03 oct 2025·8 min
Datos fuera vs dentro - Lecciones de Pat Helland para apps
Aprende la idea de Pat Helland sobre datos fuera vs dentro para trazar límites claros, diseñar llamadas idempotentes y reconciliar el estado cuando fallan las redes.
Qué significa “fuera vs dentro” en lenguaje sencillo
Cuando construyes una app, es fácil imaginar que las solicitudes llegan ordenadas, una por una, en el orden correcto. Las redes reales no funcionan así. Un usuario pulsa “Pagar” dos veces porque la pantalla se congeló. Una conexión móvil se corta justo después de pulsar un botón. Un webhook llega tarde, o llega dos veces. A veces nunca llega.
La idea de Pat Helland de datos fuera vs dentro es una forma clara de pensar sobre ese lío.
Cómo se ve lo “fuera”
“Fuera” es todo lo que tu sistema no controla. Es donde hablas con otras personas y sistemas, y donde la entrega es incierta: peticiones HTTP desde navegadores y apps móviles, mensajes de colas, webhooks de terceros (pagos, email, envíos) y reintentos desencadenados por clientes, proxies o jobs en segundo plano.
En lo fuera, asume que los mensajes pueden retrasarse, duplicarse o llegar fuera de orden. Incluso si algo es “usualmente fiable”, diseña para el día en que no lo sea.
Qué significa “dentro”
“Dentro” es lo que tu sistema puede hacer confiable. Es el estado durable que almacenas, las reglas que aplicas y los hechos que puedes probar después:
- Registros de base de datos y su historial
- Reglas de negocio (por ejemplo: “una orden solo puede pagarse una vez”)
- Una fuente de verdad para el estado (pendiente, pagada, cancelada)
Dentro es donde proteges invariantes. Si prometes “un pago por orden”, esa promesa debe hacerse valer dentro, porque lo fuera no se puede confiar en que se comporte.
El cambio de mentalidad es simple: no asumas entrega perfecta ni sincronía perfecta. Trata cada interacción externa como una sugerencia poco fiable que puede repetirse, y haz que lo interno reaccione de forma segura.
Esto importa incluso para equipos pequeños y apps simples. La primera vez que un fallo de red crea un cargo duplicado o una orden atascada, deja de ser teoría y se convierte en reembolso, ticket de soporte y pérdida de confianza.
Un ejemplo concreto: un usuario pulsa “Realizar pedido”, la app envía una petición y la conexión se cae. El usuario lo intenta de nuevo. Si tu parte interna no tiene forma de reconocer “es el mismo intento”, puedes crear dos pedidos, reservar inventario dos veces o enviar dos correos de confirmación.
La lección clave de Pat Helland
El punto de Helland es directo: el mundo exterior es incierto, pero el interior de tu sistema debe permanecer consistente. Las redes pierden paquetes, los teléfonos pierden señal, los relojes derivan y los usuarios refrescan. Tu app no puede controlar nada de eso. Lo que sí puede controlar es qué acepta como “verdad” una vez que los datos cruzan un límite claro.
Tiempo e incertidumbre en un momento cotidiano
Imagina a alguien pidiendo café en el móvil mientras camina por un edificio con Wi‑Fi malo. Pulsa “Pagar”. El spinner gira. La red se corta. Pulsa otra vez.
Quizá la primera petición llegó a tu servidor, pero la respuesta no volvió. O quizá ninguna de las peticiones llegó. Desde la vista del usuario, ambas posibilidades parecen iguales.
Eso es tiempo e incertidumbre: no sabes qué pasó todavía, y puede que lo averigües más tarde. Tu sistema debe comportarse con sensatez mientras espera.
Reintentos, duplicados y reordenamiento
Una vez aceptas que lo fuera es poco fiable, algunos comportamientos “raros” se vuelven normales:
- Los reintentos crean duplicados (dos peticiones de “Pagar”).
- Los mensajes llegan fuera de orden (un “cancelar” llega antes que “pagar”).
- Una petición se procesa, pero el cliente nunca ve la respuesta.
Los datos externos son una afirmación, no un hecho. “Pagué” es solo una declaración enviada por un canal poco fiable. Se convierte en hecho solo después de que lo registres dentro de tu sistema de forma durable y consistente.
