26 ago 2025·8 min
Cómo crear productos centrados en IA con modelos en la lógica de la aplicación
Guía práctica para crear productos centrados en IA donde el modelo impulsa decisiones: arquitectura, prompts, herramientas, datos, evaluación, seguridad y monitorización.
Qué significa construir un producto centrado en IA
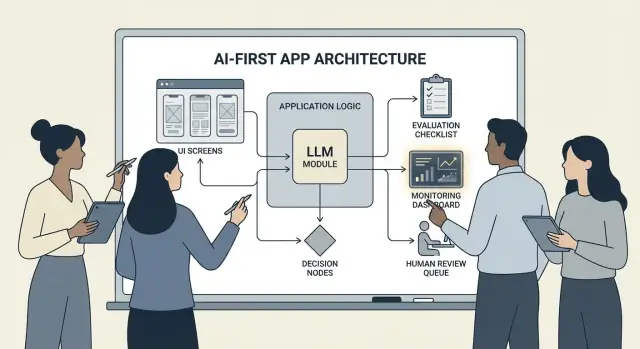
Construir un producto centrado en IA no significa “añadir un chatbot”. Significa que el modelo es una parte real y operativa de la lógica de tu aplicación —del mismo modo que lo sería un motor de reglas, un índice de búsqueda o un algoritmo de recomendaciones.
Tu aplicación no solo usa IA; está diseñada alrededor del hecho de que el modelo interpretará entradas, elegirá acciones y producirá salidas estructuradas de las que depende el resto del sistema.
En términos prácticos: en lugar de codificar a mano cada camino de decisión (“si X entonces hacer Y”), permites que el modelo gestione las partes difusas —lenguaje, intención, ambigüedad, priorización— mientras tu código se encarga de lo que debe ser preciso: permisos, pagos, escrituras en la base de datos y aplicación de políticas.
Cuándo encaja un enfoque centrado en IA (y cuándo no)
Un enfoque centrado en IA funciona mejor cuando el problema tiene:
- Muchas entradas válidas (texto libre, documentos desordenados, objetivos de usuario variados)
- Demasiados casos límite para mantener reglas manualmente
- Valor en el juicio, la síntesis o el resumen más que en una determinación perfecta
La automatización basada en reglas suele ser mejor cuando los requisitos son estables y exactos: cálculos de impuestos, lógica de inventario, comprobaciones de elegibilidad o flujos de cumplimiento donde la salida debe ser la misma siempre.
Objetivos de producto que suele soportar IA-first
Los equipos adoptan lógica impulsada por modelos para:
- Aumentar la velocidad: redactar respuestas, extraer campos, enrutar solicitudes más rápido
- Personalizar experiencias: adaptar explicaciones, planes o recomendaciones
- Apoyar decisiones: resaltar compensaciones, generar opciones, sintetizar evidencia
Compensaciones que debes aceptar (y diseñar para ellas)
Los modelos pueden ser impredecibles, a veces estar convencidos de cosas erróneas, y su comportamiento puede cambiar conforme cambian los prompts, los proveedores o el contexto recuperado. También añaden coste por petición, pueden introducir latencia y plantean preocupaciones de seguridad y confianza (privacidad, salidas dañinas, violaciones de políticas).
La mentalidad correcta es: un modelo es un componente, no una caja mágica de respuestas. Trátalo como una dependencia con especificaciones, modos de fallo, pruebas y monitorización —para obtener flexibilidad sin apostar el producto a la buena suerte.
Elige el caso de uso correcto y define el éxito
No todas las funciones se benefician de poner un modelo al mando. Los mejores casos AI-first empiezan con un trabajo claro por hacer y terminan con un resultado medible que puedas rastrear semana tras semana.
Comienza con el trabajo, no con el modelo
Redacta una historia de trabajo en una frase: “Cuando ___, quiero ___, para poder ___.” Luego haz el resultado medible.
