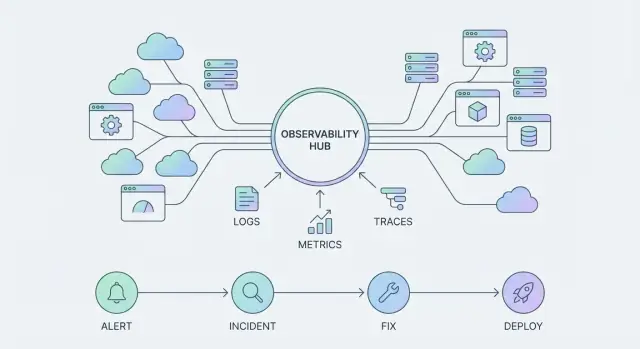
Una herramienta de observabilidad te ayuda a responder preguntas específicas sobre un sistema—normalmente mostrando gráficos, logs o el resultado de una consulta. Es algo que "usas" cuando hay un problema.
Una plataforma de observabilidad es más amplia: estandariza cómo se recoge la telemetría, cómo los equipos la exploran y cómo se manejan los incidentes de extremo a extremo. Se convierte en algo que tu organización "ejecuta" cada día, a través de muchos servicios y equipos.
De gráficos a resultados
La mayoría de los equipos empiezan con dashboards: gráficos de CPU, tasas de error, quizá algunas búsquedas de logs. Eso es útil, pero el objetivo real no es tener gráficos más bonitos—es detectar más rápido y resolver más rápido.
Un cambio a plataforma ocurre cuando dejas de preguntar “¿Podemos graficar esto?” y empiezas a preguntar:
- ¿Puede el ingeniero on-call encontrar la causa raíz en minutos, no en horas?\n- ¿Podemos enrutar la alerta correcta al equipo correcto automáticamente?\n- ¿Podemos convertir patrones repetidos de incidentes en playbooks repetibles?
Esas son preguntas orientadas a resultados, y requieren más que visualización. Requieren estándares de datos compartidos, integraciones consistentes y flujos de trabajo que conecten la telemetría con la acción.
Los tres pilares que realmente compras
A medida que plataformas como la plataforma de observabilidad de Datadog evolucionan, la "superficie de producto" no son solo los dashboards. Son tres pilares entrelazados:
- Telemetría: logs, métricas y trazas que se recogen de forma consistente y etiquetadas lo suficiente como para ser confiables.\n2. Integraciones: conexiones preconstruidas que facilitan la adopción y amplían la cobertura sin pegamento personalizado.\n3. Flujos de trabajo: respuesta a incidentes, enrutamiento de alertas, propiedad y seguimiento—para que el aprendizaje se acumule.
Un dashboard único puede ayudar a un equipo. Una plataforma se fortalece con cada servicio integrado, cada integración añadida y cada flujo estandarizado. Con el tiempo, esto se compone en menos puntos ciegos, menos herramientas duplicadas y incidentes más cortos—porque cada mejora se vuelve reutilizable, no única.
La telemetría se convierte en la superficie del producto
Cuando la observabilidad pasa de “una herramienta que consultamos” a “una plataforma sobre la que construimos”, la telemetría deja de ser un simple escape y empieza a comportarse como la superficie del producto. Lo que eliges emitir—y con qué consistencia lo emites—determina qué pueden ver, automatizar y confiar tus equipos.
Tipos de telemetría principales (y para qué sirven)
La mayoría de los equipos estandarizan alrededor de un pequeño conjunto de señales:
- Métricas: tendencias numéricas a lo largo del tiempo (latencia, tasa de errores, saturación).\n- Logs: registros detallados y legibles por humanos para investigación y auditoría.\n- Trazas: rutas de solicitudes entre servicios para encontrar dónde se consume tiempo y dónde fallan.\n- Eventos: registros discretos de “algo cambió” (despliegues, feature flags, incidentes).\n- Perfiles: comportamiento de CPU/memoria para localizar rutas de código costosas.
Individualmente, cada señal es útil. Juntas, se convierten en una única interfaz hacia tus sistemas—lo que ves en dashboards, alertas, líneas de tiempo de incidentes y postmortems.
Consistencia vence a volumen
Un modo de fallo común es recopilar “todo” pero nombrarlo de forma inconsistente. Si un servicio usa userId, otro usa uid y un tercero no registra nada, no puedes segmentar datos de forma fiable, unir señales ni construir monitores reutilizables.
