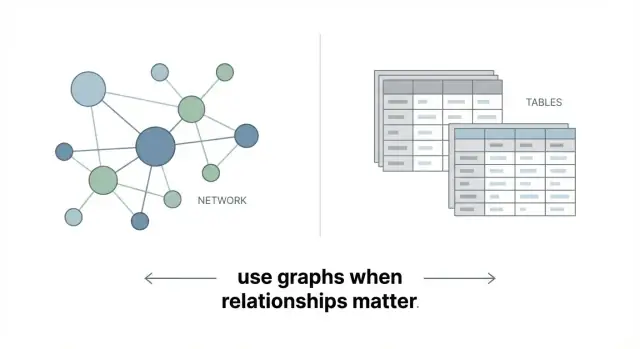
Qué es una base de datos de grafos (sin bombo)
Una base de datos de grafos almacena datos como una red en vez de un conjunto de tablas. La idea central es sencilla:
- Nodos son las “cosas” que te importan (un cliente, producto, cuenta, dispositivo, ubicación).
- Relaciones conectan nodos (cliente COMPRÓ producto, cuenta TRANSFERIÓ_A cuenta, usuario SIGUE a usuario).
- Propiedades son los detalles que adjuntas a nodos y relaciones (nombre, precio, marca temporal, cantidad, estado).
Eso es todo: una base de datos de grafos está pensada para representar datos conectados de forma directa.
Las relaciones son “de primera clase”
En una base de datos de grafos, las relaciones no son una ocurrencia tardía: se almacenan como objetos reales y consultables. Una relación puede tener sus propias propiedades (por ejemplo, una relación COMPRÓ puede guardar fecha, canal y descuento), y puedes recorrer de un nodo al siguiente de forma eficiente.
Esto importa porque muchas preguntas de negocio tratan naturalmente sobre caminos y conexiones: “¿Quién está conectado con quién?”, “¿A cuántos pasos está esta entidad?” o “¿Cuáles son los enlaces comunes entre estas dos cosas?”.
Cómo difiere de tablas y JOINs
Las bases de datos relacionales son excelentes para registros estructurados: clientes, pedidos, facturas. Allí también existen relaciones, pero suelen representarse de forma indirecta mediante claves foráneas, y conectar varios saltos suele implicar escribir JOINs entre varias tablas.
Los grafos mantienen las conexiones junto a los datos, por lo que explorar relaciones de varios pasos suele ser más sencillo de modelar y consultar.
Poniendo expectativas
Las bases de datos de grafos son excelentes cuando las relaciones son lo principal: recomendaciones, anillos de fraude, mapeo de dependencias, grafos de conocimiento. No son automáticamente mejores para informes simples, totales o cargas muy tabulares. La idea no es reemplazar todas las bases de datos, sino usar grafos donde la conectividad genera valor.
Por qué las relaciones cambian el juego
La mayoría de las preguntas de negocio no tratan solo de registros individuales: tratan de cómo se conectan las cosas.
Un cliente no es solo una fila; está vinculado a pedidos, dispositivos, direcciones, tickets de soporte, referidos y, a veces, a otros clientes. Una transacción no es solo un evento; está conectada a un comerciante, a un método de pago, una ubicación, una ventana temporal y a una cadena de actividad relacionada. Cuando la pregunta es “¿quién/qué está conectado a qué, y cómo?”, los datos de relación se convierten en el personaje principal.
Recorridos: seguir conexiones paso a paso
Las bases de datos de grafos están diseñadas para recorridos: empiezas en un nodo y “caminas” por la red siguiendo aristas.
En vez de hacer JOINs repetidos, expresas la ruta que te interesa: Cliente → Dispositivo → Inicio de sesión → Dirección IP → Otros clientes. Ese enfoque paso a paso coincide con cómo la gente investiga fraude, rastrea dependencias o explica recomendaciones.
Por qué las consultas multi-hop se simplifican
La diferencia real aparece cuando necesitas múltiples saltos (dos, tres, cinco pasos) y no sabes de antemano dónde surgirán las conexiones relevantes.
En un modelo relacional, las preguntas multi-hop a menudo se convierten en largas cadenas de JOINs más lógica extra para evitar duplicados y controlar la longitud del camino. En un grafo, “encuéntrame todos los caminos hasta N saltos” es un patrón normal y legible—especialmente en el modelo de grafo de propiedades que usan muchas bases de datos de grafos.
