Qué significa “velocidad” en la entrega real de producto
“Entregar más rápido” no es solo escribir código rápidamente. La velocidad real de entrega es el tiempo entre que una idea se convierte en una mejora fiable que los usuarios pueden sentir—y el equipo aprende si funcionó.
Las métricas que realmente describen la velocidad
Los equipos discuten sobre la velocidad porque miden cosas diferentes. Una visión práctica es un conjunto pequeño de métricas de entrega:
- Lead time: cuánto tarda desde “decidimos hacer esto” hasta “está en vivo para los usuarios”.
- Cycle time: cuánto tiempo pasa un trabajo “en progreso” una vez que alguien lo empieza.
- Frecuencia de despliegue: con qué frecuencia puedes liberar con seguridad (diario, semanal, bajo demanda).
- Tiempo para aprender: qué tan rápido obtienes una señal fiable (uso, tickets de soporte, retención, ingresos) que te diga qué hacer después.
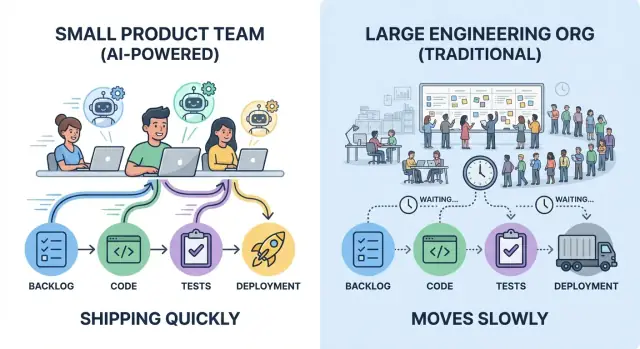
Un equipo pequeño que despliega cinco pequeños cambios por semana suele aprender más rápido que una organización grande que despliega una gran release al mes—incluso si la release mensual contiene más código.
Qué significa “usar IA” (y qué no)
En la práctica, “IA para ingeniería” suele ser un conjunto de asistentes integrados en el trabajo existente:
- Copilotos para redactar código, refactors y documentación
- Generación y mantenimiento de pruebas
- Soporte en revisiones de código (detectar casos límite, sugerir simplificaciones)
- Bots de soporte y ops (resumir incidentes, redactar runbooks, responder “¿dónde está esto implementado?”)
La IA ayuda sobre todo con el rendimiento por persona y reducir el retrabajo—pero no reemplaza el buen juicio de producto, requisitos claros ni la propiedad.
La idea central: sobrecarga vs. bucles de iteración
La velocidad está mayormente limitada por dos fuerzas: la sobrecarga de coordinación (handoffs, aprobaciones, esperas) y los bucles de iteración (construir → publicar → observar → ajustar). La IA amplifica a los equipos que ya mantienen el trabajo pequeño, las decisiones claras y la retroalimentación estrecha.
Sin hábitos ni guardarraíles—pruebas, revisión de código y disciplina de release—la IA también puede acelerar el trabajo equivocado con la misma eficiencia.
El impuesto oculto de la escala: la sobrecarga de coordinación
Los grandes equipos de ingeniería no solo añaden personas—añaden conexiones. Cada nuevo límite de equipo introduce trabajo de coordinación que no entrega funciones: sincronizar prioridades, alinear diseños, negociar propiedad y enrutar cambios por los canales “correctos”.
Dónde se va realmente el tiempo
La sobrecarga de coordinación aparece en lugares familiares:
- Reuniones para “poner a todos en la misma página” (estado, planificación, alineación de roadmap)
- Revisiones que requieren múltiples partes interesadas (seguridad, privacidad, arquitectura, marca)
- Handoffs entre roles o equipos (producto → diseño → ingeniería → plataforma → SRE)
- Documentación escrita para habilitar esos handoffs y justificar decisiones más tarde
Nada de esto es inherentemente malo. El problema es que se complica—y crece más rápido que la plantilla.
