25 jun 2025·8 min
Por qué la gestión de estado es uno de los problemas frontend más difíciles
La gestión de estado es difícil porque las apps equilibran múltiples fuentes de verdad, datos asíncronos, interacciones de UI y compensaciones de rendimiento. Aprende patrones para reducir bugs.
Qué significa realmente “estado” en una app frontend
Una definición en lenguaje claro
En una aplicación frontend, estado es simplemente los datos de los que depende tu UI y que pueden cambiar con el tiempo.
Cuando el estado cambia, la pantalla debería actualizarse para coincidir. Si la pantalla no se actualiza, lo hace de forma inconsistente o muestra una mezcla de valores antiguos y nuevos, notarás inmediatamente “problemas de estado”: botones que siguen deshabilitados, totales que no coinciden o una vista que no refleja lo que el usuario acaba de hacer.
Ejemplos comunes que ves a diario
El estado aparece en interacciones pequeñas y grandes, como:
- Entradas de formularios: lo que el usuario escribió, si una casilla está marcada, qué errores mostrar
- Opciones de navegación: pestaña seleccionada, paso actual en un asistente, secciones expandidas/colapsadas
- Datos de compra/carrito: artículos, cantidades, cupones aplicados, totales calculados
- Sesión de usuario: información del usuario logueado, permisos, feature flags, preferencias de “recordarme”
Algunos de estos son “temporales” (como una pestaña seleccionada), mientras que otros se sienten “importantes” (como un carrito). Todos son estado porque influyen en lo que la UI renderiza ahora mismo.
Por qué el estado es más que “variables en un componente”
Una variable normal solo importa donde vive. El estado es distinto porque tiene reglas:
- Propiedad: qué parte de la app tiene permitido cambiarlo
- Flujo de actualización: cuándo y cómo los cambios disparan re-renders
- Consistencia: asegurar que varias piezas de la UI no se desincronicen
El objetivo real de la gestión de estado no es tanto almacenar datos, sino hacer las actualizaciones predecibles para que la UI siga consistente. Cuando puedes responder “qué cambió, cuándo y por qué”, el estado se vuelve manejable. Cuando no puedes, incluso funciones simples se convierten en sorpresas.
Por qué el estado se siente fácil al principio (y luego no lo es)
Al inicio de un proyecto frontend, el estado se siente casi aburrido —en el buen sentido. Tienes un componente, una entrada y una actualización obvia. Un usuario escribe en un campo, guardas ese valor y la UI se vuelve a renderizar. Todo es visible, inmediato y contenido.
El caso simple: un componente, una actualización
Imagina un único campo de texto que muestra una vista previa de lo que escribiste:
- El estado vive en el mismo componente que renderiza la entrada.
- La actualización ocurre en respuesta directa a una acción del usuario.
- No hay debate sobre “quién posee” los datos.
En ese escenario, el estado es básicamente: una variable que cambia con el tiempo. Puedes señalar dónde se guarda y dónde se actualiza, y ya está.
Por qué el estado local de componente parece sencillo
El estado local funciona porque el modelo mental coincide con la estructura del código:
- El alcance es pequeño (un componente, quizá un par de hijos).
- Las actualizaciones son sincrónicas desde la perspectiva del usuario.
- El flujo de datos es obvio: input → actualización → render.
Incluso si usas un framework como React, no necesitas pensar mucho en arquitectura. Los valores por defecto bastan.
Qué cambia cuando la app crece
Tan pronto como la app deja de ser “una página con un widget” y se convierte en “un producto”, el estado deja de vivir en un solo lugar.
Ahora el mismo dato puede necesitarse en:
- múltiples pantallas (navegación)
- componentes distantes (UI compartida)
- recargas y reinicios (persistencia)
- múltiples usuarios/dispositivos (sincronización con el servidor)
Un nombre de perfil puede mostrarse en un encabezado, editarse en una página de ajustes, almacenarse en caché para una carga más rápida y también usarse para personalizar un mensaje de bienvenida. De pronto la pregunta no es “cómo guardo este valor” sino “dónde debería vivir este valor para que sea correcto en todas partes?”
