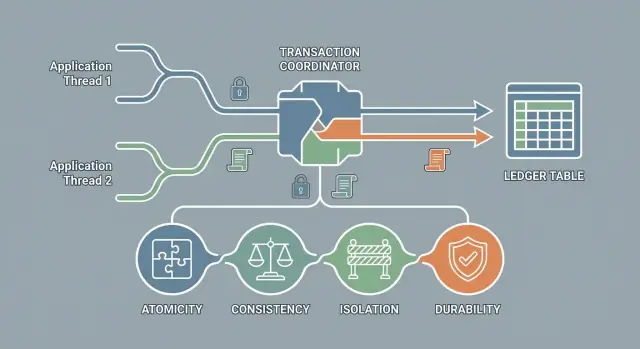
Qué significa “ACID” para las transacciones del día a día
Cuando pagas la compra, reservas un vuelo o mueves dinero entre cuentas, esperas un resultado inequívoco: o funcionó, o no. Las bases de datos intentan ofrecer esa misma certeza —incluso cuando muchos usuarios usan el sistema a la vez, los servidores fallan o la red tiene problemas.
Una transacción, en términos sencillos
Una transacción es una unidad de trabajo que la base de datos trata como un único “paquete”. Puede incluir varios pasos —restar inventario, crear un registro de pedido, cargar una tarjeta y escribir un recibo—, pero está pensada para comportarse como una sola acción coherente.
Si algún paso falla, el sistema debería retroceder a un punto seguro en vez de dejar un trabajo a medias.
Por qué las actualizaciones parciales generan problemas reales de negocio
Las actualizaciones parciales no son sólo fallos técnicos; se convierten en tickets de soporte y riesgo financiero. Por ejemplo:
- Se captura un pago, pero no se crea el pedido: el cliente es cobrado sin confirmación.
- Se crea un pedido, pero no se reduce el inventario: tu sitio sobrevende y tienes que cancelar luego.
- Una transferencia debita una cuenta pero no acredita la otra: los saldos dejan de tener sentido.
Estos fallos son difíciles de depurar porque todo parece “en su mayoría correcto”, pero los números no cuadran.
ACID es un conjunto de garantías (no un producto)
ACID es la abreviatura de cuatro garantías que muchas bases de datos pueden ofrecer para transacciones:
- Atomicidad: ejecución todo o nada
- Consistencia: los datos permanecen dentro de las reglas válidas
- Aislamiento: las transacciones concurrentes no interfieren de formas inseguras
- Durabilidad: una vez confirmado, el cambio persiste
No es una marca de base de datos ni una sola opción que activas; es una promesa sobre el comportamiento.
Beneficios — y los costes que debes esperar
Garantías más fuertes suelen implicar más trabajo por parte de la base de datos: coordinación adicional, esperar por bloqueos, rastrear versiones y escribir en logs. Eso puede reducir el rendimiento o aumentar la latencia bajo carga. El objetivo no es “máximo ACID siempre”, sino elegir garantías que coincidan con los riesgos reales de tu negocio.
Atomicidad: actualizaciones todo o nada
La atomicidad significa que una transacción se trata como una única unidad de trabajo: o termina por completo o no tiene efecto alguno. Nunca terminas con una “actualización a medias” visible en la base de datos.
Un ejemplo sencillo de transferencia bancaria
Imagina transferir $50 de Alice a Bob. Por debajo suele implicar al menos dos cambios:
- Restar $50 del saldo de Alice
- Sumar $50 al saldo de Bob
Con atomicidad, esos dos cambios tienen éxito juntos o fallan juntos. Si el sistema no puede hacer ambos de forma segura, no debe hacer ninguno. Eso evita el escenario pesadilla en que Alice es cobrada pero Bob no recibe el dinero (o Bob recibe el dinero sin que Alice haya sido cobrada).
Commit vs rollback (en lenguaje llano)
Las bases de datos dan dos salidas a las transacciones:
- Commit: “Todos los pasos tuvieron éxito; hacer oficiales los resultados.”
- Rollback: “Algo salió mal; deshacer todo lo de esta transacción.”
