20 mar 2025·8 min
Cómo crear una aplicación web de soporte al cliente para tickets y SLAs
Planifica, diseña y construye una aplicación web de soporte al cliente con flujos de tickets, seguimiento de SLAs y una base de conocimiento buscable; además roles, analítica e integraciones.
Define objetivos, usuarios y alcance
Un producto de tickets se vuelve caótico cuando se construye en torno a características en lugar de resultados. Antes de diseñar campos, colas o automatizaciones, alinéate sobre para quién es la app, qué dolor resuelve y qué significa “bueno”.
Identifica a tus usuarios (y sus tareas diarias)
Empieza listando los roles y lo que cada uno debe lograr en una semana normal:
- Agentes: filtrar, responder, resolver y documentar soluciones rápidamente.
- Líderes de equipo: redistribuir carga, detectar tickets estancados, hacer cumplir los SLAs, y entrenar a los agentes.
- Administradores: configurar canales, categorías, automatizaciones, permisos y plantillas.
- Clientes (opcional): enviar solicitudes, seguir el estado, añadir detalles y encontrar respuestas en un portal.
Si omites este paso, optimizarás por accidente para administradores mientras los agentes sufren en la cola.
Escribe los problemas que vas a resolver
Mantén esto concreto y ligado a comportamientos observables:
- SLAs incumplidos: los tickets envejecen en silencio; las escalaciones ocurren demasiado tarde.
- Colas desordenadas: propiedad poco clara, trabajo duplicado y confusión sobre “¿a dónde va esto?”.
- Preguntas repetidas: se escriben las mismas respuestas una y otra vez, ralentizando la resolución.
Decide dónde se usará la app
Sé explícito: ¿es esta una herramienta interna únicamente, o también lanzarás un portal frente al cliente? Los portales cambian los requisitos (autenticación, permisos, contenido, marca, notificaciones).
Elige métricas de éxito desde temprano
Selecciona un pequeño conjunto que seguirás desde el día uno:
- Tiempo hasta la primera respuesta
- Tiempo de resolución
- Tasa de desvío (problemas resueltos vía base de conocimiento en lugar de tickets)
Crea una declaración de alcance simple para la v1
Escribe 5–10 frases que describan qué está en la v1 (flujos imprescindibles) y qué queda para después (mejor enrutamiento, sugerencias por IA, o informes avanzados). Esto será tu guía cuando las solicitudes se acumulen.
Diseña el modelo de ticket y su ciclo de vida
Tu modelo de ticket es la “fuente de la verdad” para todo lo demás: colas, SLAs, informes y lo que los agentes ven en pantalla. Hazlo bien temprano y evitarás migraciones dolorosas después.
Mapea un ciclo de vida que puedas explicar en una frase
Empieza con un conjunto claro de estados y define qué significa cada uno operacionalmente:
- Nuevo: creado, aún no triageado
- Asignado: pertenece a un agente o equipo
- En progreso: se está trabajando activamente
- En espera: bloqueado (respuesta del cliente, tercero, ingeniería)
- Resuelto: el agente considera que está solucionado (a menudo dispara una notificación)
- Cerrado: estado final (bloqueado o con ediciones limitadas)
Añade reglas para las transiciones de estado. Por ejemplo, solo los tickets Asignados/En progreso pueden marcarse como Resuelto, y un ticket Cerrado no puede reabrirse sin crear un seguimiento.
Decide cómo entran los tickets al sistema
Lista cada vía de entrada que soportarás ahora (y lo que añadirás luego): formulario web, correo entrante, chat y API. Cada canal debería crear el mismo objeto ticket, con algunos campos específicos por canal (como cabeceras de email o IDs de transcripción de chat). La consistencia mantiene la automatización y los informes saneados.