La complejidad aumenta no linealmente
La complejidad del estado no crece gradualmente con las funciones: da saltos.
Agregar un segundo lugar que lea el mismo dato no es “dos veces más difícil”. Introduce problemas de coordinación: mantener las vistas consistentes, prevenir valores obsoletos, decidir qué actualiza qué y manejar el tiempo. Una vez que tienes unas cuantas piezas de estado compartido más trabajo asíncrono, puedes acabar con comportamientos difíciles de razonar, aun cuando cada función individual siga pareciendo simple.
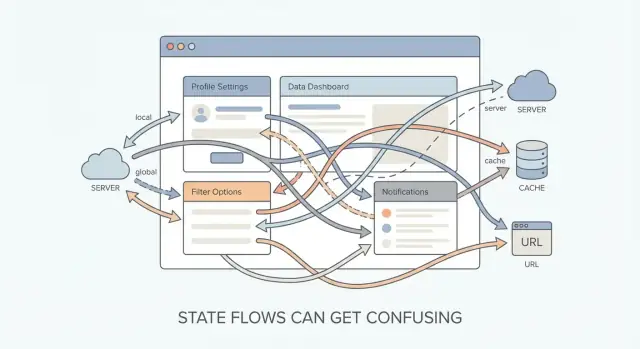
Demasiadas fuentes de la verdad
El estado se vuelve doloroso cuando un mismo “hecho” se guarda en más de un lugar. Cada copia puede desviarse, y entonces tu UI discute consigo misma.
Los culpables habituales
La mayoría de las apps terminan con varios lugares que pueden contener la “verdad”:
- Datos del servidor (tu API/base de datos): el registro canónico
- Caché del cliente (p. ej. caché de una librería de fetching): un espejo local que debe refrescarse
- Estado UI local (estado de componente): lo que el usuario está haciendo ahora mismo
- URL (ruta, query params, hash): estado que puedes marcar, compartir y restaurar
Todos estos son propietarios válidos para algunas piezas de estado. El problema empieza cuando intentan poseer el mismo estado.
Cómo ocurre la duplicación
Un patrón común: obtener datos del servidor y luego copiarlos al estado local “para poder editarlos”. Por ejemplo, cargas un perfil de usuario y haces formState = userFromApi. Más tarde, el servidor vuelve a obtener datos (o otra pestaña actualiza el registro) y ahora tienes dos versiones: la caché dice una cosa y tu formulario otra.
La duplicación también se cuela mediante transformaciones “útiles”: almacenar tanto items como itemsCount, o almacenar selectedId y selectedItem.
Síntomas que reconocerás
Cuando hay múltiples fuentes de verdad, los bugs suelen sonar así:
- “Funciona solo en esta pantalla.”
- La UI es inconsistente tras navegar o refrescar.
- Los datos se ven correctos en un componente pero obsoletos en otro.
- Guardar tiene éxito, pero la vista de lista no se actualiza (o se actualiza dos veces).
Regla práctica
Para cada pieza de estado, elige un propietario: el lugar donde se hacen las actualizaciones, y trata todo lo demás como una proyección (solo lectura, derivada o sincronizada en una sola dirección). Si no puedes señalar al propietario, probablemente estés almacenando la misma verdad dos veces.
Trabajo asíncrono y efectos secundarios complican el estado
Mucho del estado frontend se siente simple porque es sincrónico: el usuario hace clic, pones un valor y la UI se actualiza. Los efectos secundarios rompen esa historia paso a paso.
Qué cuenta como efecto secundario
Los efectos secundarios son acciones que salen del modelo puro de “renderizar según datos” del componente:
- Llamadas de red (fetching, guardado, reintentos)
- Timers y debouncing (setTimeout, intervals)
- Suscripciones (web sockets, listeners de eventos)
- Almacenamiento del navegador (localStorage/sessionStorage)
Cada uno puede ejecutarse más tarde, fallar inesperadamente o ejecutarse más de una vez.