Un modelo mental útil es “borrador vs publicar”. Mientras la transacción se ejecuta, los cambios son provisionales. Sólo un commit los publica.
Qué puede fallar a mitad de la transacción
La atomicidad importa porque los fallos son normales:
- Caída de la app: tu servicio se detiene tras actualizar una tabla pero antes de actualizar la siguiente.
- Corte de red: la app no puede alcanzar la base de datos, o el cliente nunca recibe la respuesta de “éxito”.
- Pérdida de energía: el servidor de la base de datos se detiene inesperadamente.
Si cualquiera de esto ocurre antes de completar el commit, la atomicidad asegura que la base de datos pueda revertir para que el trabajo parcial no contamine los saldos reales.
Atomicidad más idempotencia y reintentos
La atomicidad protege el estado de la base de datos, pero tu aplicación aún debe manejar la incertidumbre —especialmente cuando una caída de red hace poco claro si el commit ocurrió.
Dos complementos prácticos:
- Reintentos: repetir una petición cuando no obtienes respuesta.
- Idempotencia: hacer que repetir la misma petición sea seguro (por ejemplo, usando una clave de idempotencia para que “transferencia #123” se aplique como máximo una vez).
Juntas, las transacciones atómicas y los reintentos idempotentes te ayudan a evitar tanto actualizaciones parciales como cargos dobles accidentales.
Consistencia: mantener los datos dentro de reglas válidas
La consistencia en ACID no significa “los datos parecen razonables” ni “todas las réplicas coinciden”. Significa que cada transacción debe llevar la base de datos de un estado válido a otro válido —según las reglas que definas.
La consistencia la definen las reglas que eliges
Una base de datos sólo puede mantener datos consistentes en relación con constraints, triggers e invariantes explícitas que describan qué significa “válido” para tu sistema. ACID no inventa esas reglas; las aplica durante las transacciones.
Ejemplos comunes:
- Claves foráneas: cada
order.customer_id debe apuntar a un cliente existente.
- Constraints de unicidad: no puede haber dos usuarios con el mismo email.
- Check constraints / invariantes: el saldo de una cuenta no puede ser negativo, o la cantidad de un artículo no puede ser menor que cero.
Si estas reglas están en su lugar, la base de datos rechazará cualquier transacción que las viole —así no terminas con datos “medio válidos”.
Validación en la app vs constraints en la base de datos
La validación en la app es importante, pero por sí sola no basta.
- Validación en la app mejora la experiencia de usuario (mensajes claros, feedback temprano) y puede imponer reglas de negocio complejas.
- Constraints en la base de datos actúan como la última puerta —especialmente cuando múltiples servicios, jobs en segundo plano, importaciones o herramientas administrativas escriben en las mismas tablas.
Un fallo clásico es comprobar algo en la app (“el email está disponible”) y luego insertar la fila. Bajo concurrencia, dos solicitudes pueden pasar la comprobación al mismo tiempo. Una constraint de unicidad en la base garantiza que sólo una inserción tendrá éxito.
Cómo se ve la consistencia en la práctica
Si codificas “no saldos negativos” como constraint (o lo haces cumplir de forma fiable dentro de una sola transacción), entonces cualquier transferencia que sobrepasaría el saldo debe fallar en su totalidad. Si no codificas esa regla en ningún lado, ACID no puede protegerla —porque no hay nada que haga cumplir.
La consistencia trata, en última instancia, de ser explícito: define las reglas y deja que las transacciones aseguren que nunca se rompan.
El aislamiento asegura que las transacciones no se interfieran. Mientras una transacción está en progreso, otras no deberían ver trabajo a medio hacer ni sobrescribirlo accidentalmente. La meta es sencilla: cada transacción debe comportarse como si se ejecutara sola, incluso cuando muchos usuarios están activos.
Por qué la concurrencia complica las cosas
Los sistemas reales están ocupados: clientes hacen pedidos, agentes de soporte actualizan perfiles, jobs en segundo plano reconcilian pagos —todo al mismo tiempo. Estas acciones se solapan en el tiempo y a menudo tocan las mismas filas (un saldo, un contador de inventario o una plaza reservada).