Los equipos obtienen más valor si acuerdan unas pocas convenciones—nombres de servicio, etiquetas de entorno, IDs de petición y un conjunto estándar de atributos—que si duplican el volumen de ingestión.
Qué significa realmente alta cardinalidad (y por qué importa)
Los campos de alta cardinalidad son atributos con muchos valores posibles (como user_id, order_id o session_id). Son poderosos para depurar problemas que "solo le ocurren a un cliente", pero también pueden aumentar el coste y ralentizar consultas si se usan en todas partes.
El enfoque de plataforma es intencional: mantiene alta cardinalidad donde aporta valor investigativo claro y la evita en lugares pensados para agregados globales.
El contexto unificado reduce el trabajo de correlación
La recompensa es velocidad. Cuando métricas, logs, trazas, eventos y perfiles comparten el mismo contexto (servicio, versión, región, request ID), los ingenieros pasan menos tiempo tejiendo evidencias y más tiempo arreglando el problema real. En lugar de saltar entre herramientas y adivinar, sigues un hilo desde el síntoma hasta la causa raíz.
De la recolección de datos a una estrategia de telemetría
La mayoría de los equipos comienzan la observabilidad "metiendo datos". Eso es necesario, pero no es una estrategia. Una estrategia de telemetría es lo que mantiene la incorporación rápida y hace que tus datos sean lo bastante consistentes para impulsar dashboards compartidos, alertas confiables y SLOs significativos.
Rutas de ingestión comunes (y para qué sirven)
Datadog normalmente recibe telemetría a través de unas rutas prácticas:
- Agentes en hosts/VMs: la forma más rápida de recoger métricas de infraestructura, logs y APM con cambios mínimos en código.\n- Collectors y gateways (por ejemplo, OpenTelemetry Collector): útiles cuando quieres control central, enrutamiento a múltiples destinos, redacción o procesamiento estándar.\n- APIs y SDKs directos: útiles para eventos personalizados, métricas de negocio o cuando un agente no es factible.\n- Integraciones serverless: convenientes para runtimes gestionados donde no controlas el host subyacente, pero necesitarás ser deliberado sobre qué emites.
Velocidad vs. estandarización: decide qué optimizas
Al principio, la velocidad gana: los equipos instalan un agente, activan algunas integraciones y ven valor inmediatamente. El riesgo es que cada equipo invente sus propias etiquetas, nombres de servicio y formatos de logs—lo que hace vistas entre servicios desordenadas y alertas poco fiables.
Una regla simple: permite onboarding rápido, pero exige estandarizar en 30 días. Eso da impulso a los equipos sin consolidar el caos.
Una convención ligera de nombres y etiquetas
No necesitas una taxonomía enorme. Empieza con un pequeño conjunto que cada señal (logs, métricas, trazas) deba llevar:
service: corto, estable, en minúsculas (p. ej., checkout-api)\n- env: prod, staging, dev\n- team: identificador del equipo propietario (p. ej., payments)\n- version: versión del despliegue o SHA de git
Si quieres una más que rinda rápido, añade tier (frontend, backend, data) para simplificar el filtrado.
Muestreo, retención y valores por defecto conscientes de coste
Los problemas de coste suelen venir de valores por defecto demasiado generosos:
- Trazas: empieza con muestreo head-based para endpoints de alto volumen; mantén 100% para flujos críticos.\n- Logs: por defecto registra “errores + eventos importantes de negocio”, y añade info/debug selectivamente con retención temporal.\n- Retención: conserva datos de alta resolución menos tiempo (días), y agrega o conserva agregados clave más tiempo (semanas/meses).
La meta no es recoger menos—es recoger los datos correctos de forma consistente, para que puedas escalar el uso sin sorpresas.
Las integraciones como el verdadero canal de distribución
La mayoría de la gente piensa en las herramientas de observabilidad como “algo que instalas”. En la práctica, se extienden por una organización de la misma forma que se propagan los buenos conectores: una integración a la vez.
Qué significa realmente una “integración”
Una integración no es solo una tubería de datos. Normalmente tiene tres partes:
- Fuentes de datos: extraen métricas, logs, trazas, eventos y topología de sistemas que ya ejecutas (servicios en la nube, Kubernetes, bases de datos, CI/CD, herramientas SaaS).\n- Enriquecimiento: añade contexto para que la telemetría sea inmediatamente usable—nombres de servicio, entornos, etiquetas de propiedad, versiones de despliegue y metadatos de la nube.\n- Acciones: hace algo con lo que aprendes—crear tickets, paginar al on-call, anotar despliegues, escalar recursos o disparar runbooks.
