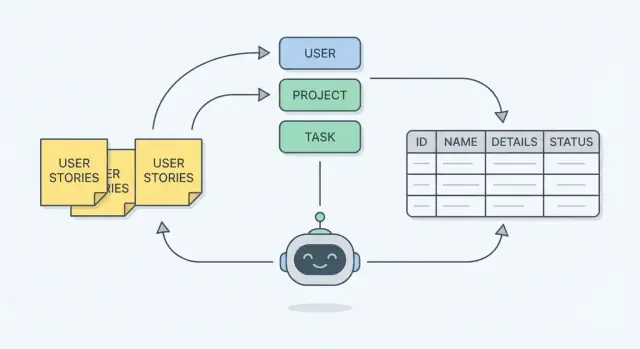
Lo que estás construyendo: un esquema que coincide con el trabajo real
Un esquema de base de datos es el plan de cómo tu app recordará cosas. En términos prácticos, es:
- Tablas: los “cubos” de información (Customers, Orders, Tickets)
- Campos (columnas): los detalles que guardas sobre cada cosa (customer_name, order_date)
- Relaciones: cómo se conectan los cubos (un Order pertenece a un Customer; un Customer puede tener muchos Orders)
Cuando el esquema coincide con el trabajo real, refleja lo que la gente realmente hace: crear, revisar, aprobar, programar, asignar, cancelar—en lugar de lo que suena ordenado en una pizarra.
¿Por qué empezar por las historias de usuario?
Las historias de usuario y los criterios de aceptación describen necesidades reales en lenguaje llano: quién hace qué y qué significa “hecho”. Si usas eso como fuente, el esquema es menos propenso a perder detalles clave (como “debemos registrar quién aprobó el reembolso” o “una reserva puede reprogramarse varias veces”).
Empezar desde las historias también te mantiene honesto respecto al alcance. Si no está en las historias (o en el flujo de trabajo), considéralo opcional en lugar de construir silenciosamente un modelo complejo “por si acaso”.
Lo que la IA puede y no puede hacer aquí
La IA puede ayudarte a avanzar más rápido al:
- Extraer candidatas de entidades (las “cosas” importantes en las historias)
- Sugerir campos implícitos en los criterios de aceptación (timestamps, estados, referencias)
- Detectar relaciones y huecos probables (“mencionas aprobaciones pero no almacenas el aprobador”)
La IA no puede, de forma fiable:
- Conocer reglas de negocio ocultas o casos límite que no escribiste
- Elegir el nivel “correcto” de detalle sin trade-offs (simple vs. flexible)
- Garantizar que el esquema cumple tus necesidades de reporting, seguridad o cumplimiento
Trata a la IA como un asistente potente, no como el decisor.
Si quieres convertir ese asistente en impulso, una plataforma de “vibe-coding” como Koder.ai puede ayudarte a pasar de decisiones de esquema a una app funcional React + Go + PostgreSQL más rápido, manteniéndote en control del modelo, las restricciones y las migraciones.
Fija expectativas: iterativo, no de una sola vez
El diseño de esquema es un ciclo: bosquejo → prueba contra historias → encontrar datos faltantes → refinar. El objetivo no es un output perfecto al primer intento; es un modelo al que puedas trazar cada historia y decir con confianza: “Sí, podemos almacenar todo lo que este flujo necesita—y podemos explicar por qué existe cada tabla”.
Entradas: historias de usuario, criterios de aceptación y ejemplos reales
Antes de convertir requisitos en tablas, aclara qué estás modelando. Un buen esquema rara vez parte de una hoja en blanco—parte de trabajo concreto que la gente hace y de la evidencia que necesitarás más tarde (pantallas, salidas y casos límite).
Las entradas típicas que quieres tener en un solo lugar
Las historias son el titular, pero no bastan por sí solas. Reúne:
- Historias de usuario + roles (quién hace qué y por qué)
- Criterios de aceptación (las reglas “debe ser verdad”)
- Formularios/pantallas (campos que los usuarios escriben, eligen o ven)
- Informes/exportaciones (qué debe resumirse, agruparse o filtrarse)
- Ejemplos reales (pedidos de ejemplo, facturas, tickets, calendarios—cualquier cosa representativa)
Si usas IA, estas entradas mantienen el modelo anclado. La IA puede proponer entidades y campos rápido, pero necesita artefactos reales para no inventar una estructura que no coincide con tu producto.
