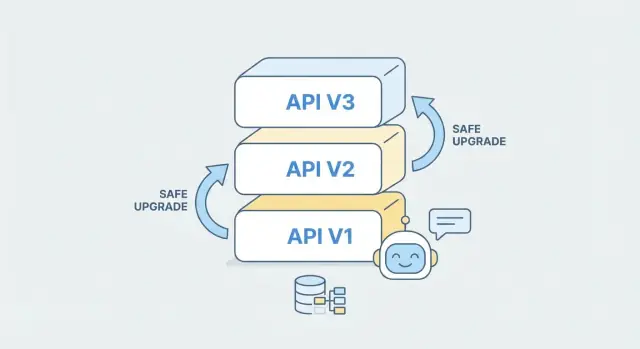
Qué significa la evolución de la API para backends generados por IA
La evolución de la API es el proceso continuo de cambiar una API después de que ya la estén usando clientes reales. Eso puede significar añadir campos, ajustar reglas de validación, mejorar el rendimiento o introducir nuevos endpoints. Empieza a importar una vez que los clientes están en producción, porque incluso un cambio “pequeño” puede romper una versión móvil, un script de integración o un flujo de trabajo de un partner.
Un cambio es retrocompatible si los clientes existentes siguen funcionando sin actualizaciones.
Por ejemplo, supongamos que tu API devuelve:
{ "id": "123", "status": "processing" }
Agregar un nuevo campo opcional normalmente es retrocompatible:
{ "id": "123", "status": "processing", "estimatedSeconds": 12 }
Los clientes antiguos que ignoran campos desconocidos seguirán funcionando. En cambio, renombrar status a state, cambiar el tipo de un campo (string → number) o convertir un campo opcional en obligatorio son cambios que suelen romper.
Qué significa “backend generado por IA” aquí
Un backend generado por IA no es solo un fragmento de código. En la práctica incluye:
- Código de API generado (handlers, controladores, serializadores)
- Configuración (rutas, reglas de auth, límites de tasa)
- Enlace de infraestructura (migraciones, plantillas de despliegue, ajustes de entorno)
Como la IA puede regenerar partes del sistema rápidamente, la API puede “derivar” a menos que gestiones los cambios intencionalmente.
Esto es especialmente cierto cuando generas aplicaciones enteras desde un flujo guiado por chat. Por ejemplo, plataformas como Koder.ai pueden crear aplicaciones web, server y mobile desde una conversación—a menudo con React en web, Go + PostgreSQL en backend y Flutter en móvil. Esa velocidad es muy valiosa, pero exige disciplina de contrato (y difs/pruebas automatizadas) para que una regeneración no cambie accidentalmente lo que los clientes esperan.
Qué puede automatizarse y qué necesita revisión humana
La IA puede automatizar mucho: producir specs OpenAPI, actualizar código repetitivo, sugerir valores por defecto seguros e incluso redactar pasos de migración. Pero la revisión humana sigue siendo esencial para decisiones que afectan contratos de cliente—qué cambios están permitidos, qué campos son estables y cómo manejar casos límite y reglas de negocio. La meta es velocidad con comportamiento predecible, no velocidad a costa de sorpresas.
Por qué la retrocompatibilidad es una prioridad
Las APIs rara vez tienen un único “cliente”. Incluso un producto pequeño puede tener múltiples consumidores que dependen de un mismo endpoint:
- Una web que se despliega continuamente
- Una app móvil que actualiza más despacio por tiendas
- Integraciones con partners (propiedad de otros equipos o empresas)
- Servicios internos y automatizaciones (facturación, analytics, soporte)
Cuando una API se rompe, el coste no es solo tiempo de desarrollo. Usuarios móviles pueden quedarse en versiones antiguas durante semanas, de modo que un cambio rompiente puede generar una larga cola de errores y tickets. Los partners pueden sufrir downtime, pérdida de datos o interrupciones críticas—con consecuencias contractuales o reputacionales. Los servicios internos pueden fallar silenciosamente y crear backlogs confusos (eventos perdidos, registros incompletos).
