05 may 2025·8 min
Crear una aplicación web para gestionar cronogramas de escalación de clientes
Plan paso a paso para crear una app web que rastrea escalaciones de clientes, plazos, SLAs, propietarios y alertas, además de informes e integraciones.
Plan paso a paso para crear una app web que rastrea escalaciones de clientes, plazos, SLAs, propietarios y alertas, además de informes e integraciones.
Antes de diseñar pantallas o elegir una pila tecnológica, defina con precisión qué significa “escalación” en su organización. ¿Es un caso de soporte que envejece, un incidente que amenaza la disponibilidad, una queja de una cuenta clave o cualquier solicitud que supere un umbral de severidad? Si diferentes equipos usan la palabra con distintos significados, su aplicación codificará confusión.
Escriba una definición de una frase con la que todo el equipo pueda estar de acuerdo y añada algunos ejemplos. Por ejemplo: “Una escalación es cualquier problema de cliente que requiere un nivel superior de soporte o la intervención de la dirección, y que tiene un compromiso con límite de tiempo”.
También defina lo que no cuenta (p. ej., tickets rutinarios, tareas internas) para que la v1 no se hinche.
Los criterios de éxito deben reflejar lo que quiere mejorar —no solo lo que quiere construir. Resultados centrales comunes incluyen:
Elija 2–4 métricas que pueda rastrear desde el día uno (p. ej., tasa de incumplimiento, tiempo en cada etapa de escalación, recuento de reasignaciones).
Enumere los usuarios primarios (agentes, líderes de equipo, managers) y los interesados secundarios (gestores de cuentas, on-call de ingeniería). Para cada uno, anote lo que necesitan hacer rápidamente: asumir la propiedad, extender una fecha límite con una razón, ver qué sigue o resumir el estado para un cliente.
Capture modos de fallo actuales con historias concretas: traspasos fallidos entre niveles, tiempos de vencimiento poco claros tras una reasignación, debates tipo “¿quién aprobó la extensión?”.
Use estas historias para separar los imprescindibles (cronograma + propiedad + auditabilidad) de las adiciones posteriores (paneles avanzados, automatizaciones complejas).
Con los objetivos claros, escriba cómo se mueve una escalación por su equipo. Un flujo de trabajo compartido evita que los “casos especiales” se conviertan en manejo inconsistente y en SLAs incumplidos.
Comience con un conjunto simple de etapas y transiciones permitidas:
Documente qué significa cada etapa (criterios de entrada) y qué debe ser verdadero para salir de ella (criterios de salida). Aquí evita ambigüedades como “Resuelto pero aún esperando al cliente”.
Las escalaciones deben crearse por reglas que pueda explicar en una frase. Disparadores comunes incluyen:
Decida si los disparadores crean una escalación automáticamente, sugieren una al agente o requieren aprobación.
Su cronograma solo es tan bueno como sus eventos. Como mínimo, capture:
Escriba reglas para los cambios de propiedad: quién puede reasignar, cuándo se necesitan aprobaciones (p. ej., traspaso entre equipos o a un proveedor) y qué sucede si un propietario sale de turno.
Finalmente, mapee dependencias que afectan los tiempos: horarios on-call, niveles de tier (T1/T2/T3) y proveedores externos (incluyendo sus ventanas de respuesta). Esto impulsará sus cálculos de cronograma y la matriz de escalación más adelante.
Una aplicación de escalación fiable es principalmente un problema de datos. Si los cronogramas, SLAs e historial no se modelan claramente, la UI y las notificaciones siempre parecerán “desajustadas”. Empiece por nombrar las entidades y relaciones centrales.
Como mínimo, planifique para:
Trate cada milestone como un temporizador con:
start_at (cuando comienza el reloj)due_at (fecha límite calculada)paused_at / pause_reason (opcional)completed_at (cuando se cumple)Almacene por qué existe una fecha de vencimiento (la regla), no solo la marca temporal calculada. Eso facilita resolver disputas más tarde.
Los SLA rara vez significan “siempre”. Modele un calendario por política de SLA: horario comercial vs 24/7, días festivos y horarios específicos por región.
Calcule los plazos en un tiempo consistente del servidor (UTC), pero siempre guarde la zona horaria del caso (o del cliente) para que la UI pueda mostrar fechas límite correctamente y los usuarios puedan razonarlas.
