Definir el alcance y las necesidades de los usuarios
Antes de diseñar pantallas o elegir un parser de archivos, aclara quién mueve datos dentro y fuera de tu producto y por qué. Una aplicación web de importación de datos pensada para operadores internos se verá muy diferente a una herramienta de importación de Excel de autoservicio para clientes.
¿Quiénes son los usuarios?
Empieza listando los roles que interactuarán con importaciones/exportaciones:
- Admins que configuran mapeos, reglas y permisos
- Operadores que ejecutan importaciones regularmente y gestionan excepciones
- Clientes que suben sus propios archivos CSV/Excel y esperan guías claras
Para cada rol, define el nivel de habilidad esperado y su tolerancia a la complejidad. Los clientes suelen necesitar menos opciones y explicaciones mucho mejores dentro del producto.
Casos de uso principales (y cuándo considerar “listo”)
Anota tus escenarios más importantes y priorízalos. Algunos comunes son:
- Carga masiva inicial durante el onboarding (alto volumen, datos desordenados)
- Sincronización periódica (actualizaciones semanales/mensuales, importa la consistencia)
- Exportes puntuales para informes, migraciones o backups
Luego define métricas de éxito medibles. Ejemplos: menos importaciones fallidas, menor tiempo de resolución de errores y menos tickets de soporte por “mi archivo no se sube”. Estas métricas te ayudarán a tomar decisiones (por ejemplo, invertir en reportes de error más claros vs. soportar más formatos).
Sé explícito sobre lo que soportarás desde el día uno:
- Formatos de archivo: CSV, Excel (XLSX), JSON
- Tamaño máximo de archivo y límites de filas (y qué sucede si se exceden)
- Expectativas de codificación (p. ej., UTF-8) y reglas de zona horaria para fechas
Finalmente, identifica necesidades de cumplimiento temprano: si los archivos contienen PII, requisitos de retención (cuánto tiempo guardas las subidas) y requisitos de auditoría (quién importó qué, cuándo y qué cambió). Estas decisiones afectan almacenamiento, logging y permisos en todo el sistema.
Elegir arquitectura y stack tecnológico
Antes de pensar en una UI elegante de mapeo de columnas o reglas de validación de CSV, elige una arquitectura que tu equipo pueda desplegar y operar con confianza. Las importaciones y exportaciones son infraestructura “aburrida”: la velocidad de iteración y la capacidad para depurar valen más que la novedad.
Empieza con un stack que tu equipo ya conozca
Cualquier stack web mainstream puede soportar una app de importación de datos. Elige según habilidades existentes y facilidad de contratación:
- React + Node (TypeScript) si quieres un full-stack en un solo lenguaje y un ecosistema fuerte para trabajos en segundo plano.
- Django si quieres admin incluido, un ORM maduro y entrega rápida.
- Rails si valoras convenciones, CRUD rápido y patrones bien establecidos para jobs en background.
La clave es la consistencia: el stack debe facilitar añadir nuevos tipos de importación, nuevas reglas de validación y nuevos formatos de exportación sin reescrituras.
Si quieres acelerar el scaffolding sin comprometerte a un prototipo único, una plataforma de prototipado como Koder.ai puede ayudar: puedes describir tu flujo de importación (upload → preview → mapping → validation → background processing → history) en chat, generar una UI en React con un backend en Go + PostgreSQL y iterar rápido usando modos de planificación y snapshots/rollback.
Almacenamiento: separa “archivo crudo” de “registros normalizados”
Usa una base de datos relacional (Postgres/MySQL) para registros estructurados, upserts y registros de auditoría de cambios de datos.
Almacena las subidas originales (CSV/Excel) en almacenamiento de objetos (S3/GCS/Azure Blob). Mantener los archivos crudos es invaluable para soporte: puedes reproducir problemas de parseo, reejecutar jobs y explicar decisiones de manejo de errores.
Decide cómo se ejecutan las importaciones
Los archivos pequeños pueden ejecutarse síncronamente (subida → validación → aplicar) para una UX ágil. Para archivos grandes, mueve el trabajo a trabajos en segundo plano:
- upload → encolar job → mostrar progreso/historial → notificar al terminar
Esto también te prepara para reintentos y escrituras con limitación de velocidad.