Por qué el estado asíncrono es más difícil que el sincrónico
Las actualizaciones asíncronas introducen el tiempo como variable. Ya no razonas sobre “qué pasó”, sino sobre “qué podría estar pasando todavía”. Dos requests pueden solaparse. Una respuesta lenta puede llegar después de una más nueva. Un componente puede desmontarse mientras un callback asíncrono aún intenta actualizar el estado.
Por eso los bugs a menudo parecen:
- Flags de carga atascados para siempre (la ruta de error no los limpió, o la petición fue cancelada)
- UI que muestra datos antiguos (valor en caché mostrado como “final”)
- Respuestas obsoletas sobrescribiendo nuevas (la petición A termina después de la B)
Una estrategia simple: modela la petición explícitamente
En lugar de esparcir booleanos como isLoading por la UI, trata el trabajo asíncrono como una pequeña máquina de estados:
- idle (nada iniciado)
- loading (en progreso)
- success (datos disponibles)
- error (fallo capturado)
Haz seguimiento del dato y del estado juntos, y guarda un identificador (como un id de petición o una clave de query) para poder ignorar respuestas tardías. Esto hace que “¿qué debería mostrar la UI ahora?” sea una decisión clara, no una suposición.
Estado de UI vs Estado del servidor (se parecen, pero no son lo mismo)
Muchos dolores de cabeza empiezan con una confusión simple: tratar “lo que el usuario está haciendo ahora” igual que “lo que el backend dice que es verdad”. Ambos pueden cambiar con el tiempo, pero siguen reglas distintas.
Estado de UI: lo que hace la interfaz
El estado de UI es temporal y guiado por la interacción. Existe para renderizar la pantalla como el usuario la espera en este momento.
Ejemplos: modales abiertos/cerrados, filtros activos, borrador de búsqueda, hover/focus, pestaña seleccionada y UI de paginación (página actual, tamaño de página, posición de scroll).
Este estado suele ser local a una página o árbol de componentes. Está bien si se reinicia al navegar.
Estado del servidor: lo que obtuviste (y lo que puede cambiar en otro lado)
El estado del servidor es dato de una API: perfiles de usuario, listas de productos, permisos, notificaciones, ajustes guardados. Es la “verdad remota” que puede cambiar sin que tu UI haga nada (otra persona lo edita, el servidor lo recalcula, un job en background lo actualiza).
Porque es remoto, también necesita metadatos: estados de carga/error, timestamps de caché, reintentos e invalidación.
Por qué mezclarlos causa confusión
Si guardas borradores de UI dentro de datos del servidor, un refetch puede borrar ediciones locales. Si guardas respuestas del servidor dentro del estado UI sin reglas de caché, lucharás con datos obsoletos, fetches duplicados e pantallas inconsistentes.
Un fallo común: el usuario edita un formulario mientras un refetch en background termina, y la respuesta entrante sobrescribe el borrador.
Guía práctica
Gestiona el estado del servidor con patrones de caché (fetch, cache, invalidar, refetch al enfocar) y trátalo como compartido y asíncrono.
Gestiona el estado de UI con herramientas de UI (estado local de componente, context para preocupaciones UI realmente compartidas) y mantiene los borradores separados hasta que decidas “guardar” intencionalmente en el servidor.
Estado derivado y la regla “no almacenes lo que puedes calcular”
Refactoriza sin miedo
Haz un snapshot antes de refactorizar para que puedas experimentar con reducers, cachés y selectores de forma segura.
Estado derivado es cualquier valor que puedes calcular desde otro estado: un total del carrito a partir de las líneas, una lista filtrada desde la lista original + una query de búsqueda, o un flag canSubmit a partir de valores de campos y reglas de validación.
