14 jul 2025·8 min
Estrategias de gestión de memoria: rendimiento vs seguridad en los lenguajes
Aprende cómo la recolección de basura, la propiedad y el conteo de referencias afectan velocidad, latencia y seguridad, y cómo elegir el lenguaje que encaje con tus objetivos.
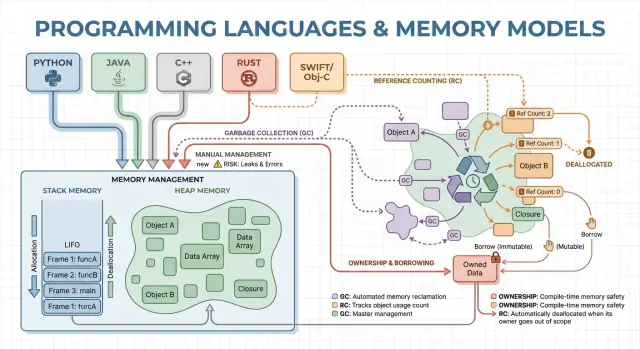
Por qué la gestión de memoria afecta el rendimiento y la seguridad
La gestión de memoria es el conjunto de reglas y mecanismos que un programa usa para solicitar memoria, usarla y devolverla. Todo programa en ejecución necesita memoria para cosas como variables, datos de usuario, buffers de red, imágenes y resultados intermedios. Como la memoria es limitada y se comparte con el sistema operativo y otras aplicaciones, los lenguajes deben decidir quién es responsable de liberarla y cuándo sucede eso.
Esas decisiones moldean dos resultados que importan a la mayoría: qué tan rápido se siente un programa y qué tan fiable se comporta bajo presión.
Qué entendemos por “rendimiento” aquí
El rendimiento no es un único número. La gestión de memoria puede afectar a:
- Throughput (rendimiento): cuánto trabajo puedes completar por segundo (peticiones atendidas, frames renderizados, archivos procesados).
- Latencia: cuánto tarda una operación individual, especialmente picos de latencia de cola causados por pausas o asignaciones lentas.
- Huella de memoria: cuánta RAM mantiene el programa mientras se ejecuta, lo que influye en coste, batería y con qué frecuencia el SO empieza a hacer swapping.
Un lenguaje que asigna rápido pero a veces se pausa para limpiar puede rendir bien en benchmarks pero sentirse entrecortado en apps interactivas. Otro modelo que evita pausas puede requerir más diseño para prevenir fugas y errores de duración.
Qué entendemos por “seguridad” aquí
La seguridad trata de prevenir fallos relacionados con la memoria, como:
- Bloqueos (acceso a memoria inválida)
- Corrupción de datos (escribir donde no deberías)
- Vulnerabilidades de seguridad (bugs que un atacante puede explotar)
Muchos problemas de seguridad de alto perfil se remontan a errores de memoria como use-after-free o desbordamientos de búfer.
Esta guía es un recorrido no técnico por los principales modelos de memoria usados por lenguajes populares, qué optimizan y los compromisos que aceptas al elegir uno.
Conceptos centrales: pila, montón y vidas de los objetos
La memoria es donde tu programa guarda datos mientras corre. La mayoría de lenguajes la organizan en torno a dos áreas principales: la pila y el montón.
Pila: almacenamiento rápido y temporal
Piensa en la pila como una pila ordenada de notas adhesivas usadas para la tarea actual. Cuando una función comienza, obtiene un pequeño “marco” en la pila para sus variables locales. Cuando la función termina, todo ese marco se elimina de una vez.
Esto es rápido y predecible, pero solo sirve para valores cuyo tamaño se conoce y cuya vida termina con la llamada a la función.
Montón: almacenamiento flexible y de mayor duración
El montón es más como un cuarto de almacenamiento donde puedes mantener objetos el tiempo que necesites. Es ideal para listas de tamaño dinámico, cadenas u objetos compartidos entre partes del programa.
Como los objetos en el montón pueden vivir más allá de una función, la cuestión clave es: quién es responsable de liberarlos y cuándo. Esa responsabilidad es el “modelo de gestión de memoria” de un lenguaje.
