Del prototipo al SaaS: donde empieza la confusión
Un prototipo demuestra una idea. Un SaaS tiene que sobrevivir al uso real: picos de tráfico, datos desordenados, reintentos y clientes que notan cada fallo. Ahí es donde las cosas se complican, porque la pregunta cambia de “¿funciona?” a “¿sigue funcionando?”.
Con usuarios reales, “funcionó ayer” falla por razones aburridas. Un job en background corre más tarde de lo habitual. Un cliente sube un archivo 10× más grande que tus datos de prueba. Un proveedor de pagos se queda bloqueado 30 segundos. Nada de esto es exótico, pero los efectos se hacen ruidosos cuando partes del sistema dependen unas de otras.
La mayoría de la complejidad aparece en cuatro sitios: datos (el mismo hecho existe en varios lugares y diverge), latencia (llamadas de 50 ms a veces toman 5 s), fallos (timeouts, actualizaciones parciales, reintentos) y equipos (personas distintas desplegando servicios con agendas diferentes).
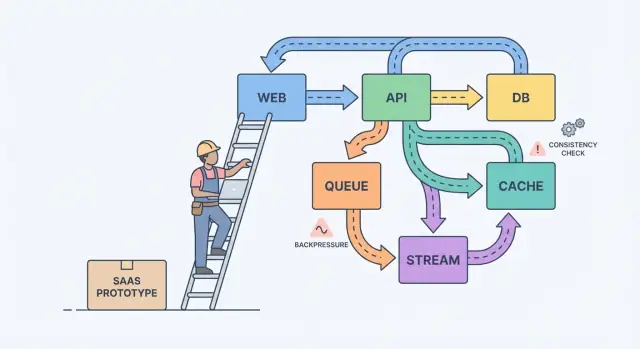
Un modelo mental simple ayuda: componentes, mensajes y estado.
Los componentes hacen trabajo (app web, API, worker, base de datos). Los mensajes mueven trabajo entre componentes (requests, eventos, jobs). El estado es lo que recuerdas (pedidos, ajustes de usuario, estado de facturación). El dolor al escalar suele ser un desajuste: envías mensajes más rápido de lo que un componente puede procesar, o actualizas estado en dos sitios sin una fuente de verdad clara.
Un ejemplo clásico es la facturación. Un prototipo puede crear una factura, enviar un email y actualizar el plan de un usuario en una sola petición. Bajo carga, el email se ralentiza, la petición hace timeout, el cliente reintenta y ahora tienes dos facturas y un solo cambio de plan. El trabajo de fiabilidad consiste en evitar que esos fallos cotidianos lleguen al cliente.
Convierte conceptos en decisiones por escrito
La mayoría de los sistemas se vuelven más difíciles porque crecen sin acuerdo sobre qué debe ser correcto, qué solo debe ser rápido y qué debería pasar cuando algo falla.
Empieza por dibujar un límite alrededor de lo que prometes a los usuarios. Dentro de ese límite, nombra las acciones que deben ser correctas siempre (movimiento de dinero, control de acceso, propiedad de cuentas). Luego nombra las áreas donde “eventualmente correcto” está bien (contadores de analytics, índices de búsqueda, recomendaciones). Esta división convierte teoría difusa en prioridades.
Después, escribe tu fuente de verdad. Es donde los hechos se registran una vez, de forma durable, con reglas claras. Todo lo demás es dato derivado construido para velocidad o conveniencia. Si una vista derivada se corrompe, deberías poder reconstruirla desde la fuente de verdad.
Cuando los equipos se atascan, estas preguntas suelen sacar a la luz lo que importa:
- ¿Qué datos nunca deben perderse, incluso si eso ralentiza las cosas?\n- ¿Qué puede recrearse desde otros datos, aunque tome horas?\n- ¿Qué puede estar obsoleto y por cuánto tiempo, desde la perspectiva del usuario?\n- ¿Qué fallo es peor para ti: duplicados, eventos faltantes o retrasos?
Si un usuario actualiza su plan, un dashboard puede retrasarse. Pero no puedes tolerar una discrepancia entre el estado de pago y el acceso real.
Si un usuario hace clic y debe ver el resultado de inmediato (guardar perfil, cargar dashboard, comprobar permisos), una API request-response suele ser suficiente. Mantenlo directo.