Multi-tenant vs single-tenant
Si estás construyendo SaaS, decide temprano cómo separar datos de tenants (escopado por fila, esquemas separados o bases de datos por cliente). Esta decisión afecta tu API de exportación, permisos y rendimiento.
Requisitos no funcionales que documentar ahora
Escribe objetivos para uptime, tamaño máximo de archivo, filas esperadas por importación, tiempo hasta completar y límites de costo. Estos números guiarán la elección de colas, la estrategia de batching y los índices—mucho antes de pulir la UI.
Construir el flujo de entrada (intake) de importación
El flujo de entrada marca el tono de cada importación. Si se siente predecible y tolerante, los usuarios volverán a intentarlo cuando algo falle—y los tickets de soporte bajarán.
Puntos de entrada: subida por UI y API
Ofrece una zona de arrastrar y soltar además del selector clásico de archivos para la UI web. El drag-and-drop es más rápido para usuarios avanzados; el selector de archivos es más accesible y familiar.
Si tus clientes importan desde otros sistemas, añade también un endpoint de API. Puede aceptar multipart (archivo + metadatos) o un flujo con URL pre-firmada para archivos grandes.
Parseo seguro: cabeceras, codificaciones y muestreo
Al subir, haz un parseo ligero para crear una “vista previa” sin comprometer datos todavía:
- Detecta cabeceras y muestra una muestra de filas (p. ej., primeras 20–100)
- Maneja codificaciones comunes (UTF‑8, UTF‑16) y delimitadores (coma, tab, punto y coma)
- Normaliza saltos de línea y recorta problemas de formato obvios
Esta vista previa alimenta pasos posteriores como mapeo de columnas y validación.
Almacena el archivo original para reproducir
Siempre guarda el archivo original de forma segura (el almacenamiento de objetos es típico). Mantenlo inmutable para que puedas:
- Reejecutar la importación cuando cambien las reglas de validación
- Investigar bugs con la entrada exacta
- Ofrecer una opción de “descargar original” desde el historial de importación
Trata cada subida como un registro de primera clase. Guarda metadatos como uploader, timestamp, sistema origen, nombre de archivo y checksum (para detectar duplicados y asegurar integridad). Esto es invaluable para auditabilidad y debugging.
Pre-checks antes de que el usuario invierta tiempo
Ejecuta comprobaciones rápidas inmediatamente y falla pronto cuando sea necesario:
- Tipo de archivo y límite de tamaño
- Legibilidad básica (¿podemos parsearlo?)
- Columnas requeridas presentes (según el tipo de importación)
Si un pre-check falla, devuelve un mensaje claro y muestra qué corregir. El objetivo es bloquear archivos realmente malos rápidamente—sin bloquear datos válidos pero imperfectos que pueden mapearse y limpiarse después.
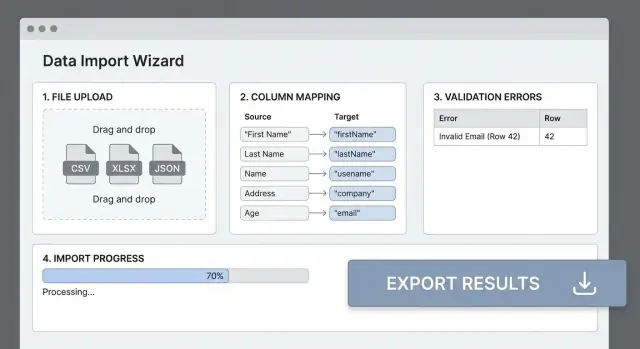
La mayoría de fallos en importaciones ocurren porque las cabeceras del archivo no coinciden con los campos de tu app. Un paso claro de mapeo de columnas convierte un CSV desordenado en una entrada predecible y evita que los usuarios prueben y fallen varias veces.
Una UI de mapeo que la gente entienda
Muestra una tabla simple: Columna de origen → Campo de destino. Detecta coincidencias probables automáticamente (coincidencia insensible a mayúsculas, sinónimos como “E-mail” → email), pero permite siempre que los usuarios sobrescriban.