Elige campos requeridos (y mantenlos mínimos)
Como mínimo, exige:
- Asunto y descripción
- Solicitante (identidad del cliente)
- Prioridad (qué tan urgente)
- Categoría (tipo de incidencia)
Todo lo demás puede ser opcional o derivado. Un formulario engorroso reduce la calidad de los datos y ralentiza a los agentes.
Planifica etiquetas y campos personalizados para equipos reales
Usa etiquetas para filtrado ligero (por ejemplo, “facturación”, “bug”, “vip”), y campos personalizados cuando necesites reporte estructurado o enrutamiento (por ejemplo, “Área del producto”, “ID de pedido”, “Región”). Asegúrate de que los campos puedan estar acotados por equipo para que un departamento no ensucie a otro.
Define la colaboración dentro de un ticket
Los agentes necesitan un lugar seguro para coordinar:
- Notas internas (no visibles para clientes)
- Menciones @ y listas de seguidores/CC
- Tickets vinculados (duplicados, incidentes padre/hijo)
Tu interfaz de agente debería poner estos elementos a un clic de la línea de tiempo principal.
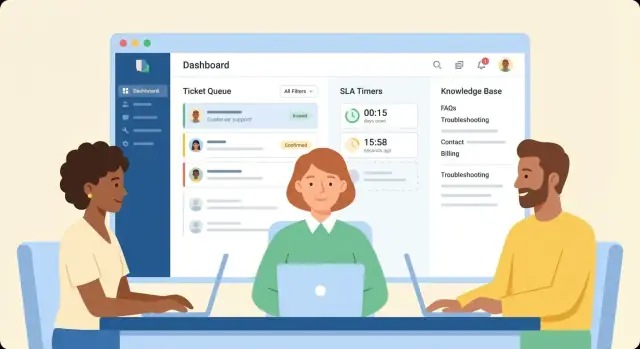
Construye colas de tickets y flujos de asignación
Las colas y las asignaciones son donde un sistema de tickets deja de ser una bandeja compartida y pasa a comportarse como una herramienta operativa. Tu objetivo es simple: cada ticket debe tener una “siguiente mejor acción” obvia, y cada agente debe saber qué trabajar ahora mismo.
Diseña una cola de agente que responda “¿qué sigue?”
Crea una vista de cola que por defecto muestre el trabajo más sensible al tiempo. Opciones de orden comunes que los agentes realmente usarán son:
- Prioridad (p. ej., P1–P4)
- Tiempo hasta el vencimiento del SLA (primero el más cercano)
- Última actualización (para detectar conversaciones estancadas)
Añade filtros rápidos (equipo, canal, producto, nivel de cliente) y una búsqueda rápida. Mantén la lista densa: asunto, solicitante, prioridad, estado, cuenta regresiva del SLA y agente asignado suelen ser suficientes.
Reglas de asignación: automáticas cuando sea posible, manuales cuando haga falta
Soporta varias rutas de asignación para que los equipos puedan evolucionar sin cambiar herramientas:
- Asignación manual para casos puntuales y momentos de formación
- Rotación (round-robin) para distribuir la carga de forma equitativa
- Enrutamiento por habilidades (idioma, área de producto, facturación vs técnico)
- Enrutamiento por equipo (p. ej., “Pagos”, “Enterprise”, “Devoluciones”)
Haz visibles las decisiones de la regla (“Asignado por: Habilidades → Francés + Facturación”) para que los agentes confíen en el sistema.
Estados y plantillas que mantienen el trabajo en movimiento
Estados como En espera del cliente y En espera de un tercero evitan que los tickets parezcan “inactivos” cuando la acción está bloqueada, y hacen que los informes sean más honestos.
Para acelerar las respuestas, incluye respuestas prediseñadas y plantillas de respuesta con variables seguras (nombre, número de pedido, fecha de SLA). Las plantillas deben ser buscables y editables por líderes autorizados.
Evita colisiones (dos agentes, un ticket)
Añade manejo de colisiones: cuando un agente abre un ticket, coloca un “bloqueo de visualización/edición” de corta duración o un banner “siendo gestionado por”. Si otra persona intenta responder, adviértele y exige una confirmación para enviar (o bloquea el envío) para evitar respuestas duplicadas o contradictorias.