Lifetimes y por qué importan punteros/referencias
Un puntero o referencia es una forma de acceder a un objeto de manera indirecta—como tener el número de estantería de una caja en el cuarto de almacenamiento. Si la caja se tira y aún tienes el número, podrías leer datos basura o provocar un bloqueo (un clásico bug use-after-free).
Un escenario de ejemplo sencillo
Imagina un bucle que crea un registro de cliente, formatea un mensaje y lo descarta:
- En la pila: variables temporales pequeñas usadas solo durante el formateo.
- En el montón: el registro del cliente y el texto del mensaje (tamaños variables).
Algunos lenguajes ocultan estos detalles (limpieza automática), otros los exponen (liberas memoria explícitamente o debes seguir reglas sobre quién posee un objeto). El resto del artículo explora cómo esas elecciones afectan velocidad, pausas y seguridad.
Gestión manual de memoria: control con mayor riesgo
La gestión manual significa que el programa (y por tanto el desarrollador) solicita memoria y más tarde la libera explícitamente. En la práctica se ve como malloc/free en C o new/delete en C++. Sigue siendo común en programación de sistemas donde necesitas control preciso sobre cuándo se adquiere y devuelve memoria.
Para qué se usa la asignación/limpieza explícita
Normalmente asignas memoria cuando un objeto debe vivir más allá de la llamada actual, crece dinámicamente (p. ej., un buffer redimensionable) o necesita un layout específico para interoperar con hardware, sistemas operativos o protocolos de red.
Ventaja de rendimiento: costos previsibles (cuando se hace bien)
Sin un recolector de basura en segundo plano, hay menos pausas sorpresa. La asignación y liberación pueden hacerse muy predecibles, especialmente si se usan asignadores personalizados, pools o buffers de tamaño fijo.
El control manual también puede reducir la sobrecarga: no hay fase de traza, ni barreras de escritura, y a menudo menos metadatos por objeto. Con código bien diseñado puedes alcanzar objetivos estrictos de latencia y mantener el uso de memoria dentro de límites cerrados.
Riesgos de seguridad: modos clásicos de fallo
El intercambio es que el programa puede cometer errores que el runtime no evitará automáticamente:
- Fugas de memoria (olvidar liberar)
- Doble liberación (
double-free) - Uso después de liberar (
use-after-free)
Estos bugs pueden causar bloqueos, corrupción de datos y vulnerabilidades.
Mitigaciones comunes
Los equipos reducen el riesgo restringiendo dónde se permite la asignación cruda y apoyándose en patrones como:
- RAII en C++ (recursos liberados automáticamente al salir de alcance)
- Smart pointers (p. ej.,
std::unique_ptr) para codificar propiedad - Estándares de codificación, listas de verificación en revisiones, sanitizadores y análisis estático
Cuándo encaja bien
La gestión manual suele ser buena para software embebido, sistemas en tiempo real, componentes del SO y bibliotecas críticas de rendimiento—lugares donde el control estricto y la latencia predecible importan más que la comodidad del desarrollador.
Recolección de basura: productividad y seguridad predecible
La recolección de basura (GC) es la limpieza automática de memoria: en lugar de pedirte que hagas free, el runtime rastrea objetos y recupera los que ya no son alcanzables. En la práctica, esto te permite concentrarte en la lógica y el flujo de datos mientras el sistema maneja la mayoría de decisiones de asignación y liberación.
Cómo encuentra GC los objetos no usados
La mayoría de recolectores identifican primero objetos vivos y luego recuperan el resto.
GC por traza parte de “raíces” (variables en pila, referencias globales y registros), sigue referencias para marcar lo alcanzable y luego barre el montón para liberar lo que no está marcado. Si nada apunta a un objeto, se vuelve elegible para colección.
Estilos comunes de GC (a alto nivel)
GC generacional se basa en la observación de que muchos objetos mueren pronto. Se separa el montón en generaciones y recolecta el área joven con más frecuencia, lo que suele ser más barato y mejora la eficiencia.
GC concurrente ejecuta partes de la recolección junto a los hilos de aplicación, intentando reducir pausas largas. Puede requerir más contabilidad para mantener una vista consistente de la memoria mientras el programa sigue corriendo.
