Lo que vas a construir: la app web IDP en términos sencillos
Una app web IDP es una “puerta de entrada” interna a tu sistema de ingeniería. Es donde los desarrolladores van a descubrir lo que ya existe (servicios, librerías, entornos), seguir la forma preferida de construir y ejecutar software, y solicitar cambios sin buscar entre una docena de herramientas.
Igualmente importante, no es otro reemplazo todo-en-uno de Git, CI, consolas cloud o ticketing. El objetivo es reducir la fricción orquestando lo que ya usas: hacer que el camino correcto sea el más fácil.
Los problemas que debe resolver
La mayoría de equipos construyen una app web IDP porque el trabajo diario se ve frenado por:
- Proliferación de herramientas: el conocimiento de “dónde hacer clic” vive en la memoria tribal.
- Onboarding lento: los ingenieros nuevos pasan semanas aprendiendo procesos en vez de enviar código.
- Estándares inconsistentes: los servicios se crean y operan de formas distintas, lo que complica fiabilidad y seguridad.
La app web debe convertir esto en flujos repetibles e información clara y searchable.
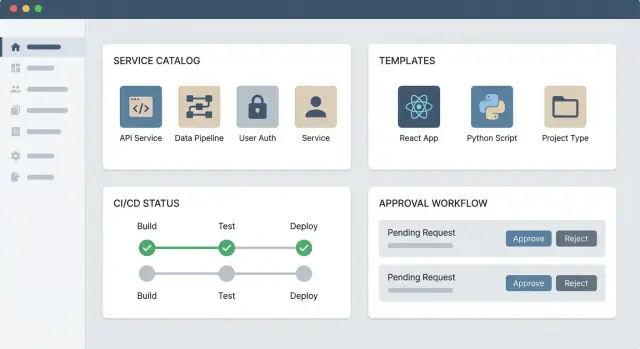
Bloques básicos
Una app web IDP práctica suele tener tres partes:
- UI del portal: un catálogo de servicios, puntos de entrada a documentación y formularios autoservicio (p. ej., “crear un servicio”, “solicitar acceso”, “provisionar una base de datos”).
- APIs backend: la lógica de negocio que valida solicitudes, aplica políticas y registra acciones.
- Integraciones: conectores a tu cadena de herramientas (alojamiento de Git, CI/CD, herramientas de infra, secretos, gestión de incidentes) para que las acciones ocurran en los sistemas de registro.
Quién lo posee (y quién no)
El equipo de plataforma típicamente posee el producto del portal: la experiencia, las APIs, las plantillas y los guardrails.
Los equipos de producto poseen sus servicios: mantener la metadata precisa, mantener docs/runbooks y adoptar las plantillas provistas. Un modelo sano es de responsabilidad compartida: el equipo de plataforma construye la vía pavimentada; los equipos de producto conducen por ella y ayudan a mejorarla.
Usuarios, casos de uso y métricas de éxito
Un portal IDP tiene éxito o fracasa según si sirve a las personas correctas con los “caminos felices” adecuados. Antes de elegir herramientas o dibujar diagramas de arquitectura, aclara quién usará el portal, qué intentan lograr y cómo medirás el progreso.
Usuarios principales (y qué les importa)
La mayoría de portales IDP tienen cuatro audiencias centrales:
- Desarrolladores de aplicaciones: quieren valores seguros y rápidos por defecto para crear y ejecutar servicios sin esperar tickets.
- SRE / ops: quieren estandarización, menos cambios sorpresa y propiedad clara cuando ocurren incidentes.
- Seguridad / cumplimiento: quieren controles consistentes (revisiones de acceso, manejo de secretos, trazas de auditoría) sin bloquear la entrega.
- Managers de ingeniería / líderes de producto: quieren visibilidad: qué existe, quién lo posee y si los equipos están entregando de forma fiable.
Si no puedes describir en una frase cómo cada grupo se beneficia, probablemente estás construyendo un portal que se siente opcional.
