“Performance‑critical” no quiere decir “sería bueno que fuera rápido”. Significa que la experiencia se rompe cuando la app está siquiera un poco lenta, inconsistente o con retraso. Los usuarios no solo notan el lag: pierden un momento, toman una decisión equivocada o dejan de confiar en la app.
Ejemplos cotidianos donde el rendimiento es el producto
Algunos tipos de app lo dejan claro:
- Cámara y vídeo: tocas el disparador y esperas la captura inmediatamente. Retrasos pueden hacerte perder el momento. Parpadeos en la vista previa, enfoque lento o frames perdidos hacen que la app parezca poco fiable.
- Mapas y navegación: el punto azul debe moverse suave, los reroutes deberían ser instantáneos y la UI debe mantenerse responsiva mientras GPS, carga de datos y renderizado ocurren en paralelo.
- Trading y finanzas: una cotización que se actualiza tarde, un botón que registra el toque con retraso o una pantalla que se congela en volatilidad pueden afectar resultados directamente.
- Juegos: caídas de frames y retraso de entrada no solo “se sienten mal”, cambian el gameplay. El pacing consistente de frames importa tanto como los FPS brutos.
En todos estos casos, el rendimiento no es una métrica técnica oculta: es visible, se siente y se juzga en segundos.
Qué entendemos por “frameworks nativos” (sin palabrería)
Cuando decimos frameworks nativos, nos referimos a construir con las herramientas de primera clase de cada plataforma:
- iOS: Swift/Objective‑C con los SDKs de Apple (por ejemplo UIKit o SwiftUI, más frameworks del sistema)
- Android: Kotlin/Java con los SDKs de Android (por ejemplo Jetpack, Views/Compose, más APIs de plataforma)
Nativo no significa automáticamente “mejor ingeniería”. Significa que tu app habla el lenguaje de la plataforma de forma directa—especialmente importante cuando exprimes el dispositivo.
Los frameworks multiplataforma pueden ser una gran elección para muchos productos, sobre todo cuando la velocidad de desarrollo y el código compartido importan más que exprimir cada milisegundo.
Este artículo no defiende “siempre nativo”. Defiende que, cuando una app es realmente crítica en rendimiento, los frameworks nativos suelen eliminar categorías enteras de sobrecarga y limitaciones.
Las dimensiones que suelen decidir
Evaluaremos necesidades críticas de rendimiento en algunas dimensiones prácticas:
- Latencia: respuesta al toque, escritura, interacciones en tiempo real, sincronía audio/vídeo
- Renderizado: scroll suave, animaciones, pacing de frames, UI impulsada por GPU
- Batería y calor: eficiencia sostenida en sesiones largas
- Acceso hardware/SO: pipelines de cámara, sensores, Bluetooth, ejecución en background, ML en dispositivo
Estas son las áreas donde los usuarios notan la diferencia—y donde los frameworks nativos suelen destacar.
Los frameworks multiplataforma pueden sentirse “lo suficientemente cerca” cuando construyes pantallas típicas, formularios y flujos basados en red. La diferencia suele aparecer cuando una app es sensible a pequeños retrasos, necesita pacing de frames consistente o debe exprimir el dispositivo durante sesiones largas.
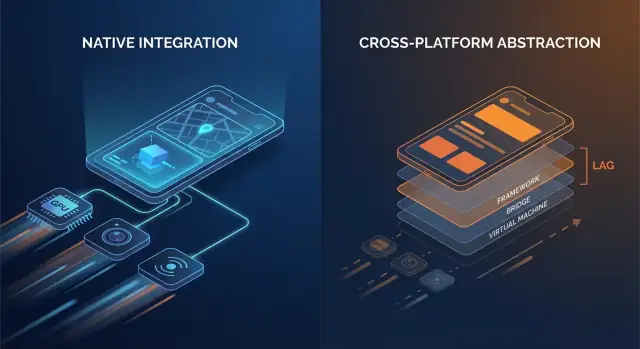
El código nativo habla con las APIs del SO directamente. Muchos stacks multiplataforma añaden una o más capas de traducción entre la lógica de la app y lo que el teléfono finalmente renderiza.