Implementa reglas de SLA, temporizadores y escalaciones
Los SLAs solo ayudan si todos están de acuerdo sobre qué se mide y la app lo aplica consistentemente. Empieza convirtiendo “respondemos rápido” en políticas que el sistema pueda calcular.
Define políticas de SLA (qué medirás)
La mayoría de equipos comienzan con dos temporizadores por ticket:
- Tiempo a primera respuesta: tiempo desde la creación del ticket hasta la primera respuesta de un agente (o la primera respuesta pública no automatizada).
- Tiempo de resolución: tiempo desde la creación del ticket hasta “Resuelto/Cerrado”.
Mantén las políticas configurables por prioridad, canal o nivel de cliente (por ejemplo: VIP 1 hora para primera respuesta, Estándar 8 horas hábiles).
Decide cuándo los relojes de SLA arrancan y paran
Escribe las reglas antes de codificar, porque los casos límite aparecen rápido:
- Horario laboral vs 24/7: define un calendario (zona horaria, días laborables, festivos).
- Estados de pausa: detén el contador cuando el ticket esté en “En espera del cliente” o “Pendiente de proveedor externo”.
- Condiciones de reanudación: reinicia cuando el cliente responda o el estado cambie a “Abierto/En progreso”.
Almacena eventos de SLA (iniciado, pausado, reanudado, incumplido) para que luego puedas explicar por qué algo incumplió.
Haz el estado del SLA obvio en la UI
Los agentes no deberían abrir un ticket para descubrir que está a punto de incumplir. Añade:
- Un temporizador regresivo (tiempo restante)
- Indicadores de retraso con severidad clara (advertencia vs incumplido)
- Alertas opcionales (en la app, email o chat) cuando se acerque un umbral
Construye caminos de escalación
La escalación debe ser automática y predecible:
- Notificar a un líder de equipo al 80% del tiempo permitido
- Reasignar a una cola de guardia si se incumple
- Aumentar la prioridad o añadir una etiqueta “Escalado”
Planifica informes de SLA
Como mínimo, registra conteo de incumplimientos, tasa de incumplimiento y tendencia en el tiempo. También registra razones de incumplimiento (pausado demasiado tiempo, prioridad equivocada, cola con poco personal) para que los informes lleven a acciones, no a culpables.
Crea una base de conocimiento que reduzca tickets repetidos
Una buena base de conocimiento (KB) no es solo una carpeta de FAQs: es una funcionalidad de producto que debe reducir de forma medible las preguntas repetidas y acelerar las resoluciones. Disénala como parte del flujo de tickets, no como un “sitio de documentación” separado.
Estructura: facilita el mantenimiento del contenido
Empieza con un modelo de información simple que escale:
- Categorías → secciones → artículos (navegación sencilla para clientes y agentes)
- Etiquetas para temas transversales (facturación, acceso, integraciones) sin duplicar artículos
- Propiedad clara (quién revisa qué) para que el contenido se mantenga actual
Mantén plantillas de artículo consistentes: enunciado del problema, solución paso a paso, capturas opcionales y “Si esto no ayudó…” con guía hacia el formulario o canal correcto.
Búsqueda que realmente encuentre respuestas
La mayoría de fracasos de KB son fallos de búsqueda. Implementa búsqueda con:
- Ajuste de relevancia (impulsos por título/encabezado, por frescura)
- Sinónimos (por ejemplo, “factura” ↔ “invoice”, “2FA” ↔ “código de autenticación”)
- Tolerancia a errores tipográficos y stemming (plural/singular)
También indexa asuntos de tickets (anonimizados) para aprender el vocabulario real del cliente y alimentar la lista de sinónimos.