Esa última parte es la que convierte a las integraciones en distribución. Si la herramienta solo lee, es un destino de dashboards. Si también escribe, pasa a formar parte del trabajo diario.
Por qué las integraciones aceleran la adopción
Las buenas integraciones reducen el tiempo de configuración porque vienen con valores por defecto sensatos: dashboards preconstruidos, monitores recomendados, reglas de parsing y etiquetas comunes. En lugar de que cada equipo invente su propio “dashboard de CPU” o “alertas de Postgres”, obtienes un punto de partida estándar que sigue las mejores prácticas.
Los equipos todavía personalizan—pero lo hacen a partir de una base compartida. Esta estandarización importa cuando estás consolidando herramientas: las integraciones crean patrones repetibles que los nuevos servicios pueden copiar, manteniendo el crecimiento manejable.
Prioriza integraciones bidireccionales
Al evaluar opciones, pregunta: ¿puede ingestar señales y ejecutar acciones? Ejemplos incluyen abrir incidentes en tu sistema de tickets, actualizar canales de incidentes o adjuntar un enlace a una traza de vuelta en un PR o vista de despliegue. Las configuraciones bidireccionales son donde los flujos empiezan a sentirse “nativos”.
Un método de lista corta simple
Comienza pequeño y predecible:
- Infra crítica primero (proveedor en la nube, Kubernetes, balanceadores, bases de datos centrales).\n2. Luego la canalización de despliegue (CI/CD, feature flags, seguimiento de releases) para que la telemetría se alinee con los cambios.\n3. Añade SaaS por equipo (colas, caches, auth, pagos) una vez que las convenciones de etiquetado y propiedad estén estables.
Si quieres una regla práctica: prioriza integraciones que mejoren inmediatamente la respuesta a incidentes, no las que solo añaden más gráficos.
Vistas estándar: servicios, dashboards y monitores
Las vistas estándar son donde una plataforma de observabilidad se vuelve utilizable en el día a día. Cuando los equipos comparten el mismo modelo mental—qué es un “servicio”, qué significa “saludable” y dónde hacer clic primero—la depuración es más rápida y las entregas más claras.
Empieza con señales doradas (y hazlas visibles)
Elige un pequeño conjunto de “señales doradas” y asigna cada una a un dashboard concreto y reutilizable. Para la mayoría de servicios, eso es:
- Latencia (p95/p99 para endpoints clave)\n- Tráfico (requests por segundo, jobs procesados)\n- Errores (tasa y tipos de error principales)\n- Saturación (CPU, memoria, profundidad de colas, conexiones DB)
La clave es consistencia: un layout de dashboard que funcione entre servicios supera a diez dashboards personalizados ingeniosos.
Los catálogos de servicio crean propiedad compartida
Un catálogo de servicios (incluso ligero) convierte “alguien debería mirar esto” en “este equipo lo administra”. Cuando los servicios están etiquetados con propietarios, entornos y dependencias, la plataforma puede responder preguntas básicas al instante: ¿Qué monitores aplican a este servicio? ¿Qué dashboards debo abrir? ¿A quién se le hace page?
Esa claridad reduce el ping-pong en Slack durante incidentes y ayuda a los ingenieros nuevos a autoabastecerse.
Los bloques de construcción que escalan
Trátalos como artefactos estándar, no extras opcionales:
- Dashboards para señales doradas y dependencias clave\n- Monitores ligados a SLOs o síntomas que afectan al usuario\n- Notebooks para investigaciones y líneas de tiempo de post-incident\n- Runbooks (enlazados desde monitores) para los primeros 5–10 minutos de respuesta
Anti-patrones a evitar
Dashboards de vanidad (gráficos bonitos sin decisiones detrás), alertas ad-hoc (creadas rápido y nunca ajustadas) y consultas sin documentar (solo una persona entiende el filtro mágico) generan ruido en la plataforma. Si una consulta importa, guárdala, ponle nombre y adjúntala a una vista de servicio que otros puedan encontrar.
Flujos de trabajo: donde la observabilidad entrega valor al negocio
Prototipa el pegamento de la plataforma
Construye un prototipo rápido en React y Go para tu equipo de plataforma en una tarde.
