Define el problema, los usuarios y el alcance del MVP
Antes de dibujar pantallas o elegir una pila tecnológica, especifica qué problema resuelve tu aplicación de reclutamiento y para quién. “Coincidencia candidato-empleo” puede significar desde un filtro por palabras clave hasta un flujo guiado que ayuda a un reclutador a llevar un puesto desde la recepción hasta la colocación.
Nombra a los usuarios primarios (y lo que necesitan)
Empieza por las personas que abrirán sesión todos los días. Para una app de agencias de reclutamiento, suelen ser:
- Reclutadores: necesitan encontrar candidatos cualificados rápido, guardar notas, seguir el outreach y presentar shortlists con confianza.
- Administradores de agencia: necesitan visibilidad del equipo, procesos consistentes, permisos e informes.
- Hiring managers (opcional para v1): pueden querer revisar candidatos enviados, dar feedback y ver el progreso de entrevistas —pero añadirlos cambia la UX, permisos y notificaciones, así que decide pronto.
Un ejercicio útil es escribir 2–3 “tareas principales” por usuario. Si una función no soporta esas tareas, probablemente no entra en el MVP.
Define métricas de éxito que realmente puedas medir
Evita objetivos vagos como “mejores matches”. Elige métricas que reflejen resultados de negocio y reduzcan trabajo manual:
- Tiempo hasta la primera shortlist: cuánto tarda desde la creación del puesto hasta enviar una lista cualificada.
- Tasa de colocación / fill rate: roles cubiertos por roles trabajados.
- Pasos manuales eliminados: p. ej., menos copiar/pegar de email a notas, menos hojas de cálculo, menos registros duplicados.
- Productividad del reclutador: roles gestionados por reclutador sin caída en la calidad.
Estas métricas informarán más tarde tus análisis de reclutamiento y ayudarán a validar si tu algoritmo de emparejamiento mejora los resultados.
Mapea el flujo de trabajo de la agencia de extremo a extremo
El flujo de reclutamiento es más que el emparejamiento. Documenta las etapas y qué datos se crean en cada paso:
Sourcing → Screening → Submitting → Interviewing → Offer → Placement
Para cada etapa, indica los “objetos” implicados (candidato, puesto, envío, entrevista), las acciones clave (registrar llamada, enviar email, agendar entrevista) y los puntos de decisión (rechazar, avanzar, mantener). Aquí es donde las funciones de ATS y CRM suelen solaparse—sé intencional sobre lo que rastreas.
Delimita con firmeza el alcance del MVP
Tu MVP debe entregar un bucle usable: crear una requisición → añadir candidatos (manual o parseo básico) → emparejar → revisar → enviar.
Inclusiones comunes en v1:
- Gestión de perfiles de candidatos (campos esenciales, subida de CV, notas)
- Gestión de requisiciones (título, requisitos, ubicación, rango salarial)
- Emparejamiento simple (reglas + puntuación) con cierta explicabilidad ("coincidió porque: Java, 5+ años, Berlín")
- Un pipeline mínimo (por ejemplo, New, Shortlisted, Submitted, Interview, Hired)
Funciones comunes para más adelante (agradables pero prescindibles al inicio):
- Integración con bolsas de empleo e import/export con ATS
- Parseo avanzado de CV y enriquecimiento
- Portal para hiring managers con bucles de feedback
- Automatizaciones complejas (secuencias de outreach, SLAs, alertas avanzadas)
- Herramientas GDPR completas (más allá de lo esencial como consentimientos y borrado)
Al definir usuarios, métricas, flujo y alcance desde el inicio, evitas que el proyecto se convierta en “un ATS que lo hace todo” y mantienes el desarrollo enfocado en shortlists más rápidas y confiables.
Planea el modelo de datos (Candidatos, Puestos y Relaciones)
Una aplicación de reclutamiento vive o muere por su modelo de datos. Si candidatos, puestos y sus interacciones no están bien estructurados, el emparejamiento se vuelve ruidoso, los informes poco fiables y el equipo acaba luchando contra la herramienta en lugar de usarla.
