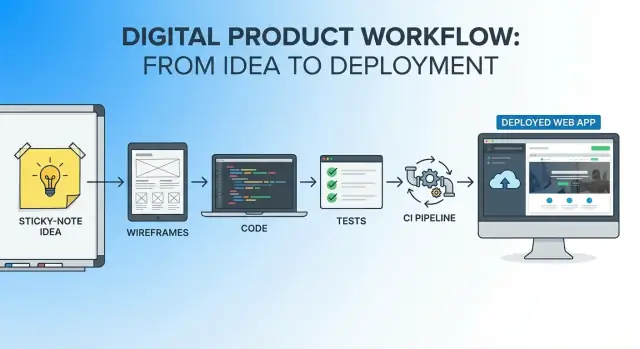
El objetivo: un camino continuo desde la idea hasta la app en vivo
Imagínate una idea pequeña y útil: un “Compañero de Cola” que permite a un empleado de una cafetería pulsar un botón para añadir a un cliente a una lista de espera y enviarle un SMS automáticamente cuando su mesa esté lista. La métrica de éxito es simple y medible: reducir las llamadas por confusión del tiempo de espera en un 50% en dos semanas, manteniendo el onboarding del personal bajo 10 minutos.
Ese es el espíritu de este artículo: elige una idea clara y acotada, define cómo se ve “bien” y luego avanza del concepto al despliegue en vivo sin cambiar constantemente de herramientas, documentos y modelos mentales.
Qué significa “flujo único”
Un flujo único es un hilo continuo desde la primera frase de la idea hasta la primera versión en producción:
- Un lugar donde se registran las decisiones (qué estamos construyendo y por qué)
- Un conjunto de artefactos que evoluciona (requisitos → pantallas → tareas → código → pruebas → notas de despliegue)
- Un bucle de retroalimentación (cada cambio puede rastrearse hasta la meta y la métrica)
Seguirás usando múltiples herramientas (editor, repo, CI, hosting), pero no “reiniciarás” el proyecto en cada fase. La misma narrativa y restricciones avanzan contigo.
El papel de la IA: asistente, no piloto automático
La IA es más valiosa cuando:
- Redacta opciones rápido (texto de requisitos, flujos de usuario, formas de API)
- Genera código inicial y tests que puedes revisar en trozos pequeños
- Señala casos límite que podrías olvidar (validación, permisos, logging)
Pero no toma las decisiones del producto. Tú las tomas. El flujo está diseñado para que siempre verifiques: ¿Este cambio mueve la métrica? ¿Es seguro publicar?
El camino de extremo a extremo que seguiremos
En las siguientes secciones avanzarás paso a paso:
- Aclarar el problema, los usuarios y una “pequeña victoria” que puedas publicar.
- Convertir la idea en un documento ligero de requisitos.
- Bocetar el recorrido del usuario y las pantallas clave.
- Elegir una arquitectura sensata para la versión 1.
- Bootstrappear un esqueleto de repo funcional.
- Construir las funciones principales en rebanadas finas y revisables.
- Añadir lo básico para seguridad: validación, permisos, logging.
- Añadir pruebas que protejan el camino feliz y las partes de riesgo.
- Configurar builds, CI y puertas de calidad.
- Desplegar con un proceso claro y reversible.
- Monitorizar, aprender e iterar—sin romper el hilo.
Al final, deberías tener una forma repetible de pasar de “idea” a “app en vivo” manteniendo el alcance, la calidad y el aprendizaje estrechamente conectados.
Empieza con claridad: problema, usuarios y una pequeña victoria
Antes de pedir a la IA que redacte pantallas, APIs o tablas de la base de datos, necesitas un objetivo nítido. Un poco de claridad aquí ahorra horas de salidas “casi correctas” más adelante.
Enunciado del problema en un párrafo
Construyes una app porque un grupo específico de personas enfrenta repetidamente la misma fricción: no pueden completar una tarea importante de forma rápida, fiable o con confianza usando las herramientas que tienen. El objetivo de la v1 es eliminar un paso doloroso en ese flujo—sin intentar automatizarlo todo—para que los usuarios pasen de “tengo que hacer X” a “X está hecho” en minutos, con un registro claro de lo que ocurrió.