Ejemplo: “Cuando recibo un correo largo de un cliente, quiero una respuesta sugerida que cumpla nuestras políticas, para poder responder en menos de 2 minutos.” Esto es mucho más accionable que “añadir un LLM al correo”.
Mapea los puntos de decisión
Identifica los momentos en los que el modelo elegirá acciones. Estos puntos de decisión deben ser explícitos para que puedas probarlos.
Los puntos de decisión comunes incluyen:
- Clasificar la intención y enrutar al flujo correcto
- Decidir si hacer una pregunta aclaratoria o seguir adelante
- Seleccionar herramientas (búsqueda, consulta CRM, redacción, creación de ticket)
- Decidir cuándo escalar a un humano
Si no puedes nombrar las decisiones, no estás listo para desplegar lógica dirigida por modelos.
Escribe criterios de aceptación para el comportamiento
Trata el comportamiento del modelo como cualquier otro requisito de producto. Define qué significa “bueno” y “malo” en lenguaje claro.
Por ejemplo:
- Bueno: usa la política más reciente, cita el ID de pedido correcto, hace una única pregunta clara si falta información
- Malo: inventa descuentos, hace referencia a localidades no soportadas, o responde sin verificar datos requeridos
Estos criterios se convierten en la base para tu conjunto de evaluación más adelante.
Identifica restricciones desde el principio
Enumera las restricciones que afectan tus decisiones de diseño:
- Tiempo (objetivos de latencia de respuesta)
- Presupuesto (coste por tarea)
- Cumplimiento (manejo de PII, requisitos de auditoría)
- Locales soportados (idiomas, tono, expectativas culturales)
Define métricas de éxito que puedas monitorizar
Elige un pequeño conjunto de métricas ligado al trabajo:
- Tasa de finalización de tareas
- Precisión (o adherencia a políticas) en casos representativos
- CSAT o valoración cualitativa del usuario
- Tiempo ahorrado por tarea (o tiempo hasta resolución)
Si no puedes medir el éxito, acabarás discutiendo percepciones en lugar de mejorar el producto.
Diseña el flujo impulsado por IA y los límites del sistema
Un flujo AI-first no es “una pantalla que llama a un LLM”. Es un recorrido de extremo a extremo donde el modelo toma ciertas decisiones, el producto las ejecuta de forma segura y el usuario se mantiene orientado.
Mapea el bucle de extremo a extremo
Comienza dibujando la canalización como una cadena simple: entradas → modelo → acciones → salidas.
- Entradas: lo que provee el usuario (texto, archivos, selecciones) más el contexto de la app (nivel de cuenta, espacio de trabajo, actividad reciente).
- Paso del modelo: qué es responsable de decidir el modelo (clasificar, redactar, resumir, elegir la siguiente acción).
- Acciones: lo que puede hacer tu sistema (buscar, crear una tarea, actualizar un registro, enviar un correo).
- Salidas: lo que ve el usuario (un borrador, una explicación, una pantalla de confirmación, un error con próximos pasos).
Este mapa obliga a aclarar dónde la incertidumbre es aceptable (redacción) frente a dónde no lo es (cambios de facturación).
Dibuja los límites del sistema: modelo vs código determinista
Separa los caminos deterministas (chequeos de permisos, reglas de negocio, cálculos, escrituras en base de datos) de las decisiones dirigidas por modelo (interpretación, priorización, generación en lenguaje natural).
Una regla útil: el modelo puede recomendar, pero el código debe verificar antes de que ocurra cualquier acción irreversible.
Decide dónde corre el modelo
Elige un runtime según las restricciones:
- Servidor: mejor para datos privados, herramientas consistentes y registros de auditoría.
- Cliente: útil para asistencias ligeras y privacidad por procesamiento local, pero más difícil de controlar.
- Edge: latencia global más rápida, pero dependencias limitadas.
- Híbrido: detección rápida de intención en el edge y trabajo pesado en servidor.