Tan pronto como el trabajo pueda ocurrir después, muévelo a async. Piensa en enviar emails, cobrar tarjetas, generar informes, redimensionar uploads o sincronizar datos a búsqueda. El usuario no debe esperar por esto, y tu API no debería quedarse ocupada mientras sucede.
Una cola es una lista de tareas: cada tarea debe ser manejada una vez por un worker. Un stream (o log) es un registro: los eventos se mantienen en orden para que múltiples lectores puedan reproducirlos, ponerse al día o construir nuevas features sin cambiar al productor.
Una forma práctica de elegir:
- Usa request-response cuando el usuario necesita una respuesta inmediata y el trabajo es pequeño.\n- Usa una cola para trabajo en background con reintentos donde solo un worker debe ejecutar cada job.\n- Usa un stream/log cuando necesites replay, una pista de auditoría o múltiples consumidores que no deben acoplarse a un servicio.
Ejemplo: tu SaaS tiene un botón “Crear factura”. La API valida la entrada y guarda la factura en Postgres. Luego una cola maneja “enviar email de factura” y “cobrar tarjeta”. Si más adelante añades analytics, notificaciones y checks de fraude, un stream de InvoiceCreated permite que cada feature se suscriba sin convertir tu servicio central en un laberinto.
Diseño de eventos: qué publicas y qué guardas
A medida que un producto crece, los eventos dejan de ser “agradables de tener” y se convierten en una red de seguridad. Un buen diseño de eventos se reduce a dos preguntas: qué hechos registras y cómo pueden otras partes reaccionar sin adivinar.
Empieza con un pequeño conjunto de eventos de negocio. Elige momentos que importen a usuarios y dinero: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
Los nombres sobreviven al código. Usa pasado para hechos completados, mantenlos específicos y evita el lenguaje de la UI. PaymentSucceeded sigue siendo significativo aunque luego añadas cupones, reintentos o varios proveedores de pago.
Trata los eventos como contratos. Evita un “UserUpdated” que lo contenga todo y cambie cada sprint. Prefiere el hecho más pequeño en el que puedas confiar durante años.
Para evolucionar con seguridad, favorece cambios aditivos (nuevos campos opcionales). Si necesitas un cambio rompedor, publica un nuevo nombre de evento (o una versión explícita) y mantén ambos hasta que los consumidores antiguos desaparezcan.
¿Qué deberías almacenar? Si solo guardas las filas más recientes en una base de datos, pierdes la historia de cómo llegaste ahí.
Los eventos crudos son excelentes para auditoría, replay y debugging. Los snapshots son buenos para lecturas rápidas y recuperación veloz. Muchos productos SaaS usan ambos: guardan eventos crudos para flujos clave (facturación, permisos) y mantienen snapshots para pantallas visibles al usuario.
Compromisos de consistencia que los usuarios realmente sienten
La consistencia aparece en momentos como: “Cambié mi plan, ¿por qué sigue apareciendo Gratis?” o “Envié una invitación, ¿por qué mi compañero aún no puede entrar?”.
La consistencia fuerte significa que una vez recibes un mensaje de éxito, todas las pantallas deben reflejar el nuevo estado de inmediato. La consistencia eventual significa que el cambio se propaga con el tiempo y durante una ventana corta distintas partes de la app pueden discrepar. Ninguna es “mejor”. Elige según el daño que una discrepancia pueda causar.
La consistencia fuerte suele encajar con dinero, acceso y seguridad: cobrar una tarjeta, cambiar una contraseña, revocar claves API, hacer cumplir límites de asientos. La consistencia eventual suele encajar con feeds de actividad, búsqueda, dashboards de analytics, “última conexión” y notificaciones.
Si aceptas obsolescencia, diseñalo en lugar de esconderlo. Mantén la UI honesta: muestra un estado “Actualizando…” después de una escritura hasta que llegue la confirmación, ofrece un refresco manual para listas y usa UI optimista solo cuando puedas revertir con seguridad.