Compromisos de rendimiento
GC típicamente intercambia control manual por trabajo en tiempo de ejecución. Algunos sistemas priorizan throughput sostenido (mucho trabajo por segundo) pero pueden introducir pausas stop-the-world. Otros minimizan pausas para aplicaciones sensibles a la latencia, aunque añadiendo sobrecarga durante la ejecución normal.
Por qué les gusta a los desarrolladores
GC elimina toda una clase de errores de vida (especialmente use-after-free) porque los objetos no se recuperan mientras sean alcanzables. También reduce fugas causadas por desalojos de liberación olvidados (aunque aún puedes “filtrar” memoria manteniendo referencias más tiempo del necesario). En bases de código grandes donde la propiedad es difícil de seguir manualmente, esto suele acelerar la iteración.
Dónde lo verás
Runtimes con GC son comunes en la JVM (Java, Kotlin), .NET (C#, F#), Go y los motores de JavaScript en navegadores y Node.js.
Conteo de referencias: limpieza inmediata con matices
El conteo de referencias es una estrategia donde cada objeto rastrea cuántos “propietarios” (referencias) apuntan a él. Cuando el contador baja a cero, el objeto se libera inmediatamente. Esa inmediatez resulta intuitiva: en cuanto nada puede alcanzar un objeto, su memoria se libera.
Cómo funciona (y por qué resulta atractivo)
Cada vez que copias o almacenas una referencia, el runtime incrementa su contador; cuando una referencia desaparece, lo decrementa. Llegar a cero dispara la limpieza en ese mismo momento.
Esto hace que la gestión de recursos sea directa: los objetos sueltan memoria cerca del momento en que dejas de usarlos, lo que puede reducir el pico de memoria y evitar recuperaciones demoradas.
Características de rendimiento
El conteo de referencias suele tener una sobrecarga constante y estable: operaciones de incremento/decremento ocurren en muchas asignaciones y llamadas. Esa sobrecarga suele ser pequeña, pero está presente en muchas partes del código.
La ventaja es que normalmente no hay grandes pausas stop-the-world como en algunos recolectores por traza. La latencia suele ser más suave, aunque aún pueden producirse ráfagas de liberación cuando grandes grafos de objetos pierden su último propietario.
El gran pero: los ciclos
El conteo no puede recuperar objetos involucrados en un ciclo. Si A referencia a B y B referencia a A, ambos contadores permanecen por encima de cero aunque nada más pueda alcanzarlos—creando una fuga.
Los ecosistemas gestionan esto de varias maneras:
- Referencias débiles (punteros no propietarios) para romper ciclos comunes (delegados, enlaces padre/hijo).
- Detección de ciclos encima del conteo de referencias (una pasada por traza que encuentra ciclos inalcanzables).
Dónde lo verás
- Swift / Objective-C usan ARC (Automatic Reference Counting), con referencias “strong/weak/unowned” para manejar ciclos.
- Python usa conteo de referencias para limpieza inmediata, más un detector de ciclos para recolectar basura cíclica.
Propiedad y préstamos: seguridad de memoria en tiempo de compilación
Prototipa una versión móvil
Prueba el mismo flujo de trabajo en Flutter para comparar la presión de memoria en dispositivos móviles.
La propiedad y el préstamo es un modelo asociado a Rust. La idea es simple: el compilador hace cumplir reglas que dificultan crear punteros colgantes, dobles liberaciones y muchas condiciones de carrera—sin depender de un recolector en tiempo de ejecución.
Propiedad: un propietario claro, limpieza determinista
Cada valor tiene exactamente un “propietario” a la vez. Cuando el propietario sale de alcance, el valor se limpia inmediata y predeciblemente. Eso te da gestión determinista de recursos (memoria, descriptores de archivo, sockets) parecido a la limpieza manual, pero con muchas menos formas de equivocarse.
La propiedad también puede moverse: asignar un valor a una nueva variable o pasarlo a una función puede transferir la responsabilidad. Tras un movimiento, el enlace antiguo ya no se puede usar, lo que previene use-after-free por construcción.