Presupuesta latencia, coste y permisos de datos
Establece un presupuesto por petición de latencia y coste (incluyendo reintentos y llamadas a herramientas), y diseña la UX en torno a ello (streaming, resultados progresivos, “continuar en segundo plano”).
Documenta fuentes de datos y permisos necesarios en cada paso: qué puede leer el modelo, qué puede escribir y qué requiere confirmación explícita del usuario. Esto se convierte en un contrato para ingeniería y confianza.
Patrones de arquitectura: orquestación, estado y trazas
Cuando un modelo es parte de la lógica de tu app, “arquitectura” no es solo servidores y APIs: es cómo ejecutas de forma confiable una cadena de decisiones del modelo sin perder el control.
Orquestación: el director del trabajo del modelo
La orquestación es la capa que gestiona cómo se ejecuta una tarea de IA de extremo a extremo: prompts y plantillas, llamadas a herramientas, memoria/contexto, reintentos, timeouts y caminos de respaldo.
Los buenos orquestadores tratan al modelo como un componente en una canalización. Deciden qué prompt usar, cuándo llamar a una herramienta (búsqueda, base de datos, correo, pago), cómo comprimir o recuperar contexto y qué hacer si el modelo devuelve algo inválido.
Si quieres avanzar rápido de la idea a la orquestación en funcionamiento, un flujo de trabajo de prototipado puede ayudarte a iterar estas canalizaciones sin reconstruir la infraestructura de la app desde cero. Por ejemplo, Koder.ai permite a los equipos crear apps web (React), backends (Go + PostgreSQL) e incluso apps móviles (Flutter) vía chat —luego iterar en flujos como “entradas → modelo → llamadas a herramientas → validaciones → UI” con funciones como modo de planificación, snapshots y rollback, además de exportación del código fuente cuando estés listo para tener el repositorio.
Máquinas de estado para tareas multi‑paso
Las experiencias multi‑paso (triaje → recopilar info → confirmar → ejecutar → resumir) funcionan mejor cuando las modelas como un flujo de trabajo o máquina de estados.
Un patrón simple es: cada paso tiene (1) entradas permitidas, (2) salidas esperadas y (3) transiciones. Esto evita conversaciones que se desvían y hace explícitos los casos límite —por ejemplo, qué ocurre si el usuario cambia de idea o proporciona información parcial.
Razonamiento en una sola pasada vs. multi‑turno
La ejecución en una sola pasada funciona bien para tareas contenidas: clasificar un mensaje, redactar una respuesta corta, extraer campos de un documento. Es más barato, rápido y fácil de validar.
El razonamiento multi‑turno es mejor cuando el modelo debe hacer preguntas aclaratorias o cuando se necesitan herramientas de forma iterativa (p. ej., plan → buscar → refinar → confirmar). Úsalo intencionadamente y limita los bucles por tiempo o número de pasos.
Idempotencia: evita efectos secundarios repetidos
Los modelos reintentan. Las redes fallan. Los usuarios hacen doble clic. Si un paso de IA puede desencadenar efectos secundarios —enviar un correo, reservar, cobrar— hazlo idempotente.
Tácticas comunes: adjuntar una clave de idempotencia a cada acción de “ejecución”, almacenar el resultado de la acción y asegurar que los reintentos devuelvan el mismo resultado en lugar de repetirlo.
Trazas: haz depurable cada paso
Añade trazabilidad para que puedas responder: ¿Qué vio el modelo? ¿Qué decidió? ¿Qué herramientas se ejecutaron?
Registra una traza estructurada por ejecución: versión del prompt, entradas, IDs de contexto recuperado, solicitudes/respuestas de herramientas, errores de validación, reintentos y la salida final. Esto convierte “la IA hizo algo raro” en una línea temporal auditable y solucionable.
El prompting como lógica de producto: contratos y formatos claros
Cuando el modelo forma parte de tu lógica de aplicación, tus prompts dejan de ser “copy” y se convierten en especificaciones ejecutables. Trátalos como requisitos de producto: alcance explícito, salidas predecibles y control de cambios.