Incluye algunos detalles de calidad de vida:
- Marca campos destino obligatorios y muestra si están mapeados
- Permite “Ignorar esta columna” para datos irrelevantes
- Resalta columnas no mapeadas para que los usuarios no pasen nada por alto
Plantillas de mapeo guardadas (por cliente o dataset)
Si los clientes importan el mismo formato cada semana, haz que sea de un clic. Permite que guarden plantillas con scope:
- una cuenta/cliente
- un conjunto/tipo de datos (por ejemplo, Contactos vs. Facturas)
- opcionalmente, una integración o sistema origen específico
Al subir un archivo, sugiere una plantilla basada en la superposición de columnas. También soporta versionado para que los usuarios puedan actualizar una plantilla sin romper ejecuciones antiguas.
Añade transformaciones ligeras que los usuarios puedan aplicar por campo mapeado:
- recortar espacios; convertir cadenas vacías a null
- parseo de fechas (MM/DD/YYYY vs. DD.MM.YYYY) con opciones de zona horaria
- normalización de monedas (p. ej., “$1,200.00” → 1200.00 + moneda)
- enums (p. ej., “Active”, “enabled”, “1” → ACTIVE)
- dividir/componer campos (Nombre completo → Nombre/Apellido, o al revés)
Mantén las transformaciones explícitas en la UI (“Aplicado: Recortar → Parsear Fecha”) para que la salida sea explicable.
Vista previa antes de confirmar
Antes de procesar el archivo completo, muestra una vista previa de los resultados mapeados para (por ejemplo) 20 filas. Muestra el valor original, el valor transformado y advertencias (como “No se pudo parsear la fecha”). Aquí es donde los usuarios detectan problemas temprano.
Detectar duplicados y campos clave
Pide a los usuarios elegir un campo clave (email, external_id, SKU) y explica qué sucede con duplicados. Incluso si manejas upserts luego, este paso establece expectativas: puedes advertir sobre claves duplicadas en el archivo y sugerir qué registro “gana” (primero, último o error).
Diseñar el sistema de validación
La validación es lo que diferencia un “subidor de archivos” de una funcionalidad de importación en la que la gente confía. El objetivo no es ser estricto por sí mismo—es evitar que los datos malos se propaguen mientras se da a los usuarios retroalimentación clara y accionable.
Separar la validación en capas
Trata la validación como tres comprobaciones distintas, cada una con un propósito diferente:
- Validación de esquema (tipos y campos obligatorios): “¿
email es una cadena?”, “¿amount es un número?”, “¿customer_id está presente?” Esto es rápido y puede ejecutarse inmediatamente tras parsear.
- Reglas de negocio: “El monto debe ser positivo”, “El estado debe ser uno de Active/Paused”, “La fecha de inicio no puede estar en el pasado.” Esto refleja cómo funciona tu producto.
- Reglas cruzadas y relacionales: “Si
country=US, state es obligatorio”, “end_date debe ser posterior a start_date”, “El nombre del plan debe existir en este workspace.” Estos suelen requerir contexto (otras columnas o consultas a la base de datos).
Mantener estas capas separadas hace el sistema más fácil de extender y más sencillo de explicar en la UI.
Modo estricto vs tolerante (y por qué importa)
Decide pronto si una importación debe:
- Fallar todo el archivo (modo estricto): mejor para datos financieros, permisos o cualquier cosa donde actualizaciones parciales creen riesgo.
- Aceptar filas válidas parcialmente (modo tolerante): mejor para listas grandes donde los usuarios esperan corregir solo los registros problemáticos.
También puedes ofrecer ambos: estricto por defecto, con una opción “Permitir importación parcial” para administradores.
Errores amigables para humanos (con referencia a fila/columna)
Cada error debe responder: qué pasó, dónde y cómo arreglarlo.
Ejemplo: “Fila 42, Columna ‘Fecha de inicio’: debe ser una fecha válida en formato YYYY-MM-DD.”
Diferencia:
- Errores: bloquean el procesamiento de esa fila (o de todo el archivo en modo estricto)
- Advertencias: se permiten, pero se resaltan (por ejemplo, “Departamento desconocido; quedará en blanco”)
Permitir ciclos de “corregir y volver a subir”
Los usuarios rara vez arreglan todo en un solo intento. Haz que las re-subidas sean sencillas manteniendo los resultados de validación vinculados a un intento de importación y permitiendo al usuario subir un archivo corregido. Acompaña esto con informes de errores descargables para que puedan resolver problemas en bloque.
Motor de reglas: configurable cuando haga falta, en código cuando sea más seguro
Un enfoque práctico es híbrido:
- Reglas configurables para requisitos por tenant (p. ej., “ID de empleado debe ser único dentro de este workspace”).
