27 sept 2025·8 min
Despliegues Azul/Verde y Canario: una estrategia clara de lanzamiento
Aprende cuándo usar despliegues Azul/Verde vs Canario, cómo funciona el desplazamiento de tráfico, qué monitorizar y pasos prácticos de rollout y rollback para lanzamientos más seguros.
Qué significan los despliegues Blue/Green y Canary
Enviar código nuevo siempre implica riesgo por una razón sencilla: no sabes realmente cómo se comportará hasta que usuarios reales lo usen. Blue/Green y Canary son dos formas comunes de reducir ese riesgo manteniendo el tiempo de inactividad cercano a cero.
Blue/Green en términos sencillos
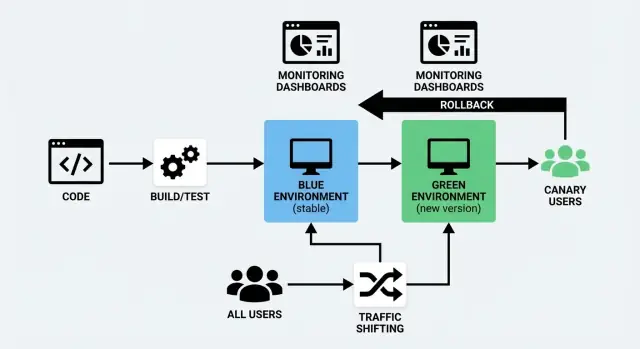
Un despliegue azul/verde usa dos entornos separados pero similares:
- Azul: la versión que actualmente atiende a los usuarios (la configuración “en vivo”).
- Verde: un segundo entorno listo donde despliegas la nueva versión.
Preparas el entorno Verde en segundo plano: despliegas la nueva compilación, ejecutas comprobaciones, lo calientas; luego cambias el tráfico de Azul a Verde cuando confías en él. Si algo sale mal, puedes volver atrás rápidamente.
La idea clave no es “dos colores”, sino un corte limpio y reversible.
Canary en términos sencillos
Un lanzamiento canario es un despliegue gradual. En lugar de cambiar a todos a la vez, envías la nueva versión a una pequeña porción de usuarios primero (por ejemplo, 1–5%). Si todo parece sano, amplías el despliegue paso a paso hasta que el 100% del tráfico esté en la nueva versión.
La idea clave es aprender con tráfico real antes de comprometerte por completo.
El objetivo compartido: lanzamientos más seguros con menos tiempo de inactividad
Ambos enfoques son estrategias de despliegue que buscan:
- reducir el impacto sobre usuarios cuando algo falla
- soportar un despliegue sin tiempo de inactividad (o lo más cercano que permita tu sistema)
- hacer las reversiones menos estresantes y más previsibles
Lo hacen de formas distintas: Blue/Green se centra en un cambio rápido entre entornos, mientras que Canary se centra en la exposición controlada mediante desplazamiento de tráfico.
No existe una opción “mejor” universal
Ningún enfoque es automáticamente superior. La elección correcta depende de cómo se usa tu producto, cuánto confías en tus pruebas, qué tan rápido necesitas feedback y qué tipo de fallos quieres evitar.
Muchos equipos también los combinan: usan Blue/Green por simplicidad operativa e introducen técnicas Canary para exponer usuarios gradualmente en servicios de mayor riesgo.
En las siguientes secciones los compararemos directamente y mostraremos cuándo suele funcionar mejor cada uno.
Blue/Green vs Canary: Comparación rápida
Blue/Green y Canary son formas de publicar cambios sin interrumpir a los usuarios, pero difieren en cómo el tráfico pasa a la nueva versión.
Cómo se cambia el tráfico
Blue/Green ejecuta dos entornos completos: “Azul” (actual) y “Verde” (nuevo). Validas Verde y después cambias todo el tráfico de golpe, como si giraras un interruptor controlado.
Canary lanza la nueva versión a una pequeña porción de usuarios primero (por ejemplo 1–5%), y luego desplaza el tráfico gradualmente mientras observas el rendimiento real.
