Qué debe resolver esta aplicación web
La mayoría de los equipos no fracasan en la experimentación por falta de ideas: fracasan porque los resultados están dispersos. Un producto tiene gráficos en una herramienta analítica, otro tiene una hoja de cálculo, un tercero tiene una presentación con capturas. Unos meses después, nadie puede responder preguntas sencillas como “¿Ya probamos esto?” o “¿Qué versión ganó, usando qué definición de métrica?”.
El problema central: resultados fragmentados y verdad inconsistente
Una aplicación de seguimiento de experimentos debe centralizar qué se probó, por qué, cómo se midió y qué pasó —a través de múltiples productos y equipos. Sin esto, los equipos pierden tiempo rehaciendo informes, discutiendo números y volviendo a ejecutar tests antiguos porque los aprendizajes no son buscables.
Para quién es (y qué necesita cada grupo)
No es solo una herramienta de analistas.
- Product managers necesitan una forma rápida de ver resultados, confianza y estado de decisión.
- Analistas necesitan un lugar fiable para documentar supuestos, definiciones de métricas y matices.
- Ingenieros necesitan claridad sobre qué feature flags, variantes y condiciones de rollout estaban en el alcance.
- Liderazgo necesita una vista consistente del impacto entre productos, sin decks hechos a medida.
Resultados que optimizar
Un buen tracker crea valor de negocio habilitando:
- Decisiones más rápidas (menos tiempo persiguiendo enlaces y aprobaciones)
- Menos errores de reporte (una única fuente de verdad para “los números finales”)
- Aprendizajes compartidos (historial buscable de éxitos, fracasos y tests neutrales)
Límites de alcance claros
Sé explícito: esta app es principalmente para rastrear y reportar resultados de experimentos—no para ejecutar experimentos de extremo a extremo. Puede enlazar a herramientas existentes (feature flagging, analíticas, data warehouse) mientras posee el registro estructurado del experimento y su interpretación final acordada.
Requisitos: el tracker de experimentos mínimamente viable
Un tracker mínimamente viable debe responder dos preguntas sin buscar en docs o hojas de cálculo: qué estamos probando y qué aprendimos. Empieza con un pequeño conjunto de entidades y campos que funcionen entre productos, y expande solo cuando los equipos sientan dolor real.
Entidades centrales a soportar
Mantén el modelo de datos lo bastante simple para que todos los equipos lo usen igual:
- Producto: la superficie (app/sitio/API) donde se despliega el cambio.
- Experimento: una hipótesis y una decisión.
- Variante: control y una o más variantes.
- Métrica: una medida nombrada con un owner y definición.
- Segmento: cortes de audiencia opcionales (usuarios nuevos, usuarios de pago, región) usados en reporting.
Tipos de experimento (empieza pequeño, mantente flexible)
Soporta los patrones más comunes desde el día uno:
- A/B tests (control vs tratamiento)
- Tests multivariantes (múltiples variantes)
- Rollouts con feature flags (exposición por porcentaje)
Aunque los rollouts no usen estadística formal al principio, rastrearlos junto a los experimentos ayuda a evitar repetir los mismos “tests” sin registro.
Campos mínimos que necesita cada experimento
Al crearlo, requiere solo lo necesario para ejecutar e interpretar el test más tarde:
- Hipótesis (qué cambio, para quién y por qué)
- Owner (persona responsable única)
- Fechas de inicio/fin (planificadas y reales)
- Targeting (reglas de elegibilidad) y asignación (split de tráfico)
- Enlaces a rollout/flag, ticket o spec (URLs relativas como /projects/123)
Criterios de éxito y estado de decisión
Haz los resultados comparables forzando estructura:
- Métrica primaria (la medida principal de éxito)
- Guardrails (métricas que no deben empeorar)
- Estado de decisión: proposed → running → analyzed → shipped/rolled back → archived
Si construyes solo esto, los equipos podrán encontrar experimentos, entender la configuración y registrar resultados, incluso antes de añadir analíticas avanzadas o automatización.
Modelo de datos que funciona entre múltiples productos
Un tracker cross-product triunfa o fracasa por su modelo de datos. Si los IDs colisionan, las métricas derivan o los segmentos son inconsistentes, tu dashboard puede parecer “correcto” mientras cuenta la historia equivocada.