- Reglas definidas en código para invariantes del producto (p. ej., límites de permisos, relaciones requeridas) para evitar mala configuración.
Esto mantiene la validación flexible sin convertirla en un “laberinto de ajustes” difícil de depurar.
Implementar procesamiento fiable y reintentos
Planifica antes de codificar
Mapea primero los estados, las tareas y los casos límite, luego deja que Koder.ai genere el código.
Las importaciones suelen fallar por razones aburridas: bases lentas, picos de archivos en horas punta o una sola fila “mala” que bloquea todo el lote. La fiabilidad trata principalmente de mover el trabajo pesado fuera del request/response y hacer que cada paso sea seguro de ejecutar de nuevo.
Usa trabajos en segundo plano para archivos grandes
Ejecuta parseo, validación y escrituras en trabajos en segundo plano (colas/trabajadores) para que las subidas no entren en timeouts web. Esto también te permite escalar los workers independientemente cuando los clientes empiecen a importar hojas más grandes.
Un patrón práctico es dividir el trabajo en chunks (por ejemplo, 1.000 filas por job). Un job “padre” programa jobs por chunk, agrega resultados y actualiza el progreso.
Rastrea estados y transiciones claros
Modela la importación como una máquina de estados para que la UI y el equipo de operaciones siempre sepan qué está pasando:
- queued → running → completed
- queued/running → failed (con motivo)
- queued/running → canceled (por usuario o sistema)
Almacena timestamps y conteos de intentos por cada transición para responder “¿cuándo empezó?” y “¿cuántos reintentos?” sin investigar logs.
Progreso en el que los usuarios puedan confiar
Muestra progreso medible: filas procesadas, filas restantes y errores encontrados hasta el momento. Si puedes estimar el rendimiento, añade una ETA aproximada: mejor “~3 min” que una cuenta regresiva precisa.
Haz el procesamiento idempotente (seguro para reintentos)
Los reintentos nunca deberían crear duplicados o aplicar actualizaciones dos veces. Técnicas comunes:
- Usa import_id más row_number (o hash de fila) como clave de idempotencia estable.
- Upsert usando una clave natural (como external_id) en lugar de “insertar siempre”.
- Escribe en transacciones por chunk para que fallos parciales no corrompan el estado.
Limita para proteger a todos
Aplica rate-limits a importaciones concurrentes por workspace y limita pasos con escrituras intensas (p. ej., N filas/seg) para evitar sobrecargar la base de datos y degradar la experiencia de otros usuarios.
Reporte de errores e historial de importación
Si la gente no entiende qué salió mal, intentará subir el mismo archivo hasta rendirse. Trata cada importación como una “ejecución” de primera clase con una pista de auditoría clara y errores accionables.
Crea un registro de ejecución de importación
Empieza creando una entidad import run en el momento en que se envía un archivo. Este registro debe capturar lo esencial:
- Quién lo inició (usuario + organización)
- Qué se importó (nombre del archivo origen, tamaño, checksum, tipo de entidad)
- Cuándo ocurrió (timestamps de inicio/fin)
- Cómo se interpretó (configuración de mapeo usada, versión de transformaciones)
- Resultado (éxito/fallo/parcial, filas procesadas, filas rechazadas)
Esto se convierte en tu pantalla de historial de importaciones: una lista simple de ejecuciones con estado, conteos y una página de “ver detalles”.
Almacena errores a nivel de fila (no solo logs)
Los logs de aplicación son útiles para ingenieros, pero los usuarios necesitan errores consultables. Almacena errores como registros estructurados vinculados al import run, idealmente en ambos niveles:
- Nivel fila: número de fila, identificador primario (si se detecta), snapshot de valores crudos
- Nivel campo: nombre de columna, código de error (p. ej., REQUIRED, INVALID_DATE), mensaje humano, severidad
Con esta estructura puedes habilitar filtros rápidos y métricas agregadas como “Top 3 tipos de error de la semana”.
En la página de detalles de la ejecución, ofrece filtros por tipo, columna y severidad, además de un cuadro de búsqueda (por ejemplo: “email”). Luego ofrece un informe de errores descargable en CSV que incluya la fila original más columnas extra como error_columns y error_message, con guías claras como “Arregla el formato de fecha a YYYY-MM-DD”.