Es tentador almacenar estos valores porque parece conveniente (“también guardaré total en el estado”). Pero tan pronto como las entradas cambian en más de un lugar, te arriesgas a la deriva: el total almacenado ya no coincide con los items, la lista filtrada no refleja la query actual o el botón de enviar sigue deshabilitado tras arreglar un error. Estos bugs son molestos porque nada parece “malo” en aislamiento: cada variable de estado es válida por sí sola, pero inconsistente con el resto.
Prefiere selectores / valores calculados
Un patrón más seguro es: almacena la mínima fuente de la verdad y calcula todo lo demás al leer. En React esto puede ser una función simple o un cálculo memoizado.
const items = useCartItems();
const total = items.reduce((sum, item) =\u003e sum + item.price * item.qty, 0);
const filtered = products.filter(p =\u003e p.name.includes(query));
En apps más grandes, los “selectores” (o getters computados) formalizan esta idea: un lugar define cómo derivar total, filteredProducts, visibleTodos, y cada componente usa la misma lógica.
Cuando cachear valores derivados está bien
Calcular en cada render suele estar bien. Cachea cuando hayas medido un coste real: transformaciones costosas, listas enormes o valores derivados compartidos por muchos componentes. Usa memoización (useMemo, memoización en selectores) para que las claves del caché sean las verdaderas entradas; de lo contrario vuelves a la deriva, solo que con un sombrero de rendimiento.
Global vs Local: elegir el propietario correcto
El estado duele cuando no está claro quién lo posee.
Qué significa “propiedad”
El propietario de una pieza de estado es el lugar en tu app que tiene derecho a actualizarla. Otras partes de la UI pueden leerla (vía props, context, selectores, etc.), pero no deberían poder cambiarla directamente.
Una propiedad clara responde a dos preguntas:
- ¿Quién puede actualizar este valor? (el propietario)
- ¿Quién puede leer este valor? (consumidores)
Cuando esas fronteras se difuminan, obtienes actualizaciones conflictivas, momentos de “¿por qué cambió esto?” y componentes difíciles de reutilizar.
Estado global: conveniente, pero aparece acoplamiento
Poner estado en un store global (o en un context de nivel superior) puede sentirse limpio: cualquier cosa puede acceder y evitas prop drilling. El tradeoff es el acoplamiento no deseado: pantallas no relacionadas dependen de los mismos valores y pequeños cambios repercuten por toda la app.
El estado global encaja con cosas realmente transversales, como la sesión de usuario actual, feature flags a nivel de app o una cola de notificaciones compartida.
Eleva el estado—solo lo necesario
Un patrón común es empezar local y “elevar” el estado al padre común más cercano solo cuando dos partes hermanas necesitan coordinarse.
Si solo un componente necesita el estado, mantenlo allí. Si varios componentes lo necesitan, elévalo al propietario compartido más pequeño. Si muchas áreas distantes lo necesitan, entonces considera global.
Una heurística simple
Mantén el estado cerca de donde se usa a menos que el compartir sea necesario.
Esto hace los componentes más fáciles de entender, reduce dependencias accidentales y hace los futuros refactors menos intimidantes porque menos partes de la app pueden mutar los mismos datos.
Concurrencia, carreras y actualizaciones fuera de orden
Planifica tu modelo de estado
Usa el modo Planificación para definir la propiedad, el estado del servidor y los valores derivados antes de codificar.
Las apps frontend parecen “single-threaded”, pero la entrada del usuario, timers, animaciones y requests de red corren independientemente. Eso significa que múltiples actualizaciones pueden estar en vuelo a la vez —y no necesariamente terminan en el orden en que las iniciaste.
Cuando las actualizaciones chocan
Una colisión común: dos partes de la UI actualizan el mismo estado.
- Un buscador actualiza
queryen cada pulsación. - Un dropdown de filtro actualiza
query(o la misma lista de resultados) al cambiar.
Individualmente, cada actualización es correcta. Juntas, pueden sobrescribirse dependiendo del timing. Peor aún, puedes acabar mostrando resultados de una query anterior mientras la UI muestra los nuevos filtros.