Préstamos: acceso temporal sin adquirir propiedad
El préstamo te permite usar un valor sin convertirte en su propietario.
Un préstamo compartido permite acceso solo de lectura y puede copiarse libremente.
Un préstamo mutable permite actualizaciones, pero debe ser exclusivo: mientras exista, nadie más puede leer o escribir ese mismo valor. Esta regla “un escritor o muchos lectores” es verificada en tiempo de compilación.
Beneficios de seguridad — y sus costes
Al rastrear lifetimes, el compilador puede rechazar código que viviría más que los datos a los que referencia, eliminando muchos errores de punteros colgantes. Las mismas reglas también previenen gran parte de las condiciones de carrera en código concurrente.
El intercambio es una curva de aprendizaje y algunas restricciones de diseño. Puede que necesites reestructurar flujos de datos, introducir límites de propiedad más claros o usar tipos especializados para estado compartido mutable.
Dónde destaca
Este modelo encaja muy bien en código de sistemas—servicios, embebido, redes y componentes sensibles al rendimiento—donde quieres limpieza predecible y baja latencia sin pausas de GC.
Arenas, regiones y pools: patrones de asignación rápidos
Cuando creas muchos objetos de vida corta—nodos AST en un parser, entidades en un frame de juego, datos temporales durante una petición web—el coste de asignar y liberar cada objeto puede dominar el tiempo de ejecución. Las arenas (o regiones) y los pools son patrones que cambian liberaciones finas por gestión rápida y por lotes.
Qué son arenas/regions
Un arena es una “zona” de memoria donde asignas muchos objetos a lo largo de un periodo y luego liberas todos ellos a la vez restableciendo el arena.
En lugar de seguir la vida de cada objeto individualmente, enlazas las vidas a un límite claro: “todo lo asignado para esta petición” o “todo lo asignado al compilar esta función”.
Por qué puede ser rápido
Las arenas suelen ser rápidas porque:
- reducen llamadas al asignador (a menudo solo incrementando un puntero)
- evitan costes de liberación por objeto
- mejoran la localidad de caché manteniendo objetos relacionados cerca
Esto puede mejorar el throughput y reducir picos de latencia causados por liberaciones frecuentes o contención del asignador.
Casos de uso típicos
Arenas y pools aparecen en:
- parsers y compiladores (árboles sintácticos, tablas de símbolos)
- datos con ámbito por petición (asignar durante la petición, liberar al final)
- juegos (asignaciones por frame que se reinician cada frame)
- simulaciones y trabajos por lotes
Consideraciones de seguridad
La regla principal es simple: no dejes que referencias escapen de la región que posee la memoria. Si algo asignado en un arena se almacena globalmente o se devuelve más allá de la vida del arena, puedes provocar use-after-free.
Lenguajes y bibliotecas manejan esto de manera distinta: algunos confían en disciplina y APIs, otros pueden codificar el límite de la región en los tipos.
Cómo complementa otros enfoques
Arenas y pools no son necesariamente una alternativa a la GC o a la propiedad—a menudo son un complemento. Lenguajes con GC usan pools para caminos calientes; lenguajes con ownership usan arenas para agrupar asignaciones y hacer lifetimes explícitos. Usados con cuidado, ofrecen asignación “rápida por defecto” sin sacrificar claridad sobre cuándo se libera memoria.
Optimizaciones del compilador y runtime que cambian la historia
Obtén código que puedas controlar
Genera una implementación base y exporta el código fuente para optimizarlo localmente.
El modelo de memoria de un lenguaje es solo una parte de la historia de rendimiento y seguridad. Compiladores y runtimes modernos reescriben tu programa para asignar menos, liberar antes y evitar contabilidad extra. Por eso frases como “GC es lento” o “manual es lo más rápido” suelen romperse en aplicaciones reales.
Análisis de escape: cuando no hace falta heap
Muchas asignaciones existen solo para pasar datos entre funciones. Con escape analysis, el compilador puede probar que un objeto no sale del alcance actual y dejarlo en la pila en lugar del montón.
Eso puede eliminar una asignación en el montón por completo, junto con costes asociados (seguimiento por GC, actualizaciones de conteo de referencias, locks del asignador). En lenguajes gestionados, esta es una razón importante por la que objetos pequeños pueden ser más baratos de lo que parece.