Los backends generados por IA añaden una complicación: el código puede cambiar rápida y frecuentemente, a veces en difs grandes, porque la generación se optimiza para producir código funcional, no para preservar comportamiento a lo largo del tiempo. Esa velocidad es valiosa, pero aumenta el riesgo de cambios rompientes accidentales (campos renombrados, defaults distintos, validaciones más estrictas, nuevos requisitos de auth).
Por eso la retrocompatibilidad debe ser una decisión de producto deliberada, no una práctica implícita. El enfoque práctico es definir un proceso de cambio predecible donde la API se trate como una interfaz de producto: puedes añadir capacidades, pero no sorprender a los clientes existentes.
Un modelo mental útil es tratar el contrato de la API (por ejemplo, un spec OpenAPI) como la “fuente de la verdad” de lo que los clientes pueden esperar. La generación se convierte entonces en un detalle de implementación: puedes regenerar el backend, pero el contrato—y las promesas que hace—se mantienen estables a menos que versionen y comuniquen los cambios intencionalmente.
El contrato de la API como fuente de la verdad
Cuando un sistema de IA puede generar o modificar código de backend rápidamente, el único ancla fiable es el contrato de la API: la descripción escrita de qué pueden llamar los clientes, qué deben enviar y qué pueden esperar.
Qué significa “contrato” en la práctica
Un contrato es un spec legible por máquina como:
- OpenAPI para endpoints REST (paths, parámetros, auth, formas de respuesta)
- JSON Schema para validar payloads de request/response (a menudo embebido en OpenAPI)
- Esquema GraphQL para tipos, queries, mutations y deprecaciones
Ese contrato es lo que prometes a consumidores externos, aunque la implementación detrás cambie.
Contract-first vs code-first (y dónde encajan los generadores)
En un flujo contract-first, diseñas o actualizas el OpenAPI/GraphQL primero y luego generas stubs de servidor y completas la lógica. Esto suele ser más seguro para compatibilidad porque los cambios son intencionales y revisables.
En un flujo code-first, el contrato se produce desde anotaciones en el código o introspección en tiempo de ejecución. Los backends generados por IA suelen tender al code-first por defecto, lo cual está bien—siempre que el contrato generado se trate como un artefacto para revisar, no como un apéndice.
Un híbrido práctico: deja que la IA proponga cambios en el código, pero exige que también actualice (o regenere) el contrato, y trata las difs del contrato como la señal principal de cambio.
Poner el contrato bajo control de versiones
Almacena tus specs de API en el mismo repo que el backend y revísalos mediante pull requests. Una regla simple: no mergear a menos que el cambio del contrato esté entendido y aprobado. Esto hace visibles los edits incompatibles antes de que lleguen a producción.
Generar servidor y clientes desde una misma fuente
Para reducir la deriva, genera stubs de servidor y SDKs de cliente desde el mismo contrato. Cuando el contrato se actualice, ambos lados se actualizan juntos—haciendo mucho más difícil que una implementación generada por IA “invente” comportamiento que los clientes no esperaban.
Estrategias de versionado que funcionan en la práctica
Versionar la API no se trata de predecir cada cambio futuro—se trata de dar a los clientes una forma clara y estable de seguir funcionando mientras mejoras el backend. En la práctica, la estrategia “mejor” es la que tus consumidores entienden al instante y que tu equipo puede aplicar de forma consistente.
Estrategias comunes (y cómo se sienten para los clientes)
Versionado en la URL pone la versión en la ruta, como /v1/orders y /v2/orders. Es visible en cada petición, fácil de depurar y funciona bien con cache y routing.
Versionado por header mantiene las URLs limpias y mueve la versión a un header (por ejemplo, Accept: application/vnd.myapi.v2+json). Puede ser elegante, pero menos obvio al depurar y fácil de olvidar en ejemplos.
Versionado por query usa algo como /orders?version=2. Es directo, pero puede complicarse si clientes o proxies alteran query strings, y es más fácil mezclar versiones accidentalmente.
Recomendación por defecto
Para la mayoría de equipos—especialmente si quieres que los clientes entiendan fácilmente—usa por defecto versionado en la URL. Es lo menos sorprendente, fácil de documentar y muestra claramente qué versión está llamando un SDK, una app móvil o una integración partner.