Las dependencias crean espera, no trabajo
En una gran organización, un cambio simple suele cruzar varias líneas de dependencia: un equipo posee la UI, otro el API, un equipo de plataforma controla el despliegue y un grupo de infosec la aprobación. Incluso si cada grupo es eficiente, el tiempo en cola domina.
Los cuellos de botella comunes parecen:
- Una feature bloqueada por una junta de revisión arquitectónica trimestral
- Un pequeño ajuste de API esperando dos semanas en la backlog de plataforma
- Un release retenido hasta que se abre una ventana central de QA o cumplimiento
- “Necesitamos el OK del Equipo X” que se convierte en un hilo de tres reuniones
Cómo la sobrecarga estira el lead time
El lead time no es solo tiempo de codificación; es tiempo transcurrido desde la idea hasta producción. Cada apretón de manos añade latencia: esperas la siguiente reunión, el siguiente revisor, el siguiente sprint, el siguiente hueco en la cola de otra persona.
Los equipos pequeños suelen ganar porque mantienen la propiedad ajustada y las decisiones locales. Eso no elimina las revisiones—reduce el número de saltos entre “listo” y “entregado”, que es donde las grandes organizaciones silenciosamente pierden días y semanas.
Los equipos pequeños ganan con propiedad clara y menos handoffs
La velocidad no es solo teclear más rápido—es hacer que menos gente espere. Los equipos pequeños tienden a publicar rápidamente cuando el trabajo tiene propiedad single-threaded: una persona (o pareja) claramente responsable que impulsa una funcionalidad desde la idea hasta producción, con un decisor nombrado que puede resolver trade-offs.
La propiedad single-threaded abarata las decisiones
Cuando un propietario es responsable por los resultados, las decisiones no rebotan entre producto, diseño, ingeniería y “el equipo de plataforma” en un bucle. El propietario recoge insumos, toma la decisión y avanza.
Esto no significa trabajar en solitario. Significa que todos saben quién dirige, quién aprueba y qué significa “hecho”.
Menos handoffs significa menos retrabajo
Cada handoff añade dos tipos de costo:
- Pérdida de contexto: los detalles se simplifican, las suposiciones quedan tácitas y los casos límite desaparecen.
- Retrabajo: la siguiente persona descubre restricciones tarde y devuelve el trabajo upstream.
Los equipos pequeños evitan esto manteniendo el problema dentro de un bucle estrecho: el mismo propietario participa en requisitos, implementación, despliegue y seguimiento. El resultado es menos momentos de “espera, eso no es lo que quería”.
Cómo la IA ayuda a un propietario a cubrir más terreno
La IA no reemplaza la propiedad—la extiende. Un solo propietario puede seguir siendo eficaz en más tareas usando IA para:
- Redactar especificaciones de primera versión, notas de lanzamiento y actualizaciones para clientes
- Resumir hilos largos, historial de incidentes o decisiones pasadas en un breve informe
- Estructurar la implementación: generar boilerplate, esquemas de pruebas, scripts de migración o stubs de cliente API
El propietario aún valida y decide, pero el tiempo desde la página en blanco hasta un borrador operativo cae bruscamente.
Si usas un flujo vibe-coding (por ejemplo, Koder.ai), este modelo de “un propietario cubre toda la porción” es aún más sencillo: puedes redactar un plan, generar una UI en React más un esqueleto backend en Go/PostgreSQL e iterar por pequeños cambios en el mismo bucle basado en chat—luego exportar código fuente cuando quieras más control.
Señales de que tienes propiedad fuerte
Fíjate en estas señales operativas:
- Un backlog por iniciativa (no disperso en varias herramientas o equipos)
- Una definición de hecho, incluyendo pruebas y rollout (no “hecho en dev”)
- Un único decisor para prioridad y alcance
- Interfaces claras con otros equipos: las solicitudes son explícitas, temporizadas y documentadas
Con estas señales, un equipo pequeño puede moverse con confianza—y la IA hace más fácil mantener ese impulso.