Registros de candidato (qué almacenas vs qué buscas)
Comienza con una entidad Candidate que soporte tanto almacenamiento de documentos como campos buscables. Conserva el currículum original (archivo + texto extraído), pero normaliza también los atributos clave que necesitarás para el emparejamiento:
- Habilidades (preferible una lista estructurada y además un resumen en texto libre)
- Historial de experiencia (empresas, cargos, fechas)
- Preferencias (ubicaciones, remoto/onsite, industrias)
- Compensación (actual/esperada, moneda, tipo)
- Disponibilidad (preaviso, fecha de inicio)
Consejo: separa los datos “crudos” (texto parseado) de los campos “curados” que los reclutadores pueden editar. Eso evita que errores de parseo corrompan perfiles silenciosamente.
Registros de puesto (el objetivo contra el que emparejas)
Crea una entidad Job (requisición) con campos consistentes: título, seniority, habilidades obligatorias vs deseables, política de ubicación/remoto, rango salarial, estado (draft/open/on hold/closed) y detalles del hiring manager. Haz los requisitos lo suficientemente estructurados para puntuar, pero flexibles para descripciones reales.
Entidades de relación (el flujo real)
La mayor parte de la actividad ocurre entre candidatos y puestos, así que modela relaciones explícitas:
- Submissions (candidate ↔ job) con estado, timestamps y propiedad
- Interviews (etapa, hora programada, resultado)
- Notes y messages (vinculados a candidato, puesto y submission)
- Tasks (seguimientos con fecha y asignado)
Modelo de permisos (quién puede ver qué)
Define el acceso desde temprano: candidatos visibles a toda la agencia vs solo al equipo, visibilidad específica por cliente y derechos de edición según rol (reclutador, manager, admin). Ata los permisos a cada ruta de lectura/escritura para que candidatos privados o puestos confidenciales no se filtren por búsqueda o resultados de matching.
Diseña la UX central para reclutadores
Los reclutadores se mueven rápido: escanean, filtran, comparan y hacen seguimientos—a menudo entre llamadas. Tu UX debe hacer esos “siguientes clics” obvios y baratos.
Pantallas imprescindibles (y qué deben responder)
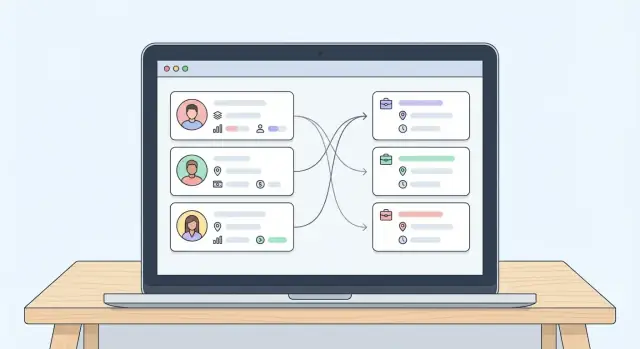
Empieza con cuatro páginas principales más una vista de matching:
- Lista de candidatos: “¿A quién debo mirar ahora?” Muestra nombre, titular, habilidades clave, ubicación, estado actual, última actividad e indicador rápido de match (si un puesto está seleccionado).
- Lista de puestos: “¿Qué roles estoy cubriendo y qué es urgente?” Muestra título del rol, ubicación/remoto, prioridad, conteos por etapa y propietario.
- Detalle de candidato: “¿Es viable esta persona y cuál es el siguiente paso?” Mantén un layout limpio: resumen, habilidades, experiencia, expectativas salariales, disponibilidad, notas y línea temporal de actividad.
- Detalle de puesto: “¿Qué significa ‘bueno’ para este rol?” Incluye requisitos, deseables, rango salarial, etapas de entrevista y quién contrata.
- Vista de match: Comparación lado a lado que explique por qué alguien coincide (y por qué no). Facilita acciones: preseleccionar, rechazar, pedir más info o agendar.
Búsqueda rápida y filtros que parezcan instantáneos
Los reclutadores esperan que la búsqueda se comporte como una barra de comandos. Ofrece búsqueda global más filtros por habilidades, ubicación, años de experiencia, salario, estado y disponibilidad. Permite multi-selección y filtros guardados (p. ej., “Londres Java 5+ años < £80k”). Mantén los filtros visibles, con badges claros que indiquen lo activo.
Acciones masivas para flujos reales
Las acciones masivas ahorran horas cuando se trabaja con largas listas. Desde la lista de candidatos o la vista de match, soporta: etiquetado, cambio de estado, añadir a shortlist de un puesto y exportar emails. Incluye un toast de “deshacer” y muestra cuántos registros serán cambiados antes de confirmar.
