Por qué importan todavía las decisiones tempranas de Joe Beda
Joe Beda fue una de las personas clave detrás del diseño inicial de Kubernetes—junto a otros fundadores que llevaron las lecciones de los sistemas internos de Google a una plataforma abierta. Su influencia no buscaba funciones de moda; buscaba elegir primitivas simples que pudieran sobrevivir al caos de la producción y seguir siendo comprensibles para equipos cotidianos.
Esas decisiones tempranas son la razón por la que Kubernetes se convirtió en algo más que “una herramienta de contenedores”. Pasó a ser un kernel reutilizable para plataformas de aplicaciones modernas.
Orquestación de contenedores, en términos sencillos
“Orquestación de contenedores” es el conjunto de reglas y automatización que mantiene tu aplicación en marcha cuando las máquinas fallan, el tráfico aumenta o despliegas una nueva versión. En lugar de que una persona vigile servidores, el sistema programa contenedores en máquinas, los reinicia cuando se caen, los distribuye para resiliencia y conecta la red para que los usuarios puedan alcanzarlos.
El desorden antes de Kubernetes
Antes de que Kubernetes fuera común, los equipos a menudo cosían scripts y herramientas personalizadas para responder preguntas básicas:
- ¿Dónde debe ejecutarse este contenedor ahora mismo?
- ¿Qué pasa si un nodo muere a las 2 a. m.?
- ¿Cómo desplegamos de forma segura sin tiempo de inactividad?
- ¿Cómo se encuentran los servicios cuando las IP cambian constantemente?
Esos sistemas caseros funcionaban—hasta que dejaron de hacerlo. Cada nueva app o equipo añadía lógica específica, y la consistencia operativa era difícil de lograr.
Qué cubre este artículo
Este artículo recorre las decisiones de diseño tempranas de Kubernetes (la “forma” de Kubernetes) y por qué siguen influyendo en las plataformas modernas: el modelo declarativo, los controladores, los Pods, las etiquetas, los Services, una API fuerte, un estado de clúster consistente, planificación enchufable y extensibilidad. Incluso si no ejecutas Kubernetes directamente, probablemente estés usando una plataforma construida sobre estas ideas—o luchando con los mismos problemas.
El problema que Kubernetes trató de resolver
Antes de Kubernetes, “ejecutar contenedores” solía significar ejecutar unos pocos contenedores. Los equipos combinaban bash scripts, cron jobs, imágenes doradas y un puñado de herramientas ad hoc para desplegar. Cuando algo se rompía, la solución a menudo vivía en la cabeza de alguien—o en un README que nadie confiaba. Las operaciones eran una sucesión de intervenciones puntuales: reiniciar procesos, reenfocar balanceadores, limpiar discos y adivinar qué máquina era segura para tocar.
Los contenedores a escala crearon nuevos modos de fallo
Los contenedores facilitaron el empaquetado, pero no eliminaron las partes desordenadas de producción. A escala, el sistema falla de más maneras y más a menudo: los nodos desaparecen, las redes se particionan, las imágenes se despliegan de forma inconsistente y las cargas se desvían de lo que crees que se está ejecutando. Un despliegue “simple” puede convertirse en una cascada—algunas instancias actualizadas, otras no, algunas atascadas, otras sanas pero inalcanzables.
El problema real no era arrancar contenedores. Era mantener los contenedores correctos ejecutándose, con la forma correcta, pese al churn constante.
Un modelo consistente a través de infraestructuras
Los equipos también lidiaban con entornos distintos: hardware on‑prem, VMs, primeros proveedores cloud y diversas configuraciones de red y almacenamiento. Cada plataforma tenía su propio vocabulario y patrones de fallo. Sin un modelo compartido, cada migración significaba reescribir herramientas operativas y reentrenar personas.
Kubernetes se propuso ofrecer una manera única y consistente de describir aplicaciones y sus necesidades operativas, sin importar dónde vivieran las máquinas.
