19 dic 2025·8 min
Cómo MySQL escaló la web temprana — y aún funciona a gran escala
Cómo MySQL pasó de sitios LAMP tempranos a producción de alto volumen: decisiones de diseño clave, InnoDB, replicación, sharding y patrones prácticos de escalado.
Por qué MySQL se convirtió en una base para la web temprana
MySQL se convirtió en la base de datos preferida de la web temprana por una razón simple: encajaba con lo que los sitios necesitaban entonces—almacenar y recuperar datos estructurados con rapidez, funcionar en hardware modesto y ser fácil de operar para equipos pequeños.
Era accesible. Podías instalarlo rápido, conectarlo desde lenguajes de programación comunes y poner un sitio en marcha sin contratar a un administrador de bases de datos dedicado. Esa mezcla de “rendimiento suficiente” y bajo coste operativo lo convirtió en la opción por defecto para startups, proyectos personales y negocios en crecimiento.
Qué significa “escalar” en este contexto
Cuando la gente dice que MySQL “escaló”, suelen referirse a una mezcla de:
- Crecimiento de tráfico: más usuarios concurrentes y más consultas por segundo.
- Crecimiento de datos: tablas que pasan de miles de filas a millones o miles de millones.
- Expectativas de fiabilidad: permanecer en línea ante caídas, despliegues y fallos de hardware.
- Restricciones de coste: lograr lo anterior sin presupuestos empresariales exclusivos.
Las empresas de la web temprana no solo necesitaban velocidad; necesitaban rendimiento predecible y tiempo de actividad manteniendo el gasto en infraestructura bajo control.
Las palancas centrales que volveremos a ver
La historia de escalado de MySQL es, en realidad, una historia de compensaciones prácticas y patrones repetibles:
- Diseño de esquemas y consultas (qué almacenas, cómo haces joins, qué evitas)
- Índices (la diferencia entre “funciona en dev” y “funciona en producción”)
- Caché (no golpear la base de datos por cada vista de página)
- Replicación y réplicas de lectura (repartir tráfico de lectura)
- Sharding/particionado (dividir datos cuando una sola DB no da abasto)
Alcance de este artículo
Este es un recorrido por los patrones que los equipos usaron para mantener MySQL funcionando con tráfico web real—no un manual completo de MySQL. El objetivo es explicar cómo la base de datos encajó con las necesidades de la web y por qué las mismas ideas aparecen hoy en sistemas de producción masivos.
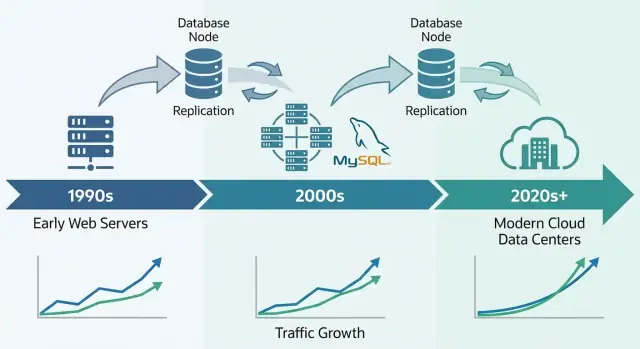
La era LAMP: cómo la simplicidad ayudó a MySQL a difundirse
El momento decisivo de MySQL estuvo ligado al auge del hosting compartido y de equipos pequeños que construían apps web rápidamente. No solo era que MySQL fuera “suficientemente bueno”—encajaba con cómo se desplegaba, gestionaba y pagaba la web temprana.
Por qué LAMP encajaba con el hosting temprano
LAMP (Linux, Apache, MySQL, PHP/Perl/Python) funcionaba porque se alineaba con el servidor por defecto que la mayoría podía pagar: una sola máquina Linux ejecutando un servidor web y una base de datos lado a lado.
Los proveedores de hosting podían plantillar esta configuración, automatizar instalaciones y ofrecerla barato. Los desarrolladores podían asumir el mismo entorno base casi en cualquier parte, reduciendo sorpresas al mover de desarrollo local a producción.
La simplicidad como estrategia de distribución
MySQL era sencillo de instalar, arrancar y conectar. Hablaba SQL familiar, tenía un cliente de línea de comandos simple e integraba bien con los lenguajes y frameworks populares de la época.