Elige identificadores estables (y cíñete a ellos)
Empieza con una estrategia de identificadores clara:
- product_id: estable a pesar de renombres (no uses nombres de display como claves)
- experiment_key: slug legible (p. ej.,
checkout_free_shipping_banner) además de un experiment_id inmutable
- variant_key: etiquetas estables como
control, treatment_a
Esto permite comparar resultados entre productos sin adivinar si “Web Checkout” y “Checkout Web” son lo mismo.
Colecciones/tablas centrales
Mantén las entidades principales pequeñas y explícitas:
- experiments: product_id, hypothesis, primary_metric_def_id, start/end, status
- variants: experiment_id, variant_key, traffic_split
- assignments: experiment_id, user_id (o anonymous_id), variant_key, assigned_at
- metric_defs: nombre de métrica, lógica numerador/denominador, unidad (usuario/sesión/pedido), owner
- results: experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
Aunque el cálculo ocurra en otro sitio, almacenar las salidas (results) permite dashboards rápidos y un historial fiable.
Ventanas temporales y versionado
Las métricas y experimentos no son estáticos. Modela:
- ventanas temporales (por ejemplo, “primeros 7 días tras la asignación”, “semanas calendario”)
- definiciones de métrica versionadas: cuando la fórmula cambia, crea una versión nueva en lugar de editar la anterior
Esto evita que los experimentos del mes pasado cambien cuando alguien actualiza la lógica del KPI.
Segmentos y rastro de auditoría
Planifica segmentos consistentes entre productos: país, dispositivo, plan, nuevo vs recurrente.
Finalmente, añade un rastro de auditoría que capture quién cambió qué y cuándo (cambios de estado, splits de tráfico, actualizaciones de definiciones de métricas). Es esencial para confianza, revisiones y gobernanza.
Definiciones de métricas y cálculos consistentes
Si tu tracker calcula mal las métricas (o de forma inconsistente entre productos), el “resultado” es solo una opinión con un gráfico. La forma más rápida de evitarlo es tratar las métricas como activos compartidos, no como snippets de query ad‑hoc.
Construye un catálogo canónico de métricas
Crea un catálogo de métricas que sea la única fuente de verdad para definiciones, lógica de cálculo y ownership. Cada entrada debe incluir:
- Una definición en lenguaje claro (qué decisión soporta)
- Un owner (persona/equipo responsable de cambios)
- La fórmula exacta y los eventos/campos requeridos
- Reglas de inclusión/exclusión (p. ej., usuarios internos, bots, pedidos reembolsados)
- Niveles de agregación válidos y productos soportados
Mantén el catálogo cerca del flujo de trabajo (por ejemplo, enlazado desde la creación de experimentos) y versionado para explicar resultados históricos.
Estandariza niveles de agregación
Decide de antemano cuál es la “unidad de análisis” para cada métrica: por usuario, por sesión, por cuenta o por pedido. Una tasa de conversión “por usuario” puede diferir de “por sesión” aunque ambas sean correctas.
Para reducir confusión, guarda la elección de agregación con la definición de la métrica y exígela al configurar un experimento. No dejes que cada equipo elija la unidad ad hoc.
Maneja conversiones retrasadas y atribución
Muchos productos tienen ventanas de conversión (p. ej., registro hoy, compra en 14 días). Define reglas de atribución consistentemente:
- ¿Cuándo empieza el reloj? (tiempo de exposición, primera visita, momento de asignación)
- ¿Qué cuenta como conversión si un usuario es expuesto múltiples veces?
- ¿Cómo manejar viajes cross-device o cross-product?
Haz estas reglas visibles en el dashboard para que el lector sepa qué está viendo.
Almacena conteos crudos y estadísticas calculadas
Para dashboards rápidos y auditabilidad, almacena ambos:
- Conteos crudos (exposiciones, conversores, sumas de ingresos, insumos para varianza)
- Estadísticas computadas (lift, intervalos de confianza, p-values)
Esto permite renderizar rápido y aún recomputar cuando cambien definiciones.