La observabilidad solo se vuelve “real” para el negocio cuando acorta el tiempo entre un problema y una solución confiada. Eso ocurre mediante flujos de trabajo—rutas repetibles que te llevan de señal a acción y de acción a aprendizaje.
El viaje del incidente: alerta → triage → comunicar → mitigar → aprender
Un flujo escalable es más que hacer page a alguien.
Una alerta debería abrir un bucle de triage enfocado: confirmar impacto, identificar el servicio afectado y reunir el contexto más relevante (despliegues recientes, salud de dependencias, picos de errores, señales de saturación). Desde ahí, la comunicación convierte un evento técnico en una respuesta coordinada—quién asume el incidente, qué ven los usuarios y cuándo será la próxima actualización.
La mitigación es donde quieres “movimientos seguros” a mano: feature flags, shifting de tráfico, rollback, limitación de tasa o un workaround conocido. Finalmente, el aprendizaje cierra el ciclo con una revisión ligera que capture qué cambió, qué funcionó y qué debería automatizarse después.
Herramientas de incidentes + ChatOps = colaboración, no heroísmos
Plataformas como la plataforma de observabilidad de Datadog añaden valor cuando respaldan el trabajo compartido: canales de incidentes, actualizaciones de estado, handoffs y líneas de tiempo consistentes. Las integraciones ChatOps pueden convertir alertas en conversaciones estructuradas—creando un incidente, asignando roles y publicando gráficos y consultas clave directamente en el hilo para que todos vean la misma evidencia.
Qué contiene realmente un buen runbook
Un runbook útil es corto, contundente y seguro. Debe incluir: el objetivo (restaurar el servicio), propietarios claros/rotaciones on-call, comprobaciones paso a paso, enlaces a los dashboards/monitores correctos y “acciones seguras” que reduzcan riesgo (con pasos de rollback). Si no es seguro ejecutarlo a las 3 a.m., no está listo.
Vincula incidentes con despliegues y cambios
La causa raíz es más rápida cuando los incidentes se correlacionan automáticamente con despliegues, cambios de configuración y flips de feature flags. Haz que “¿qué cambió?” sea una vista de primera clase para que el triage empiece con evidencia, no con suposiciones.
SLOs y presupuestos de error como sistema operativo de equipo
Qué es un SLO (y por qué supera a los “dashboards verdes”)
Un SLO (Service Level Objective) es una promesa simple sobre la experiencia de usuario en una ventana de tiempo—como “99.9% de las solicitudes exitosas en 30 días” o “p95 de cargas de página bajo 2 segundos”.
Eso supera a un “dashboard verde” porque los dashboards suelen mostrar salud del sistema (CPU, memoria, profundidad de colas) en lugar de impacto al cliente. Un servicio puede parecer verde y aun así fallar a usuarios (por ejemplo, una dependencia hace timeouts o los errores se concentran en una región). Los SLOs obligan al equipo a medir lo que realmente siente el usuario.
Un presupuesto de error es la cantidad permitida de indisponibilidad implícita en tu SLO. Si prometes 99.9% de éxito en 30 días, “te permiten” aproximadamente 43 minutos de errores en esa ventana.
Esto crea un sistema operativo práctico para decisiones:
- Presupuesto sano: lanza features, prueba experimentos, toma riesgos razonables.\n- Presupuesto quemándose: ralentiza releases, enfoca trabajo en confiabilidad, reduce cambios.\n- Presupuesto agotado: pausa despliegues riesgosos y aborda las causas principales de fallos.
En lugar de debatir opiniones en una reunión de release, debates un número que todos pueden ver.
Alertar por burn rate, no por cada pico
El alertado SLO funciona mejor cuando alertas por burn rate (qué tan rápido consumes el presupuesto), no por recuentos de errores en bruto. Eso reduce ruido:
- Un pico breve que se recupera solo puede no generar page.\n- Un problema sostenido que agotaría el presupuesto pronto dispara una alerta clara y accionable.
Muchos equipos usan dos ventanas: un fast burn (pager rápido) y un slow burn (ticket/notificación).
Un conjunto inicial ligero de SLOs para un servicio web típico
Empieza pequeño—dos a cuatro SLOs que realmente vayas a usar:
- Disponibilidad: % de solicitudes exitosas (por ejemplo, HTTP 2xx/3xx) sobre 30 días.\n- Latencia: p95 de latencia de solicitudes bajo un umbral (separar lecturas de escrituras si hace falta).\n- Checkout / endpoint crítico: tasa de éxito para el camino de negocio más importante.\n- Freshness (si aplica): jobs en background completan dentro de X minutos.