Sin aislamiento, el orden en que ocurren las cosas pasa a formar parte de la lógica de negocio. Una actualización de “restar stock” puede competir con otro pago, o un informe puede leer datos a medio cambiar y mostrar cifras que nunca existieron en un estado estable.
El aislamiento suele ser configurable
El aislamiento completo de “actuar como si estuvieras solo” puede ser caro. Puede reducir el throughput, aumentar la espera (bloqueos) o provocar reintentos de transacción. Mientras tanto, muchos flujos no necesitan la protección más estricta —los análisis diarios, por ejemplo, toleran incoherencias menores.
Por eso las bases de datos ofrecen niveles de aislamiento configurables: eliges cuánto riesgo de concurrencia aceptas a cambio de mejor rendimiento y menos conflictos.
Un vistazo rápido: anomalías que el aislamiento previene (o permite)
Cuando el aislamiento es demasiado débil para tu carga, aparecerán anomalías clásicas:
- Lecturas sucias: leer cambios que otra transacción no ha confirmado.
- Lost updates: dos transacciones se sobrescriben y desaparece un conjunto de cambios.
- Phantom reads: reejecutar una consulta devuelve un conjunto distinto de filas porque otra transacción insertó o eliminó filas coincidentes.
Entender estos modos de fallo facilita elegir un nivel de aislamiento acorde a las promesas de tu producto.
Anomalías comunes que el aislamiento evita (o permite)
Evita errores comunes de concurrencia
Pon en marcha un sistema de reservas o inventario que evite sobreventas y actualizaciones perdidas.
El aislamiento determina qué otras transacciones puedes “ver” mientras la tuya se ejecuta. Con aislamiento demasiado débil se producen anomalías: comportamientos técnicamente posibles pero sorprendentes para los usuarios.
Anomalías de lectura
Lectura sucia ocurre cuando lees datos que otra transacción ha escrito pero no ha confirmado.
Escenario: Alex transfiere $500 fuera de una cuenta, el saldo queda temporalmente en $200, y tú lees esos $200 antes de que la transferencia de Alex falle y haga rollback.
Resultado para el usuario: un cliente ve un saldo incorrecto bajo, una regla antifraude se dispara erróneamente o un agente de soporte da una respuesta equivocada.
Lectura no repetible significa que lees la misma fila dos veces y obtienes valores diferentes porque otra transacción confirmó entre medias.
Escenario: cargas el total de un pedido ($49.00), luego lo refrescas y ves $54.00 porque se eliminó una línea de descuento.
Resultado para el usuario: “Mi total cambió mientras finalizaba la compra”, lo que genera desconfianza o abandono del carrito.
Phantom read es como la lectura no repetible, pero con un conjunto de filas: una segunda consulta devuelve filas extra (o faltantes) porque otra transacción insertó/eliminó registros coincidentes.
Escenario: una búsqueda de hotel muestra “3 habitaciones disponibles”, luego al reservar el sistema vuelve a comprobar y no hay ninguna porque se añadieron nuevas reservas.
Resultado para el usuario: intentos de reserva duplicada, pantallas de disponibilidad inconsistentes o sobreventa de inventario.
Anomalías de escritura (errores reales habituales)
Lost update ocurre cuando dos transacciones leen el mismo valor y ambas escriben actualizaciones, y la escritura posterior sobrescribe a la anterior.
Escenario: dos administradores editan el mismo precio de producto. Ambos parten de $10; uno guarda $12, el otro guarda $11 al final.
Resultado para el usuario: desaparece el cambio de alguien; totales e informes incorrectos.
Write skew sucede cuando dos transacciones hacen cambios que son válidos por separado pero, juntas, violan una regla.
Escenario: Regla: “Al menos un médico de guardia debe estar programado.” Dos médicos, de forma independiente, se quitan de guardia después de comprobar que el otro sigue de guardia.
Resultado para el usuario: acabas con cero cobertura, a pesar de que cada transacción pasó sus comprobaciones.