Pros y contras que importan
| Factor | Blue/Green | Canary |
|---|---|---|
| Velocidad | Corte muy rápido tras la validación | Más lento por diseño (despliegue escalonado) |
| Riesgo | Medio: una mala versión afecta a todos tras el cambio | Menor: los problemas suelen aparecer antes del despliegue completo |
| Complejidad | Moderada (dos entornos, cambio limpio) | Más alta (división de tráfico, análisis, pasos graduales) |
| Coste | Más alto (duplica capacidad durante el despliegue) | A menudo menor (puedes escalar usando capacidad existente) |
| Mejor para | Cambios grandes y coordinados | Mejoras pequeñas y frecuentes |
Guía simple para decidir
Elige Blue/Green cuando quieras un momento de corte limpio y predecible—especialmente para cambios grandes, migraciones o despliegues que requieren una separación clara “viejo vs nuevo”.
Elige Canary cuando publiques a menudo, quieras aprender con uso real de forma segura y prefieras reducir el radio de impacto dejando que las métricas guíen cada paso.
Si dudas, empieza con Blue/Green por simplicidad operativa y añade Canary en servicios de mayor riesgo una vez que la monitorización y las prácticas de rollback estén consolidadas.
Cuándo Blue/Green es la opción adecuada
Blue/Green es una buena opción cuando quieres que los lanzamientos parezcan un “interruptor”: ejecutas dos entornos parecidos en producción, Azul (actual) y Verde (nuevo). Cuando Verde está verificado, rediriges a los usuarios.
Necesitas casi cero tiempo de inactividad
Si tu producto no puede tolerar ventanas de mantenimiento visibles—flujos de pago, sistemas de reservas, paneles autenticados—Blue/Green ayuda porque la nueva versión se inicia, se calienta y se comprueba antes de enviar usuarios reales. La mayor parte del tiempo de despliegue sucede al margen, no delante de los clientes.
Quieres el rollback más simple posible
La reversión suele ser solo volver a enrutar el tráfico a Azul. Esto es valioso cuando:
- una versión debe revertirse en minutos
- quieres evitar hotfixes de emergencia bajo presión
- necesitas una respuesta a fallos clara y repetible
El beneficio clave es que la reversión no exige reconstruir o volver a desplegar: es un cambio de tráfico.
Tus cambios de base de datos pueden mantenerse compatibles
Blue/Green es más sencillo cuando las migraciones de BD son compatibles hacia atrás, porque durante un breve periodo azul y verde pueden coexistir (y leer/escribir, según el enrutamiento y los jobs).
Buenos casos de uso incluyen:
- cambios de esquema aditivos (nuevas columnas nulas, nuevas tablas)
- ampliar formatos de datos que el código antiguo puede ignorar
Casos riesgosos: eliminar columnas, renombrar campos o cambiar significados en el lugar—eso puede romper la promesa de “volver atrás” a menos que planifiques migraciones en varios pasos.
Puedes permitir entornos duplicados y control de enrutamiento
Blue/Green requiere capacidad extra (dos stacks) y una forma de dirigir tráfico (balanceador, ingress, o enrutamiento de plataforma). Si ya tienes automatización para provisionar entornos y una palanca de enrutamiento limpia, Blue/Green se vuelve una opción práctica por defecto para despliegues de alta confianza y bajo drama.
Cuándo los lanzamientos Canary tienen más sentido
Un lanzamiento canario despliega un cambio a una pequeña porción de usuarios primero, aprendes de lo que ocurre y luego amplías. Es la opción correcta cuando quieres reducir riesgo sin parar el mundo con un gran despliegue "todo a la vez".
Tienes mucho tráfico y señales claras
Canary funciona mejor en apps de alto tráfico porque incluso el 1–5% puede dar datos significativos rápido. Si ya mides métricas claras (tasa de errores, latencia, conversión, finalización de checkout, tiempos de API), puedes validar el despliegue con patrones de uso real en lugar de depender solo de entornos de prueba.
Te preocupan el rendimiento y los casos límite
Algunos problemas solo aparecen bajo carga real: consultas lentas a BD, fallos de caché, latencia regional, dispositivos inusuales o flujos raros de usuarios. Con un canario, confirmas que el cambio no aumenta errores ni degrada rendimiento antes de llegar a todos.