Los desarrolladores querían autoservicio: desplegar sin tickets, escalar sin pedir capacidad y revertir sin drama. Los equipos de operaciones querían previsibilidad: comprobaciones de salud estandarizadas, despliegues repetibles y una fuente de verdad clara sobre lo que debería estar ejecutándose.
Kubernetes no intentaba ser un scheduler elegante. Aspiraba a ser la base de una plataforma de aplicaciones confiable—una que convierta la realidad desordenada en un sistema razonable.
Decisión 1: Un modelo declarativo de estado deseado
Una de las elecciones más influyentes fue hacer Kubernetes declarativo: describes lo que quieres y el sistema trabaja para que la realidad coincida con esa descripción.
Estado deseado, explicado con un termostato
Un termostato es un buen ejemplo cotidiano. No enciendes y apagas la calefacción cada pocos minutos. Fijas una temperatura deseada—por ejemplo 21°C—y el termostato va comprobando la habitación y ajustando la calefacción para mantenerse cerca de ese objetivo.
Kubernetes funciona igual. En vez de decir al clúster, paso a paso, “arranca este contenedor en esa máquina y reinícialo si falla”, declaras el resultado: “quiero 3 copias de esta app ejecutándose.” Kubernetes comprueba continuamente qué se está ejecutando realmente y corrige la deriva.
Menos pasos manuales, menos sorpresas
La configuración declarativa reduce la “lista de operaciones” oculta que suele vivir en la cabeza de alguien o en un runbook medio actualizado. Aplicas la configuración y Kubernetes maneja la mecánica: colocación, reinicios y reconciliación de cambios.
También facilita la revisión de cambios. Un cambio es visible como un diff en la configuración, no como una serie de comandos ad hoc.
Repetibilidad entre entornos
Porque el estado deseado está por escrito, puedes reutilizar el mismo enfoque en dev, staging y producción. El entorno puede diferir, pero la intención se mantiene, lo que hace los despliegues más predecibles y fáciles de auditar.
Los trade-offs
Los sistemas declarativos tienen curva de aprendizaje: hay que pensar en “qué debe ser cierto” en lugar de “qué hago ahora”. Además dependen mucho de buenos valores por defecto y convenciones claras—sin ellos, los equipos pueden producir configuraciones que técnicamente funcionan pero son difíciles de entender y mantener.
Decisión 2: Bucles de control (controladores) como motor
Kubernetes no triunfó porque pudiera ejecutar contenedores una vez: triunfó porque podía mantenerlos ejecutándose correctamente en el tiempo. El gran movimiento de diseño fue convertir los “control loops” (controladores) en el motor central del sistema.
Qué es un controlador
Un controlador es un bucle simple:
- Mira el estado actual (lo que realmente se está ejecutando)
- Compara con el estado deseado (lo que pediste)
- Toma acciones hasta que ambos coincidan
Es menos una tarea única y más un piloto automático. No “cuidas” las cargas; declaras lo que quieres y los controladores siguen orientando el clúster hacia ese resultado.
Manejar caídas, pérdida de nodos y deriva
Este patrón explica por qué Kubernetes es resiliente cuando suceden cosas del mundo real:
- Caídas de contenedores: el controlador detecta menos instancias de las deseadas y crea reemplazos.
- Pérdida de nodos: cuando un nodo desaparece, los controladores reprograman pods en otros nodos para restaurar el conteo deseado.
- Deriva de configuración: si alguien cambia o borra recursos, los controladores reconcilian la diferencia y la corrigen.
En lugar de tratar los fallos como casos especiales, los controladores los tratan como un simple “desajuste de estado” y lo arreglan siempre de la misma forma.
Por qué escala mejor que los scripts
Los scripts tradicionales suelen asumir un entorno estable: ejecutar A, luego B, luego C. En sistemas distribuidos, esas asunciones se rompen constantemente. Los controladores escalan mejor porque son idempotentes (seguros de ejecutar repetidamente) y eventualmente consistentes (siguen intentando hasta alcanzar el objetivo).