Los bucles de retroalimentación cerrados vencen a los grandes planes
Los grandes planes parecen eficientes porque reducen la cantidad de “momentos de decisión”. Pero a menudo empujan el aprendizaje al final—después de semanas de construcción—cuando los cambios son más caros. Los equipos pequeños se mueven más rápido encogiendo la distancia entre una idea y la retroalimentación real.
Los bucles cortos previenen trabajo desperdiciado
Un bucle de retroalimentación corto es simple: construye lo más pequeño que pueda enseñarte algo, muéstralo a usuarios y decide el siguiente paso.
Cuando la retroalimentación llega en días (no trimestres), dejas de pulir la solución equivocada. También evitas sobreingeniería por requisitos “por si acaso” que nunca aparecen.
Cómo se ve el aprendizaje rápido
Los equipos pequeños pueden ejecutar ciclos ligeros que aún producen señales sólidas:
- Prototipos rápidos: maquetas clicables o flujos “happy path” finos para validar si los usuarios entienden el valor.
- Entrevistas tempranas: 5–8 conversaciones suelen sacar las principales objeciones y piezas faltantes.
- Iteraciones rápidas A/B: pequeños cambios en UI o onboarding medidos en una ventana corta pueden revelar qué reduce la fricción.
La clave es tratar cada ciclo como un experimento, no como un mini-proyecto.
La IA puede acelerar el aprendizaje, no solo la construcción
La mayor palanca de la IA aquí no es escribir más código—es comprimir el tiempo desde “escuchamos algo” hasta “sabemos qué probar después”. Por ejemplo, puedes usar IA para:
- Resumir feedback de entrevistas, tickets de soporte, reseñas de apps o notas de ventas en conclusiones nítidas.
- Agrupar temas (p. ej., puntos de confusión, características faltantes, problemas de confianza) para que los patrones emerjan rápido.
- Redactar experimentos: proponer hipótesis, métricas de éxito y la prueba más pequeña que las confirme o rechace.
Eso significa menos tiempo en reuniones de síntesis y más tiempo ejecutando la siguiente prueba.
Velocidad de shipping vs. velocidad de aprendizaje
Los equipos suelen celebrar la velocidad de entrega—cuántas funciones se sacaron. Pero la velocidad real es la velocidad de aprendizaje: qué tan rápido reduces la incertidumbre y tomas mejores decisiones.
Una gran org puede publicar mucho y aun así ser lenta si aprende tarde. Un equipo pequeño puede publicar menos “volumen” pero moverse más rápido aprendiendo antes, corrigiendo pronto y dejando que la evidencia—no las opiniones—moldee la hoja de ruta.
La IA como multiplicador de fuerza, no como reemplazo
Mantente al tanto
Reduce el cambio de contexto manteniendo plan, código y cambios en un flujo de trabajo guiado.
La IA no hace a un equipo pequeño “más grande”. Hace que el juicio y la propiedad existentes viajen más lejos. La ganancia no es que la IA escriba código; es que elimina fricciones en partes del delivery que roban tiempo sin mejorar el producto.
Usos de alto apalancamiento que se acumulan
Los equipos pequeños obtienen ganancias desproporcionadas cuando enfocan la IA en trabajo necesario pero poco diferenciador:
- Generación de boilerplate: scaffolding de endpoints, archivos de prueba, plantillas de migración, config de CI o componentes UI repetitivos.
- Refactors con plan: renombrar, extraer helpers, convertir patrones y actualizar call sites—especialmente con restricciones claras (“no cambiar comportamiento”, “mantener API pública estable”).
- Borradores de documentación: notas de lanzamiento, esquemas de ADR, documentación de API, guías de onboarding y “cómo ejecutar localmente”.
El patrón es consistente: la IA acelera el primer 80% para que los humanos inviertan más tiempo en el 20% final—la parte que requiere sentido de producto.
Dónde la IA ayuda más (y dónde no)
La IA brilla en tareas rutinarias, “problemas conocidos” y cualquier cosa que arranque desde un patrón de código existente. También es buena para explorar opciones rápidamente: proponer dos implementaciones, listar trade-offs o sacar a la luz casos límite que podrías haber pasado por alto.