Condiciones de carrera: usuarios rápidos, redes lentas
Las condiciones de carrera aparecen cuando disparas la petición A y luego rápidamente la B —pero la A responde al final.
Ejemplo: el usuario escribe “c”, “ca”, “cat”. Si la petición de “c” es lenta y la de “cat” rápida, la UI puede mostrar resultados para “cat” y luego ser sobrescrita por la respuesta obsoleta de “c”.
El bug es sutil porque todo “funcionó”, solo que en el orden equivocado.
Técnicas para reducir bugs por orden fuera de lugar
Normalmente quieres una de estas estrategias:
- Cancelar la petición anterior cuando una nueva la reemplaza (por ejemplo usando
AbortController). - Ignorar respuestas obsoletas comprobando si la respuesta todavía coincide con la entrada más reciente.
- Usar IDs de petición / números de secuencia y aceptar solo la más nueva.
Un enfoque simple con request ID:
let latestRequestId = 0;
async function fetchResults(query) {
const requestId = ++latestRequestId;
const res = await fetch(`/api/search?q=${encodeURIComponent(query)}`);
const data = await res.json();
if (requestId !== latestRequestId) return; // stale response
setResults(data);
}
Actualizaciones optimistas (y cómo fallan)
Las actualizaciones optimistas hacen que la UI se sienta instantánea: actualizas la pantalla antes de que el servidor confirme. Pero la concurrencia puede romper suposiciones:
- El usuario hace clic en “Me gusta” dos veces rápido (me gusta → no me gusta), pero las peticiones se resuelven fuera de orden.
- Disminuyes optimistamente el inventario y luego una falla obliga a revertir: el usuario ya navegó o hizo más cambios.
Para mantener la optimización segura, normalmente necesitas una regla clara de reconciliación: rastrear la acción pendiente, aplicar respuestas del servidor en orden y, si debes revertir, hacerlo a partir de un checkpoint conocido (no “lo que la UI muestra ahora”).
Rendimiento: cuando cambiar el estado es demasiado caro
Las actualizaciones de estado no son “gratis”. Cuando el estado cambia, la app tiene que calcular qué partes de la pantalla pueden verse afectadas y luego hacer el trabajo para reflejar la nueva realidad: recalcular valores, re-renderizar UI, volver a ejecutar lógica de formateo y, a veces, volver a fetch o validar datos. Si esa reacción en cadena es mayor de lo necesario, el usuario la nota como lag, stutter o botones que parecen “pensar” antes de responder.
Por qué un cambio pequeño puede sentirse grande
Un solo toggle puede disparar mucho trabajo extra:
- Se re-renderizan grandes secciones de la UI aunque solo haya cambiado una pequeña parte.
- Las listas se vuelven a dibujar y medir, causando trompicones al hacer scroll.
- Objetos y arrays se recrean en cada actualización (“deep churn”), por lo que la app no puede distinguir fácilmente qué cambió realmente.
El resultado no es solo técnico: es experiencial. Escribir se siente lento, las animaciones se traban y la interfaz pierde esa sensación “snappy” que asocian las personas con productos pulidos.
Trampas comunes de rendimiento
Una de las causas más habituales es un estado demasiado amplio: un “gran cubo” que contiene mucha información no relacionada. Actualizar cualquier campo hace que todo el cubo parezca nuevo, por lo que más partes de la UI se despiertan de lo necesario.
Otra trampa es almacenar valores computados en el estado y actualizarlos manualmente. Eso suele crear actualizaciones extra (y trabajo UI extra) solo para mantener todo en sincronía.
Tácticas para mantener la UI rápida
Divide el estado en rebanadas más pequeñas. Mantén preocupaciones no relacionadas separadas para que cambiar una búsqueda no refresque toda la página de resultados.