Usuarios objetivo y sus 3 principales tareas
Elige un usuario primario. Los secundarios pueden esperar.
- Usuario primario: Operadores/propietarios ocupados que gestionan el proceso de punta a punta (no especialistas).
- Principales tareas a realizar:
- Capturar la solicitud (o entrada) rápido, sin perder detalles clave.
- Rastrear el estado de un vistazo y saber qué hacer a continuación.
- Compartir un resultado (confirmación, resumen o exportación) que otros puedan confiar.
Suposiciones (lo que debe ser cierto)
Las suposiciones son donde las buenas ideas fallan en silencio—hazlas visibles.
- Los usuarios aceptarán una pequeña configuración inicial a cambio de un flujo repetible.
- Los datos necesarios existen (o pueden introducirse) con precisión razonable.
- Un rastro de auditoría ligero es suficiente; no se requieren características completas de cumplimiento para v1.
- La “ayuda de IA” mejora la velocidad, pero los usuarios aún quieren el control final.
Definición de hecho para la primera versión
La versión 1 debe ser una pequeña victoria publicable.
- Un usuario puede completar el flujo central en menos de 3 minutos.
- Los datos se validan y almacenan, con permisos básicos y un registro de actividad.
- Existe una salida compartible (email, PDF o enlace) y es consistente.
- Puedes desplegar, revertir y responder: “¿está funcionando?”
Convierte la idea en un documento ligero de requisitos
Un doc ligero de requisitos (piensa: una página) es el puente entre “idea genial” y “plan construible”. Te mantiene enfocado, da a tu asistente IA el contexto correcto y evita que la primera versión se convierta en un proyecto de meses.
Redacta una PRD de una página (las partes que importan)
Manténlo apretado y fácil de ojear. Una plantilla simple:
- Problema: ¿Qué dolor resolvemos, en una frase?
- Usuarios objetivo: ¿Quién sufre este dolor con más frecuencia?
- Alcance (Versión 1): Qué construirás ahora.
- No-objetivos: Qué explícitamente no construirás aún (aquí muere el scope creep).
- Restricciones: Presupuesto, cronograma, limitaciones técnicas, cumplimiento, dispositivos, fuentes de datos.
- Métrica de éxito: ¿Qué significa “funcionó”? (incluso un proxy simple está bien).
Define y prioriza 5–10 funcionalidades centrales
Escribe 5–10 funciones máximo, redactadas como resultados. Luego ordénalas:
- Must-have (la app falla sin ello)
- Should-have (alto valor, pero puede esperar)
- Nice-to-have (aparcar)
Este ranking también guía los planes y el código que genere la IA: “Implementa solo los must-haves primero.”
Añade criterios de aceptación para las principales funciones
Para las 3–5 funciones superiores, añade 2–4 criterios de aceptación cada una. Usa lenguaje llano y declaraciones comprobables.
Ejemplo:
- Función: Crear una cuenta
- El usuario puede registrarse con email y contraseña
- La contraseña debe tener al menos 12 caracteres
- Después del registro, el usuario aterriza en el panel
- Un email duplicado muestra un mensaje de error claro
Captura preguntas abiertas para validación rápida
Termina con una corta lista de “Preguntas abiertas”—cosas que puedes responder con un chat, una llamada al cliente o una búsqueda rápida.
Ejemplos: “¿Necesitan los usuarios login de Google?” “¿Cuál es el dato mínimo que debemos guardar?” “¿Necesitamos aprobación administrativa?”
Este documento no es papeleo; es una fuente compartida de verdad que seguirás actualizando durante el desarrollo.
Boceta el recorrido del usuario y las pantallas clave
Antes de pedir a la IA que genere pantallas o código, aclara la historia del producto. Un boceto rápido del recorrido mantiene a todos alineados: qué intenta hacer el usuario, qué significa éxito y dónde pueden ir las cosas mal.
Mapea los flujos principales (camino feliz + casos límite clave)
Comienza con el camino feliz: la secuencia más simple que entrega el valor principal.