Accesibilidad y básicos para móvil
Haz la UI amigable con teclado (estados de foco, orden lógico de tabulación) y legible (buen contraste, objetivos táctiles grandes). En móvil, prioriza el flujo lista → detalle, mantiene los filtros en un panel deslizable y asegura que las acciones clave (preseleccionar, email, cambiar estado) sean alcanzables con un pulgar.
Construye la lógica de matching: reglas, scoring y explicabilidad
El matching es el motor de una app de reclutamiento: decide quién aparece primero, quién se oculta y en quién confían los reclutadores para actuar. Un buen MVP empieza simple—reglas claras primero, scoring después—y añade matices conforme aprendes de resultados reales.
Empieza con reglas basadas en “gates” (filtros duros)
Comienza con no negociables que deben cumplirse antes de considerar a un candidato. Estas reglas mantienen los resultados relevantes y evitan “matches con alta puntuación pero imposibles”.
Gates típicos incluyen habilidades/certificaciones requeridas, restricciones de ubicación o autorización para trabajar, y solapamiento salarial (p. ej., las expectativas del candidato deben intersectar con el presupuesto del puesto).
Añade scoring para priorizar (señales suaves)
Una vez que un candidato pasa los gates, calcula una puntuación para ordenar las coincidencias. Mantén la primera versión transparente y ajustable.
Una mezcla de scoring práctica:
- % de coincidencia de habilidades: cuántas habilidades requeridas aparecen en el perfil del candidato
- Recencia: mayor peso a habilidades usadas recientemente o roles relevantes recientes
- Ajuste de seniority: alinear años de experiencia y nivel del rol (junior/mid/senior)
- Similitud por palabras clave: similitud ligera entre CV/perfil y descripción del puesto
Puedes expresar esto como una puntuación ponderada (pesos afinados con el tiempo):
score = 0.45*skill_match + 0.20*recency + 0.20*seniority_fit + 0.15*keyword_similarity
Requisitos “must-have” vs “nice-to-have”
Modela los requisitos del puesto en dos cubos:
- Must-have: si faltan, fallan el match (usados en gates)
- Nice-to-have: aumentan la puntuación si están presentes (usados en ranking)
Esto evita excluir candidatos sólidos por preferencias mientras se recompensa un mejor encaje.
Haz los matches explicables (y accionables)
Los reclutadores necesitan saber por qué un candidato coincidió —y por qué alguien no lo hizo. Muestra un breve desglose en la tarjeta de match:
- Gates pasados/fallados (p. ej., “Solapamiento salarial”, “Falta: certificación AWS”)
- Factores que impulsan la puntuación (p. ej., “8/10 skills coinciden”, “Proyecto reciente en React: +12”)
- Sugerencias para mejorar la calidad del match (p. ej., “Añadir ubicación preferida” o “Marcar cuándo se usó la skill por última vez”)
La buena explicabilidad convierte el matching de una caja negra a una herramienta que los reclutadores pueden ajustar, defender frente a hiring managers y usar con confianza.
Captación de candidatos, parseo y calidad de datos
La calidad de datos de candidatos es la diferencia entre “emparejar” y “adivinar”. Si los perfiles llegan en formatos inconsistentes, el mejor algoritmo seguirá produciendo resultados ruidosos. Diseña caminos de entrada fáciles para reclutadores y candidatos, y mejora progresivamente el parseo y la normalización.
Ingesta de perfiles: tres puntos de entrada prácticos
Ofrece varias formas de crear un perfil para que los equipos no se queden bloqueados:
- Entrada manual para leads rápidos y screening telefónicos (nombre, contacto, título actual, habilidades principales, ubicación, expectativas salariales).
- Subida de currículum (PDF/DOCX) para la mayoría de aplicantes entrantes.
- Pegado estilo LinkedIn (donde esté permitido): un cuadro de texto plano que capture resúmenes, experiencia y habilidades sin forzar un archivo.
Mantén un indicador claro de “confianza” en los campos (p. ej., “parseado”, “ingresado por usuario”, “verificado por reclutador”) para que los reclutadores sepan qué confiar.
Parseo de CV: empieza simple y luego mejora
En el MVP, prioriza la fiabilidad sobre la estructura perfecta:
- Extrae texto de los archivos subidos y almacena el texto bruto junto al documento original.
- Parseo ligero con heurísticas (detección de email/teléfono, separación de secciones Experiencia/Educación, reconocimiento básico de fechas).