Decida temprano entre:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), oPara cumplimiento y responsabilidad, prefiera un registro de eventos (aunque también mantenga columnas de “estado actual” para rendimiento). Cada cambio debe registrar quién, qué cambió, cuándo y origen (UI, API, automatización), más un ID de correlación para trazar acciones relacionadas.
Los permisos son donde las herramientas de escalación ganan confianza —o son reemplazadas por hojas de cálculo paralelas. Defina quién puede hacer qué desde el inicio y aplíquelo de forma coherente en la UI, API y exportaciones.
Mantenga la v1 simple con roles que coincidan con cómo trabajan realmente los equipos de soporte:
Haga las comprobaciones de rol explícitas en el producto: desactive controles en lugar de permitir que los usuarios hagan clic y reciban errores.
Las escalaciones suelen abarcar varios grupos (Tier 1, Tier 2, CSM, respuesta a incidentes). Planifique soporte multi-equipo mediante visibilidad limitada usando una o más de estas dimensiones:
Un buen valor por defecto: los usuarios pueden acceder a casos donde son asignados, watcher o pertenecen al equipo propietario, más cualquier cuenta compartida explícitamente con su rol.
No todos los datos deben ser visibles para todos. Campos sensibles comunes incluyen PII del cliente, detalles contractuales y notas internas. Implemente permisos a nivel de campo como:
Para la v1, email/contraseña con soporte MFA suele ser suficiente. Diseñe el modelo de usuario para que pueda añadir SSO más tarde (SAML/OIDC) sin reescribir permisos (p. ej., almacene roles/equipos internamente, mapee grupos SSO al iniciar sesión).
Trate los cambios de permiso como acciones auditables. Registre eventos como actualizaciones de rol, reasignación de equipo, descargas de exportaciones y edición de configuraciones —quién lo hizo, cuándo y qué cambió. Esto ayuda durante incidentes y facilita las revisiones de acceso.
Su aplicación de escalación triunfa o falla en las pantallas cotidianas: lo que ve primero un líder de soporte, qué tan rápido puede entender un caso y si la próxima fecha límite es imposible de pasar por alto.
Comience con un pequeño conjunto de páginas que cubran el 90% del trabajo:
Mantenga la navegación predecible: una barra lateral izquierda o pestañas superiores con “Queue”, “My Cases”, “Reports”. Haga que la cola sea la página de inicio por defecto.
En la lista de casos, muestre solo los campos que ayudan a decidir qué hacer a continuación. Una buena fila por defecto incluye: cliente, prioridad, propietario actual, estado, siguiente fecha de vencimiento e un indicador de advertencia (p. ej., “Due in 2h” o “Overdue by 1d”).
Agregue filtrado y búsqueda rápidos y prácticos:
Diseñe para escaneado: anchos de columna consistentes, chips de estado claros y un color de resaltado único usado solo para urgencia.
La vista de caso debe responder, de un vistazo:
Coloque acciones rápidas cerca de la parte superior (no ocultas en menús): Reassign, Escalate, Add milestone, Add note, Set next deadline. Cada acción debe confirmar lo que cambió y actualizar el cronograma inmediatamente.
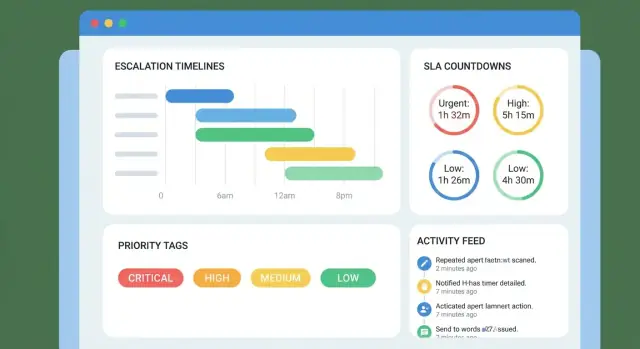
Su cronograma debe leerse como una secuencia clara de compromisos. Incluya:
Use divulgación progresiva: muestre primero los eventos más recientes con opción de expandir el historial antiguo. Si tiene una traza de auditoría, enlace a ella desde el cronograma (p. ej., “View change log”).
Use contraste de color legible, combine color con texto (“Overdue”), asegure que todas las acciones sean accesibles por teclado y escriba etiquetas que coincidan con el lenguaje del usuario (“Set next customer update deadline”, no “Update SLA”). Esto reduce clics equivocados cuando la presión es alta.
Las alertas son el “latido” de un cronograma de escalación: mantienen los casos en movimiento sin obligar a la gente a mirar un tablero todo el día. El objetivo es simple: notificar a la persona correcta, en el momento correcto, con el menor ruido posible.
