incorrecta de la regla.
Por qué siguen siendo útiles para reglas empresariales
Incluso sin una verdadera “comprensión”, los LLM son útiles si los tratas como asistentes estructurados:
- Resumir políticas largas en lenguaje más claro para revisión
- Mapear texto desordenado en campos consistentes (quién, qué, umbral, excepción, fecha de vigencia)
- Verificar una decisión propuesta contra las reglas declaradas (“¿qué cláusula respalda esto?”)
La clave es colocar al modelo en una posición donde no pueda desviarse fácilmente hacia la improvisación.
Restringir al modelo para que no divague
Una manera práctica de reducir la ambigüedad es la salida restringida: exigir que el LLM responda en un esquema o plantilla fija (por ejemplo, JSON con campos específicos, o una tabla con columnas obligatorias). Cuando el modelo debe completar rule_id, conditions, exceptions y decision, es más fácil detectar lagunas y validar la salida automáticamente.
Los formatos restringidos también hacen más evidente cuando el modelo no sabe algo. Si falta un campo obligatorio, puedes forzar una pregunta de seguimiento en lugar de aceptar una respuesta dudosa.
La conclusión: el “razonamiento” de los LLM es mejor verlo como generación basada en patrones guiada por estructura —útil para organizar y cotejar reglas, pero arriesgado si lo tratas como un decisor infalible.
Convertir texto de políticas desordenado en representaciones de reglas utilizables
Los documentos de política están escritos para humanos: mezclan objetivos, excepciones y “sentido común” en el mismo párrafo. Un LLM puede resumir ese texto, pero seguirá las reglas más confiablemente cuando conviertas la política en entradas explícitas y verificables.
Cómo son las reglas “utilizables"
Las buenas representaciones de regla comparten dos rasgos: no son ambiguas y se pueden comprobar.
Escribe reglas como afirmaciones que puedas probar:
- IF/THEN para decisiones (elegibilidad, enrutamiento, aprobaciones)
- MUST / MUST NOT para restricciones rígidas
- MAY para opciones permitidas (a menudo necesitan un criterio de desempate)
Las reglas pueden proporcionarse al modelo en varias formas:
- Viñetas en lenguaje natural (más rápido, aún estructurado)
- Una tabla (ideal para políticas basadas en umbrales)
- YAML/JSON (mejor cuando también quieres salidas restringidas y validación automática)
Manejar conflictos y prioridades
Las políticas reales entran en conflicto. Cuando dos reglas discrepan, el modelo necesita un esquema de prioridad claro. Enfoques comunes:
- Lo específico vence a lo general (una excepción anula el valor por defecto)
- La autoridad superior gana (legal/cumplimiento sobre preferencia de equipo)
- El más reciente gana (la versión más nueva anula la anterior)
- Números de prioridad explícitos (lo más confiable)
Explica la regla de resolución de conflictos directamente, o encódala (por ejemplo, priority: 100). De lo contrario, el LLM puede “promediar” las reglas.
Ejemplo: convertir un párrafo en una lista de reglas
Texto de política original:
“Los reembolsos están disponibles dentro de los 30 días para planes anuales. Los planes mensuales no son reembolsables después de 7 días. Si la cuenta muestra fraude o contracargos excesivos, no emita reembolso. Los clientes Enterprise necesitan aprobación de Finanzas para reembolsos superiores a $5,000.”
Reglas estructuradas (YAML):
rules:
- id: R1
statement: "IF plan_type = annual AND days_since_purchase <= 30 THEN refund MAY be issued"
priority: 10
- id: R2
statement: "IF plan_type = monthly AND days_since_purchase > 7 THEN refund MUST NOT be issued"
priority: 20
- id: R3
statement: "IF fraud_flag = true OR chargeback_rate = excessive THEN refund MUST NOT be issued"
priority: 100
- id: R4
statement: "IF customer_tier = enterprise AND refund_amount > 5000 THEN finance_approval MUST be obtained"
priority: 50
conflict_resolution: "Higher priority wins; MUST NOT overrides MAY"
Ahora el modelo no está adivinando qué importa: está aplicando un conjunto de reglas que puedes revisar, probar y versionar.
Rastrear el estado del flujo de trabajo para que el modelo se mantenga consistente
Un flujo de trabajo no es solo un conjunto de reglas; es una secuencia de eventos donde pasos anteriores cambian lo que debe ocurrir después. Esa “memoria” es el estado: los hechos actuales sobre el caso (quién envió qué, qué está aprobado, qué está pendiente y qué plazos aplican). Si no rastreas el estado explícitamente, los flujos se rompen de maneras previsibles: aprobaciones duplicadas, omisión de verificaciones requeridas, invertir decisiones o aplicar la política equivocada porque el modelo no puede inferir con fiabilidad lo que ya ocurrió.