Ayuda menos cuando los requisitos son poco claros, cuando la decisión arquitectónica tiene consecuencias a largo plazo o cuando el problema es muy específico de dominio con poco contexto escrito. Si el equipo no puede explicar qué significa "hecho", la IA solo generará salidas plausibles más rápido.
Velocidad sin atajos: la validación es innegociable
Trata la IA como un colaborador junior: útil, rápido y a veces equivocado. Los humanos siguen siendo responsables del resultado.
Eso significa que cada cambio asistido por IA aún debe tener revisión, pruebas y comprobaciones básicas. La regla práctica: usa la IA para redactar y transformar; usa humanos para decidir y verificar. Así los equipos pequeños entregan más rápido sin convertir la velocidad en deuda futura.
Reducir el cambio de contexto con asistencia de IA
El cambio de contexto es uno de los asesinos silenciosos de la velocidad en equipos pequeños. No es solo “ser interrumpido”—es el reinicio mental cada vez que saltas entre código, tickets, docs, hilos de Slack y partes del sistema desconocidas. La IA ayuda cuando convierte esos reinicios en paradas rápidas.
Cómo la IA recorta el coste del switching
En lugar de pasar 20 minutos buscando una respuesta, puedes pedir un resumen rápido, una pista de archivos probables o una explicación en lenguaje sencillo de lo que estás viendo. Bien usada, la IA se convierte en un generador de “primer borrador” para entender: puede resumir un PR largo, convertir un informe de bug vago en hipótesis o traducir un stack trace aterrador en causas probables.
La ganancia no es que la IA siempre acierte—es que te orienta más rápido para que tomes decisiones reales.
Tácticas prácticas que funcionan en equipos reales
Algunos patrones de prompt reducen el thrash consistentemente:
- Pedir opciones: “Dame 3 enfoques para arreglar esto, con trade-offs y riesgos.”
- Explica este código: “Explica qué hace esta función, casos límite y qué rompería si cambiamos X.”
- Genera un plan: “Crea un plan paso a paso para lanzar esto en dos PRs pequeños, incluidos tests.”
- Escribe una checklist: “Checklist para liberar esto de forma segura (monitorización, rollback, validación).”
Estos prompts te cambian de deambular a ejecutar.
Haz los prompts reutilizables, no heroicos
La velocidad se compone cuando los prompts se convierten en plantillas que usa todo el equipo. Mantén un pequeño “kit de prompts” interno para tareas comunes: revisiones de PR, notas de incidentes, planes de migración, checklists de QA y runbooks de release. La consistencia importa: incluye objetivo, restricciones (tiempo, alcance, riesgo) y formato de salida esperado.
Límites y guardarraíles
No pegues secretos, datos de clientes ni nada que no pondrías en un ticket. Trata las salidas como sugerencias: verifica afirmaciones críticas, ejecuta pruebas y revisa el código generado—especialmente en auth, pagos y eliminación de datos. La IA reduce el cambio de contexto; no debe reemplazar el juicio de ingeniería.
Publica pequeño, publica frecuente: prácticas que la IA amplifica
Publicar más rápido no es sobre sprints heroicos; es reducir el tamaño de cada cambio hasta que la entrega sea rutinaria. Los equipos pequeños ya tienen una ventaja: menos dependencias hacen más fácil trocear el trabajo fino. La IA amplifica esa ventaja reduciendo el tiempo entre “idea” y “cambio seguro y liberable”.
Un pipeline ligero de entrega (que escala bien hacia abajo)
Un pipeline simple vence a uno elaborado:
- Desarrollo basado en trunk: integrar en main con frecuencia en lugar de ramas largas.
- PRs pequeños: cambios que se puedan revisar en minutos, no horas.
- Despliegues frecuentes: liberar cuando un cambio esté listo, no esperar a que un lote sea “lo bastante grande”.