Necesitas despliegues escalonados, no un único corte
Si tu producto se entrega con frecuencia, tiene varios equipos contribuyendo o incluye cambios que pueden introducirse gradualmente (ajustes de UI, experimentos de precios, lógica de recomendaciones), los canarios encajan naturalmente. Puedes avanzar de 1% → 10% → 50% → 100% según lo que veas.
Las feature flags son parte de tu caja de herramientas
Canary combina muy bien con banderas de características: puedes desplegar código de forma segura y luego habilitar funcionalidades para un subconjunto de usuarios, regiones o cuentas. Eso hace los rollbacks menos dramáticos—a menudo basta apagar una bandera en vez de volver a desplegar.
Si aspiras a entrega progresiva, los lanzamientos canarios suelen ser el punto de partida más flexible.
See also: /blog/feature-flags-and-progressive-delivery
Fundamentos del desplazamiento de tráfico (sin jerga)
El desplazamiento de tráfico significa controlar quién recibe la nueva versión y cuándo. En lugar de pasar a todos a la vez, mueves las solicitudes de forma gradual (o selectiva) desde la versión antigua a la nueva. Es el corazón práctico tanto de un despliegue azul/verde como de un lanzamiento canario—y también lo que hace posible un despliegue sin tiempo de inactividad.
El “volante”: dónde se enruta el tráfico
Puedes desplazar tráfico en varios puntos de tu stack. La elección depende de lo que ya uses y de cuán fino necesites el control.
- Balanceador de carga: reparte solicitudes entre dos entornos o grupos de servidores.
- Controlador Ingress (Kubernetes): enruta tráfico a distintos Services según reglas.
- Service mesh: controla el tráfico entre servicios con reglas precisas y mayor visibilidad.
- CDN / enrutamiento en el borde: útil cuando quieres decisiones de enrutamiento cercanas al usuario, a menudo para tráfico web.
No necesitas todas las capas. Elige una fuente de verdad para las decisiones de enrutamiento para que tu gestión de lanzamientos no se vuelva conjetural.
Formas comunes de dividir tráfico
La mayoría de equipos usa una (o mezcla) de estas aproximaciones para el desplazamiento de tráfico:
- Basada en porcentaje: 1% → 5% → 25% → 50% → 100%. Patrón clásico canario.
- Basada en cabeceras: enrutar solicitudes con una cabecera específica (por ejemplo, de herramientas QA o testers internos) a la nueva versión.
- Cohortes de usuarios: cambiar grupos específicos primero—empleados, usuarios beta, una región o un nivel de cliente.
El porcentaje es fácil de explicar, pero las cohortes suelen ser más seguras porque controlas qué usuarios ven el cambio (y evitas sorprender a tus clientes más importantes la primera hora).
Sesiones y cachés: los dos “puntos a tener en cuenta”
Dos cosas suelen romper planes de despliegue aparentemente sólidos:
Sesiones pegajosas (session affinity). Si tu sistema liga a un usuario a un servidor/versión, una división del 10% puede no comportarse como un 10%. También puede provocar errores cuando los usuarios rebotan entre versiones en una misma sesión. Si puedes, usa almacenamiento de sesión compartido o garantiza que el enrutamiento mantenga a un usuario en una sola versión.
Calentamiento de cachés. Las nuevas versiones suelen golpear cachés frías (CDN, caché de aplicación, caché de consultas DB). Eso puede parecer una regresión de rendimiento aunque el código esté bien. Planea tiempo para calentar cachés antes de aumentar tráfico, especialmente en páginas de alto tráfico y endpoints costosos.
Haz los cambios de tráfico una operación controlada
Trata los cambios de enrutamiento como cambios de producción, no como clics improvisados.
Documenta:
- quién puede cambiar los porcentajes
- cómo se aprueba (on-call? release manager? ticket de cambio?)
- dónde se hace (config del balanceador, reglas de ingress, política del mesh)
- qué significa “parar” (el disparador para pausar el despliegue y seguir el plan de reversión)
Este pequeño gobierno evita que bienintencionadas personas “lo suban al 50%” mientras aún evalúas si el canario está sano.
Qué monitorizar durante un despliegue
Controla tu ruta de lanzamiento
Mantén el control exportando el código fuente cuando lo necesites.