Mapea 5–10 recorridos clave
Elige recorridos que ocurran semanalmente (no anualmente) y hazlos verdaderamente end-to-end:
- Crear un servicio nuevo desde una plantilla (repo + CI + ownership + tags).
- Solicitar un entorno (dev/stage) con guardrails.
- Ver la salud del servicio (estado de deploy, alertas, dependencias).
- Rotar claves / secretos con un flujo auditable.
- Solicitar acceso a un sistema o dataset con aprobaciones.
Escribe cada recorrido como: trigger → steps → systems touched → expected outcome → failure modes. Esto se convierte en tu backlog de producto y en los criterios de aceptación.
Define métricas de éxito que puedas rastrear
Las buenas métricas se atan directamente al tiempo ahorrado y la fricción eliminada:
- Tiempo hasta el primer deploy para un nuevo servicio (mediana, p90).
- Volumen de tickets manuales para solicitudes comunes (y tiempo de resolución).
- Tasa de adopción: % de servicios registrados, % de equipos usando plantillas.
- Tasa de fallos de cambio y tiempo medio de recuperación (si el portal estandariza la entrega).
Escribe una declaración de alcance “versión 1”
Manténla corta y visible:
Alcance V1: “Un portal que permite a los desarrolladores crear un servicio desde plantillas aprobadas, registrarlo en el catálogo de servicios con un propietario y mostrar estado de deploy + salud. Incluye RBAC básico y registros de auditoría. Excluye dashboards personalizados, reemplazo completo de CMDB y flujos a medida.”
Esa declaración es tu filtro contra el feature-creep y tu ancla de roadmap.
Alcance del MVP y roadmap para un portal interno
Un portal interno tiene éxito cuando resuelve un problema doloroso end-to-end y luego se gana el derecho a expandirse. El camino más rápido es un MVP estrecho lanzado a un equipo real en semanas —no en trimestres.
Un MVP estrecho que aún se sienta “completo”
Comienza con tres bloques:
- Catálogo de servicios: un lugar para descubrir qué existe, quién lo posee y dónde están los enlaces operativos.
- Un flujo autoservicio: elige una solicitud de alta frecuencia (p. ej., “crear un nuevo repo de servicio” o “provisionar un entorno estándar”) y automatízala.
- Hub de docs/enlaces: no migres todo—enlaza a las fuentes de verdad existentes (CI/CD, herramientas de incidentes, runbooks) mientras aprendes qué usan realmente las personas.
Este MVP es pequeño, pero entrega un resultado claro: “Puedo encontrar mi servicio y realizar una acción importante sin pedir ayuda en Slack.”
Si quieres validar la UX y el flujo feliz rápidamente, una plataforma de prototipado como Koder.ai puede ser útil para prototipar la UI del portal y las pantallas de orquestación a partir de una especificación de flujo escrita. Porque Koder.ai puede generar una app React con backend en Go + PostgreSQL y soporta exportación de código fuente, los equipos pueden iterar rápido y mantener propiedad a largo plazo del código.
Estructura del backlog: descubrir, crear, operar, gobernar
Para mantener el roadmap organizado, agrupa el trabajo en cuatro cubos:
- Descubrir: búsqueda, etiquetas, propiedad, páginas de equipo, vistas de dependencias.
- Crear: plantillas, scaffolding, aprovisionamiento de entornos, configuraciones estándar.
- Operar: enlaces a dashboards/runbooks, info de on-call, resúmenes de SLO, acciones comunes.
- Gobernar: RBAC, pasos de aprobación, registros de auditoría, checks de políticas.
Esta estructura evita un portal que sea “todo catálogo” o “toda automatización” sin nada que lo ate.
Automatizar ahora vs. enlazar externamente
Automatiza solo lo que cumple al menos uno de estos criterios: (1) se repite semanalmente, (2) es propenso a errores cuando se hace manualmente, (3) requiere coordinación multi-equipo. Todo lo demás puede ser un enlace bien curado hacia la herramienta adecuada, con instrucciones claras y propiedad.