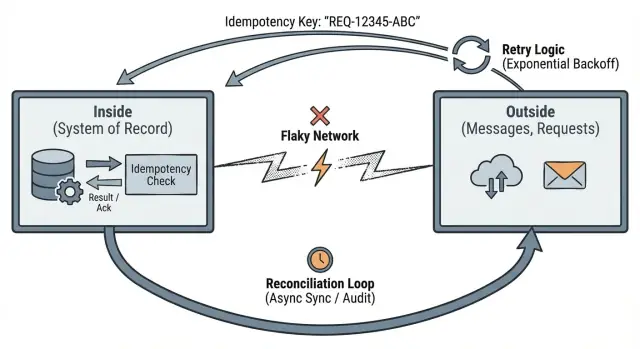
Esto te empuja hacia tres hábitos prácticos: define límites claros, haz que los reintentos sean seguros con idempotencia y planifica la reconciliación cuando la realidad no coincida.
Límites claros: qué posee tu sistema y qué no
La idea de “fuera vs dentro” empieza con una pregunta práctica: ¿dónde comienza y termina la verdad de tu sistema?
Dentro del límite, puedes hacer garantías sólidas porque controlas los datos y las reglas. Fuera del límite, haces intentos de la mejor voluntad y asumes que los mensajes pueden perderse, duplicarse, retrasarse o llegar fuera de orden.
En apps reales, ese límite suele aparecer en lugares como:
- Un endpoint de API que escribe un registro en tu base de datos
- Un consumidor de cola que convierte un evento en un cambio almacenado
- Un handler de callback que registra lo que un proveedor dice que ocurrió
- Un emisor que notifica a otro sistema después de confirmar tu propio estado
Una vez trazas esa línea, decide qué invariantes son innegociables dentro de ella. Ejemplos:
- Un ID de orden es único en tu base de datos.
- Un saldo nunca queda negativo.
- Un estado solo avanza (creado -> pagado -> enviado).
- Cada petición externa que aceptas tiene una bitácora almacenada.
El límite también necesita un lenguaje claro para “dónde estamos”. Muchos fallos viven en la brecha entre “te escuchamos” y “lo terminamos”. Un patrón útil es separar tres significados:
Received: el mensaje llegó a tu borde (no necesariamente guardado aún)Accepted: lo guardaste y puedes reintentar el trabajo de forma segura más tardeProcessed: el trabajo previsto se completó y registraste el resultado
Cuando los equipos saltan esto, acaban con bugs que solo aparecen bajo carga o durante fallos parciales. Un sistema usa “pagado” para significar dinero capturado; otro lo usa para significar intento de pago iniciado. Ese desajuste crea duplicados, órdenes atascadas y tickets de soporte que nadie puede reproducir.
Idempotencia: hacer seguros los reintentos
Idempotencia significa: si la misma petición se envía dos veces, el sistema la trata como una sola y devuelve el mismo resultado.
Los reintentos son normales. Ocurren timeouts. Los clientes se repiten. Si lo fuera puede repetirse, tu dentro tiene que convertir eso en cambios de estado estables.
Un ejemplo sencillo: una app móvil envía “pagar $20” y la conexión se corta. La app reintenta. Sin idempotencia, el cliente podría cobrarse dos veces. Con idempotencia, la segunda petición devuelve el resultado del primer cobro.
Formas comunes de implementar idempotencia
La mayoría de equipos usan uno de estos patrones (a veces una mezcla):
- Clave de idempotencia: el cliente envía una clave única por acción pretendida (por ejemplo,
Idempotency-Key: ...). El servidor registra la clave y la respuesta final. - Tabla de desduplicación: almacena una fila indexada por (client_id, key) o (order_id, operation) y rechaza un segundo efecto lateral.
- Claves naturales: usa un identificador de negocio que ya es único, de modo que “crear pago” solo pueda existir una vez.
Cuando llega un duplicado, el mejor comportamiento normalmente no es un “409 conflict” o un error genérico. Es devolver el mismo resultado que devolviste la primera vez, incluyendo el mismo ID de recurso y estado. Eso es lo que hace que los reintentos sean seguros para clientes y jobs en segundo plano.