Un despliegue no es solo “¿pasó la publicación?” sino “¿los usuarios reales experimentan peor servicio?” La forma más fácil de mantener la calma durante un Blue/Green o Canary es vigilar un conjunto pequeño de señales que respondan: ¿el sistema está sano y el cambio perjudica a los clientes?
Las cuatro señales centrales: errores, latencia, saturación, impacto en el usuario
Tasa de errores: monitorea 5xx HTTP, fallos de solicitud, timeouts y errores de dependencias (BD, pagos, APIs de terceros). Un canario que aumenta “errores pequeños” puede generar mucha carga de soporte.
Latencia: observa p50 y p95 (y p99 si lo tienes). Un cambio que mantiene la latencia media puede aún crear ralentizaciones en la cola larga que los usuarios notan.
Saturación: mira qué tan “lleno” está tu sistema—CPU, memoria, IO de disco, conexiones DB, profundidad de colas, pools de hilos. Los problemas de saturación suelen aparecer antes de los fallos completos.
Señales de impacto al usuario: mide lo que los usuarios realmente experimentan—fallos de checkout, éxito de inicio de sesión, resultados de búsqueda, tasa de caídas de la app, tiempos de carga de páginas clave. Estas son a menudo más significativas que las métricas de infraestructura solas.
Crea un “panel de lanzamiento” que todo el mundo entienda
Haz un panel pequeño que quepa en una pantalla y compártelo en tu canal de lanzamiento. Manténlo consistente en cada despliegue para que nadie pierda tiempo buscando gráficos.
Incluye:
- tasa de errores (total + endpoints clave)
- latencia (p50/p95 para rutas críticas)
- saturación (los 3 cuellos de botella principales del stack, por ejemplo CPU de la app, conexiones BD, profundidad de colas)
- KPIs de impacto al usuario (tus 1–3 flujos críticos de negocio)
Si haces un lanzamiento canario, segmenta métricas por versión/grupo de instancias para comparar canario vs baseline directamente. Para despliegue azul/verde, compara el entorno nuevo contra el antiguo durante la ventana de corte.
Establece umbrales claros para pausar/revertir
Decide las reglas antes de empezar a mover tráfico. Ejemplos de umbrales:
- la tasa de errores aumenta X% sobre la baseline durante Y minutos
- p95 excede un límite fijo (o sube X% sobre la baseline)
- un KPI de usuario cae por debajo de un mínimo aceptable
Los números dependen del servicio, pero lo importante es el acuerdo. Si todos conocen el plan de reversión y los disparadores, se evita el debate mientras los clientes se ven afectados.
Alertas enfocadas en la ventana de despliegue
Añade (o ajusta temporalmente) alertas específicamente durante las ventanas de despliegue:
- picos inesperados en 5xx/timeouts
- regresión súbita de latencia en rutas clave
- crecimiento rápido en señales de saturación (pools de conexiones, colas)
Mantén las alertas accionables: “qué cambió, dónde, y qué hacer después”. Si tus alertas son ruidosas, la gente perderá la señal importante cuando el desplazamiento de tráfico esté en marcha.
Comprobaciones previas al lanzamiento que atrapan problemas temprano
La mayoría de fallos en despliegues no vienen de “bugs grandes”. Vienen de desajustes pequeños: un valor de configuración faltante, una migración mal aplicada, un certificado expirado o una integración que se comporta distinto en el nuevo entorno. Las comprobaciones previas al lanzamiento son tu oportunidad para captar esos problemas cuando el radio de impacto sigue siendo pequeño.
Empieza con health checks y smoke tests
Antes de mover tráfico (ya sea un cambio azul/verde o un pequeño canario), confirma que la nueva versión está viva y puede servir solicitudes.
- Asegura que los endpoints de salud reporten OK (no solo “el proceso está vivo”)
- Valida dependencias: BD, caché, colas, almacenamiento de objetos, proveedores de email/SMS
- Confirma que secretos y variables de entorno están presentes y con el scope correcto
Ejecuta pruebas rápidas end-to-end contra el nuevo entorno
Los tests unitarios son útiles, pero no prueban el sistema desplegado. Corre una suite E2E corta contra el nuevo entorno que termine en minutos, no horas.