- Más adelante, integra un servicio de parseo dedicado cuando el volumen lo justifique, pero mantiene tu modelo de datos interno estable para que cambiar de proveedor no rompa flujos.
Siempre permite que los reclutadores editen campos parseados y guarda un historial de auditoría de los cambios.
Normaliza habilidades y cargos con un vocabulario controlado
El matching funciona mejor cuando “JS”, “JavaScript” y “Javascript” mapean al mismo skill. Usa un vocabulario controlado con:
- Nombres canónicos para skills/cargos
- Sinónimos y variantes ortográficas
- Niveles opcionales (junior/mid/senior) y categorías (frontend, data, finanzas)
Aplica la normalización al guardar (y ejecútala de nuevo cuando el vocabulario se actualice) para que la búsqueda y el matching se mantengan consistentes.
Prevén duplicados con un flujo seguro de fusión
Los duplicados envenenan silenciosamente tu pipeline. Detecta posibles duplicados usando email y teléfono (más comprobaciones difusas opcionales por nombre + empresa). Cuando aparezca un conflicto, muestra una pantalla de merge guiada que:
- Resalte conflictos de campos
- Elija por defecto valores más recientes/verificados
- PresERVE los currículums originales, notas e historial de actividad
Así mantienes la base de datos limpia sin riesgo de pérdida accidental de datos.
Requisiciones de trabajo y configuración del pipeline de contratación
Mantén control total del código
Construye con Koder.ai y exporta el código fuente cuando quieras tener el repositorio.
Una app de matching solo es tan buena como los puestos dentro de ella. Si las requisiciones son inconsistentes, faltas de detalles clave o difíciles de actualizar, los reclutadores dejarán de confiar en los resultados. Tu objetivo es hacer la entrada de puestos rápida, estructurada y repetible, sin obligar a los usuarios a rellenar formularios interminables.
Captura de puestos: vías rápidas que encajen en flujos reales
Los reclutadores suelen comenzar puestos de tres maneras:
- Crear desde cero para roles nuevos o solicitudes urgentes.
- Duplicar un rol antiguo (el ahorro de tiempo más común) y editar solo lo que cambió.
- Importar desde un ATS más adelante, cuando el producto core esté estable y sepas qué ATS son prioritarios.
En la UI, trata “Duplicar puesto” como una acción de primera clase en la lista de puestos, no como una opción escondida.
Requisitos estructurados (lo que el matching puede usar)
Las descripciones libres son útiles para humanos, pero el matching necesita estructura. Captura requisitos en campos consistentes:
- Habilidades (con niveles cuando sea posible), más must-haves vs “nice-to-haves”
- Preguntas de screening (knockout vs informativas)
- Rango salarial (y si es flexible)
Mantenlo ligero: un reclutador debe poder añadir habilidades en segundos y luego refinar. Si tienes un paso de parseo, úsalo para sugerir campos —no para guardarlos automáticamente.
Etapas del pipeline por puesto
Haz el pipeline explícito y específico por puesto. Un valor por defecto simple funciona bien:
New → Shortlisted → Submitted → Interview → Offer → Placed
Cada relación candidato-puesto debe almacenar la etapa actual, el historial de etapas, el propietario y notas. Esto da a los reclutadores una fuente de verdad compartida y hace tus análisis significativos.
Plantillas de puesto que reducen trabajo repetido
Las plantillas ayudan a las agencias a estandarizar la entrada para roles comunes (p. ej., “Sales Development Rep” o “Picker de almacén”). Una plantilla debe prefijar etapas, preguntas de screening y habilidades must-have típicas —pero permitir ediciones rápidas por cliente.
Si quieres un flujo consistente, enruta la creación del puesto directamente hacia matching y shortlisting, y luego al pipeline, en lugar de dispersar estos pasos en distintas pantallas.
Cuentas de usuario, roles y seguridad básica
La seguridad es más fácil de acertar cuando se diseña desde la primera versión. Para una app de reclutamiento, la meta es simple: solo las personas correctas pueden acceder a datos de candidatos y cada cambio importante es trazable.
Autenticación (sign-in)
Empieza con email + contraseña, más recuperación de contraseña y verificación por email. Incluso en un MVP, añade algunas protecciones prácticas:
- Límite de intentos de inicio de sesión para reducir ataques por fuerza bruta
- MFA opcional para admins (y luego para todos)
- Timeouts de sesión sensatos, especialmente en máquinas compartidas
Para agencias grandes, planea una ruta de actualización a SSO (SAML/OIDC) para usar Google Workspace o Microsoft Entra ID. No tienes que construir SSO desde el día uno, pero evita decisiones que dificulten añadirlo más tarde.