Cómo pueden ayudar los backends generados por IA
Al usar IA para generar o extender un backend, trata cada versión como una unidad separada de “contrato + implementación”. Puedes scaffoldear un nuevo /v2 a partir de un OpenAPI actualizado manteniendo /v1 intacto, y compartir la lógica de negocio debajo cuando sea posible. Esto reduce el riesgo: los clientes existentes siguen funcionando mientras los nuevos adoptan v2 intencionalmente.
Documentación y comunicación de cambios
El versionado solo funciona si la documentación se mantiene. Mantén docs de API versionadas, ejemplos coherentes por versión y publica un changelog que deje claro qué cambió, qué está deprecado y notas de migración (idealmente con ejemplos lado a lado de request/response).
Cambios compatibles vs rompientes: una checklist práctica
Cuando un backend generado por IA se actualiza, la forma más segura de pensar en compatibilidad es: “¿Un cliente existente seguirá funcionando sin cambios?” Usa la checklist a continuación para clasificar cambios antes de enviarlos.
Normalmente compatibles (cambios aditivos)
Estos cambios normalmente no rompen a clientes existentes porque no invalidan lo que los clientes ya envían o esperan:
- Nuevos campos de respuesta opcionales (p. ej.,
middleName o metadata). Los clientes existentes deben seguir funcionando mientras no requieran un conjunto exacto de campos.
- Nuevos endpoints (o nuevos métodos en otra ruta). No cambia lo existente.
- Nuevos campos de request opcionales que el servidor puede ignorar o tratar con valores por defecto.
- Expansión de enums en respuestas (los clientes deben manejar valores desconocidos de forma defensiva).
Normalmente rompientes (riesgosos)
Trátalos como rompientes a menos que tengas evidencia en contrario:
- Eliminar campos o endpoints, o dejar de soportar un campo que los clientes envían.
- Renombrar campos (incluso si el significado es el mismo). Muchos clientes mapearán por nombre.
- Cambios de tipo (string → number, objeto → array,
nullable → no-nullable).
- Cambios de comportamiento: defaults distintos, ordenaciones cambiadas, semántica de paginación, validaciones alteradas.
- Endurecer restricciones: hacer obligatorio un campo que antes era opcional, reducir max length, cambiar formatos aceptados.
Lectores tolerantes como línea base de compatibilidad
Incentiva a los clientes a ser lectores tolerantes: ignorar campos desconocidos y manejar valores de enum inesperados con gracia. Esto permite que el backend evolucione añadiendo campos sin forzar actualizaciones cliente.
Cómo deberían aplicar las reglas los generadores de IA
Un generador puede prevenir cambios accidentales rompedores mediante políticas:
- Bloquear merges si las difs OpenAPI incluyen eliminación de campos, renombres o cambios de tipo sin un bump de versión.
- Requerir que cualquier cambio rompiente se introduzca primero como campos/endpoints nuevos, con avisos de deprecación en los antiguos.
- Emitir warnings al añadir enums de respuesta o cambiar defaults, solicitando una revisión de compatibilidad.
Migraciones de BD y esquema sin romper clientes
Versiona tu API de forma ordenada
Crea una nueva versión de la API manteniendo v1 estable para los clientes existentes.
Los cambios de API son lo que los clientes ven: formas de request/response, nombres de campos, reglas de validación y comportamiento de errores. Los cambios de BD son lo que tu backend almacena: tablas, columnas, índices, constraints y formatos de datos. Están relacionados, pero no son idénticos.
Un error común es tratar una migración de BD como “solo interna”. En backends generados por IA, la capa de API suele generarse desde el esquema (o estar muy acoplada), así que un cambio de esquema puede convertirse silenciosamente en un cambio de API. Ahí es donde clientes antiguos se rompen aunque no pretendieras tocar la API.
Patrón seguro de migración (expand → migrate → contract)
Usa un enfoque en varios pasos que mantenga rutas de código antiguas y nuevas durante actualizaciones continuas:
- Agregar: introducir nuevas columnas/tablas sin eliminar o renombrar las existentes.
- Backfill: poblar nuevos campos para filas existentes (en batches si hace falta).
- Escritura dual: el backend escribe tanto en la ubicación antigua como en la nueva.