Igualmente importante, el modelo operativo era accesible: un proceso principal, un puñado de archivos de configuración y modos de fallo claros. Eso lo hizo realista para sysadmins generalistas (y a menudo desarrolladores) ejecutar una base de datos sin formación especializada.
Coste, accesibilidad y momentum comunitario
Ser open-source eliminó la fricción de licencias iniciales. Un proyecto estudiantil, un foro de hobby y un sitio de pequeña empresa podían usar el mismo motor de base de datos que compañías más grandes.
La documentación, las listas de correo y más adelante los tutoriales en línea crearon momentum: más usuarios significaron más ejemplos, más herramientas y resolución de problemas más rápida.
Las cargas tempranas que MySQL atendía bien
La mayoría de los primeros sitios eran orientados a lectura y bastante simples: foros, blogs, páginas impulsadas por CMS y pequeños catálogos e-commerce. Estas apps necesitaban búsquedas rápidas por ID, posts recientes, cuentas de usuario y filtrados básicos—exactamente el tipo de carga que MySQL podía manejar con eficiencia en hardware modesto.
Presiones iniciales de escalado: más usuarios, más lecturas, más escrituras
Las implantaciones tempranas de MySQL a menudo empezaban como “un servidor, una base de datos, una app.” Eso funcionaba para un foro de hobby o un sitio pequeño—hasta que la app se popularizaba. Las vistas de página se convirtieron en sesiones, las sesiones en tráfico constante, y la base de datos dejó de ser un componente silencioso.
Por qué las lecturas normalmente dominaban
La mayoría de las apps web eran (y siguen siendo) orientadas a lectura. Una página principal, una lista de productos o un perfil puede verse miles de veces por cada actualización. Ese desequilibrio moldeó las decisiones de escalado temprano: si podías hacer las lecturas más rápidas—o evitar golpear la base de datos para lecturas—podías servir a muchos más usuarios sin reescribir todo.
El problema: incluso las apps orientadas a lectura tienen escrituras críticas. Registros, compras, comentarios y actualizaciones administrativas no se pueden perder. A medida que el tráfico crece, el sistema debe manejar tanto una avalancha de lecturas como las escrituras que deben tener éxito.
Los primeros puntos de dolor que sentían los equipos
A mayor tráfico, los problemas se volvieron visibles en términos simples:
- Consultas lentas: una página que antes cargaba instantáneamente ahora “se colgaba” cuando una consulta de tipo informe escaneaba demasiadas filas.
- Bloqueos en tablas: en algunas configuraciones antiguas, las escrituras podían bloquear lecturas (y viceversa), creando atascos.
- RAM limitada: índices y datos calientes no cabían en memoria, así que el servidor accedía más al disco—mucho más lento que la RAM.
Separar responsabilidades desde el principio
Los equipos aprendieron a dividir responsabilidades: la app maneja la lógica de negocio, un cache absorbe lecturas repetidas y la base de datos se centra en almacenamiento preciso y consultas esenciales. Ese modelo mental preparó el camino para pasos posteriores como afinado de consultas, mejores índices y escala con réplicas.
Motores de almacenamiento: el gran punto de inflexión para la fiabilidad
Una cosa única de MySQL es que no es “un único motor” por debajo. Es un servidor de base de datos que puede almacenar y recuperar datos usando diferentes motores de almacenamiento.
Qué es realmente un motor de almacenamiento
A alto nivel, un motor de almacenamiento es la parte que decide cómo se escriben las filas en disco, cómo se mantienen los índices, cómo funcionan los locks y qué ocurre tras un fallo. Tu SQL puede lucir idéntica, pero el motor determina si la DB se comporta más como un cuaderno rápido o como un libro mayor bancario.
MyISAM vs InnoDB (diferencias en lenguaje llano)
Durante mucho tiempo, muchas instalaciones de MySQL usaban MyISAM. Era simple y a menudo rápido para sitios orientados a lectura, pero tenía compromisos:
- Bloqueos: MyISAM usa comúnmente locks a nivel de tabla. Una escritura puede bloquear otras lecturas/escrituras más de lo esperado.