Roles y permisos
Como mínimo, define dos roles:
- Admin: gestiona usuarios, roles, políticas de retención e integraciones
- Recruiter: trabaja con candidatos, puestos y etapas del pipeline
Si tu producto incluye un portal para clientes/hiring managers, trátalo como un conjunto de permisos aparte. Los clientes suelen necesitar acceso limitado (p. ej., solo a candidatos enviados a sus puestos, con detalles personales restringidos según tu modelo de privacidad).
Una buena regla: por defecto el menor acceso necesario, y añade permisos de forma intencional (p. ej., “puede exportar candidatos”, “puede ver campos de compensación”, “puede eliminar registros”).
Registros de auditoría (responsabilidad)
El reclutamiento implica muchos traspasos, así que un registro ligero de auditoría previene confusiones y construye confianza interna. Registra acciones clave como:
- Ediciones de candidato/perfil (quién cambió qué y cuándo)
- Envíos a puestos
- Cambios de etapa y motivos de rechazo
Mantén estos logs buscables en la app y protégelos contra edición.
Manejo seguro de archivos (CVs y documentos)
Los CVs son altamente sensibles. Guárdalos en almacenamiento de objetos privado (no URL públicas), exige enlaces de descarga firmados/expirables y escanea uploads por malware. Restringe acceso por rol y evita enviar adjuntos por email cuando un enlace seguro en la app sirve.
Finalmente, encripta datos en tránsito (HTTPS) y en reposo cuando sea posible, y haz que los valores seguros sean no opcionales para workspaces nuevos.
Privacidad, cumplimiento y confianza del candidato
Itera sin miedo
Guarda instantáneas antes de ajustar el ranking y revierte si los resultados empeoran.
Las apps de reclutamiento manejan datos muy sensibles—CVs, contactos, compensación, notas de entrevistas. Si los candidatos no confían en cómo almacenas y compartes esa información, no participarán y las agencias asumen riesgos legales innecesarios. Trata la privacidad y el cumplimiento como características centrales del producto, no añadidos.
Consentimiento y base legal (por agencia)
Diferentes agencias y regiones se basan en distintas bases legales (consentimiento, interés legítimo, contrato). Construye un rastreador configurable en cada registro de candidato que capture:
- La base legal usada (seleccionable por agencia)
- Qué acordó el candidato (p. ej., “compartir con cliente X” vs “compartir con cualquier cliente”)
- Timestamp, fuente y evidencia (formulario, respuesta de email, nota de importación)
Haz que el consentimiento sea fácil de revisar y actualizar, y asegúrate de que las acciones de compartir (enviar perfiles a clientes, exportar, añadir a campañas) comprueben esos ajustes.
Retención, eliminación y anonimización
Añade ajustes de retención a nivel agencia: cuánto tiempo conservar candidatos inactivos, aplicantes rechazados y notas de entrevistas. Luego implementa flujos claros:
- Eliminar cuando debas borrar datos personales por completo
- Anonimizar cuando necesites conservar reportes agregados pero quitar identificadores
Mantén estas acciones auditable y reversibles solo cuando corresponda.
Exportación de datos para solicitudes de acceso
Soporta la exportación del registro de un candidato para solicitudes de acceso. Hazlo simple: un export JSON estructurado más un resumen legible (PDF/HTML) cubren la mayoría de necesidades.
Almacenamiento seguro y acceso de menor privilegio
Usa cifrado en tránsito y en reposo, entornos separados y una gestión de sesiones robusta. Por defecto, asigna roles con el mínimo privilegio: los reclutadores no deben ver automáticamente compensación, notas privadas o todas las presentaciones a clientes.
Añade un log de auditoría para vistas/exportaciones/compartidos de datos de candidatos y enlaza la política desde /privacy para que las agencias puedan explicarle a los candidatos tus salvaguardas.
Integraciones: Email, Calendario, ATS y bolsas de empleo
Las integraciones deciden si tu app encaja naturalmente en el día a día del reclutador—o si será “otra pestaña más”. Apunta a un pequeño conjunto de conexiones de alto impacto primero, y deja lo demás detrás de una capa de API limpia para poder añadir sin reescribir workflows.
Integración de email (v1)
Empieza por email porque soporta outreach y crea un historial de actividad valioso.
