Aclarar el objetivo: qué debe entregar un bucle de retroalimentación
Una app de gestión de retroalimentación no es “un lugar para guardar mensajes”. Es un sistema que ayuda a tu equipo a pasar de forma fiable de entrada a acción a seguimiento visible para el cliente, y luego a aprender de lo ocurrido.
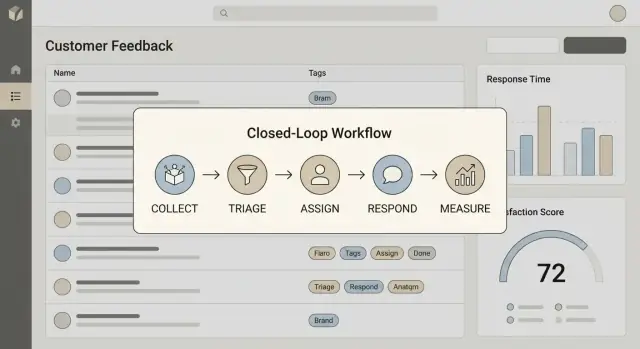
Define qué significa “cerrar el ciclo”
Escribe una definición de una frase que tu equipo pueda repetir. Para la mayoría de equipos, cerrar el ciclo incluye cuatro pasos:
- Recoger: capturar la retroalimentación con suficiente contexto (quién, qué, de dónde vino)
- Actuar: convertirla en trabajo o en una decisión (arreglar, enviar, explicar o rechazar)
- Responder: informar al cliente con un resultado claro y un plazo (incluso si es “todavía no”)
- Aprender: reinyectar los resultados en la priorización, el descubrimiento de producto y los playbooks de soporte
Si falta alguno de estos pasos, tu app se convertirá en una tumba de backlog.
Identifica los usuarios clave y lo que necesitan
Tu primera versión debe servir roles reales del día a día:
- Soporte: triage rápido, claridad de estado, plantillas para respuestas
- Producto: tendencias, impacto, enlaces al roadmap
- Customer success: visibilidad por cuentas, actualizaciones proactivas
- Admins: configuración, higiene de datos, control de accesos
- Clientes finales (opcional): acuse, actualizaciones, estado self‑service
Enumera las decisiones que tu app debe soportar
Sé específico sobre las “decisiones por clic”:
- ¿De qué trata esta retroalimentación (etiqueta/categoría)?
- ¿Quién la posee y cuál es el siguiente paso?
- ¿Cuál es el estado actual y qué cambió desde la semana pasada?
- ¿Qué respuesta enviamos y cuándo?
Establece resultados medibles (para saber si funciona)
Elige un conjunto pequeño de métricas que reflejen velocidad y calidad, como tiempo hasta la primera respuesta, tasa de resolución y cambio en CSAT tras el seguimiento. Estas serán tu estrella del norte para decisiones de diseño posteriores.
Mapea el recorrido de la retroalimentación y el modelo de datos
Antes de diseñar pantallas o elegir una base de datos, mapea qué le ocurre a la retroalimentación desde que se crea hasta que respondes. Un mapa de recorrido simple mantiene al equipo alineado sobre qué significa “hecho” y evita que construyas funciones que no encajan con el trabajo real.
Comienza con las fuentes y luego normaliza
Enumera tus fuentes de retroalimentación y anota qué datos proporciona cada una de forma fiable:
- Widget in‑app (a menudo incluye contexto de usuario/sesión)
- Email (hilos, adjuntos)
- Chat (timestamps, info del agente)
- Formulario web (campos estructurados)
- Reseñas en tiendas de apps (texto público, valoración)
- Encuestas (puntuaciones más comentarios libres)
Aunque las entradas difieran, tu app debería normalizarlas en una forma consistente de “elemento de retroalimentación” para que los equipos puedan triagear todo en un mismo lugar.