Añade un modo de prueba (dry run)
Un “modo de prueba” valida todo usando el mismo mapeo y reglas, pero no escribe datos. Es ideal para importaciones iniciales y permite a los usuarios iterar a salvo antes de confirmar cambios.
Modelo de datos, upserts y auditabilidad
Prototipa tu asistente de importación
Describe tu flujo de importación en el chat y consigue rápidamente un esqueleto funcional en React y Go.
Las importaciones se consideran “hechas” cuando las filas llegan a la base, pero el coste a largo plazo suele estar en actualizaciones desordenadas, duplicados e historial de cambios poco claro. Esta sección trata de diseñar tu modelo de datos para que las importaciones sean predecibles, reversibles y explicables.
Decide: crear, actualizar o ambos
Define cómo una fila importada mapea a tu modelo de dominio. Para cada entidad, decide si la importación puede:
- Crear registros nuevos únicamente
- Actualizar registros existentes únicamente
- Hacer ambos (caso común en SaaS)
Esta decisión debe estar explícita en la UI de configuración de importación y almacenada con el job para que el comportamiento sea repetible.
Elige claves de upsert y reglas de colisión
Si soportas “crear o actualizar”, necesitas claves de upsert estables—campos que identifican el mismo registro siempre. Opciones comunes:
external_id (ideal cuando viene de otro sistema)- Email (útil para usuarios/contactos, pero puede cambiar)
- Claves compuestas (p. ej.,
account_id + sku)
Define reglas de colisión: ¿qué pasa si dos filas comparten la misma clave, o si una clave coincide con múltiples registros? Buenos valores por defecto son “fallar la fila con un error claro” o “gana la última fila”, pero decide con intención.
Transacciones sin bloquear todo
Usa transacciones donde protejan la consistencia (por ejemplo, crear un parent y sus hijos). Evita una transacción gigante para un archivo de 200k filas; puede bloquear tablas y hacer reintentos costosos. Prefiere escrituras por chunk (p. ej., 500–2.000 filas) con upserts idempotentes.
Protege la integridad referencial
Las importaciones deben respetar relaciones: si una fila referencia un registro padre (como una Company), requiere que exista o que se cree en un paso controlado. Fallar pronto con error de “parent faltante” evita datos medio conectados.
Audita todo lo que cambien las importaciones
Añade logs de auditoría para cambios impulsados por importaciones: quién activó la importación, cuándo, archivo origen y un resumen por registro de lo que cambió (antiguo vs nuevo). Esto facilita soporte, genera confianza en el usuario y simplifica rollbacks.
Construir exportaciones que escalen
Las exportaciones parecen sencillas hasta que los clientes intentan descargar “todo” justo antes de una entrega. Un sistema de exportación escalable debe manejar conjuntos grandes sin ralentizar la app ni producir archivos inconsistentes.
Ofrece los tipos de exportación adecuados
Empieza con tres opciones:
- Exportación completa: todo lo que el usuario puede ver.
- Exportación filtrada: respeta los mismos filtros/búsquedas de la UI (estado, rango de fechas, propietario, etc.).
- Exportación incremental: “cambios desde X” para sincronizaciones y pipelines de reporting.
Las exportaciones incrementales son especialmente útiles para integraciones y reducen carga frente a volcados completos repetidos.
- CSV es el predeterminado para hojas de cálculo y análisis masivo.
- JSON es mejor para una API de exportación de datos y automatización.
- Excel solo cuando sea necesario (varias hojas, formato rico o flujos no técnicos).
Sea cual sea la elección, mantiene cabeceras consistentes y orden de columnas estable para que procesos downstream no se rompan.
Stream y paginación para evitar picos de memoria
Las exportaciones grandes no deberían cargar todas las filas en memoria. Usa streaming/paginación para escribir filas conforme las vas obteniendo. Esto evita timeouts y mantiene la app web responsiva.
Para datasets grandes, genera exportes en un job en background y notifica al usuario cuando esté listo. Un patrón común:
- El usuario solicita exportación.
- La app encola un job.
- El job escribe el archivo en almacenamiento de objetos.
- La UI muestra un link de descarga y lo guarda en el historial de exportes.
Esto encaja bien con tus jobs de importación y con el mismo patrón de “historial de ejecuciones + artefacto descargable” que usas para informes de errores.