Los reintentos son donde la consistencia se vuelve traicionera. Las redes fallan, los clientes hacen doble clic y los workers se reinician. Para operaciones importantes, haz las peticiones idempotentes para que repetir la misma acción no cree dos facturas, dos invitaciones o dos reembolsos. Un enfoque común es una key de idempotencia por acción más una regla en servidor para devolver el resultado original en repeticiones.
Backpressure: evitar que el sistema se derrita
Backpressure es lo que necesitas cuando las peticiones o eventos llegan más rápido de lo que tu sistema puede manejar. Sin él, el trabajo se acumula en memoria, las colas crecen y la dependencia más lenta (a menudo la base de datos) decide cuándo todo falla.
En términos simples: tu productor no para de hablar mientras tu consumidor se está ahogando. Si sigues aceptando trabajo, no solo te vuelves más lento. Desencadenas una reacción en cadena de timeouts y reintentos que multiplican la carga.
Las señales suelen aparecer antes de una caída: el backlog crece sin parar, la latencia salta después de picos o despliegues, aumentan los reintentos por timeouts, endpoints no relacionados fallan cuando una dependencia se ralentiza y las conexiones a la DB permanecen al límite.
Cuando llegas a ese punto, elige una regla clara para qué pasa cuando estás lleno. El objetivo no es procesar todo a cualquier costo. Es seguir vivo y recuperarte rápido. Los equipos suelen empezar con una o dos medidas: límites de tasa (por usuario o API key), colas acotadas con política definida de descarte/retardo, circuit breakers para dependencias fallidas y prioridades para que las peticiones interactivas ganen sobre jobs en background.
Protege la base de datos primero. Mantén pools de conexión pequeños y previsibles, establece timeouts en queries y pon límites duros en endpoints caros como informes ad-hoc.
Un camino paso a paso hacia la fiabilidad (sin reescribirlo todo)
La fiabilidad rara vez exige una gran reescritura. Normalmente viene de unas pocas decisiones que hacen los fallos visibles, contenidos y recuperables.
Empieza con los flujos que generan o pierden confianza, luego añade protecciones antes de añadir features:
-
Mapear caminos críticos. Escribe los pasos exactos para signup, login, restablecer contraseña y cualquier flujo de pago. Para cada paso, lista sus dependencias (base de datos, proveedor de email, worker). Esto obliga a aclarar qué debe ser inmediato y qué puede arreglarse “eventualmente”.
-
Añadir lo básico de observabilidad. Da a cada request un ID que aparezca en logs. Rastrea un pequeño conjunto de métricas que reflejen el dolor del usuario: tasa de errores, latencia, profundidad de colas y consultas lentas. Añade traces solo donde las peticiones cruzan servicios.
-
Aislar trabajo lento o inestable. Todo lo que hable con un servicio externo o normalmente tome más de un segundo debería moverse a jobs y workers.
-
Diseñar para reintentos y fallos parciales. Asume timeouts. Haz operaciones idempotentes, usa backoff, fija límites de tiempo y mantén las acciones orientadas al usuario cortas.
-
Practicar la recuperación. Los backups importan solo si puedes restaurarlos. Usa despliegues pequeños y mantén un camino rápido de rollback.
Si tu tooling soporta snapshots y rollback (Koder.ai lo hace), intégralo en los hábitos normales de despliegue en lugar de tratarlo como un truco de emergencia.
Ejemplo: convertir un pequeño SaaS en algo fiable
Imagina un pequeño SaaS que ayuda a equipos a incorporar nuevos clientes. El flujo es simple: un usuario se registra, elige un plan, paga y recibe un email de bienvenida más algunos pasos iniciales.
En el prototipo, todo ocurre en una petición: crear cuenta, cobrar tarjeta, marcar “pagado” en el usuario, enviar email. Funciona hasta que crece el tráfico, ocurren reintentos y los servicios externos se ralentizan.
Para hacerlo fiable, el equipo convierte acciones clave en eventos y mantiene un historial append-only. Introducen unos eventos: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Eso les da una pista de auditoría, facilita analytics y permite que el trabajo lento ocurra en background sin bloquear el registro.
Unas pocas decisiones hacen la mayor parte del trabajo:
- Trata los pagos como la fuente de verdad para acceso, no un simple flag “pagado”.\n- Concede derechos desde
PaymentSucceeded con una key de idempotencia clara para que los reintentos no dupliquen concesiones.\n- Envía emails desde una cola/worker, no desde la petición de checkout.\n- Registra eventos aunque falle un handler, para que puedas reproducir y recuperar.\n- Añade timeouts y un circuit breaker alrededor de proveedores externos.