- Cambiar lecturas: empezar a leer desde la nueva fuente mientras se sigue escribiendo en ambas.
- Limpiar: eliminar los campos legados solo después de que todos los clientes estén actualizados.
Este patrón evita releases tipo “big bang” y te da opciones de rollback.
Defaults, nulos y campos “falta”
Los clientes antiguos suelen asumir que un campo es opcional o tiene un significado estable. Al añadir una nueva columna non-null, elige entre:
- un default del servidor que preserve el comportamiento, o
- permitir NULL temporalmente y manejarlo explícitamente en la capa de API.
Cuidado: un default en la BD no siempre ayuda si el serializador de la API sigue emitiendo null o cambia reglas de validación.
Migraciones generadas por IA: útiles, no automáticas
Las herramientas de IA pueden redactar scripts de migración y sugerir backfills, pero necesitas validación humana: confirmar constraints, revisar rendimiento (locks, builds de índices) y ejecutar migraciones contra datos de staging para asegurar que los clientes antiguos sigan funcionando.
Feature flags y despliegues graduales para actualizaciones más seguras
Los feature flags te permiten cambiar comportamiento sin cambiar la forma del endpoint. Eso es especialmente útil en backends generados por IA, donde la lógica interna puede regenerarse u optimizarse con frecuencia, pero los clientes dependen de peticiones y respuestas consistentes.
En lugar de lanzar un “gran interruptor”, envías la nueva ruta de código desactivada por defecto y la activas gradualmente. Si hay un problema, la apagas—sin necesidad de un redeploy urgente.
Cómo funciona un rollout gradual
Un plan de despliegue práctico suele combinar tres técnicas:
- Canary release: activar el nuevo comportamiento para una porción pequeña del tráfico (o un pequeño tenant) primero.
- Rollout por porcentaje: aumentar exposición de 1% → 10% → 50% → 100%, observando errores y impacto.
- Plan de rollback rápido: definir métricas que disparen rollback (p. ej., tasa de 5xx, fallos de validación, tickets de soporte) y hacer la flag reversible en minutos.
Para APIs, la clave es mantener las respuestas estables mientras experimentas internamente. Puedes intercambiar implementaciones (nuevo modelo, nueva lógica de routing, nuevo plan de consulta DB) mientras devuelves los mismos códigos de estado, nombres de campos y formatos de error que promete el contrato. Si necesitas añadir datos, prefiere campos aditivos que los clientes puedan ignorar.
Ejemplo simple: desplegar una validación más estricta
Imagina POST /orders que actualmente acepta phone en muchos formatos. Quieres exigir formato E.164, pero endurecer la validación puede romper clientes.
Un enfoque más seguro:
- Desplegar el validador estricto detrás de una flag (p. ej.,
strict_phone_validation).
- Empezar en modo “solo report”: aceptar la petición pero registrar qué fallaría. Las respuestas siguen igual.
- Canary de enforcement para usuarios internos o 1% del tráfico.
- Subir porcentajes mientras monitorizas: picos de errores de validación, reintentos de clientes y abandonos.
- Hacer rollback inmediatamente si los fallos exceden umbrales.
Este patrón te permite mejorar la calidad de datos sin convertir una API retrocompatible en un cambio rompiente accidental.
Deprecación y sunsetting: cómo retirar versiones antiguas
Reduce los cambios incompatibles accidentales
Añade campos y endpoints con confianza usando prompts repetibles y diffs claros en tu flujo de trabajo.
La deprecación es la “salida educada” de un comportamiento antiguo: dejas de fomentarlo, avisas a los clientes con antelación y les das un camino predecible para avanzar. El sunsetting es el paso final: una versión antigua se apaga en una fecha publicada. Para backends generados por IA—donde endpoints y esquemas pueden evolucionar rápido—tener un proceso estricto de retirada es lo que mantiene la confianza y permite actualizaciones seguras.
Define qué significa “mayor” (Versionado semántico)
Aplica versionado semántico al nivel del contrato de API, no solo al repo.
- MAJOR: cualquier cambio rompiente (eliminar campos/endpoints, cambiar el significado de un campo, endurecer validación, cambiar requisitos de auth, alterar defaults que clientes esperan).