Mejora progresiva sin rediseños
Diseña el portal para que nuevos flujos se enchufen como “acciones” adicionales en la página de un servicio o entorno. Si cada nuevo flujo requiere repensar la navegación, la adopción se estancará. Trata los flujos como módulos: entradas consistentes, estado consistente, historial consistente—para que puedas añadir más sin cambiar el modelo mental.
Arquitectura de referencia: UI, APIs e integraciones
Una arquitectura práctica mantiene la experiencia de usuario simple mientras maneja el trabajo “desordenado” de integraciones detrás de escena. El objetivo es dar a los desarrolladores una app web, aunque las acciones a menudo abarquen Git, CI/CD, cuentas cloud, ticketing y Kubernetes.
Elige un modelo de despliegue
Hay tres patrones comunes; la elección correcta depende de la velocidad de entrega y de cuántos equipos extenderán el portal:
- App única (monolito): MVP más rápido. UI, API y lógica de integración se entregan juntas. Bueno cuando el equipo de plataforma posee la mayoría de funciones.
- Servicios modulares: UI, API core y algunos servicios de integración separados. Más fácil de escalar y con propiedad más clara a medida que crece el portal.
- Basado en plugins: un “core” estable más plugins para fuentes de catálogo, scaffolding, docs y flujos. Mejor cuando muchos equipos contribuyen funciones.
Componentes core (qué corre dónde)
Como mínimo, espera estos bloques:
- Web UI (portal de desarrolladores): exploración de catálogo, rutas recomendadas, formularios, páginas de estado.
- API backend (a menudo detrás de un API gateway): auth, checks RBAC, validación, orquestación.
- Workers de integración: tareas de larga duración (creación de repos, aprovisionamiento) ejecutadas asíncronamente.
- Base de datos: configuración del portal, vistas cacheadas del catálogo, historial de flujos, eventos de auditoría.
Dónde debe residir el estado
Decide pronto qué “posee” el portal versus qué solo muestra:
- Mantén la fuente de la verdad en sistemas existentes (Git, cloud IAM, CI/CD, Kubernetes, ticketing).
- Almacena en la DB del portal: solicitudes de flujo, estado, aprobaciones, registros de auditoría e índices cacheados que aceleran la UI.
Fiabilidad de las integraciones
Las integraciones fallan por razones normales (límites de tasa, caídas transitorias, éxitos parciales). Diseña para:
- Reintentos con backoff y mensajes de error claros
- Idempotencia (re-ejecutar una solicitud no debe crear duplicados)
- Timeouts y cancelación
- Historial duradero del flujo para que los usuarios vean qué pasó y se recuperen con seguridad
Modelo de datos: catálogo de servicios y propiedad
Tu catálogo de servicios es la fuente de verdad sobre qué existe, quién lo posee y cómo encaja en el resto del sistema. Un modelo de datos claro evita “servicios misteriosos”, entradas duplicadas y automatizaciones rotas.
Define la entidad core “Service”
Empieza acordando qué significa “servicio” en tu organización. Para la mayoría, es una unidad desplegable (API, worker, web) con un ciclo de vida.
Como mínimo, modela estos campos:
- Nombre + descripción (legible por humanos)
- Propietarios: un equipo primario, más contactos secundarios opcionales (grupo on-call, tech lead)
- Repositorios de origen: uno o varios links/IDs de repo
- Entornos de runtime: dev/stage/prod, o variantes por región
- Dependencias: servicios upstream/downstream y librerías compartidas
Agrega metadata práctica que alimenta portales:
- Lifecycle (experimental, activo, deprecated)
- Criticidad/tiér (para expectativas de soporte y gobernanza)
- Enlaces (runbooks, dashboards, SLOs, canal de incidentes)
Modela relaciones explícitamente
Trata las relaciones como primera clase, no solo campos de texto:
- Services ↔ teams: muchos servicios por equipo; a veces propiedad compartida (usa
primary_owner_team_id más additional_owner_team_ids).