Ejemplo de flujo (genérico):
- El usuario se registra / inicia sesión
- El usuario crea un nuevo Proyecto
- El usuario añade Tareas
- El usuario marca una Tarea como completada
- El usuario ve progreso / confirmación
Luego añade algunos casos límite probables y costosos si se manejan mal:
- El usuario abandona el registro a mitad (¿qué pasa con los datos parciales?)
- El usuario pierde acceso (sesión expirada, permiso revocado)
- Estado vacío (aún no hay proyectos)
- Guardado fallido (error de red) y comportamiento de reintento
No necesitas un gran diagrama. Una lista numerada con notas basta para guiar el prototipado y la generación de código.
Lista pantallas/páginas clave y lo que cada una debe lograr
Escribe una corta “tarea a realizar” para cada pantalla. Enfócate en resultados, no en UI.
- Login / Registro: meter al usuario; explicar errores claramente; habilitar restablecimiento de contraseña
- Panel: mostrar elementos actuales y la siguiente acción; manejar el estado vacío con gracia
- Detalle de Proyecto: mostrar información del proyecto; permitir añadir/editar tareas; mostrar estado
- Editor de Tarea (modal/página): crear o actualizar una tarea; validar campos obligatorios
- Ajustes / Cuenta: gestionar perfil; cerrar sesión; eliminar cuenta si hace falta
Si trabajas con IA, esta lista es excelente material de prompt: “Genera un Panel que soporte X, Y, Z e incluya estados vacío/cargando/error.”
Define entidades de datos a alto nivel
Mantenlo en nivel “esquema en servilleta”: suficiente para soportar pantallas y flujos.
- User: id, email, name, role
- Project: id, ownerId, title, createdAt
- Task: id, projectId, title, status, dueDate
Nota relaciones (User → Projects → Tasks) y todo lo que afecte permisos.
Identifica dónde importan la confianza y la seguridad
Marca los puntos donde los errores rompen la confianza:
- Autenticación y manejo de sesiones
- Permisos (¿quién puede ver/editar un proyecto?)
- Acciones destructivas (borrar proyecto/tarea) y confirmaciones
- Auditabilidad (logging básico de ediciones y borrados)
No se trata de sobre-ingeniería—es evitar sorpresas que conviertan una demo en un problema de soporte tras el lanzamiento.
Elige una arquitectura sensata para la versión 1
La arquitectura de v1 debe hacer una cosa bien: permitir que lances el producto útil más pequeño sin meterte en un callejón sin salida. Una buena regla: “un repo, un backend desplegable, un frontend desplegable, una base de datos”—y solo añade piezas cuando un requisito lo demande.
Elige la pila más simple que encaje
Si construyes una app web típica, un valor por defecto sensato es:
- Frontend: React (o Next.js si quieres enrutado + SSR básico)
- Backend: Node.js + un framework minimal (Express/Fastify) o rutas API de Next.js si el API es pequeño
- Base de datos: Postgres (fiable, flexible y soportado casi en todas partes)
Mantén el número de servicios bajo. Para v1, un “monolito modular” (código bien organizado, pero un servicio backend) suele ser más fácil que microservicios.
Si prefieres un entorno orientado a IA donde la arquitectura, las tareas y el código generado se mantengan estrechamente conectados, plataformas como Koder.ai pueden encajar: describes el alcance v1 en chat, iteras en “modo planificación” y luego generas un frontend React con un backend Go + PostgreSQL—manteniendo la revisión y el control en tus manos.
Esboza tu API como un contrato
Antes de generar código, escribe una pequeña tabla de API para que tú y la IA compartan el mismo objetivo. Ejemplo de forma:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }
Añade notas sobre códigos de estado, formato de error (p. ej., { error: { code, message } }) y cualquier paginación.
Decide sobre la autenticación (o evítala)
Si v1 puede ser pública o de un solo usuario, omite la auth y publica más rápido. Si necesitas cuentas, usa un proveedor gestionado (enlace mágico por email u OAuth) y mantén los permisos simples: “el usuario posee sus registros”. Evita roles complejos hasta que el uso real lo demande.