Define entidades centrales (y mantenlas aburridas)
Un modelo práctico para empezar suele incluir:
- Cliente: la persona que da la retroalimentación
- Cuenta: la empresa u organización (opcional para B2C)
- Elemento de retroalimentación: el registro principal (mensaje, origen, metadatos)
- Etiqueta: categorización (p. ej., “Facturación”, “Bug”, “Solicitud de función”)
- Estado: dónde está en el flujo de trabajo
- Asignación: quién posee el siguiente paso (persona/equipo)
- Respuesta: mensajes salientes ligados al elemento de retroalimentación (y opcionalmente a un hilo)
Estados para empezar: New → Triaged → Planned → In Progress → Shipped → Closed. Mantén los significados de los estados por escrito para que “Planned” no signifique “Quizá” para un equipo y “Comprometido” para otro.
Decide qué significa “duplicado”
Los duplicados son inevitables. Define reglas desde el principio:
- ¿Cuándo son duplicados dos elementos: mismo problema raíz, misma solicitud de función o mismas palabras clave?
- ¿Qué hace la fusión: combina etiquetas, mantiene ambos clientes, mueve respuestas?
Un enfoque común es mantener un elemento canónico de retroalimentación y vincular otros como duplicados, preservando la atribución (quién lo solicitó) sin fragmentar el trabajo.
Diseña los flujos de usuario centrales (Bandeja → Triage → Acción → Respuesta)
Una app de bucle de retroalimentación tiene éxito o fracasa en el primer día según si las personas pueden procesar la retroalimentación rápidamente. Apunta a un flujo que se sienta como: “escanear → decidir → continuar”, preservando a la vez el contexto para decisiones posteriores.
1) Bandeja: escaneo rápido con los filtros correctos
Tu bandeja es la cola compartida del equipo. Debe soportar triage rápido mediante un pequeño conjunto de filtros potentes:
- Origen (in‑app, email, chat, tienda de apps, notas de ventas)
- Etiqueta (facturación, bugs, solicitud de función, onboarding)
- Estado (new, triaged, in progress, shipped, replied)
- Prioridad (baja → urgente)
- Tier del cliente (free, pro, enterprise)
Añade “vistas guardadas” desde temprano (aunque sean básicas), porque distintos equipos escanean de forma diferente: Soporte quiere “urgente + clientes de pago”, Producto quiere “solicitudes de función + alto ARR”.
2) Vista de detalle: todo lo necesario para decidir
Cuando un usuario abre un elemento, debería ver:
- Historial completo de la retroalimentación (texto original más ediciones, fusiones y cambios de estado)
- Contexto del cliente (plan, valor de la cuenta, empresa, última vez conectado, NPS/CSAT si está disponible)
- Un hilo de conversación que mantenga las respuestas y las notas internas separadas
El objetivo es evitar cambiar de pestañas para responder a: “¿Quién es, qué quiso decir y ya respondimos?”
3) Acciones de triage: ligeras pero completas
Desde la vista de detalle, el triage debe ser una acción por decisión:
- Etiquetar y establecer prioridad
- Asignar un propietario (o cola de equipo)
- Fusionar duplicados (con un elemento “canónico”)
- Vincular a una feature/issue para que el trabajo permanezca conectado con la realidad del cliente
4) Responder: decide qué es externo vs interno
Probablemente necesitarás dos modos:
- Seguimiento sólo interno (la mayoría de equipos B2B): estados y notas privadas; los clientes reciben respuestas directas cuando hay una actualización.
- Página de estado orientada al cliente: útil cuando quieres transparencia a escala (actualizaciones públicas estilo changelog). Manténlo opt‑in y muy curado.
Sea cual sea la opción, convierte “responder con contexto” en el paso final—para que cerrar el ciclo sea parte del flujo, no un pensamiento posterior.
Planea roles, permisos y nociones básicas de seguridad
Una app de retroalimentación se convierte pronto en un sistema compartido de registro: producto quiere temas, soporte quiere respuestas rápidas y liderazgo quiere exportaciones. Si no defines quién puede hacer qué (y pruebas lo que ocurrió), la confianza se rompe.
Comienza con límites multi‑tenant
Si vas a servir a múltiples empresas, trata cada workspace/org como un límite duro desde el día uno. Cada registro central (elemento de retroalimentación, cliente, conversación, etiquetas, informes) debe incluir un workspace_id, y cada consulta debe estar acotada a él.
