13 dic 2025·8 min
De startup de gráficos a titán de la IA: la historia de Nvidia
Explora el recorrido de Nvidia desde una startup de gráficos en 1993 hasta convertirse en una potencia global en IA: productos clave, avances, líderes y apuestas estratégicas.
Introducción: por qué importa la historia de Nvidia
Nvidia se ha convertido en un nombre conocido por motivos muy distintos, según a quién preguntes. Los jugadores de PC piensan en las tarjetas GeForce y en tasas de frames suaves. Los investigadores en IA piensan en GPUs que entrenan modelos punteros en días en lugar de meses. Los inversores ven una de las compañías de semiconductores más valiosas de la historia, una acción que se convirtió en un proxy para todo el auge de la IA.
Sin embargo, esto no era inevitable. Cuando Nvidia se fundó en 1993, era una pequeña startup que apostaba por una idea de nicho: que los chips gráficos transformarían la informática personal. A lo largo de tres décadas, evolucionó de fabricante de tarjetas gráficas a proveedor central de hardware y software para la IA moderna, alimentando desde sistemas de recomendación y prototipos de conducción autónoma hasta gigantescos modelos de lenguaje.
Por qué importa esta historia
Entender la historia de Nvidia es una de las vías más claras para comprender el hardware moderno de IA y los modelos de negocio que se están formando alrededor. La compañía se sitúa en la intersección de varias fuerzas:
- La evolución de la computación GPU, desde gráficos de función fija hasta procesadores masivamente paralelos.
- El auge de CUDA como plataforma de programación, no solo como característica de chip.
- El desplazamiento del gaming de consumo hacia la nube y los centros de datos como principal motor de crecimiento.
En el camino, Nvidia ha hecho repetidamente apuestas de alto riesgo: apostar por GPUs programables antes de que existiera un mercado claro, construir una pila completa de software para deep learning y gastar miles de millones en adquisiciones como Mellanox para controlar más del centro de datos.
Qué cubrirá este artículo
Este artículo traza el recorrido de Nvidia desde 1993 hasta hoy, centrado en:
- Cómo Jensen Huang y sus cofundadores convirtieron una idea gráfica en una compañía plataforma.
- Hitos de producto clave: RIVA, GeForce, CUDA y la era de la GPU para centros de datos.
- El avance del deep learning que desbloqueó el dominio de Nvidia en IA.
- Estrategia, competencia con AMD y otros, y adquisiciones importantes.
- Transformación financiera: de fabricante de chips de nicho a gigante del mercado.
- Qué sugiere el pasado de Nvidia sobre el futuro de la IA y el papel de la compañía en él.
El artículo está escrito para lectores de tecnología, negocio e inversión que quieran una visión narrativa clara de cómo Nvidia se convirtió en un titán de la IA —y qué podría venir después.
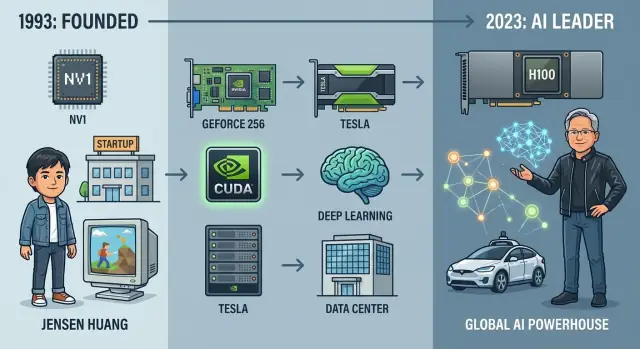
Fundación de Nvidia: de idea a startup
En 1993, tres ingenieros con personalidades diferentes pero la convicción compartida sobre gráficos 3D fundaron Nvidia alrededor de una mesa en un Denny’s en Silicon Valley. Jensen Huang, ingeniero taiwanés‑estadounidense y exdiseñador de chips en LSI Logic, aportó gran ambición y talento para contar la historia ante clientes e inversores. Chris Malachowsky venía de Sun Microsystems con experiencia en estaciones de trabajo de alto rendimiento. Curtis Priem, antes en IBM y Sun, era el arquitecto de sistemas obsesionado por cómo encajaban hardware y software.
Silicon Valley a principios de los 90
La zona por entonces giraba alrededor de estaciones de trabajo, minicomputadoras y fabricantes emergentes de PC. Los gráficos 3D eran potentes pero caros, ligados sobre todo a Silicon Graphics (SGI) y otros proveedores de estaciones de trabajo para CAD, cine y visualización científica.
Huang y sus cofundadores vieron una oportunidad: llevar ese tipo de potencia visual a PCs asequibles. Si millones de personas pudieran obtener gráficos 3D de alta calidad para juegos y multimedia, el mercado sería mucho mayor que el mundo nicho de las estaciones de trabajo.
La visión original: gráficos acelerados para todos
La idea fundacional de Nvidia no era ser un fabricante de semiconductores genérico; era gráficos acelerados para el mercado masivo. En vez de que las CPUs lo hicieran todo, un procesador gráfico especializado manejaría las matemáticas pesadas de renderizar escenas 3D.
El equipo creía que esto requería:
- Una arquitectura gráfica dedicada que pudiera evolucionar más rápido que las hojas de ruta de las CPUs.
- Un acoplamiento estrecho entre hardware y software (drivers, APIs, herramientas para desarrolladores).
- Reducción de costes implacable para que los OEM adoptaran la solución a escala.
Primeros fondos, casi fracasos y supervivencia a la fuerza
Huang obtuvo capital inicial de firmas de riesgo como Sequoia, pero el dinero nunca sobró. El primer chip, NV1, era ambicioso pero no iba alineado con el estándar emergente DirectX y las APIs de juego dominantes. Se vendió poco y casi mata a la compañía.