Las propiedades de las relaciones añaden significado
Las aristas no son solo líneas; pueden transportar datos:
- Tipo: purchased, referred, works_with
- Tiempo: cuándo empezó, terminó o cuándo ocurrió por última vez
- Peso: frecuencia, puntuación de confianza, cantidad, nivel de riesgo
Esas propiedades te permiten hacer mejores preguntas: “conectado en los últimos 30 días”, “vínculos más fuertes” o “caminos que incluyen transacciones de alto riesgo”—sin forzar todo en tablas de búsqueda separadas.
Casos de uso ideales para bases de datos de grafos
Los grafos brillan cuando tus preguntas dependen de la conectividad: “¿quién está vinculado con quién, por qué camino y a cuántos pasos?”. Si el valor de tus datos reside en las relaciones (no solo en filas de atributos), un modelo de grafo puede hacer que el modelado y las consultas sean más naturales.
Redes sociales y profesionales
Todo lo que tiene forma de red—amigos, seguidores, compañeros, equipos, referidos—se mapea limpiamente a nodos y relaciones. Preguntas típicas: “conexiones mutuas”, “camino más corto hacia una persona” o “¿quién conecta estos dos grupos?”. Esas consultas suelen volverse torpes (o lentas) cuando se fuerzan en muchas tablas de JOIN.
Recomendaciones (y descubrimiento)
Los motores de recomendación suelen depender de conexiones multi-step: usuario → ítem → categoría → ítems similares → otros usuarios. Los grafos son adecuados para “personas que les gustó X también les gustó Y”, “ítems vistos en conjunto” y “encuéntrame productos conectados por atributos o comportamiento compartido”. Esto es especialmente útil cuando las señales son diversas y vas añadiendo nuevos tipos de relación.
Fraude e investigación de riesgo
Los grafos de fraude funcionan bien porque el comportamiento sospechoso rara vez es aislado. Cuentas, dispositivos, transacciones, teléfonos, emails y direcciones forman telas de identificadores compartidos. Un grafo facilita detectar anillos, patrones repetidos y enlaces indirectos (por ejemplo, dos cuentas “no relacionadas” que usan el mismo dispositivo a través de una cadena de actividad).
Mapeo de dependencias de red y TI
Para servicios, hosts, APIs, llamadas y propiedad, la pregunta principal es dependencia: “¿qué se rompe si esto cambia?”. Los grafos soportan análisis de impacto, exploración de causa raíz y consultas de “radio de explosión” cuando los sistemas están interconectados.
Grafos de conocimiento
Los grafos de conocimiento conectan entidades (personas, empresas, productos, documentos) con hechos y referencias. Esto ayuda en búsqueda, resolución de entidades y trazar el “por qué” de un hecho (proveniencia) a través de múltiples fuentes enlazadas.
Preguntas comunes que puedes responder fácilmente con grafos
Los grafos brillan cuando la pregunta trata realmente sobre conexiones: quién está unido a quién, por qué cadena, y qué patrones se repiten. En vez de volver a hacer JOINs una y otra vez, formulas la pregunta de relación directamente y conservas la consulta legible a medida que la red crece.
1) Búsqueda de rutas: “¿Cómo están A y B conectados?”
Preguntas típicas:
- “¿Cuál es el camino más corto de este cliente a ese comerciante?”
- “¿Qué colegas conectan a Alice y Bob, y en cuántos pasos?”
- “Muéstrame todas las rutas desde este dispositivo hasta esa cuenta en 3 saltos.”
Esto es útil para soporte al cliente (“¿por qué sugerimos esto?”), cumplimiento (“muestra la cadena de propiedad”) e investigaciones (“¿cómo se propagó esto?”).
2) Detección de comunidades: grupos y clústeres dentro de una red
Los grafos ayudan a detectar agrupaciones naturales:
- “¿Qué clientes forman un clúster por direcciones, teléfonos y dispositivos compartidos?”
- “¿Dónde están las comunidades fuertes en nuestra red de proveedores?”
Puedes usar esto para segmentar usuarios, encontrar bandas de fraude o entender cómo se compran productos juntos. La clave es que el “grupo” se define por cómo se conectan las cosas, no por una única columna.
3) Centralidad e influencia: encontrar nodos importantes
A veces la pregunta no es solo “quién está conectado”, sino “quién importa más” en la red:
- “¿Qué cuenta aparece en más caminos entre otras?”
- “¿Qué producto es el puente más fuerte entre dos segmentos de clientes?”
Esos nodos centrales suelen señalar influenciadores, infraestructura crítica o cuellos de botella que vale la pena vigilar.