Borradores, revisiones y aprobaciones de publicación
Añade un flujo ligero: borrador → revisión → publicado, con publicación programada opcional. Guarda historial de versiones e incluye metadatos de “última actualización”. Asócialo con roles (autor, revisor, publicador) para que no todos los agentes puedan editar docs públicas.
Mide lo que reduce tickets
Mide más que vistas de página. Métricas útiles incluyen:
- Votos de utilidad (sí/no) y “¿qué faltó?”
- Señales de desvío: búsqueda → artículo visto → no se crea ticket en X horas
- Búsquedas principales sin buenos resultados (brechas de contenido)
Enlaza artículos a los tickets donde se trabaja
Dentro del compositor de respuesta del agente, muestra artículos sugeridos según asunto del ticket, etiquetas e intención detectada. Un clic debería insertar un enlace público (p. ej., /help/account/reset-password) o un fragmento interno para respuestas más rápidas.
Bien hecho, la KB se convierte en tu primera línea de soporte: los clientes resuelven cosas solos y los agentes manejan menos tickets repetidos con mayor consistencia.
Configura roles, permisos y auditabilidad
Itera sin afectar las operaciones
Prueba reglas de SLA y enrutamiento de forma segura con instantáneas y reversión rápida durante pilotos.
Los permisos son donde una herramienta de tickets o bien se mantiene segura y predecible, o bien se vuelve un lío rápidamente. No esperes hasta después del lanzamiento para “bloquearlo”. Modela el acceso temprano para que los equipos puedan moverse rápido sin exponer tickets sensibles ni permitir cambios indebidos en reglas del sistema.
Separa roles (y mantenlos simples)
Empieza con pocos roles claros y añade matices solo cuando haya una necesidad real:
- Agente: trabaja tickets, añade notas, responde y actualiza campos.
- Líder: todo lo que puede hacer un agente, además de reasignar, gestionar colas y flujos de coaching.
- Administrador: configuración global como canales, gestión de usuarios y ajustes.
- Editor de contenido: crea y publica artículos de la base de conocimiento.
- Solo lectura: auditoría, finanzas, legal o stakeholders que requieren visibilidad sin cambios.
Define permisos por capacidad
Evita el acceso “todo o nada”. Trata las acciones importantes como permisos explícitos:
- Ver vs editar tickets (incluyendo notas privadas)
- Gestionar macros/respuestas prediseñadas
- Editar reglas de SLA, temporizadores y políticas de escalación
- Publicar/despublicar contenido KB
Esto facilita conceder acceso con principio de menor privilegio y soportar crecimiento (nuevos equipos, regiones, contratistas).
Acceso por equipo para colas sensibles
Algunas colas deberían estar restringidas por defecto—facturación, seguridad, VIP o solicitudes relacionadas con RR. HH. Usa la pertenencia a equipo para controlar:
- Qué colas son visibles
- Quién puede reasignar o fusionar tickets
- Si los campos de datos del cliente se enmascaran
Registros de auditoría que realmente usarás
Registra acciones clave con quién, qué, cuándo y valores antes/después: cambios de asignación, eliminaciones, ediciones de SLA/políticas, cambios de rol y publicación de KB. Haz los logs buscables y exportables para que las investigaciones no requieran acceso a BD.
Planea multi-marca o multi-bandeja desde temprano
Si soportas varias marcas o bandejas, decide si los usuarios cambian de contexto o si el acceso está particionado. Esto afecta verificaciones de permiso e informes y debería ser consistente desde el día uno.
Diseña la experiencia de usuario para agentes y administradores
Un sistema de tickets se gana o se pierde por lo rápido que los agentes pueden entender una situación y tomar la siguiente acción. Trata el espacio de trabajo del agente como tu “pantalla principal”: debe responder tres preguntas inmediatamente—qué pasó, quién es este cliente y qué debo hacer ahora.
Disposición del espacio de trabajo del agente
Comienza con una vista dividida que mantenga el contexto visible mientras el agente trabaja:
- Hilo de conversación (email/chat/mensajes) con marcas de tiempo claras, adjuntos y citas.