Enfócate en flujos que crucen límites de servicio (web → API → BD → terceros) e incluye al menos una solicitud “real” por integración clave.
Verifica trayectorias de usuario críticas (las que pagan las cuentas)
Los tests automáticos a veces pasan por alto lo obvio. Haz una verificación dirigida y humana de los flujos centrales:
- inicio de sesión y restablecimiento de contraseña
- flujo de checkout o pago (incluyendo rutas de fallo)
- acciones básicas “crear / actualizar / borrar” que los usuarios realizan todos los días
Si soportas múltiples roles (admin vs cliente), prueba al menos una trayectoria por rol.
Mantén una checklist de preparación previa al lanzamiento
Una checklist convierte el conocimiento tribal en una estrategia repetible. Manténla corta y accionable:
- migraciones de BD aplicadas y reversibles (o claramente seguras)
- observabilidad lista: logs, dashboards, alertas para métricas clave
- plan de reversión revisado (quién, cómo y qué significa “parar”)
Cuando estas comprobaciones son rutinarias, el desplazamiento de tráfico se convierte en un paso controlado, no en un salto de fe.
Despliegue Blue/Green: un playbook práctico
Prueba lanzamientos más seguros rápido
Crea y despliega una pequeña app piloto; practica la reversión segura con instantáneas.
Un despliegue azul/verde es más fácil si lo tratas como una checklist: preparar, desplegar, validar, cambiar, observar y limpiar.
1) Desplegar en Verde (sin tocar usuarios)
Envía la nueva versión al entorno Verde mientras Azul sigue atendiendo tráfico real. Mantén configuraciones y secretos alineados para que Verde sea un espejo verdadero.
2) Validar Verde antes de cualquier cambio de tráfico
Haz comprobaciones rápidas y de alta señal: la app arranca limpia, las páginas clave cargan, pagos/inicios de sesión funcionan y los logs parecen normales. Si tienes smoke tests automáticos, ejecútalos ahora. Este también es el momento para verificar que dashboards y alertas están activos para Verde.
3) Planear migraciones de BD de forma segura (expandir/contraer)
Blue/Green se complica cuando cambia la base de datos. Usa un enfoque expandir/contraer:
- Expandir: añade columnas/tablas nuevas de forma compatible hacia atrás.
- Despliega Verde para que pueda funcionar con ambos esquemas.
- Contraer: elimina campos antiguos solo después de que Azul sea retirado y estés seguro de la estabilidad del nuevo código.
Esto evita situaciones “Verde funciona, Azul se rompe” durante el cambio.
4) Calentar cachés y manejar jobs en background
Antes de cambiar el tráfico, calienta cachés críticos (home, consultas comunes) para que los usuarios no paguen el coste de “arranque en frío”.
Para jobs en background/cron, decide quién los ejecuta:
- ejecuta jobs en un solo entorno durante el corte para evitar procesamiento doble
5) Cambiar el tráfico y luego observar
Cambia el enrutamiento de Azul a Verde (balanceador/DNS/ingress). Vigila la tasa de errores, latencia y métricas de negocio durante una ventana corta.
6) Verificación post-cambio y limpieza
Haz una comprobación de estilo usuario real y luego mantiene Azul disponible brevemente como fallback. Una vez estable, deshabilita jobs en Azul, archiva logs y reprovisiona Azul para reducir costes y confusión.
Despliegue Canary: un playbook práctico
Un despliegue canario trata de aprender de forma segura. En lugar de enviar a todos a la nueva versión, expones una pequeña porción de tráfico real, observas de cerca y solo entonces amplías. La meta no es “ir despacio”, sino “demostrar que es seguro” con evidencia en cada paso.
Un plan de rampa sencillo (1–5% → 25% → 50% → 100%)
- Preparar el canario
Despliega la nueva versión junto a la versión estable actual. Asegúrate de poder enrutar un porcentaje definido de tráfico a cada una y de que ambas versiones sean visibles en la monitorización (dashboards separados o tags ayudan).
- Etapa 1: 1–5%
Empieza pequeño. Aquí salen rápido problemas obvios: endpoints rotos, configs faltantes, sorpresas en migraciones de BD o picos de latencia inesperados.