- Services ↔ resources: conéctalos a recursos cloud (namespaces de Kubernetes, colas, bases de datos) para responder “¿qué usa este servicio?”.
- Tiers de servicio: guarda el tier como enum estructurado y enlázalo a políticas (p. ej., tier-0 requiere on-call y registros de auditoría).
Esta estructura relacional permite páginas como “todo lo que posee el Equipo X” o “todos los servicios que tocan esta base de datos.”
Identificadores y reglas de nombrado
Decide pronto la ID canónica para que no aparezcan duplicados tras importaciones. Patrones comunes:
- Un slug estable (p. ej.,
payments-api) único
- Un UUID inmutable más un slug legible
- Opcional: una clave derivada del repo (
github_org/repo) si los repos son 1:1 con servicios
Documenta reglas de nombre (caracteres permitidos, unicidad, política de renombrado) y valídalas en creación.
Plan para mantener los datos frescos
Un catálogo falla cuando queda obsoleto. Elige o combina:
- Importaciones programadas (sync nocturno desde Git, CI/CD, inventario cloud)
- Webhooks (actualizar en cambios de repo, deploys, cambios de ownership)
- Streams de eventos (publicar eventos como “service.created” o “dependency.updated”)
Mantén last_seen_at y data_source por registro para mostrar frescura y depurar conflictos.
Autenticación, autorización y auditabilidad
Prueba la UX del portal rápido
Crea una interfaz de portal en React y itera formularios y navegación en horas, no semanas.
Si tu portal IDP va a ser de confianza, necesita tres cosas que funcionen en conjunto: autenticación (¿quién eres?), autorización (¿qué puedes hacer?) y auditabilidad (¿qué pasó y quién lo hizo?). Haz esto bien desde temprano y evitarás rehacer cuando el portal empiece a tocar cambios en producción.
Por defecto, usa SSO con mapeo de grupos
La mayoría ya tiene infraestructura de identidad. Úsala.
Haz del SSO vía OIDC o SAML la ruta de ingreso por defecto y extrae miembros de grupos desde tu IdP (Okta, Azure AD, Google Workspace, etc.). Luego mapea grupos a roles del portal y membresía de equipos.
Esto simplifica el onboarding (“inicia sesión y ya estás en los equipos correctos”), evita almacenar contraseñas y permite a IT aplicar políticas globales como MFA y timeouts de sesión.
Define roles claros (y qué pueden hacer)
Evita un modelo vago “admin vs todos”. Un conjunto práctico de roles es:
- Developer: navegar el portal, usar plantillas y flujos autoservicio dentro de los alcances permitidos.
- Service Owner: gestionar la entrada del catálogo de servicios (metadata, on-call, lifecycle), ver historial específico del servicio.
- Approver: aprobar o rechazar solicitudes sensibles (acceso a prod, nuevos entornos, recursos con impacto de coste).
- Platform Admin: gestionar plantillas, integraciones, settings globales y valores por defecto de política.
- Auditor: acceso de solo lectura a logs de auditoría, aprobaciones e historial de configuración.
Mantén los roles simples y comprensibles. Puedes extender luego; un modelo confuso baja la adopción.
RBAC más permisos a nivel de recurso
RBAC es necesario pero no suficiente. El portal también necesita permisos a nivel de recurso: el acceso debe estar acotado a un equipo, un servicio o un entorno.
Ejemplos:
- Un desarrollador puede ejecutar “crear entorno sandbox” para los servicios de su equipo, pero no para otros.
- Un owner de servicio puede editar la entrada del catálogo del servicio que posee.
- Un aprobador puede aprobar solicitudes solo para centros de coste o namespaces de producción específicos.
Implementa esto con un patrón de política simple: (principal) puede (acción) sobre (recurso) si (condición). Empieza con scoping por equipo/servicio y crece desde ahí.