Convenciones de nombres para evitar proliferación de métricas
Adopta un estándar de nombres que codifique significado (p. ej., activation_rate_user_7d, revenue_per_account_30d). Exige IDs únicos, soporta alias, y marca casi-duplicados al crear métricas para mantener el catálogo limpio.
Recolección de datos: eventos, pipelines y checks de calidad
Tu tracker solo es creíble si los datos que ingresa lo son. El objetivo es poder responder para cada producto: quién fue expuesto a qué variante y qué hizo después. Todo lo demás (métricas, estadísticas, dashboards) depende de esa base.
Elige un enfoque de ingestión
La mayoría elige uno de estos patrones:
- Stream de eventos (near real-time): ideal para lecturas rápidas y depuración más veloz. Requiere madurez de ingeniería para mantenerse estable.
- Batch diario: más sencillo y barato. Mejor cuando las decisiones no necesitan ser horarias.
- Híbrido: stream para exposiciones y eventos críticos (valida asignaciones rápido), batch para el resto por completitud y coste.
Sea cual sea, estandariza el conjunto mínimo de eventos entre productos: exposición/asignación, eventos clave de conversión, y contexto suficiente para unirlos (user ID/device ID, timestamp, experiment ID, variant).
Mapea eventos del producto a métricas (y valida completitud)
Define un mapeo claro de eventos crudos a las métricas que reportará el tracker (p. ej., purchase_completed → Revenue, signup_completed → Activation). Mantén este mapeo por producto, pero con nombres consistentes para comparar “manzana con manzana”.
Valida la completitud temprano:
- Confirma que toda exposición tiene experiment ID y variante.
- Asegura que los eventos de conversión incluyan los mismos campos de identidad usados para las uniones.
- Vigila pérdidas de eventos entre cliente, servidor y warehouse (los SDKs móviles suelen ser culpables comunes).
Comprobaciones de calidad de datos que debes automatizar
Construye checks que corran en cada carga y fallen en alto:
- Exposiciones faltantes: conversiones sin exposición previa (a menudo gaps de instrumentación o mismatch de identidad).
- Asignaciones sesgadas: variantes recibiendo 70/30 cuando esperabas 50/50 (puede indicar bugs de targeting).
- Sanidad de timestamps: exposiciones después de conversiones, o retrasos grandes que sugieran problemas de reloj.
Muestra estos avisos en la app como warnings adjuntos al experimento, no ocultos en logs.
Backfills y reprocesado
Los pipelines cambian. Cuando arregles un bug de instrumentación o deduplicación, necesitarás reprocesar datos históricos para mantener métricas e KPIs consistentes.
Planifica para:
- transformaciones versionadas (para saber qué lógica produjo cada resultado)
- backfills seguros (limita por fecha/producto/experimento)
- un rastro de auditoría de la recomputación
Documenta integraciones
Trata las integraciones como features de producto: documenta SDKs soportados, esquemas de eventos y pasos de troubleshooting. Si tienes un área de docs, enlázala con rutas relativas como /docs/integrations.
Estadística y cálculo de resultados en los que se pueda confiar
Añade RBAC desde el primer día
Crea roles Viewer, Editor y Admin para mantener el acceso entre productos ordenado.
Si la gente no confía en los números, no usará el tracker. El objetivo no es impresionar con matemáticas —es hacer decisiones repetibles y defendibles entre productos.
Elige un “dialecto” estadístico y adhiérete a él
Decide si la app reportará resultados frecuentistas (p-values, intervalos de confianza) o bayesianos (probabilidad de mejora, intervalos creíbles). Ambos funcionan, pero mezclarlos entre productos confunde (“¿Por qué este test muestra 97% de probabilidad de ganar, mientras que aquel tiene p=0.08?”).
Una regla práctica: elige el enfoque que tu org ya entienda y estandariza terminología, valores por defecto y umbrales.
Define exactamente qué muestra la UI
Como mínimo, la vista de resultados debe aclarar:
- Lift (absoluto y/o relativo) vs control
- Intervalo (intervalo de confianza o creíble) mostrado como rango, no solo punto
- Fuerza de evidencia (p-value para frecuentista, o probabilidad de superar al control para bayesiano)
También muestra la ventana de análisis, unidad contada (usuarios, sesiones, pedidos) y la versión de la definición de métrica usada. Estos “detalles” marcan la diferencia entre reportes consistentes y debates.