- Caídas: tras un cierre no limpio, las tablas MyISAM podían requerir reparación y podrían perder cambios recientes.
- Transacciones: MyISAM no soporta transacciones, así que no se puede garantizar que una operación de varios pasos “todo tenga éxito o todo falle”.
InnoDB invierte esas suposiciones:
- Bloqueos: locking a nivel de fila reduce el bloqueo cuando muchos usuarios actualizan filas distintas.
- Recuperación tras fallos: mejor durabilidad y recuperación automática después de fallos.
- Transacciones: soporte completo de transacciones, haciendo el comportamiento de la app mucho más predecible.
Por qué InnoDB se convirtió en el estándar para producción
A medida que las apps web pasaron de leer principalmente páginas a manejar logins, carritos, pagos y mensajería, la corrección y la recuperación importaron tanto como la velocidad. InnoDB hizo realista escalar sin temer que un reinicio o un pico de tráfico corrompiera datos o paralizara toda la tabla.
La lección práctica: la elección del motor afecta rendimiento y seguridad. No es un simple checkbox: tu modelo de locking, comportamiento ante fallos y garantías de la app dependen de ello.
Índices y diseño de consultas: el primer multiplicador de escalado
Antes de shardear, añadir réplicas o caching elaborado, muchas mejoras tempranas en MySQL vinieron de un cambio consistente: hacer las consultas predecibles. Índices y diseño de consultas fueron el primer “multiplicador” porque redujeron cuánto tenía que leer MySQL por petición.
Índices B-tree: búsquedas rápidas vs escaneos de tabla completa
La mayoría de los índices de MySQL usan B-tree. Piénsalos como un directorio ordenado: MySQL puede saltar al lugar correcto y leer un pequeño bloque de datos contiguo. Sin el índice adecuado, el servidor a menudo recurre a escanear filas una por una. A bajo tráfico eso es solo lento; a escala se convierte en un amplificador de carga—más CPU, más I/O de disco, más tiempo de lock y mayor latencia para todo.
Anti-patrones de consultas que perjudican a escala
Algunos patrones provocaban repetidamente fallos de “funcionaba en staging”:
SELECT *: trae columnas innecesarias, aumenta I/O y puede impedir beneficios de índices cubrientes.- Wildcards al inicio:
WHERE name LIKE '%shoe'no puede usar eficazmente un índice B-tree normal. - Funciones sobre columnas indexadas:
WHERE DATE(created_at) = '2025-01-01'suele impedir el uso del índice; prefiere filtros por rango comocreated_at >= ... AND created_at < ....
Convertir EXPLAIN y los logs lentos en herramientas diarias
Dos hábitos escalan mejor que cualquier truco elegante:
- Ejecutar
EXPLAINpara verificar que estás usando el índice previsto y no escaneando. - Vigilar el log de consultas lentas para detectar regresiones cuando se envían nuevas funciones, no semanas después.
Los índices deben mapear a funciones reales
Diseña índices según cómo se comporta el producto:
- Búsqueda: considera full-text o estrategias por prefijo en lugar de escaneos con wildcard.
- Feeds: índices compuestos como
(user_id, created_at)hacen rápidas las “últimas entradas”. - Flujos de checkout: índices únicos en identificadores de orden/pago previenen duplicados y aceleran búsquedas.
Un buen índice no es “más índices”. Son los correctos que coinciden con las rutas de lectura/escritura críticas.
Escalado vertical vs horizontal: qué cambia y por qué
Planifica el esquema antes de construir
Usa Planning Mode para mapear entidades, índices y supuestos de crecimiento en lenguaje sencillo.
Cuando un producto respaldado por MySQL empieza a ralentizarse, la gran decisión es si escalar verticalmente (up) o horizontalmente (out). Resuelven distintos problemas—y cambian tu vida operativa de maneras muy diferentes.
Escalado vertical: la movida de “caja más grande”
Escalar verticalmente significa dar más recursos al servidor MySQL: CPU más rápida, más RAM, mejor almacenamiento.
Esto suele funcionar sorprendentemente bien porque muchos cuellos de botella son locales:
- CPU: consultas complejas, ordenados, joins y WHERE ineficientes pueden saturar los cores.
- I/O: discos lentos y lecturas/escrituras aleatorias dominan cuando los datos no caben en memoria.