Criterios de aceptación: la fuente oculta de restricciones
Los criterios de aceptación a menudo contienen las reglas de base de datos más importantes, incluso si no mencionan datos explícitamente. Busca declaraciones como:
- “El correo debe ser único” (unicidad)
- “El estado puede ser Draft, Submitted, Approved” (valores permitidos)
- “Solo los managers pueden aprobar” (permisos, posiblemente campos de auditoría)
- “No se puede borrar una factura con pagos” (reglas referenciales)
Errores comunes para arreglar temprano
Historias vagas (“Como usuario, puedo gestionar proyectos”) ocultan múltiples entidades y flujos. Otra brecha frecuente es olvidar casos límite como cancelaciones, reintentos, reembolsos parciales o reasignaciones.
Lista rápida de calidad de historia (antes de modelar)
- El actor/rol está explícito.
- El objeto es específico (no “datos” o “cosas”).
- Existe al menos un ejemplo real.
- Los criterios de aceptación incluyen validaciones y límites.
- Se mencionan errores y casos “qué pasa si” (o se difieren explícitamente).
Antes de pensar en tablas o diagramas, lee las historias y subraya los sustantivos. En redacción de requisitos, los sustantivos suelen apuntar a las “cosas” que tu sistema debe recordar—estas suelen convertirse en entidades en tu esquema.
Un modelo mental rápido: los sustantivos se vuelven entidades, mientras que los verbos indican acciones o flujos. Si una historia dice “Un manager asigna un técnico a un trabajo”, las entidades probables son manager, technician y job—y “asigna” sugiere una relación que modelarás luego.
Cómo saber si un sustantivo es una entidad real
No todo sustantivo merece su propia tabla. Un sustantivo es buen candidato a entidad cuando:
- Tiene identidad propia: puedes señalar una instancia específica (Job #1042, Cliente A).
- Cambia con el tiempo: tiene ciclo de vida (un trabajo pasa de programado → completado).
- Se usa en varios lugares: varias historias lo referencian, o varios flujos lo tocan.
Si un sustantivo aparece solo una vez, o solo describe otra cosa (“botón rojo”, “viernes”), puede no ser una entidad.
Atributo vs. entidad separada (la prueba de “Dirección” y “Etiqueta”)
Un error común es convertir cada detalle en una tabla. Usa esta regla empírica:
- Si es un valor que describe algo, suele ser un atributo (p. ej., Customer.phone_number).
- Si es repetible, compartido o estructurado, suele ser una entidad separada.
Dos ejemplos clásicos:
- Dirección: si guardas direcciones de envío y facturación, mantienes historial o reusas direcciones entre clientes/ubicaciones, Address probablemente sea entidad propia. Si solo necesitas una dirección postal única y nunca la reaprovechas, puede quedarse como atributos.
- Etiqueta (Tag): las etiquetas casi siempre son su propia entidad porque son repetibles y muchos-a-muchos (un Job tiene muchas Tags; una Tag aplica a muchos Jobs).
Usar IA para sugerir entidades candidatas (con cautela)
La IA puede acelerar el descubrimiento de entidades al escanear historias y devolver una lista inicial de sustantivos agrupados por tema (personas, ítems de trabajo, documentos, ubicaciones). Un prompt útil es: “Extrae sustantivos que representen datos que debemos almacenar, y agrupa duplicados/sinónimos.”
Trata el resultado como un punto de partida, no la respuesta final. Haz seguimientos como:
- “¿Cuáles de estos tienen ciclo de vida o necesitan su propio ID?”
- “¿Cuáles son en realidad estados, categorías o atributos?”
- “¿Hay sinónimos (p. ej., ‘client’ vs ‘customer’)?”
El objetivo del Paso 1 es una lista corta y limpia de entidades que puedas defender señalando las historias reales.