Conecta con Gmail y Microsoft 365 para:
- Enviar emails de outreach desde la app (plantillas + tokens de personalización)
- Registrar conversaciones entrantes y salientes en los registros de candidato y puesto
- Adjuntar archivos y mantener una línea temporal de comunicación buscable
Mantenlo simple: guarda metadatos de mensaje (asunto, timestamp, participantes) y una copia segura del cuerpo para búsqueda. Haz el logging explícito para que los reclutadores elijan qué hilos pertenecen al sistema.
Integración de calendario (opcional para v1)
El calendario puede esperar si pone en riesgo tu calendario, pero es una mejora fuerte. Con Google Calendar / Outlook Calendar puedes crear eventos de entrevista, proponer horarios y registrar resultados.
Para versiones tempranas, céntrate en: crear eventos + añadir asistentes + escribir los detalles de la entrevista de vuelta al estado del pipeline del candidato.
Conexiones ATS y una capa clara de API/webhooks
Muchas agencias ya usan un ATS/CRM. Proporciona webhooks para eventos clave (candidate created/updated, stage changed, interview scheduled) y documenta tus endpoints REST para que partners conecten rápido. Considera una página dedicada como /docs/api y una pantalla ligera de “integration settings”.
Bolsas de empleo (fase 2)
Publicar en bolsas y recibir aplicantes es poderoso, pero añade complejidad (políticas de anuncios, aplicantes duplicados, seguimiento de origen). Trátalo como fase 2:
- Publica puestos en bolsas seleccionadas
- Ingiera aplicantes en tu flujo de gestión de perfiles
- Rastrea la fuente y atribuye hires con precisión
Diseña ahora tu modelo para que “source” y “canal de aplicación” sean campos de primera clase más adelante.
Elige la pila tecnológica y la arquitectura
Tu stack debe optimizar para lanzar un MVP fiable rápido, dejando espacio para mejor búsqueda e integraciones luego. Las apps de reclutamiento tienen dos necesidades distintas: workflows transaccionales (pipelines, permisos, logs) y búsqueda/puntuación rápida (emparejar candidatos con puestos).
Opciones de stack que permiten lanzar rápido
Para un stack moderno en JavaScript, React + Node.js (NestJS/Express) es una elección común: un solo lenguaje en frontend y backend, muchas librerías del mercado y trabajo de integración directo.
Si quieres CRUD rápido y convenciones fuertes, Rails o Django son excelentes para construir workflows core de ATS/CRM con menos decisiones. Combínalos con un frontend ligero (vistas Rails, templates Django) o React si necesitas UI más rica.
Si tu cuello de botella es prototipado rápido (especialmente para herramientas internas o validación temprana), una plataforma low-code como Koder.ai puede ayudarte a construir un MVP end-to-end desde una especificación de chat estructurada: pantallas core, workflows y un modelo de datos base. Los equipos la usan para iterar rápido en planning mode, y luego exportar código cuando están listos. Las snapshots y rollback también facilitan probar cambios de matching sin romper la app para los reclutadores.
Almacenamiento de datos: empieza relacional
Usa una base relacional (normalmente PostgreSQL) como fuente de la verdad. Los datos de reclutamiento son heavy en workflows: candidatos, puestos, etapas, notas, tareas, emails y permisos se benefician de transacciones y constraints.
Modela “documentos” (resumes, attachments) como archivos almacenados (S3-compatible) con metadatos en Postgres.
Búsqueda y ranking: crece en etapas
Empieza con Postgres full-text search para búsquedas por palabras clave y filtros. Muchas veces es suficiente para un MVP y evita añadir otro sistema.
Cuando el matching y la búsqueda sean un cuello de botella (ranking complejo, sinónimos, consultas difusas, alto volumen), añade Elasticsearch/OpenSearch como índice dedicado—alimentado de forma asíncrona desde Postgres.
Despliegue: controla riesgo y coste
Mantén entornos separados de staging y production para probar parseos, matching e integraciones con seguridad.
Configura backups automáticos, monitorización básica (errores, latencia, profundidad de colas) y controles de coste (retención de logs, instancias dimensionadas). Esto mantiene el sistema predecible a medida que agregas reclutadores y datos.
Analítica y bucles de feedback para mejorar el matching
Lanza un piloto rápido
Envía un piloto a reclutadores reales usando despliegue y hosting integrados.