Por qué no usar siempre el aislamiento más estricto
Un aislamiento más fuerte reduce anomalías pero puede aumentar esperas, reintentos y costes bajo alta concurrencia. Muchos sistemas eligen aislamiento más débil para análisis de lectura intensiva, mientras usan configuraciones más estrictas para movimientos de dinero, reservas y otros flujos críticos.
Niveles de aislamiento: elegir el ajuste de seguridad correcto
El aislamiento trata de qué puede “ver” tu transacción mientras otras se ejecutan. Las bases de datos exponen esto como niveles de aislamiento: niveles más altos reducen comportamientos sorprendentes, pero pueden costar rendimiento o aumentar la espera.
Los niveles de aislamiento comunes
- Read Uncommitted: puedes leer cambios que otra transacción aún no ha confirmado (“lecturas sucias”). Casi nada queda prevenido.
- Read Committed: sólo lees datos confirmados, por lo que las lecturas sucias se previenen. Pero si ejecutas la misma consulta dos veces, puedes ver resultados distintos porque alguien más confirmó entre medias (“lecturas no repetibles”).
- Repeatable Read: las lecturas que ya hiciste permanecen estables durante la transacción, así que las lecturas no repetibles suelen prevenirse. Dependiendo del motor, aún puedes ver “phantoms” o no.
- Serializable: las transacciones se comportan como si se ejecutaran una a la vez. Es el ajuste más fuerte, generalmente previene lecturas sucias, lecturas no repetibles y phantoms, y reduce muchas anomalías sutiles de escritura.
Elegir un nivel: rendimiento vs corrección
Los equipos suelen elegir Read Committed como predeterminado para apps orientadas al usuario: buen rendimiento y “no lecturas sucias” satisface la mayoría de expectativas.
Usa Repeatable Read cuando necesites resultados estables dentro de la transacción (por ejemplo, generar una factura) y puedas tolerar algo de sobrecarga.
Usa Serializable cuando la corrección sea más importante que la concurrencia (por ejemplo, para hacer cumplir invariantes complejos como “nunca sobrevender inventario”), o cuando no puedas razonar fácilmente sobre condiciones de carrera en el código de la aplicación.
Read Uncommitted es raro en sistemas OLTP; a veces se usa para monitorización o informes aproximados donde lecturas ocasionalmente erróneas son aceptables.
Advertencia importante: el comportamiento varía
Los nombres están estandarizados, pero las garantías exactas difieren según el motor de base de datos (y a veces según la configuración). Confirma con la documentación de tu SGBD y prueba las anomalías que importan para tu negocio.
Durabilidad: hacer que los commits perduren
La durabilidad significa que una vez que una transacción está confirmada, sus resultados deben sobrevivir a un fallo —pérdida de energía, reinicio o reboot inesperado. Si tu app dice a un cliente “pago exitoso”, la durabilidad es la promesa de que la base de datos no “olvidará” ese hecho tras el siguiente fallo.
Cómo hacen las bases de datos que los commits sobrevivan a fallos
La mayoría de bases relacionales consiguen durabilidad con write-ahead logging (WAL). A alto nivel, la base escribe un “recibo” secuencial de cambios en un log en disco antes de considerar la transacción como confirmada. Si la base falla, puede reproducir el log durante el arranque para restaurar los cambios confirmados.
Para mantener razonable el tiempo de recuperación, las bases también crean checkpoints. Un checkpoint es un momento en que la base asegura que suficientes cambios recientes están escritos en los archivos de datos principales, de modo que la recuperación no tenga que reproducir un historial de log ilimitado.
La durabilidad depende del almacenamiento y la configuración
La durabilidad no es un interruptor on/off; depende de cuánto fuerce la base los datos a almacenamiento estable.
- Con ajustes síncronos, la base espera a que el log se vuelque (a menudo mediante
fsync) antes de confirmar el commit. Esto es más seguro, pero puede añadir latencia.
- Con ajustes asíncronos, la base puede reconocer el commit antes de que el log esté completamente en almacenamiento duradero. El rendimiento puede mejorar, pero un fallo puede perder las transacciones "confirmadas" más recientes.
El hardware subyacente también importa: SSDs, controladores RAID con caché de escritura y volúmenes cloud pueden comportarse de forma distinta ante fallos.