- MINOR: añadidos retrocompatibles (nuevos campos opcionales, nuevos endpoints, valores de enum aditivos, nuevos parámetros de filtro).
- PATCH: correcciones y mejoras no funcionales (rendimiento, refactors internos) que no cambian el contrato ni el comportamiento observable.
Incluye esta definición en la documentación y aplícala con consistencia. Evitas “majors silenciosos” donde un cambio asistido por IA parece pequeño pero rompe clientes reales.
Cronograma práctico de deprecación
Elige una política por defecto y cúmplela para que los usuarios puedan planear. Un enfoque común:
- Anunciar la deprecación: al publicar la nueva versión.
- Ventana de deprecación: mantener la versión antigua operativa 90–180 días (más para clientes enterprise).
- Fecha de sunset: publicar una fecha límite desde el día uno.
Si dudas, elige una ventana ligeramente más larga; el coste de mantener una versión un tiempo extra suele ser menor que el coste de migraciones de emergencia.
Señales de deprecación (difíciles de ignorar)
Usa múltiples canales porque no todos leen release notes:
- Headers de respuesta: p. ej.,
Deprecation: true y Sunset: Wed, 31 Jul 2026 00:00:00 GMT, más un Link a docs de migración.
- Notas en docs: un banner claro en la documentación de la versión antigua con la fecha de retiro y checklist de migración (enlazando a /docs/api/v2/migration).
- Warnings en SDKs: avisos en SDKs oficiales (logs en runtime + anotaciones deprecadas en tiempo de compilación cuando sea posible).
Incluye también avisos en changelogs y comunicaciones de estado para que procurement y ops los vean.
Retirada: sunset con fecha firme (y estado final seguro)
Mantén versiones antiguas hasta la fecha de sunset y luego desactívalas deliberadamente—no mediante una rotura accidental.
Al sunset:
- Devuelve un error claro para la versión retirada (p. ej.,
410 Gone) con un mensaje apuntando a la versión más reciente y la guía de migración.
- Mantén una página explicativa y legible por humanos durante un tiempo (p. ej., /docs/deprecations/v1).
Lo más importante: trata el sunsetting como un cambio programado con responsables, monitorización y plan de rollback. Esa disciplina es lo que hace posible evolucionar frecuentemente sin sorprender a los clientes.
Pruebas que evitan cambios rompientes accidentales
El código generado por IA puede cambiar rápido—y a veces en lugares inesperados. La forma más segura de mantener a los clientes funcionando es probar el contrato (lo que prometes externamente), no solo la implementación.
Pruebas de contrato: comparaciones spec-a-spec
Una línea base práctica es una prueba de contrato que compare el OpenAPI previo con el recién generado. Trátala como una comprobación “antes vs después”:
- Detecta endpoints removidos, campos renombrados, reglas de validación más estrictas o cambios en auth
- Señala cambios en códigos de respuesta (p. ej., 200 → 204, o comportamiento 404 distinto)
- Captura cambios sutiles como convertir un campo opcional en obligatorio
Muchos equipos automatizan un diff de OpenAPI en CI para que ningún cambio generado pueda desplegarse sin revisión. Esto es especialmente útil cuando cambian prompts, plantillas o versiones de modelo.
Pruebas impulsadas por consumidores (en términos llanos)
Las pruebas impulsadas por consumidores invierten la perspectiva: en vez de que el equipo backend adivine cómo usan la API los clientes, cada cliente comparte un conjunto pequeño de expectativas (las peticiones que envía y las respuestas de las que depende). El backend debe probar que sigue cumpliendo esas expectativas antes de una release.
Funciona bien cuando tienes múltiples consumidores (web, móvil, partners) y quieres actualizar sin coordinar cada despliegue.
Añade pruebas de regresión que fijen:
- Forma JSON de las respuestas (nombres de campos, tipos, anidamiento)
- Defaults y nulabilidad (ausente vs null)
- Semántica de paginación y ordenación
- Formato de errores: códigos estables, estructura del mensaje y campos de error de validación
Si publicas un esquema de errores, pruébalo explícitamente—los clientes suelen parsear errores más de lo que creemos.