Nvidia sobrevivió pivotando rápidamente hacia NV3 (RIVA 128), reposicionando la arquitectura en torno a estándares industriales y aprendiendo a trabajar mucho más estrechamente con desarrolladores de juegos y Microsoft. La lección: la tecnología por sí sola no bastaba; la alineación con el ecosistema determinaría la supervivencia.
Cultura: velocidad, profundidad de ingeniería y frugalidad
Desde el principio, Nvidia cultivó una cultura donde los ingenieros tenían una influencia desproporcionada y el tiempo hasta el mercado se trataba como algo existencial. Los equipos se movían rápido, iteraban diseños con agresividad y aceptaban que algunas apuestas fallarían.
Las limitaciones de caja fomentaron la frugalidad: muebles de oficina reutilizados, largas jornadas y una preferencia por contratar a pocos ingenieros altamente capaces en lugar de formar equipos grandes y jerárquicos. Esa cultura temprana —intensidad técnica, urgencia y gasto prudente— moldearía cómo Nvidia atacó oportunidades mucho mayores más adelante, más allá de los gráficos de PC.
La primera revolución gráfica: RIVA, GeForce y el gaming en PC
Gráficos en PC antes del ascenso de Nvidia
A principios y mediados de los 90, los gráficos en PC eran básicos y fragmentados. Muchos juegos aún dependían del renderizado por software, con la CPU haciendo la mayor parte del trabajo. Existían aceleradores 2D dedicados para Windows, y tarjetas 3D de la vieja guardia como la Voodoo de 3dfx ayudaban a los juegos, pero no había una forma estándar de programar hardware 3D. APIs como Direct3D y OpenGL todavía maduraban, y los desarrolladores a menudo tenían que dirigirse a tarjetas específicas.
Ese era el entorno en el que entró Nvidia: rápido, desordenado y lleno de oportunidades para cualquiera que pudiera combinar rendimiento con un modelo de programación limpio.
NV1: un traspié ambicioso
El primer producto importante de Nvidia, el NV1, salió en 1995. Intentó hacerlo todo a la vez: 2D, 3D, audio e incluso soporte para el gamepad de Sega Saturn en una sola tarjeta. Técnicamente, se centraba en superficies cuadráticas en lugar de triángulos, justo cuando Microsoft y la industria estaban estandarizando APIs 3D alrededor de polígonos triangulares.
El desajuste con DirectX y el soporte de software limitado hicieron del NV1 un fracaso comercial. Pero enseñó a Nvidia dos lecciones cruciales: seguir la API dominante (DirectX) y concentrarse en rendimiento 3D más que en características exóticas.
RIVA 128 y TNT: ganando credibilidad
Nvidia se reagrupó con la RIVA 128 en 1997. Adoptó triángulos y Direct3D, ofreció buen rendimiento 3D e integró 2D y 3D en una sola tarjeta. Los críticos lo notaron y los OEM comenzaron a ver a Nvidia como un socio serio.
RIVA TNT y TNT2 refinaron la fórmula: mejor calidad de imagen, mayores resoluciones y drivers mejorados. Aunque 3dfx seguía mandando en reconocimiento, Nvidia redujo la distancia rápido al enviar actualizaciones frecuentes de controladores y cortejar a los desarrolladores de juegos.
GeForce 256 y el nacimiento de la GPU
En 1999, Nvidia introdujo la GeForce 256 y la presentó como la “primera GPU del mundo” —una Graphics Processing Unit. Esto fue más que marketing. GeForce 256 integró transformaciones y iluminación por hardware (T&L), descargando cálculos de geometría de la CPU hacia el chip gráfico.
Este cambio liberó a las CPUs para lógica de juego y física, mientras la GPU manejaba escenas 3D cada vez más complejas. Los juegos pudieron dibujar más polígonos, usar iluminación más realista y correr con más fluidez a resoluciones más altas.
Aprovechando el boom del gaming con asociaciones OEM
Al mismo tiempo, el gaming en PC explotaba, impulsado por títulos como Quake III Arena y Unreal Tournament, y por la rápida adopción de Windows y DirectX. Nvidia se alineó estrechamente con ese crecimiento.
La compañía aseguró acuerdos de diseño con OEMs importantes como Dell y Compaq, asegurando que millones de PCs de consumo salieran con gráficos Nvidia por defecto. Programas de marketing conjunto con estudios de juego y la marca “The Way It’s Meant to Be Played” reforzaron la imagen de Nvidia como la elección predeterminada para jugadores serios.
A comienzos de los 2000, Nvidia había pasado de ser una startup con un producto inicial desalineado a una fuerza dominante en gráficos de PC, preparando el terreno para todo lo que vendría en computación GPU y, eventualmente, en IA.
Apostando por la programabilidad: CUDA y la computación GPU
Al principio, las GPUs eran máquinas de función fija: canalizaciones cableadas que tomaban vértices y texturas y escupían píxeles. Eran increíblemente rápidas, pero casi completamente inflexibles.
De la función fija a los shaders programables
A principios de los 2000, los shaders programables (Vertex y Pixel/Fragment Shaders en DirectX y OpenGL) cambiaron esa fórmula. Con chips como la GeForce 3 y más tarde la GeForce FX y la GeForce 6, Nvidia empezó a exponer pequeñas unidades programables que permitían a los desarrolladores escribir efectos personalizados en lugar de depender de una pipeline rígida.
Estos shaders todavía iban dirigidos a gráficos, pero plantaron una idea crucial dentro de Nvidia: si una GPU podía programarse para muchos efectos visuales, ¿por qué no para cómputo en general?