- Buffer pool / memoria: con InnoDB, más RAM mantiene datos e índices calientes en caché, reduciendo accesos a disco.
- Límites de conexiones: demasiadas conexiones concurrentes pueden saturar hilos, memoria y cambios de contexto.
Escalar verticalmente es normalmente la victoria más rápida: menos piezas en movimiento, modos de fallo más simples y menos cambios en la app. La desventaja es que siempre hay un techo (y las actualizaciones pueden requerir tiempo de inactividad o migraciones riesgosas).
Escalado horizontal: “más cajas”, más coordinación
Escalar horizontalmente añade máquinas. Para MySQL, eso normalmente significa:
- Repartir lecturas entre réplicas
- Repartir escrituras dividiendo datos (sharding) o reestructurando flujos de trabajo
Es más difícil porque introduces problemas de coordinación: lag de replicación, comportamiento de failover, compensaciones de consistencia y más herramientas operativas. Tu aplicación también necesita saber a qué servidor hablar (o necesitas una capa proxy).
Poner expectativas: no saltar al sharding
La mayoría de los equipos no necesitan sharding como primer paso. Empieza confirmando dónde se consume el tiempo (CPU vs I/O vs contención por locks), arregla consultas lentas e índices y dimensiona memoria y almacenamiento. El escalado horizontal compensa cuando una sola máquina no puede cubrir tu tasa de escrituras, tamaño de almacenamiento o requerimientos de disponibilidad—incluso después de buen tuning.
Replicación y réplicas de lectura: escalar lecturas de forma práctica
La replicación es una de las formas más prácticas en que los sistemas MySQL manejaron el crecimiento: en lugar de hacer que una base de datos lo haga todo, copias sus datos a otros servidores y repartes el trabajo.
Replicación en términos sencillos: un primario y réplicas
Piensa en un primario (a veces llamado “master”) como la base de datos que acepta cambios—INSERTs, UPDATEs, DELETEs. Una o más réplicas (antes “slaves”) tiran continuamente esos cambios y los aplican, manteniendo una copia casi en tiempo real.
Tu aplicación puede entonces:
- Enviar escrituras al primario
- Enviar muchas lecturas a las réplicas
Este patrón se volvió común porque el tráfico web a menudo crece “más en lecturas” que en escrituras.
Para qué se usaban las réplicas de lectura
Las réplicas de lectura no solo servían para páginas más rápidas. También ayudaban a aislar trabajos que de otro modo ralentizarían la base principal:
- Escalado de lectura: páginas de producto, feeds, resultados de búsqueda y endpoints con muchas lecturas
- Analítica e informes: ejecutar consultas largas en una réplica en vez de bloquear el primario
- Backups: hacer dumps lógicos o ejecutar herramientas de backup contra una réplica para reducir el impacto en producción
Los compromisos que debes aceptar
La replicación no es gratis. El problema más común es el lag de replicación—las réplicas pueden ir segundos (o más) detrás del primario durante picos.
Eso conduce a una pregunta clave a nivel de aplicación: consistencia “leer tras escribir”. Si un usuario actualiza su perfil y lees inmediatamente desde una réplica, podría ver datos antiguos. Muchos equipos resuelven esto leyendo desde el primario para vistas “frescas” o usando una ventana corta de “leer del primario tras escribir”.
Replicación no es lo mismo que failover
La replicación copia datos; no te mantiene automáticamente en línea durante fallos. Failover—promover una réplica, redirigir tráfico y asegurar que la app se reconecte de forma segura—es una capacidad separada que requiere herramientas, pruebas y procedimientos operativos claros.
Fundamentos de alta disponibilidad: permanecer en línea ante fallos
Convierte lecciones de MySQL en código
Describe tu app y deja que Koder.ai genere un esqueleto en React y Go que puedas refinar.
Alta disponibilidad (HA) son las prácticas que mantienen tu app funcionando cuando un servidor de bases de datos se cae, un enlace de red se rompe o necesitas hacer mantenimiento. Los objetivos son simples: reducir el tiempo de inactividad, hacer el mantenimiento seguro y asegurar que la recuperación sea predecible en lugar de improvisada.