Backups y replicación están relacionados, pero son distintos
Backups y replicación te ayudan a recuperar o reducir el tiempo de inactividad, pero no son lo mismo que la durabilidad. Una transacción puede ser durable en el primario aunque no haya llegado aún a una réplica, y los backups suelen ser snapshots en un punto en el tiempo en lugar de garantías commit a commit.
Cómo las bases de datos hacen cumplir ACID por debajo
Prueba la concurrencia desde el principio
Modela rápidamente bloqueos, reintentos y transacciones cortas en un proyecto funcional que puedas ejecutar.
Cuando haces BEGIN en una transacción y luego COMMIT, la base coordina muchas piezas: quién puede leer qué filas, quién puede actualizarlas y qué pasa si dos personas intentan cambiar el mismo registro al mismo tiempo.
Control de concurrencia pesimista vs optimista
Una decisión clave “por debajo” es cómo manejar conflictos:
- Bloqueo pesimista asume que los conflictos son probables. Cuando una transacción actualiza una fila, la base la bloquea para que otras transacciones esperen. Esto previene muchas anomalías, pero puede causar bloqueo.
- Enfoques optimistas asumen que los conflictos son raros. Las transacciones proceden con menos bloqueo y la base detecta conflictos al confirmar (o mediante checks) y puede rechazar una transacción para que se reintente.
Muchos sistemas mezclan ambas ideas según la carga y el nivel de aislamiento.
MVCC: los lectores no bloquean a los escritores
Las bases modernas suelen usar MVCC (Multi-Version Concurrency Control): en lugar de mantener sólo una copia de una fila, la base conserva múltiples versiones.
- Los lectores pueden ver un snapshot consistente (una versión anterior) sin esperar.
- Los escritores pueden crear una nueva versión mientras las lecturas continúan.
Esto explica en gran parte por qué algunas bases manejan muchas lecturas y escrituras concurrentes con menos bloqueos —aunque los conflictos write/write siguen requiriendo resolución.
Los bloqueos pueden llevar a deadlocks: la transacción A espera un bloqueo que retiene B, mientras que B espera uno que retiene A.
Las bases suelen resolver esto detectando el ciclo y abortar una transacción (la “víctima del deadlock”), devolviendo un error para que la app pueda reintentarlo.
Signos prácticos de que algo va mal
Si la aplicación sufre por la aplicación de ACID, a menudo verás:
- Aumentos en esperas por bloqueos durante picos
- Timeouts (consultas que fallan tras esperar demasiado)
- Puntos calientes de contención (unas pocas filas/tablas actualizadas constantemente, como contadores o campos "última vez visto")
Estos síntomas suelen indicar que es hora de revisar el tamaño de las transacciones, el indexing o la estrategia de aislamiento/bloqueo que encaja con la carga.
Cómo ACID moldea decisiones de diseño de la aplicación
Las garantías ACID no son sólo teoría de bases; influyen en cómo diseñas APIs, jobs en segundo plano e incluso flujos de UI. La idea central es simple: decide qué pasos deben tener éxito juntos y envuelve sólo esos pasos en una transacción.
Diseñar APIs alrededor de “un cambio de negocio”
Una API transaccional suele mapearse a una sola acción de negocio, aunque toque varias tablas. Por ejemplo, una operación /checkout podría: crear un pedido, reservar inventario y registrar una intención de pago. Esos escritos en BD deberían vivir típicamente en una transacción para que confirmen juntos (o se reviertan juntos) si alguna validación falla.
Un patrón común es:
- Validar entrada antes de abrir la transacción.
- Abrir una transacción.
- Realizar las lecturas/escrituras mínimas necesarias.
- Commit.
Esto preserva atomicidad y consistencia evitando transacciones lentas y frágiles.
Límites de transacción en requests, servicios y jobs
Dónde colocas los límites de transacción depende de qué signifique “una unidad de trabajo”:
- Requests de usuario: Mantén transacciones cortas —idealmente unas pocas consultas. No mantengas bloqueos mientras renderizas vistas o esperas respuestas externas.