Comienza con un system prompt que defina el contrato
Tu system prompt debe establecer el rol del modelo, qué puede y no puede hacer y las reglas de seguridad que importan para tu producto. Mantenlo estable y reutilizable.
Incluye:
- Rol y objetivo: quién es (p. ej., “asistente de triaje de soporte”) y qué significa el éxito.
- Límites de alcance: qué solicitudes debe rechazar o escalar.
- Reglas de seguridad: manejo de PII, avisos médicos/legales, no especular.
- Política de herramientas: cuándo llamar a herramientas frente a responder directamente.
Estructura los prompts con entradas/salidas claras
Escribe prompts como definiciones de API: lista las entradas exactas que provees (texto del usuario, nivel de cuenta, locale, fragmentos de política) y las salidas exactas que esperas. Añade 1–3 ejemplos que coincidan con el tráfico real, incluyendo casos límite complicados.
Un patrón útil es: Contexto → Tarea → Restricciones → Formato de salida → Ejemplos.
Usa formatos restringidos para resultados legibles por máquina
Si el código necesita actuar sobre la salida, no confíes en prosa. Pide JSON que coincida con un esquema y rechaza cualquier otra cosa.
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
Versiona los prompts y despliega con seguridad
Almacena los prompts en control de versiones, etiqueta releases y despliega como características: despliegue por etapas, A/B cuando corresponda y rollback rápido. Registra la versión del prompt con cada respuesta para depuración.
Construye una suite de pruebas para prompts
Crea un pequeño conjunto representativo de casos (camino feliz, solicitudes ambiguas, violaciones de política, entradas largas, distintos locales). Ejecútalos automáticamente en cada cambio de prompt y falla la compilación cuando las salidas rompan el contrato.
Llamado a herramientas: que el modelo decida, que el código ejecute
Lánzalo con tu marca
Publica tu app centrada en IA en tu propio dominio cuando esté lista para los usuarios.
El llamado a herramientas es la forma más limpia de dividir responsabilidades: el modelo decide qué debe ocurrir y qué capacidad usar, mientras tu código realiza la acción y devuelve resultados verificados.
Esto mantiene hechos, cálculos y efectos secundarios (crear tickets, actualizar registros, enviar correos) en código determinista y auditable —en lugar de confiar en texto libre.
Diseña un conjunto pequeño e intencional de herramientas
Comienza con un puñado de herramientas que cubran el 80% de las solicitudes y sean fáciles de asegurar:
- Búsqueda (tu centro de ayuda/documentación) para responder preguntas de producto
- Consulta DB (primero solo lectura) para estado de usuario/cuenta/pedido
- Calculadora para precios, totales, conversiones y matemáticas basadas en reglas
- Ticketing para abrir solicitudes de soporte cuando el usuario necesita seguimiento humano
Mantén el propósito de cada herramienta estrecho. Una herramienta que hace “de todo” se vuelve difícil de probar y fácil de usar mal.
Valida entradas, sanea salidas
Trata al modelo como un llamador no de confianza.
- Valida entradas de herramienta con esquemas estrictos (tipos, rangos, enums). Rechaza o repara argumentos inseguros (p. ej., IDs faltantes, consultas demasiado amplias).
- Sanea salidas de herramienta antes de devolverlas al modelo: elimina secretos, normaliza formatos y devuelve solo los campos que el modelo necesita.
Esto reduce el riesgo de inyección de prompts vía texto recuperado y limita fugas accidentales de datos.
Añade permisos y límites por herramienta
Cada herramienta debe imponer:
- Comprobaciones de permiso (quién puede acceder a qué registros, qué acciones)
- Límites de tasa (por usuario/sesión/herramienta) para reducir abuso y bucles descontrolados
Si una herramienta puede cambiar estado (ticketing, reembolsos), requiere autorización más fuerte y generar un registro de auditoría.