Puntos comunes de sobrecarga incluyen:
- Llamadas puente y cambios de contexto: si tu capa UI y la lógica viven en runtimes distintos (por ejemplo, un runtime gestionado o motor de scripting más código nativo), cada interacción puede requerir un salto entre fronteras.
- Serialización y copiado: los datos que cruzan fronteras pueden necesitar conversión (payloads tipo JSON, mapas tipados, buffers de bytes). Esa conversión puede aparecer en caminos calientes como scroll o escritura.
- Jerarquías de vistas extra: algunos frameworks crean su propio árbol UI y luego lo mapean a vistas nativas (o renderizan a un canvas). La reconciliación y el layout pueden volverse más costosos que una actualización directa de vista nativa.
Ninguno de estos costes es enorme por sí solo. El problema es la repetición: pueden aparecer en cada gesto, en cada tick de animación y en cada elemento de lista.
Tiempo de arranque y “jank” en tiempo de ejecución
La sobrecarga no es solo velocidad bruta; también es cuándo sucede el trabajo.
- El tiempo de inicio puede aumentar cuando la app debe inicializar un runtime adicional, cargar assets empaquetados, calentar un motor UI o reconstruir estado antes de que la primera pantalla sea interactiva.
- El jank en tiempo de ejecución suele venir de pausas impredecibles: recolección de basura, retropresión del puente, diffing costoso o una tarea larga que bloquea el hilo principal justo cuando la UI necesita completar el siguiente frame.
Las apps nativas también pueden sufrir estos problemas, pero hay menos piezas móviles, lo que significa menos sitios donde pueden esconderse sorpresas.
Un modelo mental simple
Piensa: menos capas = menos sorpresas. Cada capa añadida puede estar bien diseñada, pero todavía introduce más complejidad de planificación, más presión de memoria y más trabajo de traducción.
Cuándo la sobrecarga está bien—y cuándo no
Para muchas apps, la sobrecarga es aceptable y la ganancia de productividad es real. Pero para apps críticas en rendimiento—feeds de desplazamiento rápido, animaciones intensas, colaboración en tiempo real, procesamiento audio/vídeo o cualquier cosa sensible a la latencia—esos costes “pequeños” pueden volverse visibles rápido.
Suavidad de la UI: frames, jank y rutas de renderizado nativas
La UI suave no es solo algo “agradable”: es una señal directa de calidad. En una pantalla a 60 Hz, tu app tiene alrededor de 16.7 ms para producir cada frame. En dispositivos a 120 Hz, ese presupuesto baja a 8.3 ms. Cuando fallas en esa ventana, el usuario lo percibe como stutter (jank): scroll que “enganchado”, transiciones que tartamudean o un gesto que parece detrás del dedo.
Por qué es tan fácil notar frames perdidos
La gente no cuenta frames conscientemente, pero sí nota la inconsistencia. Un frame perdido durante un fade lento puede ser tolerable; varios durante un scroll rápido se vuelven inmediatamente obvios. Las pantallas de alta frecuencia también suben las expectativas: una vez que los usuarios experimentan suavidad a 120 Hz, el render inconsistente se siente peor que a 60 Hz.
El hilo principal es el cuello de botella habitual
La mayoría de frameworks UI aún dependen de un hilo primario/UI para coordinar input, layout y dibujo. El jank aparece cuando ese hilo hace demasiado trabajo en un frame:
- Pasadas de layout pesadas: jerarquías de vista complejas, contenedores anidados o relayouts frecuentes por cambios en constraints/tamaños.
- Animaciones costosas: animar propiedades que fuerzan relayout o re‑rasterización en lugar de dejar que la GPU maneje transformaciones.
- Trabajo síncrono en callbacks UI: parsear JSON, formatear grandes bloques de texto o ejecutar lógica de negocio durante eventos de scroll/gesto.
Los frameworks nativos tienden a tener pipelines bien optimizados y prácticas claras para mantener trabajo fuera del hilo principal, minimizar invalidaciones de layout y usar animaciones amigables con GPU.