Dónde guardar el registro (y por cuánto tiempo)
El registro de idempotencia debe vivir dentro de tu límite en almacenamiento durable, no en memoria. Si tu API se reinicia y lo olvida, la garantía de seguridad desaparece.
Mantén registros el tiempo suficiente para cubrir reintentos realistas y entregas retrasadas. La ventana depende del riesgo del negocio: minutos u horas para creaciones de bajo riesgo, días para pagos/correos/envíos donde los duplicados son costosos, y más tiempo si los socios pueden reintentar durante periodos extendidos.
Cómo evitar las trampas de “transacción distribuida”
Configura jobs de reconciliación
Genera un worker que re-verifique registros pendientes y repare estados desajustados.
Las transacciones distribuidas suenan reconfortantes: un gran commit a través de servicios, colas y bases de datos. En la práctica suelen ser indisponibles, lentas o demasiado frágiles para depender de ellas. Una vez hay un salto de red, no puedes asumir que todo committeará junto.
Una trampa común es construir un flujo de trabajo que solo funciona si cada paso tiene éxito ahora mismo: guardar orden, cobrar tarjeta, reservar inventario, enviar confirmación. Si el paso 3 hace timeout, ¿falló o tuvo éxito? Si reintentas, ¿duplicarás cobros o reservas?
Dos enfoques prácticos evitan esto:
- Outbox/inbox: escribe una intención durable en tu base de datos (una fila outbox) en la misma transacción que tu cambio de estado, luego un worker envía el mensaje. En el lado receptor, guarda un inbox indexado por ID de mensaje para que manejarlo sea seguro si llega el mismo mensaje otra vez.
- Pasos estilo saga con compensaciones: divide el flujo en pasos más pequeños que se completen independientemente. Si un paso posterior falla, ejecuta una compensación (por ejemplo, libera inventario o cancela una orden no pagada) en lugar de intentar revertir el historial.
Elige un estilo por flujo y mantente con él. Mezclar “a veces usamos outbox” con “a veces asumimos éxito sincrónico” crea casos límite difíciles de probar.
Una regla simple ayuda: si no puedes commit en forma atómica a través de límites, diseña para reintentos, duplicados y retrasos.
Reconciliación: cómo los sistemas reales se recuperan de desajustes
La reconciliación admite una verdad básica: cuando tu app habla con otros sistemas por la red, a veces discreparán sobre lo que ocurrió. Las peticiones hacen timeout, los callbacks llegan tarde y la gente reintenta acciones. La reconciliación es cómo detectas desajustes y los arreglas con el tiempo.
Trata a los sistemas externos como fuentes de verdad independientes. Tu app mantiene su propio registro interno, pero necesita comparar ese registro con lo que los socios, proveedores y usuarios hicieron realmente.
Mecanismos comunes de reconciliación
La mayoría de equipos usan un pequeño conjunto de herramientas aburridas (lo aburrido es bueno): un worker que reintenta acciones pendientes y vuelve a comprobar el estado externo, un escaneo programado para inconsistencias y una pequeña acción de reparación para soporte que permita reintentar, cancelar o marcar como revisado.
Qué comparar y qué registrar
La reconciliación solo funciona si sabes qué comparar: libro mayor interno vs libro mayor del proveedor (pagos), estado de la orden vs estado del envío (fulfillment), estado de suscripción vs estado de facturación.
Haz que los estados sean reparables. En lugar de saltar directamente de “creado” a “completado”, usa estados intermedios como pending, on hold o needs review. Eso permite decir con seguridad “no estamos seguros todavía” y da a la reconciliación un lugar claro donde aterrizar.
Captura una pequeña bitácora de auditoría en cambios importantes:
- Cuándo enviaste una petición y cuándo fue la última vez que recibiste respuesta
- IDs de correlación que enlacen tu registro con un evento/referencia externa
- El último estado externo conocido (y de dónde vino)
- Un campo de razón para sobrescrituras manuales (quién, qué, por qué)
Ejemplo: si tu app solicita una etiqueta de envío y la red se corta, podrías quedarte con “sin etiqueta” internamente mientras el transportista creó una. Un worker de reconciliación puede buscar por ID de correlación, descubrir que la etiqueta existe y avanzar la orden (o marcarla para revisión si los detalles no coinciden).