Comparaciones múltiples y políticas de “peeking”
Si los equipos prueban muchas variantes, muchas métricas o revisan resultados diariamente, hay más falsos positivos. La app debe codificar una política en lugar de dejarla a cada equipo:
- Comparaciones múltiples: decide si ajustas (p. ej., controlar FDR) o etiquetas claramente como “no ajustado/exploratorio”.
- Peeking repetido: o bien (1) lo desincentivas con fecha final fija y estado “finalizado”, o (2) soportas métodos secuenciales y muestras guía de “safe-to-stop”.
Guardrails que atrapen fallos comunes
Añade flags automáticos junto a los resultados, no ocultos en logs:
- Sample Ratio Mismatch (SRM): advierte cuando el split de tráfico difiere del esperado.
- Detección de anomalías: marca caídas/picos súbitos en tráfico, conversiones o ingresos que puedan indicar roturas de tracking, outages o tráfico bot.
Explicaciones en lenguaje llano
Junto a los números, añade una breve explicación para lectores no técnicos, por ejemplo: “La mejor estimación es +2.1% de lift, pero el efecto real podría estar entre -0.4% y +4.6%. Aún no tenemos evidencia suficiente para declarar un ganador.”
UX y dashboards para tomar decisiones rápidas
Buen tooling de experimentos ayuda a responder dos preguntas rápido: Qué debo mirar a continuación? y Qué deberíamos hacer al respecto? La UI debe minimizar la búsqueda de contexto y hacer explícito el “estado de decisión”.
Páginas clave que anclan el flujo
Empieza con tres páginas que cubren la mayoría del uso:
- Lista de experimentos: una cola ordenable para toda la org (o por producto).
- Detalle del experimento: la fuente única de verdad para configuración, resultados y decisión.
- Resumen del producto: rollup de tests activos, decisiones recientes y salud de métricas por producto.
En la lista y en las páginas de producto, haz filtros rápidos y “pegajosos”: producto, owner, rango de fechas, estado, métrica primaria y segmento. La gente debe poder filtrar a “Experimentos de Checkout, owned por Maya, corriendo este mes, métrica primaria = conversión, segmento = usuarios nuevos” en segundos.
Estados de decisión en los que se pueda confiar
Trata el estado como vocabulario controlado, no texto libre:
Draft → Running → Stopped → Shipped / Rolled back
Muestra el estado en todas partes (filas de lista, cabecera del detalle y enlaces compartidos) y registra quién lo cambió y por qué. Esto previene “lanzamientos silenciosos” y resultados poco claros.
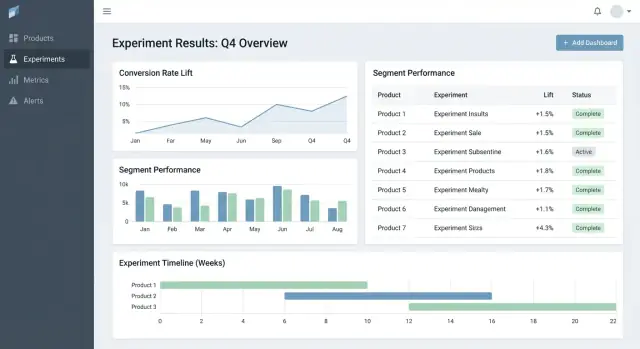
Una tabla de resultados que haga la decisión obvia
En la vista de detalle, lidera con una tabla compacta de resultados por métrica:
- Baseline
- Variante
- Lift
- Incertidumbre (intervalo de confianza o creíble)
- Notas (p. ej., caveats de instrumentación, particularidades del segmento)
Mantén gráficos avanzados en una sección “Más detalles” para no abrumar a quienes deciden.
Compartir y exportar sin perder control
Agrega export CSV para analistas y enlaces compartibles para stakeholders, pero aplica acceso: los enlaces deben respetar roles y permisos por producto. Un botón simple de “Copiar enlace” y una acción “Exportar CSV” cubren la mayoría de necesidades de colaboración.
Permisos, privacidad y gobernanza
Mantén la propiedad total del código
Exporta el código fuente cuando quieras y sigue desarrollando en tu propio repositorio.