Una vez que estos estén estables, puedes expandir—si no, solo construirás otra pared de dashboards. Para más, ver /blog/slo-monitoring-basics.
Alertado que escala sin quemar a la gente
Haz que los incidentes sean más fáciles de seguir
Crea una página de línea de tiempo del incidente que reúna despliegues, enlaces y notas clave en una sola vista.
El alertado es donde muchos programas de observabilidad se estancan: los datos están, los dashboards se ven bien, pero la experiencia on-call se vuelve ruidosa y no confiable. Si la gente aprende a ignorar alertas, tu plataforma pierde su capacidad de proteger el negocio.
Por qué ocurre la fatiga de alertas (y por qué las señales se duplican)
Las causas más comunes son sorprendentemente consistentes:
- Demasiadas alertas “FYI” que no requieren acción.\n- Umbrales copiados entre servicios sin contexto (la misma regla de CPU para cargas muy distintas).\n- Múltiples herramientas o equipos alertando del mismo síntoma—por ejemplo, un monitor APM de tasa de errores y un monitor basado en logs alertando a la vez por el mismo incidente.\n- Métricas ruidosas (percentiles de latencia con picos, efectos de autoscaling) que disparan fluctuaciones en lugar de problemas reales.
En términos de Datadog, las señales duplicadas aparecen cuando los monitores se crean desde diferentes “superficies” (métricas, logs, trazas) sin decidir cuál es la fuente canónica de la página.
Enrutamiento: propiedad, severidad y horas silenciosas
Escalar el alertado empieza con reglas de enrutamiento que tengan sentido para humanos:
- Propiedad: cada monitor debe tener un propietario claro (servicio/equipo) y una ruta de escalado.\n- Severidad: reserva la paginación para problemas urgentes que impactan a usuarios; usa tickets o notificaciones en chat para severidad menor.\n- Ventanas de mantenimiento: despliegues planeados, migraciones y pruebas de carga no deben generar pages.
Reglas simples que mantienen las alertas accionables
Un por defecto útil es: alertar por síntomas, no por cada cambio de métrica. Pager por cosas que sienten los usuarios (tasa de errores, checkouts fallidos, latencia sostenida, burn de SLO), no por “inputs” (CPU, conteo de pods) a menos que predeciblemente indiquen impacto.
Una cadencia de revisión que realmente funciona
Haz la higiene de alertas parte de la operación: podado y afinado mensual de monitores. Elimina monitores que nunca se disparan, ajusta umbrales que saltan demasiado y fusiona duplicados para que cada incidente tenga una página primaria y contexto de soporte.
Hecho bien, el alertado se convierte en un flujo que la gente confía—no en un generador de ruido de fondo.
Llamar observabilidad "plataforma" no es solo tener logs, métricas, trazas y muchas integraciones en un mismo lugar. También implica gobernanza: la consistencia y las barreras que mantienen el sistema usable cuando el número de equipos, servicios, dashboards y alertas se multiplica.
Sin gobernanza, Datadog (o cualquier plataforma de observabilidad) puede derivar en un álbum ruidoso—cientos de dashboards ligeramente diferentes, etiquetas inconsistentes, propiedad poco clara y alertas que nadie confía.
Gobernanza es un problema de personas y procesos
Una buena gobernanza aclara quién decide qué y quién es responsable cuando la plataforma se ensucia:
- Equipo de plataforma: define estándares (etiquetado, naming, patrones de dashboard), provee componentes compartidos y mantiene integraciones.\n- Propietarios de servicio: se encargan de la calidad de telemetría de sus servicios y mantienen monitores significativos.\n- Seguridad y cumplimiento: establece reglas de manejo de datos (PII, retención, límites de acceso) y revisa integraciones de alto riesgo.\n- Liderazgo: alinea la gobernanza con prioridades del negocio (objetivos de confiabilidad, expectativas de respuesta a incidentes) y financia el trabajo.