Paso a paso: diseñando un flujo que sobreviva fallos de red
Añade lo básico de outbox e inbox
Genera tablas outbox e inbox y handlers que sean seguros ante reintentos.
Una vez asumes que la red fallará, el objetivo cambia. No buscas que cada paso tenga éxito en un solo intento. Buscas que cada paso sea seguro de repetir y fácil de reparar.
Un flujo práctico
-
Escribe una frase que describa el límite. Sé explícito sobre lo que tu sistema posee (la fuente de verdad), lo que refleja y lo que solo solicita a otros.
-
Lista los modos de fallo antes del camino feliz. Como mínimo: timeouts (no sabes si funcionó), peticiones duplicadas, éxito parcial (un paso ocurrió, el siguiente no) y eventos fuera de orden.
-
Elige una estrategia de idempotencia para cada entrada. Para APIs síncronas, suele ser una clave de idempotencia más un resultado almacenado. Para mensajes/eventos, suele ser un ID de mensaje único y un registro de “¿he procesado esto?”
-
Persiste la intención, luego actúa. Primero guarda algo durable como
PaymentAttempt: pendingoShipmentRequest: queued, luego realiza la llamada externa y después almacena el resultado. Devuelve un ID de referencia estable para que los reintentos apunten a la misma intención en lugar de crear una nueva. -
Construye reconciliación y una ruta de reparación, y hazlas visibles. La reconciliación puede ser un job que escanee registros “pendientes por demasiado tiempo” y vuelva a comprobar el estado. La ruta de reparación puede ser una acción administrativa segura como “reintentar”, “cancelar” o “marcar resuelto”, con una nota de auditoría. Añade observabilidad básica: correlation IDs, campos de estado claros y algunos contadores (pendientes, reintentos, fallos).
Ejemplo: si el checkout hace timeout justo después de llamar a un proveedor de pagos, no adivines. Guarda el intento, devuelve el ID del intento y permite que el usuario reintente con la misma clave de idempotencia. Más tarde, la reconciliación puede confirmar si el proveedor cobró o no y actualizar el intento sin duplicar cobros.
Escenario de ejemplo: flujo de orden con reintentos y callbacks retrasados
Un cliente pulsa “Realizar pedido”. Tu servicio envía una petición de pago a un proveedor, pero la red es inestable. El proveedor tiene su propia verdad, y tu base de datos tiene la tuya. Derivarán a menos que lo diseñes para evitarlo.
Qué sucede en lo fuera (eventos que no controlas)
Desde tu punto de vista, lo fuera es una secuencia de mensajes que puede estar atrasada, repetirse o faltar:
- “Enviar pedido” llega a tu API.
- Tu petición de pago va al proveedor.
- El proveedor envía un webhook diciendo “autorizado”.
- El proveedor reintenta el webhook y envía el mismo callback otra vez.
- Tu cliente hace timeout y reintenta “Realizar pedido”.
Ninguno de esos pasos garantiza “exactamente una vez”. Solo garantizan “quizá”.
Qué guardas dentro (registros que controlas)
Dentro de tu límite, almacena hechos durables y lo mínimo necesario para conectar eventos externos a esos hechos.
Cuando el cliente hace el pedido por primera vez, crea un registro order en un estado claro como pending_payment. También crea un registro payment_attempt con una referencia única del proveedor más una idempotency_key vinculada a la acción del cliente.
Si el cliente hace timeout y reintenta, tu API no debería crear una segunda orden. Debe buscar la idempotency_key y devolver el mismo order_id y estado actual. Esa elección evita duplicados cuando fallan las redes.
Ahora el webhook llega dos veces. El primer callback actualiza payment_attempt a authorized y mueve la orden a paid. El segundo callback llega al mismo handler, pero detectas que ya procesaste ese evento del proveedor (almacenando el ID del evento del proveedor o comprobando el estado actual) y no haces nada. Aún puedes responder 200 OK, porque el resultado ya es verdadero.
Finalmente, la reconciliación maneja los casos desordenados. Si la orden sigue en pending_payment después de un retraso, un job en segundo plano consulta al proveedor usando la referencia almacenada. Si el proveedor dice “autorizado” pero te perdiste el webhook, actualizas tus registros. Si el proveedor dice “fallido” pero tú la marcaste como pagada, la marcas para revisión o activas una compensación como un reembolso.