- Panel del cliente con identidad, plan/nivel de cuenta, organización, tickets pasados y notas clave.
- Campos del ticket (estado, prioridad, cola, asignado, etiquetas, temporizadores SLA) agrupados lógicamente, no dispersos.
Mantén el hilo legible: diferencia cliente vs agente vs eventos del sistema, y haz que las notas internas sean visualmente distintas para que nunca se envíen por error.
Acciones de un clic que eliminen fricción
Pon acciones comunes donde ya está el cursor—cerca del último mensaje y en la parte superior del ticket:
- Asignar / reasignar
- Cambiar estado (incluyendo “en espera del cliente”)
- Añadir nota interna
- Aplicar macro (respuesta prellenada + actualizaciones de campos)
Apunta a “un clic + comentario opcional”. Si una acción necesita un modal, que sea corto y manejable por teclado.
Funciones de velocidad para equipos de alto volumen
El soporte de alto rendimiento necesita atajos previsibles:
- Atajos de teclado para responder, añadir nota, asignarme, cerrar y siguiente ticket
- Acciones masivas en vistas de lista (etiquetar, asignar, cerrar, fusionar)
- Una paleta de comandos rápida para usuarios avanzados
Accesibilidad y seguridad de la UI
Construye accesibilidad desde el día uno: contraste suficiente, estados de foco visibles, navegación por tabulación completa y etiquetas para lectores de pantalla en controles y temporizadores. También previene errores costosos con pequeñas salvaguardas: confirma acciones destructivas, etiqueta claramente “respuesta pública” vs “nota interna” y muestra lo que se enviará antes de enviar.
UX para admin y portal de clientes
Los administradores necesitan pantallas simples y guiadas para colas, campos, automatizaciones y plantillas—evita ocultar lo esencial tras ajustes anidados.
Si los clientes pueden enviar y seguir incidencias, diseña un portal liviano: crear ticket, ver estado, añadir actualizaciones y ver artículos sugeridos antes de enviar. Manténlo consistente con tu marca pública y enlázalo desde /help.
Planifica integraciones, APIs y entrada omnicanal
Lanza tu v1 más rápido
Prototipa una app de tickets con colas, SLAs y un portal describiéndola por chat.
Una app de tickets se vuelve útil cuando se conecta a los lugares donde los clientes ya hablan contigo y a las herramientas que tu equipo usa para resolver incidencias.
Comienza con los sistemas que debes conectar
Lista tus integraciones “día uno” y qué datos necesitas de cada una:
- Correo (bandejas compartidas, reglas de reenvío, SMTP saliente)
- Chat (widget web, WhatsApp, herramientas estilo Intercom)
- CRM (contexto de cuenta, propietario, nivel de plan)
- Facturación (estado de suscripción, facturas, reembolsos)
- Proveedor de identidad (SSO vía Google/Microsoft, aprovisionamiento SCIM)
Escribe la dirección del flujo de datos (solo lectura vs escritura) y quién posee cada integración internamente.
Diseña tu API y webhooks desde temprano
Aunque publiques integraciones después, define primitivas estables ahora:
- Endpoints API para crear, actualizar y buscar tickets, además de comentarios/mensajes y cambios de estado.
- Webhooks para eventos clave (ticket.created, ticket.updated, message.received, sla.breached) para que sistemas externos reaccionen.
Mantén la autenticación predecible (API keys para servidores; OAuth para apps instaladas por usuarios) y versiona la API para evitar romper clientes.
Evita tickets duplicados con buen threading de email
El email es donde aparecen primeros los casos límite. Planea cómo:
- Encadenar respuestas usando cabeceras Message-ID / In-Reply-To / References
- Parsear mensajes reenviados y firmas comunes de forma segura
- Deduplificar detectando payloads entrantes repetidos (especialmente de proveedores de correo)
Una pequeña inversión aquí evita desastres de “cada respuesta crea un ticket nuevo”.