Siempre soporta una ruta “sin herramienta”
A veces la mejor acción es no hacer nada: responder desde el contexto existente, hacer una pregunta aclaratoria o explicar limitaciones.
Haz de “sin herramienta” un resultado de primera clase para que el modelo no llame a herramientas solo por aparentar actividad.
Datos y RAG: ancla el modelo en tu realidad
Si las respuestas de tu producto deben coincidir con tus políticas, inventario, contratos o conocimiento interno, necesitas una forma de anclar el modelo en tus datos —no solo en su entrenamiento general.
RAG vs. ajuste fino vs. contexto simple
- Contexto simple (pegar unos párrafos en el prompt) funciona cuando el conocimiento es pequeño, estable y puedes enviarlo cada vez (p. ej., una tabla de precios corta).
- RAG (Retrieval-Augmented Generation) es mejor cuando la información es grande, cambia con frecuencia o necesita citas (p. ej., artículos de ayuda, docs de producto, datos por cuenta).
- Ajuste fino es mejor cuando quieres estilo/formato consistentes o patrones específicos del dominio —no como método principal para “almacenar hechos”. Úsalo para mejorar cómo escribe y sigue tus reglas; combínalo con RAG para obtener verdad actualizada.
Fundamentos de ingestión: chunking, metadatos, frescura
La calidad de RAG es, en gran medida, un problema de ingestión.
Divide documentos en fragmentos del tamaño adecuado para tu modelo (a menudo unos pocos cientos de tokens), idealmente alineados a límites naturales (encabezados, entradas de FAQ). Almacena metadatos como: título del documento, sección, producto/versión, audiencia, locale y permisos.
Planifica la frescura: programa reindexados, registra “última actualización” y expira fragmentos antiguos. Un fragmento obsoleto que rankea alto degradará silenciosamente toda la función.
Citas y respuestas calibradas
Haz que el modelo cite fuentes devolviendo: (1) respuesta, (2) lista de IDs/URLs de fragmentos, y (3) una declaración de confianza.
Si la recuperación es escasa, instruye al modelo para que diga lo que no puede confirmar y ofrezca pasos siguientes (“No encontré esa política; aquí tienes a quién contactar”). Evita que rellene los huecos.
Datos privados: control de acceso y redacción
Aplica el control de acceso antes de la recuperación (filtrar por permisos de usuario/organización) y de nuevo antes de la generación (redactar campos sensibles).
Trata embeddings e índices como almacenes de datos sensibles con registros de auditoría.
Cuando falla la recuperación: retrocesos elegantes
Si los mejores resultados son irrelevantes o vacíos, retrocede a: preguntar algo aclaratorio, enrutar a soporte humano o cambiar a un modo sin RAG que explique limitaciones en lugar de adivinar.
Fiabilidad: guardarraíles, validación y caché
Cuando un modelo está dentro de la lógica de tu app, “más o menos bien la mayoría del tiempo” no basta. Fiabilidad significa que los usuarios ven comportamiento consistente, tu sistema puede consumir salidas de forma segura y las fallas degradan la experiencia con gracia.
Define objetivos de fiabilidad (antes de añadir arreglos)
Escribe qué significa “fiable” para la función:
- Salidas consistentes: entradas similares deberían producir respuestas comparables (tono, nivel de detalle, restricciones).
- Formatos estables: la respuesta debe ser parseable siempre (JSON, lista, campos específicos).
- Comportamiento acotado: límites claros sobre lo que debe hacer el modelo (no adivinar, citar fuentes, preguntar cuando esté inseguro).
Estas metas se convierten en criterios de aceptación para prompts y código.
Guardarraíles: valida, filtra y aplica políticas
Trata la salida del modelo como entrada no confiable.
- Validación por esquema: exige un formato estricto (p. ej., JSON con claves requeridas) y rechaza lo que no pueda parsearse.
- Filtros de contenido: ejecuta comprobaciones de blasfemias, detectores de PII o validadores de política tanto sobre la entrada del usuario como sobre la salida del modelo.