Componentes nativos vs UI renderizada a medida
Una diferencia clave es la ruta de renderizado:
- Componentes nativos de plataforma normalmente se mapean directamente a widgets optimizados por el SO y a sistemas de compositing.
- Enfoques de UI renderizada a medida (comunes en stacks multiplataforma) pueden añadir un árbol de renderizado separado, subidas extra de texturas o trabajo adicional de reconciliación. Eso puede estar bien—hasta que tu pantalla se llena de animaciones o listas y la sobrecarga compite por un presupuesto de frame apretado.
Dónde se nota: ejemplos reales de pantalla
Listas complejas son la prueba de esfuerzo clásica: desplazamiento rápido + carga de imágenes + alturas de celda dinámicas pueden crear churn de layout y presión de GC/memoria.
Las transiciones pueden revelar ineficiencias de pipeline: animaciones de elemento compartido, fondos desenfocados y sombras en capas son visualmente ricas pero pueden disparar coste GPU y overdraw.
Las pantallas con muchos gestos (arrastrar para reordenar, tarjetas swipe, scrubbers) son implacables porque la UI debe responder continuamente. Cuando los frames llegan tarde, la UI deja de sentirse “pegada” al dedo del usuario—lo que precisamente las apps de alto rendimiento evitan.
Baja latencia: toque, escritura, audio y UX en tiempo real
La latencia es el tiempo entre una acción del usuario y la respuesta de la app. No es la “velocidad” global, sino la brecha que sientes al tocar un botón, escribir un carácter, arrastrar un slider, dibujar una traza o reproducir una nota.
Reglas prácticas por umbrales:
- 0–50 ms: se siente instantáneo. Toques y escritura se sienten directamente conectados al dedo.
- 50–100 ms: generalmente aceptable, pero la gente empieza a notar “suavidad” perdida, especialmente al arrastrar o scrubbing.
- 100–200 ms: retraso perceptible. Escribir parece atrasado; dibujar líneas “persigue” el stylus.
- 200 ms+: frustrante. Los usuarios ralentizan para compensar.
Las apps críticas en rendimiento—mensajería, toma de notas, trading, navegación, herramientas creativas—viven o mueren por estas brechas.
Bucles de eventos, scheduling y “saltos de hilo”
La mayoría de frameworks manejan input en un hilo, ejecutan lógica en otro y luego piden al UI actualizarse. Cuando ese camino es largo o inconsistente, la latencia se dispara.
Las capas multiplataforma pueden añadir pasos extra:
- Llega el input → se traduce a eventos del framework
- La lógica corre en un runtime separado (con su propio event loop)
- Los cambios de estado se serializan y devuelven
- Las actualizaciones UI se programan más tarde, a veces perdiendo el próximo frame
Cada transferencia (un “thread hop”) suma overhead y, más importante, jitter—la variación en el tiempo de respuesta—que suele sentirse peor que un retraso constante.
Los frameworks nativos tienden a tener un camino más corto y predecible del toque → actualización UI porque se alinean con el scheduler del SO, el sistema de input y el pipeline de renderizado.
UX en tiempo real: audio, vídeo y colaboración en vivo
Algunos escenarios tienen límites estrictos:
- Monitorización de audio/instrumentos: la latencia de ida y vuelta suele necesitar mantenerse por debajo de ~20 ms para sentirse tocable.
- Llamadas de voz/vídeo: puedes usar buffering para ocultar problemas de red, pero los controles UI (mute, altavoz, subtítulos) deben responder de inmediato.
- Colaboración en vivo (docs, pizarras): las ediciones locales deben aparecer instantáneamente, aunque la sincronización remota tarde más.
Las implementaciones nativas facilitan mantener la “ruta crítica” corta—priorizando input y renderizado sobre trabajo en background—para que las interacciones en tiempo real se mantengan ajustadas y fiables.
Hardware y funciones del SO: nativo primero, siempre
Lanza con un dominio personalizado
Aloja tu app en Koder.ai y añade un dominio personalizado cuando esté lista.