Maneja adjuntos de forma segura
Soporta adjuntos, pero con guardarraíles: límites de tipo/tamaño de archivo, almacenamiento seguro y ganchos para escaneo de virus (o un servicio de escaneo). Considera eliminar formatos peligrosos y nunca renderizar HTML no confiable inline.
Documenta la configuración como una característica de producto
Crea una guía de integración corta: credenciales requeridas, configuración paso a paso, resolución de problemas y pasos de prueba. Si mantienes docs, enlaza tu hub de integraciones en /docs para que los administradores no necesiten ayuda de ingeniería para conectar sistemas.
Añade analítica e informes para el desempeño del soporte
La analítica es donde tu sistema de tickets deja de ser “un lugar para trabajar” y se convierte en “una forma de mejorar”. La clave es capturar los eventos correctos, calcular unas métricas consistentes y presentarlas a audiencias distintas sin exponer datos sensibles.
Empieza con una traza de eventos (no solo el estado actual del ticket)
Guarda los momentos que explican por qué un ticket luce como luce. Como mínimo, registra: cambios de estado, respuestas de cliente y agente, asignaciones y reasignaciones, actualizaciones de prioridad/categoría y eventos del temporizador SLA (inicio/parada, pausas e incumplimientos). Esto te permite responder preguntas como “¿Incumplimos porque teníamos poco personal, o porque esperamos al cliente?”
Mantén los eventos append-only cuando sea posible; hace auditoría e informes más fiables.
Dashboards para líderes de equipo
Los líderes suelen necesitar vistas operativas accionables hoy:
- Backlog por cola, prioridad y categoría
- Tickets envejecidos (p. ej., más antiguos abiertos, más antiguos esperando cliente)
- Riesgo de SLA (tickets que probablemente incumplan en X horas)
- Carga de trabajo por agente (conteo asignado, trabajo activo, tiempo desde la última actualización)
Haz estos dashboards filtrables por rango temporal, canal y equipo—sin forzar a los managers a usar hojas de cálculo.
Informes para ejecutivos
A los ejecutivos les importan menos los tickets individuales y más las tendencias:
- Volumen por categoría/canal, incluyendo días y horas pico
- Tendencias de primera respuesta y resolución (mediana y percentil 90)
- Tendencias de CSAT (y tasa de respuesta, para que las puntuaciones no engañen)
Si enlazas resultados a categorías, puedes justificar staffing, formación o correcciones de producto.
Filtros, exportaciones y controles de acceso
Añade exportación CSV para vistas comunes, pero protégela con permisos (y, idealmente, controles a nivel de campo) para evitar filtrar emails, cuerpos de mensajes o identificadores de clientes. Registra quién exportó qué y cuándo.
Retención de datos sin promesas arriesgadas
Define cuánto tiempo conservas eventos de ticket, contenido de mensajes, adjuntos y agregados analíticos. Prefiere ajustes de retención configurables y documenta qué se elimina realmente frente a lo que se anonimiza para no prometer garantías que no puedes verificar.
Elige una arquitectura y stack tecnológico prácticos
Un producto de tickets no necesita una arquitectura compleja para ser efectivo. Para la mayoría de equipos, una configuración simple se entrega antes, es más fácil de mantener y aún escala bien.
Comienza con un diagrama de sistema sencillo
Una base práctica se ve así:
- Frontend web: UI de agente/admin y formularios/portal para clientes
- Backend API: reglas de negocio para tickets, SLAs, usuarios y KB
- Base de datos: fuente de verdad para tickets, usuarios, eventos y ajustes
- Trabajos en segundo plano: cualquier tarea programada o larga
Este enfoque de “monolito modular” (un backend, módulos claros) mantiene la v1 manejable y deja espacio para dividir servicios después si es necesario.