- Reglas de negocio: aplica restricciones en código (rangos de precios, reglas de elegibilidad, acciones permitidas), incluso si el prompt las menciona.
Si la validación falla, devuelve un fallback seguro (hacer una pregunta aclaratoria, cambiar a una plantilla más simple o enrutar a un humano).
Reintentos que realmente ayuden
Evita repetir a ciegas. Reintenta con un prompt modificado que aborde el modo de fallo:
- “Devuelve solo JSON válido. Sin markdown.”
- “Si estás inseguro, establece
confidencea bajo y haz una pregunta.”
Limita los reintentos y registra la razón de cada fallo.
Post‑procesado determinista
Usa código para normalizar lo que produce el modelo:
- canonizar unidades, fechas y nombres
- eliminar duplicados
- aplicar reglas de ranking o umbrales
Esto reduce la varianza y hace las salidas más fáciles de probar.
Caché sin crear problemas de privacidad
Cachea resultados repetibles (p. ej., consultas idénticas, embeddings compartidos, respuestas de herramientas) para reducir coste y latencia.
Prefiere:
- TTLs cortos para datos específicos de usuario
- claves de caché que excluyan PII bruto (o hashea cuidadosamente)
- flags de “no cachear” para flujos sensibles
Bien hecho, el caching aumenta la consistencia manteniendo la confianza del usuario.
Seguridad y confianza: reducir riesgo sin matar la UX
Prototipa la lógica de IA rápido
Crea un flujo de trabajo centrado en IA con chat, y luego itera con seguridad usando instantáneas y reversión.
La seguridad no es una capa de cumplimiento que se añade al final. En productos AI-first, el modelo puede influir en acciones, formulación y decisiones —así que la seguridad debe ser parte del contrato de producto: qué puede hacer el asistente, qué debe rechazar y cuándo debe pedir ayuda.
Preocupaciones clave de seguridad para diseñar
Nombra los riesgos que realmente enfrenta tu app y asigna un control a cada uno:
- Datos sensibles: identificadores personales, credenciales, documentos privados y cualquier cosa regulada.
- Orientación dañina: instrucciones que podrían facilitar autolesiones, violencia, actividad ilegal o acciones médicas/financieras inseguras.
- Sesgos y resultados injustos: calidad de servicio inconsistente, recomendaciones o decisiones desiguales entre grupos.
Temas permitidos/bloqueados + vías de escalado
Redacta una política explícita que tu producto pueda aplicar. Manténla concreta: categorías, ejemplos y respuestas esperadas.
Usa tres niveles:
- Permitido: responder normalmente.
- Restringido: responder con limitaciones (p. ej., solo información general, sin instrucciones paso a paso).
- Bloqueado: rechazar y enrutar a una vía de escalado (soporte, recursos o un agente humano).
El escalado debe ser un flujo de producto, no solo un mensaje de rechazo. Ofrece una opción “Hablar con una persona” y asegura que la transferencia incluya el contexto ya compartido por el usuario (con consentimiento).
Revisión humana para acciones de alto impacto
Si el modelo puede desencadenar consecuencias reales —pagos, reembolsos, cambios de cuenta, cancelaciones, eliminación de datos— añade un punto de control.
Patrones buenos incluyen: pantallas de confirmación, “borrador y luego aprobar”, límites (topes de importe) y una cola de revisión humana para casos límite.
Declaraciones, consentimiento y políticas testeables
Informa a los usuarios cuando interactúan con IA, qué datos se usan y qué se almacena. Pide consentimiento cuando sea necesario, especialmente para guardar conversaciones o usar datos para mejorar el sistema.
Trata las políticas internas de seguridad como código: versionálas, documenta la razón y añade pruebas (prompts de ejemplo + resultados esperados) para que la seguridad no retroceda con cada cambio de prompt o modelo.
Evaluación: prueba el modelo como cualquier otro componente crítico
Si un LLM puede cambiar lo que hace tu producto, necesitas una forma repetible de demostrar que sigue funcionando —antes de que los usuarios detecten regresiones por ti.