Ejemplos cotidianos: Deployments y ReplicaSets
Si has usado un Deployment, dependes de bucles de control. Bajo el capó, Kubernetes usa un ReplicaSet controller para asegurar que exista el número solicitado de pods—y un controlador de Deployment para gestionar actualizaciones continuas y rollbacks de manera predecible.
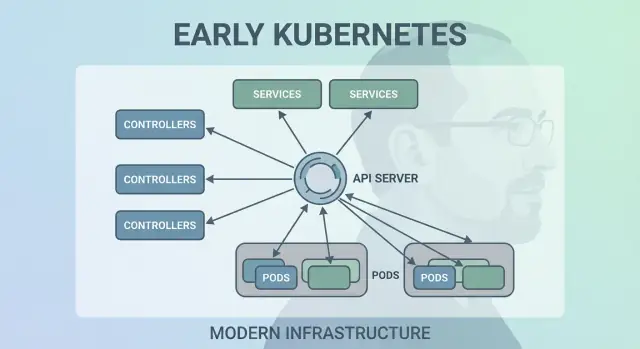
Decisión 3: Pods como unidad atómica de programación
Kubernetes pudo haber programado “solo contenedores”, pero el equipo de Joe Beda introdujo los Pods para representar la unidad mínima desplegable que el clúster coloca en una máquina. La idea clave: muchas aplicaciones reales no son un único proceso. Son un pequeño grupo de procesos estrechamente acoplados que deben vivir juntos.
¿Por qué Pods en vez de contenedores individuales?
Un Pod es un contenedor para uno o más contenedores que comparten el mismo destino: arrancan juntos, se ejecutan en el mismo nodo y escalan juntos. Esto hace patrones como los sidecars naturales—piensa en un recolector de logs, un proxy, un recargador de configuración o un agente de seguridad que siempre debe acompañar a la app principal.
En vez de enseñar a cada app a integrar esos ayudantes, Kubernetes permite empaquetarlos como contenedores separados que aun así se comportan como una unidad.
Lo que habilitaron los Pods para red y almacenamiento
Los Pods hicieron prácticas dos suposiciones importantes:
- Red: los contenedores en un Pod comparten una identidad de red (una IP y espacio de puertos). La app principal puede hablar con el sidecar por
localhost, lo que es simple y rápido.
- Almacenamiento: los contenedores en un Pod pueden compartir volúmenes. Un ayudante puede escribir archivos que la app principal lea, sin saltos externos incómodos.
Estas elecciones redujeron la necesidad de código glue personalizado, manteniendo a la vez el aislamiento a nivel de proceso.
Dónde confunden los Pods a los nuevos usuarios
Los usuarios nuevos suelen esperar “un contenedor = una app” y luego se tropiezan con conceptos a nivel de Pod: reinicios, IPs y escalado. Muchas plataformas suavizan esto ofreciendo plantillas opinadas (por ejemplo, “servicio web”, “worker” o “job”) que generan Pods detrás de escena—así los equipos obtienen los beneficios de sidecars y recursos compartidos sin pensar en la mecánica del Pod cada día.
Decisión 4: Etiquetas y selectores para acoplamiento flojo
Lanza sin despliegues arriesgados
Despliega y aloja tu app, y protege los cambios con instantáneas y reversión.
Una elección silenciosamente poderosa en Kubernetes fue tratar las etiquetas como metadatos de primera clase y los selectores como la forma principal de “encontrar” cosas. En lugar de relaciones rígidas (como “estas tres máquinas exactas ejecutan mi app”), Kubernetes te anima a describir grupos por atributos compartidos.
Una etiqueta es un par clave/valor que adjuntas a recursos—Pods, Deployments, Nodes, Namespaces y más. Actúan como “tags” consultables y coherentes:
app=checkoutenv=prodtier=frontend
Al ser ligeras y definidas por el usuario, puedes modelar la realidad de tu organización: equipos, centros de costo, zonas de cumplimiento, canales de lanzamiento o lo que importe para operar.