Si tu tracker abarca varios productos, el control de acceso y la auditabilidad no son opcionales. Son lo que hace la herramienta segura de adoptar y creíble en revisiones.
Control de acceso basado en roles (RBAC)
Empieza con un conjunto simple de roles y mantenlos consistentes:
- Viewer: acceso solo lectura a experimentos, resultados y dashboards.
- Editor: crear/editar experimentos, subir docs, cambiar estado (draft → running → concluded).
- Admin: gestionar usuarios, permisos, definiciones de métricas, reglas de retención e integraciones.
Centraliza las decisiones RBAC (una capa de políticas) para que UI y API apliquen las mismas reglas.
Permisos por producto y a nivel de fila
Muchas orgs necesitan acceso por producto: el Equipo A ve Productos A pero no B. Módelalo explícitamente (p. ej., membresías user ↔ product) y asegura que cada query sea filtrada por producto.
Para casos sensibles (datos de partners, segmentos regulados), añade restricciones a nivel de fila encima del scope por producto. Una aproximación práctica es etiquetar experimentos (o cortes de resultados) con un nivel de sensibilidad y requerir un permiso adicional para verlos.
Rastro de auditoría: accesos + cambios
Registra dos cosas por separado:
- Logs de cambio: quién editó un experimento, definición de métrica o decisión—qué cambió y cuándo.
- Logs de acceso: quién vio o exportó resultados (especialmente experimentos sensibles).
Expón el historial de cambios en la UI para transparencia y conserva logs profundos para investigaciones.
Reglas de retención y eliminación
Define reglas de retención para:
- Metadatos del experimento (hipótesis, owners, fechas, notas de decisión)
- Resultados computados (efectos, intervalos, flags de significancia)
Haz la retención configurable por producto y sensibilidad. Cuando haya que eliminar datos, guarda un registro mínimo (tombstone) con ID, tiempo de eliminación y razón para preservar integridad de reporting sin retener contenido sensible.
Funcionalidades de workflow: de la idea a la biblioteca de aprendizajes
Un tracker es verdaderamente útil cuando cubre el ciclo completo del experimento, no solo el p-value final. Funcionalidades de workflow convierten docs dispersos, tickets y gráficos en un proceso repetible que mejora la calidad y facilita reutilizar aprendizajes.
Workflow de ciclo de vida: idea → revisión → ejecución → post‑mortem
Modela experimentos como estados (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). Cada estado debe tener criterios de salida claros para que los experimentos no salgan en vivo sin esenciales como hipótesis, métrica primaria y guardrails.
Las aprobaciones no tienen que ser pesadas. Un paso simple de revisor (p. ej., product + data) con rastro de auditoría de quién aprobó qué y cuándo puede prevenir errores evitables. Tras completar, exige un post‑mortem breve antes de marcar “Published” para asegurar que resultados y contexto queden capturados.
Plantillas que estandarizan el pensamiento
Agrega plantillas para:
- Brief del experimento (objetivo, hipótesis, audiencia objetivo, métricas de éxito, guardrails, plan de rollout)
- Notas de análisis (fuentes de datos, exclusiones, checks de sanidad, interpretación, riesgos)
Las plantillas reducen la fricción del “papel en blanco” y aceleran revisiones porque todos saben dónde mirar. Permítelas editar por producto manteniendo un núcleo común.
Aprendizajes: enlaza todo, hazlo buscable
Los experimentos rara vez viven solos—la gente necesita contexto. Permite adjuntar enlaces a tickets/specs y writeups relacionados (por ejemplo: /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). Almacena campos estructurados de “Aprendizaje” como:
- Qué se cambió (decisión)
- Qué aprendimos (insight)
- Qué sigue (siguientes pasos)
Alertas por guardrails y cambios en resultados
Soporta notificaciones cuando los guardrails empeoran (p. ej., tasa de error, cancelaciones) o cuando resultados cambian materialmente tras datos tardíos o recálculo de métricas. Haz las alertas accionables: muestra la métrica, umbral, periodo y un owner para reconocer o escalar.