Paso 2 — Convertir detalles en campos (los recordatorios que debes almacenar)
Una vez nombradas las entidades (como Order, Customer, Ticket), el siguiente trabajo es capturar los detalles que necesitarás más tarde. En la base de datos, esos detalles son campos (también llamados atributos): los recordatorios que tu sistema no puede permitirse olvidar.
Cómo elegir campos (sin adivinar)
Empieza con la historia de usuario, luego lee los criterios de aceptación como una lista de verificación de lo que debe almacenarse.
Si un requisito dice “Los usuarios pueden filtrar pedidos por fecha de entrega”, entonces delivery_date no es opcional—debe existir como campo (o derivarse de forma fiable de otros datos almacenados). Si dice “Mostrar quién aprobó la solicitud y cuándo”, probablemente necesites approved_by y approved_at.
Una prueba práctica: ¿Alguien necesitará esto para mostrar, buscar, ordenar, auditar o calcular algo? Si la respuesta es sí, probablemente pertenece como campo.
Reglas simples para campos limpios
- Mantén los valores atómicos: guarda “Nombre” y “Apellido” por separado si vas a buscarlos u ordenarlos. Evita empaquetar múltiples valores en un campo (p. ej., “rojo, azul”).
- Usa tipos consistentes: fechas como fechas, dinero como decimales, booleanos como true/false—no formatos mixtos como “$10”, “10 USD” y “10”.
- Evita texto duplicado: no copies la dirección del cliente en cada línea de pedido. Guárdala una vez y referencia esa fila.
Vocabularios controlados: estados, tipos y categorías
Muchas historias incluyen palabras como “estado”, “tipo” o “prioridad”. Trátalas como vocabularios controlados—un conjunto limitado de valores permitidos.
Si el conjunto es pequeño y estable, un campo estilo enum puede funcionar. Si puede crecer, necesita etiquetas o permisos (p. ej., categorías administradas por admin), usa una tabla de consulta separada (p. ej., status_codes) y guarda una referencia.
Así las historias se convierten en campos en los que puedes confiar—buscables, reportables y difíciles de ingresar mal.
Paso 3 — Conectar entidades con relaciones
Una vez listadas las entidades (User, Order, Invoice, Comment, etc.) y bosquejados sus campos, el siguiente paso es conectarlas. Las relaciones son la capa de “cómo interactúan estas cosas” implícita en tus historias.
Uno-a-uno (1:1) significa “una cosa tiene exactamente otra”.
- Frase de historia: “Cada usuario tiene un perfil.”
- Idea de modelo:
User ↔ Profile (a menudo puedes unirlas a menos que haya razón para separarlas).
Uno-a-muchos (1:N) significa “una cosa puede tener muchas de otra”. Esto es lo más común.
- Frase de historia: “Un usuario puede tener muchos pedidos.”
- Idea de modelo:
User → Order (almacena user_id en Order).
Muchos-a-muchos (M:N) significa “muchas cosas pueden relacionarse con muchas cosas”. Esto necesita una tabla extra.
- Frase de historia: “Un pedido puede incluir muchos productos, y un producto puede estar en muchos pedidos.”
Muchos-a-muchos: el truco de la tabla de unión
Las bases de datos no manejan bien “una lista de IDs” dentro de Order para relaciones M:N; causa problemas para buscar, actualizar e informar. En cambio, crea una tabla de unión que represente la relación en sí.
Ejemplo:
OrderProductOrderItem (tabla de unión)
OrderItem típicamente incluye:
order_idproduct_id- detalles de la historia como
quantity, unit_price, discount
Fíjate cómo los detalles de la historia (“cantidad”) suelen pertenecer a la relación, no a ninguna de las entidades por separado.
Requerido vs. opcional (sin jerga)
Las historias también te dicen si una conexión es obligatoria o a veces ausente.
- “Un pedido debe pertenecer a un usuario” → cada
Order necesita un user_id (no debe permitirse vacío).
- “Un usuario puede tener un teléfono” →
phone puede quedar vacío.
- “Un pedido puede tener una dirección de envío (si son bienes físicos)” →
shipping_address_id puede estar vacío para pedidos digitales.