Esto no es sólo un detalle de base de datos: afecta URLs, invitaciones y analítica. Un valor por defecto seguro: los usuarios pertenecen a uno o varios workspaces y sus permisos se evalúan por workspace.
Define roles que reflejen el trabajo real
Mantén la primera versión simple:
- Admin: gestionar ajustes del workspace, facturación, integraciones y roles
- Manager: configurar categorías/ruteo, acciones masivas, ver informes, exportar
- Agent: triagear items, asignar, comentar y responder a clientes
Luego mapea permisos a acciones, no a pantallas: ver vs editar retroalimentación, fusionar duplicados, cambiar estado, exportar datos y enviar respuestas. Esto facilita añadir un rol “Sólo lectura” después sin reescribir todo.
Añade un registro de auditoría pronto
Un audit log evita debates de “¿quién cambió esto?”. Registra eventos clave con actor, timestamp y antes/después cuando sea útil:
- cambios de asignación
- actualizaciones de estado y fusiones
- edición de etiquetas/categorías
- respuestas enviadas al cliente
Seguridad básica que no te ralentice
Aplica una política de contraseñas razonable, protege endpoints con limitación de tasa (especialmente login e ingestión) y asegura el manejo de sesiones.
Diseña con SSO en mente (SAML/OIDC) aunque lo lances más tarde: guarda un identificador del proveedor de identidad y planifica el enlace de cuentas. Esto evita que solicitudes enterprise te obliguen a una refactorización dolorosa.
Elige una arquitectura adecuada para tu primera versión
Al principio, el mayor riesgo arquitectónico no es “¿escalará?”—es “¿podremos cambiarlo rápido sin romper cosas?”. Una app de retroalimentación evoluciona rápido conforme aprendes cómo los equipos triagean, rutean y responden.
Empieza simple: un monolito con límites claros
Un monolito modular suele ser la mejor primera opción. Obtienes un servicio desplegable, un set de logs y debugging más simple—mientras mantienes el código organizado.
Una división práctica de módulos es:
- Auth & orgs: usuarios, equipos, SSO más adelante
- Feedback: fuentes, envíos, adjuntos, etiquetas
- Workflow: estado de triage, reglas de ruteo, asignaciones
- Messaging: respuestas salientes, plantillas, registro de auditoría
- Analytics: informes, exportaciones, dashboards
Piensa en “carpetas y APIs internas” antes que en “servicios separados”. Si un límite se vuelve doloroso más adelante (por ejemplo, volumen de ingestión), puedes extraerlo con menos drama.
Elige una pila que tu equipo pueda mantener
Usa frameworks y librerías que tu equipo pueda desplegar con confianza. Una pila estable y conocida gana porque:
- contratar y hacer onboarding es más fácil
- las actualizaciones son más predecibles
- depurar en producción es más rápido
Herramientas novedosas pueden esperar hasta que tengas restricciones reales (alto volumen de ingestión, necesidades estrictas de latencia, permisos complejos). Hasta entonces, optimiza para claridad y entrega constante.
Almacenamiento de datos: relacional primero, búsqueda después
La mayoría de entidades centrales—elementos de retroalimentación, clientes, cuentas, etiquetas, asignaciones—encajan de forma natural en una base de datos relacional. Querrás buenas consultas, restricciones y transacciones para cambios de workflow.
Si la búsqueda de texto completo y el filtrado se vuelven importantes, puedes añadir un índice de búsqueda dedicado más adelante (o usar capacidades integradas al principio). Evita tener dos fuentes de la verdad demasiado pronto.
Usa trabajos en background donde los usuarios no deban esperar
Un sistema de retroalimentación acumula rápido tareas “hacer esto después”: enviar correos, sincronizar integraciones, procesar adjuntos, generar resúmenes, disparar webhooks. Ponlas en una cola/trabajador en background desde el inicio.
Esto mantiene la UI responsiva, reduce timeouts y hace los fallos reintentables—sin obligarte a microservicios desde el día uno.
Ruta rápida para un MVP funcional (si quieres moverte más rápido)
Si tu objetivo es validar el workflow y la UI rápido (bandeja → triage → respuestas), considera usar una plataforma de desarrollo rápido como Koder.ai para generar la primera versión a partir de una especificación de chat estructurada. Puede ayudarte a levantar un front end en React con un backend en Go + PostgreSQL, iterar en “modo planificación” y aún exportar el código fuente cuando quieras adoptar un flujo de ingeniería clásico.