Trazas de auditoría para acciones sensibles
Trata los logs de auditoría como una característica de primera clase, no un detalle de backend. El portal debe registrar:
- Quién inició un flujo autoservicio (y desde dónde)
- Valores de parámetros enviados (redactar secretos)
- Quién aprobó/denegó y comentarios
- Cambios resultantes (enlaces a runs de CI/CD, tickets o cambios infra)
- Cambios a plantillas, permisos e integraciones
Haz que las trazas sean accesibles desde los lugares donde la gente trabaja: la página del servicio, una pestaña “Historial” del flujo y una vista admin para compliance. Esto acelera las revisiones de incidentes cuando algo falla.
Diseño UX para desarrolladores: facilitar el camino correcto
Un buen UX para IDP no se trata de verse bonito, sino de reducir la fricción cuando alguien intenta entregar. Los desarrolladores deben poder responder tres preguntas rápido: ¿Qué existe? ¿Qué puedo crear? ¿Qué necesita atención ahora?
Diseña la navegación alrededor de tareas reales
En lugar de organizar menús por sistemas backend (“Kubernetes”, “Jira”, “Terraform”), estructura el portal alrededor del trabajo que hacen los desarrolladores:
- Descubrir: encontrar servicios, APIs, docs, propietarios, runbooks
- Crear: iniciar un servicio nuevo, añadir un endpoint, solicitar una base de datos
- Operar: ver salud, incidentes, estado de deploy, cambios recientes
- Gobernar: permisos, checks de cumplimiento, excepciones de política
Esta navegación basada en tareas también facilita el onboarding: los nuevos no necesitan conocer tu toolchain para empezar.
Haz que la propiedad sea imposible de ignorar
Cada página de servicio debe mostrar claramente:
- Equipo propietario y canal del equipo
- Rotación on-call y path de escalado
- Repo(s) primario(s) y target de despliegue
Coloca este panel “¿Quién posee esto?” cerca de la parte superior, no enterrado en una pestaña. Cuando ocurren incidentes, los segundos cuentan.
Búsqueda, filtros y estado que coincidan con cómo piensa la gente
La búsqueda rápida es la característica potente del portal. Soporta filtros que los desarrolladores usan de forma natural: equipo, lifecycle (experimental/producción), tier, lenguaje, plataforma y “propiedad mía”. Añade indicadores de estado nítidos (healthy/degraded, SLO en riesgo, bloqueado por aprobación) para que los usuarios puedan escanear y decidir qué hacer.
Al crear recursos, pide solo lo estrictamente necesario ahora. Usa plantillas (“rutas recomendadas”) y valores por defecto para evitar errores evitables: convenciones de nombres, hooks de logging/métricas y ajustes CI estándar deben venirse prellenados. Si un campo es opcional, ocúltalo en “Opciones avanzadas” para mantener el camino feliz rápido.
Flujos autoservicio: plantillas, aprobaciones e historial
Reduce costes mientras aprendes
Gana créditos compartiendo lo que creaste o invitando a otros a probar Koder.ai.
El autoservicio es donde un portal interno gana confianza: los desarrolladores deben completar tareas comunes end-to-end sin abrir tickets, mientras el equipo de plataforma mantiene control sobre seguridad, cumplimiento y coste.
Elige los tipos de flujo que importan primero
Comienza con un pequeño conjunto de flujos que mapeen a solicitudes frecuentes y de alta fricción. Los “primeros cuatro” típicos:
- Crear servicio: scaffold de repo, registrar en el catálogo, asignar propiedad y bootstrap de CI/CD.
- Provisionar entorno: crear un entorno dev/stage con red, logging y presupuestos estándar.
- Solicitar acceso: conceder acceso con menor privilegio (base de datos, cola, API externa) con opción de expiración.
- Rotar secretos: disparar la rotación, actualizar configs downstream y validar que las apps quedan sanas.