Inlining y eliminación de asignaciones
Cuando un compilador inlinea una función (reemplaza la llamada por el cuerpo), puede “ver a través” de capas de abstracción. Esa visibilidad permite optimizaciones como:
- eliminar objetos temporales
- reemplazo escalar (convertir un objeto en unas pocas variables locales)
- eliminar tráfico de conteo de referencias cuando las vidas son obvias
APIs bien diseñadas pueden volverse “de coste cero” tras las optimizaciones, aunque en el código fuente parezcan generar muchas asignaciones.
JIT vs compilación AOT
Un JIT (just-in-time) puede optimizar usando datos reales de producción: rutas calientes, tamaños típicos de objetos y patrones de asignación. Eso suele mejorar throughput, pero añade tiempo de calentamiento y pausas ocasionales por recompilación o GC.
La compilación ahead-of-time debe adivinar más por adelantado, pero ofrece arranque predecible y latencia más estable.
Palancas de tuning del runtime (y cuándo tocarlas)
Runtimes con GC exponen ajustes como tamaño del heap, objetivos de tiempo de pausa y umbrales generacionales. Ajusta estas opciones cuando tengas evidencia medida (p. ej., picos de latencia o presión de memoria), no como primer paso.
Por qué el mismo algoritmo se comporta distinto
Dos implementaciones de un “mismo” algoritmo pueden diferir en recuentos de asignaciones ocultas, objetos temporales y accesos a punteros. Esas diferencias interactúan con optimizadores, el asignador y el comportamiento de caché—por eso las comparaciones de rendimiento requieren profiling, no suposiciones.
Compromisos de rendimiento: throughput, latencia y uso de memoria
Las elecciones de gestión de memoria no solo cambian cómo escribes código—cambian cuándo se hace el trabajo, cuánta memoria necesitas reservar y cuán consistente se siente el rendimiento para los usuarios.
Throughput vs latencia (un ejemplo concreto)
Throughput es “cuánto trabajo por unidad de tiempo.” Piensa en un job nocturno que procesa 10 millones de registros: si GC o conteo añaden pequeña sobrecarga pero mantienen alta productividad del equipo, aún puedes terminar más rápido en conjunto.
Latencia es “cuánto tarda una operación de extremo a extremo.” Para una petición web, una sola respuesta lenta perjudica la experiencia aunque el throughput medio sea alto. Un runtime que ocasionalmente se pausa puede estar bien para procesamiento por lotes, pero ser notable en apps interactivas.
Huella de memoria: coste y velocidad
Una mayor huella de memoria aumenta costes en la nube y puede ralentizar programas. Cuando el working set no cabe bien en las cachés de CPU, la CPU espera más por datos desde RAM. Algunas estrategias intercambian memoria extra por velocidad (p. ej., mantener objetos libres en pools), otras reducen memoria pero añaden contabilidad.
Fragmentación y localidad de caché (en términos sencillos)
La fragmentación ocurre cuando la memoria libre está dividida en muchas hendiduras pequeñas—como intentar aparcar una furgoneta en un aparcamiento con espacios dispersos. Los asignadores pueden tardar más en buscar espacio y la memoria puede crecer aun cuando “hay suficiente” técnicamente.
La localidad de caché significa que datos relacionados están cerca. La asignación por pool/arena mejora la localidad (objetos asignados juntos quedan próximos), mientras que un montón con objetos de vida mixta puede derivar en layouts menos amigables con la caché.
Requisitos de tiempo predecible
Si necesitas tiempos de respuesta consistentes—juegos, audio, trading, controladores embebidos o en tiempo real—“casi siempre rápido pero a veces lento” puede ser peor que “algo más lento pero consistente.” Aquí importan patrones de liberación predictibles y control estricto de asignaciones.