- Jobs en segundo plano: Trata cada intento de job como una unidad de trabajo. Si un job procesa 10.000 registros, confirma por lotes para poder reiniciarlo con seguridad.
- Límites de servicio: Preferible mantener una transacción dentro de la base de datos de un solo servicio. Cruzar servicios normalmente exige otro enfoque (como un outbox), porque una transacción ACID no cubre fácilmente varias bases de datos.
Manejo de errores: rollback, reintentos y reejecuciones seguras
ACID ayuda, pero tu aplicación aún debe manejar fallos correctamente:
- Rollback ante error: Si algún paso falla, aborta la transacción para que no se filtren actualizaciones parciales.
- Reintento en errores transitorios: Fallos de serialización y deadlocks son normales con concurrencia. Reintentar toda la transacción suele ser la solución correcta.
- Haz las operaciones idempotentes: Si una petición se reintenta (por el cliente o el ejecutor de jobs), debe poder “reproducirse de forma segura” sin cobrar/envíar dos veces —usa claves de idempotencia y constraints únicas.
Antipatrones comunes
Evita transacciones largas, llamar APIs externas dentro de una transacción y tiempo de pensamiento del usuario dentro de la transacción (por ejemplo, “bloquear la fila del carrito y pedir confirmación al usuario”). Estas prácticas aumentan la contención y vuelven más probables los conflictos de aislamiento.
Dónde las herramientas pueden ayudar (sin cambiar lo fundamental)
Si estás construyendo un sistema transaccional rápidamente, el mayor riesgo no suele ser “no saber ACID”, sino dispersar una acción de negocio a través de múltiples endpoints, jobs o tablas sin un límite transaccional claro.
Plataformas como Koder.ai pueden ayudarte a avanzar más rápido manteniendo el diseño alrededor de ACID: puedes describir un flujo (por ejemplo, “checkout con reserva de inventario e intención de pago”) en un chat de planificación, generar una UI en React más un backend en Go + PostgreSQL, e iterar con snapshots/rollback si necesitas cambiar un esquema o un límite de transacción. La base de datos sigue aplicando las garantías; el valor está en acelerar el camino desde un diseño correcto hasta una implementación funcional.
ACID en sistemas distribuidos y multi‑servicio
Planifica tus transacciones con claridad
Usa un chat orientado a la planificación para definir invariantes, tablas y límites de transacción antes de codificar.
Una única base de datos suele ofrecer garantías ACID dentro de un límite transaccional. Cuando repartes trabajo entre varios servicios (y a menudo varias bases), esas mismas garantías son más difíciles de mantener —y más caras cuando se intentan conservar.
Consistencia vs disponibilidad: el trade‑off que sientes en producción
Consistencia estricta significa que cada lectura ve la “última verdad confirmada”. Alta disponibilidad significa que el sistema sigue respondiendo aunque partes estén lentas o inaccesibles.
En un entorno multi‑servicio, un problema de red temporal puede obligarte a elegir: bloquear o fallar peticiones hasta que todos los participantes estén de acuerdo (más consistente, menos disponible), o aceptar que los servicios estén brevemente desincronizados (más disponible, menos consistente). Ninguna opción es siempre “correcta”: depende de qué errores pueda tolerar tu negocio.
Por qué las transacciones distribuidas son difíciles
Las transacciones distribuidas requieren coordinación entre límites que no controlas completamente: retardos de red, reintentos, timeouts, caídas de servicio y fallos parciales.
Incluso si cada servicio es correcto, la red puede crear ambigüedad: ¿el servicio de pagos confirmó pero el de pedidos nunca recibió el acuse? Para resolverlo con seguridad, los sistemas usan protocolos de coordinación (como two‑phase commit), que pueden ser lentos, reducir disponibilidad durante fallos y añadir complejidad operativa.
Patrones prácticos que reemplazan la “gran transacción”
Sagas dividen un flujo en pasos, cada uno confirmado localmente. Si un paso posterior falla, los pasos anteriores se “deshacen” mediante acciones compensatorias (por ejemplo, reembolsar un cobro).