Trata prompts, versiones de modelo, esquemas de herramientas y ajustes de recuperación como artefactos de release que requieren pruebas.
Construye un conjunto de evaluación desde la realidad
Recoge intenciones reales de usuarios de tickets de soporte, consultas de búsqueda, logs de chat (con consentimiento) y llamadas de ventas. Conviértelas en casos de prueba que incluyan:
- Solicitudes comunes en el camino feliz
- Prompts ambiguos que requieren preguntas aclaratorias
- Casos límite (datos faltantes, restricciones en conflicto, formatos inusuales)
- Escenarios sensibles a políticas (datos personales, contenido no permitido)
Cada caso debe incluir comportamiento esperado: la respuesta, la decisión tomada (p. ej., “llamar a la herramienta A”) y cualquier estructura requerida (campos JSON presentes, citas incluidas, etc.).
Elige métricas que casen con el riesgo del producto
Un solo indicador no captura la calidad. Usa un pequeño conjunto de métricas que se mapeen a resultados de usuario:
- Precisión / éxito de la tarea: ¿resolvió el objetivo del usuario?
- Groundedness: ¿las afirmaciones están respaldadas por contexto o fuentes proporcionadas?
- Validez de formato: ¿la salida cumple el contrato (JSON, tabla, bullets)?
- Tasa de rechazo: ¿rechaza cuando debe y evita rechazar cuando no debe?
Rastrea coste y latencia junto a calidad; un “mejor” modelo que duplica el tiempo de respuesta puede perjudicar la conversión.
Ejecuta evaluaciones offline para cada cambio
Ejecuta evaluaciones offline antes del lanzamiento y tras cada cambio de prompt, modelo, herramienta o configuración de recuperación. Mantén los resultados versionados para comparar ejecuciones y localizar rápidamente qué rompió.
Añade tests online con guardarraíles
Usa tests A/B online para medir resultados reales (tasa de finalización, ediciones, valoraciones de usuarios), pero añade protecciones: define condiciones de parada (p. ej., picos en salidas inválidas, rechazos o errores en herramientas) y revierte automáticamente cuando se excedan umbrales.
Monitorización en producción: deriva, fallos y feedback
Escala más allá del prototipo
Pasa de prototipar en solitario a un espacio de trabajo compartido a medida que tu funcionalidad de IA crece.
Lanzar una función AI-first no es la meta final. Con usuarios reales, el modelo enfrentará nuevas frases, casos límite y datos cambiantes. La monitorización convierte “funcionó en staging” en “sigue funcionando el próximo mes”.
Registra lo que importa (sin recopilar secretos)
Captura suficiente contexto para reproducir fallos: intención del usuario, versión del prompt, llamadas a herramientas y la salida final del modelo.
Registra entradas/salidas con redacción segura para la privacidad. Trata los logs como datos sensibles: elimina emails, teléfonos, tokens y texto libre que pueda contener datos personales. Mantén un “modo debug” que puedas activar temporalmente para sesiones específicas en lugar de registrar en exceso por defecto.
Vigila las señales correctas
Monitoriza tasas de error, fallos de herramientas, violaciones de esquema y deriva. Concretamente, haz seguimiento de:
- Tasa de éxito y timeouts de llamadas a herramientas (¿eligió bien el modelo y se ejecutó?)
- Cumplimiento de formato/esquema de la salida (¿lo rechazaron los validadores?)
- Uso de fallback (¿con qué frecuencia tuviste que enrutar a un camino más simple o seguro?)
- Bloqueos por seguridad (¿con qué frecuencia rechazaste o saneaste?)
Para detectar deriva, compara el tráfico actual con tu línea base: cambios en mezcla de temas, idioma, longitud promedio de prompts e intenciones “desconocidas”. La deriva no siempre es mala, pero siempre es una señal para re‑evaluar.