La apuesta radical: CUDA y la computación GPU de propósito general
La computación GPU de propósito general (GPGPU) era una apuesta contraria. Internamente, muchos cuestionaban si tenía sentido gastar presupuesto de transistores, tiempo de ingeniería y esfuerzo en software en cargas fuera del gaming. Externamente, los escépticos descartaban las GPUs como juguetes para gráficos, y los primeros experimentos GPGPU (hackear álgebra lineal en fragment shaders) eran notoriamente dolorosos.
La respuesta de Nvidia fue CUDA, anunciada en 2006: un modelo de programación tipo C/C++, con runtime y toolchain diseñado para hacer sentir a la GPU como un coprocesador masivamente paralelo. En vez de forzar a los científicos a pensar en términos de triángulos y píxeles, CUDA expuso hilos, bloques, grillas y jerarquías de memoria explícitas.
Fue un riesgo estratégico enorme: Nvidia tuvo que construir compiladores, depuradores, bibliotecas, documentación y programas de formación —inversiones de software más propias de una compañía plataforma que de un simple proveedor de chips.
Primeros casos de uso no gráficos
Las primeras victorias vinieron de la computación de alto rendimiento (HPC):
- Dinámica molecular y química computacional.
- Álgebra lineal y solucionadores numéricos.
- Valoración de opciones, simulaciones de riesgo y otras cargas financieras cuantitativas.
- Imagen sísmica y procesamiento de señales.
Investigadores pudieron ejecutar simulaciones de semanas en días u horas, a menudo en una sola GPU de estación de trabajo en lugar de en un clúster completo de CPUs.
Sembrando un ecosistema de desarrolladores
CUDA no solo aceleró código; creó un ecosistema de desarrolladores alrededor del hardware de Nvidia. La compañía invirtió en SDKs, bibliotecas matemáticas (como cuBLAS y cuFFT), programas universitarios y su propia conferencia (GTC) para enseñar programación paralela en GPUs.
Cada aplicación y librería CUDA profundizó el foso: los desarrolladores optimizaban para GPUs Nvidia, las toolchains maduraban alrededor de CUDA y nuevos proyectos empezaban con Nvidia como el acelerador por defecto. Mucho antes de que el entrenamiento de IA llenara centros de datos de GPUs, este ecosistema ya había convertido la programabilidad en uno de los activos estratégicos más poderosos de Nvidia.
Del gaming a los centros de datos: construyendo un nuevo negocio
Ver más allá de los gráficos para PC
A mediados de los 2000, el negocio gaming de Nvidia prosperaba, pero Jensen Huang y su equipo vieron un límite en depender únicamente de GPUs de consumo. La misma potencia de procesamiento paralelo que hacía los juegos más fluidos podía también acelerar simulaciones científicas, finanzas y, eventualmente, IA.
Nvidia empezó a posicionar las GPUs como aceleradores de propósito general para estaciones de trabajo y servidores. Las tarjetas profesionales para diseñadores e ingenieros (línea Quadro) fueron un primer paso, pero la apuesta mayor era entrar directamente en el corazón del centro de datos.
Tesla: GPUs para servidores y supercomputadoras
En 2007 Nvidia presentó la línea Tesla, sus primeras GPUs diseñadas específicamente para high‑performance computing (HPC) y cargas de servidor más que para pantallas.
Las placas Tesla priorizaban rendimiento en doble precisión, memoria con corrección de errores y eficiencia energética en racks densos —características que a los centros de datos y laboratorios de supercomputación les importaban mucho más que los frames por segundo.
HPC y laboratorios nacionales se convirtieron en adoptantes tempranos. Sistemas como la supercomputadora “Titan” en Oak Ridge demostraron que clústeres de GPUs programables con CUDA podían ofrecer enormes aceleraciones para física, modelado climático y dinámica molecular. Esa credibilidad en HPC ayudaría más tarde a convencer a empresas y proveedores cloud de que las GPUs eran infraestructura seria, no solo hardware de juegos.
Investigación, nube y una nueva mezcla de ingresos
Nvidia invirtió fuertemente en relaciones con universidades e institutos de investigación, proveyendo hardware y herramientas CUDA. Muchos de los investigadores que experimentaron con computación GPU en el ámbito académico luego impulsaron la adopción dentro de empresas y startups.
Al mismo tiempo, los primeros proveedores cloud empezaron a ofrecer instancias con GPUs Nvidia, convirtiendo las GPUs en un recurso on‑demand. Amazon Web Services, seguida por Microsoft Azure y Google Cloud, pusieron GPUs tipo Tesla al alcance de cualquiera con una tarjeta de crédito, lo que fue vital para el deep learning en GPUs.
A medida que creció el mercado de centros de datos y profesional, la base de ingresos de Nvidia se amplió. El gaming siguió siendo un pilar, pero nuevos segmentos —HPC, IA empresarial y nube— evolucionaron hasta convertirse en un segundo motor de crecimiento, sentando la base económica para el posterior dominio de Nvidia en IA.
El avance del deep learning: cuando la IA se encuentra con las GPUs
Publica una guía interactiva
Convierte esta historia en un sitio explicativo interactivo con secciones, gráficos y preguntas frecuentes.
El punto de inflexión llegó en 2012, cuando una red neuronal llamada AlexNet dejó alucinada a la comunidad de visión por computador al dominar el benchmark ImageNet. Crucialmente, se entrenó en un par de GPUs Nvidia. Lo que había sido una idea de nicho —entrenar redes neuronales grandes con chips gráficos— empezó a verse como el futuro de la IA.
Por qué las GPUs eran perfectas para deep learning
Las redes neuronales profundas están construidas a partir de un gran número de operaciones idénticas: multiplicaciones de matrices y convoluciones aplicadas sobre millones de pesos y activaciones. Las GPUs fueron diseñadas para ejecutar miles de hilos simples y paralelos para sombreado gráfico. Esa misma paralelidad encajó casi perfectamente con las redes neuronales.