Define objetivos de rendimiento y fiabilidad para el primer lanzamiento
Documenta unas pocas restricciones prácticas:
- Tráfico esperado (aunque sea un número aproximado)
- Objetivo de tiempo de respuesta básico (p. ej., “la mayoría de peticiones bajo 300 ms”)
- Logging mínimo (peticiones, errores y eventos de negocio clave)
- Backups y un plan de rollback
Estas notas guían a la generación de código asistida por IA hacia algo desplegable, no solo funcional.
Bootstrap del repo: de carpeta vacía a esqueleto funcional
Crea un repo funcional rápido
Genera un esqueleto mínimo web + API desde un solo chat en Koder.ai.
La forma más rápida de matar el impulso es debatir herramientas durante una semana y no tener código ejecutable. Tu objetivo aquí: llegar a un “hello app” que arranque localmente, tenga una pantalla visible y pueda aceptar una petición—manteniéndose lo bastante pequeño para revisar cada cambio.
Pide a la IA un esqueleto práctico (no un producto acabado)
Dale a la IA un prompt ajustado: elección de framework, páginas básicas, un stub de API y los archivos que esperas. Buscas convenciones predecibles, no genialidades.
Un primer pase bueno es una estructura como:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
Si usas un repo monorrepo, pide rutas básicas (p. ej., / y /settings) y un endpoint API (p. ej., GET /health o GET /api/status). Eso basta para probar que la tubería funciona.
Si usas Koder.ai, este también es un buen punto de partida: pide un esqueleto mínimo “web + api + listo para base de datos”, y exporta el código cuando estés satisfecho con la estructura y convenciones.
Genera una UI mínima conectada a un backend stub
Mantén la UI intencionalmente sosa: una página, un botón, una llamada.
Comportamiento de ejemplo:
- La homepage renderiza “App is running.”
- Un botón llama al endpoint del backend.
- La respuesta se muestra en la página.
Esto te da un bucle de retroalimentación inmediato: si la UI carga pero la llamada falla, sabes dónde buscar (CORS, puerto, enrutado, errores de red). Evita añadir auth, bases de datos o estado complejo aquí—lo harás tras estabilizar el esqueleto.
Añade variables de entorno e instrucciones de desarrollo local
Crea un .env.example desde el día uno. Evita problemas de “funciona en mi máquina” y facilita el onboarding.
Ejemplo:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
Luego haz el README ejecutable en menos de un minuto:
- instalar dependencias
- copiar
.env.example a .env
- arrancar web + api
- abrir la URL en el navegador
Mantén los cambios pequeños y commitea pronto
Trata esta fase como trazar líneas de cimiento limpias. Commitea tras cada pequeño logro: “init repo”, “añadir shell web”, “añadir endpoint de salud al api”, “conectar web con api”. Commits pequeños hacen la iteración asistida por IA más segura: si un cambio generado sale mal, puedes revertir sin perder un día de trabajo.
Construye las funciones principales en rebanadas finas y revisables
Una vez que el esqueleto funciona de extremo a extremo, resiste la tentación de “terminarlo todo”. En su lugar, construye una rebanada vertical estrecha que toque la base de datos, API y UI (si aplica), y repite. Las rebanadas finas mantienen las revisiones rápidas, los bugs pequeños y la asistencia IA más fácil de verificar.
Empieza con el modelo de datos principal (y migraciones)
Elige el modelo sin el que la app no puede funcionar—a menudo la “cosa” que los usuarios crean o gestionan. Defínelo claramente (campos, obligatorios vs opcionales, por defecto), y añade migraciones si usas BD relacional. Mantén la primera versión simple: evita normalizaciones elegantes y flexibilidad prematura.
Si usas IA para redactar el modelo, pídele que justifique cada campo y valor por defecto. Si no lo explica en una frase, probablemente no pertenece a la v1.