El rendimiento no es solo velocidad de CPU o tasa de frames. Para muchas apps, los momentos decisivos ocurren en los bordes—donde tu código toca la cámara, sensores, radios y servicios a nivel SO. Esas capacidades se diseñan y publican primero como APIs nativas, y esa realidad define qué es factible (y qué tan estable es) en stacks multiplataforma.
El acceso al hardware raramente es genérico
Funciones como pipelines de cámara, AR, BLE, NFC y sensores de movimiento a menudo requieren integración estrecha con frameworks específicos del dispositivo. Los wrappers multiplataforma pueden cubrir casos comunes, pero los escenarios avanzados tienden a exponer huecos.
Ejemplos donde las APIs nativas importan:
- Controles avanzados de cámara: enfoque y exposición manuales, captura RAW, vídeo a alta tasa de frames, ajuste HDR, conmutación multi‑cámara (wide/tele), datos de profundidad y comportamiento en baja luz.
- Experiencias AR: capacidades de ARKit/ARCore evolucionan rápido (oclusión, detección de planos, reconstrucción de escenas).
- BLE y modos de background: escaneos, comportamiento de reconexión y “funciona con pantalla apagada” dependen de reglas de ejecución en segundo plano por plataforma.
- NFC: acceso a elementos seguros, límites de emulación de tarjeta y gestión de sesiones lector son muy específicos por plataforma.
- Datos de salud: permisos de HealthKit/Google Fit, tipos de datos y entrega en background pueden ser matizados y requieren manejo nativo.
Las actualizaciones del SO llegan primero a lo nativo
Cuando iOS o Android lanzan nuevas funciones, las APIs oficiales están disponibles inmediatamente en los SDKs nativos. Las capas multiplataforma pueden tardar semanas (o más) en añadir bindings, actualizar plugins y resolver casos límite.
Esa demora no es solo incómoda: puede crear riesgo de fiabilidad. Si un wrapper no se actualiza para un release del SO, puedes ver:
- flujos de permisos que fallan,
- tareas en background restringidas,
- crashes provocados por comportamientos del sistema actualizados,
- regresiones que solo ocurren en ciertos modelos de dispositivo.
Para apps críticas en rendimiento, los frameworks nativos reducen el problema de “esperar al wrapper” y permiten a los equipos adoptar nuevas capacidades del SO desde el día uno—a menudo la diferencia entre lanzar una función este trimestre o el siguiente.
Batería, memoria y calor: rendimiento que se siente con el tiempo
La velocidad en una demo corta es solo la mitad de la historia. El rendimiento que los usuarios recuerdan es el que se mantiene después de 20 minutos de uso—cuando el teléfono está caliente, la batería baja y la app ha estado en background varias veces.
De dónde viene realmente el consumo de batería
La mayoría de drenajes “misteriosos” de batería son autoinfligidos:
- Wake locks y timers fuera de control mantienen la CPU despierta incluso con la pantalla apagada.
- Trabajo en background que nunca para (polling, comprobaciones de localización frecuentes, reintentos de red repetidos) suma rápidamente.
- Redibujados excesivos: reconstruir UI o re‑renderizar animaciones más a menudo de lo necesario mantiene CPU/GPU ocupados.
Los frameworks nativos suelen ofrecer herramientas más claras y predecibles para programar trabajo de forma eficiente (tareas en background, job scheduling, refresco gestionado por el SO), de modo que puedes hacer menos trabajo en total—y hacerlo en mejores momentos.
Presión de memoria: la fuente oculta de los stutters
La memoria no solo afecta si una app se cuelga; afecta la suavidad.
Muchos stacks multiplataforma usan un runtime gestionado con recolección de basura (GC). Cuando la memoria sube, la GC puede pausar la app brevemente para limpiar objetos no usados. No necesitas conocer los detalles internos para sentirlo: micro‑congelaciones ocasionales durante scroll, escritura o transiciones.
Las apps nativas tienden a seguir patrones de plataforma (como ARC en Apple), que suelen repartir el trabajo de limpieza de forma más uniforme. El resultado puede ser menos pausas “sorpresa”, especialmente bajo condiciones de memoria ajustada.