Los patrones de HA más comunes
Las implantaciones tempranas con MySQL empezaban con un primario. HA típicamente añadía una segunda máquina para que un fallo no significara una larga indisponibilidad.
- Primario–standby (activo–pasivo): un servidor maneja tráfico; un standby está listo para tomar el relevo.
- Clústeres multinodo: varios nodos cooperan para mantener el servicio disponible, generalmente con reglas más estrictas sobre escrituras.
- Failover automatizado: monitorización que detecta fallo del primario y promueve un standby, actualizando el objetivo de conexión de la app.
La automatización ayuda, pero también eleva el nivel: tu equipo debe confiar en la lógica de detección y evitar un “split brain” (dos servidores creyendo ser primarios).
RPO y RTO, en lenguaje llano
Dos métricas hacen las decisiones de HA menos emocionales y más mensurables:
- RPO (Recovery Point Objective): cuánta información puedes permitirte perder. Si una réplica va 10 segundos detrás, tu RPO es hasta ~10 segundos.
- RTO (Recovery Time Objective): cuánto tiempo puedes permitirte estar caído. Esto incluye detección, promoción y reconexión de la app.
Fundamentos operativos que hacen real la HA
HA no es solo topología—es práctica.
Las copias de seguridad deben ser rutinarias, pero la clave son las pruebas de restauración: ¿puedes realmente recuperar en un servidor nuevo, rápido y bajo presión?
Los cambios de esquema también importan. Alteraciones de tablas grandes pueden bloquear escrituras o ralentizar consultas. Enfoques más seguros incluyen cambios en ventanas de baja carga, herramientas de cambio de esquema en línea y tener siempre un plan de rollback.
Bien hecho, HA convierte fallos en eventos planificados y ensayados en lugar de emergencias.
Estrategias de caché que mantenían a MySQL rápido con tráfico web
El caching fue una de las formas más sencillas con las que los equipos web tempranos mantenían MySQL responsivo al subir el tráfico. La idea es simple: servir peticiones repetidas desde algo más rápido que la base de datos y golpear MySQL solo cuando sea estrictamente necesario. Bien hecho, el caching reduce dramáticamente la carga de lectura y hace que picos repentinos se sientan como una subida suave en vez de una estampida.
Las capas de caché comunes
Cache de aplicación/objetos guarda “piezas” de datos que el código pide con frecuencia—perfiles de usuario, detalles de producto, comprobaciones de permisos. En lugar de ejecutar la misma SELECT cientos de veces por minuto, la app lee un objeto precomputado por clave.
Cache de página o fragmento guarda HTML renderizado (páginas completas o partes como una barra lateral). Esto es especialmente efectivo para sitios de contenido donde muchos visitantes ven las mismas páginas.
Cache de resultados de consultas guarda el resultado de una consulta específica (o una versión normalizada). Incluso si no cacheas a nivel SQL, puedes cachear “el resultado de este endpoint” usando una clave que represente la petición.
Conceptualmente, los equipos usan stores key/value en memoria, caches HTTP o caching incorporado en frameworks. La herramienta exacta importa menos que claves consistentes, TTLs y propiedad clara.
La parte difícil: invalidación del caché
Cachear intercambia frescura por velocidad. Algunos datos pueden estar ligeramente desactualizados (páginas de noticias, contadores). Otros no pueden (totales de checkout, permisos). Normalmente eliges entre:
- Expiración por tiempo (simple, permite ligera desactualización)
- Invalidación por evento (más precisa, más fácil de romper)
Si la invalidación falla, los usuarios ven contenido desactualizado. Si es demasiado agresiva, pierdes el beneficio y MySQL recibe la presión de nuevo.
Por qué suaviza picos
Cuando el tráfico sube, los caches absorben lecturas repetidas mientras MySQL se concentra en el “trabajo real” (escrituras, misses de caché, consultas complejas). Esto reduce colas, evita que las ralentizaciones se propaguen y da tiempo para escalar con seguridad.
Sharding y particionado: cuando una base de datos no basta
Hay un punto donde “hardware más grande” e incluso el ajuste cuidadoso de consultas dejan de dar margen. Si un solo servidor MySQL no puede seguir el ritmo de escrituras, tamaño de dataset o ventanas de mantenimiento, empiezas a plantearte dividir los datos.