Una comprobación rápida: si la historia implica que no puedes crear el registro sin el enlace, trátalo como obligatorio. Si la historia dice “puede”, “puede que” o da excepciones, trátalo como opcional.
Convierte oraciones de historia en oraciones de relación
Cuando leas una historia, reescríbela como un emparejamiento simple:
- “Un usuario puede dejar muchos comentarios” →
User 1:N Comment
- “Un comentario pertenece a un usuario” →
Comment N:1 User
Haz esto para cada interacción en tus historias. Al final tendrás un modelo conectado que refleja cómo ocurre el trabajo—antes de abrir cualquier herramienta de diagrama ER.
Paso 4 — Usa los flujos de trabajo para encontrar estados, eventos y huecos
Cambia el esquema sin miedo
Itera de forma segura con instantáneas y reversión mientras ajustas tablas y restricciones.
Las historias dicen qué quieren las personas. Los flujos de trabajo muestran cómo se mueve el trabajo realmente, paso a paso. Traducir un flujo de trabajo a datos es una de las formas más rápidas de detectar problemas de “no guardamos esto”—antes de construir nada.
Empieza con un flujo simple
Escribe el flujo como una secuencia de acciones y cambios de estado. Por ejemplo:
- Crear solicitud → Draft
- Enviar solicitud → Submitted
- El manager revisa → Approved o Rejected
- Si se aprueba, se programa el trabajo → In progress
- Completado → Done
Esas palabras en negrita suelen convertirse en un campo status (o una pequeña tabla de “estado”), con valores permitidos claros.
Los flujos revelan campos faltantes
Mientras recorres cada paso, pregunta: “¿Qué necesitaríamos saber después?” Los flujos suelen revelar campos como:
- timestamps:
submitted_at, approved_at, completed_at
- propiedad:
created_by, assigned_to, approved_by
- motivo/contexto:
rejection_reason, approval_note
- orden:
sequence para procesos de múltiples pasos
Si tu flujo incluye esperas, escalados o entregas, normalmente necesitarás al menos un timestamp y un campo de “quién lo tiene ahora”.
Los flujos exponen tablas faltantes
Algunos pasos del flujo no son solo campos—son estructuras de datos separadas:
- Registro de auditoría / historial para “quién cambió el estado cuándo”
- Aprobaciones para reglas de aprobación multi-aprobador o condicionales
- Adjuntos cuando los usuarios suben archivos durante un paso
- Comentarios cuando la discusión es parte del proceso
Usar IA para verificar huecos
Dale a la IA: (1) las historias y criterios de aceptación, y (2) los pasos del flujo. Pídele listar cada paso e identificar datos requeridos para cada uno (estado, actor, timestamps, salidas), luego resaltar cualquier requisito que no pueda ser soportado por los campos/tablas actuales.
En plataformas como Koder.ai, esta “verificación de huecos” es especialmente práctica porque puedes iterar rápido: ajustas supuestos del esquema, regeneras scaffolding y sigues avanzando sin un gran desvío por boilerplate manual.
Claves, unicidad y restricciones básicas (sin la jerga)
Al convertir historias en tablas, no solo listas campos: decides cómo los datos permanecen identificables y consistentes a lo largo del tiempo.
Claves primarias: una “identidad” estable para cada fila
Una clave primaria identifica de forma única un registro—piénsalo como la tarjeta de identidad permanente de la fila.
Por qué cada fila la necesita: las historias implican actualizaciones, referencias e historial. Si una historia dice “Soporte puede ver un pedido y emitir un reembolso”, necesitas una forma estable de apuntar al pedido—aunque el cliente cambie su correo, la dirección se edite o el estado cambie.
En la práctica, suele ser un id interno (número o UUID) que nunca cambia.
Claves foráneas: punteros entre tablas
Una clave foránea es cómo una tabla apunta de forma segura a otra. Si orders.customer_id referencia customers.id, la base de datos puede hacer cumplir que cada pedido pertenece a un cliente real.
Esto coincide con historias como “Como usuario, puedo ver mis facturas.” La factura no está flotando; está adjunta a un cliente (y a menudo a un pedido o suscripción).