Una vista de biblioteca para reutilizar trabajo previo
Proporciona una biblioteca filtrable por producto, área de feature, audiencia, métrica, resultado y tags (p. ej., “pricing”, “onboarding”, “mobile”). Añade sugerencias de “experimentos similares” basadas en tags/métricas compartidas para evitar reejecutar lo mismo y favorecer construir sobre aprendizajes previos.
Arquitectura y opciones de stack tecnológico
No necesitas un stack “perfecto” para construir un tracker, pero sí límites claros: dónde viven los datos, dónde corren los cálculos y cómo acceden los equipos a resultados consistentemente.
Un stack baseline práctico
Para muchos equipos, una configuración simple y escalable es:
- Frontend: React (o Vue) para dashboards y workflows
- Backend API: Node.js/Express, Python/FastAPI o Java/Spring—elige lo que el equipo pueda mantener
- Base de datos: Postgres para datos de app (experimentos, definiciones de métricas, permisos)
- Data warehouse: BigQuery/Snowflake/Redshift para eventos y agregaciones pesadas
Esta separación mantiene workflows transaccionales rápidos mientras el warehouse hace cómputo a gran escala.
Si quieres prototipar la UI de workflow rápido (lista de experimentos → detalle → readout) antes de un ciclo completo de ingeniería, una plataforma de prototipado como Koder.ai puede ayudarte a generar una base React + backend desde una especificación conversacional. Es útil para sacar entidades, formularios, scaffolding RBAC y CRUD audit-friendly, y luego iterar en los contratos de datos con el equipo de analítica.
Dónde deben vivir los cálculos de métricas
Típicamente tienes tres opciones:
- Warehouse-first: modelos SQL calculan métricas y tablas de resultados. La app solo lee.
- Jobs en backend: un worker calcula resultados en horarios o cuando cambian experimentos.
- Híbrido: agregaciones canónicas en warehouse y post‑procesado en backend (formateo, guardrails, cache).
Warehouse-first suele ser la opción más simple si el equipo de datos ya posee SQL confiable. Backend-heavy funciona cuando necesitas baja latencia o lógica custom, pero aumenta la complejidad de la app.
Rendimiento: cache y precomputado
Los dashboards repiten consultas (KPIs top-line, series temporales, cortes por segmento). Planea:
- Precomputar rollups (agregados diarios por experimento/variante/segmento)
- Cachear lecturas caras en la capa API (p. ej., Redis) con reglas claras de invalidación
- Usar materialized views o tablas programadas en el warehouse para dashboards comunes
Multi‑tenant vs single‑tenant
Si soportas muchos productos/unidades de negocio, decide temprano:
- Single-tenant (esquema compartido): más fácil de operar, pero requiere filtrado de permisos estricto.
- Multi-tenant: esquemas/proyectos separados por producto/equipo para mayor aislamiento, más overhead.
Un compromiso común es infraestructura compartida con un modelo fuerte de tenant_id y acceso a nivel de fila aplicado.
Define las APIs centrales
Mantén la superficie de la API pequeña y explícita. La mayoría de sistemas necesitan endpoints para experiments, metrics, results, segments y permissions (más lecturas audit‑friendly). Esto facilita añadir productos sin reescribir la tubería.
Testing, monitorización y operaciones fiables
Añade una vista móvil
Crea una app complementaria en Flutter para lecturas rápidas y comprobaciones de estado.
Un tracker solo es útil si la gente confía en él. Esa confianza viene de testing disciplinado, monitorización clara y operaciones predecibles—especialmente cuando múltiples productos y pipelines alimentan los mismos dashboards.
Observabilidad acorde al uso de la app
Empieza con logging estructurado para cada paso crítico: ingestión de eventos, asignación, rollups de métricas y cálculo de resultados. Incluye identificadores como product, experiment_id, metric_id y pipeline run_id para que soporte rastree un resultado hasta sus inputs.
Añade métricas del sistema (latencia API, tiempos de jobs, profundidad de colas) y métricas de datos (eventos procesados, % eventos tardíos, % rechazados por validación). Compleméntalo con tracing entre servicios para responder: “¿Por qué falta ayer en este experimento?”.