La IA ayuda redactando notas de lanzamiento, sugiriendo commits más pequeños y señalando archivos que probablemente se toquen juntos—empujándote hacia PRs más limpios y ajustados.
Tests acelerados por IA: cobertura sin fricción
Las pruebas suelen ser donde “publicar frecuente” se rompe. La IA puede reducir esa fricción mediante:
- Generar tests unitarios/integración iniciales a partir de patrones de código.
- Brainstorming de casos límite que podrías pasar por alto (zonas horarias, estados vacíos, reintentos, límites de tasa).
- Proponer datos de prueba y mocks que coincidan con las formas reales de la API.
Trata los tests generados por IA como un primer borrador: revísalos por corrección y conserva los que protejan comportamiento.
Confianza en el release: monitorizar, alertar, rollback
Los despliegues frecuentes requieren detección y recuperación rápidas. Configura:
- Chequeos de salud básicos y dashboards para flujos de usuario principales
- Alertas ligadas a síntomas (tasa de errores, latencia, jobs fallidos), no a métricas de vanidad
- Un rollback con un comando (o rollback automático) para que un mal release sea un pequeño tropiezo
Si tus fundamentos de entrega necesitan repaso, vincula esto a la lectura compartida del equipo: /blog/continuous-delivery-basics.
Con estas prácticas, la IA no te “hace más rápido” por arte de magia—elimina los pequeños retrasos que se acumulan en ciclos de semanas.
Latencia en las decisiones: aprobaciones vs guardarraíles
Lanza tu próxima pieza
Convierte una pequeña parte en una app en vivo con un ciclo de construcción guiado por chat.
Las grandes organizaciones de ingeniería rara vez se mueven despacio porque la gente sea perezosa. Se mueven despacio porque las decisiones se encolan. Los consejos arquitectónicos se reúnen mensualmente. Las revisiones de seguridad y privacidad esperan en backlogs. Un cambio “simple” puede requerir revisión de tech lead, luego de un staff engineer, luego aprobación de plataforma, luego del release manager. Cada salto añade tiempo de espera, no solo tiempo de trabajo.
Los equipos pequeños no pueden permitirse esa latencia en decisiones, por lo que deben aspirar a un modelo distinto: menos aprobaciones, guardarraíles más sólidos.
Qué intentan resolver las aprobaciones (y por qué se atascan)
Las cadenas de aprobación son una herramienta de gestión de riesgos. Reducen la probabilidad de cambios malos, pero centralizan la toma de decisiones. Cuando el mismo pequeño grupo debe bendecir cada cambio significativo, el throughput colapsa y los ingenieros optimizan por “conseguir la aprobación” en vez de mejorar el producto.
Guardarraíles: la alternativa para equipos pequeños
Los guardarraíles desplazan las comprobaciones de calidad de reuniones a valores por defecto:
- Estándares de codificación claros y definiciones de hecho
- Checklists ligeros para áreas riesgosas (auth, pagos, eliminación de datos)
- Comprobaciones automatizadas: tests, linters, type checking, escaneo de dependencias
En lugar de “¿Quién aprobó esto?”, la pregunta es “¿Pasó esto las puertas acordadas?”
Cómo la IA reduce el coste de los guardarraíles
La IA puede estandarizar la calidad sin añadir más humanos al bucle:
- Sugerencias de lint y refactor para alinear el código con los estándares del equipo
- Resúmenes de PR que expliquen intención, alcance y riesgo en lenguaje llano
- Listas de verificación de revisión generadas desde el diff (p. ej., “toca PII: confirma política de retención”) para que los revisores no dependan de la memoria
Esto mejora la consistencia y acelera las revisiones, porque los revisores parten de un informe estructurado en lugar de una pantalla en blanco.