Qué significa “estado” en lenguaje llano
Piensa en el estado como el marcador del flujo de trabajo. Responde: ¿Dónde estamos ahora? ¿Qué se ha hecho? ¿Qué está permitido a continuación? Para un LLM, tener un resumen claro del estado evita que vuelva a litigar pasos previos o que haga suposiciones.
Cómo pasar el estado al modelo
Cuando llamas al modelo, incluye una carga útil de estado compacta junto con la solicitud del usuario. Los campos útiles son:
- Nombre y estado del paso (p. ej.,
manager_review: approved,finance_review: pending) - IDs estables (request ID, employee ID) para que el modelo no confunda casos
- Marcas temporales (submitted at, last updated) para resolver situaciones de “el más reciente gana”
- Flags (excepciones de política, documentos faltantes, escalamiento requerido)
Evita volcar todo el historial de mensajes. En su lugar, proporciona el estado actual más una breve pista de auditoría con las transiciones clave.
Mantén una única fuente de verdad
Trata el motor de flujo de trabajo (base de datos, sistema de tickets u orquestador) como la fuente única de verdad. El LLM debe leer el estado desde ese sistema y proponer la siguiente acción, pero el sistema debe ser la autoridad que registre las transiciones. Esto reduce la “deriva de estado”, donde la narración del modelo diverge de la realidad.
Ejemplo: instantánea de estado en un flujo de aprobación
{
"request_id": "TRV-10482",
"workflow": "travel_reimbursement_v3",
"current_step": "finance_review",
"step_status": {
"submission": "complete",
"manager_review": "approved",
"finance_review": "pending",
"payment": "not_started"
},
"actors": {
"employee_id": "E-2291",
"manager_id": "M-104",
"finance_queue": "FIN-AP"
},
"amount": 842.15,
"currency": "USD",
"submitted_at": "2025-12-12T14:03:22Z",
"last_state_update": "2025-12-13T09:18:05Z",
"flags": {
"receipt_missing": false,
"policy_exception_requested": true,
"needs_escalation": false
}
}
Con una instantánea así, el modelo puede mantenerse consistente: no pedirá la aprobación del gerente otra vez, se enfocará en las comprobaciones de finanzas y podrá explicar decisiones en términos de los flags y el paso actual.
Patrones de prompt que mejoran el seguimiento de reglas y las decisiones
Revertir con confianza
Protege las versiones con instantáneas y revierte cuando cambien reglas o indicaciones.
Un buen prompt no solo pide una respuesta: establece expectativas sobre cómo debe aplicar el modelo tus reglas y cómo debe informar el resultado. El objetivo son decisiones repetibles, no prosa ingeniosa.
1) Prompt por rol: asigna un trabajo, no un estado de ánimo
Da al modelo un rol concreto ligado a tu proceso. Tres roles que funcionan bien juntos:
- Analista de políticas: interpreta el texto de la regla y lo mapea al caso actual.
- Validador: comprueba la decisión contra los requisitos y señala entradas faltantes.
- Agente: toma la siguiente acción del flujo de trabajo (crear ticket, redactar correo, cambiar estado).
Puedes ejecutarlos secuencialmente (“analista → validador → agente”) o pedir las tres salidas en una única respuesta estructurada.
2) Instrucciones paso a paso (sin pedir razonamiento oculto)
En lugar de solicitar “cadena de pensamiento”, especifica pasos y artefactos visibles:
- Identificar reglas relevantes.
- Extraer las entradas necesarias del caso.
- Aplicar las reglas en orden de prioridad.
- Producir una decisión y el siguiente paso.
Esto mantiene al modelo organizado y enfocado en entregables: qué reglas se usaron y qué comportamiento sigue.
3) Pide una motivación estructurada: IDs de regla + evidencia
Las explicaciones libres se desvían. Exige una justificación compacta que apunte a fuentes:
- IDs de regla usados (p. ej., R-12, R-18)
- Evidencia (fragmentos citados de la política y campos específicos del caso)
- Supuestos (solo si falta una entrada)
Eso acelera las revisiones y te ayuda a depurar desacuerdos.
4) Patrón de checklist: entradas, decisión, excepciones, siguiente paso
Usa una plantilla fija cada vez:
- Entradas recibidas: …
- Entradas faltantes: …
- Decisión: aprobar/denegar/necesita-revisión
- Referencias de regla: [R-…]
- Excepciones consideradas: …
- Siguiente paso del flujo: actualizar estado / solicitar info / escalar
La plantilla reduce la ambigüedad y empuja al modelo a exponer vacíos antes de comprometerse con una acción incorrecta.