Las exportaciones suelen auditarse. Siempre incluye:
- Una política de zona horaria clara (p. ej., almacenar en UTC, exportar en la zona horaria del usuario).
- Formato de fecha consistente (ISO-8601 para JSON; formatos explícitos para CSV/Excel).
- Un timestamp de “generado en” y, para exportes incrementales, el corte usado.
Estos detalles reducen confusión y ayudan a reconciliaciones fiables.
Seguridad, permisos y privacidad de datos
Las importaciones y exportaciones son potentes porque mueven gran cantidad de datos rápidamente. Eso también las convierte en un punto habitual de fallos de seguridad: un rol con permisos excesivos, una URL de archivo filtrada o una línea de log que incluye datos personales.
Autenticación: elige lo que encaje con el uso
Empieza con la misma autenticación que usas en la app—no crees una ruta “especial” solo para importaciones.
Si tus usuarios trabajan en navegador, auth basada en sesión (más SSO/SAML opcional) suele encajar. Si las importaciones/exportaciones se automatizan (jobs nocturnos, partners), considera API keys o tokens OAuth con scope claro y rotación.
Una regla práctica: la UI de importación y la API de importación deben imponer los mismos permisos, aunque las usen distintos públicos.
Acceso basado en roles: define quién puede qué
Trata capacidades de import/export como privilegios explícitos. Roles comunes:
- Puede importar (subir archivos, ejecutar importaciones)
- Puede exportar (generar y descargar exportes)
- Puede ver historial (ver ejecuciones, errores, conteos)
- Puede descargar archivos (subidas originales, informes de error)
Haz “descargar archivos” un permiso separado. Muchas fugas sensibles ocurren cuando alguien puede ver una ejecución y el sistema asume que también puede descargar el archivo original.
Considera también límites por fila o por tenant: un usuario solo debería importar/exportar datos del account o workspace al que pertenece.
Protege datos sensibles de extremo a extremo
Para archivos almacenados (subidas, CSVs de error generados, archivos de exportación), usa almacenamiento de objetos privado y enlaces de descarga de corta duración. Cifra en reposo cuando lo requiera tu cumplimiento y sé consistente: la subida original, el archivo de staging procesado y cualquier informe generado deben seguir las mismas reglas.
Cuidado con los logs. Redacta campos sensibles (emails, teléfonos, IDs, direcciones) y nunca registres filas crudas por defecto. Cuando sea necesario depurar, restringe “logging detallado de filas” a settings admin y asegúrate de que expiren.
Valida y escanea subidas antes de procesar
Trata cada subida como input no confiable:
- Aplica chequeos de tipo de archivo (no confíes solo en el nombre)
- Establece límites de tamaño para evitar denegación de servicio y subidas accidentales enormes
- Considera escaneo de malware si tu perfil de riesgo o industria lo exige
También valida la estructura temprano: rechaza archivos claramente malformados antes de que lleguen a los jobs en background y proporciona un mensaje claro al usuario sobre el problema.
Trazabilidad (audit trails) para eventos de seguridad
Registra eventos que quieras durante una investigación: quién subió un archivo, quién inició una importación, quién descargó un export, cambios de permisos e intentos de acceso fallidos.
Las entradas de auditoría deben incluir actor, timestamp, workspace/tenant y el objeto afectado (import run ID, export ID), sin almacenar datos sensibles por fila. Esto complementa la UI de historial de importación y te ayuda a responder “¿quién cambió qué y cuándo?” rápidamente.
Pruebas, monitorización y operabilidad
Configura roles y accesos
Modela permisos multitenant desde el inicio y genera las interfaces de administración que necesitas.
Si las importaciones y exportaciones tocan datos de clientes, tarde o temprano surgirán casos límite: codificaciones raras, celdas combinadas, filas medio llenas, duplicados y “ayer funcionaba”. La operabilidad es lo que evita que esos problemas se conviertan en pesadillas de soporte.
Tests que reflejen archivos reales
Empieza con tests enfocados en las partes más propensas a fallo: parseo, mapeo y validación.
- Tests de parseo: usa un pequeño set de fixtures representativas CSV/XLSX (diferentes delimitadores, formatos de fecha, columnas vacías, números grandes, UTF‑8 vs Windows-1252). Asegura conteos de filas y que campos clave se parseen consistentemente.