Particionado vs sharding (y por qué son distintos)
Particionado divide una tabla en piezas más pequeñas dentro de la misma instancia MySQL (por ejemplo, por fecha). Puede hacer deletes, archivado y algunas consultas más rápidas, pero no te permite superar los límites de CPU, RAM e I/O de ese único servidor.
Sharding divide datos a través de múltiples servidores MySQL. Cada shard guarda un subconjunto de filas y tu aplicación (o una capa de enrutamiento) decide a qué servidor va cada petición.
Cuándo el sharding se vuelve necesario
El sharding suele aparecer cuando:
- Las escrituras saturan un primario incluso tras índices, arreglos de consultas y caching
- El crecimiento de almacenamiento hace que backups, restores y cambios de esquema sean demasiado lentos
- Trabajos “vecinos ruidosos” crean latencia impredecible para el resto
Claves de shard comunes
Una buena clave de shard reparte tráfico uniformemente y mantiene la mayor parte de las peticiones en un único shard:
- user_id: común en apps de consumo; mantiene juntos los datos de un usuario
- tenant_id: ideal para SaaS; fuerte aislamiento entre clientes
- geografía: útil para latencia y residencia de datos, pero puede crear hotspots (regiones grandes)
Los costes reales
Sharding cambia simplicidad por escala:
- Consultas cross-shard son más difíciles (a menudo resueltas por fan-out + agregación)
- Transacciones cross-shard están limitadas; muchos equipos pasan a patrones de “consistencia eventual”
- Migraciones y reequilibrado son operacionalmente costosos (mover rangos, actualizar enrutamiento)
Un enfoque por fases (antes de comprometerse)
Empieza con caching y réplicas de lectura para quitar presión del primario. Luego, aisla tablas o workloads más pesados (a veces separando por función o servicio). Solo entonces pasa al sharding—idealmente de forma que puedas añadir shards gradualmente en lugar de rediseñar todo de una vez.
Operaciones a escala: monitorización, mantenimiento e incidentes
Exporta el código fuente en cualquier momento
Empieza rápido en chat y luego exporta el código cuando quieras control total.
Ejecutar MySQL para un producto con mucho tráfico tiene menos que ver con features ingeniosas y más con operaciones disciplinadas. La mayoría de las caídas no empiezan con un fallo dramático—empiezan con pequeñas señales que nadie conectó a tiempo.
Qué monitorean realmente los equipos
A escala, las “cuatro grandes” señales suelen predecir problemas antes que otras:
- Latencia de consultas (p50/p95/p99): el aumento en la cola importa más que las medias.
- Locks y esperas por locks: picos pueden indicar filas calientes, índices faltantes o transacciones largas.
- Lag de replicación: el lag convierte el “escalado de lectura” en lecturas obsoletas y puede romper failovers.
- Crecimiento del disco y presión de I/O: el disco se llena, pero la saturación de I/O suele afectar primero.
Buen dashboard añade contexto: tráfico, tasas de error, conteo de conexiones, buffer pool hit rate y consultas top. La meta es detectar cambios, no memorizar el “normal”.
Por qué las consultas lentas aparecen solo bajo carga real
Muchas consultas parecen bien en staging e incluso en producción en horas tranquilas. Bajo carga, la DB se comporta distinto: las caches dejan de ayudar, las peticiones concurrentes amplifican la contención por locks y una consulta ligeramente ineficiente puede desencadenar más lecturas, más tablas temporales o mayor trabajo de ordenado.
Por eso los equipos confían en el log de consultas lentas, digest de consultas e histogramas en producción en lugar de benchmarks aislados.
Mantenimiento sin sorpresas
Las prácticas seguras son deliberadamente aburridas: ejecutar migraciones en pequeños lotes, añadir índices con bloqueo mínimo cuando sea posible, verificar con planes EXPLAIN y mantener rollbacks realistas (a veces el rollback es “parar el rollout y hacer failover”). Los cambios deben ser medibles: latencia antes/después, esperas por locks y lag de replicación.
Incidentes: diagnosticar, mitigar, prevenir
Durante un incidente: confirmar impacto, identificar al culpable principal (una consulta, un host, una tabla), luego mitigar—limitar tráfico, matar consultas desbocadas, añadir un índice temporal o desplazar lecturas/escrituras. Después, documentar qué pasó, añadir alertas para las señales tempranas y hacer la solución reproducible para evitar la misma falla la semana siguiente.