Lista de comprobación para medición
- Haz benchmarks de throughput (jobs/sec) y latencia de cola (p95/p99 de peticiones)
- Perfila asignaciones: tasa de asignación, tiempo de pausa y tiempo en alloc/free
- Usa cargas representativas (formas de tráfico reales, tamaños de datos, concurrencia)
- Rastrea memoria: pico RSS, tamaño del heap en el tiempo, métricas de fragmentación (si están disponibles)
- Repite ejecuciones para capturar variabilidad (efectos de warm-up, ciclos de GC en segundo plano)
Seguridad: cómo los modelos de memoria previenen errores comunes
Los errores de memoria no son solo “errores de programador.” En muchos sistemas reales se convierten en problemas de seguridad: bloqueos (DoS), exposición accidental de datos (leer memoria liberada o no inicializada) o condiciones explotables donde atacantes inducen al programa a ejecutar código no intencionado.
Cómo los bugs se relacionan con los modelos
Diferentes estrategias de gestión tienden a fallar de distintas formas:
- Gestión manual (C/C++) frecuentemente arriesga use-after-free, double free y desbordamientos de búfer—problemas que pueden corromper memoria y ser explotables.
- GC elimina la mayoría de errores estilo UAF porque los objetos no se liberan mientras sean alcanzables, pero aún puedes tener fugas de memoria (mantener referencias involuntariamente) y riesgos en interoperabilidad nativa insegura.
- Conteo de referencias ofrece limpieza inmediata, ayudando con la liberación predecible, pero puede sufrir ciclos (fugas) y problemas sutiles en estado mutable compartido.
- Sistemas de propiedad/préstamo (ej. Rust) previenen muchas clases de UAF y condiciones de carrera en tiempo de compilación al hacer difícil tener referencias colgantes o mutaciones sin sincronización.
Seguridad en hilos y concurrencia
La concurrencia cambia el modelo de amenaza: memoria que está “bien” en un hilo puede ser peligrosa cuando otro hilo la libera o la muta. Modelos que imponen reglas sobre compartir (o requieren sincronización explícita) reducen la probabilidad de condiciones de carrera que llevan a estado corrupto, fugas de datos y fallos intermitentes.
Defensa en profundidad sigue siendo necesaria
Ningún modelo de memoria elimina todo el riesgo—bugs lógicos (errores de autenticación, configuraciones inseguras, validación defectuosa) siguen ocurriendo. Los equipos sólidos aplican capas de protección: sanitizadores en pruebas, bibliotecas estándar seguras, revisiones de código exigentes, fuzzing y límites estrictos alrededor de código inseguro/FFI. La seguridad de memoria reduce mucho la superficie de ataque, pero no garantiza ausencia total de problemas.
Herramientas y técnicas para encontrar problemas de memoria temprano
Revisa la latencia percibida por el usuario
Empareja un front end reactivo en React con una API para detectar picos de latencia rápidamente.
Los problemas de memoria son más fáciles de arreglar si los detectas cerca del cambio que los introdujo. La clave es medir primero y luego acotar con la herramienta adecuada.
Fundamentos del profiling: qué medir (y cuándo)
Empieza decidiendo si persigues velocidad o crecimiento de memoria.
Para rendimiento, mide tiempo real, tiempo CPU, tasa de asignación (bytes/sec) y tiempo gastado en GC o el asignador. Para memoria, rastrea pico RSS, RSS en estado estable y conteos de objetos en el tiempo. Ejecuta la misma carga con entradas consistentes; pequeñas variaciones pueden ocultar churn de asignación.
Categorías de herramientas (qué encuentra cada una)
- Perfiles CPU + asignación: muestran dónde se gasta el tiempo y qué rutas asignan más. Ideales para encontrar “muerte por mil asignaciones pequeñas.”
- Detectores de fugas: informan memoria asignada pero nunca liberada (o no hecha inalcanzable para el GC).
- Sanitizadores: detectan use-after-free, desbordamientos, condiciones de carrera y comportamiento indefinido en pruebas.
- Fuzzing: alimenta entradas inesperadas para desencadenar bloqueos y corrupción que las pruebas normales no cubren.
Localiza hotspots de asignación y reduce churn
Señales comunes: una petición asigna mucho más de lo esperado, o la memoria sube con tráfico aunque el throughput sea estable. Las soluciones suelen incluir reutilizar buffers, pasar a arenas/pools para objetos de vida corta y simplificar grafos de objetos para que menos sobrevivan entre ciclos.