Selectores: relaciones sin dependencias rígidas
Los selectores son consultas sobre etiquetas (por ejemplo, “todos los Pods donde app=checkout y env=prod”). Esto vence a las listas de hosts fijas porque el sistema se adapta cuando los Pods se reprograman, escalan o se reemplazan durante un rollout. Tu configuración permanece estable aun cuando las instancias subyacentes cambian constantemente.
Agrupación dinámica a escala
Este diseño escala operativamente: no gestionas miles de identidades de instancias—gestionas unos pocos conjuntos de etiquetas significativas. Esa es la esencia del acoplamiento flojo: los componentes se conectan a grupos cuya membresía puede cambiar con seguridad.
Las etiquetas impulsan más que agrupación
Una vez que existen las etiquetas, se vuelven un vocabulario compartido en toda la plataforma. Se usan para ruteo de tráfico (Services), límites de políticas (NetworkPolicy), filtros de observabilidad (métricas/logs) e incluso seguimiento de costes y chargeback. Una idea simple—etiquetar cosas consistentemente—desbloquea todo un ecosistema de automatización.
Decisión 5: Services para una red estable
Kubernetes necesitaba una forma de hacer que la red pareciera predecible aun cuando los contenedores no lo son. Los Pods se reemplazan, se reprograman y escalan—sus IPs y las máquinas específicas cambiarán. La idea central de un Service es simple: proporcionar una “puerta de entrada” estable a un conjunto cambiante de Pods.
Acceso estable a Pods cambiantes
Un Service te da una IP virtual y un nombre DNS consistentes (como payments). Detrás de ese nombre, Kubernetes rastrea continuamente qué Pods coinciden con el selector del Service y enruta el tráfico. Si un Pod muere y aparece uno nuevo, el Service sigue apuntando al lugar correcto sin que toques la configuración de la app.
Descubrimiento de servicios que simplificó la configuración
Este enfoque eliminó mucho cableado manual. En lugar de incrustar IPs en archivos de configuración, las apps pueden depender de nombres. Despliegas la app, despliegas el Service y otros componentes la encuentran vía DNS—sin registro personalizado ni endpoints hardcodeados.
Balanceo de carga incorporado para fiabilidad
Los Services también introdujeron un comportamiento por defecto de balanceo de carga entre endpoints saludables. Eso significó que los equipos no tenían que construir (o reconstruir) su propio balanceador para cada microservicio interno. Repartir tráfico reduce el blast radius de la falla de un Pod y hace que las actualizaciones continuas sean menos arriesgadas.
Límites—y cómo Ingress/Gateway lo amplían
Un Service es excelente para L4 (TCP/UDP), pero no modela reglas de ruteo HTTP, terminación TLS o políticas de borde. Ahí encajan Ingress y, cada vez más, la Gateway API: construyen sobre Services para manejar hostnames, paths y puntos de entrada externos con más claridad.
Decisión 6: Una API como superficie de producto
Una de las elecciones tempranas más radicales fue tratar Kubernetes como una API con la que se construye, no como una herramienta monolítica que “se usa”. Ese enfoque API-first hizo que Kubernetes pareciera menos un producto para clicar y más una plataforma que puedes extender, automatizar y gobernar.
Cuando la API es la superficie, los equipos de plataforma pueden estandarizar cómo se describen y gestionan las aplicaciones, sin importar qué UI, pipeline o portal interno se ponga encima. “Desplegar una app” se convierte en “enviar y actualizar objetos de la API” (como Deployments, Services y ConfigMaps), que es un contrato mucho más limpio entre equipos de aplicación y la plataforma.
Herramientas, UIs y automatización sin acceso especial
Puesto que todo pasa por la misma API, las nuevas herramientas no necesitan puertas traseras privilegiadas. Dashboards, controladores GitOps, motores de políticas y sistemas CI/CD pueden operar como clientes normales de la API con permisos bien acotados.
Esa simetría importa: las mismas reglas, auth, auditoría y controles de admisión se aplican tanto si la petición viene de una persona, un script o una UI interna.