Empiece con un conjunto pequeño de eventos que se mapeen directamente a acciones:
Para la v1, elija canales que pueda entregar de forma fiable y medir:
SMS o herramientas de chat pueden venir después una vez que las reglas y volúmenes estén estables.
Represente la escalación como umbrales temporales ligados al cronograma del caso:
Mantenga la matriz configurable por prioridad/cola para que los “P1 incidents” no sigan el mismo patrón que “preguntas de facturación”.
Implemente deduplicación (“no enviar la misma alerta dos veces”), agrupado (digest de alertas similares) y horas de silencio que retrasen recordatorios no críticos pero los registres.
Cada alerta debe soportar:
Almacene estas acciones en su traza de auditoría para que los informes puedan distinguir “nadie lo vio” de “alguien lo vio y lo pospuso”.
La mayoría de las aplicaciones de cronogramas de escalación fallan cuando requieren que la gente reescriba datos que ya existen. Para la v1, integre solo lo necesario para mantener los cronogramas precisos y las notificaciones a tiempo.
Decida qué canales pueden crear o actualizar un caso de escalación:
Mantenga las cargas entrantes pequeñas: case ID, customer ID, estado actual, prioridad, marcas de tiempo y un resumen corto.
Su app debe notificar otros sistemas cuando ocurra algo importante:
Use webhooks con peticiones firmadas y un ID de evento para deduplicación.
Si sincroniza en ambas direcciones, declare una fuente de la verdad por campo (p. ej., la herramienta de tickets es la que manda en estado; su app manda en temporizadores SLA). Defina reglas de conflicto (“last write wins” rara vez es correcto) y añada lógica de reintento con backoff más una dead-letter queue para fallos.
Para la v1, importe clientes y contactos usando IDs externos estables y un esquema mínimo: nombre de cuenta, nivel, contactos clave y preferencias de escalación. Evite reflejar profundamente el CRM.
Documente una lista corta (método auth, campos requeridos, límites de tasa, reintentos, entorno de prueba). Publique un contrato API mínimo (aunque sea en una página) y manténgalo versionado para que las integraciones no se rompan inesperadamente.
Su backend necesita hacer bien dos cosas: mantener los tiempos de escalación precisos y ser rápido a medida que crece el volumen de casos.
Elija la arquitectura más simple que su equipo pueda mantener. Una app clásica MVC con una API REST suele ser suficiente para una v1 de flujo de soporte. Si ya usan GraphQL con éxito, también puede funcionar —pero evite agregarlo “solo porque sí”. Combínelo con una base de datos gestionada (p. ej., Postgres) para que dedique tiempo a la lógica de escalación, no a operaciones de base de datos.
Si quiere validar el flujo end-to-end antes de comprometer semanas de ingeniería, una plataforma de prototipado como Koder.ai puede ayudar a prototipar el bucle central (queue → case detail → timeline → notifications) desde una interfaz conversacional, iterar en modo planificación y exportar código fuente cuando esté listo. Su stack por defecto (React en web, Go + PostgreSQL en backend) encaja bien con este tipo de app orientada a auditoría.
Las escalaciones dependen de trabajo programado, por lo que necesitará procesamiento en background para:
Implemente jobs idempotentes (seguros de ejecutar dos veces) y reintentables. Guarde un timestamp last evaluated at por caso/cronograma para evitar acciones duplicadas.
Almacene todas las marcas de tiempo en UTC. Conviértalas a la zona horaria del usuario solo en la frontera UI/API. Añada pruebas para casos extremos: cambios por horario de verano, años bisiestos y relojes “pausados” (p. ej., SLA pausado esperando al cliente).
Use paginación para colas y vistas de trazas de auditoría. Añada índices que coincidan con sus filtros y ordenamientos —comúnmente (due_at), (status), (owner_id) y compositos como (status, due_at).
Planifique el almacenamiento de archivos separado de la BD: imponga límites de tamaño/tipo, escanee cargas (o use un proveedor), y establezca reglas de retención (p. ej., borrar después de 12 meses salvo retención legal). Mantenga metadata en las tablas de gestión de casos; almacene el archivo en object storage.
Los informes son donde su app deja de ser una bandeja compartida y se convierte en una herramienta de gestión. Para la v1, apunte a una sola página de informes que responda dos preguntas: “¿Estamos cumpliendo los SLA?” y “¿Dónde se atascan las escalaciones?” Manténgala simple, rápida y basada en definiciones con las que todos estén de acuerdo.