Puertas en CI antes del rollout
Combina difs OpenAPI, contratos de consumidores y tests de regresión de forma/código en una puerta de CI. Si un cambio generado falla, la solución suele ser ajustar el prompt, las reglas de generación o añadir una capa de compatibilidad—antes de que los usuarios lo noten.
Manejo de errores y estabilidad de comportamiento entre versiones
Cuando los clientes se integran con tu API, normalmente no “leen” mensajes de error humanos: reaccionan a formas y códigos de error. Un error tipográfico en message molesta pero es manejable; cambiar un código de estado, omitir un campo o renombrar un identificador de error puede convertir una situación recuperable en un checkout roto, una sincronización fallida o un loop de reintentos infinito.
Errores estables: prioriza la legibilidad por máquina
Apunta a mantener una envoltura de error consistente (JSON) y un conjunto de identificadores estables que los clientes puedan usar. Por ejemplo, si devuelves { code, message, details, request_id }, no elimines ni renombres esos campos en una nueva versión. Puedes mejorar el texto en message libremente, pero mantén la semántica de code documentada y estable.
Si ya tienes múltiples formatos en producción, resiste la tentación de “limpiarlo” en el mismo lugar. En su lugar, añade un nuevo formato detrás de una frontera de versión o un mecanismo de negociación (p. ej., header Accept), y sigue soportando el antiguo.
Añadir códigos de error nuevos sin romper clientes antiguos
A veces necesitas nuevos códigos de error (nuevas validaciones, nuevos checks de autorización), pero debes introducirlos sin sorprender a integraciones existentes.
Un enfoque seguro:
- Mantén códigos antiguos válidos: si los clientes ya manejan
VALIDATION_ERROR, no lo reemplaces por INVALID_FIELD de la noche a la mañana.
- Introduce nuevos códigos como variantes más específicas: devuelve el nuevo
code pero incluye pistas compatibles en details (o mapea también al código general anterior para versiones antiguas).
- Documenta una regla de fallback: indica a los clientes que traten códigos desconocidos según la clase HTTP (400/401/403/404/409/429/500) y que muestren
message.
Nunca cambies el significado de un código existente. Si NOT_FOUND significaba “recurso no existe”, no lo uses para “acceso denegado” (eso sería 403).
Estabilidad de comportamiento: los defaults no deben cambiar silenciosamente
La retrocompatibilidad también es “misma petición, mismo resultado”. Cambios de default aparentemente pequeños pueden romper clientes que nunca establecieron parámetros explícitos.
Paginación: no cambies limit, page_size o el comportamiento de cursor por defecto sin versionar. Pasar de paginación por página a basada en cursor es rompiente a menos que mantengas ambas rutas.
Ordenación: el orden por defecto debe ser estable. Cambiar de created_at desc a relevance desc puede reordenar listas y romper suposiciones de UI o sincronizaciones incrementales.
Filtrado: evita alterar filtros implícitos (p. ej., excluir “inactive” por defecto). Si necesitas un nuevo comportamiento, añade una bandera explícita como include_inactive=true o status=all.
Algunos problemas no son de endpoints sino de interpretación.
- Zonas horarias: especifica siempre si los timestamps están en UTC, incluye offsets y sé consistente. Un cambio de hora local a UTC sin aviso puede causar eventos duplicados o perdidos.
- Formatos numéricos: los números JSON son claros, pero strings que parecen números (moneda, decimales) pueden variar. No cambies
"9.99" a 9.99 (o viceversa) en marcha.
- Defaults booleanos: valores por defecto como
include_deleted=false o send_email=true no deben invertirse. Si debes cambiar un default, exige que el cliente haga opt-in mediante un nuevo parámetro.
Para backends generados por IA, bloquea estos comportamientos con contratos explícitos y pruebas: el modelo puede “mejorar” respuestas a menos que forces la estabilidad como requisito principal.
Observabilidad: monitorizar la compatibilidad en producción
Lanza una v1 rápidamente
Construye una pequeña API v1 hoy y practica las reglas de compatibilidad antes de tu primera integración con socios.
La retrocompatibilidad no se comprueba una vez y se olvida. Con backends generados por IA, el comportamiento puede cambiar más rápido que en sistemas hechos a mano, así que necesitas bucles de feedback que muestren quién usa qué y si una actualización está dañando a clientes.