Errores comunes que causan duplicados y estados atascados
Prueba casos de fallo de forma segura
Itera en flujos críticos usando snapshots y revierte cuando los cambios fallen.
La mayoría de registros duplicados y flujos “atascados” vienen de mezclar lo que pasó fuera de tu sistema (llegó una petición, se recibió un mensaje) con lo que comprometiste de forma segura dentro de tu sistema.
Un fallo clásico: un cliente envía “realizar pedido”, tu servidor empieza a trabajar, la red se cae y el cliente reintenta. Si tratas cada reintento como una verdad nueva, obtendrás cargos dobles, pedidos duplicados o correos múltiples.
Las causas habituales son:
- Confiar en la petición entrante demasiado pronto: enviar correos o loguear “orden creada” antes de que el commit en base de datos sea durable.
- Reintentos que crean nuevas filas: generar un nuevo order ID en cada intento en lugar de mapear reintentos a un mismo resultado.
- Asumir entrega “exactamente una vez”: colas y callbacks no lo prometen. Ocurren duplicados, retrasos y reordenamientos.
- No tener identificadores estables: si no puedes responder “¿he visto exactamente esta intención antes?”, no puedes evitar duplicados.
- Solo éxito/fracaso, sin estado intermedio: sin estados pending/awaiting, los timeouts se vuelven misterios y los usuarios hacen clic otra vez.
Un problema que empeora todo: sin rastro de auditoría. Si sobrescribes campos y mantienes solo el estado más reciente, pierdes la evidencia necesaria para reconciliar después.
Una buena comprobación de cordura es: “Si ejecuto este handler dos veces, ¿obtengo el mismo resultado?” Si la respuesta es no, los duplicados no son un raro caso límite. Son garantizados.
Una lista rápida y pasos prácticos siguientes
Si recuerdas una cosa: tu app debe seguir correcta incluso cuando los mensajes lleguen tarde, lleguen dos veces o nunca lleguen.
Usa esta lista para detectar puntos débiles antes de que se conviertan en registros duplicados, actualizaciones perdidas o flujos atascados:
- La fuente de verdad está explícita: para cada flujo, puedes señalar un lugar que es “la verdad” (a menudo tu base de datos).
- Cada escritura puede reintentarse de forma segura: cada comando/llamada API tiene una clave de idempotencia (o una clave natural única).
- Existen IDs estables y correlation IDs de extremo a extremo: puedes trazar una acción de negocio en logs, tablas y callbacks.
- La reconciliación corre automáticamente: comparas regularmente “lo que creemos” vs “lo que ocurrió” y reparas o elevas una alerta clara.
- Rollback no corrompe el estado: los cambios son auditables y compatibles entre versiones.
Si no puedes responder una de estas rápido, eso ya es útil. Normalmente significa que un límite es difuso o falta una transición de estado.
Pasos prácticos siguientes:
-
Dibuja primero límites y estados. Define un pequeño conjunto de estados por flujo (por ejemplo: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
-
Añade idempotencia donde más importa. Empieza por las escrituras de mayor riesgo: crear orden, capturar pago, emitir reembolso. Almacena claves de idempotencia en PostgreSQL con una restricción única para que los duplicados se rechacen de forma segura.
-
Trata la reconciliación como una característica normal. Programa un job que busque registros “pendientes por demasiado tiempo”, consulte sistemas externos y repare el estado local.
-
Itera con seguridad. Ajusta transiciones y reglas de reintento y prueba reenviando deliberadamente la misma petición y reprocesando el mismo evento.
Si construyes rápido en una plataforma guiada por chat como Koder.ai (koder.ai), vale la pena incorporar estas reglas en tus servicios generados desde el principio: la velocidad viene de la automatización, pero la fiabilidad viene de límites claros, handlers idempotentes y reconciliación.
Preguntas frecuentes
¿Qué significa “datos fuera vs dentro” en términos simples?
"Outside" es cualquier cosa que no controlas: navegadores, redes móviles, colas, webhooks de terceros, reintentos y timeouts. Asume que los mensajes pueden demorarse, duplicarse, perderse o llegar fuera de orden.
"Inside" es lo que tú sí controlas: tu estado almacenado, tus reglas y los hechos que puedes demostrar después (por lo general en tu base de datos).