Flujo práctico para fugas y bloqueos
Reproduce con una entrada mínima, habilita las comprobaciones más estrictas del runtime (sanitizadores/verificación GC), y captura:
- un perfil (CPU + asignaciones), 2) una instantánea de heap o informe de fugas, 3) el stack trace en el fallo.
Trata la primera corrección como experimento; vuelve a medir para confirmar que redujo asignaciones o estabilizó memoria—sin trasladar el problema a otro sitio. Para más sobre interpretación de trade-offs, ver /blog/performance-trade-offs-throughput-latency-memory-use.
Elegir un lenguaje: alinea el modelo de memoria con tus objetivos
Elegir un lenguaje no es solo sintaxis o ecosistema—su modelo de memoria moldea la velocidad del desarrollo, el riesgo operacional y cuán predecible será el rendimiento bajo tráfico real.
Empieza por tus requisitos (no por preferencias)
Relaciona las necesidades de producto con una estrategia de memoria respondiendo preguntas prácticas:
- Habilidades del equipo y tolerancia a la complejidad: ¿La mayoría maneja razonamiento sobre lifetimes y ownership, o prefieres que el runtime lo gestione?
- Latencia vs throughput: ¿Necesitas latencia de cola consistente (p. ej., trading, audio, control en tiempo real) o priorizas throughput promedio (backends web, trabajos por lotes)?
- Restricciones de despliegue: ¿Corres en un entorno con memoria limitada (embebido, móvil) o tienes margen para un runtime y heaps grandes?
Ajustes habituales “buen encaje”
- GC: Buena opción para servicios backend y aplicaciones de producto donde la velocidad de desarrollo y la seguridad importan más que microsegundos de pausas.
- Propiedad/préstamo (ej. Rust): Encaja en software de sistemas, componentes críticos de rendimiento y código sensible a seguridad donde los bugs de memoria son inaceptables.
- Conteo de referencias: Funciona bien en apps de escritorio/móviles e interfaces de usuario que se benefician de limpieza incremental y predecible, aceptando el manejo de ciclos y la sobrecarga por asignación.
Migración e interoperabilidad
Si cambias de modelo, planea fricción: llamadas a librerías existentes (FFI), convenciones de memoria mixtas, tooling y mercado de contratación. Prototipos ayudan a descubrir costes ocultos (pausas, crecimiento de memoria, sobrecarga CPU) temprano.
Un enfoque práctico es prototipar la misma funcionalidad en los entornos que consideras y comparar tasa de asignación, latencia de cola y pico de memoria bajo carga representativa. Algunos equipos hacen evaluaciones “manzana a manzana” en entornos como Koder.ai para iterar rápido y exportar código cuando están listos.
Marco ligero de decisión
Define las 3–5 restricciones principales, construye un prototipo delgado y mide uso de memoria, latencia de cola y modos de fallo.
| Modelo | Seguridad por defecto | Predictibilidad de latencia | Velocidad de desarrollo | Peligros típicos |
|---|---|---|---|---|
| Manual | Baja–Media | Alta | Media | fugas, use-after-free |
| GC | Alta | Media | Alta | pausas, crecimiento del heap |
| RC | Media–Alta | Alta | Media | ciclos, sobrecarga |
| Propiedad | Alta | Alta | Media | curva de aprendizaje |
Preguntas frecuentes
¿Qué es la “gestión de memoria” y por qué importa tanto para la velocidad y la seguridad?
La gestión de memoria es cómo un programa asigna memoria para datos (como objetos, cadenas, buffers) y luego la libera cuando ya no se necesita.
Impacta en:
- Rendimiento: velocidad de asignación, pausas, comportamiento de caché y huella de memoria general.
- Seguridad: riesgo de bloqueos, corrupción y fallos de seguridad provocados por errores como uso después de liberar o desbordamientos de búfer.
¿Cuál es la diferencia entre pila y montón, en términos sencillos?
La pila es rápida, automática y está ligada a las llamadas de función: cuando una función retorna, su marco de pila se elimina de un golpe.