Versionado y compatibilidad para clústeres de larga vida
El versionado de la API permitió evolucionar Kubernetes sin romper cada clúster o herramienta de la noche a la mañana. Las deprecaciones pueden escalonarse; la compatibilidad puede probarse; las actualizaciones pueden planificarse. Para organizaciones que ejecutan clústeres durante años, esta es la diferencia entre “podemos actualizar” y “estamos atrapados”.
Qué representa realmente kubectl
kubectl no es Kubernetes: es un cliente. Ese modelo mental empuja a los equipos a pensar en flujos de trabajo basados en la API: puedes cambiar kubectl por automatización, una UI web o un portal personalizado, y el sistema sigue siendo coherente porque el contrato es la API misma.
Decisión 7: Estado centralizado del clúster (etcd) y consistencia
Aprovecha al máximo tu presupuesto de construcción
Gana créditos compartiendo lo que construiste en Koder.ai o refiriendo a compañeros.
Kubernetes necesitaba una “fuente de verdad” única sobre cómo debe verse el clúster ahora: qué Pods existen, qué nodos están saludables, a qué apuntan los Services y qué objetos se están actualizando. Ahí es donde entra etcd.
Qué hace etcd (en términos sencillos)
etcd es la base de datos para el plano de control. Cuando creas un Deployment, escalas un ReplicaSet o actualizas un Service, la configuración deseada se escribe en etcd. Los controladores y otros componentes del plano de control observan ese estado almacenado y trabajan para hacer que la realidad coincida.
Por qué la consistencia importa cuando todo actúa a la vez
Un clúster de Kubernetes está lleno de partes móviles: scheduler, controladores, kubelets, autoscalers y checks de admisión pueden reaccionar simultáneamente. Si leen versiones distintas de “la verdad”, aparecen carreras—como dos componentes tomando decisiones contradictorias sobre el mismo Pod.
La consistencia fuerte de etcd asegura que cuando el plano de control dice “este es el estado actual”, todos estén alineados. Esa alineación hace que los bucles de control sean previsibles en lugar de caóticos.
Cómo afecta a backups, upgrades y recuperación de desastres
Porque etcd guarda la configuración del clúster y el historial de cambios, también es lo que proteges durante:
- Backups: sin un snapshot de etcd no puedes restaurar objetos del clúster de forma fiable.
- Upgrades: una buena salud de etcd y snapshotting reduce el riesgo de actualizar.
- Recuperación de desastres: restaurar etcd suele ser la vía más rápida para recuperar el plano de control con la misma intención.
Guía práctica
Trata el estado del plano de control como datos críticos. Haz snapshots de etcd regularmente, prueba las restauraciones y almacena backups fuera del clúster. Si usas un Kubernetes gestionado, aprende qué respalda tu proveedor y qué debes respaldar tú (por ejemplo, volúmenes persistentes y datos de aplicación).
Decisión 8: Planificación enchufable y conciencia de recursos
Kubernetes no trató “dónde corre una carga” como un asunto secundario. Desde temprano, el scheduler fue un componente distinto con un trabajo claro: asignar Pods a nodos que realmente puedan ejecutarlos, usando el estado actual del clúster y los requisitos del Pod.
Cómo el scheduler empareja cargas con nodos
A grandes rasgos, la planificación es una decisión en dos pasos:
- Filtrar: eliminar nodos que no cumplen restricciones duras (CPU/memoria insuficiente, etiquetas faltantes, taints incompatibles, puertos ocupados, etc.).
- Puntuar: ordenar los nodos restantes por preferencias (distribuir entre zonas, empacar para eficiencia, evitar vecinos ruidosos, respetar reglas de afinidad).
Esta estructura hizo posible evolucionar la planificación sin reescribir todo.
Separación de responsabilidades: scheduler vs runtime vs networking
Una decisión clave fue mantener responsabilidades limpias:
- El scheduler decide la colocación.
- El runtime de contenedores (y kubelet) realiza la ejecución en el nodo elegido.
- La capa de red proporciona conectividad una vez que todo está en ejecución.