Implementa el almacenamiento: esquema, índices y reglas de retención
Mantén la propiedad y la portabilidad
Exporta el código fuente en cualquier momento y pasa a un flujo de trabajo de ingeniería clásico cuando estés listo.
Tu capa de almacenamiento decide si el bucle de retroalimentación se siente rápido y fiable—o lento y confuso. Apunta a un esquema fácil de consultar para el trabajo diario (triage, asignación, estado), preservando suficiente detalle bruto para auditar lo que realmente llegó.
Un modelo de datos práctico para empezar
Para un MVP, puedes cubrir la mayoría de necesidades con un pequeño conjunto de tablas/colecciones:
- workspaces: contenedor a nivel de cuenta (plan, ajustes, política de retención)
- users: miembros del equipo (rol, workspace_id)
- customers: usuarios finales/organizaciones (email, external_id, workspace_id)
- feedback: registro primario (título, cuerpo/resumen, estado, prioridad, origen, customer_id, assigned_to, created_at)
- tags: definiciones normalizadas de etiquetas (nombre, color, workspace_id)
- feedback_tags (join): feedback_id ↔ tag_id
- events: timeline append-only (cambios de estado, asignaciones, fusiones, notas)
- replies: respuestas salientes (canal, mensaje, sent_at, feedback_id, customer_id)
Una regla útil: mantiene feedback ligero (lo que consultas constantemente) y empuja el “todo lo demás” a events y metadatos por canal.
Almacena payloads crudos para trazabilidad
Cuando llega un ticket por email, chat o webhook, guarda la carga útil entrante cruda exactamente como se recibió (p. ej., cabeceras de correo + cuerpo original, o JSON del webhook). Esto te ayuda a:
- depurar problemas de parseo (“¿por qué se truncó el subject?”)
- probar qué se recibió cuando hay una disputa
- reprocesar datos antiguos tras mejorar tu parser
Patrón común: una tabla ingestions con source, received_at, raw_payload (JSON/text/blob) y un enlace al feedback_id creado/actualizado.
Indexa para las consultas que la gente realmente hace
La mayoría de pantallas se reducen a unos filtros previsibles. Añade índices pronto para:
(workspace_id, status) para vistas de bandeja/kanban(workspace_id, assigned_to) para “mis items”(workspace_id, created_at) para ordenación y filtros por fecha- etiquetas: o
(tag_id, feedback_id) en la tabla de unión o un índice dedicado de búsqueda por etiqueta
Si soportas búsqueda de texto completa, considera un índice de búsqueda separado (o la búsqueda integrada de tu BD) en lugar de cargar queries LIKE complejos en producción.
Retención, eliminación y “derecho al olvido”
La retroalimentación a menudo contiene datos personales. Decide desde el inicio:
- cuánto tiempo conservar los payloads crudos (suele ser menor que la retroalimentación normalizada)
- cómo manejar solicitudes de eliminación GDPR (borrar o anonimizar identificadores de cliente y redactar payloads crudos)
- qué ocurre cuando un cliente se da de baja (exportación + eliminación programada)
Implementa la retención como una política por workspace (p. ej., 90/180/365 días) y aplícala con un job programado que expira ingestions crudas primero, luego eventos/respuestas más antiguas si hace falta.
Construye la ingestión: captura retroalimentación desde múltiples canales
La ingestión es donde tu bucle de retroalimentación se mantiene limpio y útil—o se vuelve un caos. Busca “fácil de enviar, consistente de procesar”. Empieza con los canales que tus clientes ya usan, luego expande.
Opciones de captura para lanzar pronto
Un set práctico inicial suele incluir:
- Widget in‑app: un formulario pequeño para ideas y problemas (adjuntar captura opcional). Manténlo mínimo: mensaje, categoría, email.
- Endpoint API: permite que herramientas internas o partners envíen retroalimentación programáticamente. Prefiere un esquema JSON simple y una clave API por workspace.
- Ingestión por email: una dirección única por workspace (p. ej., feedback+acme@…). Parsea subject/body y conserva el correo crudo para auditoría.
- Importación CSV: útil para migraciones y lotes de investigación. Valida columnas y ofrece una vista previa antes de importar.
Control de spam y calidad
No necesitas filtrado pesado el día uno, pero sí protecciones básicas:
- CAPTCHA para envíos públicos desde el widget
- Límites de texto (p. ej., 5–5.000 caracteres) y límites de tamaño de adjuntos
- Sugerencias de detección de duplicados: hashea el mensaje normalizado + área de producto, o detecta “casi duplicados” comparando subjects recientes. No borres automáticamente; marca como “posible duplicado”.
Normaliza las entradas para que el trabajo downstream sea consistente
Normaliza cada evento en un formato interno con campos consistentes:
- Origen (widget, API, email, CSV)
- Identificadores de cliente (workspace, account ID, email de contacto, plan)
- Área de producto (facturación, onboarding, móvil, etc.)
Mantén tanto el payload crudo como el registro normalizado para poder mejorar el parseo más tarde sin perder datos.
Acuse automático que establece expectativas
Envía una confirmación inmediata (para email/API/widget cuando sea posible): agradéceles, explica qué pasará a continuación y evita promesas. Ejemplo: “Revisamos todos los mensajes. Si necesitamos más detalles, responderemos. No podemos contestar individualmente todas las solicitudes, pero tu retroalimentación queda registrada.”
Crea un sistema de triage y ruteo que escale
Construye web y móvil juntos
Crea una app web en React y una aplicación complementaria en Flutter para capturar feedback en un solo lugar.
Una bandeja de retroalimentación sólo se mantiene útil si los equipos pueden responder rápido a tres preguntas: ¿Qué es esto? ¿Quién lo posee? ¿Qué urgencia tiene? El triage convierte mensajes crudos en trabajo organizado.
Comienza con un sistema de etiquetado controlado
Las etiquetas libres parecen flexibles, pero se fragmentan rápido (“login”, “log-in”, “signin”). Empieza con una pequeña taxonomía controlada que refleje cómo ya piensa tu equipo de producto:
- Área de producto (Billing, Mobile, Admin)
- Tema (Bug, Solicitud de función, Problema de UX)
- Impacto (Blocker, Alto, Normal)
Permite a los usuarios sugerir nuevas etiquetas, pero exige un owner (p. ej., PM/lead de Soporte) para aprobarlas. Esto mantiene los informes significativos más adelante.
Usa reglas de auto‑triage para reducir el orden manual
Construye un motor de reglas simple que pueda enrutar retroalimentación automáticamente basándose en señales previsibles:
- Palabra clave/intent: “refund”, “cancel”, “invoice” → cola de Billing
- Plan/nivel de cuenta: Enterprise → cola de soporte prioritario
- Área de producto: derivada de la ruta URL, módulo de la app o categoría seleccionada
Mantén las reglas transparentes: muestra “Ruteado porque: Enterprise plan + palabra clave ‘SSO’.” La gente confía en la automatización cuando puede auditarla.
Haz visibles los SLA, no ocultos
Añade timers de SLA a cada item y a cada cola:
- Tiempo hasta la primera respuesta (qué tan rápido acusas recibo)
- Tiempo hasta el cierre (qué tan rápido resuelves o concluyes)
Muestra el estado del SLA en la vista de lista (“quedan 2h”) y en la página de detalle, para que la urgencia sea compartida por el equipo y no quede en la cabeza de una persona.
Construye escalados y recordatorios en el workflow
Crea un camino claro cuando los items se estanquen: una cola de overdue, resúmenes diarios a los owners y una escalera de escalado ligera (Soporte → Lead de equipo → On‑call/Manager). El objetivo no es presionar, sino evitar que retroalimentación importante caduque en silencio.
Cerrar el ciclo: conecta el trabajo con las respuestas a clientes
Cerrar el ciclo es donde un sistema de gestión de retroalimentación deja de ser una “caja de colección” y se convierte en una herramienta de construcción de confianza. El objetivo es simple: cada retroalimentación puede vincularse a trabajo real, y los clientes que preguntaron pueden enterarse de lo ocurrido—sin hojas de cálculo manuales.
Vincula la retroalimentación al trabajo interno
Comienza permitiendo que un elemento de retroalimentación apunte a uno o varios objetos de trabajo internos (bug, tarea, solicitud de feature). No intentes replicar todo tu issue tracker: guarda referencias ligeras:
work_type (p. ej., issue/task/feature)external_system (p. ej., jira, linear, github)external_id y opcionalmente external_url
Esto mantiene estable tu modelo de datos aunque cambies de herramientas. También permite vistas como “muéstrame toda la retroalimentación de clientes ligada a este release” sin raspar otro sistema.
Define un workflow “Shipped” que notifique a todos
Cuando el trabajo vinculado pase a Shipped (o Done/Released), tu app debería poder notificar a todos los clientes adjuntos a los elementos relacionados.
Usa un mensaje con plantilla y placeholders seguros (nombre, área de producto, resumen, enlace a notas de release). Mantén el texto editable al enviarlo para evitar redacción torpe. Si tienes notas públicas, enlázalas con una ruta relativa como /releases.
Canales de respuesta y seguimiento
Soporta respuestas por los canales desde los que puedas enviar de forma fiable:
- Email
- Notificación in‑app
- Webhook a tu sistema de mensajería
Sea cual sea, registra las respuestas por elemento con una línea de tiempo audit‑friendly: sent_at, channel, author, template_id y estado de entrega. Si un cliente responde, guarda los mensajes entrantes con timestamps también, para poder demostrar que el ciclo realmente se cerró—no sólo que se marcó como "shipped".
Añade reporting que ayude a tomar decisiones
El reporting sólo sirve si cambia lo que los equipos hacen a continuación. Apunta a unas pocas vistas que la gente pueda revisar a diario y luego expande cuando estés seguro de que los datos de workflow subyacentes (estado, etiquetas, propietarios, timestamps) son consistentes.
Dashboards que respondan “¿qué necesita atención?”
Comienza con dashboards operativos que apoyen ruteo y seguimiento:
- Volumen por origen (email, in‑app, social, llamadas): detecta cambios de canal y necesidades de personal
- Principales etiquetas / categorías: qué temas aumentan esta semana
- Backlog por estado (new, triaged, in progress, esperando al cliente, closed): dónde se atasca el trabajo
- Cumplimiento de SLA: tiempo hasta primera respuesta y tiempo hasta cierre contra objetivos
Mantén los gráficos simples y clicables para que un manager pueda profundizar en los items que componen un pico.
Vista a nivel cliente para conversaciones más inteligentes
Añade una página “customer 360” que ayude a soporte y success a responder con contexto:
- Toda la retroalimentación de ese cliente a través de canales
- Último contacto y quién respondió
- Items abiertos y estado/propietario actual
- Un lugar para notas de sentimiento ligeras (p. ej., “molesto por facturación; prefiere email”)—no una puntuación opaca
Esta vista reduce preguntas duplicadas y hace que los seguimientos sean intencionales.
Exporta sin romper la confianza
Los equipos pedirán exportaciones pronto. Proporciona:
- Exportación CSV que respete los mismos filtros que la UI
- Endpoints API de solo lectura para reporting/BI
Haz que el filtrado sea consistente en todas partes (mismos nombres de etiquetas, rangos de fecha, definiciones de estado). Esa consistencia evita “dos versiones de la verdad”.
Evita métricas de vanidad
Evita dashboards que sólo midan actividad (tickets creados, etiquetas añadidas). Prefiere métricas de resultado vinculadas a acción y respuesta: tiempo hasta primera respuesta, % de items que alcanzaron una decisión y problemas recurrentes que realmente se solucionaron.
Integra con las herramientas que tu equipo ya usa
Empieza con un modelo de datos sólido
Deja que Koder.ai genere la estructura de workspace, feedback, tags, events y replies con React y Go.
Un bucle de retroalimentación sólo funciona si vive donde la gente ya pasa tiempo. Las integraciones reducen el copiar/pegar, mantienen el contexto cerca del trabajo y hacen que “cerrar el ciclo” sea un hábito en lugar de un proyecto especial.