Usar herramientas y recuperación para anclar decisiones en datos reales
Un LLM puede redactar una respuesta convincente incluso cuando le faltan hechos clave. Eso es útil para borradores, pero arriesgado para decisiones empresariales. Si el modelo tiene que adivinar el estado de una cuenta, el nivel del cliente, una tasa fiscal regional o si se alcanzó un límite, obtendrás errores con apariencia confiada.
Las herramientas resuelven eso al convertir el “razonamiento” en un proceso de dos pasos: recuperar evidencia primero, decidir después.
Herramientas comunes que mantienen al modelo honesto
En sistemas centrados en reglas y flujos de trabajo, unas pocas herramientas simples hacen la mayor parte del trabajo:
- Consulta a base de datos (perfil del cliente, estado de la cuenta, derechos, totales de uso)
- Almacén de políticas/reglas (texto de regla aprobado, procedimientos versionados, listas de excepciones)
- Calculadora (tarifas, prorrateos, impuestos, ventanas temporales, umbrales)
- API de tickets/flujo (casos abiertos, temporizadores SLA, aprobaciones, finalización de pasos)
La clave es que el modelo no está “inventando” hechos operativos: solicita los hechos.
Recuperación: trae solo las reglas que importan
Aunque guardes todas las políticas en un repositorio central, rara vez quieres pegar todo en el prompt. La recuperación ayuda seleccionando solo los fragmentos más relevantes para el caso actual —por ejemplo:
- La política de cancelación para el plan del cliente
- La cláusula de cumplimiento regional según país/estado
- La regla de excepción que aplica cuando hay un contracargo pendiente
Esto reduce contradicciones y evita que el modelo siga una regla desactualizada solo porque apareció antes en el contexto.
Convertir salidas de herramientas en evidencia para la decisión
Un patrón fiable es tratar los resultados de herramientas como evidencia que el modelo debe citar en su decisión. Por ejemplo:
- Herramienta:
get_account(account_id)→status="past_due",plan="Business",usage_this_month=12000 - Herramienta:
retrieve_policies(query="overage fee Business plan")→ devuelve la regla: “Overage fee applies above 10,000 units at $0.02/unit.” - Herramienta:
calculate_overage(usage=12000, threshold=10000, rate=0.02)→$40.00
Ahora la decisión no es una conjetura: es una conclusión anclada a entradas específicas (“past_due”, “12,000 units”, “$0.02/unit”). Si más tarde auditas el resultado, puedes ver exactamente qué hechos y qué versión de la regla se usaron —y corregir la parte adecuada cuando algo cambie.
Salidas restringidas: esquemas que reducen la ambigüedad
Diseña el flujo primero
Usa el modo planificación para mapear estados, prioridades y rutas de escalada antes de ejecutar.
El texto libre es flexible, pero también la forma más fácil de que un flujo de trabajo falle. Un modelo puede dar una respuesta “razonable” que no se puede automatizar (“me parece bien”) o ser inconsistente entre pasos (“approve” vs. “approved”). Las salidas restringidas obligan cada decisión a tener una forma predecible.
Devolver decisiones como JSON
Un patrón práctico es exigir que el modelo responda con un único objeto JSON que tu sistema pueda parsear y enrutar:
{
"decision": "needs_review",
"reasons": [
"Applicant provided proof of income, but the document is expired"
],
"next_action": "request_updated_document",
"missing_info": [
"Income statement dated within the last 90 days"
],
"assumptions": [
"Applicant name matches across documents"
]
}
Esta estructura hace que la salida sea útil incluso cuando el modelo no puede decidir del todo. missing_info y assumptions convierten la incertidumbre en seguimientos accionables, en lugar de suposiciones ocultas.
Usar enumeraciones para limitar resultados
Para reducir la variabilidad, define valores permitidos (enums) para campos clave. Por ejemplo:
decision:approved|denied|needs_reviewnext_action:approve_case|deny_case|request_more_info|escalate_to_human
Con enums, los sistemas posteriores no necesitan interpretar sinónimos, puntuación o tono. Simplemente bifurcan según valores conocidos.
Por qué los esquemas hacen los flujos más seguros
Los esquemas funcionan como barandillas. Ellos:
- Evitan “respuestas parciales” al requerir campos obligatorios.
- Hacen más fácil auditar por qué ocurrió una decisión (vía
reasons). - Habilitan la automatización fiable: colas, notificaciones y creación de tareas pueden dispararse directamente desde
decisionynext_action. - Soportan validación: puedes rechazar salidas que no coincidan con el esquema y pedir al modelo que lo intente de nuevo.