Controles prácticos que previenen la “expansión” de observabilidad
Unos pocos controles ligeros rinden más que largos documentos de política:
- Plantillas por defecto: dashboards y packs de monitores iniciales por tipo de servicio (API, worker, base de datos) para que los equipos empiecen consistentes.\n- Política de etiquetado: un conjunto pequeño requerido (ej.,
service, env, team, tier) y reglas claras para etiquetas opcionales. Imponlo en CI cuando sea posible.\n- Acceso y propiedad: usa acceso basado en roles para datos sensibles y exige un propietario para dashboards y monitores.\n- Flujos de aprobación para cambios de alto impacto: monitores que generan paginación, pipelines de logs que afectan coste e integraciones que extraen datos sensibles deberían pasar por revisión.
Reutilizar vence reinventar
La forma más rápida de escalar calidad es compartir lo que funciona:
- Librerías compartidas: paquetes internos o snippets que estandarizan campos de logging, atributos de trazas y métricas comunes.\n- Dashboards y monitores reutilizables: un catálogo central de dashboards “dorados” y plantillas de monitores que los equipos pueden clonar y adaptar.\n- Estándares versionados: trata activos clave como código—documenta cambios, depreca patrones antiguos y anuncia actualizaciones en un lugar.
Si quieres que esto cale, haz que el camino gobernado sea el camino fácil—menos clics, configuración más rápida y propiedad clara.
Una vez que la observabilidad se comporta como una plataforma, empieza a seguir economía de plataforma: cuantas más adopciones, más telemetría se produce y más útil se vuelve.
Eso crea una rueda:
- Más servicios incorporados → mejor visibilidad entre servicios y correlación\n- Mejor visibilidad → diagnóstico más rápido, menos incidentes repetidos, más confianza en la herramienta\n- Más confianza → más equipos instrumentan e integran → aún más datos
La pega es que el mismo bucle también incrementa costes. Más hosts, contenedores, logs, trazas, sintéticos y métricas personalizadas pueden crecer más rápido que tu presupuesto si no lo gestionas deliberadamente.
Palancas prácticas de coste (sin matar la señal)
No tienes que “apagarlo todo”. Empieza por moldear los datos:
- Muestreo: conserva trazas de alta fidelidad para endpoints críticos, muestrea más agresivo en otros lugares.\n- Niveles de retención: retención corta para logs crudos de alto volumen; retención más larga para streams curatoriales de seguridad/auditoría.\n- Filtrado y parsing de logs: descarta ruido obvio temprano (health checks, requests a assets estáticos) y estandariza parsing para enrutar por atributos.\n- Agregación de métricas: prefiere percentiles, tasas y rollups sobre cardinalidad ilimitada (p. ej., por ID de usuario).
KPIs que conectan coste con resultados
Sigue un conjunto pequeño de métricas que muestren si la plataforma está devolviendo valor:
- MTTD (mean time to detect)\n- MTTR (mean time to resolve)\n- Cuenta de incidentes y reincidencias (mismo root cause)\n- Frecuencia de despliegue (y tasa de fallos en cambios si la mides)
Ejecutar una revisión trimestral “valor vs coste” (sin culpas)
Hazla como una revisión de producto, no como una auditoría. Reúne a propietarios de plataforma, algunos equipos de servicio y finanzas. Revisa:
- Principales impulsores de coste por tipo de dato (logs/métricas/trazas) y por equipo\n- Principales victorias: incidentes acortados, outages evitadas, toil reducido\n- 2–3 acciones acordadas (p. ej., ajustar reglas de muestreo, añadir niveles de retención, arreglar una integración ruidosa)
El objetivo es propiedad compartida: el coste se convierte en un input para mejores decisiones de instrumentación, no en la razón para dejar de observar.
Qué significa esto para tu stack de herramientas de observabilidad
Crea un catálogo de servicios
Crea una interfaz de catálogo de servicios para que quien esté de guardia siempre sepa qué abrir y quién es el responsable.
Si la observabilidad se convierte en plataforma, tu “stack” deja de ser una colección de soluciones puntuales y pasa a comportarse como infraestructura compartida. Ese cambio hace que la proliferación de herramientas sea más que una molestia: crea instrumentación duplicada, definiciones inconsistentes (¿qué cuenta como error?) y mayor carga on-call porque las señales no se alinean entre logs, métricas, trazas e incidentes.
Consolidar no significa por defecto “un proveedor para todo”. Significa menos sistemas de registro para telemetría y respuesta, propiedad más clara y un conjunto más pequeño de lugares que la gente tiene que mirar durante un outage.