Calor y rendimiento sostenido
El calor es rendimiento. A medida que los dispositivos se calientan, el SO puede throttlear velocidades de CPU/GPU para proteger el hardware y los FPS caen. Esto es común en cargas sostenidas como juegos, navegación en tiempo real, cámara + filtros o audio en tiempo real.
El código nativo puede ser más eficiente en energía en estos escenarios porque puede usar APIs aceleradas por hardware y ajustadas por el SO para tareas pesadas—por ejemplo pipelines nativos de reproducción de vídeo, muestreo eficiente de sensores y codecs de medios de plataforma—reduciendo trabajo desperdiciado que se convierte en calor.
Cuando “rápido” también significa “fresco y estable”, los frameworks nativos suelen llevar la ventaja.
Perfilado y depuración: ver los cuellos de botella reales
Itera con seguridad usando instantáneas
Mantén las demos estables mientras mejoras la suavidad de la UI con instantáneas y reversiones.
El trabajo de rendimiento triunfa o fracasa por la visibilidad. Los frameworks nativos suelen traer los ganchos más profundos hacia el sistema operativo, el runtime y el pipeline de renderizado—porque los crean los mismos proveedores que definen esas capas.
Las apps nativas pueden adjuntar perfiles en las fronteras donde se introducen retrasos: el hilo principal, el hilo de render, el compositor del sistema, la pila de audio y los subsistemas de red y almacenamiento. Cuando persigues un stutter que ocurre cada 30 segundos, o un drenaje de batería que solo aparece en ciertos dispositivos, esos trazados “por debajo del framework” son a menudo la única forma de obtener una respuesta definitiva.
Herramientas nativas comunes
No necesitas memorizar todas para beneficiarte, pero ayuda saber qué existe:
- Xcode Instruments (Time Profiler, Allocations, Leaks, Core Animation, Energy Log)
- Depurador de Xcode (inspección de hilos, gráfico de memoria, breakpoints simbólicos)
- Android Studio Profiler (CPU, Memoria, Red, Energía)
- Perfetto / System Trace (trazado a nivel sistema en Android)
- Herramientas GPU como las de Metal en Xcode o inspectores de proveedores (para diagnosticar overdraw, coste de shaders, pacing de frames)
Estas herramientas están diseñadas para responder preguntas concretas: “¿Qué función está caliente?”, “¿Qué objeto nunca se libera?”, “¿Qué frame no cumplió su deadline y por qué?”.
Los bugs del “último 5%”: congelaciones, leaks y frames perdidos
Los problemas de rendimiento más duros suelen esconderse en casos límite: un deadlock de sincronización raro, un parseo JSON lento en el hilo principal, una vista que dispara layout costoso o un leak de memoria que solo aparece tras 20 minutos de uso.
El perfilado nativo te permite correlacionar síntomas (un freeze o jank) con causas (una pila de llamadas específica, un patrón de allocs o un pico GPU) en lugar de confiar en prueba y error.
Arreglos más rápidos para problemas de alto impacto
Mejor visibilidad acorta el tiempo para arreglar porque convierte debates en evidencia. Los equipos pueden capturar un trazo, compartirlo y acordar el cuello de botella rápidamente—a menudo reduciendo días de “tal vez es la red” a un parche enfocado y un resultado medible antes/después.
Fiabilidad a escala: dispositivos, actualizaciones del SO y casos límite
El rendimiento no es lo único que falla al distribuir a millones de teléfonos: la consistencia también. La misma app puede comportarse distinto entre versiones de SO, personalizaciones de OEM e incluso drivers GPU de distintos proveedores. La fiabilidad a escala es la capacidad de mantener la app predecible cuando el ecosistema no lo es.
Por qué “mismo Android/iOS” no es realmente lo mismo
En Android, las capas OEM pueden modificar límites en background, notificaciones, selectores de archivos y gestión de energía. Dos dispositivos con la “misma” versión de Android pueden diferir porque los vendedores incluyen distintos componentes y parches.