Empieza por integraciones que desbloqueen el trabajo diario
Prioriza los sistemas que tu equipo usa para comunicarse, construir y gestionar clientes:
- Slack / Microsoft Teams: notifica el canal correcto cuando llega retroalimentación de alto impacto, cuando se asigna un owner o cuando se responde a un cliente
- Jira / Linear: vincula la retroalimentación a un issue (o crea uno) para que el trabajo de ingeniería sea trazable hacia la retroalimentación real
- Sincronización CRM (Salesforce/HubSpot): adjunta retroalimentación a cuentas/contactos para que soporte y success tengan contexto completo
Mantén la primera versión simple: notificaciones unidireccionales + enlaces profundos a tu app, y luego añade acciones de escritura (p. ej., “Asignar owner” desde Slack) más adelante.
Añade un sistema de webhooks para extensibilidad
Aunque lances solo unas pocas integraciones nativas, los webhooks permiten que clientes y equipos internos conecten cualquier otra cosa.
Ofrece un conjunto pequeño y estable de eventos:
feedback.createdfeedback.updatedfeedback.closed
Incluye una clave de idempotencia, timestamps, tenant/workspace id y un payload mínimo más una URL para obtener detalles completos. Esto evita romper consumidores cuando evolucionas tu modelo de datos.
Haz visibles y recuperables las fallas
Las integraciones fallan por razones normales: tokens revocados, límites de tasa, problemas de red, desajustes de esquema.
Diseña para esto desde el principio:
- Reintentos con backoff para errores transitorios
- Una dead-letter queue para fallos repetidos
- Una página simple de salud de integraciones (último éxito, último error, próximo reintento)
- Estados de error accionables en la UI (p. ej., “Reconectar Slack” o “Permiso faltante en Jira”)
Si empaquetas esto como producto, las integraciones son también un disparador de compra. Añade pasos claros desde tu app (y la web) a /pricing y /contact para equipos que quieran demo o ayuda conectando su stack.
Lanza un MVP y mejora con datos reales de uso
Una app de retroalimentación efectiva no está “terminada” tras el lanzamiento: se moldea por cómo los equipos triagean, actúan y responden. El objetivo de tu primera versión es simple: probar el workflow, reducir esfuerzo manual y capturar datos limpios en los que puedas confiar.
Define un MVP pequeño pero completo
Mantén el alcance ajustado para poder lanzar rápido y aprender. Un MVP práctico suele incluir:
- Un workspace (sin complejidad multi‑org todavía)
- Una bandeja central con búsqueda y filtros básicos
- Etiquetado/categorización y asignación simple
- Un flujo de respuesta básico (aunque sean plantillas de email simples al principio)
Si una función no ayuda a procesar retroalimentación de extremo a extremo, puede esperar.
Prueba lo que rompe la confianza
Los usuarios iniciales perdonarán funciones faltantes, pero no retroalimentación perdida o ruteo incorrecto. Enfoca las pruebas donde los errores son caros:
- Tests unitarios para reglas de ruteo, lógica de etiquetado y comprobaciones de permisos
- Tests de integración para fuentes de ingestión y webhooks (incluyendo reintentos y eventos duplicados)
Apunta a confianza en el workflow, no cobertura perfecta.
Planea para la realidad operativa
Incluso un MVP necesita unos pocos elementos “aburridos” esenciales:
- Monitorización de fallos de ingestión y acumulación en colas
- Backups y un proceso de restauración que hayas probado realmente
- Seguimiento de errores con suficiente contexto para reproducir problemas
- Herramientas admin ligeras (reproducir un evento, reasignar items, corregir etiquetas malas)
Despliega como un experimento de producto
Comienza con un piloto: un equipo, un conjunto limitado de canales y una métrica clara de éxito (p. ej., “responder al 90% de retroalimentación de alta prioridad dentro de 2 días”). Recopila puntos de fricción semanalmente y itera el workflow antes de invitar a más equipos.
Trata los datos de uso como tu roadmap: dónde hacen clic las personas, dónde abandonan, qué etiquetas no se usan y qué “workarounds” revelan requisitos reales.