Un informe solo es tan fiable como sus definiciones. Escríbalas en lenguaje claro y réflejas en su modelo de datos:
Decida también qué reloj de SLA reporta: primera respuesta, siguiente actualización o resolución (o los tres).
Su panel puede ser ligero pero accionable:
Añada vistas operativas para la gestión diaria:
Exportar a CSV suele ser suficiente para la v1. Ate las exportaciones a permisos (acceso por equipo, comprobaciones de rol) y registre una entrada en el log de auditoría por cada exportación (quién, cuándo, filtros usados, número de filas). Esto evita “hojas de cálculo misteriosas” y soporta cumplimiento.
Envíe la primera página de informes rápidamente y revísela con los líderes de soporte semanalmente durante un mes. Recoja feedback sobre filtros faltantes, definiciones confusas y preguntas tipo “No puedo responder X”: esos son sus mejores insumos para la v2.
Probar una app de cronogramas de escalación no es solo “¿funciona?” sino “¿se comporta como espera el equipo de soporte cuando hay presión?” Enfóquese en escenarios realistas que estresen reglas de cronograma, notificaciones y traspasos.
Dedique la mayor parte del esfuerzo de pruebas a los cálculos de cronograma, porque pequeños errores aquí generan grandes disputas de SLA.
Cubra casos como cómputo en horas laborales, festivos y zonas horarias. Añada pruebas para pausas (esperando cliente, ingeniería pendiente), cambios de prioridad a mitad de caso y escalaciones que desplazan objetivos. También pruebe condiciones límite: caso creado un minuto antes del cierre comercial o una pausa iniciada exactamente en un límite de SLA.
Las notificaciones suelen fallar en las grietas entre sistemas. Escriba pruebas de integración que verifiquen:
Si usa email, chat o webhooks, aserte los payloads y los tiempos —no solo que “algo se envió”.
Cree datos de muestra realistas que revelen problemas de UX temprano: clientes VIP, casos de larga duración, reasignaciones frecuentes, incidentes reabiertos y picos de cola “calientes”. Esto ayuda a validar que las colas, la vista de caso y la visualización del cronograma sean legibles sin explicación.
Ejecute un piloto con un único equipo durante 1–2 semanas. Recoja problemas diariamente: campos faltantes, etiquetas confusas, ruido en notificaciones y excepciones a sus reglas de cronograma.
Rastree lo que los usuarios hacen fuera de la app (hojas de cálculo, canales paralelos) para detectar brechas.
Escriba qué significa “hecho” antes del lanzamiento general: las métricas clave de SLA coinciden con resultados esperados, las notificaciones críticas son fiables, las trazas de auditoría están completas y el equipo piloto puede ejecutar escalaciones end-to-end sin soluciones alternativas.
Lanzar la primera versión no es la meta final. Una app de cronogramas de escalación se vuelve “real” cuando sobrevive a fallos cotidianos: jobs perdidos, consultas lentas, notificaciones mal configuradas y cambios inevitables en las reglas de SLA. Trate despliegue y operaciones como parte del producto.
Mantenga su proceso de lanzamiento aburrido y repetible. Como mínimo, documente y automatice:
Si tiene un entorno de staging, péñalo con datos realistas (sanitizados) para verificar comportamiento de cronogramas y notificaciones antes de producción.
Los chequeos de disponibilidad tradicionales no captarán los peores problemas. Añada monitorización donde las escalaciones puedan romperse silenciosamente:
Cree un playbook on-call pequeño: “Si los recordatorios de escalación no se envían, revise A → B → C.” Esto reduce el tiempo de inactividad en incidentes bajo presión.
Los datos de escalación a menudo incluyen nombres, correos y notas sensibles. Defina políticas temprano:
Haga la retención configurable para no necesitar cambios de código por actualizaciones de políticas.
Incluso en la v1, los admins necesitan maneras de mantener el sistema sano:
Escriba documentación corta, basada en tareas: “Crear una escalación”, “Pausar un cronograma”, “Anular el SLA”, “Auditar quién cambió qué”.
Añada un flujo de onboarding ligero en la app que guíe a los usuarios a las colas, vista de caso y acciones del cronograma, más un enlace a una página /help para referencia.