4) Coincidencia de patrones: “encuentra triángulos” y “anillos sospechosos”
Los grafos son muy buenos buscando formas repetibles:
- Triángulos: “A conoce a B, B conoce a C y C conoce a A.”
- Anillos: “Cuentas que transfieren fondos en un bucle.”
En Cypher (un lenguaje de consulta común), un patrón de triángulo puede verse así:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
Aunque nunca escribas Cypher personalmente, esto ilustra por qué los grafos son accesibles: la consulta refleja la imagen en tu cabeza.
Grafo vs Relacional: la diferencia real
Las bases de datos relacionales son geniales para lo que fueron diseñadas: transacciones y registros bien estructurados. Si tus datos encajan en tablas (clientes, pedidos, facturas) y los recuperas mayormente por IDs, filtros y agregados, los sistemas relacionales suelen ser la opción más simple y segura.
El problema de los JOINs no es “los JOINs son malos”, sino los JOINs profundos
Los JOINs están bien cuando son ocasionales y poco profundos. La fricción aparece cuando tus preguntas más importantes requieren muchos JOINs, todo el tiempo, entre múltiples tablas.
Ejemplos:
- “¿Qué clientes compraron a vendedores conectados a este proveedor a través de dos intermediarios?”
- “Encuentra todos los dispositivos que compartieron red con dispositivos usados por los contactos cercanos de esta cuenta.”
En SQL, esto puede convertirse en consultas largas con auto-JOINs repetidos y lógica compleja. También se vuelven más difíciles de afinar a medida que crece la profundidad de las relaciones.
Los grafos hacen las “caminatas” multi-step una operación de primera clase
Las bases de datos de grafos almacenan relaciones explícitamente, por lo que los recorridos multi-step son una operación natural. En lugar de coser tablas en tiempo de consulta, recorres nodos y aristas conectadas.
Eso suele significar:
- Consultas más cortas para patrones multi-hop (la consulta se lee más como la pregunta)
- Complejidad más predecible al explorar profundidades variables (p. ej., de 2 a 6 saltos)
Regla práctica
Si tu equipo pregunta con frecuencia preguntas multi-hop—“conectado a”, “a través de”, “en la misma red que”, “dentro de N pasos”—vale la pena considerar un grafo.
Si tu carga principal son transacciones de alto volumen, esquemas estrictos, reportes y JOINs directos, SQL suele ser la opción por defecto. Muchos sistemas reales usan ambos; ver /blog/practical-architecture-graph-alongside-other-databases.
Cuando una base de datos de grafos es la herramienta equivocada
Reduce el coste de desarrollo
Obtén créditos compartiendo lo que construiste con Koder.ai o refiriendo compañeros para que lo prueben.
Los grafos brillan cuando las relaciones son el “plato principal”. Si el valor de tu aplicación no depende de recorrer conexiones (quién-conoce-a-quién, cómo se relacionan los ítems, caminos, vecindarios), un grafo puede añadir complejidad sin mucho beneficio.
CRUD simple con búsquedas de registro único
Si la mayoría de las peticiones son “obtener usuario por ID”, “actualizar perfil”, “crear pedido”, y los datos que necesitas caben en un registro (o un conjunto pequeño y predecible de tablas), un grafo suele ser innecesario. Perderás tiempo modelando nodos y aristas, afinando recorridos y aprendiendo un nuevo estilo de consulta—mientras una base relacional resuelve ese patrón de forma eficiente y con herramientas conocidas.
Dashboards basados en totales, promedios y métricas agrupadas (ingresos por mes, pedidos por región, tasa de conversión por canal) encajan mejor con SQL y análisis columnar que con consultas de grafo. Los motores de grafos pueden responder algunos agregados, pero rara vez son la forma más fácil o rápida para cargas OLAP pesadas.
Necesidades transaccionales fuertes y características “nativas de SQL”
Si dependes de funcionalidades SQL maduras—JOINs complejos con restricciones estrictas, estrategias avanzadas de índices, procedimientos almacenados o patrones ACID bien establecidos—los sistemas relacionales suelen ser la opción natural. Muchas bases de datos de grafos soportan transacciones, pero el ecosistema y los patrones operativos pueden no coincidir con lo que tu equipo ya usa.