Por qué MySQL sigue alimentando sistemas masivos hoy
MySQL sigue siendo la opción por defecto para muchos sistemas modernos porque empata con la forma de los datos de aplicaciones cotidianas: muchas lecturas y escrituras pequeñas, límites transaccionales claros y consultas predecibles. Por eso encaja aún en productos OLTP como apps SaaS, e-commerce, marketplaces y plataformas multi-tenant—especialmente si modelas datos alrededor de entidades de negocio reales y mantienes transacciones enfocadas.
Un MySQL moderno es muy distinto al “MySQL antiguo”
El ecosistema actual de MySQL se beneficia de años de lecciones duras incorporadas en mejores valores por defecto y hábitos operativos más seguros. En la práctica, los equipos confían en:
- InnoDB como motor estándar, con mejor recuperación ante fallos y garantías transaccionales
- Características de rendimiento mejoradas (optimizers mejores, opciones de replicación más rápidas, concurrencia más predecible)
- Observabilidad más fácil de activar: logs de consultas lentas, performance schema, exporters de métricas y dashboards que resaltan cuellos de botella reales
- Automatización alrededor de cambios de esquema, backups y failover—para que escalar no dependa del trabajo heroico manual
MySQL gestionado reduce el coste operativo
Muchas compañías ahora ejecutan MySQL mediante servicios gestionados, donde el proveedor se encarga de trabajo rutinario como parches, backups automáticos, cifrado, recuperación punto-en-el-tiempo y pasos de escalado comunes (instancias más grandes, réplicas de lectura, crecimiento de almacenamiento). Sigues siendo responsable de tu esquema, consultas y patrones de acceso a datos—pero pasas menos tiempo en ventanas de mantenimiento y ejercicios de recuperación.
Llevar estos patrones a la entrega moderna de apps
Una razón por la que el “libro de jugadas de escalado MySQL” sigue siendo relevante es que rara vez es solo un problema de base de datos—es un problema de arquitectura de la aplicación. Decisiones como separación lectura/escritura, claves e invalidación de caché, migraciones seguras y planes de rollback funcionan mejor cuando se diseñan junto al producto, no se añaden tras un incidente.
Si estás construyendo servicios nuevos y quieres codificar estas decisiones desde el inicio, un flujo de trabajo de vibe-coding puede ayudar. Por ejemplo, Koder.ai puede tomar una especificación en lenguaje natural (entidades, expectativas de tráfico, necesidades de consistencia) y ayudar a generar un esqueleto de app—típicamente React en web y servicios en Go—mientras te mantiene al mando del diseño de la capa de datos. Su Planning Mode, snapshots y rollback son especialmente útiles al iterar en esquemas y despliegues sin convertir cada migración en un evento de alto riesgo.
Si quieres explorar los planes de Koder.ai (Free, Pro, Business, Enterprise), ver /pricing.
Elegir MySQL hoy (checklist basado en requisitos)
Elige MySQL cuando necesites: transacciones sólidas, un modelo relacional, herramientas maduras, rendimiento predecible y una amplia bolsa de talento. Considera alternativas cuando necesites: fan-out masivo de escrituras con esquemas flexibles (algunos sistemas NoSQL), escrituras multi-región con consistencia global (bases distribuidas especializadas) o cargas analíticas intensivas (almacenes columnarios).
La conclusión práctica: parte de los requisitos (latencia, consistencia, modelo de datos, tasa de crecimiento, habilidades del equipo) y elige el sistema más simple que los cumpla—y MySQL con frecuencia sigue haciéndolo.
Preguntas frecuentes
¿Por qué MySQL se volvió tan popular para las aplicaciones web tempranas?
MySQL alcanzó un punto óptimo para sitios web tempranos: rápido de instalar, fácil de conectar desde lenguajes comunes y con rendimiento “suficientemente bueno” en hardware modesto. Combinado con la accesibilidad open source y la ubicuidad del stack LAMP en hosting compartido, se convirtió en la base por defecto para muchos equipos pequeños y sitios en crecimiento.