Mantener el cumplimiento ligero (sin saltárselo)
El cumplimiento no necesita un comité. Mantenlo repetible:
- Define disparadores de “requiere revisión” (PII, movimiento de dinero, permisos)
- Usa plantillas para evidencia (resumen de PR + checklist + resultados de tests)
- Guarda decisiones en el hilo del PR para que las auditorías sean buscables
Las aprobaciones pasan a ser la excepción para trabajo de alto riesgo; los guardarraíles se encargan del resto. Así los equipos pequeños se mantienen rápidos sin ser imprudentes.
Trabajo de diseño como thin slices para mantener el momentum
Los grandes equipos a menudo “diseñan todo el sistema” antes de que alguien entregue. Los equipos pequeños pueden moverse más rápido diseñando thin slices: la unidad vertical mínima de valor que puede ir de idea → código → producción y ser usada (incluso por una cohorte pequeña).
Qué es realmente un thin slice
Un thin slice es propiedad vertical, no una fase horizontal. Incluye lo necesario en diseño, backend, frontend y ops para hacer real un resultado.
En lugar de “rediseñar el onboarding”, un thin slice podría ser “recoger un campo de signup adicional, validarlo, almacenarlo, mostrarlo en el perfil y medir la finalización”. Es lo suficientemente pequeño para terminar rápido, pero lo bastante completo para aprender.
Cómo la IA te ayuda a trocear el trabajo (sin adivinar)
La IA es útil como compañero de pensamiento estructurado:
- Proponer 2–4 opciones de hitos (mínimo viable, medio, completo)
- Generar un desglose de tareas por capa (UI, API, datos, analítica, rollout)
- Señalar dependencias ocultas (migraciones, permisos, casos límite)
- Sugerir un plan de rollout (feature flag, cohorte limitada, fallback)
El objetivo no es más tareas—es un límite claro y entregable.
Define “hecho” para cada slice
El momentum muere cuando lo “casi hecho” se alarga. Para cada slice, escribe elementos explícitos de Definición de Hecho:
- Comportamiento visible para el usuario (qué cambió, para quién)
- Criterios de aceptación (happy path + casos límite clave)
- Instrumentación (nombres de eventos, dashboards, alertas si hace falta)
- Pasos de despliegue/rollback (o reglas de feature flag)
Ejemplos de thin slices
- Un endpoint:
POST /checkout/quote que devuelve precio + impuestos
- Una pantalla: una página de ajustes para preferencias de notificación
- Un flujo: restablecimiento de contraseña de petición → email → nueva contraseña → confirmación
Los thin slices mantienen el diseño honesto: diseñas lo que puedes publicar ahora, aprendes rápido y dejas que el siguiente slice gane su complejidad.
Riesgos de la velocidad acelerada por IA (y cómo gestionarlos)
Haz que los despliegues frecuentes sean más seguros
Experimenta más a menudo con instantáneas y reversiones cuando un lanzamiento necesite un reinicio rápido.
La IA puede ayudar a un equipo pequeño a moverse rápido, pero también cambia los modos de fallo. El objetivo no es “ralentizar para ser seguro”—es añadir guardarraíles ligeros para seguir publicando sin acumular deuda invisible.
Riesgos comunes cuando la IA está en el bucle
Moverse más rápido aumenta la probabilidad de que los bordes ásperos lleguen a producción. Con asistencia de IA, aparecen repetidamente algunos riesgos:
- Código y estilo inconsistentes: parches generados por IA pueden variar en patrones, nombres y arquitectura, dificultando el mantenimiento.
- Problemas de seguridad: sugerencias pueden introducir defaults inseguros (chequeos de auth débiles, falta de validación de entrada, deserialización insegura).
- Lógica “alucinada”: el código puede parecer plausible pero ser sutilmente incorrecto (casos límite, suposiciones de API equivocadas, manejo de errores incorrecto).
- Expansión de dependencias: la IA puede introducir librerías nuevas “para facilitar”, aumentando la superficie de ataque y el coste de mantenimiento.
Guardarraíles que mantienen la velocidad sin caos
Mantén reglas explícitas y fáciles de seguir. Unas pocas prácticas rinden rápido:
- Guía de codificación segura: una checklist corta para áreas comunes (auth, permisos, validación, logging, cifrado).