Qué puede resolver realmente la consolidación
La proliferación de herramientas típicamente esconde costes en tres lugares: tiempo perdido saltando entre UIs, integraciones frágiles que hay que mantener y gobernanza fragmentada (naming, etiquetas, retención, acceso).
Un enfoque de plataforma más consolidado puede reducir el cambio de contexto, estandarizar vistas de servicio y hacer que los flujos de incidentes sean repetibles.
Lista de comprobación de decisión (rápida pero práctica)
Al evaluar tu stack (incluyendo Datadog u otras alternativas), presiona con esto:
- Integraciones imprescindibles: proveedor en la nube, Kubernetes, CI/CD, gestión de incidentes, paginación y almacenes de datos clave—más cualquier sistema de negocio sin el que no puedas lanzar.\n- Flujos de trabajo: ¿puedes ir de alerta → propietario → runbook → línea de tiempo → postmortem sin copiar/pegar manualmente?\n- Gobernanza: estándares de etiquetas, controles de acceso, retención y barreras para la expansión de dashboards/monitores.\n- Modelo de precios: ¿qué impulsa el coste (hosts, contenedores, logs ingeridos, trazas indexadas)? ¿Puedes predecir el crecimiento sin sorpresas?
Ejecuta un piloto con una métrica de éxito clara
Elige uno o dos servicios con tráfico real. Define una métrica de éxito única como “tiempo para identificar causa raíz baja de 30 a 10 minutos” o “reducir alertas ruidosas en 40%”. Instrumenta solo lo necesario y revisa resultados tras dos semanas.
Centraliza la documentación interna para que el aprendizaje se acumule—enlaza el runbook del piloto, reglas de etiquetado y dashboards desde un lugar (por ejemplo, /blog/observability-basics como punto de partida interno).
Un plan práctico de adopción que puedes copiar
No “despliegas Datadog” una vez. Empiezas pequeño, estableces estándares temprano y escalas lo que funciona.
Despliegue 30/60/90 días
Días 0–30: Onboard (demostrar valor rápido)
Elige 1–2 servicios críticos y una trayectoria de cliente. Instrumenta logs, métricas y trazas de forma consistente y conecta las integraciones que ya usas (nube, Kubernetes, CI/CD, on-call).
Días 31–60: Estandarizar (hacerlo repetible)
Convierte lo aprendido en valores por defecto: naming de servicio, etiquetado, plantillas de dashboard, nombres de monitores y propiedad. Crea vistas de “señales doradas” (latencia, tráfico, errores, saturación) y un set mínimo de SLOs para los endpoints más importantes.
Días 61–90: Escalar (expandir sin caos)
Incorpora más equipos usando las mismas plantillas. Introduce gobernanza (reglas de tags, metadata requerida, proceso de revisión para nuevos monitores) y empieza a seguir coste vs uso para que la plataforma se mantenga saludable.
Dónde encaja Koder.ai (pragmáticamente)
Una vez que tratas la observabilidad como plataforma, normalmente querrás pequeñas apps “pegamento” alrededor: una UI de catálogo de servicios, un hub de runbooks, una página de línea de tiempo de incidentes o un portal interno que enlace propietarios → dashboards → SLOs → playbooks.
Este es el tipo de tooling interno ligero que puedes construir rápidamente en Koder.ai—una plataforma vibe-coding que permite generar aplicaciones web vía chat (comúnmente React en frontend, Go + PostgreSQL en backend), con exportación de código fuente y soporte de despliegue/hosting. En la práctica, los equipos la usan para prototipar y enviar superficies operativas que facilitan la gobernanza y los flujos sin sacar a un equipo de producto completo de la hoja de ruta.
Victorias rápidas para enviar en la primera semana
- Top 10 monitores para disponibilidad, tasa de errores, latencia, saturación y dependencias clave\n- Marcas de despliegue (desde CI/CD) en dashboards y trazas para correlación instantánea de cambios\n- Plantilla de incidente: qué pasó, impacto, línea de tiempo, propietarios, enlaces a dashboards/consultas, próximas acciones
Realiza dos sesiones de 45 minutos: (1) “Cómo consultamos aquí” con patrones de consulta compartidos (por servicio, env, región, versión), y (2) “Playbook de resolución” con un flujo simple: confirmar impacto → revisar marcas de despliegue → acotar a servicio → inspeccionar trazas → confirmar salud de dependencias → decidir rollback/mitigación.
Checklist para copiar/pegar