¿Por qué no puedo confiar en que las solicitudes entrantes o los webhooks ocurran exactamente una vez?
Porque la red te miente.
Un cliente que agota el tiempo no significa que tu servidor no procesó la petición. Un webhook que llega dos veces no implica que el proveedor hizo la acción dos veces. Si tratas cada mensaje como una "nueva verdad", acabarás con órdenes duplicadas, cargos dobles y flujos bloqueados.
¿Dónde debería trazar el “límite” en una app típica?
Un límite claro es el punto donde un mensaje poco fiable se convierte en un hecho durable.
Límites comunes:
- Un endpoint API que hace commit en tu base de datos
- Un consumidor de cola que almacena un evento como cambio de estado
- Un handler de callback que registra lo que el proveedor afirma que ocurrió
Una vez que los datos cruzan ese límite, aplicas invariantes dentro (por ejemplo: "una orden solo puede pagarse una vez").
¿Cómo evito cargos dobles cuando los usuarios reintentan "Pagar"?
Usa idempotencia. La regla es: la misma intención debe producir el mismo resultado incluso si se envía varias veces.
Patrones prácticos:
- El cliente envía una clave de idempotencia por acción
- El servidor almacena la clave y el resultado final en almacenamiento durable
- En duplicados, devuelve el mismo ID de recurso/estado que en la primera petición
¿Dónde almaceno registros de idempotencia y cuánto tiempo debería mantenerlos?
No lo guardes solo en memoria. Almacénalo dentro de tu límite (por ejemplo, PostgreSQL) para que reinicios no borren la protección.
Regla de retención orientativa:
- Acciones de bajo riesgo: minutos a horas
- Acciones de alto costo (pagos, reembolsos, envíos, correos): días o más
Guárdalo el tiempo suficiente para cubrir reintentos realistas y callbacks demorados.
¿Qué estados debería añadir para evitar bugs de “no estamos seguros”?
Usa estados que admitan incertidumbre.
Un conjunto simple y práctico:
pending_*(aceptamos la intención pero no sabemos aún el resultado)succeeded/failed(registramos un resultado final)needs_review(detectamos un desajuste que requiere intervención humana o un job especial)
¿Por qué las transacciones distribuidas suelen ser una trampa en flujos de app?
Porque no puedes commitear atómicamente a través de múltiples sistemas por la red.
Si haces "guardar orden → cobrar tarjeta → reservar inventario" sincrónicamente y el paso 2 hace timeout, no sabrás si reintentar. Reintentar puede causar duplicados; no reintentar puede dejar trabajo incompleto.
Diseña para éxito parcial: persiste la intención primero, luego realiza acciones externas y finalmente registra los resultados.
¿Qué es el patrón outbox/inbox y cuándo debería usarlo?
El patrón outbox/inbox hace el mensajería entre sistemas fiable sin fingir que la red es perfecta.
- Outbox: en la misma transacción de base de datos que tu cambio de estado, escribe una fila que represente el mensaje que quieres enviar.
- Un worker lee el outbox y envía el mensaje.
- Inbox (lado receptor): almacena IDs de mensajes procesados para que re-entregas no creen efectos secundarios duplicados.
¿Qué es la reconciliación y cuál es una forma simple de implementarla?
La reconciliación es cómo recuperas cuando tus registros y un sistema externo no coinciden.
Buenos valores por defecto:
- Un job programado que vuelve a comprobar ítems “pendientes por demasiado tiempo”
- Un paso de comparación (nuestro estado vs estado del proveedor)
- Una acción de reparación: reintentar, cancelar, reembolsar o marcar
needs_review
No es opcional para pagos, fulfillment, suscripciones o cualquier cosa con webhooks.
¿Sigue importando esto si desarrollo rápido con una plataforma como Koder.ai?
Sí. Construir rápido no elimina las fallas de red; solo te hace encontrarlas antes.
Si generas servicios con Koder.ai, aplica estas reglas desde el inicio:
- Límite claro (cuándo una intención se vuelve durable)
- Handlers idempotentes para acciones de tipo crear/capturar/reembolso
- Correlation IDs almacenados con referencias externas
- Un job de reconciliación para registros pendientes
Así, reintentos y callbacks duplicados se vuelven aburridos en lugar de costosos.