Los checks de frescura de datos son la forma más rápida de prevenir fallos silenciosos. Si un SLA es “diario a las 9am”, monitoriza frescura por producto y fuente, y alerta cuando:
- falta la partición más reciente
- el volumen de eventos cae bruscamente respecto al baseline
- jobs de rollup terminan pero producen cero filas
Tests automáticos: protege los datos y las matemáticas
Crea tests en tres niveles:
- Esquema y constraints: campos requeridos, unicidad (p. ej., una asignación por usuario por experimento), claves foráneas y rangos de fecha válidos.
- Permisos: tests RBAC (viewer/editor/admin) y scoping por producto para que equipos solo vean lo suyo.
- Matemáticas de resultados: tests unitarios para lift, intervalos, flags de significancia y casos límite (muestras pequeñas, denominadores cero, múltiples variantes).
Mantén un pequeño “golden dataset” con salidas conocidas para detectar regresiones antes de publicar.
Deploys, migraciones y seguridad histórica
Trata las migraciones como parte de operaciones: versiona definiciones de métricas y lógica de cómputo, y evita reescribir experimentos históricos salvo solicitud explícita. Cuando se requiera un cambio, provee ruta de backfill controlada y documenta qué cambió en el rastro de auditoría.
Herramientas de admin para incidentes y reprocesado
Proporciona una vista admin para re‑ejecutar un pipeline para un experimento/rango de fechas específico, inspeccionar errores de validación y marcar incidentes con actualizaciones de estado. Enlaza notas de incidentes directamente desde experimentos afectados para que los usuarios entiendan retrasos y no tomen decisiones con datos incompletos.
Plan de rollout y errores comunes a evitar
Desplegar un tracker entre productos es menos sobre “día de lanzamiento” y más sobre reducir ambiguedad gradualmente: qué se rastrea, quién lo posee y si los números coinciden con la realidad.
Secuencia de rollout práctica
Empieza con un producto y un set pequeño y de alta confianza de métricas (por ejemplo: conversión, activación, ingresos). El objetivo es validar el flujo end-to-end —crear experimento, capturar exposición y outcomes, calcular resultados y registrar la decisión— antes de escalar la complejidad.
Cuando el primer producto esté estable, expande producto a producto con un cadence de onboarding predecible. Cada nuevo producto debe sentirse como una configuración repetible, no un proyecto custom.
Si tu org se atasca en largos ciclos de construcción, considera una aproximación de dos vías: construye contratos de datos duraderos (eventos, IDs, definiciones de métricas) en paralelo con una capa de aplicación delgada. Algunos equipos usan Koder.ai para levantar esa capa delgada rápidamente—formularios, dashboards, permisos y export—y luego la endurecen conforme crece la adopción (incluyendo export de código fuente y rollbacks iterativos vía snapshots cuando cambian requisitos).
Checklist de rollout por producto
Usa una checklist ligera para onboardear productos y esquemas de eventos consistentemente:
- Confirma taxonomía de eventos y convenciones de nombres (y quién puede cambiarlas)
- Verifica que existan eventos de exposición y sean atribuibles a unívocos
- Mapea métricas al esquema de eventos del producto (incluyendo casos límite como reembolsos)
- Ejecuta un periodo de backfill o ejecución paralela para comparar con analítica existente
- Asigna ownership para setup del experimento, validación de datos y notas de decisión final
Donde ayude la adopción, enlaza “siguientes pasos” desde resultados a áreas relevantes del producto (por ejemplo, experimentos de pricing pueden enlazar a /pricing). Mantén los enlaces informativos y neutrales—sin implicar resultados.
Mide adopción para arreglar fricción temprano
Mide si la herramienta se está volviendo el lugar por defecto para decisiones:
- usuarios activos semanales por rol (PM, analista, ingeniero)
- experimentos creados y completados
- porcentaje con notas de decisión completadas (no solo resultados vistos)
- tiempo desde fin del experimento → decisión registrada
Errores comunes a evitar
En la práctica, la mayoría de despliegues tropiezan con repetidos problemas:
- Definiciones de métricas inconsistentes entre productos (mismo nombre, matemática distinta)
- Tracking de exposición faltante o defectuoso, que sesga resultados
- Ownership poco claro para validación y sign-off, generando experimentos zombi
- Cambios silenciosos de esquema que rompen tendencias sin que nadie lo note
- Escalar a muchas métricas demasiado pronto, antes de que el flujo central sea fiable