¿Qué significa “escalar MySQL” en la práctica?
En este contexto, “escalar” normalmente significa manejar:
- Más tráfico (más usuarios concurrentes y más consultas por segundo)
- Más datos (tablas que crecen a millones o miles de millones de filas)
- Mayores expectativas de fiabilidad (permanecer en línea ante fallos y despliegues)
- Restricciones de costo (hacer todo lo anterior sin presupuestos empresariales)
No es solo velocidad bruta: es rendimiento predecible y tiempo de actividad bajo cargas reales.
¿Cómo ayudó el stack LAMP a que MySQL se extendiera tanto?
LAMP hizo que el despliegue fuera predecible: una sola máquina Linux podía ejecutar Apache + PHP + MySQL de forma económica, y los proveedores de hosting podían estandarizar y automatizar la configuración. Esa consistencia redujo la fricción al pasar del desarrollo local a producción y ayudó a que MySQL se difundiera como una base de datos “disponible por defecto”.
¿Qué tipos de cargas de trabajo manejaba bien MySQL en la web temprana?
Los workloads tempranos eran a menudo muy orientados a lectura y sencillos: cuentas de usuario, publicaciones recientes, catálogos de productos y filtrados básicos. MySQL rendía bien en búsquedas rápidas (a menudo por clave primaria) y patrones comunes como “elementos más recientes”, especialmente cuando los índices reflejaban los patrones de acceso.
¿Cuáles fueron las primeras señales de que una base de datos MySQL empezaba a fallar?
Los signos habituales de que una base de datos MySQL empezaba a tener problemas incluían:
- Consultas lentas que escaneaban demasiadas filas
- Contención por locks (especialmente con locking a nivel de tabla)
- Memoria insuficiente para mantener índices/datos calientes en RAM, causando mucho I/O de disco
Estos problemas a menudo aparecían solo después de que aumentara el tráfico, convirtiendo “ineficiencias menores” en picos de latencia importantes.
¿Qué es un motor de almacenamiento en MySQL y por qué importa?
Un motor de almacenamiento controla cómo MySQL escribe datos, mantiene índices, bloquea filas/tablas y se recupera de fallos. Elegir el motor correcto afecta tanto el rendimiento como la corrección: dos configuraciones pueden ejecutar la misma SQL pero comportarse de forma muy diferente ante concurrencia y fallos.
¿Por qué InnoDB reemplazó a MyISAM como la opción por defecto en producción?
MyISAM fue común al principio porque era simple y a veces rápido para lecturas, pero usa locking a nivel de tabla, carece de transacciones y es más débil en recuperación tras fallos. InnoDB introdujo locking a nivel de fila, transacciones y mayor durabilidad—lo que lo hizo más adecuado cuando las aplicaciones empezaron a necesitar escrituras seguras (inicios de sesión, carritos, pagos) a escala.
¿Cuáles son las prácticas de indexación y diseño de consultas más importantes para escalar?
Los índices permiten a MySQL encontrar filas rápidamente en lugar de escanear tablas enteras. Hábitos prácticos que importan:
- Evitar
SELECT *; recuperar solo las columnas necesarias - Cuidado con
LIKEcon wildcard al inicio y con funciones sobre columnas indexadas - Usar
EXPLAINpara confirmar el uso de índices
¿Debo escalar MySQL vertical u horizontalmente primero?
Escalar verticalmente (“una caja más grande”) añade CPU/RAM/almacenamiento más rápido a un servidor—suele ser la ganancia más rápida con menos componentes móviles. Escalar horizontalmente (“más máquinas”) añade réplicas y/o shards, pero introduce complejidad de coordinación (lag de replicación, enrutamiento, comportamiento de failover). La mayoría de los equipos deben agotar las correcciones de consultas/índices y el dimensionamiento apropiado antes de saltar al sharding.
¿Cómo ayudan las réplicas de lectura y qué problemas introducen?
Las réplicas de lectura ayudan enviando muchas lecturas (y cargas de análisis/respaldo) a servidores secundarios mientras las escrituras quedan en el primario. El principal compromiso es el lag de replicación, que puede romper la expectativa de “leer tras escribir”; por eso las apps suelen leer del primario justo después de una escritura o usar una ventana corta de lectura en primario.