Construye endpoints primarios con reglas de validación
Crea solo los endpoints necesarios para el primer recorrido de usuario: normalmente crear, leer y una actualización mínima. Coloca la validación cerca del límite (DTO/schema de la petición) y haz las reglas explícitas:
- Campos requeridos, formatos y rangos permitidos
- Comprobaciones de propiedad/permiso (“¿puede este usuario acceder a este registro?”)
- Formas de respuesta consistentes (éxito y fallo)
La validación es parte de la función, no un pulido—evita datos sucios que te ralenticen después.
Manejo de errores que ayude a humanos
Trata los mensajes de error como UX para debugging y soporte. Devuelve mensajes claros y accionables (qué falló y cómo arreglarlo) sin exponer detalles sensibles al cliente. Loggea el contexto técnico en el servidor con un request ID para poder trazar incidentes sin conjeturas.
Usa sugerencias de IA—y revisa cada cambio
Pide a la IA propuestas incrementales del tamaño de un PR: una migración + un endpoint + una prueba a la vez. Revisa diffs como revisarías el trabajo de un compañero: verifica nombres, casos límite, supuestos de seguridad y si el cambio realmente apoya la “pequeña victoria” del usuario. Si añade funciones extra, córtalas y sigue adelante.
Hazlo lo suficientemente seguro: validación, permisos y logging
Lanza la pila web clásica
Construye un frontend en React con backend en Go y PostgreSQL en un mismo flujo de trabajo.
La v1 no necesita seguridad de nivel empresarial—pero sí evitar fallos previsibles que conviertan una app prometedora en un problema de soporte. El objetivo aquí es “suficientemente seguro”: prevenir entrada malformada, restringir acceso por defecto y dejar un rastro útil cuando algo falle.
Validación de entrada + protección básica contra abuso
Trata cada límite como no confiable: campos de formularios, payloads de API, parámetros de consulta e incluso webhooks internos. Valida tipo, longitud y valores permitidos, y normaliza datos (trim, cambiar mayúsculas/minúsculas) antes de almacenar.
Unos valores por defecto prácticos:
- Validación server-side (siempre), aunque también valides en UI.
- Límites de tasa para login, restablecimiento de contraseña y endpoints costosos.
- Comprobaciones de subida de archivos: tamaño máximo, tipos MIME permitidos y escaneo antivirus si aceptas uploads públicos.
- Mensajes de error seguros: indica qué arreglar, pero no leaks con stack traces o identificadores internos.
Si pides a la IA handlers, pídele que incluya reglas de validación explícitas (p. ej., “máx 140 caracteres” o “debe ser uno de: …”) en lugar de “valida la entrada”.
Permisos: empieza pequeño, deniega por defecto
Un modelo simple suele bastar en v1:
- Anónimo: solo páginas públicas.
- Usuario autenticado: puede crear y ver sus propios datos.
- Owner/editor (opcional): puede editar registros compartidos.
Haz comprobaciones de propiedad centrales y reutilizables (middleware/funciones policy), para no esparcir if userId == … por todo el código.
Logging que te ayude a depurar rápido
Los buenos logs responden: ¿qué pasó, a quién y dónde? Incluye:
- Request ID (propágalo entre servicios)
- User ID (cuando haya auth)
- Acción + recurso (p. ej.,
update_project, project_id)
- Tiempos (duración para peticiones lentas)
Registra eventos, no secretos: nunca escribas contraseñas, tokens o datos de pago completos.
Checklist de “errores comunes” rápido
Antes de llamar a la app “suficientemente segura”, comprueba:
- Auth requerido en todas las rutas no públicas
- Chequeos de autorización (no solo autenticación)
- Límites de tasa en auth y endpoints de escritura
- Validación server-side en todas las entradas
- Secretos en env/secret manager (no en el repo)
- Logging consistente y no sensible con request IDs
Añade pruebas que protejan el camino feliz y los riesgos
Las pruebas no buscan una puntuación perfecta—protegen contra fallos que dañen usuarios, rompan confianza o generen costosos incidentes. En un flujo asistido por IA, las pruebas también actúan como “contrato” que mantiene el código generado alineado con lo que realmente querías.