Normaliza los datos. En lugar de almacenar la misma entidad en muchos sitios, guárdala una vez y referencia. Esto reduce actualizaciones repetidas y previene “tormentas de cambios” donde una edición fuerza muchas copias a reescribirse.
Memoiza valores derivados. Si un valor puede calcularse desde otro estado (como resultados filtrados), cachea ese cálculo para que solo se recalcule cuando las entradas realmente cambien.
El objetivo: menos bloqueos, menos sorpresas
La buena gestión de estado con foco en rendimiento trata sobre contención: las actualizaciones deberían afectar al área más pequeña posible y el trabajo costoso debería ocurrir solo cuando sea necesario. Cuando eso se cumple, los usuarios dejan de notar el framework y empiezan a confiar en la interfaz.
Depurar y testear el estado sin conjeturas
Los bugs de estado a menudo se sienten personales: la UI está “mal”, pero no puedes responder la pregunta más simple—¿quién cambió este valor y cuándo? Si un número cambia, un banner desaparece o un botón se desactiva, necesitas una línea de tiempo, no una corazonada.
Haz que los cambios sean trazables (no misteriosos)
El camino más rápido hacia la claridad es un flujo de actualización predecible. Ya uses reducers, eventos o un store, apunta a un patrón donde:
- Los cambios ocurren a través de un conjunto pequeño de acciones bien nombradas (no mutaciones aleatorias)
- Cada acción tiene una carga clara (
setShippingMethod('express'), noupdateStuff) - Puedes loguear acciones y transiciones de estado de forma consistente
Un logging claro de acciones convierte la depuración de “mirar la pantalla” a “seguir el recibo”. Incluso logs simples en consola (nombre de acción + campos clave) superan intentar reconstruir lo ocurrido a partir de los síntomas.
Testea la lógica donde es estable
No intentes testear cada re-render. En vez de eso, prueba las partes que deberían comportarse como lógica pura:
- Unit tests para reducers / actualizadores de estado: dado un estado previo + acción, aserta el siguiente estado
- Unit tests para selectores / cálculos derivados: dado un estado, aserta la salida computada
- Tests de integración para flujos clave de usuario: login → cargar datos → editar → guardar → ver confirmación
Esta mezcla atrapa tanto “errores de cálculo” como problemas de wiring en el mundo real.
Añade instrumentación ligera para bugs asíncronos
Los problemas asíncronos se esconden en huecos. Añade metadata mínima que haga visibles las líneas de tiempo:
- timestamps en actualizaciones importantes
- IDs de petición (adjunta el ID a acciones y respuestas)
Entonces cuando una respuesta tardía sobrescribe una más nueva, puedes probarlo de inmediato y arreglarlo con confianza.
Elegir un enfoque de gestión de estado (sin guerras de herramientas)
Comparte una demo funcional
Publica una demo funcional con hosting y dominio personalizado cuando necesites algo para compartir.
Elegir una herramienta de estado es más fácil cuando la tratas como una consecuencia de decisiones de diseño, no como punto de partida. Antes de comparar librerías, mapea los límites de tu estado: qué es puramente local al componente, qué necesita compartirse y qué es realmente “estado del servidor” que obtienes y sincronizas.
Criterios de selección que importan
Una forma práctica de decidir es mirar algunas restricciones:
- Tamaño y vida de la app: una herramienta interna pequeña puede mantenerse simple; un producto de larga vida se beneficia de convenciones fuertes.
- Hábitos del equipo: elige algo que tu equipo pueda usar de forma consistente (y revisar con confianza).
- Necesidades asíncronas: mucho fetching, caching, paginación y mutaciones cambian la ecuación.
- Complejidad del estado: flujos entre páginas, undo/redo y formularios multi-paso suelen requerir más estructura.
Comparación a alto nivel (sin ideología)
- Context + hooks: excelente para inyección de dependencias y valores compartidos de baja frecuencia (tema, info de auth). Puede funcionar para estado, pero actualizaciones frecuentes pueden volverse ruidosas sin patrones adicionales.