En vez de renderizar píxeles, las GPUs podían procesar neuronas. Cargas de trabajo intensivas en cómputo que en CPUs serían lentas se aceleraron órdenes de magnitud en GPUs. Los tiempos de entrenamiento que antes tomaban semanas bajaron a días u horas, permitiendo a los investigadores iterar y escalar modelos.
De hardware bruto a una pila de IA
Nvidia actuó rápido para convertir esa curiosidad de investigación en una plataforma. CUDA ya ofrecía a los desarrolladores una forma de programar GPUs, pero el deep learning necesitaba herramientas de más alto nivel.
Nvidia desarrolló cuDNN, una biblioteca optimizada para GPU con primitivas de redes neuronales —convoluciones, pooling, funciones de activación. Frameworks como Caffe, Theano, Torch y después TensorFlow y PyTorch integraron cuDNN, de modo que los investigadores podían obtener aceleración GPU sin afinar kernels a mano.
Al mismo tiempo, Nvidia ajustó su hardware: añadió soporte de precisión mixta, memoria de alto ancho de banda y luego Tensor Cores en las arquitecturas Volta y posteriores, diseñados específicamente para el álgebra matricial del deep learning.
Asociaciones, DGX y GPUs pensadas para IA
Nvidia cultivó relaciones cercanas con laboratorios e investigadores de primer nivel en la Universidad de Toronto, Stanford, Google, Facebook y startups tempranas como DeepMind. La compañía ofrecía hardware temprano, ayuda de ingeniería y drivers personalizados, y a cambio recibía retroalimentación directa sobre lo que las cargas de IA necesitaban.
Para facilitar la supercomputación de IA, Nvidia introdujo sistemas DGX —servidores AI preintegrados con GPUs de gama alta, interconexiones rápidas y software afinado. DGX‑1 y sus sucesores se convirtieron en el aparato predeterminado para muchos laboratorios y empresas que construían capacidades serias de deep learning.
Con GPUs como Tesla K80, P100, V100 y finalmente A100 y H100, Nvidia dejó de ser una “compañía de gaming que también hacía cómputo” y se convirtió en el motor por defecto para entrenar y servir modelos de deep learning de vanguardia. El momento AlexNet abrió una nueva era, y Nvidia se posicionó en su centro.
Construyendo la plataforma y el ecosistema de IA de Nvidia
Nvidia no ganó la IA vendiendo solo chips más rápidos. Construyó una plataforma de extremo a extremo que facilita mucho más construir, desplegar y escalar IA en hardware Nvidia que en cualquier otro lugar.
CUDA en el núcleo
La base es CUDA, el modelo de programación paralelo de Nvidia introducido en 2006. CUDA permite a los desarrolladores tratar la GPU como un acelerador de propósito general, con toolchains familiares en C/C++ y Python.
Sobre CUDA, Nvidia apila bibliotecas y SDKs especializados:
- Math & HPC: cuBLAS, cuSPARSE, cuFFT para rutinas numéricas núcleo.
- IA & deep learning: cuDNN para redes neuronales, TensorRT para optimización de inferencia, Triton Inference Server para servir modelos.
- Datos & analítica: RAPIDS para ciencia de datos acelerada por GPU, cuGraph para analítica de grafos.
Esta pila hace que un investigador o ingeniero rara vez escriba código GPU de bajo nivel; llaman a bibliotecas Nvidia afinadas para cada generación de GPU.
Fosos de software y bloqueo de desarrolladores
Años de inversión en tooling, documentación y formación en CUDA crearon un foso poderoso. Millones de líneas de código en producción, proyectos académicos y frameworks open source están optimizados para GPUs Nvidia.
Migrar a una arquitectura rival suele implicar reescribir kernels, revalidar modelos y formar a ingenieros. Ese coste de cambio mantiene anclados a desarrolladores, startups y grandes empresas a Nvidia.
Servir a proveedores cloud y empresas
Nvidia trabaja estrechamente con nubes hiperescalas, proporcionando plataformas de referencia HGX y DGX, drivers y pilas de software afinadas para que los clientes puedan alquilar GPUs con mínima fricción.
La suite Nvidia AI Enterprise, el catálogo de software NGC y modelos preentrenados ofrecen a las empresas un camino soportado desde piloto a producción, ya sea on‑premises o en la nube.
Pilas verticales de IA
Nvidia extiende su plataforma hacia soluciones verticales completas:
- Conducción autónoma con Nvidia Drive (hardware, percepción, mapeo, simulación y herramientas de software).
- Salud con Nvidia Clara para imagen médica, genómica y aprendizaje federado.
- Robótica con Nvidia Isaac para simulación, percepción y control.
- Gemelos digitales y simulación industrial con Nvidia Omniverse y pilas de simulación relacionadas.
Estas plataformas verticales agrupan GPUs, SDKs, aplicaciones de referencia e integraciones con partners, ofreciendo a los clientes soluciones casi llave en mano.
Ecosistema como multiplicador de fuerza
Al nutrir ISVs, partners cloud, laboratorios de investigación y sistemas integradores alrededor de su stack de software, Nvidia convirtió las GPUs en el hardware por defecto para IA.
Cada framework nuevo optimizado para CUDA, cada startup que lanza en Nvidia y cada servicio cloud afinado para sus GPUs refuerzan un ciclo de realimentación: más software en Nvidia atrae más usuarios, lo que justifica más inversión y amplía la brecha con los competidores.
Apuestas estratégicas, adquisiciones y expansión más allá de las GPUs
Crea una app móvil complementaria
Crea una app móvil en Flutter que resuma la historia de las GPU y los hitos clave de la IA.