- Tests de mapeo + transformación: dado un set de columnas de entrada, verifica que la app mapea a los campos internos correctos y aplica transformaciones (recorte, normalización de mayúsculas, conversión de moneda/porcentaje).
- Tests de reglas de validación: para cada regla (requerido, único, rango, existencia FK), incluye filas “buenas” y “malas” y asserta los códigos/mensajes exactos.
Luego añade al menos un test end-to-end para el flujo completo: upload → procesamiento en background → generación de informe. Estos tests atrapan desajustes de contrato entre UI, API y workers (por ejemplo, un payload de job que no incluye la configuración de mapeo).
Monitorización que responda “¿qué se rompió?”
Mide señales que reflejen impacto en usuarios:
- Fallos de jobs (conteo y tasa)
- Tiempo de procesamiento (p50/p95)
- Tasa de errores de validación (picos suelen indicar cambio de plantilla)
- Profundidad de colas y throughput de workers
Conecta alertas a síntomas (crecimiento de la cola, picos de fallos) en lugar de cada excepción suelta.
Herramientas de administración y ayuda al usuario
Da a los equipos internos una pequeña superficie admin para re-ejecutar jobs, cancelar importaciones atascadas e inspeccionar fallos (metadatos del archivo, mapeo usado, resumen de errores y link a logs/trazas).
Para los usuarios, reduce errores prevenibles con consejos inline, plantillas de muestra descargables y pasos claros en las pantallas de error. Mantén una página central de ayuda y enlázala desde la UI de importación (por ejemplo: /docs).
Despliegue, rollout y mejoras futuras
Lanzar un sistema de import/export no es solo “hacer push a producción”. Trátalo como una funcionalidad de producto con valores por defecto seguros, rutas de recuperación claras y espacio para evolucionar.
Entornos: dev, staging, prod
Configura entornos separados dev/staging/prod con BD aisladas y buckets de almacenamiento de objetos (o prefijos) separados para subidas y exportes generados. Usa claves de cifrado y credenciales distintas por entorno y asegura que los workers apunten a las colas correctas.
Staging debe reflejar producción: misma concurrencia de jobs, timeouts y límites de tamaño. Ahí validarás rendimiento y permisos sin arriesgar datos reales.
Migraciones y plantillas versionadas
Las importaciones tienden a “vivir para siempre” porque los clientes conservan hojas antiguas. Usa migraciones DB como de costumbre, pero también versiona tus plantillas de importación (y presets de mapeo) para que un cambio de esquema no rompa un CSV del trimestre pasado.
Un enfoque práctico es almacenar template_version con cada import run y mantener código de compatibilidad para versiones antiguas hasta que puedas desaprobarlas.
Estrategia de rollout con feature flags
Usa feature flags para lanzar cambios con seguridad:
- Nuevas reglas de validación (primero como advertencia, luego como error)
- Nuevos formatos de exportación (por ejemplo, añadir JSON junto a CSV)
- Nuevas opciones de mapeo (p. ej., dividir una columna “Nombre completo”)
Las flags permiten probar con usuarios internos o una cohorte pequeña antes de activar la funcionalidad globalmente.
Flujos de soporte y diagnóstico
Documenta cómo el soporte debe investigar fallos usando historial de importación, IDs de job y logs. Una checklist simple ayuda: confirmar versión de plantilla, revisar la primera fila con fallo, comprobar acceso al almacenamiento, luego inspeccionar logs de workers. Enlaza esto desde tu runbook interno y, cuando corresponda, desde la UI admin (/admin/imports).
Siguientes pasos: integraciones
Cuando el flujo central sea estable, extiéndelo más allá de subidas manuales:
- Importaciones vía API para pipelines automáticos
- Webhooks para “import terminado” o “export listo”
- Conectores para herramientas comunes (Google Sheets, S3, Snowflake)
Estas mejoras reducen trabajo manual y hacen que tu app de importación de datos se sienta nativa en los procesos existentes de los clientes.
Si estás construyendo esto como una funcionalidad de producto y quieres acortar el tiempo hasta una “primera versión usable”, considera usar Koder.ai para prototipar el asistente de importación, las páginas de estado de jobs y las pantallas de historial de ejecución end-to-end, y luego exportar el código fuente para un flujo de ingeniería convencional. Ese enfoque puede ser especialmente práctico cuando la meta es fiabilidad y velocidad de iteración (no la perfección estética de la UI el primer día).