Empieza por la lógica de mayor riesgo
Antes de aumentar la cobertura, identifica dónde los errores serían costosos. Áreas típicas: dinero/créditos, permisos, transformaciones de datos y validaciones de casos límite. Escribe tests unitarios para esas piezas primero. Manténlos pequeños y específicos: dado X, se espera Y (o un error). Si una función tiene demasiadas ramas para probar limpiamente, quizás deba simplificarse.
Añade una o dos pruebas de integración para el flujo principal
Los unit tests capturan bugs de lógica; las pruebas de integración capturan fallos de “cableado”: rutas, llamadas a BD, checks de auth y el flujo UI funcionando junto. Elige el recorrido central (camino feliz) y automatízalo de extremo a extremo:
- Crear cuenta / iniciar sesión
- Completar la acción principal de la app
- Confirmar que el resultado aparece donde el usuario espera (pantalla, email, panel)
Un par de pruebas de integración sólidas a menudo previenen más incidentes que docenas de tests pequeños.
Usa la IA para redactar tests—y hazlos significativos
La IA es buena creando andamiaje de tests y enumerando casos límite que podrías olvidar. Pide:
- casos límite (valores vacíos, longitudes máximas, zonas horarias)
- casos negativos (acceso no autorizado, estados inválidos)
- ejemplos de datos realistas (no solo “foo/bar”)
Luego revisa cada aserción generada. Las pruebas deben verificar comportamiento, no detalles de implementación. Si un test seguiría pasando tras un bug, no cumple su función.
Fija un objetivo de cobertura pequeño y apuesta a la fiabilidad
Elige una meta modesta (por ejemplo, 60–70% en módulos centrales) y úsala de guardarraíl, no de trofeo. Enfócate en pruebas estables y rápidas que se ejecuten en CI y fallen por las razones correctas. Las pruebas inestables erosionan la confianza—y cuando la gente deja de confiar en la suite, deja de protegerte.
Prepárate para la automatización: builds, CI y puertas de calidad
La automatización es donde un flujo asistido por IA deja de ser “funciona en mi portátil” y se convierte en algo que puedes publicar con confianza. El objetivo no es tooling sofisticado: es repetibilidad.
Empieza con un comando de build repetible
Escoge un comando que produzca el mismo resultado local y en CI. En Node, npm run build; en Python, make build; en móvil, un paso Gradle/Xcode concreto.
También separa pronto la configuración de desarrollo y producción. Regla simple: los valores por defecto dev son cómodos; los de producción son seguros.
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
Un linter detecta patrones de riesgo (variables sin usar, llamadas async inseguras). Un formateador evita “debates de estilo” en diffs de revisión. Mantén las reglas modestas para v1, pero hazlas cumplir consistentemente.
Un orden práctico de puertas:
- format → 2) lint → 3) tests → 4) build
Configura un CI básico: ejecutar tests en cada push
Tu primer workflow de CI puede ser pequeño: instalar dependencias, ejecutar las puertas y fallar rápido. Eso ya evita que código roto llegue silenciosamente.
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
Define el manejo de secretos (y haz que sea difícil equivocarse)
Decide dónde viven los secretos: store de secretos del CI, gestor de contraseñas o la configuración de entorno de tu plataforma de despliegue. Nunca los comites: añade .env a .gitignore e incluye .env.example con placeholders seguros.
Si quieres un siguiente paso claro, conecta estas puertas con tu proceso de despliegue, de modo que “CI en verde” sea la única vía a producción.
Despliega a producción con un proceso claro y reversible
Mantén la propiedad del código
Exporta tu código fuente en cualquier momento para mantener el control total de tu proyecto.
Publicar no es un botón único: es una rutina repetible. El objetivo para v1 es simple: elige un destino de despliegue que encaje con tu stack, despliega en pequeños incrementos y siempre ten una forma de regresar.
Escoge el destino de despliegue adecuado (no compres de más)
Elige una plataforma que encaje con cómo corre tu app:
- Sitio estático + API serverless: Vercel / Netlify
- App web basada en Docker: Render / Fly.io
- Necesidades de VM tradicionales: un VPS pequeño (solo si realmente lo necesitas)
Optimizar por “fácil de redeployar” suele superar optimizar por “control máximo” en esta etapa.