Si quieres acelerar una v1 sin reinventar todo, una plataforma de prototipado como Koder.ai puede ayudarte a prototipar el panel de agente, el ciclo de tickets y las pantallas admin vía chat—luego exportar código fuente cuando estés listo para tener control total.
Sabe qué debe ejecutarse en segundo plano
Los sistemas de tickets parecen en tiempo real, pero mucho trabajo es asíncrono. Planifica trabajos en background desde temprano para:
- Temporizadores SLA y escalaciones (p. ej., “primera respuesta en 30 minutos”)
- Notificaciones (email, in-app, webhooks)
- Indexado de búsqueda (tickets y artículos KB)
- Procesamiento de correo entrante (parseo, adjuntos, threading)
Si el procesamiento en background es un pensamiento tardío, los SLAs se vuelven poco fiables y los agentes pierden confianza.
Almacena datos para exactitud, busca para velocidad
Usa una base relacional (PostgreSQL/MySQL) para registros centrales: tickets, comentarios, estados, asignaciones, políticas SLA y una tabla de auditoría/eventos.
Para búsqueda rápida y relevante, mantén un índice de búsqueda separado (Elasticsearch/OpenSearch o un equivalente gestionado). No intentes que tu base relacional haga búsqueda full-text a escala si tu producto depende de ella.
Decide construir vs comprar (y por qué)
Tres áreas suelen ahorrar meses si se compran:
- Autenticación: usa un proveedor probado (SSO, MFA, políticas de contraseña)
- Entrega de email: servicio de email transaccional para entregabilidad y manejo de rebotes
- Búsqueda: búsqueda gestionada si no tienes expertise interno
Construye lo que te diferencia: reglas de flujo, comportamiento de SLA, lógica de enrutamiento y la experiencia del agente.
Planifica hitos con una lista clara de v1
Estima esfuerzo por hitos, no por características. Una lista sólida de hitos de v1 es: CRUD de tickets + comentarios, asignación básica, temporizadores SLA (núcleo), notificaciones por email, informes mínimos. Mantén los “lujos” fuera del alcance hasta que el uso de la v1 demuestre lo que importa.
Cubre lo básico de seguridad, privacidad y fiabilidad
Despliega sin configuración extra
Despliega y aloja tu app de soporte cuando estés listo para ponerla en producción.
Las decisiones de seguridad y fiabilidad son más sencillas (y baratas) si las integras desde el principio. Una app de soporte maneja conversaciones sensibles, adjuntos y detalles de cuenta—trátala como un sistema central, no como una herramienta secundaria.
Protege los datos de clientes por defecto
Comienza con cifrado en tránsito en todas partes (HTTPS/TLS), incluyendo llamadas internas entre servicios si tienes varios. Para datos en reposo, cifra bases y almacenamiento de objetos (adjuntos) y guarda secretos en un vault gestionado.
Aplica acceso con menor privilegio: los agentes solo deben ver los tickets que pueden manejar y los administradores deben tener derechos elevados solo cuando hacen falta. Añade registros de acceso para poder responder “¿quién vio/exportó qué y cuándo?” sin conjeturas.
Elige autenticación que se adapte a tu audiencia
La autenticación no es igual para todos. Para equipos pequeños, email + contraseña puede bastar. Si vendes a organizaciones grandes, SSO (SAML/OIDC) puede ser requisito. Para portales ligeros de clientes, un enlace mágico reduce fricción.
Sea lo que sea, asegura sesiones (tokens de corta vida, estrategia de refresh, cookies seguras) y añade MFA para cuentas admin.
Prevén ataques comunes antes de que empiecen
Pon limitación de tasa en login, creación de tickets y endpoints de búsqueda para frenar fuerza bruta y spam. Valida y sanea entradas para prevenir inyección y HTML inseguro en comentarios.
Si usas cookies, añade protección CSRF. Para APIs, aplica reglas CORS estrictas. Para subidas de archivos, escanea malware y restringe tipos/tamaños.