La versión 1 debe probar el bucle central: un caso tiene un cronograma claro, el reloj de SLA se comporta predeciblemente y las personas correctas reciben notificaciones. La v2 puede añadir potencia sin convertir la v1 en un sistema “lo tiene todo”. El truco es mantener un backlog corto y explícito de mejoras que solo saque cuando vea uso real.
Un buen ítem para v2 es algo que (a) reduce trabajo manual a escala, o (b) previene errores costosos. Si principalmente añade opciones de configuración, póngalo en espera hasta tener evidencia de que varios equipos lo necesitan.
Calendarios SLA por cliente suelen ser la primera expansión significativa: distintos horarios laborales, festivos o tiempos contratados de respuesta.
Después, añada playbooks y plantillas: pasos de escalación preconstruidos, interesados recomendados y borradores de mensajes que hagan las respuestas consistentes.
Cuando la asignación se convierta en un cuello de botella, considere enrutamiento por habilidades y horarios on-call. Mantenga la primera iteración simple: un pequeño conjunto de habilidades, un propietario fallback y controles claros de anulación.
La auto-escalación puede dispararse con ciertas señales (cambios de severidad, palabras clave, sentimiento, contactos repetidos). Empiece con “sugerir escalación” (un prompt) antes de “escalación automática”, y registre cada razón de disparo para ganarse la confianza y mantener auditabilidad.
Añada campos obligatorios antes de escalar (impacto, severidad, nivel de cliente) y pasos de aprobación para escalaciones de alta gravedad. Esto reduce ruido y ayuda a que los informes sigan siendo precisos.
Si quiere explorar patrones de automatización antes de implementarlos, vea /blog/workflow-automation-basics. Si está alineando el alcance con empaquetado, verifique cómo las características mapean a los niveles en /pricing.
Empieza con una definición de una sola frase con la que todo el equipo esté de acuerdo (más algunos ejemplos). Incluye explícitamente qué no es una escalación (tickets rutinarios, tareas internas) para que la v1 no se convierta en un sistema general de tickets.
Luego escribe 2–4 métricas de éxito que puedas medir de inmediato, como tasa de incumplimiento de SLA, tiempo en cada etapa o recuento de reasignaciones.
Elige resultados que reflejen mejora operativa, no solo el hecho de haber construido una característica. Métricas prácticas para la v1 incluyen:
Escoge un pequeño conjunto que puedas calcular con las marcas de tiempo del día uno.
Usa un conjunto pequeño y compartido de etapas con criterios claros de entrada/salida, por ejemplo:
Especifica qué debe ser verdadero para entrar y salir de cada etapa. Esto evita ambigüedades como “Resuelto pero aún esperando al cliente”.
Captura los eventos mínimos necesarios para reconstruir la línea de tiempo y justificar decisiones sobre SLA:
Si no puedes explicar para qué se usa una marca de tiempo, no la recolectes en la v1.
Modela cada milestone como un temporizador con:
start_atdue_at (calculado)paused_at y pause_reason (opcional)completed_atAdemás, guarda la regla que produjo (política + calendario + motivo). Eso facilita auditorías y disputas mucho más que almacenar solo la fecha límite final.
Almacena todas las marcas de tiempo en UTC, pero guarda la zona horaria del caso/cliente para la presentación y el razonamiento de los usuarios. Modela calendarios de SLA explícitamente (24/7 vs horario laboral, festivos, horarios regionales).
Prueba casos límite como cambios por horario de verano, casos creados cerca del cierre comercial y “pausa que empieza exactamente en el límite”.
Mantén las roles de la v1 simples y alineadas con flujos reales:
Añade reglas de alcance (equipo/región/cuenta) y controles a nivel de campo para datos sensibles como notas internas y PII.
Diseña primero las pantallas “del día a día”:
Optimiza para escaneo y reduce cambios de contexto: las acciones rápidas no deben estar escondidas en menús.
Empieza con un conjunto pequeño de notificaciones de alta señal:
Elige 1–2 canales para la v1 (normalmente in-app + email), y añade una matriz de escalación con umbrales claros (T–2h, T–0h, T+1h). Evita la fatiga con deduplicación, agrupado y horas de silencio, y haz que reconocer/posponer sea algo auditable.
Integra solo lo necesario para mantener los cronogramas precisos:
Si sincronizas bidireccionalmente, declara una fuente de la verdad por campo y reglas de conflicto (evita “el último en escribir gana”). Publica un contrato API mínimo versionado para que las integraciones no se rompan. Para más sobre patrones de automatización, ve /blog/workflow-automation-basics; para consideraciones de empaquetado, ve /pricing.
due_at