Mide por versión de API (y por endpoint)
Etiqueta cada petición con una versión de API explícita (ruta /v1/..., header X-Api-Version, o esquema negociado). Luego recoge métricas segmentadas por versión:
- Uso: requests por minuto por versión y ruta
- Latencia: p50/p95 por versión (un cambio compatible puede seguir siendo demasiado lento)
- Tasas de error: 4xx vs 5xx por versión (picos suelen revelar rupturas ocultas)
Esto te permite ver, por ejemplo, que /v1/orders es solo 5% del tráfico pero 70% de los errores tras un rollout.
Detecta clientes que siguen usando campos o endpoints antiguos
Instrumenta tu API gateway o aplicación para registrar qué clientes envían realmente y qué rutas llaman:
- Requests a endpoints deprecados (p. ej.,
/v1/legacy-search)
- Payloads que contienen campos deprecados
- Requests que faltan nuevos campos opcionales que algún código generado podría asumir presentes
Si controlas SDKs, añade un header identificador ligero + versión del SDK para detectar integraciones desactualizadas.
Usa logs y tracing para localizar el cambio
Cuando los errores suben, debes responder: “¿Qué despliegue cambió el comportamiento?” Correlaciona picos con:
- identificadores de release (commit hash/build id)
- logs estructurados que incluyan versión, ruta y fallos de validación
- trazas distribuidas que muestren dónde apareció latencia o excepciones (gateway → handler → BD)
Rollback acorde a despliegues generados
Mantén los rollbacks aburridos: siempre poder redeployar el artifact generado previo (imagen/container) y volver a enrutar tráfico. Evita rollbacks que requieran revertir datos; si hay cambios de esquema, prefiere migraciones aditivas para que las versiones antiguas sigan funcionando mientras reviertes la capa de API.
Si tu plataforma soporta snapshots de entorno y rollback rápido, úsalos. Por ejemplo, Koder.ai incluye snapshots y rollback en su workflow, lo que encaja bien con migraciones “expand → migrate → contract” y rollouts graduales de API.
Un flujo repetible para evolucionar APIs generadas por IA
Los backends generados por IA pueden cambiar rápido: aparecen endpoints nuevos, modelos cambian y validaciones se endurecen. La forma más segura de mantener a los clientes estables es tratar los cambios de API como un pequeño proceso de release repetible y no como “edits puntuales”.
El flujo (propuesta → retiro)
- Proponer el cambio
Escribe el “por qué”, el comportamiento previsto y el impacto exacto en el contrato (campos, tipos, requerido/opcional, códigos de error).
- Clasificarlo
Márqualo como compatible (seguro) o rompiente (requiere cambios de cliente). Si dudas, asume que rompe y diseña una ruta de compatibilidad.
- Diseñar el plan de compatibilidad
Decide cómo vas a soportar clientes antiguos: alias, dual-write/dual-read, valores por defecto, parseo tolerante o una nueva versión.
- Implementar detrás de guardarraíles
Añade el cambio con feature flags o configuración para desplegar gradualmente y revertir rápido.
- Probar el contrato
Ejecuta chequeos automáticos de contrato (p. ej., dif OpenAPI) y tests “golden” de clientes conocidos para detectar deriva.
- Liberar con documentación
Cada release debe incluir: docs actualizadas en /docs, una nota breve de migración cuando aplique y una entrada en el changelog que indique si el cambio es compatible.
- Deprecar y eliminar según calendario
Anuncia deprecaciones con fechas, añade headers/warnings, mide uso restante y elimina tras la ventana de sunset.
Mini-ejemplo: renombrar un campo sin romper clientes
Si quieres renombrar last_name a family_name:
- Request: acepta ambos campos; si ambos existen, preferir
family_name.
- Response: devuelve ambos durante el periodo de transición (o devuelve
family_name y deja last_name como alias).
- Almacenamiento: mapea ambos al mismo campo interno.
- Docs + changelog: documenta el nuevo nombre, marca
last_name como deprecado y fija una fecha de eliminación.
Si tu producto incluye soporte por plan o soporte a largo plazo, indícalo claramente en /pricing.