El resultado es menos ambigüedad, menos fallos en casos límite y decisiones que pueden avanzar consistentemente por un flujo de trabajo.
Estrategias de validación: atrapar errores antes del despliegue
Incluso un modelo bien promptado puede “sonar bien” mientras viola una regla, omite un paso obligatorio o inventa un valor. La validación es la red de seguridad que convierte una respuesta plausible en una decisión confiable.
Precontroles: validar entradas antes de razonar
Empieza verificando que tienes la información mínima necesaria para aplicar las reglas. Los precontroles deben ejecutarse antes de que el modelo tome cualquier decisión.
Los precontroles típicos incluyen campos obligatorios (p. ej., tipo de cliente, total del pedido, región), formatos básicos (fechas, IDs, moneda) y rangos permitidos (montos no negativos, porcentajes hasta 100%). Si algo falla, devuelve un error claro y accionable (“Falta ‘region’; no se puede elegir conjunto de reglas fiscales”) en lugar de permitir que el modelo adivine.
Post-checks: validar la decisión contra las reglas
Después de que el modelo produzca un resultado, valida que sea consistente con tu conjunto de reglas.
Concéntrate en:
- Cobertura de regla: ¿La decisión citó o mapeó a las reglas aplicables, o ignoró una política obligatoria?
- Comprobaciones de contradicción: ¿La salida entra en conflicto con las entradas declaradas (p. ej., “approved” mientras una condición de bloqueo rígida es verdadera)?
- Casos límite: Prueba bordes como umbrales (exactamente $10,000), estados vacíos (“sin violaciones previas”) y escenarios “apenas por encima”.
Validación de segundo pase: un paso deliberado de revisión
Añade un “segundo pase” que reevalúe la primera respuesta. Puede ser otra llamada al modelo o el mismo modelo con un prompt de validador que solo compruebe el cumplimiento, no la creatividad.
Un patrón simple: el primer pase produce una decisión + justificación; el segundo pase devuelve valid o una lista estructurada de fallos (campos faltantes, restricciones violadas, interpretación ambigua de la regla).
Registro: haz las decisiones auditables
Para cada decisión, registra las entradas usadas, la versión de la regla/política y los resultados de validación (incluidos los hallazgos del segundo pase). Cuando algo falla, esto te permite reproducir las condiciones exactas, corregir el mapeo de reglas y confirmar la corrección —sin adivinar qué “debió” haber querido decir el modelo.
Pruebas y monitoreo para la fiabilidad de reglas y flujos
Probar funciones de LLM centradas en reglas y flujos es menos sobre “¿generó algo?” y más sobre “¿tomó la misma decisión que un humano cuidadoso, por la razón correcta, cada vez?”. La buena noticia: puedes probarlo con la misma disciplina que usarías para la lógica de decisión tradicional.
Pruebas unitarias para reglas empresariales (chequeos pequeños y previsibles)
Trata cada regla como una función: dadas entradas, debe devolver un resultado que puedas afirmar.
Por ejemplo, si tienes una regla de reembolso como “los reembolsos están permitidos dentro de 30 días para artículos sin abrir”, escribe casos enfocados con resultados esperados:
- Edad del pedido = 10 días, sin abrir = true → aprobar
- Edad del pedido = 10 días, sin abrir = false → denegar
- Edad del pedido = 45 días, sin abrir = true → denegar
- Casos límite: exactamente 30 días, campo “sin abrir” faltante, señales conflictivas
Estas pruebas unitarias atrapan errores de límite, campos faltantes y el comportamiento “útil” del modelo donde intenta rellenar desconocidos.
Pruebas de escenario para flujos (rutas multi-paso con conciencia temporal)
Los flujos fallan cuando el estado se vuelve inconsistente entre pasos. Las pruebas de escenario simulan trayectorias reales:
- Pruebas de ruta: enviar reclamo → solicitar documentos → documentos recibidos → decisión
- Bordes temporales: “si no responde en 7 días, enviar recordatorio”, “si pasan 30 días, cerrar caso”
- Bifurcaciones: cliente escala, se solicita excepción de política, se detecta caso duplicado
El objetivo es verificar que el modelo respete el estado actual y solo tome transiciones permitidas.
Construir un “gold set” de casos correctos
Crea un conjunto curado de ejemplos reales anonimados con resultados acordados (y breves racionales). Mantenlo versionado y revísalo cada vez que cambie la política. Un pequeño gold set (incluso 100–500 casos) es poderoso porque refleja la realidad desordenada: datos faltantes, redacción inusual, decisiones en el límite.