El matching mejora cuando mides resultados y capturas el “por qué” de las decisiones de los reclutadores. La meta no son métricas de vanidad: es un bucle cerrado donde cada shortlist, entrevista y colocación hace tus recomendaciones más precisas.
Rastrea KPIs que reflejen velocidad real de reclutamiento
Comienza con un pequeño conjunto de KPIs que se mapearon al rendimiento de la agencia:
- Tiempo hasta shortlist: días desde creación del puesto hasta la primera shortlist cualificada.
- Colocaciones por reclutador: output mensual/trimestral, normalizado por requisiciones activas.
- Efectividad por fuente: qué canales producen candidatos que llegan a entrevista/oferta.
Mantén los KPIs filtrables por cliente, tipo de rol, seniority y reclutador. Eso hace que los números sean accionables, no promedios vagos.
Construye un bucle de feedback de calidad de match
Añade feedback ligero donde se toman decisiones (lista de matches y perfil del candidato): pulgar arriba/abajo, más razones opcionales (p. ej., “desajuste salarial”, “falta certificación”, “ubicación/visa”, “mala tasa de respuesta”).
Vincula el feedback a outcomes:
- shortlists aceptadas
- entrevistas agendadas
- ofertas hechas
- placements
- rechazos (y motivo declarado)
Esto te permite comparar tu scoring con la realidad y ajustar pesos o reglas con evidencia.
Crea algunos informes por defecto:
- Salud del pipeline: conteos por etapa, tasas de conversión y cuellos de botella.
- Candidatos envejecidos: perfiles fuertes sin actividad en X días.
- Tasa de llenado de puestos: abiertos vs cubiertos, más tiempo medio en cada etapa.
Dashboards legibles y exportables
Los dashboards deben responder “¿qué cambió esta semana?” en una pantalla y permitir drill-down. Haz todas las tablas exportables a CSV/PDF para actualizaciones a clientes y revisiones internas, y mantén las definiciones visibles (tooltip o /help) para que todos interpreten las métricas igual.
Pruebas, lanzamiento y hoja de ruta de iteración
Una app de reclutamiento triunfa cuando funciona de forma fiable con puestos reales, candidatos reales y plazos reales. Trata el lanzamiento como el inicio del aprendizaje —no la meta final.
Checklist de lanzamiento del MVP (qué significa “listo”)
Antes de invitar a tus primeros usuarios, asegúrate de que lo básico no solo esté construido, sino usable de extremo a extremo:
- Datos semilla: 10–20 candidatos realistas y 5–10 puestos que reflejen tu nicho objetivo (incluyendo CVs desordenados y perfiles incompletos).
- Onboarding: un flujo inicial que cree un puesto, importe candidatos y muestre la primera shortlist en menos de 10 minutos.
- Permisos: roles como Admin/Recruiter/Viewer y valores por defecto seguros (los usuarios nuevos deben ver solo lo necesario).
- Plantillas de email: solicitudes de entrevista, outreach y mensajes de “app recibida” con branding y variables consistentes.
Enfoque de pruebas que proteja la calidad del matching
No necesitas una suite enorme, pero sí las pruebas correctas:
- Tests unitarios para scoring: fija resultados esperados en escenarios clave (habilidades must-have, reglas de ubicación, rangos salariales, dealbreakers). Esto evita cambios silenciosos en el ranking.
- Tests end-to-end para workflows: crear puesto → importar candidato → ejecutar match → enviar email → mover etapa. Esto detecta roturas en integración entre pantallas.
Plan de despliegue: empieza pequeño, aprende rápido
Pilota con 1–3 agencias (o equipos internos) que den feedback semanal. Define métricas de éxito por adelantado: tiempo hasta shortlist, menos intercambios de email y confianza del reclutador en las explicaciones del match.
Corre en cadencia de dos semanas: recopila issues, arregla los bloqueadores top y publica mejoras. Publica cambios en un changelog ligero (una simple /blog funciona bien).
Próximos hitos tras el MVP
Una vez el flujo core sea estable, prioriza:
- Automatización: recordatorios, follow-ups, nudges por etapa, detección de duplicados.
- Resúmenes asistidos por IA: borradores de highlights de candidatos y razonamiento job-to-candidate (con edición sencilla).
- Portal para clientes: compartir shortlists, recoger feedback y aprobar entrevistas sin largas cadenas de email.
A medida que añadas niveles (portal, integraciones, analítica avanzada), mantén el empaquetado claro en /pricing.