Patrón Outbox/Inbox hace fiable la publicación y consumo de eventos. Un servicio escribe datos de negocio y un registro “evento a publicar” en la misma transacción local (outbox). Los consumidores registran los IDs de mensajes procesados (inbox) para manejar reintentos sin duplicar efectos.
Consistencia eventual acepta ventanas cortas donde los datos difieren entre servicios, con un plan claro de reconciliación.
Cuándo relajar garantías — y cómo controlar el riesgo
Relaja garantías cuando:
- Puedes tolerar desincronizaciones temporales (estado de envío que va con retraso respecto al pedido).
- Puedes corregir errores con compensaciones (reembolsos, cancelaciones).
- La latencia y el tiempo de actividad importan más que la corrección global instantánea.
Controla el riesgo definiendo invariantes (lo que nunca debe violarse), diseñando operaciones idempotentes, usando timeouts y reintentos con backoff, y monitorizando la desviación (sagas atascadas, compensaciones repetidas, tablas outbox creciendo). Para invariantes realmente críticas (por ejemplo, “nunca gastar de más una cuenta”), mantenlas dentro de un solo servicio y una sola transacción de base de datos cuando sea posible.
Lista práctica: diseñar, probar y monitorear sistemas ACID
Una transacción puede ser “correcta” en un test unitario y aun así fallar bajo tráfico real, reinicios y concurrencia. Usa esta lista para alinear las garantías ACID con cómo tu sistema se comporta en producción.
1) Diseño: define invariantes y límites de transacción
Empieza escribiendo qué debe siempre ser verdad (tus invariantes de datos). Ejemplos: “el saldo de una cuenta nunca es negativo”, “el total de un pedido es la suma de sus líneas”, “el inventario no puede bajar de cero”, “un pago está vinculado exactamente a un pedido”. Trata estas reglas como normas de producto, no como trivia de base de datos.
Luego decide qué debe estar dentro de una transacción y qué puede diferirse.
- Invariantes de datos: lista tablas/filas involucradas y la regla exacta.
- Escenarios de fallo: caída del proceso a mitad de petición, timeout de red tras el commit, reintento que causa duplicados, failover de replica, disco lleno.
- Perfil de concurrencia: qué operaciones corren en paralelo (picos de checkout, actualizaciones por lotes, jobs programados), puntos calientes esperados y si las lecturas deben ser “en este momento” o pueden estar ligeramente obsoletas.
Mantén las transacciones pequeñas: toca menos filas, haz menos trabajo (sin llamadas externas) y confirma rápido.
2) Prueba: demuestra el comportamiento bajo carreras y fallos
Haz de la concurrencia una dimensión principal de las pruebas.
- Tests de condiciones de carrera: ejecuta la misma operación crítica concurrentemente (por ejemplo, dos checkouts para el último artículo) y verifica que las invariantes nunca se rompan.
- Inyección de fallos: mata el proceso de la app a mitad de transacción; inyecta timeouts; simula reintentos; fuerza un reinicio de BD; verifica que los resultados son o bien confirmados una vez o bien revertidos.
- Pruebas de carga con comprobaciones de corrección: bajo máximo throughput, valida no sólo latencias sino también totales, conteos y constraints “sin duplicados”.
Si soportas reintentos, añade una clave de idempotencia explícita y prueba “petición repetida después de un éxito”.
3) Monitorea: detecta el dolor ACID antes que los usuarios
Observa indicadores de que tus garantías se están volviendo caras o frágiles:
- Esperas por bloqueos y tiempo en cola (aumento de contención)
- Deadlocks (frecuencia, consultas víctimas)
- Transacciones de larga duración (a menudo la causa raíz)
- Lag de replicación (lecturas obsoletas y failover retrasado)
- Tiempos de commit/fsync (presión en almacenamiento; coste de durabilidad)
Avisa por tendencias, no sólo picos, y relaciona métricas con endpoints o jobs que las provocan.
Reglas prácticas: aislamiento y alcance de la transacción
Usa el aislamiento más débil que aún proteja tus invariantes; no "subas al máximo" por defecto. Cuando necesites corrección estricta para una pequeña sección crítica (movimiento de dinero, decremento de inventario), reduce la transacción a esa sección y deja todo lo demás fuera.