Las GPUs añaden otra variable. Los drivers de proveedor (Adreno, Mali, PowerVR) pueden divergir en precisión de shaders, formatos de textura y agresividad de optimizaciones. Un camino de render que se ve bien en una GPU puede mostrar parpadeos, bandas o crashes raros en otra—especialmente en vídeo, cámara y gráficos personalizados.
iOS es más homogéneo, pero las actualizaciones del SO aún cambian comportamientos: flujos de permiso, peculiaridades del teclado/autocompletado, reglas de sesiones de audio y políticas de tareas en background pueden variar entre versiones menores.
Las plataformas nativas exponen las APIs “reales” primero. Cuando el SO cambia, los SDKs nativos y la documentación suelen reflejar esos cambios de inmediato, y las herramientas de plataforma (Xcode/Android Studio, logs del sistema, símbolos de crash) se alinean con lo que corre en los dispositivos.
Los stacks multiplataforma añaden otra capa de traducción: el framework, su runtime/render y los plugins. Cuando aparece un caso límite, estás depurando tanto tu app como el bridge.
Riesgo de dependencias: actualizaciones, cambios rompientes y calidad de plugins
Las actualizaciones de framework pueden introducir cambios en runtime (threading, render, input, gestos) que solo fallan en ciertos dispositivos. Los plugins pueden ser peores: algunos son wrappers finos; otros embeben código nativo pesado con mantenimiento inconsistente.
Lista de verificación: evaluar librerías de terceros en caminos críticos
- Mantenimiento: releases recientes, triage activo de issues, propiedad clara.
- Paridad nativa: usa APIs oficiales de plataforma (no hooks privados/no soportados).
- Rendimiento: benchmarks, evita copias/allocs extras, mínimos saltos de puente.
- Modos de fallo: fallbacks gráciles, timeouts y reporte de errores.
- Compatibilidad: probado en versiones SO, dispositivos OEM y vendors GPU.
- Observabilidad: logs, símbolos de crash y casos reproducibles.
- Seguridad de upgrades: disciplina semver, changelogs, notas de migración.
A escala, la fiabilidad rara vez depende de un bug: depende de reducir el número de capas donde las sorpresas pueden esconderse.
Gráficos, medios y ML: cuando lo nativo es una ventaja clara
Gana créditos por lo que construyas
Comparte lo que construiste y gana créditos que puedes usar en Koder.ai.
Algunas cargas penalizan incluso pequeñas cantidades de sobrecarga. Si tu app necesita FPS sostenidos altos, trabajo GPU intenso o control fino sobre decodificación y buffers, lo nativo suele ganar porque puede conducir las rutas más rápidas de la plataforma directamente.
Trabajos que favorecen fuertemente lo nativo
Lo nativo encaja claramente para escenas 3D, experiencias AR, juegos de alta FPS, edición de vídeo y apps centradas en cámara con filtros en tiempo real. Estos casos no son solo “computacionalmente pesados”: son pesados en pipeline: mueves texturas y frames grandes entre CPU, GPU, cámara y encoders docenas de veces por segundo.
Copias extra, frames tardíos o sincronización desajustada se notan de inmediato como frames perdidos, sobrecalentamiento o controles laggy.
Acceso directo a APIs GPU, codecs y aceleración
En iOS, el código nativo puede usar Metal y la pila de medios del sistema sin capas intermedias. En Android, puede acceder a Vulkan/OpenGL y codecs de plataforma mediante NDK y APIs de media.
Eso importa porque la sumisión de comandos GPU, compilación de shaders y gestión de texturas son sensibles a cómo la app programa el trabajo.
Pipelines de render y uploads de texturas (alto nivel)
Un pipeline típico en tiempo real es: captura o carga de frames → conversión de formatos → subida de texturas → ejecución de shaders GPU → componer UI → presentar.
El código nativo puede reducir la sobrecarga manteniendo datos en formatos amigables para GPU más tiempo, agrupando llamadas de dibujo y evitando subidas repetidas de texturas. Incluso una conversión innecesaria por frame (por ejemplo RGBA ↔ YUV) puede añadir suficiente coste para romper la reproducción suave.