Si quieres minimizar cambios de herramienta, considera plataformas que integren build + hosting + rollback. Por ejemplo, Koder.ai soporta despliegue y hosting con snapshots y rollback, así que puedes tratar lanzamientos como pasos reversibles en lugar de puertas sin retorno.
Usa una checklist de despliegue cada vez
Escribe la checklist una vez y reutilízala en cada release. Manténla corta para que la gente la siga:
- Confirma variables de entorno y secretos
- Ejecuta migraciones de BD (o confirma que no hacen falta)
- Build y arranque en configuración de producción
- Ejecuta una prueba de humo del flujo principal
- Verifica que los logs fluyen y los errores son visibles
Si la guardas en el repo (por ejemplo en /docs/deploy.md), permanece cerca del código.
Añade
Añade checks de salud y un endpoint de estado
Crea un endpoint ligero que responda: “¿La app está arriba y puede alcanzar sus dependencias?” Patrones comunes:
GET /health para balanceadores y monitores de uptimeGET /status devolviendo versión de la app + checks de dependencias
Mantén respuestas rápidas, sin cache y seguras (no revelar secretos ni detalles internos).
Planea el rollback antes de necesitarlo
Un plan de rollback debe ser explícito:
- Cómo redeplegar la versión anterior (tag, release o imagen)
- Qué hacer con migraciones (compatibles hacia atrás primero; reversibles solo cuando sea necesario)
- Quién decide hacer rollback y qué señales lo desencadenan (tasa de error, checks de salud fallidos)
Cuando el despliegue es reversible, publicar se vuelve rutinario—y puedes lanzar más seguido con menos estrés.
Cierra el ciclo: monitoriza, aprende e itera en el mismo flujo
Lanzar es el inicio de la fase más valiosa: aprender qué hacen los usuarios reales, dónde falla la app y qué pequeños cambios mueven tu métrica de éxito. El objetivo es mantener el mismo flujo asistido por IA que usaste para construir—pero ahora apuntando a evidencia en vez de suposiciones.
Configura monitorización básica (uptime, errores, rendimiento)
Comienza con un stack mínimo que responda tres preguntas: ¿Está arriba? ¿Falla? ¿Está lenta?
Checks de uptime pueden ser simples (golpear periódicamente el endpoint de salud). El tracking de errores debe capturar stack traces y contexto de la petición (sin datos sensibles). El monitoreo de rendimiento puede empezar con tiempos de respuesta para endpoints clave y métricas de carga front-end.
Pide a la IA que genere:
- un formato de logging y IDs de correlación para poder seguir una acción de usuario end-to-end
- umbrales de alerta (inicialmente conservadores) y una checklist de primer paso para on-call
Añade analítica de producto ligada a la métrica de éxito
No rastrees todo—rastrea lo que demuestra que la app funciona. Define una métrica primaria (p. ej.: “checkout completado”, “primer proyecto creado” o “invitó a un compañero”). Luego instrumenta un pequeño embudo: entrada → acción clave → éxito.
Pide a la IA propuestas de nombres de eventos y propiedades, y revísalas por privacidad y claridad. Mantén los eventos estables; cambiar nombres cada semana hace que las tendencias pierdan sentido.
Convierte el feedback de usuarios en el plan de la siguiente iteración
Crea una entrada simple: botón de feedback in-app, un alias de email corto y una plantilla ligera de bug. Triage semanal: agrupa feedback por temas, conecta temas con analítica y decide 1–2 mejoras siguientes.
Mantén el flujo continuo post-lanzamiento
Trata alertas de monitorización, caídas en analítica y temas de feedback como nuevos “requisitos”. Introdúcelos en el mismo proceso: actualiza el doc, genera una pequeña propuesta de cambio, implementa en rebanadas finas, añade una prueba dirigida y despliega vía el mismo proceso reversible. Para equipos, una página compartida de “Registro de Aprendizajes” (link desde /blog o docs internos) mantiene las decisiones visibles y repetibles.