El ascenso de Nvidia al dominio en IA tiene tanto que ver con apuestas estratégicas más allá de la GPU como con los chips en sí.
Mellanox y el rompecabezas de la red
La adquisición de Mellanox en 2019 fue un punto de inflexión. Mellanox aportó InfiniBand y Ethernet de alto nivel, además de experiencia en interconexiones de baja latencia y alto rendimiento.
Entrenar modelos grandes depende de arreglar miles de GPUs como un solo ordenador lógico. Sin redes rápidas, esas GPUs idlean esperando datos o sincronización de gradientes. Mellanox dio a Nvidia control crítico sobre esa tela de comunicación.
El trato de Arm que no se concretó
En 2020 Nvidia anunció su intención de adquirir Arm, buscando combinar su experiencia en aceleración de IA con una arquitectura de CPU ampliamente licenciada usada en móviles, dispositivos embebidos y cada vez más en servidores.
Reguladores en EE. UU., Reino Unido, UE y China plantearon fuertes inquietudes antimonopolio: Arm es un proveedor de IP neutral para muchos rivales de Nvidia y la consolidación amenazaba esa neutralidad. Tras un largo escrutinio e impugnaciones de la industria, Nvidia abandonó el acuerdo en 2022.
Incluso sin Arm, Nvidia siguió adelante con su propio CPU Grace, demostrando que aún pretende modelar el nodo completo de centro de datos, no solo la tarjeta aceleradora.
Omniverse, automoción y IA en el edge
Omniverse lleva a Nvidia hacia la simulación, los gemelos digitales y la colaboración 3D. Conecta herramientas y datos alrededor de OpenUSD, permitiendo a empresas simular fábricas, ciudades y robots antes de desplegarlos en el mundo físico. Omniverse es a la vez una carga pesada de GPU y una plataforma de software que ata a los desarrolladores.
En automoción, la plataforma DRIVE apunta a la computación centralizada dentro del coche, conducción autónoma y asistencia avanzada al conductor. Ofreciendo hardware, SDKs y herramientas de validación a fabricantes y suministradores, Nvidia se incrusta en ciclos de producto largos y genera ingresos recurrentes por software.
En el edge, los módulos Jetson y pilas de software relacionadas impulsan robótica, cámaras inteligentes y IA industrial. Estos productos llevan la plataforma de Nvidia a retail, logística, salud y ciudades, capturando cargas de trabajo que no pueden vivir solo en la nube.
De vendedor de chips a compañía de pila completa
Con Mellanox y la conectividad, jugadas instructivas como la fallida compra de Arm, y expansiones en Omniverse, automoción y edge, Nvidia se ha movido deliberadamente más allá de ser un “vendedor de GPUs”.
Ahora vende:
- Chips (GPUs, DPUs y CPUs como Grace).
- Sistemas (DGX, HGX, arquitecturas de referencia).
- Software cloud y empresarial (CUDA, frameworks de IA, Omniverse, SDKs verticales).
- Plataformas de extremo a extremo para industrias como automoción, robótica y gemelos digitales.
Estas apuestas hacen que Nvidia sea más difícil de desplazar: los competidores deben igualar no solo un chip, sino una pila integrada que abarca cómputo, red, software y soluciones específicas de dominio.
Competencia, regulación y vientos geopolíticos
El ascenso de Nvidia ha atraído rivales poderosos, reguladores más exigentes y nuevos riesgos geopolíticos que condicionan cada movimiento estratégico de la compañía.
El escenario competitivo: AMD, Intel y startups de IA
AMD sigue siendo el par más cercano de Nvidia en GPUs, compitiendo a menudo cabeza a cabeza en gaming y aceleradores para data center. La serie MI de AMD apunta a los mismos clientes cloud e hiperescalas que Nvidia sirve con sus H100 y sucesores.
Intel ataca por varios flancos: CPUs x86 que aún dominan servidores, sus propias GPUs discretas y aceleradores dedicados para IA. Al mismo tiempo, hiperescaladores como Google (TPU), Amazon (Trainium/Inferentia) y una ola de startups (Graphcore, Cerebras) diseñan chips propios para reducir dependencia de Nvidia.
La defensa principal de Nvidia sigue siendo la combinación de liderazgo en rendimiento y software. CUDA, cuDNN, TensorRT y una profunda pila de SDKs y librerías atan a desarrolladores y empresas. Sólo el hardware no basta; portar modelos y herramientas fuera del ecosistema Nvidia implica costes reales de migración.
Regulación, controles de exportación y escrutinio antimonopolio
Los gobiernos tratan ahora a las GPUs avanzadas como activos estratégicos. Los controles de exportación de EE. UU. han limitado reiteradamente el envío de chips de IA de alta gama a China y otras regiones sensibles, obligando a Nvidia a diseñar variantes compatibles con exportación y recortadas en rendimiento. Estos controles protegen la seguridad nacional pero restringen el acceso a un mercado importante.
Los reguladores también observan el poder de mercado de Nvidia. La cancelación de la adquisición de Arm puso de manifiesto preocupaciones sobre permitir que Nvidia controlara IP de chips fundamentales. A medida que crece su cuota en aceleradores de IA, reguladores en EE. UU., UE y otros lugares están más dispuestos a examinar exclusividades, empaquetado y posible discriminación en el acceso a hardware y software.
Cadena de suministro, foundries y geopolítica
Nvidia es fabless y depende en gran medida de TSMC para la fabricación de vanguardia. Cualquier perturbación en Taiwán —por desastres naturales, tensiones políticas o conflicto— golpearía directamente la capacidad de Nvidia para suministrar GPUs de primera línea.