Inferencia ML: throughput, latencia y energía
El ML en dispositivo a menudo depende de delegados/backends (Neural Engine, GPU, DSP/NPU). La integración nativa tiende a exponer estos antes y con más opciones de ajuste—importante cuando te importa la latencia de inferencia y la batería.
Estrategia híbrida: módulos nativos para hotspots
No siempre necesitas una app totalmente nativa. Muchos equipos mantienen una UI multiplataforma para la mayoría de pantallas y añaden módulos nativos para los hotspots: pipelines de cámara, renderers personalizados, motores de audio o inferencia ML.
Esto puede entregar rendimiento casi nativo donde importa, sin reescribirlo todo.
Elegir un framework es menos ideológico y más cuestión de alinear expectativas de usuario con lo que el dispositivo debe hacer. Si tu app se siente instantánea, se mantiene fresca y permanece suave bajo estrés, rara vez los usuarios preguntan con qué está hecha.
Matriz práctica de decisión
Usa estas preguntas para acotar la elección:
- Expectativas del usuario: ¿es una app “utilitaria” donde algún hiccup es tolerable, o una experiencia donde el stutter rompe la confianza (banca, navegación, colaboración en vivo, herramientas creativas)?
- Necesidades de hardware: ¿necesitas pipeline de cámara, periféricos Bluetooth, sensores, procesamiento en background, audio de baja latencia, AR o trabajo pesado en GPU? Cuanto más “cerca del metal”, más compensa lo nativo.
- Línea de tiempo y velocidad de iteración: multiplataforma puede reducir time‑to‑market para UI sencilla y flujos compartidos. Nativo puede ser más rápido para tunear rendimiento porque trabajas directamente con tooling y APIs de plataforma.
- Habilidades del equipo y contratación: un equipo fuerte iOS/Android entregará código nativo de alta calidad más rápido. Un equipo pequeño con experiencia web puede llegar antes a un MVP con multiplataforma—si las restricciones de rendimiento son moderadas.
Si prototipas varias direcciones, puede ayudar validar flujos de producto rápidamente antes de invertir en optimización nativa profunda. Por ejemplo, equipos a veces usan Koder.ai para montar una web app (React + Go + PostgreSQL) mediante chat, probar UX y modelo de datos, y luego comprometerse a un build móvil nativo o híbrido cuando las pantallas críticas en rendimiento estén claras.
Qué significa realmente “híbrido” (y por qué suele ganar)
Híbrido no tiene que ser “web dentro de una app”. Para productos críticos en rendimiento, híbrido suele significar:
- Núcleo nativo + lógica compartida: mantener networking, estado y lógica de dominio compartida, mientras la UI y partes sensibles al rendimiento son nativas.
- Shell nativa + UI compartida donde sea seguro: usar UI compartida para pantallas mayormente estáticas o basadas en formularios, y mantener vistas con animaciones intensas o en tiempo real en nativo.
Este enfoque limita el riesgo: puedes optimizar los caminos más calientes sin reescribirlo todo.
Mide primero, luego decide
Antes de comprometer, construye un prototipo pequeño de la pantalla más difícil (por ejemplo, feed en vivo, timeline de editor, mapa + overlays). Mide estabilidad de frames, latencia de entrada, memoria y batería en una sesión de 10–15 minutos. Usa esos datos—no suposiciones—para elegir.
Si usas una herramienta asistida por IA como Koder.ai para iteraciones tempranas, trátala como multiplicador de velocidad para explorar arquitectura y UX, no como sustituto del perfilado a nivel dispositivo. Cuando apuntas a una experiencia crítica en rendimiento, la misma regla aplica: mide en dispositivos reales, define presupuestos de rendimiento y mantiene los caminos críticos (renderizado, input, medios) tan cerca de lo nativo como requieran tus necesidades.
Evita la optimización prematura
Empieza haciendo la app correcta y observable (profiling básico, logging y presupuestos de rendimiento). Optimiza solo cuando puedas señalar un cuello de botella que los usuarios notarán. Esto evita que los equipos pasen semanas rebajando milisegundos que no están en el camino crítico.