Al separar estas preocupaciones, las mejoras en un área (por ejemplo, un nuevo plugin CNI) no obligan a cambiar el modelo de scheduling.
Restricciones y prioridades crecieron naturalmente
La conciencia de recursos comenzó con requests y limits, dando al scheduler señales útiles en lugar de conjeturas. Desde ahí se añadieron controles más ricos—node affinity/anti-affinity, pod affinity, priorities y preemption, taints y tolerations, y el reparto consciente de topología—construidos sobre la misma base.
Impacto moderno: multi-tenant y colocación eficiente en costes
Este enfoque permite clústeres compartidos actuales: los equipos pueden aislar servicios críticos con prioridades y taints, y al mismo tiempo todos se benefician de mayor utilización. Con mejor bin-packing y controles topológicos, las plataformas colocan cargas de forma más rentable sin sacrificar fiabilidad.
Crea una pila web y de API
Crea una app web en React y un backend en Go y PostgreSQL desde un simple chat.
Kubernetes pudo haber venido con una experiencia PaaS completa y muy opinada—buildpacks, reglas de ruteo de apps, jobs, convenciones de config y más. En cambio, Joe Beda y el equipo mantuvieron el núcleo enfocado en una promesa más pequeña: ejecutar y sanar cargas de trabajo con fiabilidad, exponerlas y proporcionar una API consistente para automatizar.
Por qué Kubernetes no intentó ser un PaaS completo
Un PaaS “completo” habría impuesto un único flujo de trabajo y un conjunto de trade-offs a todo el mundo. Kubernetes apuntó a una fundación más amplia que pudiera soportar muchos estilos de plataforma—simplicidad tipo Heroku, gobernanza empresarial, pipelines de batch y ML, o control de infraestructura sin adornos—sin forzar una sola filosofía de producto.
Cómo las extensiones permiten añadir funciones con seguridad
Los mecanismos de extensibilidad de Kubernetes crearon una forma controlada de crecer capacidades:
- CRDs (CustomResourceDefinitions) permiten añadir nuevos tipos de API (por ejemplo,
Certificate o Database) que se sienten nativos.
- Controladores/operadores reconcilian esos nuevos recursos usando el mismo patrón deseado-estado que los componentes integrados.
- Admission controllers/webhooks aplican política (seguridad, nombres, cuotas) y rellenan valores por defecto en el límite de la API.
Esto significa que equipos de plataforma internos y proveedores pueden ofrecer características como add-ons, usando al mismo tiempo primitivas de Kubernetes como RBAC, namespaces y logs de auditoría.
Beneficios—y el riesgo principal
Para los proveedores, permite productos diferenciados sin forkear Kubernetes. Para los equipos internos, posibilita una “plataforma sobre Kubernetes” adaptada a necesidades organizativas.
El trade-off es la proliferación del ecosistema: demasiados CRDs, herramientas solapadas y convenciones inconsistentes. La gobernanza—estándares, propiedad, versionado y reglas de deprecación—pasa a formar parte del trabajo de la plataforma.
Las decisiones tempranas de Kubernetes no solo crearon un scheduler de contenedores: crearon un kernel de plataforma reutilizable. Por eso muchas plataformas internas de desarrollador (IDP) son, en su esencia, “Kubernetes más flujos de trabajo opinados”. El modelo declarativo, los controladores y una API consistente hicieron posible construir productos de nivel superior sin reinventar despliegue, reconciliación y descubrimiento de servicios cada vez.
Kubernetes como plano de control compartido
Porque la API es la superficie de producto, proveedores y equipos de plataforma pueden estandarizar en un plano de control y construir experiencias diferentes encima: GitOps, gestión multi-clúster, políticas, catálogos de servicios y automatización de despliegue. Esta es una gran razón por la que Kubernetes se convirtió en el denominador común para plataformas cloud native: las integraciones apuntan a la API, no a una UI específica.