La montón (heap) es flexible para datos dinámicos o de larga duración, pero necesita una estrategia sobre cuándo y quién la libera.
Una regla práctica: la pila va bien para locales de vida corta y tamaño fijo; el montón se usa cuando las vidas o tamaños son impredecibles.
¿Por qué los punteros/referencias suelen ser una fuente de errores serios?
Una referencia/puntero permite acceder a un objeto de forma indirecta. El peligro aparece cuando la memoria del objeto se libera pero aún existe una referencia que lo apunta.
Eso puede provocar:
- Bloqueos (acceso inválido)
- Corrupción de datos (leer/escribir memoria equivocada)
- Vulnerabilidades de seguridad (ataques que explotan errores de memoria)
¿Qué significa la gestión manual de memoria y cuándo se usa?
Significa que asignas y liberas memoria explícitamente (por ejemplo, malloc/free, new/delete).
Es útil cuando necesitas:
- control preciso sobre cuándo se recupera la memoria
- diseños de memoria o disposiciones personalizadas para interoperabilidad (SO, hardware, protocolos de red)
- tiempos predecibles en sistemas críticos de rendimiento
El coste es un mayor riesgo de errores si la propiedad y las vidas no se gestionan con cuidado.
¿Por qué la gestión manual puede ser rápida y por qué aún puede fallar?
La gestión manual puede ofrecer latencias muy predecibles si el programa está bien diseñado, porque no hay un recolector en segundo plano que detenga la ejecución.
También se puede optimizar con:
- pools / asignadores de tamaño fijo
- reducir metadatos por objeto
- controlar patrones de asignación
Pero es fácil crear patrones costosos accidentalmente (fragmentación, contención del asignador, muchas asignaciones/liberaciones pequeñas).
¿Cómo decide la recolección de basura (GC) qué liberar?
La recolección de basura encuentra automáticamente objetos que ya no son alcanzables y recupera su memoria.
La mayoría de los recolectores por traza funcionan así:
- Empiezan desde las raíces (pila, globales, registros).
- Siguen referencias para marcar objetos alcanzables.
- Liberan lo que no quedó marcado.
Esto mejora la seguridad (menos errores por uso después de liberar) pero añade trabajo en tiempo de ejecución y puede introducir pausas según el diseño del recolector.
¿Qué es el conteo de referencias y por qué los ciclos causan fugas?
El conteo de referencias libera un objeto cuando su “contador de propietarios” baja a cero.
Pros:
- la limpieza suele ser inmediata y predecible
- menos pausas grandes «stop-the-world»
Contras:
- sobrecarga en muchas asignaciones de referencias
- pueden provocar fugas (A ↔ B se mantienen vivos)
¿Cómo mejoran la propiedad y el préstamo la seguridad de memoria sin usar GC?
La propiedad y el préstamo (ownership/borrowing), especialmente en el modelo de Rust, usan reglas en tiempo de compilación para evitar muchos errores de duración de objetos.
Ideas clave:
- cada valor tiene un propietario claro responsable de la limpieza
- los préstamos permiten acceso temporal sin adquirir la propiedad
- reglas como “un escritor o muchos lectores” reducen condiciones de carrera
Esto ofrece limpieza predecible sin pausas de GC, pero a menudo exige reestructurar el flujo de datos para satisfacer las reglas del compilador.
¿Qué son arenas/regions/pools y cuándo son una buena idea?
Un arena/region asigna muchos objetos en una “zona” y luego los libera todos a la vez reiniciando o destruyendo el arena.
Es eficaz cuando hay un límite de vida claro, por ejemplo:
- asignaciones “por petición” en servidores
- asignaciones “por frame” en juegos
- nodos temporales en compiladores/analizadores
La regla de seguridad clave: no dejes que referencias escapen más allá de la vida del arena.
¿Qué debo medir primero al depurar problemas de rendimiento o fugas de memoria?
Empieza con mediciones reales bajo carga representativa:
- Rendimiento: trabajos/sec
- Latencia de cola: p95/p99 (observa picos)
- Tasa de asignación: bytes/sec y número de asignaciones
- Huella de memoria: pico y RSS/heap en estado estable
Luego usa herramientas específicas: