07 nov 2025·8 min
Los avances de Geoffrey Hinton en redes neuronales, explicados
Una guía clara sobre las ideas clave de Geoffrey Hinton—from retropropagación y máquinas de Boltzmann hasta redes profundas y AlexNet—y cómo moldearon la IA moderna.
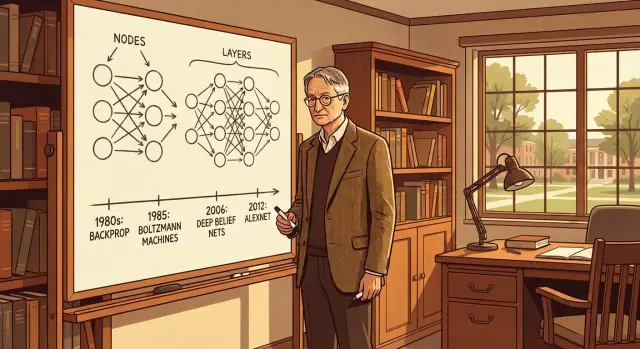
Por qué Geoffrey Hinton importa
Esta guía es para lectores curiosos y no técnicos que oyen que “las redes neuronales lo cambiaron todo” y quieren una explicación clara y fundamentada de lo que eso realmente significa—sin necesidad de cálculo ni programación.
Lo que aprenderás aquí
Recibirás un recorrido en inglés claro sobre las ideas que Geoffrey Hinton ayudó a impulsar, por qué importaron en su momento y cómo se conectan con las herramientas de IA que la gente usa hoy. Piénsalo como una historia sobre mejores maneras de enseñar a las máquinas a reconocer patrones—palabras, imágenes, sonidos—aprendiendo a partir de ejemplos.
Por qué Hinton importa (sin exageraciones)
Hinton no “inventó la IA”, y ninguna persona por sí sola creó el aprendizaje automático moderno. Su importancia es que, repetidamente, ayudó a que las redes neuronales funcionaran en la práctica cuando muchos investigadores creían que eran callejones sin salida. Contribuyó conceptos clave, experimentos y una cultura de investigación que trató el aprendizaje de representaciones (características internas útiles) como el problema central—en lugar de codificar reglas a mano.
Vista previa rápida de los avances cubiertos
En las secciones siguientes desglosaremos:
- La retropropagación como forma práctica de mejorar una red aprendiendo de los errores
- Las máquinas de Boltzmann y el aprendizaje basado en energía como una vía temprana para aprender estructura a partir de datos
- El aprendizaje de representaciones y por qué las “buenas características” se pueden aprender en lugar de diseñarse
- Redes de creencias profundas, dropout y trucos de entrenamiento que hicieron posibles modelos más profundos
- AlexNet y el momento en que las redes neuronales se probaron a escala real
Qué cuenta como un “avance” en redes neuronales
En este artículo, un avance significa un cambio que hace que las redes neuronales sean más útiles: se entrenan con más fiabilidad, aprenden mejores características, generalizan mejor a nuevos datos o escalan a tareas mayores. Es menos sobre una demostración vistosa y más sobre convertir una idea en un método fiable.
El problema que intentaban resolver las redes neuronales
Las redes neuronales no fueron inventadas para “reemplazar programadores”. Su promesa original fue más concreta: construir máquinas que pudieran aprender representaciones internas útiles a partir de entradas reales y desordenadas—imágenes, voz y texto—sin que los ingenieros codificaran cada regla.
De la entrada cruda al significado
Una foto son millones de valores de píxeles. Una grabación de sonido es una sucesión de mediciones de presión. El reto es convertir esos números crudos en conceptos que importan: bordes, formas, fonemas, palabras, objetos, intención.
Antes de que las redes neuronales fueran prácticas, muchos sistemas dependían de características diseñadas a mano—medidas cuidadosamente creadas como detectores de bordes o descriptores de textura. Eso funcionaba en escenarios estrechos, pero a menudo fallaba cuando cambiaba la iluminación, los acentos o los entornos se volvían más complejos.
Las redes neuronales intentaron resolver esto aprendiendo automáticamente características, capa por capa, a partir de datos. Si un sistema puede descubrir los bloques intermedios adecuados por sí mismo, puede generalizar mejor y adaptarse a nuevas tareas con menos ingeniería manual.
Por qué esto fue difícil durante décadas
La idea era atractiva, pero varias barreras impidieron que las redes neuronales cumplieran su promesa durante mucho tiempo:
- Computación: el entrenamiento requería enormes cantidades de cálculos. En los 80 y 90, la mayoría de los laboratorios no tenían potencia suficiente para modelos grandes.
- Datos: los conjuntos de datos grandes y etiquetados que hacen fiable el aprendizaje no fueron ampliamente disponibles hasta los 2000.
- Estabilidad del entrenamiento: las primeras redes multicapa eran difíciles de entrenar bien; el progreso dependía de algoritmos de aprendizaje y trucos prácticos que aún no estaban maduros.
Persistencia como estrategia
Incluso cuando las redes neuronales estaban fuera de moda—especialmente durante partes de los 90 y principios de los 2000—investigadores como Geoffrey Hinton siguieron empujando el aprendizaje de representaciones. Propuso ideas (desde mediados de los 80) y revisó ideas antiguas (como modelos basados en energía) hasta que el hardware, los datos y los métodos alcanzaron el nivel necesario.
Esa persistencia ayudó a mantener vivo el objetivo central: máquinas que aprendan las representaciones correctas, no solo la respuesta final.
Retropropagación, en palabras sencillas
La retropropagación (a menudo abreviada como “backprop”) es el método que permite a una red neuronal mejorar mediante aprender de sus errores. La red hace una predicción, medimos cuánto se equivoca y luego ajustamos los “mandos” internos de la red (sus pesos) para que lo haga un poco mejor la próxima vez.
Aprender corrigiendo errores
Imagina una red que intenta etiquetar una foto como “gato” o “perro”. Adivina “gato”, pero la respuesta correcta es “perro”. La retropropagación comienza con ese error final y trabaja hacia atrás por las capas de la red, determinando cuánto contribuyó cada peso al error.
Una forma práctica de pensarlo:
- Pasada hacia delante: hacer una predicción.
- Pérdida: calcular el error (qué tan lejos estuvo la predicción).
- Pasada hacia atrás: asignar “culpa” a través de las capas.
- Actualización: ajustar los pesos para reducir ese error la próxima vez.
Esos ajustes suelen realizarse con un algoritmo compañero llamado descenso por gradiente, que simplemente significa “dar pequeños pasos cuesta abajo sobre la superficie del error”.
Lo que permitió la retropropagación
Antes de que la retropropagación se adoptara ampliamente, entrenar redes multicapa era inestable y lento. La retropropagación hizo viable entrenar redes más profundas porque proporcionó una forma sistemática y repetible de sintonizar muchas capas a la vez—en lugar de ajustar solo la capa final o adivinar cambios.
Ese cambio fue clave para los avances siguientes: una vez que puedes entrenar varias capas de forma efectiva, las redes pueden aprender características más ricas (bordes → formas → objetos, por ejemplo).
Malentendidos comunes
La retropropagación no es que la red “piense” o “entienda” como una persona. Es una retroalimentación matemática: una manera de ajustar parámetros para que coincidan mejor con ejemplos.
Además, la retropropagación no es un único modelo—es un método de entrenamiento que puede usarse en muchos tipos de redes neuronales.
Si quieres una inmersión suave sobre cómo se estructuran las redes, ve a /blog/neural-networks-explained.
Máquinas de Boltzmann y aprendizaje basado en energía
Las máquinas de Boltzmann fueron uno de los pasos clave de Geoffrey Hinton hacia que las redes neuronales aprendieran representaciones internas útiles, no solo ofrecieran respuestas.
La idea básica: una puntuación de “energía” para cada posibilidad
Una máquina de Boltzmann es una red de unidades simples que pueden estar activas/inactivas (o, en versiones modernas, tomar valores reales). En lugar de predecir una salida directamente, asigna una energía a toda una configuración de unidades. Menor energía significa “esta configuración tiene sentido”.
Una analogía útil es una mesa con pequeños valles. Si dejas caer una canica, rodará y se asentará en un punto bajo. Las máquinas de Boltzmann hacen algo similar: dadas algunas unidades visibles fijadas por datos, la red “vibra” sus unidades internas hasta asentarse en estados de baja energía—estados que ha aprendido a considerar probables.
Por qué importó (aunque fuera lento)
Entrenar máquinas de Boltzmann clásicas implicaba muestrear repetidamente muchas posibles configuraciones para estimar lo que el modelo cree frente a lo que muestran los datos. Ese muestreo puede ser dolorosamente lento, especialmente para redes grandes.
Aun así, el enfoque fue influyente porque:
- enmarcó el aprendizaje como modelado de una distribución de probabilidad, no solo ajuste de etiquetas
- empujó el campo hacia el aprendizaje no supervisado (aprender sin respuestas explícitas)
- inspiró atajos prácticos como la divergencia contrastiva y métodos basados en energía posteriores
Cómo se compara con las redes profundas actuales
Hoy la mayoría de los productos usan redes profundas feedforward entrenadas con retropropagación porque son más rápidas y fáciles de escalar.
El legado de las máquinas de Boltzmann es más conceptual que práctico: la idea de que los buenos modelos aprenden “estados preferidos” del mundo y que el aprendizaje puede verse como desplazar masa de probabilidad hacia esos valles de baja energía.
Aprendizaje de representaciones: la idea central detrás de los avances
Las redes neuronales no solo mejoraron en ajustar curvas: mejoraron en inventar las características correctas. Eso es lo que significa “aprendizaje de representaciones”: en vez de que un humano programe qué buscar, el modelo aprende descripciones internas (representaciones) que facilitan la tarea.
Qué son las “representaciones”
Una representación es la manera en que el modelo resume la entrada cruda. Aún no es una etiqueta como “gato”; es la estructura útil en camino a esa etiqueta—patrones que capturan lo que suele importar. Las capas tempranas pueden responder a señales simples; las capas posteriores las combinan en conceptos más significativos.
Por qué cambió el rendimiento en el mundo real
Antes de este cambio, muchos sistemas dependían de características diseñadas por expertos: detectores de bordes para imágenes, señales de audio diseñadas para voz o estadísticas de texto cuidadosamente elaboradas. Esas características funcionaban, pero a menudo fallaban cuando las condiciones cambiaban (iluminación, acentos, redacción).
El aprendizaje de representaciones permitió que los modelos adaptaran las características a los datos mismos, lo que mejoró la precisión y hizo los sistemas más resistentes frente a entradas reales y desordenadas.
Una idea, muchos dominios
- Visión: los píxeles se convierten en conceptos visuales cada vez más estructurados.
- Voz: las ondas sonoras se convierten en patrones tipo fonema, luego en palabras.
- Lenguaje: los tokens se convierten en frases, significados y relaciones entre ideas.
El hilo común es la jerarquía: patrones simples se combinan en patrones más ricos.
Un ejemplo simple: bordes → formas → objetos
En reconocimiento de imágenes, una red puede aprender primero patrones tipo borde (cambios claro‑oscuro). Después combina bordes en esquinas y curvas, luego en partes como ruedas o ojos, y finalmente en objetos completos como “bicicleta” o “cara”.
Los avances de Hinton ayudaron a que esta construcción por capas fuera práctica—y esa es una gran razón por la que el aprendizaje profundo empezó a ganar en tareas que realmente importan.
Redes de creencias profundas y el camino hacia modelos más profundos
Mantén tu código portátil
Obtén el código fuente para que tu equipo pueda revisarlo, modificarlo y ser dueño del proyecto.
Las redes de creencias profundas (DBN) fueron un escalón importante hacia las redes profundas actuales. A grandes rasgos, una DBN es una pila de capas donde cada capa aprende a representar la capa inferior—empezando por entradas crudas y construyendo poco a poco conceptos más abstractos.
Qué es una DBN (conceptualmente)
Imagina enseñar a un sistema a reconocer la escritura a mano. En vez de aprender todo a la vez, una DBN primero aprende patrones simples (como bordes y trazos), luego combinaciones de esos patrones (bucles, esquinas) y finalmente formas más altas que se parecen a partes de los dígitos.
La idea clave es que cada capa intenta modelar los patrones en su entrada sin que aún se le diga la respuesta correcta. Luego, después de que la pila ha aprendido estas representaciones útiles, puedes afinar toda la red para una tarea específica como la clasificación.
Por qué el preentrenamiento capa a capa importó
Las redes profundas iniciales a menudo tenían dificultades para entrenar bien cuando se inicializaban de forma aleatoria. Las señales de entrenamiento podían debilitarse o volverse inestables al atravesar muchas capas, y la red podía quedarse en configuraciones poco útiles.
El preentrenamiento capa a capa dio al modelo un “arranque razonable”. Cada capa empezaba con una comprensión aceptable de la estructura en los datos, por lo que la red completa no buscaba a ciegas.
Cómo esto hizo la profundidad más factible
El preentrenamiento no resolvió todos los problemas, pero hizo que la profundidad fuera práctica en una época en la que los datos, la potencia de cómputo y los trucos de entrenamiento eran más limitados que ahora.
Las DBN contribuyeron a demostrar que aprender buenas representaciones a través de múltiples capas podía funcionar y que la profundidad no era solo teoría, sino un camino utilizable.
Dropout y la lucha contra el sobreajuste
Las redes neuronales pueden ser curiosamente buenas en “estudiar para el examen” de la peor forma: memorizar los datos de entrenamiento en vez de aprender el patrón subyacente. Ese problema se llama sobreajuste y aparece cuando un modelo va muy bien en las pruebas conocidas pero falla en datos nuevos.
Sobreajuste, con un ejemplo cotidiano
Imagina que te preparas para un examen de conducir memorizando la ruta exacta que usó tu instructor: cada giro, cada señal, cada bache. Si el examen usa la misma ruta, te irá muy bien. Pero si la ruta cambia, tu rendimiento cae porque no aprendiste a conducir; aprendiste un guion específico.
Eso es sobreajuste: alta precisión en ejemplos familiares, peor desempeño en casos nuevos.
Dropout: una idea sencilla que funciona
Dropout se popularizó por Geoffrey Hinton y colaboradores como un truco de entrenamiento sorprendentemente simple. Durante el entrenamiento, la red apaga aleatoriamente algunas de sus unidades en cada pasada por los datos.
Esto obliga al modelo a no confiar en ninguna vía única ni en un conjunto “favorito” de características. En su lugar, debe repartir la información entre muchas conexiones y aprender patrones que sigan siendo útiles aun cuando partes de la red falten.
Un modelo mental útil: es como estudiar perdiendo aleatoriamente acceso a páginas de tus apuntes—te ves obligado a entender el concepto, no a memorizar una redacción concreta.
Qué mejoró el dropout
El beneficio principal es la mejor generalización: la red se vuelve más fiable en datos que no ha visto antes. En la práctica, dropout hizo que redes más grandes fueran más fáciles de entrenar sin que colapsaran en una memorización inteligente, y se convirtió en una herramienta estándar en muchos montajes de aprendizaje profundo.
AlexNet: el momento en que el aprendizaje profundo se volvió mainstream
Haz que tu proyecto refleje tu marca
Agrega un dominio personalizado para que tu demo parezca un producto real.
Por qué importaban las pruebas de imagen
Antes de AlexNet, el reconocimiento de imágenes no era solo una demo bonita: era una competencia medible. Bancas de pruebas como ImageNet preguntaban: dado una foto, ¿puede tu sistema decir qué hay en ella?
El truco era la escala: millones de imágenes y miles de categorías. Esa magnitud importaba porque separaba ideas que funcionaban en experimentos pequeños de métodos que resistían cuando el mundo se volvía ruidoso.
El progreso en esos marcadores solía ser incremental. Entonces llegó AlexNet (construido por Alex Krizhevsky, Ilya Sutskever y Geoffrey Hinton) y los resultados dejaron de sentirse como una subida constante para convertirse en un salto.
Qué demostró realmente AlexNet
AlexNet mostró que una red convolucional profunda podía superar a las mejores canalizaciones tradicionales de visión por ordenador cuando se combinaban tres ingredientes:
- Convoluciones (capas especiales que explotan la estructura de las imágenes)
- GPUs (para entrenar un modelo grande en tiempo razonable)
- Muchos datos etiquetados (la escala de ImageNet)
No era solo “un modelo más grande”. Era una receta práctica para entrenar redes profundas de forma efectiva en tareas del mundo real.
Convolución, explicado visualmente (sin matemáticas)
Imagina deslizar una pequeña “ventana” por una foto—como mover un sello postal sobre la imagen. Dentro de esa ventana, la red busca un patrón simple: un borde, una esquina, una franja. Ese comprobador de patrones se reutiliza en toda la imagen, por lo que puede encontrar “cosas tipo borde” estén donde estén.
Apila suficientes de estas capas y obtienes una jerarquía: los bordes se vuelven texturas, las texturas se vuelven partes (como ruedas) y las partes se vuelven objetos (como bicicletas).
Por qué cambió la atención de la industria
AlexNet hizo que el aprendizaje profundo pareciera fiable y merecedor de inversión. Si las redes profundas podían dominar un banco de pruebas difícil y público, probablemente mejorarían productos también—búsqueda, etiquetado de fotos, funciones de cámara, herramientas de accesibilidad y más.
Ayudó a convertir las redes neuronales de “investigación prometedora” a una dirección obvia para equipos que construyen sistemas reales.
Qué cambió: datos, cómputo y entrenamiento práctico
El aprendizaje profundo no “llegó de la noche a la mañana”. Empezó a parecer drástico cuando unos pocos ingredientes finalmente se alinearon—después de años de trabajo que mostraban que las ideas eran prometedoras pero difíciles de escalar.
Los tres ingredientes que lo hicieron click
Más datos. La web, los smartphones y conjuntos etiquetados grandes (como ImageNet) permitieron que las redes aprendieran de millones de ejemplos en lugar de miles. Con datos pequeños, los modelos grandes tienden a memorizar.
Más cómputo (especialmente GPUs). Entrenar una red profunda significa repetir las mismas operaciones miles de millones de veces. Las GPUs hicieron eso asequible y lo bastante rápido para iterar. Lo que antes tomaba semanas podía tardar días u horas, permitiendo probar más arquitecturas y parámetros.
Mejores trucos de entrenamiento. Mejoras prácticas redujeron la aleatoriedad del “se entrena… o no se entrena”:
- mejores inicializaciones y opciones de optimización
- normalizaciones y pipelines de entrada más limpias
- métodos de regularización como dropout para frenar el sobreajuste
- funciones de activación y patrones arquitectónicos mejorados
Ninguno de estos cambió la idea central de las redes neuronales; cambiaron la fiabilidad para hacerlas funcionar.
Por qué el progreso pareció repentino
Una vez que los datos y el cómputo alcanzaron un umbral, las mejoras empezaron a acumularse. Mejores resultados atrajeron más inversión, que financió datasets más grandes y hardware más rápido, lo que permitió resultados aún mejores. Desde fuera parece un salto; desde dentro, es un efecto compuesto.
Las compensaciones: modelos más grandes, costes mayores
Escalar trae costes reales: más consumo energético, entrenamientos más caros y más esfuerzo para desplegar modelos eficientemente. También aumenta la brecha entre lo que un equipo pequeño puede prototipar y lo que solo laboratorios bien financiados pueden entrenar desde cero.
Cómo aparecen estas ideas en productos que la gente usa
Las ideas clave de Hinton—aprender representaciones útiles, entrenar redes profundas con fiabilidad y prevenir el sobreajuste—no son “características” que señalar en una app. Son la razón por la que muchas funciones cotidianas parecen más rápidas, precisas y menos frustrantes.
Búsqueda y recomendaciones
Los sistemas modernos de búsqueda no solo emparejan palabras clave. Aprenden representaciones de consultas y contenidos para que “mejores auriculares con cancelación de ruido” pueda mostrar páginas que no repiten exactamente la frase. El mismo aprendizaje de representaciones ayuda a los feeds de recomendación a entender que dos ítems son “similares” aunque sus descripciones difieran.
Traducción y herramientas de texto
La traducción automática mejoró dramáticamente cuando los modelos aprendieron patrones por capas (de caracteres a palabras a significado). Aunque el tipo de modelo subyacente haya evolucionado, la hoja de ruta de entrenamiento—grandes datasets, optimización cuidadosa y regularización—sigue marcando cómo los equipos construyen funciones de lenguaje fiables.
Voz y transcripción
Asistentes de voz y dictado dependen de redes que transforman audio ruidoso en texto limpio. La retropropagación es el caballo de trabajo que ajusta esos modelos, mientras que técnicas como dropout les impiden memorizar las peculiaridades de un hablante o un micrófono.
Fotos: etiquetado, agrupado y “buscar por imagen”
Las apps de fotos pueden reconocer rostros, agrupar escenas similares y dejarte buscar “playa” sin etiquetado manual. Eso es aprendizaje de representaciones en acción: el sistema aprende características visuales (bordes → texturas → objetos) que hacen que el etiquetado y la recuperación funcionen a escala.
Dónde los equipos siguen usando estas ideas
Aunque no estés entrenando modelos desde cero, estos principios aparecen en el trabajo diario de producto: empezar con representaciones sólidas (a menudo mediante modelos preentrenados), estabilizar el entrenamiento y la evaluación, y aplicar regularización cuando los sistemas empiezan a “memorizar el benchmark”.
Por eso herramientas modernas de “vibe-coding” pueden parecer tan capaces. Plataformas como Koder.ai se apoyan en LLMs de generación actual y flujos de agentes para ayudar a equipos a convertir especificaciones en lenguaje natural en aplicaciones web, backend o móviles—a menudo más rápido que los procesos tradicionales—mientras permiten exportar código fuente y desplegar como un equipo de ingeniería normal.
Si quieres la intuición de entrenamiento a alto nivel, ve a /blog/backpropagation-explained.
Mitos comunes sobre Hinton y las redes neuronales
Crea un explicador interactivo de IA
Lanza una demo pequeña que explique backprop o dropout con una interfaz interactiva.
Los grandes avances suelen convertirse en historias simples. Eso las hace fáciles de recordar—pero también genera mitos que ocultan lo que realmente pasó y lo que aún importa hoy.
Mito: “Una persona inventó la IA”
Hinton es una figura central, pero las redes neuronales modernas son el resultado de décadas de trabajo de muchos grupos: investigadores que desarrollaron métodos de optimización, gente que construyó datasets, ingenieros que hicieron las GPUs prácticas para entrenamiento y equipos que demostraron ideas a escala.
Incluso dentro del “trabajo de Hinton”, sus estudiantes y colaboradores jugaron papeles clave. La historia real es una cadena de contribuciones que finalmente se alinearon.
Mito: “Las redes neuronales son algo totalmente nuevo”
Las redes neuronales se investigan desde mediados del siglo XX, con periodos de entusiasmo y desencanto. Lo que cambió no fue la existencia de la idea, sino la capacidad para entrenar modelos más grandes con fiabilidad y mostrar victorias claras en problemas reales.
La era del “aprendizaje profundo” es más una resurgencia que una invención súbita.
Mito: “Más capas siempre ganan”
Los modelos más profundos pueden ayudar, pero no son magia. El tiempo de entrenamiento, el coste, la calidad de los datos y los rendimientos decrecientes son limitaciones reales. A veces modelos más pequeños superan a modelos más grandes porque son más fáciles de ajustar, menos sensibles al ruido o mejor adaptados a la tarea.
Mito: “Retropropagación es aprendizaje humano”
La retropropagación es una forma práctica de ajustar parámetros usando retroalimentación etiquetada. Las personas aprenden con muchos menos ejemplos, usan conocimientos previos ricos y no dependen de las mismas señales de error explícitas.
Las redes pueden inspirarse en la biología sin replicar con precisión el cerebro.
Lecciones para el futuro
La historia de Hinton no es solo una lista de inventos. Es un patrón: mantener una idea de aprendizaje simple, probarla sin descanso y mejorar los ingredientes alrededor (datos, cómputo y trucos de entrenamiento) hasta que funcione a escala.
Qué pueden copiar hoy los creadores
Los hábitos más transferibles son prácticos:
- Iterar en bucles cortos. Trata cada ejecución como un experimento pequeño: cambia una cosa, registra el resultado, repite.
- Medir lo que importa. Sigue una métrica clara (precisión, tasa de error, latencia, coste por consulta) y compárala con una línea base. “Mejor” necesita un número.
- Simplificar explicaciones. Si no puedes explicar el objetivo del sistema, sus entradas y modos de fallo a un compañero no técnico, probablemente no puedas lanzarlo de forma segura.
Qué no copiar
Es tentador entender la lección como “los modelos más grandes ganan”. Eso es incompleto.
Perseguir tamaño sin objetivos claros suele llevar a:
- mayores costes sin mejoras visibles para el usuario
- más dificultad para depurar cuando algo falla
- equipos que optimizan benchmarks en vez de resultados de producto
Un mejor por defecto es: comienza pequeño, demuestra valor y luego escala—y escala solo la parte que claramente limita el rendimiento.
Lecturas sugeridas
Si quieres convertir estas lecciones en práctica diaria, estos siguientes artículos son buenos complementos:
- /blog/ai-model-evaluation
- /blog/how-to-reduce-overfitting
- /blog/representation-learning-explained
Una narrativa para recordar
Desde la regla básica de retropropagación, pasando por representaciones que capturan significado, hasta trucos prácticos como dropout y una demo decisiva como AlexNet—el arco es consistente: aprender características útiles a partir de datos, hacer estable el entrenamiento y validar el progreso con resultados reales.
Ese es el manual que vale la pena conservar.
Preguntas frecuentes
¿Por qué importa Geoffrey Hinton si no inventó la IA?
Geoffrey Hinton importa porque, una y otra vez, ayudó a que las redes neuronales funcionaran en la práctica cuando muchos investigadores las consideraban un callejón sin salida.
En lugar de “inventar la IA”, su impacto viene de impulsar el aprendizaje de representaciones, mejorar métodos de entrenamiento y fomentar una cultura de investigación que priorizaba aprender características desde los datos en vez de codificar reglas a mano.
¿Qué cuenta como un avance en redes neuronales en esta guía?