- Stores estilo Redux: convenciones fuertes, actualizaciones predecibles y excelente tooling. Mejor cuando necesitas un historial de auditoría claro o coordinación compleja entre features.
- Atom stores (estado de grano fino): ergonómicos para estado compartido sin cablear muchos reducers. A menudo más fácil de escalar de forma incremental.
- Caches de query (herramientas de server-state): especializadas en fetching, caching, deduplicación, refetch en background y mutaciones. Reducen una gran parte del “pegamento” asíncrono.
Evita pensar en función de la herramienta primero
Si empiezas con “usamos X en todas partes”, acabarás guardando cosas equivocadas en sitios equivocados. Parte de la propiedad: quién actualiza, quién lee y qué debería pasar cuando cambia.
Combinar herramientas suele ser la mejor opción
Muchas apps funcionan bien con una librería de server-state para datos de API y una solución pequeña de UI-state para preocupaciones del cliente como modales, filtros o borradores de formularios. La meta es claridad: cada tipo de estado vive donde es más fácil de razonar.
Dónde encaja Koder.ai
Si iteras sobre límites de estado y flujos asíncronos, Koder.ai puede acelerar el bucle de “probar, observar, refinar”. Al generar frontends React (y backends en Go + PostgreSQL) desde chat con un workflow basado en agentes, puedes prototipar modelos alternativos de propiedad (local vs global, caché del servidor vs borradores UI) rápidamente y quedarte con la versión que resulte predecible.
Dos funcionalidades prácticas ayudan al experimentar con estado: Planning Mode (para esbozar el modelo de estado antes de construir) y snapshots + rollback (para probar refactors como “eliminar estado derivado” o “introducir IDs de petición” sin perder una línea base funcional).
Checklist práctico para hacer el estado menos doloroso
El estado se vuelve más fácil si lo tratas como un problema de diseño: decide quién lo posee, qué representa y cómo cambia. Usa este checklist cuando un componente empiece a sentirse “misterioso”.
1) Aclara la propiedad y la fuente única de la verdad
Pregunta: ¿Qué parte de la app es responsable de estos datos? Pon el estado lo más cerca posible de donde se usa y elévalo solo cuando varias partes realmente lo necesiten.
- Un propietario por pieza de estado.
- Pasa datos hacia abajo; envía cambios hacia arriba vía callbacks/eventos.
- Si dos lugares pueden actualizar el mismo valor, no tienes una fuente de verdad—tienes un conflicto esperando ocurrir.
2) Evita duplicaciones y modela valores derivados
Si puedes calcular algo a partir de otro estado, no lo almacenes.
- Guarda las entradas mínimas (p. ej.,
items,filterText). - Calcula las salidas (p. ej.,
visibleItems) durante el render o via memoización.
3) Haz explícitos los estados asíncronos (no los asumas)
El trabajo asíncrono es más claro cuando lo modelas directamente:
- Prefiere una pequeña forma de “request state”:
status: 'idle' | 'loading' | 'success' | 'error', másdatayerror. - Trata “loading” y “error” como estados UI de primera clase, no booleanos dispersos.
4) Vigila antipatrónes comunes
- Copiar props al state “por si acaso” (crea deriva).
- Globalizarlo todo (hace que pantallas no relacionadas se acoplen).
- Sopa de booleanos (
isLoading,isFetching,isSaving,hasLoaded, …) en lugar de un únicostatus.
5) Refactoriza en pasos pequeños y seguros
- Divide el estado mezclado: separa preocupaciones de UI (open/closed, texto de input) de datos del servidor.
- Borra valores derivados almacenados y cómputalos desde la fuente real.
- Centraliza efectos secundarios (fetching, suscripciones) en un solo lugar por feature.
Objetivos prácticos
Apunta a menos bugs del tipo “¿cómo llegó a este estado?”, cambios que no requieren tocar cinco archivos y un modelo mental donde puedas señalar un lugar y decir: aquí vive la verdad.