Toma notas para la etapa:
- qué cambió en este lanzamiento (incluyendo cambios “pequeños” de config)
- qué esperabas que pasara
- qué observaste (errores, latencia, impacto en usuarios)
- Etapa 2: 25%
Si la primera etapa está limpia, sube a alrededor de un cuarto del tráfico. Ahora verás más variedad del mundo real: comportamientos distintos, dispositivos de cola larga, casos límite y mayor concurrencia.
- Etapa 3: 50%
Con la mitad del tráfico, problemas de capacidad y rendimiento quedan más claros. Si vas a alcanzar un límite de escalado, a menudo verás señales tempranas aquí.
- Etapa 4: 100% (promoción)
Cuando las métricas estén estables y el impacto en usuarios sea aceptable, mueve todo el tráfico a la nueva versión y declárala promovida.
Elegir intervalos de rampa (cuánto esperar en cada paso)
El tiempo de cada etapa depende del riesgo y del volumen de tráfico:
- Cambio de alto riesgo o poco tráfico: espera más en cada etapa para obtener señal suficiente (p. ej., 30–60 minutos o más). Servicios de bajo tráfico pueden necesitar horas para ver patrones significativos.
- Cambio de bajo riesgo con alto tráfico: etapas más cortas pueden funcionar (p. ej., 5–15 minutos) porque recoges datos rápido.
También considera ciclos de negocio. Si tu producto tiene picos (hora de comida, fines de semana, procesos de facturación), corre el canario el tiempo suficiente para cubrir las condiciones que suelen causar problemas.
Automatiza promoción y reversión
Los despliegues manuales generan dudas e inconsistencia. Cuando sea posible, automatiza:
- promoción cuando métricas clave se mantengan dentro de umbrales durante una ventana definida
- reversión cuando se violen umbrales (por ejemplo, tasa de errores o latencia)
La automatización no elimina el juicio humano: elimina la demora.
Trata cada etapa como un experimento
Para cada rampa escribe:
- resumen del cambio (qué es diferente exactamente)
- criterios de éxito (qué métricas deben permanecer estables)
- resultados observados (qué viste, incluido “nada inusual”)
- decisión (promover, mantener o revertir) y por qué
Estas notas convierten la historia de tus despliegues en un playbook para el próximo lanzamiento—y facilitan diagnosticar incidentes futuros.
Planes de reversión y manejo de fallos
Las reversiones son más fáciles cuando decides antes qué es “malo” y quién puede pulsar el botón. Un plan de reversión no es pesimismo: es cómo evitas que fallos pequeños se conviertan en caídas prolongadas.
Define disparadores claros para la reversión
Elige una lista corta de señales y fija umbrales explícitos para no debatir durante un incidente. Disparadores comunes:
- tasa de errores: picos en 5xx, checkouts fallidos, fallos de login o timeouts de API
- latencia: p95/p99 sobre un límite acordado durante una ventana sostenida (p. ej., 5–10 minutos)
- KPIs de negocio: caídas súbitas en conversión, éxito de pagos, registros o aumento de cancelaciones
Haz el disparador medible (“p95 > 800ms durante 10 minutos”) y asígnalo a un responsable (on-call, release manager) con permiso para actuar de inmediato.
Mantén la reversión rápida (y aburrida)
La velocidad importa más que la elegancia. Tu reversión debería ser una de estas:
- invertir el desplazamiento de tráfico (típico para blue/green y canary): mover tráfico de vuelta a la versión conocida buena
- re-deplegar la versión previa: si cambió la infraestructura, volver a la última build estable y re-ejecutar checks de salud
Evita “arreglar manualmente y continuar” como primer movimiento. Estabiliza primero, investiga después.
Planifica rollbacks parciales
En un canario, algunos usuarios pueden haber creado datos bajo la nueva versión. Decide de antemano:
- ¿los usuarios canarios se reencaminarán inmediatamente o se mantienen en el canario mientras evalúas?
- Si cambiaron formatos de datos, ¿la BD es compatible hacia atrás? Si no, la reversión puede requerir una mitigación separada.
Revisión posterior que mejore el próximo despliegue
Una vez estable, escribe una nota breve de post-mortem: qué provocó la reversión, qué señales faltaron y qué cambiarás en la checklist. Trátalo como un ciclo de mejora de producto para tu proceso de lanzamientos, no como una búsqueda de culpables.