Qué siguió siendo difícil (la realidad del Day-2)
Incluso con abstracciones limpias, lo más duro sigue siendo operativo:
- Seguridad: identidad, policy de red, secretos y confianza en la cadena de suministro
- Actualizaciones: versiones de Kubernetes, CRDs y add-ons moviéndose a distintas velocidades
- Fiabilidad: depurar controladores, malas configuraciones y vecinos ruidosos
Haz preguntas que revelen madurez operativa:
- ¿Cómo se manejan las actualizaciones y cuál es la historia de rollback?
- ¿Qué partes son Kubernetes estándar vs. extensiones propietarias?
- ¿Qué guardarraíles existen (política, valores por defecto, plantillas) para evitar errores peligrosos?
- ¿Qué tan observable es el sistema (eventos, logs, auditoría) y quién gestiona los incidentes?
Una buena plataforma reduce la carga cognitiva sin ocultar el plano de control subyacente ni hacer tortuosos los escape hatches.
Un lente práctico: ¿la plataforma ayuda a los equipos a pasar de “idea → servicio en ejecución” sin obligar a todos a ser expertos en Kubernetes desde el día uno? Herramientas en la categoría “vibe-coding”—como Koder.ai—apuntan a esto permitiendo generar aplicaciones reales desde chat (web en React, backends en Go con PostgreSQL, móvil en Flutter) y luego iterar rápido con funciones como modo de planificación, snapshots y rollback. Tanto si adoptas algo así como si construyes tu propio portal, el objetivo es el mismo: preservar las primitivas fuertes de Kubernetes mientras reduces la sobrecarga de flujo de trabajo que las rodea.
Conclusiones y lecciones prácticas
Kubernetes puede parecer complicado, pero la mayor parte de su “rareza” es intencional: es un conjunto de pequeñas primitivas diseñadas para componer muchos tipos de plataformas.
Aclara dos conceptos erróneos comunes
Primero: “Kubernetes es solo orquestación de Docker.” Kubernetes no trata principalmente de arrancar contenedores. Trata de reconciliar continuamente el estado deseado (lo que quieres que corra) con el estado real (lo que está ocurriendo), a través de fallos, rollouts y demanda cambiante.
Segundo: “Si usamos Kubernetes, todo se convierte en microservicios.” Kubernetes soporta microservicios, pero también monolitos, jobs batch y plataformas internas. Las primitivas (Pods, Services, etiquetas, controladores y la API) son neutrales; tus decisiones arquitectónicas no vienen dictadas por la herramienta.
De dónde viene realmente la complejidad
Lo difícil suele ser la red, la seguridad y el uso por múltiples equipos: identidad y acceso, gestión de secretos, políticas, ingress, observabilidad, controles de la cadena de suministro y crear guardarraíles para que los equipos desplieguen con seguridad sin pisarse.
Lecciones a nivel de decisión que puedes aplicar
Al planificar, piensa en términos de las apuestas de diseño originales:
- Prefiere flujos declarativos y automatización que reconcilien la deriva.
- Usa etiquetas/selectores para mantener bajo el acoplamiento entre equipos y componentes.
- Trata la API como un producto: versionado, convenciones y propiedad clara importan.
Un siguiente paso práctico
Mapea tus requisitos reales a las primitivas y capas de plataforma de Kubernetes:
-
Cargas → Pods/Deployments/Jobs
-
Conectividad → Services/Ingress
-
Operaciones → controladores, políticas y observabilidad
Si estás evaluando o estandarizando, escribe este mapeo y revísalo con las partes interesadas—luego construye tu plataforma de forma incremental alrededor de las brechas, no alrededor de las tendencias.
Si además buscas acelerar la parte de “construir” (no solo la de “ejecutar”), considera cómo tu flujo de entrega convierte la intención en servicios desplegables. Para algunos equipos eso son plantillas curadas; para otros, un flujo asistido por IA como Koder.ai que puede producir un servicio funcional inicial rápidamente y luego exportar código fuente para personalización profunda—mientras tu plataforma sigue beneficiándose de las decisiones de diseño centrales de Kubernetes por debajo.