Los cuellos de botella en capacidad de empaquetado avanzado (CoWoS, integración de HBM) ya generan restricciones de suministro, dando a Nvidia menos flexibilidad para responder a picos de demanda. La compañía debe negociar capacidad, navegar fricciones tecnológicas EE. UU.–China y cubrirse frente a reglas de exportación que pueden cambiar más rápido que las hojas de ruta de semiconductores.
Equilibrar estas presiones mientras se mantiene la ventaja tecnológica es hoy tanto una tarea geopolítica y regulatoria como un desafío de ingeniería.
Liderazgo, cultura y cómo opera Nvidia
Estilo de liderazgo de Jensen Huang
Jensen Huang es un CEO fundador que aún actúa como ingeniero práctico. Participa en revisión de producto, sesiones técnicas y pizarra blancas, no solo en llamadas con inversores.
Su persona pública mezcla espectáculo y claridad. Las presentaciones con chaqueta de cuero son deliberadas: usa metáforas simples para explicar arquitecturas complejas, posicionando a Nvidia como una compañía que entiende tanto la física como el negocio. Internamente, es conocido por su feedback directo, altas expectativas y disposición a tomar decisiones incómodas cuando la tecnología o el mercado cambian.
Cultura: ingeniería, iteración y grandes apuestas
La cultura de Nvidia gira en torno a temas recurrentes:
- Excelencia en ingeniería: equipos de silicio, software y sistemas empujan objetivos agresivos de rendimiento y consumo. El fracaso se tolera solo si se captura aprendizaje para la siguiente iteración.
- Iteración rápida: arquitecturas GPU, lanzamientos de CUDA y SDKs evolucionan rápido. Los equipos envían, miden y refinan en lugar de esperar diseños perfectos.
- Tomar riesgos audaces: CUDA, GPUs para centros de datos y las primeras inversiones en IA fueron apuestas contrarias en su momento.
Esta mezcla crea una cultura donde coexisten ciclos largos (diseño de chips) con bucles rápidos (software e investigación), y donde hardware, software e investigación deben colaborar estrechamente.
Balancear visión a largo plazo con la realidad trimestral
Nvidia invierte en plataformas plurianuales —nuevas arquitecturas GPU, interconexiones, CUDA— mientras gestiona expectativas trimestrales.
Organizativamente, ello implica:
- Las hojas de ruta núcleo (arquitectura, nodos de proceso, interconexiones) se tratan como compromisos inalterables.
- Ajustes a corto plazo giran alrededor de mezcla de producto, precios y enfoque go‑to‑market, no de la dirección tecnológica central.
Huang a menudo encuadra las discusiones de resultados en tendencias seculares (IA, cómputo acelerado) para alinear a inversores con el horizonte temporal de la compañía, incluso cuando la demanda a corto plazo fluctúa.
Relaciones con desarrolladores y ecosistemas de partners
Nvidia trata a los desarrolladores como clientes primarios. CUDA, cuDNN, TensorRT y docenas de SDKs de dominio se respaldan con:
- Documentación extensa y código de ejemplo.
- Soporte directo a laboratorios clave, proveedores cloud y empresas.
- Programas que ayudan a startups a optimizar y escalar en plataformas Nvidia.
Los socios —OEMs, proveedores cloud, integradores de sistemas— se cultivan con diseños de referencia, marketing conjunto y acceso temprano a hojas de ruta. Este ecosistema cerrado hace que la plataforma de Nvidia sea pegajosa y difícil de desplazar.
Cambios culturales conforme Nvidia escaló
Al crecer de vendedor de tarjetas gráficas a compañía global de plataformas de IA, la cultura de Nvidia evolucionó:
- De foco mayoritariamente en gaming a multi‑vertical (investigación, nube, automoción, salud).
- De una organización centrada en EE. UU. a una distribución global, con mayor atención a regulación, seguridad y geopolítica.
- De centrarse en productos a centrarse en plataformas, integrando redes, pilas de software y servicios junto a las GPUs.
A pesar de la escala, Nvidia ha intentado preservar una mentalidad liderada por el fundador y orientada a la ingeniería, donde se fomentan apuestas técnicas ambiciosas y los equipos deben moverse rápido en busca de avances.
De fabricante de chips de nicho a gigante del mercado: la historia financiera
Pon tu app en un dominio
Crea un sitio sencillo para tu proyecto de IA y publícalo en tu propio dominio personalizado.
La trayectoria financiera de Nvidia es de las más dramáticas en tecnología: de un proveedor modesto de gráficos para PC a una compañía multimillonaria en el centro del boom de la IA.
De small‑cap al club del billón de dólares
Tras su IPO en 1999, Nvidia pasó años valorada en decenas de miles de millones, vinculada mayormente a mercados cíclicos de PC y gaming. Durante los 2000s, los ingresos crecieron hasta los miles de millones, pero la compañía aún se veía como un proveedor de chips especializado, no como un líder de plataforma.
La inflexión llegó a mediados de los 2010s cuando los ingresos por centro de datos e IA comenzaron a crecer de forma compuesta. Hacia 2017 la capitalización cruzó los $100 mil millones; en 2021 fue una de las compañías de semiconductores más valiosas del mundo. En 2023 llegó brevemente al club del billón de dólares, y para 2024 cotizaba frecuentemente por encima de esa cifra, reflejando la convicción inversora de que Nvidia era infraestructura central para la IA.
Cambio en la mezcla de ingresos: de gaming a centro de datos
Durante gran parte de su historia, las GPUs para gaming fueron el negocio principal. Gráficos de consumo, más visualización profesional y tarjetas de estación de trabajo impulsaban la mayor parte de ingresos y beneficios.
Esa mezcla se invirtió con la explosión de la IA y el cómputo acelerado en la nube:
- Gaming sigue siendo un negocio de miles de millones, sostenido por GeForce, portátiles para juego y software asociado.