Estos flujos deben ser opinados y reflejar tu ruta recomendada, permitiendo opciones controladas (runtime, región, tier, clasificación de datos).
Define un contrato de flujo (para que las plantillas sean predecibles)
Trata cada flujo como una API de producto. Un contrato claro hace los flujos reusables, testeables y más fáciles de integrar con tu cadena de herramientas.
Un contrato práctico incluye:
- Inputs: campos tipados con defaults (p. ej., nombre del servicio, equipo propietario, entorno, sensibilidad de datos).
- Validación: reglas de nombre, regiones permitidas, checks de cuota y “¿esto ya existe?”.
- Steps: secuencia de acciones (ejecutar plantilla, llamar a CI/CD, crear recursos cloud, actualizar catálogo).
- Outputs: artefactos y enlaces que los desarrolladores necesitan (URL del repo, URL de despliegue, link al runbook, recursos creados).
Mantén la UX enfocada: muestra solo los inputs que el desarrollador realmente puede decidir e infiere el resto desde el catálogo y la política.
Aprobaciones rápidas, claras y ejecutables
Las aprobaciones son inevitables para ciertas acciones (acceso a prod, datos sensibles, aumentos de coste). El portal debe hacer las aprobaciones predecibles:
- Quién aprueba qué: define aprobadores basados en reglas (owner del equipo, owner del sistema, seguridad) en vez de pings ad-hoc.
- Límites de tiempo: establece un SLA para aprobación y expira solicitudes obsoletas.
- Escalado: si el aprobador principal no está disponible, enruta a un backup o a la rotación on-call.
Crucialmente, las aprobaciones deben ser parte del motor de flujos, no un canal manual. El desarrollador debe ver estado, próximos pasos y por qué se requiere una aprobación.
Almacena historial y resultados para que los equipos se autodiagnostiquen
Cada ejecución de flujo debe producir un registro permanente:
- Inputs usados, resultados de validación y decisiones de aprobadores
- Logs paso a paso (con secretos redactados)
- Outputs finales, recursos creados y acciones de rollback
Este historial es tu “rastro de papel” y tu sistema de soporte: cuando algo falla, los desarrolladores pueden ver exactamente dónde y por qué —a menudo resolviendo sin abrir un ticket. También da al equipo de plataforma datos para mejorar plantillas y detectar fallos recurrentes.
Integraciones: conectar el portal a tu herramienta
Un portal IDP solo se siente “real” cuando puede leer y actuar sobre los sistemas que ya usan los desarrolladores. Las integraciones convierten una entrada del catálogo en algo que puedes desplegar, observar y soportar.
Empieza con una checklist clara de integraciones
La mayoría de portales necesitan un set base de conexiones:
- Git (repos, ramas por defecto, CODEOWNERS, pull requests)
- CI/CD (pipelines, estado de build, artefactos, promociones)
- Kubernetes (clusters, namespaces, workloads, rollouts)
- Cloud (cuentas/proyectos, networking, servicios gestionados)
- IAM (equipos, grupos, SSO, mapeos de roles)
- Secretos (vaults, referencias a secretos, estado de rotación)
Sé explícito sobre qué datos son solo lectura (p. ej., estado de pipeline) vs escritura (p. ej., disparar un despliegue).
Prefiere API-first; usa webhooks o sync cuando debas
Las integraciones API-first son más fáciles de razonar y testear: puedes validar auth, esquemas y manejo de errores.
Usa webhooks para eventos casi en tiempo real (PR mergeado, pipeline finalizado). Usa sync programado para sistemas que no pueden empujar eventos o donde la consistencia eventual es aceptable (p. ej., importación nocturna de cuentas cloud).
Construye una capa de conectores (no amases vendors en el core)
Crea un “conector” fino que normalice detalles vendor-specific en un contrato interno estable (p. ej., Repository, PipelineRun, Cluster). Esto aisla cambios cuando migras herramientas y mantiene la UI/API del portal limpia.