Monitoreo en producción (detectar deriva antes que los clientes)
Monitorea distribuciones de decisiones y señales de calidad a lo largo del tiempo:
- Deriva: tasas de aprobación/denegación cambiando sin una actualización de política
- Picos en needs_review o en derivaciones a humanos (a menudo un problema de prompt, recuperación o datos upstream)
- Agrupaciones de errores por producto, región o categoría de política
Combina el monitoreo con rollback seguro: conserva un paquete de prompts/reglas anterior, feature-flaggea nuevas versiones y está listo para revertir rápidamente cuando las métricas empeoren. Para guiones operativos y puertas de liberación, ver /blog/validation-strategies.
Dónde encaja Koder.ai en esta canalización
Despliega e itera rápidamente
Lanza tu asistente de flujo de trabajo con despliegue y hosting en un solo lugar.
Si implementas los patrones anteriores, normalmente terminarás construyendo un pequeño sistema alrededor del modelo: almacenamiento de estado, llamadas a herramientas, recuperación, validación de esquemas y un orquestador de flujo. Koder.ai es una forma práctica de prototipar y lanzar ese tipo de asistente respaldado por flujo más rápido: puedes describir el flujo en chat, generar una app web funcional (React) más servicios backend (Go con PostgreSQL) e iterar con seguridad usando snapshots y rollback.
Esto importa para el razonamiento sobre reglas empresariales porque las “barandillas” a menudo viven en la aplicación, no en el prompt:
- Modo planificación te ayuda a diseñar el flujo (estados, transiciones permitidas, rutas de escalamiento) antes de ejecutar.
- Respuestas con esquemas pueden imponerse en el límite del API, de modo que solo aceptes decisiones parseables.
- Ganchos de herramientas (lecturas a BD, recuperación de política, calculadoras, actualizaciones de tickets) pueden implementarse como endpoints explícitos, haciendo que “recuperar evidencia primero, decidir después” sea el comportamiento por defecto.
- Exportación de código fuente evita que te quedes atado una vez que el prototipo se vuelve crítico en producción.
Límites, uso seguro y cuándo mantener a un humano en el circuito
Los LLM pueden ser sorprendentemente buenos aplicando políticas cotidianas, pero no son lo mismo que un motor de reglas determinista. Trátalos como asistentes de decisión que necesitan barandillas, no como la autoridad final.
Dónde suelen fallar los LLM
Tres modos de fallo aparecen con frecuencia en flujos pesados en reglas:
- Excepciones raras y casos límite: si una excepción ocurre una vez al año, puede estar poco representada en los datos de entrenamiento y ser fácil de pasar por alto a menos que se provea explícitamente en el prompt o se recupere de los documentos de política.
- Contextos largos y restricciones “enterradas”: cuando detalles clave están dispersos en muchas páginas o mensajes, el modelo puede dar más peso al texto más reciente o más vívido y subaplicar restricciones anteriores.
- Precisión numérica y cálculos estrictos: totales, prorrateos, umbrales y reglas de redondeo pueden desviarse. Usa herramientas para las matemáticas y exige que el modelo cite los números exactos que usó.
Cuándo exigir revisión humana
Añade revisión obligatoria cuando:
- El resultado es de alto riesgo (movimiento de dinero, cumplimiento, seguridad, compromisos legales, crédito/eligibilidad del cliente).
- El modelo indica baja confianza (pide adivinar entradas faltantes, no encuentra base en la política o produce razonamientos contradictorios).
- El caso es novo (producto nuevo, región nueva, política cambiada recientemente) o extraordinariamente sensible.
Rutas de escalamiento que mantienen el flujo
En lugar de dejar que el modelo “invente” algo, define pasos claros:
- Hacer preguntas aclaratorias (fechas faltantes, nivel de cliente, jurisdicción, estado de aprobación).
- Derivar a un agente con los hechos extraídos, la decisión propuesta y las citas.
- Crear un ticket cuando la política sea ambigua o conflictiva, para que se corrija en la fuente (y luego pueda recuperarse automáticamente).
Un marco de adopción simple
Usa LLM en flujos con reglas cuando puedas responder “sí” a la mayoría de esto:
- ¿Podemos anclar decisiones en texto de política aprobado o datos del sistema?
- ¿Podemos restringir salidas (esquema, acciones permitidas, citas obligatorias)?
- ¿Podemos validar (chequeos, umbrales, pruebas unitarias, muestreo) antes de ejecutar?
- ¿Tenemos una ruta de escalamiento humano para casos riesgosos o inciertos?
Si no, mantiene al LLM en un rol de borrador/asistente hasta que existan esos controles.