Un “avance” aquí significa que las redes neuronales se volvieron más fiables y útiles: entrenan con mayor estabilidad, aprenden mejores características internas, generalizan mejor a datos nuevos o escalan a tareas más complejas.
Se trata menos de una demostración llamativa y más de convertir una idea en un método repetible en el que los equipos puedan confiar.
¿Qué problema intentaban resolver originalmente las redes neuronales?
Las redes neuronales buscan convertir entradas crudas y ruidosas (píxeles, formas de onda de audio, tokens de texto) en representaciones útiles—características internas que capturan lo importante.
En lugar de que los ingenieros diseñen cada característica, el modelo aprende capas de características a partir de ejemplos, lo que suele ser más robusto cuando cambian las condiciones (iluminación, acentos, redacción).
¿Qué es la retropropagación en palabras sencillas?
La retropropagación es un método de entrenamiento que mejora una red aprendiendo de sus errores:
- Hacer una predicción (pasada hacia delante)
- Medir el error (pérdida)
- Enviar la “culpa” hacia atrás por las capas (pasada hacia atrás)
- Ajustar ligeramente los pesos para reducir el error en el futuro
Funciona junto con algoritmos como el descenso por gradiente, que da pequeños pasos para disminuir la pérdida con el tiempo.
¿Por qué fue tan importante la retropropagación para el aprendizaje profundo?
La retropropagación permitió ajustar muchas capas a la vez de forma sistemática.
Eso importa porque las redes más profundas pueden construir jerarquías de características (por ejemplo, bordes → formas → objetos). Sin una forma fiable de entrenar múltiples capas, la profundidad no solía traducirse en mejoras reales.
¿Qué son las máquinas de Boltzmann y por qué importaron?
Las máquinas de Boltzmann asignan una energía (una puntuación) a configuraciones completas de unidades; baja energía significa que “esta configuración tiene sentido”.
Fueron influyentes porque:
- Plantearon el aprendizaje como modelado de una distribución de probabilidad, no solo predicción de etiquetas
- Fomentaron el aprendizaje no supervisado (aprender estructura sin respuestas explícitas)
- Inspiraron ideas prácticas como la divergencia contrastiva y enfoques basados en energía posteriores
Hoy son menos comunes en producto porque el entrenamiento clásico escala con mucha lentitud.
¿Qué es el aprendizaje de representaciones y por qué mejoró el rendimiento?
El aprendizaje de representaciones significa que el modelo aprende sus propias características internas que facilitan la tarea, en vez de depender de rasgos diseñados por humanos.
En la práctica, esto suele mejorar la robustez: las características aprendidas se adaptan a la variación real de los datos (ruido, distintas cámaras, distintos hablantes) mejor que tuberías rígidas de características hechas a mano.
¿Qué son las redes de creencias profundas y qué problema resolvieron?
Las redes de creencias profundas (DBN) hicieron la profundidad más práctica usando un preentrenamiento capa a capa.
Cada capa primero aprende la estructura de su entrada (a menudo sin etiquetas), lo que da a la red completa un “arranque en caliente”. Después, toda la pila se ajusta finamente para una tarea concreta como la clasificación.
¿Cómo reduce el sobreajuste el dropout?
Dropout combate el sobreajuste “apagando” aleatoriamente algunas unidades durante el entrenamiento.
Eso impide que la red dependa en exceso de una sola vía y la fuerza a aprender características que sigan funcionando aunque partes del modelo falten, mejorando la generalización a datos nuevos en muchos casos.
¿Por qué fue AlexNet un punto de inflexión para el aprendizaje profundo?
AlexNet mostró una receta práctica que escalaba: redes convolucionales profundas + GPUs + muchos datos etiquetados (ImageNet).
No fue solo un “modelo más grande”: demostró consistentemente que el aprendizaje profundo podía superar las canalizaciones tradicionales de visión por ordenador en un banco de pruebas duro y público, lo que desencadenó inversión industrial amplia.