Reglas de unicidad: convertir “debe ser único” en enforcement
Las historias contienen requisitos de unicidad ocultos regularmente:
- “Los usuarios se registran con correo” → aplica correo único (o único por tenant si soportas múltiples cuentas).
- “Finanzas busca por número de factura” → asegúrate invoice_number único.
Estas reglas evitan duplicados confusos que aparecen meses después como “bugs de datos”.
Indexado (alto nivel): haz rápidas las búsquedas comunes
Los índices aceleran búsquedas como “buscar cliente por correo” o “listar pedidos por cliente”. Empieza con índices alineados a tus consultas más comunes y reglas de unicidad.
Qué dejar para después: indexado pesado para informes raros o filtros especulativos. Registra esas necesidades en historias, valida el esquema primero y optimiza según uso real y evidencia de consultas lentas.
Mantén los datos consistentes: una lista práctica de normalización
Comparte una vista previa real
Publica una app real con tu propio dominio personalizado cuando estés listo para compartirla.
La normalización tiene un objetivo simple: evitar duplicados conflictivos. Si el mismo hecho puede guardarse en dos sitios, tarde o temprano discrepancias surgirán (dos ortografías, dos precios, dos direcciones “actuales”). Un esquema normalizado almacena cada hecho una vez y lo referencia.
Una lista rápida que puedes ejecutar sobre cualquier esquema provisional
1) Vigila grupos repetidos
Si ves patrones como “Phone1, Phone2, Phone3” o “ItemA, ItemB, ItemC”, es señal de otra tabla (p. ej., CustomerPhones, OrderItems). Los grupos repetidos complican la búsqueda, validación y escalado.
2) No copies el mismo nombre/detalle en varias tablas
Si CustomerName aparece en Orders, Invoices y Shipments, creaste múltiples fuentes de la verdad. Mantén los detalles del cliente en Customers y guarda solo customer_id en otros sitios.
3) Evita “múltiples columnas para lo mismo”
Columnas como billing_address, shipping_address, home_address pueden estar bien si realmente son conceptos distintos. Pero si modelas “muchas direcciones de distintos tipos”, usa una tabla Addresses con un campo type.
4) Separa lookup de texto libre
Si los usuarios eligen de un conjunto conocido (estado, categoría, rol), módelos consistentemente: o un enum restringido o una tabla de consulta. Esto evita “Pending” vs “pending” vs “PENDING”.
5) Comprueba que cada campo no-ID dependa de lo correcto
Un chequeo útil: en una tabla, si una columna describe algo distinto de la entidad principal de la tabla, probablemente pertenece en otra tabla. Ejemplo: Orders no debe almacenar product_price a menos que signifique “precio al momento del pedido” (un snapshot histórico).
Cuando la desnormalización es aceptable (como elección posterior)
A veces sí almacenas duplicados a propósito:
- Informes/rendimiento: totales pre-aggregados o tablas resumen.
- Caching: un valor computado para evitar recálculos costosos.
- Auditoría/historial: copiar “nombre en el momento de la compra” para preservar la realidad pasada.
La clave es que sea intencional: documenta cuál campo es la fuente de verdad y cómo se actualizan las copias.
Dónde ayuda la IA—and dónde deciden las personas
La IA puede señalar duplicaciones sospechosas (columnas repetidas, nombres similares, campos de “estado” inconsistentes) y sugerir divisiones en tablas. Los humanos siguen eligiendo el trade-off—simplicidad vs. flexibilidad vs. rendimiento—según el uso real del producto.
Almacenado vs. calculado: qué pertenece a la base de datos
Una regla útil: almacena hechos que no puedes recrear con fiabilidad; calcula todo lo demás.
Almacenado vs. calculado (derivado)
Datos almacenados son la fuente de verdad: partidas, timestamps, cambios de estado, quién hizo qué. Datos calculados se derivan de esos hechos: totales, contadores, banderas como “está atrasado” y rollups como “inventario actual”.
Si dos valores pueden calcularse a partir de los mismos hechos subyacentes, prefiere almacenar los hechos y calcular el resto. Si no, corres el riesgo de contradicciones.