Un patrón práctico es:
- El portal llama a tu conector
- El conector maneja auth, rate limits, reintentos y mapeo
- El conector devuelve datos normalizados + enlaces accionables (p. ej.,
/deployments/123)
Documenta modos de fallo y qué debe hacer el usuario
Cada integración debe tener un pequeño runbook: qué significa “degradado”, cómo se muestra en la UI y qué hacer.
Ejemplos:
- Git API con rate limit: el portal muestra datos cacheados; el usuario aún puede explorar el catálogo, pero “Crear desde plantilla” está deshabilitado.
- CI/CD caído: el portal ofrece una alternativa manual (enlace a la UI del pipeline) y explica tiempos de reintento.
- Gestor de secretos indisponible: bloquea cambios que requieren nuevos secretos; permite acceso solo lectura a metadata de servicio.
Mantén estos docs cerca del producto (p. ej., /docs/integrations) para que los desarrolladores no tengan que adivinar.
Observabilidad: monitorizar el portal y sus automatizaciones
Tu portal IDP no es solo una UI —es una capa de orquestación que dispara CI/CD, crea recursos cloud, actualiza un catálogo y aplica aprobaciones. La observabilidad te permite responder, rápida y con confianza: “¿Qué pasó?”, “¿Dónde falló?” y “¿Quién debe actuar ahora?”.
Traza cada solicitud a través de pasos
Instrumenta cada ejecución de flujo con un correlation ID que siga la solicitud desde la UI del portal por APIs backend, checks de aprobación y herramientas externas (Git, CI, cloud, ticketing). Añade tracing de requests para que una vista muestre el camino completo y el tiempo de cada paso.
Complementa los traces con logs estructurados (JSON) que incluyan: nombre del flujo, run ID, nombre del paso, servicio objetivo, entorno, actor y resultado. Esto facilita filtrar por “todas las ejecuciones fallidas de deploy-template” o “todo lo que afectó al Servicio X”.
Métricas que reflejen el dolor del desarrollador
Las métricas infra básicas no bastan. Añade métricas de workflow que se mapeen a resultados reales:
- Conteo de ejecuciones, tasa de éxito y duración por flujo y paso
- Tiempo de espera en aprobaciones vs tiempo de ejecución (ayuda a identificar cuellos de botella)
- Reintentos, timeouts y rate limits desde conectores
Vistas operativas dentro del portal
Da a los equipos de plataforma páginas “de un vistazo”:
- Cola de flujos: en ejecución, en cola, fallidos, esperando aprobación
- Salud de conectores: validez de tokens, última llamada exitosa, tasa de error
- Estado de sync: último sync del catálogo, drift detectado, tamaño del backlog
Enlaza cada estado a detalles y logs/traces exactos para esa ejecución.
Alertas, retención y auditoría
Configura alertas para integraciones rotas (p. ej., 401/403 repetidos), aprobaciones atascadas (sin acción durante N horas) y fallos de sync. Planifica retención de datos: conserva logs de alto volumen por menos tiempo, pero retén eventos de auditoría más tiempo para cumplimiento e investigación, con controles de acceso y opciones de export.
Seguridad y gobernanza sin frenar a los equipos
Experimenta sin miedo
Usa snapshots y rollback para iterar con seguridad en cambios del portal y plantillas.
La seguridad en un portal IDP funciona mejor cuando se siente como “guardrails”, no como puertas. El objetivo es reducir elecciones riesgosas haciendo el camino seguro el más fácil, sin quitar autonomía a los equipos.
La mayor parte de gobernanza puede ocurrir en el momento en que un desarrollador solicita algo (nuevo servicio, repo, entorno o recurso cloud). Trata cada formulario y llamada API como input no confiable.
Aplica estándares en código, no en docs:
- Requiere propiedad (equipo, on-call y contacto de escalado) y bloquea la creación si falta.
- Valida convenciones de nombres para evitar colisiones y confusión.
- Requiere tags/metadata usadas para asignación de costes, cumplimiento y descubrimiento.