Registros mayormente independientes con pocos enlaces significativos
Si tus datos son en gran medida un conjunto de entidades independientes (tickets, facturas, lecturas de sensores) con escaso enlazado, un modelo de grafo puede sentirse forzado. En esos casos, céntrate en un esquema relacional limpio (o en un modelo de documentos) y considera grafos más adelante si las consultas centradas en relaciones se vuelven críticas.
Una buena regla: si puedes describir tus consultas principales sin palabras como “conectado”, “camino”, “vecindario” o “recomendar”, un grafo puede no ser la primera elección.
Compromisos a conocer antes de elegir grafo
Los grafos brillan cuando necesitas seguir conexiones rápido—pero esa fortaleza tiene un coste. Antes de comprometerte, conviene entender dónde los grafos tienden a ser menos eficientes, más caros o simplemente diferentes de operar a diario.
Coste y huella
Los grafos a menudo almacenan e indexan relaciones de modo que los “saltos” sean rápidos (por ejemplo, de un cliente a sus dispositivos y a sus transacciones). El compromiso es que pueden costar más en memoria y almacenamiento que una configuración relacional comparable, especialmente si añades índices para búsquedas comunes y mantienes los datos de relaciones accesibles.
No todas las consultas se aceleran
Si tu carga parece una hoja de cálculo—escaneos grandes tipo tabla, consultas de reporte sobre millones de filas o agregados pesados—un grafo puede ser más lento o más caro para el mismo resultado. Los grafos están optimizados para recorridos (“¿qué está conectado con qué?”), no para procesar grandes lotes de registros independientes.
Diferencias operativas
La complejidad operativa puede ser un factor real. Backups, escalado y monitorización son distintos a lo que muchos equipos conocen con sistemas relacionales. Algunas plataformas de grafos escalan mejor subiéndose a máquinas más grandes (scale-up), mientras otras soportan scale-out pero requieren planificación cuidadosa sobre consistencia, replicación y patrones de consulta.
Habilidades y herramientas
Tu equipo puede necesitar tiempo para aprender nuevos patrones de modelado y enfoques de consulta (por ejemplo, el modelo de grafo de propiedades y lenguajes como Cypher). La curva es manejable, pero es un coste—especialmente si reemplazas flujos de trabajo de reporting SQL maduros.
Un enfoque práctico es usar grafos donde las relaciones son el producto y mantener sistemas existentes para reporting, agregación y analítica tabular.
Conceptos básicos de modelado: nodos, aristas y esquemas
Crea un MVP de grafo para fraude
Crea un flujo de investigación para caminos, clústeres y anillos con una interfaz que tu equipo pueda usar.
Una forma útil de pensar en modelado de grafos es simple: los nodos son cosas y las aristas son relaciones entre cosas. Personas, cuentas, dispositivos, pedidos, productos, ubicaciones—esos son nodos. “Compró”, “inició sesión desde”, “trabaja con”, “es padre de”—esas son aristas.
Grafos de propiedades vs. RDF
La mayoría de las bases de datos orientadas a producto usan el modelo de grafo de propiedades: tanto nodos como aristas pueden tener propiedades (campos clave–valor). Por ejemplo, una arista PURCHASED podría almacenar date, amount y channel. Esto facilita modelar “relaciones con detalles”.
RDF representa conocimiento como tripletas: sujeto – predicado – objeto. Es bueno para vocabularios interoperables y enlazar datos entre sistemas, pero a menudo desplaza “detalles de relación” hacia nodos/triplas adicionales. En la práctica, notarás que RDF te empuja hacia ontologías estándar y patrones SPARQL, mientras que los grafos de propiedades se sienten más cercanos al modelado de datos de aplicación.
Lenguajes de consulta en términos simples
- Cypher (popular en grafos de propiedades) se lee como un patrón que quieres encontrar: “(Customer)-[PURCHASED]->(Product).”
- Gremlin es más como un recorrido paso a paso: empieza aquí, camina por aristas así, filtra y luego agrega.
- SPARQL es el lenguaje del mundo RDF, que hace coincidir patrones de grafo contra tripletas, a menudo usando vocabularios compartidos.
No necesitas memorizar sintaxis al principio—lo importante es que las consultas de grafo se expresan como caminos y patrones, no como JOINs entre tablas.
Qué significa “esquema” en sistemas de grafos
Los grafos suelen ser flexibles en el esquema, lo que significa que puedes añadir una nueva etiqueta de nodo o propiedad sin una migración pesada. Pero la flexibilidad necesita disciplina: define convenciones de nombres, propiedades requeridas (p. ej., id) y reglas para tipos de relación.