- Escaneo de secretos en CI y hooks pre-commit, además de reglas claras sobre dónde viven los secretos.
- Políticas de dependencias: lista de librerías aprobadas, fijado de versiones y un estándar de “nueva dependencia requiere justificación”.
Comprobaciones humanas que más importan
La IA puede redactar código; los humanos deben poseer los resultados.
- Modelado de amenazas para cambios que tocan datos, auth, pagos o flujos administrativos. Incluso una revisión de 10 minutos atrapa riesgos de alto impacto.
- Revisión de código enfocada en comportamiento, no solo estilo: entradas/salidas, rutas de error, permisos y manejo de datos.
- Estrategia de pruebas: exigir tests unitarios para la lógica, tests de integración para flujos críticos y un pequeño conjunto de checks end-to-end de alta señal.
Usar la IA con seguridad en el día a día
Trata los prompts como texto público: no pegues secretos, tokens ni datos de clientes. Pide al modelo que explique suposiciones y luego verifícalas con fuentes primarias (docs) y tests. Cuando algo parece “demasiado conveniente”, suele necesitar una revisión más profunda.
Si usas un entorno de construcción impulsado por IA como Koder.ai, aplica las mismas reglas: mantiene datos sensibles fuera de prompts, exige tests y revisión, y confía en snapshots/flujo de rollback para que “rápido” también signifique “recuperable”.
Cómo medir ganancias y construir un sistema repetible
La velocidad solo importa si puedes verla, explicarla y reproducirla. El objetivo no es “usar más IA”—es un sistema simple donde las prácticas asistidas por IA reducen de forma fiable el tiempo hasta el valor sin aumentar el riesgo.
Métricas que muestran velocidad real de entrega (no actividad)
Elige un conjunto pequeño para seguir semanalmente:
- Cycle time: desde “trabajo empezado” hasta “en producción”.
- Tamaño de PR: líneas/archivos cambiados (más pequeño suele ser más fácil de revisar y más seguro).
- Tiempo de revisión: tiempo medio que un PR espera la primera revisión y hasta el merge.
- Incidentes/regresiones: problemas en producción por semana (y severidad), más MTTR.
- Tiempo de respuesta al cliente: tiempo desde feedback de usuario hasta un cambio desplegado.
Añade una señal cualitativa: “¿Qué nos ralentizó más esta semana?” Te ayuda a detectar cuellos que las métricas no verán.
Un ritmo operativo ligero
Mantenlo consistente y amigable para equipos pequeños:
- Objetivos semanales (30 minutos): 1–3 resultados, no una larga lista de tareas.
- Actualizaciones diarias asíncronas: ayer/hoy/bloqueos en Slack/Linear/GitHub.
- Cadencia de demo (semanal o quincenal): mostrar trabajo entregado, no diapositivas. Esto refuerza “hecho significa en manos de usuarios”.
Plan de despliegue de 30 días para flujos de trabajo con IA
Semana 1: Línea base. Mide las métricas anteriores durante 5–10 días laborables. Sin cambios aún.
Semanas 2–3: Elige 2–3 flujos de IA. Ejemplos: generar descripción de PR + checklist de riesgos, asistencia para escribir tests, redactar notas de lanzamiento y changelogs.
Semana 4: Compara antes/después y fija hábitos. Si el tamaño de PR baja y el tiempo de revisión mejora sin más incidentes, mantenlo. Si suben los incidentes, añade guardarraíles (rollouts más pequeños, mejores tests, propiedad más clara).
Checklist: empieza esta semana
- Elige 3 métricas para publicar en un hilo semanal.
- Fija un objetivo de tamaño de PR por defecto (y refuérzalo con normas sociales, no con burocracia).
- Añade un paso de “pre-revisión” asistido por IA: resumir cambios, riesgos y cobertura de tests.
- Programa una demo en el calendario.
- Ejecuta un “retro del cuello de botella”: ¿qué causó la mayor demora y qué cambiaremos la próxima semana?