- Rechaza solicitudes que no cumplan la política mínima (por ejemplo, “exposición pública” requiere revisión extra).
Esto mantiene limpio tu catálogo y facilita las auditorías.
Protege los secretos por diseño
Un portal a menudo toca credenciales (tokens CI, acceso cloud, API keys). Trata los secretos como radioactivos:
- Nunca registres secretos ni los incluyas en mensajes de error.
- Prefiere tokens de corta duración (OIDC, acceso federado con tiempo limitado) sobre claves de larga vida.
- Almacena secretos solo en un gestor de secretos dedicado; el portal debe referenciarlos, no copiarlos.
Asegura también que los logs de auditoría capturen quién hizo qué y cuándo —sin capturar valores secretos.
Modela amenazas en fallos “normales”
Concéntrate en riesgos realistas:
- Escalada de privilegios por RBAC mal configurado y permisos demasiado amplios.
- Webhooks o callbacks suplantados que disparen acciones sin verificación.
- Fugas de datos vía endpoints de depuración, logs verbosos o búsqueda permisiva.
Mitiga con verificación firmada de webhooks, principio de mínimo privilegio y separación estricta entre operaciones de “lectura” y “cambio”.
Lleva controles a la izquierda con CI y revisiones de permisos
Ejecuta checks de seguridad en CI para el código del portal y para las plantillas generadas (linting, policy checks, escaneo de dependencias). Luego programa revisiones regulares de:
- Roles RBAC y mapeos de grupos
- Permisos de plantillas (quién puede crear qué)
- Accesos “break-glass” y procedimientos de rotación
La gobernanza es sostenible cuando es rutinaria, automatizada y visible —no un proyecto puntual.
Despliegue, adopción y mantenimiento a largo plazo
Un portal de desarrolladores solo entrega valor si los equipos lo usan. Trata el despliegue como un lanzamiento de producto: empieza pequeño, aprende rápido y escala con evidencia.
Comienza con un piloto enfocado
Pilotea con 1–3 equipos motivados y representativos (uno “greenfield”, uno con legado pesado, uno con necesidades de cumplimiento más estrictas). Observa cómo completan tareas reales—registrar un servicio, solicitar infra, disparar un deploy—y arregla fricciones de inmediato. El objetivo no es la completitud de funciones; es probar que el portal ahorra tiempo y reduce errores.
Haz la migración aburrida y predecible
Proporciona pasos de migración que encajen en un sprint normal. Por ejemplo:
- registrar un servicio existente en el catálogo,
- adjuntar propiedad y info on-call,
- conectar CI/CD,
- adoptar una plantilla (repo, pipeline o infra) para el próximo componente nuevo.
Mantén las mejoras "día 2" simples: permite que los equipos añadan metadata gradualmente y reemplacen scripts a medida con flujos del portal.
Docs y ayuda in-product que la gente leerá
Escribe docs concisas para los flujos que importan: “Registrar un servicio”, “Solicitar una base de datos”, “Revertir un deploy”. Añade ayuda in-product junto a campos de formularios y enlaza a /docs/portal y /support para contexto profundo. Trata la doc como código: versiona, revisa y poda.
La propiedad es un compromiso a largo plazo
Planea ownership continuo desde el inicio: alguien debe triagear el backlog, mantener conectores a herramientas externas y soportar usuarios cuando las automatizaciones fallen. Define SLAs para incidentes del portal, establece una cadencia regular para actualizar conectores y revisa logs de auditoría para detectar puntos de dolor y brechas de política.
A medida que el portal madura, querrás capacidades como snapshots/rollback para la configuración del portal, despliegues predecibles y promoción de entornos entre regiones. Si estás construyendo o experimentando rápido, Koder.ai también puede ayudar a equipos a montar apps internas con modo de planificación, despliegue/hosting y exportación de código —útil para pilotar funciones del portal antes de endurecerlas como componentes de plataforma a largo plazo.