Tipos de relación, dirección y propiedades
Elige tipos de relación que expliquen el significado (“FRIEND_OF” vs “CONNECTED”). Usa dirección para aclarar semántica (p. ej., FOLLOWS del seguidor al creador) y añade propiedades en la arista cuando la relación tenga hechos propios (tiempo, confianza, rol, peso).
Cómo decidir si tu problema está impulsado por relaciones
Un problema es “impulsado por relaciones” cuando lo difícil no es almacenar registros, sino entender cómo se conectan las cosas y cómo esas conexiones cambian el significado según la ruta que tomes.
Empieza por preguntas, no por tablas
Comienza escribiendo tus 5–10 preguntas principales en lenguaje llano—las que los interesados siguen haciendo y que tu sistema actual responde lentamente o de forma inconsistente. Los buenos candidatos a grafo suelen incluir frases como “conectado a”, “a través de”, “similar a”, “dentro de N pasos” o “quién más”.
Ejemplos:
- “¿Qué clientes están conectados a este anillo de fraude por dispositivos y direcciones compartidas?”
- “¿Qué productos se compran a menudo juntos por personas que también vieron X?”
- “¿Qué proveedores se ven afectados indirectamente si esta fábrica deja de funcionar?”
Traduce la pregunta en entidades e interacciones
Una vez tengas preguntas, mapea los sustantivos y verbos:
- Las entidades clave se convierten en nodos (Customer, Account, Device, Product, Supplier).
- Las interacciones se convierten en relaciones (PAID_WITH, LOGGED_IN_FROM, BOUGHT, SUPPLIES).
Luego decide qué debe ser relación frente a nodo. Una regla práctica: si algo necesita sus propios atributos y vas a conectar múltiples partes a ello, conviértelo en nodo (por ejemplo, un “Order” o un “Login event” puede ser nodo cuando lleva detalle y conecta muchas entidades).
Facilita filtrado y puntuación
Añade propiedades que te permitan acotar resultados y ordenar relevancia sin JOINs adicionales o post-procesado. Propiedades de alto valor: tiempo, cantidad, estado, canal y puntuación de confianza.
Si la mayoría de tus preguntas importantes requieren conexiones multi-step más filtrado por esas propiedades, probablemente estés ante un problema impulsado por relaciones donde los grafos destacan.
Arquitectura práctica: grafos junto a otras bases de datos
La mayoría de los equipos no reemplazan todo con un grafo. Un enfoque práctico es mantener tu “sistema de registro” donde ya funciona bien (a menudo SQL) y usar un grafo como motor especializado para preguntas con muchas relaciones.
Mantén la fuente de la verdad en SQL (o tu datastore principal)
Usa tu base relacional para transacciones, restricciones y entidades canónicas (clientes, pedidos, cuentas). Luego proyecta una vista de relaciones en un grafo—solo los nodos y aristas que necesitas para consultas conectadas.
Esto mantiene la auditoría y gobernanza de datos claras y al mismo tiempo desbloquea consultas de recorrido rápidas.
Construye el grafo para una característica, no para toda la compañía
Un grafo brilla cuando lo enlazas a una característica claramente acotada, como:
- Recomendaciones (“personas que compraron X también compraron Y”)
- Puntuación de riesgo (anillos de fraude, dispositivos compartidos, instrumentos de pago comunes)
- Resolución de identidad (vincular perfiles entre sistemas)
Empieza con una característica, un equipo y un resultado medible. Puedes ampliar más tarde si demuestra valor.
Si tu cuello de botella es lanzar el prototipo (no debatir el modelo), una plataforma de “vibe-coding” como Koder.ai puede ayudarte a montar una app simple potenciada por grafos rápidamente: describes la funcionalidad en chat, generas una UI en React y un backend en Go/PostgreSQL, e iteras mientras tu equipo de datos valida el esquema y las consultas de grafo.
Estrategias de sincronización: lote vs casi tiempo real
¿Qué frescura necesita el grafo?
- Actualizaciones por lote (cada hora/noche) son más simples y a menudo suficientes para analítica, descubrimiento y muchas recomendaciones.
- Flujos casi en tiempo real (minutos/segundos) encajan con detección de fraude y decisiones operativas.
Un patrón común: escribir transacciones en SQL → publicar eventos de cambio → actualizar el grafo.
Identificadores consistentes y propiedad clara
Los grafos se vuelven un lío cuando los IDs divergen.