Por qué almacenar valores derivados causa desajustes
Los derivados cambian cuando cambian sus entradas. Si almacenas tanto las entradas como el resultado derivado, debes mantenerlos sincronizados en cada flujo y caso límite (ediciones, reembolsos, cambios con efecto retroactivo). Un fallo y la base cuenta dos historias distintas.
Ejemplo: almacenar order_total junto con order_items. Si alguien cambia una cantidad o aplica un descuento y el total no se actualiza perfectamente, finanzas ve un número y el carrito otro.
Usa flujos para decidir qué debe almacenarse (historial y snapshots)
Los flujos revelan cuándo necesitas verdad histórica, no solo “verdad actual”. Si los usuarios necesitan saber cuál fue el valor en ese momento, almacena un snapshot.
Para un pedido, puedes almacenar:
- Partidas y precios (hechos)
- Un
order_total capturado en el checkout (snapshot), porque impuestos, descuentos y reglas de precios cambian después
Para inventario, “nivel de inventario” suele calcularse desde movimientos (recepciones, ventas, ajustes). Pero si necesitas trazabilidad, almacena movimientos y opcionalmente snapshots periódicos para velocidad de informe.
Para tracking de login, guarda last_login_at como hecho (timestamp de evento). “Está activo en los últimos 30 días?” se calcula.
Ejemplo trabajado: de 5 historias de usuario a un modelo ER
Usemos una app de tickets de soporte conocida. Iremos de cinco historias a un ER simple (entidades + campos + relaciones), y luego lo comprobamos con un flujo.
5 historias → sustantivos → entidades
- Como cliente, puedo crear un ticket de soporte con asunto, descripción y categoría.
- Como agente, puedo asignar un ticket a mí o a otro agente.
- Como agente, puedo añadir notas internas y respuestas públicas a un ticket.
- Como cliente, puedo ver cuándo se actualiza mi ticket y cuándo se cierra.
- Como manager, puedo medir cuánto tiempo permanecen abiertos los tickets y quién los cerró.
De esos sustantivos obtenemos entidades centrales:
- User (clientes, agentes, managers)
- Ticket
- Message (respuestas públicas + notas internas)
- Category
- TicketEvent (auditoría/historial)
Campos y relaciones (un ER compacto)
- User: id, name, email, role
- Category: id, name
- Ticket: id, subject, description, status, created_at, updated_at, closed_at
- relaciones: Ticket.category_id → Category.id
- relaciones: Ticket.requester_id → User.id (cliente)
- relaciones: Ticket.assignee_id → User.id (agente, nullable)
- Message: id, ticket_id, author_id, body, is_internal, created_at
- relaciones: Message.ticket_id → Ticket.id
- relaciones: Message.author_id → User.id
- TicketEvent: id, ticket_id, actor_id, type, from_status, to_status, created_at
Mapeo del flujo: crear → actualizar → cerrar
- Crear: insertar Ticket (status = “open”, created_at), insertar TicketEvent(type = “created”).
- Actualizar (asignar, responder): insertar Message o actualizar Ticket.assignee_id, e insertar TicketEvent(type = “assigned”/“replied”, updated_at).
- Cerrar: actualizar Ticket.status = “closed”, set closed_at, insertar TicketEvent(type = “closed”, actor_id = closer).
“Antes y después”: la IA detecta una restricción faltante
Antes (error común): Ticket tiene assignee_id, pero olvidamos asegurar que solo agentes puedan ser asignados.
Después: la IA lo marca y agregas una regla práctica: assignee debe ser un User con role = “agent” (implementado vía validación de aplicación o una restricción/política de base de datos, según tu stack). Esto evita “asignado a cliente” que rompe informes más tarde.
Validar el esquema: traza cada historia
Consigue un borrador de esquema rápido
Boceta tablas, campos y relaciones a partir de tus criterios de aceptación y refínalos rápidamente.
Un esquema está “listo” cuando cada historia puede responderse con datos que puedas almacenar y consultar de forma fiable. La validación más simple es tomar cada historia y preguntar: “¿Podemos responder esto desde la base de datos, de forma fiable, en todos los casos?” Si la respuesta es “quizá”, tu modelo tiene una brecha.