Alertas, runbooks y respuesta a incidentes
Configura umbrales de alerta y runbooks on‑call. Las alertas deben mapear a acciones: revertir una versión de prompt, desactivar una herramienta inestable, endurecer validaciones o cambiar a fallback.
Planifica la respuesta a incidentes para comportamientos inseguros o incorrectos. Define quién puede accionar interruptores de seguridad, cómo notificar a los usuarios y cómo documentar y aprender del suceso.
Cierra el bucle con feedback de usuarios
Usa bucles de retroalimentación: pulgares arriba/abajo, códigos de motivo, informes de errores. Pide opciones ligeras de “por qué” (datos incorrectos, no siguió instrucciones, inseguro, demasiado lento) para enrutar problemas al arreglo correcto —prompt, herramientas, datos o política.
UX para lógica dirigida por modelos: transparencia y control
Las funciones dirigidas por modelos parecen mágicas cuando funcionan —y frágiles cuando no. La UX debe asumir la incertidumbre y aun así ayudar a los usuarios a completar la tarea.
Muestra el “porqué” sin abrumar
Los usuarios confían más en salidas de IA cuando pueden ver de dónde vienen —no porque quieran una lección, sino porque les ayuda a decidir si actuar.
Usa revelación progresiva:
- Empieza con el resultado (respuesta, borrador, recomendación).
- Ofrece un toggle “¿Por qué?” o “Mostrar trabajo” que revele las entradas clave: la solicitud del usuario, las herramientas usadas y las fuentes o registros consultados.
- Si usas recuperación, muestra citas que vayan al fragmento exacto (por ejemplo, “Basado en: Política §3.2”). Manténlo fácil de hojear.
Si tienes un explicador más profundo, enlaza internamente (p. ej., /blog/rag-grounding) en lugar de cargar la UI con detalles.
Diseña para la incertidumbre (sin advertencias alarmantes)
Un modelo no es una calculadora. La interfaz debe comunicar confianza e invitar a la verificación.
Patrones prácticos:
- Indicadores de confianza en lenguaje plano (“Probablemente correcto”, “Necesita revisión”) en vez de precisión falsa.
- Opciones, no respuestas únicas: “Aquí tienes 3 formas de responder.” Esto reduce el coste de un primer intento erróneo.
- Confirmaciones para acciones de alto impacto (enviar correos, borrar datos, reservar pagos). Haz una única pregunta clara: “¿Enviar este mensaje a 12 destinatarios?”
Facilita la corrección y recuperación
Los usuarios deberían poder dirigir la salida sin empezar de nuevo:
- Edición en línea con “Aplicar cambios” para que el modelo continúe desde las correcciones del usuario.
- “Regenerar” con controles (tono, longitud, restricciones) en vez de una remezcla ciega.
- “Deshacer” e historial visible para que los errores sean reversibles.
Ofrece una salida
Cuando el modelo falla —o el usuario no está seguro— ofrece un flujo determinista o ayuda humana.
Ejemplos: “Cambiar a formulario manual”, “Usar plantilla” o “Contactar soporte” (p. ej., /support). Esto no es un fallback vergonzoso; es cómo proteges la finalización de la tarea y la confianza.
Del prototipo a producción (sin reconstruirlo todo)
La mayoría de los equipos no fracasan porque los LLMs sean incapaces; fracasan porque el camino del prototipo a una función fiable, testeable y observable es más largo de lo esperado.
Una forma práctica de acortar ese camino es estandarizar temprano el “esqueleto de producto”: máquinas de estado, esquemas de herramientas, validación, trazas y una historia de despliegue/rollback. Plataformas como Koder.ai pueden ser útiles cuando quieres levantar un flujo AI-first rápidamente —construyendo UI, backend y base de datos juntos— y luego iterar con snapshots/rollback, dominios personalizados y hosting. Cuando estés listo para operacionalizar, puedes exportar el código fuente y continuar con tu CI/CD y stack de observabilidad preferido.