Define identificadores estables (p. ej., customer_id, account_id) que coincidan entre sistemas y documenta quién “posee” cada campo y relación. Si dos sistemas pueden crear la misma arista (por ejemplo, “knows”), decide cuál prevalece.
Si planeas un piloto, consulta /blog/getting-started-a-low-risk-pilot-plan para un enfoque de despliegue por etapas.
Empezar: un plan piloto de bajo riesgo
Lanza el piloto
Aloja tu piloto para que los interesados puedan probar recorridos reales y dar feedback rápidamente.
Un piloto de grafo debe sentirse como un experimento, no como una reescritura. La meta es probar (o refutar) que las consultas centradas en relaciones se vuelven más simples y rápidas—sin apostar toda la arquitectura de datos.
1) Escoge un fragmento pequeño y de alto valor
Empieza con un conjunto limitado de datos que ya cause dolor: demasiados JOINs, SQL frágil o consultas lentas de “quién está conectado con qué”. Limítalo a un flujo (por ejemplo: cliente ↔ cuenta ↔ dispositivo, o usuario ↔ producto ↔ interacción) y define un puñado de consultas que quieras responder de extremo a extremo.
2) Define métricas de éxito antes de construir
Mide algo más que velocidad:
- Complejidad de la consulta: ¿Cuántas líneas, JOINs o tablas intermedias requiere hoy vs. en grafo?
- Latencia: tiempo de respuesta con volúmenes de datos realistas.
- Tiempo de desarrollador: cuánto tarda en construir y cambiar consultas cuando cambian los requisitos.
Si no puedes nombrar los números “antes”, no confiarás en los “después”.
3) Mantén el modelo intencional (evita la expansión descontrolada)
Da ganas modelar todo como nodos y aristas. Resiste. Vigila la “expansión del grafo”: demasiadas etiquetas y relaciones sin una consulta clara que las requiera. Cada nueva etiqueta o relación debe ganar su lugar habilitando una pregunta real.
4) Trata la gobernanza como parte del piloto
Planifica privacidad, control de acceso y retención desde el inicio. Los datos de relación pueden revelar más que registros individuales (por ejemplo, conexiones que implican comportamiento). Define quién puede consultar qué, cómo se auditan los resultados y cómo se borra la información cuando sea necesario.
5) Ejecútalo junto a tu base de datos actual
Usa una sincronización simple (batch o streaming) para alimentar el grafo mientras tu sistema actual sigue siendo la fuente de la verdad. Si el piloto demuestra valor, puedes ampliar el alcance—con cuidado, caso de uso por caso de uso.
Lista de comprobación rápida: usa grafo para relaciones
Si eliges una base de datos, no empieces por la tecnología—empieza por las preguntas. Los grafos destacan cuando tus problemas más difíciles son sobre conexiones y caminos, no solo almacenar registros.
Lista rápida “¿esto es impulsado por relaciones?”
Usa esta lista para comprobar el ajuste antes de invertir:
- Profundidad de relaciones: ¿Necesitas seguir relaciones 2+ saltos con frecuencia (A→B→C→D)?
- Patrones de consulta: ¿Tus preguntas clave tratan sobre patrones (p. ej., “personas que comparten empleadores y teléfonos”) en vez de filtros de una sola tabla?
- Frecuencia de actualización: ¿Las relaciones cambian a menudo y necesitas que esos cambios se reflejen rápidamente?
- Escala: ¿El dataset es lo bastante grande como para que unir muchas tablas sea lento, caro o frágil?
Si respondiste “sí” a la mayoría, un grafo puede encajar bien—especialmente cuando necesitas coincidencia de patrones multi-hop como:
- “Encuentra el camino más corto entre dos entidades.”
- “Muestra todas las cuentas conectadas a este dispositivo dentro de 3 pasos.”
- “Recomienda ítems basado en vecinos compartidos, no solo en categorías.”
Cuando deberías quedarte con SQL/NoSQL
Si tu trabajo es mayormente búsquedas simples (por ID/email) o agregaciones (“ventas totales por mes”), una base relacional o un almacén key-value/document es generalmente más simple y barato de operar.
Cómo reducir el riesgo de la decisión
Escribe tus 10 preguntas de negocio principales en oraciones simples, luego pruébalas con datos reales en un piloto pequeño. Mide las consultas, anota lo difícil de expresar y lleva un registro corto de los cambios de modelo que tuviste que hacer. Si el piloto se convierte mayormente en “más JOINs” o “más caching”, eso es señal de que un grafo podría ayudar. Si son mayormente conteos y filtros, probablemente no.