Si el pago succeed pero el acceso no se ha concedido todavía, los usuarios se sienten estafados. La solución no es “consistencia perfecta en todas partes”. Es decidir qué debe ser consistente ahora mismo y reflejar esa decisión en la UI con un estado como “Activando tu plan” hasta que EntitlementGranted llegue.
En un mal día, el backpressure marca la diferencia. Si la API de email se queda lenta durante una campaña, el diseño antiguo hace que los checkouts hagan timeout y los usuarios reintenten, creando cargos e emails duplicados. En el diseño mejor, el checkout termina con éxito, las solicitudes de email se encolan y un job de replay vacía el backlog cuando el proveedor se recupera.
Trampas comunes cuando los sistemas escalan
La mayoría de las caídas no las causa un bug heroico. Provienen de pequeñas decisiones que tenían sentido en un prototipo y luego se volvieron hábito.
Una trampa común es dividir en microservicios demasiado pronto. Terminas con servicios que se llaman mucho entre sí, propiedad poco clara y cambios que requieren cinco despliegues en vez de uno.
Otra trampa es usar “consistencia eventual” como excusa. A los usuarios no les importa el término. Les importa que hicieron clic en Guardar y luego la página muestra datos antiguos, o que el estado de una factura salta de un lado a otro. Si aceptas retrasos, igual necesitas feedback al usuario, timeouts y una definición de “suficiente” en cada pantalla.
Otros errores repetidos: publicar eventos sin plan de reprocesado, reintentos sin límite que multiplican la carga durante incidentes y permitir que cada servicio hable directamente al mismo esquema de base de datos para que un cambio rompa a muchos equipos.
Chequeos rápidos antes de llamar “listo para producción”
“Listo para producción” es un conjunto de decisiones que puedas señalar a las 2 a.m. La claridad vence a la sofisticación.
Empieza por nombrar tus fuentes de verdad. Para cada tipo de dato clave (clientes, suscripciones, facturas, permisos), decide dónde vive el registro final. Si tu app lee la “verdad” de dos lugares, eventualmente mostrarás respuestas distintas a distintos usuarios.
Luego mira los reintentos. Asume que cada acción importante se ejecutará dos veces en algún momento. Si la misma petición llega dos veces, ¿puedes evitar cargos dobles, envíos dobles o duplicados?
Una pequeña lista que atrapa la mayoría de fallos dolorosos:
- Para cada tipo de dato, puedes señalar una fuente de verdad y decir qué es derivado.\n- Cada escritura importante es segura para reintentos (key de idempotencia o restricción única).\n- Tu trabajo asíncrono no puede crecer sin control (mides lag, edad del mensaje más antiguo y alertas antes de que los usuarios lo noten).\n- Tienes un plan para cambios (migraciones reversibles, versionado de eventos).\n- Puedes hacer rollback y restaurar con confianza porque lo has practicado.
Próximos pasos: toma una decisión a la vez
Escalar se vuelve más fácil cuando tratas el diseño del sistema como una lista corta de elecciones, no una pila de teoría.
Escribe de 3 a 5 decisiones que esperas enfrentar en el próximo mes, en lenguaje claro: “¿Movemos el envío de emails a un job en background?” “¿Aceptamos analytics ligeramente obsoletos?” “¿Qué acciones deben ser inmediatamente consistentes?” Usa esa lista para alinear producto e ingeniería.
Luego elige un flujo que hoy sea síncrono y conviértelo solo a async. Recibos, notificaciones, informes y procesamiento de archivos son movimientos iniciales comunes. Mide dos cosas antes y después: latencia visible al usuario (¿la página se sintió más rápida?) y comportamiento ante fallos (¿los reintentos crearon duplicados o confusión?).
Si quieres prototipar estos cambios rápido, Koder.ai (koder.ai) puede ser útil para iterar en un SaaS con React + Go + PostgreSQL mientras mantienes snapshots y rollback a mano. La regla es simple: lanza una mejora, aprende del tráfico real y decide la siguiente.