Convierte cada historia en una pregunta de base de datos
Reescribe cada historia como una o más preguntas de prueba—cosas que esperarías que un informe, pantalla o API pregunte. Ejemplos:
- Informes: “Mostrar todos los pedidos abiertos por cliente, con totales de los últimos 30 días.”
- Permisos: “¿Qué usuarios pueden aprobar reembolsos para esta tienda?”
- Casos límite: “¿Puede existir un pedido sin dirección de envío? ¿Y para artículos digitales?”
- Eliminaciones: “Si borramos un cliente, ¿qué pasa con pedidos, facturas y notas?”
Si no puedes expresar una historia como pregunta clara, la historia no está clara. Si puedes expresarla—pero no puedes responderla con tu esquema—te falta un campo, una relación, un estado/evento o una restricción.
Usa datos de ejemplo como chequeo rápido
Crea un pequeño dataset (5–20 filas por tabla clave) que incluya casos normales y difíciles (duplicados, valores faltantes, cancelaciones). Luego “juega” las historias con esos datos. Detectarás rápidamente problemas como “no podemos saber qué dirección se usó en el momento de la compra” o “no hay dónde guardar quién aprobó el cambio”.
Deja que la IA te ayude a encontrar casos no manejados
Pide a la IA que genere preguntas de validación por historia (incluyendo casos límite y escenarios de eliminación), y que liste los datos requeridos para responderlas. Compara esa lista con tu esquema: cualquier desajuste es una acción concreta, no una sensación vaga de que “algo está mal”.
La IA puede acelerar el modelado de datos, pero también aumenta el riesgo de filtrar información sensible o codificar suposiciones malas. Trátala como un asistente muy rápido: útil, pero necesita guardarraíles.
Qué compartir con la IA (y qué evitar)
Comparte entradas realistas pero saneadas:
- Historias de usuario saneadas (renombra clientes, productos, ubicaciones)
- Criterios de aceptación y casos límite (“reembolso en 14 días”, “una suscripción activa por cuenta”)
- Ejemplos de campos con datos falsos (p. ej.,
invoice_total: 129.50, status: "paid")
- Cabeceras CSV / tablas existentes (la estructura suele ser segura; el contenido no)
Evita cualquier cosa que identifique personas o revele operaciones confidenciales:
- Nombres reales, correos, teléfonos, direcciones
- Historiales reales de pedidos, tickets, notas internas
- Claves API, credenciales de BD, capturas con datos privados
Si necesitas realismo, genera muestras sintéticas que respeten formatos y rangos—nunca copies filas de producción.
Pon las suposiciones junto al esquema
Los esquemas fallan porque “todos asumieron” cosas distintas. Junto a tu ER (o en el mismo repo), guarda un breve registro de decisiones:
- Definiciones (“¿Qué cuenta como una cuenta ‘activa’?”)
- Restricciones (“Un usuario puede pertenecer a múltiples organizaciones”)
- Trade-offs (“Almacenamos el código de moneda en cada factura para auditoría”)
Esto convierte la salida de la IA en conocimiento de equipo en lugar de un artefacto puntual.
Planea para el cambio: versionado y migraciones
Tu esquema evolucionará con nuevas historias. Protégelo así:
- Versiona los cambios de esquema (migraciones en Git)
- Escribe migraciones reversibles cuando sea posible
- Actualiza seeds y consultas de ejemplo para que los cambios sean testeables
- Revisa migraciones generadas por IA como cualquier otro código
Si usas una plataforma como Koder.ai, aprovecha guardarraíles como snapshots y rollback al iterar en esquemas, y exporta el código fuente cuando necesites personalización o una revisión tradicional.
Un flujo repetible y simple
- Sanea historias + crea 5–10 ejemplos sintéticos.
- Pide a la IA proponer entidades, campos, relaciones y restricciones.
- Revisa con el equipo; registra suposiciones.
- Implementa migraciones; ejecuta una pequeña prueba de “trazado de historias” (cada historia puede satisfacerse con el modelo).
- Repite cuando las historias cambien; mantén el esquema y las notas sincronizadas.