Backups, recuperación y objetivos medibles
Define objetivos RPO/RTO (cuánto dato puedes perder, qué rapidez para volver). Automatiza backups para DB y almacenamiento de archivos, y—crucialmente—prueba restauraciones con regularidad. Un backup que no puedes restaurar no es backup.
Básicos de privacidad que tus usuarios pedirán
Las apps de soporte suelen recibir solicitudes de privacidad. Ofrece formas de exportar y borrar datos de clientes y documenta qué se elimina vs conserva por razones legales/audit. Mantén rastros de auditoría y logs de acceso disponibles para admins (ver /security) para poder investigar incidentes rápidamente.
Prueba, lanza y mejora con equipos de soporte reales
Lanzar una app de soporte no es el punto final: es el comienzo de aprender cómo trabajan los agentes bajo presión real. El objetivo de pruebas y despliegue es proteger el soporte diario mientras validas que tu sistema de tickets y gestión de SLAs funciona correctamente.
Escribe escenarios E2E que reflejen trabajo real
Más allá de pruebas unitarias, documenta (y automatiza cuando sea posible) un conjunto pequeño de escenarios de extremo a extremo que reflejen tus flujos de mayor riesgo:
- Creación de ticket: intake por email/web/API crea un ticket con los campos correctos, identidad del cliente y estado inicial.
- Respuestas y threading: las respuestas del cliente se adhieren al ticket correcto, las respuestas de agentes notifican al cliente y las notas internas permanecen internas.
- Incumplimientos de SLA: los temporizadores arrancan/paran correctamente (p. ej., pausa en “En espera del cliente”), los incumplimientos disparan la escalación correcta y la traza de auditoría registra lo ocurrido.
- Búsqueda en KB: los agentes encuentran artículos relevantes desde la vista de ticket y los clientes ven sugerencias antes de enviar.
Si tienes un entorno staging, pópulalo con datos realistas (clientes, etiquetas, colas, horas laborales) para que las pruebas no pasen “en teoría”.
Ejecuta un piloto y recoge feedback semanalmente
Comienza con un grupo pequeño de soporte (o una sola cola) por 2–4 semanas. Establece un ritual semanal de feedback: 30 minutos para revisar qué los ralentizó, qué confundió a los clientes y qué reglas sorprendieron.
Mantén el feedback estructurado: “¿Cuál era la tarea?”, “¿Qué esperabas?”, “¿Qué pasó?” y “¿Con qué frecuencia ocurre?”. Esto ayuda a priorizar arreglos que afectan throughput y cumplimiento de SLA.
Crea una lista de verificación de onboarding para admins y agentes
Haz el onboarding repetible para que el despliegue no dependa de una sola persona.
Incluye esenciales como: iniciar sesión, vistas de cola, responder vs nota interna, asignar/mencionar, cambiar estado, usar macros, leer indicadores SLA y encontrar/crear artículos KB. Para admins: gestionar roles, horas laborales, etiquetas, automatizaciones y básicos de reporting.
Planea un despliegue por fases (con opción de rollback)
Despliega por equipo, canal o tipo de ticket. Define un camino de rollback por adelantado: cómo volver a enrutar intake temporalmente, qué datos necesitarían re-sincronizarse y quién toma la decisión.
Los equipos que construyen sobre Koder.ai a menudo usan snapshots y rollback durante pilotos tempranos para iterar con seguridad en flujos (colas, SLAs y formularios de portal) sin interrumpir operaciones en vivo.
Establece una hoja de ruta de iteración
Cuando el piloto se estabilice, planifica mejoras en oleadas:
- Mejor automatización (macros, triggers, auto-etiquetado)
- Enrutamiento avanzado (asignación por habilidades, balanceo de carga)
- Flujos KB más ricos (revisión de artículos, bucles de feedback, métricas de desvío)
Trata cada oleada como un pequeño release: prueba, piloto, mide y luego expande.