- Centro de datos se convirtió en el motor de crecimiento, impulsado por entrenamiento/inferencia en hiperescalas y clústeres empresariales. Para el año fiscal 2024, el centro de datos aportó la mayoría de los ingresos, eclipsando al gaming.
- Visualización profesional, automoción y edge son flujos menores hoy, pero estratégicamente importantes para diversificar la demanda del consumidor.
La economía del hardware AI transformó el perfil financiero de Nvidia. Plataformas aceleradoras de alta gama, junto con networking y software, tienen precios premium y elevados márgenes brutos. Con el auge del centro de datos, los márgenes globales se expandieron, convirtiendo a Nvidia en una máquina de generación de caja con apalancamiento operativo extraordinario.
IA, márgenes y recalificación del mercado
La demanda por IA no solo añadió una línea de producto; redefinió cómo los inversores valoran a Nvidia. La compañía pasó de ser modelada como un semiconductores cíclico a ser tratada más como infraestructura crítica y plataforma de software.
Los márgenes brutos, soportados por aceleradores AI y software de plataforma, subieron con fuerza. Con costes fijos que escalan mucho más lentamente que los ingresos, los márgenes marginales del crecimiento en IA han sido extremadamente altos, impulsando una aceleración notable en las ganancias por acción. Esto provocó varias rondas de revisiones al alza por parte de analistas y un repricing de la acción.
Splits, rallies y volatilidad
La historia del precio de la acción de Nvidia está marcada por rallies espectaculares y retrocesos pronunciados.
La compañía realizó varias divisiones de acciones para mantener el precio por acción accesible: múltiples 2‑por‑1 en los 2000s, un 4‑por‑1 en 2021 y un 10‑por‑1 en 2024. Los accionistas a largo plazo que mantuvieron las posiciones han visto rendimientos compuestos extraordinarios.
La volatilidad también ha sido notable. La acción sufrió retrocesos profundos durante:
- Caídas en el mercado de PC y GPUs.
- La crisis financiera de 2008.
- El desplome posterior a la minería de criptomonedas en 2018–2019.
- La venta masiva tecnológica y de semiconductores en 2022.
Cada vez, las preocupaciones sobre la ciclicidad o correcciones de demanda golpearon las acciones. Sin embargo, el boom de la IA volvió a llevar a Nvidia a máximos cuando las expectativas se reajustaron.
Cómo ven los inversores el riesgo y el potencial a largo plazo
Pese al éxito, Nvidia no se considera libre de riesgo. Los inversores debaten varios puntos clave:
- Ciclicidad y concentración: Nvidia está muy expuesta a ciclos de gasto de capital de un pequeño número de clientes hiperescaladores. Una pausa o cambio en ese gasto podría impactar resultados.
- Competencia e chips internos: AMD, aceleradores especializados y chips diseñados internamente por proveedores cloud son amenazas potenciales a la cuota y a la capacidad de fijación de precios de Nvidia.
- Regulación y geopolítica: controles de exportación a China y tensiones en cadenas de suministro introducen riesgo político.
- Sostenibilidad de la inversión en IA: algunos inversores temen una burbuja donde la demanda de hardware se sobreexpanda respecto al uso real a largo plazo.
Al mismo tiempo, el caso alcista a largo plazo es que el cómputo acelerado y la IA se conviertan en estándar across data centers, empresas y edge por décadas. En esa visión, la combinación de GPUs, redes, software y bloqueo de ecosistema de Nvidia podría justificar años de alto crecimiento y márgenes fuertes, apoyando su transición de fabricante de chips de nicho a gigante perdurable del mercado.
El futuro de Nvidia y la próxima era de la IA
El siguiente capítulo de Nvidia trata de convertir las GPUs de herramienta de entrenamiento en la tela subyacente de sistemas inteligentes: IA generativa, máquinas autónomas y mundos simulados.
Dónde apuesta Nvidia ahora
La IA generativa es el foco inmediato. Nvidia quiere que cada modelo importante —texto, imagen, video, código— se entrene, ajuste fino y sirva en su plataforma. Eso requiere GPUs de centro de datos más potentes, redes más rápidas y pilas de software que faciliten a las empresas construir copilotos personalizados y modelos de dominio.
Más allá de la nube, Nvidia empuja sistemas autónomos: coches autoconducidos, robots de entrega, brazos de fábrica y drones. El objetivo es reutilizar la misma pila CUDA, IA y simulación en automoción (Drive), robótica (Isaac) y plataformas embebidas (Jetson).
Los gemelos digitales integran todo esto. Con Omniverse y herramientas relacionadas, Nvidia apuesta a que las empresas simulen fábricas, ciudades y redes 5G antes de construir o reconfigurarlas. Eso crea ingresos de software y servicios duraderos además del hardware.
Oportunidades y riesgos
La automoción, la automatización industrial y el edge son grandes premios. Los coches se convierten en centros de datos rodantes, las fábricas en sistemas impulsados por IA y hospitales y comercios en entornos con multitud de sensores. Cada uno necesita inferencia de baja latencia, software crítico para seguridad y ecosistemas de desarrolladores robustos —áreas donde Nvidia invierte fuertemente.
Pero los riesgos son reales:
- Competencia: AMD, Intel, chips internos de nubes y una ola de aceleradores buscan socavar a Nvidia en coste o especialización.
- Regulación y geopolítica: controles de exportación, escrutinio antimonopolio y políticas industriales pueden limitar dónde y cómo vende Nvidia.
- Cambios tecnológicos: si arquitecturas especializadas (ASICs), chips neuromórficos o nuevas memorias superan a las GPUs en cargas clave, Nvidia deberá adaptarse rápido.
- Alternativas abiertas: hardware abierto (RISC‑V), pilas de software como ROCm y esfuerzos comunitarios para optimizar IA en CPUs o aceleradores personalizados podrían erosionar el bloqueo de CUDA.