Banderas de características y entrega progresiva
Despliega con confianza
Despliega y aloja tu app con una forma fácil de tomar instantáneas y revertir.
Las banderas de características permiten separar “desplegar” (enviar código a producción) de “habilitar” (activarlo para usuarios). Eso es importante porque puedes usar la misma canalización—blue/green o canary—mientras controlas la exposición con un interruptor.
Despliega sin presión, libera con intención
Con banderas, puedes mergear y desplegar con seguridad aunque una característica no esté lista para todos. El código está presente pero inactivo. Cuando confías, habilitas la bandera gradualmente—a menudo más rápido que publicar una nueva build—y si algo va mal, la desactivas igual de rápido.
Habilitación dirigida (no todo o nada)
La entrega progresiva trata de aumentar el acceso en pasos deliberados. Una bandera puede habilitarse para:
- un grupo específico de usuarios (personal interno, beta, clientes de pago)
- una región (empezar por un país o centro de datos)
- un porcentaje de usuarios (1% → 10% → 50% → 100%)
Esto es útil cuando un canario dice que la nueva versión está sana, pero quieres gestionar el riesgo de la funcionalidad por separado.
Guardarraíles que evitan la “deuda de banderas”
Las banderas son poderosas, pero solo si se gobiernan. Algunos guardarraíles las mantienen ordenadas y seguras:
- propiedad: cada bandera tiene un equipo o responsable
- caducidad: fija una fecha de eliminación (o revisión) para que no se acumulen
- documentación: describe qué hace la bandera, a quién afecta y cómo revertirla
Una regla práctica: si alguien no puede responder “¿qué ocurre si la apagamos?” la bandera no está lista.
For deeper guidance on using flags as part of a release strategy, see /blog/feature-flags-release-strategy.
Cómo elegir tu estrategia y empezar
Elegir entre blue/green y canary no es “qué es mejor”, sino qué riesgo quieres controlar y con qué recursos operativos cuentas.
Una forma rápida de decidir
Si tu prioridad es un corte limpio y un botón fácil de “volver a la versión anterior”, blue/green suele ser la opción más simple.
Si tu prioridad es reducir el radio de impacto y aprender con tráfico real antes de ampliar, canary es más seguro—especialmente cuando los cambios son frecuentes o difíciles de probar por completo.
Una regla práctica: empieza con el enfoque que tu equipo pueda ejecutar de forma consistente a las 2 a.m. cuando algo falle.
Comienza pequeño: pilota una cosa
Elige un servicio (o un flujo visible por el usuario) y haz un piloto durante unos lanzamientos. Selecciona algo suficientemente importante, pero no tan crítico que paralice a todos. La meta es crear memoria muscular sobre desplazar tráfico, monitorizar y revertir.
Escribe un runbook simple (y asigna responsabilidad)
Mantenlo corto—una página está bien:
- qué es “bueno” (métricas clave y umbrales)
- quién está a cargo durante el despliegue
- cómo pausar, revertir y comunicar
Asegura que la responsabilidad esté clara. Una estrategia sin dueño se vuelve una sugerencia.
Usa primero lo que ya tienes
Antes de añadir plataformas nuevas, mira las herramientas que ya usas: ajustes del balanceador, scripts de despliegue, monitorización e incidencias. Añade nuevas herramientas solo cuando eliminen fricción real que sentiste en el piloto.
Si construyes y lanzas servicios nuevos rápido, plataformas que combinan generación de apps con controles de despliegue pueden también reducir la carga operativa. Por ejemplo, Koder.ai es una plataforma "vibe-coding" que permite a equipos crear apps web, backend y móviles desde una interfaz de chat—y luego desplegarlas y hospedarlas con características de seguridad prácticas como snapshots y rollback, además de soporte para dominios personalizados y exportación de código fuente. Esas capacidades encajan con el objetivo central de este artículo: hacer lanzamientos repetibles, observables y reversibles.
Siguientes pasos sugeridos
Si quieres ver opciones de implementación y flujos soportados, revisa /pricing y /docs/deployments. Después programa tu primer piloto, documenta lo que funcionó y mejora tu runbook tras cada despliegue.