Lecciones para constructores y responsables públicos
Para fundadores e ingenieros, la historia de Nvidia muestra el poder de poseer una pila completa: hardware, software y herramientas para desarrolladores, y de apostar siempre por el próximo cuello de botella de cómputo antes de que sea obvio.
Para los responsables públicos, es un caso de estudio sobre cómo plataformas de cómputo críticas se vuelven infraestructura estratégica. Las decisiones sobre controles de exportación, política de competencia y financiación de alternativas abiertas determinarán si Nvidia sigue siendo la pasarela dominante a la IA o uno de varios jugadores importantes.
Preguntas frecuentes
¿Qué hacía diferente la visión original de Nvidia frente a otras empresas de chips en los años 90?
Nvidia se fundó alrededor de una apuesta muy concreta: que los gráficos 3D pasarían de costosas estaciones de trabajo al PC de consumo masivo, y que ese cambio exigiría un procesador gráfico dedicado estrechamente acoplado con software.
En lugar de intentar ser una compañía de semiconductores genérica, Nvidia:
- Se centró en gráficos acelerados para todos, no solo para profesionales.
- Diseñó chips y controladores/APIs conjuntamente, no por separado.
- Optimizó por coste y adopción por parte de los OEM, para que los grandes fabricantes de PC incorporaran Nvidia por defecto.
Ese enfoque estrecho pero profundo sobre un problema concreto —gráficos en tiempo real— creó la base técnica y cultural que más tarde se tradujo en computación GPU y aceleración para IA.
¿Cómo ayudó CUDA a que Nvidia se convirtiera en el hardware predeterminado para IA y aprendizaje profundo?
CUDA convirtió las GPUs de Nvidia de hardware gráfico de función fija en una plataforma de computación paralela de propósito general.
Maneras clave en que impulsó la dominancia en IA:
¿Por qué fue tan importante la adquisición de Mellanox para la estrategia de IA de Nvidia?
Mellanox proporcionó a Nvidia control sobre la tela de red que conecta miles de GPUs en supercomputadoras de IA.
Para modelos grandes, el rendimiento depende no solo de chips rápidos sino de la rapidez con la que pueden intercambiar datos y gradientes. Mellanox aportó:
- InfiniBand y Ethernet de alto rendimiento para enlaces de baja latencia y gran ancho de banda.
¿Cómo gana dinero Nvidia hoy y cómo ha cambiado su mezcla de ingresos con el tiempo?
Los ingresos de Nvidia han pasado de estar dominados por gaming a estar impulsados por centros de datos.
A grandes rasgos:
- Gaming: GPUs GeForce, portátiles para juegos y software relacionado siguen siendo un negocio grande y rentable.
¿Qué amenazas competitivas enfrenta Nvidia por parte de AMD, Intel y chips de IA personalizados?
Nvidia afronta presión tanto de rivales tradicionales como de aceleradores personalizados:
- AMD: compite en GPUs para gaming y aceleradores AI (serie MI), frecuentemente con una propuesta de menor coste por FLOP.
- Intel: ataca con CPUs x86 dominantes en servidores, sus propias GPUs discretas y chips dedicados para IA.
- : Google (TPU), Amazon (Trainium/Inferentia) y otros diseñan chips propios para reducir dependencia de Nvidia.
¿Cómo afectan los controles de exportación, la regulación y la geopolítica al negocio de Nvidia?
Las GPUs avanzadas se consideran ahora tecnología estratégica, especialmente para IA.
Impactos sobre Nvidia:
- Controles de exportación: las reglas de EE. UU. limitan el envío de GPUs de alta gama a China y otras regiones, por lo que Nvidia debe diseñar variantes con rendimiento capado y puede perder demanda de alto margen.
¿Cómo es la pila de software de IA de Nvidia en términos sencillos?
La pila de software de IA de Nvidia es una capa de herramientas que oculta la complejidad de la GPU a la mayoría de desarrolladores:
- : el modelo de programación central que expone la GPU como procesador paralelo.
¿Cómo encajan las apuestas de Nvidia en conducción autónoma y robótica dentro de su estrategia global?
La conducción autónoma y la robótica son extensiones de la plataforma central de IA y simulación de Nvidia hacia sistemas físicos.
Estratégicamente:
- Reutilizan las mismas librerías CUDA y de IA desarrolladas para centros de datos.
- Generan demanda de GPUs para edge y embebidas (Jetson, plataformas Drive para el coche).
¿Qué pueden aprender fundadores e ingenieros de la evolución de Nvidia de startup de gráficos a plataforma de IA?
La trayectoria de Nvidia ofrece varias lecciones:
- Controla la pila completa: combinar chips, diseño de sistemas y software (CUDA, SDKs) crea muros defensivos duraderos.
- Apuesta temprano por los próximos cuellos de botella de cómputo: los shaders programables, CUDA y el soporte temprano al deep learning se hicieron antes de que los mercados fueran obvios.
¿Cómo podría cambiar la posición de Nvidia si las arquitecturas de hardware para IA superan a las GPUs tradicionales?
Si las cargas de trabajo futuras se alejan de los patrones que favorecen a las GPUs, Nvidia tendría que adaptar rápidamente su hardware y software.
Posibles cambios:
- Mayor adopción de ASICs especializados para IA que sacrifiquen flexibilidad por eficiencia en tareas concretas.
- Nuevos paradigmas (neuromórficos, analógicos o jerarquías de memoria radicales) que no se mapeen bien a las GPUs actuales.
- Pilas de software estandarizadas y abiertas (ecosistemas tipo ROCm u otras) que reduzcan el bloqueo de CUDA.
Probables respuestas de Nvidia: