Qué estás construyendo y para quién es
Estás construyendo una aplicación web que se interpone entre tu API y las personas que la consumen. Su trabajo es emitir claves API, controlar cómo se pueden usar esas claves y explicar qué ocurrió—de forma lo bastante clara para desarrolladores y no desarrolladores.
Como mínimo, responde a tres preguntas prácticas:
- ¿Quién está llamando a la API? (qué cliente, qué app, qué clave)
- ¿Cuánto pueden usar? (cuotas, límites de tasa, reglas del plan)
- ¿Cuánto usaron realmente? (medición y analítica en las que puedas confiar)
Si quieres avanzar rápido con el portal y la UI de administración, herramientas como Koder.ai pueden ayudarte a prototipar y lanzar una base de producción rápidamente (frontend en React + backend en Go + PostgreSQL), manteniendo control total vía exportación de código fuente, snapshots/rollback y despliegue/alojamiento.
Quién lo usa
Una aplicación de gestión de claves no es solo para ingenieros. Aparecen roles diferentes con objetivos distintos:
-
Admins / propietarios de plataforma quieren crear políticas (límites, niveles de acceso), resolver incidentes rápido y mantener control sobre muchos clientes.
-
Desarrolladores (tus clientes o equipos internos) quieren creación autoservicio de claves, documentación simple y respuestas rápidas cuando algo falla (“¿Por qué me dan 429s?”).
-
Equipos de finanzas y soporte quieren historial de uso, resúmenes por cliente y datos que respalden facturas, créditos o upgrades—sin leer logs en crudo.
Módulos centrales que probablemente necesites
La mayoría de implementaciones exitosas convergen en unos módulos clave:
- Claves: crear claves, nombrarlas/etiquetarlas, acotar permisos, rotar, revocar y ver último uso.
- Cuotas y limitación de tasa: definir límites por clave, por cliente, por endpoint y aplicarlos de forma consistente.
- Medición de uso: capturar eventos de petición (o resúmenes) y agregarlos en uso diario/mensual.
- Analítica: paneles que expliquen tendencias de uso, endpoints principales, errores y throttling.
- Alertas: notificar cuando el uso sube, las cuotas se acercan al máximo, hay mal uso de claves o errores aumentan.
Alcance: empieza simple y luego amplía
Un MVP sólido se centra en emisión de claves + límites básicos + informes de uso claros. Funcionalidades avanzadas—como upgrades automáticos de plan, flujos de facturación, prorrateos y términos contractuales complejos—pueden venir después cuando confíes en tu metering y enforcement.
Una guía práctica para el primer lanzamiento: facilita que alguien cree una clave, entienda sus límites y vea su uso sin abrir un ticket de soporte.
Checklist de requisitos (MVP vs después)
Antes de escribir código, decide qué significa “terminado” para la primera versión. Este tipo de sistema crece rápido: facturación, auditorías y seguridad empresarial aparecen antes de lo que esperas. Un MVP claro te mantiene lanzando.
MVP: lo mínimo que crea valor real
Como mínimo, los usuarios deberían poder:
- Crear y revocar claves API (con un nombre/etiqueta y expiración opcional)
- Establecer cuotas (p. ej., peticiones/día o peticiones/mes) por clave o por proyecto
- Aplicar limitación de tasa (p. ej., peticiones/minuto) para proteger tu API
- Ver gráficos de uso (totales diarios simples, claves principales y tasas de error)
- Rastrear eventos de auditoría básicos (clave creada/revocada, cuota cambiada) para soporte y responsabilidad
Si no puedes emitir una clave de forma segura, limitarla y demostrar lo que hizo, no está lista.
Necesidades no funcionales que debes decidir desde el inicio
- Rendimiento: ¿cuál es el pico de requests/sec que debes medir sin perder eventos?
- Confiabilidad: ¿necesitas “no perder nunca eventos de uso” o es suficiente “exactitud eventual”?
- Retención de datos: ¿cuánto tiempo conservas eventos crudos vs totales agregados (p. ej., 7 días crudos, 13 meses agregados)?
Modelo de tenancy: organización única vs multi-tenant
Elige uno pronto:
- Organización única: más rápido de construir, menos aristas de roles/permisos.
- SaaS multi-tenant: requiere aislamiento de tenant, cuotas por tenant y roles de administración desde el día uno.
Funciones “posteriores” que vale la pena planear
Flujos de rotación, notificaciones por webhook, exportes de facturación, SSO/SAML, cuotas por endpoint, detección de anomalías y registros de auditoría más ricos.
Métricas de éxito (hazlas medibles)
- Tiempo para emitir claves: p. ej., menos de 2 minutos desde el registro hasta la primera clave
- Precisión del metering: p. ej., <0.5% de discrepancia entre conteos del gateway y agregados
- Carga de soporte: menos tickets “¿por qué me bloquearon?”; explicaciones claras de cuota/limitación
Opciones de arquitectura de alto nivel
Tu elección de arquitectura debería empezar con una pregunta: ¿dónde aplicas acceso y límites? Esa decisión afecta latencia, confiabilidad y la rapidez para lanzar.
Opción 1: aplicar en un gateway de API
Un gateway de API (gestionado o self-hosted) puede validar claves, aplicar rate limits y emitir eventos de uso antes de que las peticiones lleguen a tus servicios.
Encaja bien cuando tienes múltiples servicios, necesitas políticas consistentes o quieres mantener la aplicación fuera del código de negocio. La contrapartida: la configuración del gateway puede convertirse en su propio “producto” y depurar a menudo requiere trazado robusto.
Opción 2: aplicar en un reverse proxy
Un reverse proxy (p. ej., NGINX/Envoy) puede manejar verificaciones de clave y limitación de tasa con plugins o hooks de auth externos.
Funciona bien cuando quieres una capa de borde ligera, pero puede ser más difícil modelar reglas de negocio (planes, cuotas por tenant, casos especiales) sin construir servicios de apoyo.
Opción 3: aplicar en middleware de la app
Meter las comprobaciones en la aplicación API suele ser lo más rápido para un MVP: una base de código, un despliegue, pruebas locales más sencillas.
Se puede complicar al añadir más servicios—el drift de políticas y la lógica duplicada son comunes—así que planifica una extracción eventual a un componente compartido o capa de borde.
Separa responsabilidades desde temprano
Incluso si empiezas pequeño, mantiene límites claros:
- Auth (¿es válida la clave?), cuota/limitación (¿se permite ahora?), metering (registrar lo ocurrido), UI de analítica (mostrarlo).
Seguimiento síncrono vs asíncrono
Para metering, decide qué debe ocurrir en la ruta de petición:
- Síncrono: incrementar contadores antes de responder (aplicación precisa, mayor latencia).
- Asíncrono: emitir eventos a una cola/log para agregación (peticiones más rápidas, consistencia eventual en reportes).
Plan para escala: rutas calientes vs frías
Las comprobaciones de rate limit son la ruta caliente (optimiza para baja latencia, memoria/Redis). Los reportes y dashboards son la ruta fría (optimiza para consultas flexibles y agregación por lotes).
Modelo de datos para claves, cuotas y uso
Un buen modelo de datos separa tres preocupaciones: quién posee el acceso, qué límites aplican y qué ocurrió realmente. Si lo consigues, todo lo demás—rotación, dashboards, facturación—se simplifica.
Entidades centrales (lo necesario el día uno)
Como mínimo, modela estas tablas (o colecciones):
- Organization: límite de tenant (propietario de facturación, miembros).
- Project/App: contenedor para claves y ajustes (a menudo mapea a un cliente API).
- API Key: metadata del credencial (nombre, estado, created_at, last_used_at).
- Plan: paquete de límites y características (p. ej., Free, Pro).
- Quota: reglas de límite específicas (p. ej., 10k peticiones/día, 60 req/min).
- Usage Event: registro bruto de uso (timestamp, project_id, endpoint, status code, unidades).
Nunca almacenes tokens API en crudo. Guarda solo:
- Un prefijo de clave (primeros 6–8 caracteres) para mostrar/buscar.
- Un verificador para el token (típicamente SHA-256 o HMAC-SHA-256 con un pepper del lado servidor sobre un secreto aleatorio de 32–64 bytes) para verificación.
- Opcional: scopes, entorno (prod/sandbox) y expires_at.
Así puedes mostrar “Key: ab12cd…”, manteniendo el secreto irrecuperable.
Auditabilidad no es opcional
Agrega tablas de auditoría temprano: KeyAudit y AdminAudit (o un único AuditLog) que capture:
- actor_id (usuario/servicio), acción, target_type/id
- before/after (para ediciones de cuota)
- ip/user_agent, timestamp
Cuando un cliente pregunte “¿quién revocó mi clave?”, tendrás la respuesta.
Ventanas de tiempo y contadores
Modela cuotas con ventanas explícitas: per_minute, per_hour, per_day, per_month.
Almacena contadores en una tabla separada como UsageCounter con clave (project_id, window_start, window_type, metric). Eso hace que los reseteos sean previsibles y mantiene rápidas las consultas de analítica.
Para las vistas del portal, puedes agregar Usage Events en rollups diarios y enlazar a /blog/usage-metering para más detalle.
Autenticación, autorización y roles
Si tu producto gestiona claves API y uso, el control de acceso de tu propia app debe ser más estricto que un dashboard CRUD típico. Un modelo de roles claro mantiene a los equipos productivos y evita que “todos sean admins”.
Diseño de roles que mapean a equipos reales
Empieza con un conjunto pequeño de roles por organización (tenant):
- Owner: control total, propietario de facturación, puede gestionar ajustes de org y eliminar la org.
- Admin: gestiona usuarios, proyectos, claves, cuotas y ajustes de seguridad.
- Developer: puede crear/rotar claves para proyectos asignados, ver uso, pero no puede cambiar facturación ni seguridad global.
- Read-only: puede ver claves (enmascaradas), cuotas y analítica.
- Finance: puede ver facturas/reportes de coste por uso y exportar datos, pero no gestionar claves.
Mantén permisos explícitos (p. ej., keys:rotate, quotas:update) para añadir funciones sin reinventar roles.
Login seguro para humanos
Usa username/password solo si debes; de lo contrario, soporta OAuth/OIDC. SSO es opcional, pero MFA debe ser obligatorio para owners/admins y muy recomendado para todos.
Añade protecciones de sesión: tokens de acceso de corta vida, rotación de refresh tokens y gestión de dispositivos/sesiones.
Autenticación para las APIs que proteges
Ofrece por defecto clave API en un header (p. ej., Authorization: Bearer <key> o X-API-Key). Para clientes avanzados, añade opcionalmente firma HMAC (previene replay/manipulación) o JWT (útil para acceso de corta duración y con scope). Documenta esto claramente en tu portal para desarrolladores.
Aislamiento de tenant: no negociable
Aplica el aislamiento en cada consulta: org_id en todas partes. Evita confiar solo en filtros de UI—aplica org_id en restricciones de base de datos, políticas de filas (si están disponibles) y chequeos en el servicio, y escribe tests que intenten acceso entre tenants.
Ciclo de vida de la clave API: crear, rotar, revocar
Implementa la interfaz del ciclo de vida de las claves
Crea pantallas para la creación, rotación y revocación de claves sin empezar desde cero.
Un buen ciclo de vida de claves mantiene a los clientes productivos y te da formas rápidas de reducir riesgo cuando algo sale mal. Diseña la UI y la API para que la “ruta feliz” sea obvia y las opciones más seguras (rotación, expiración) sean la configuración por defecto.
Crear: captura la intención, no solo una cadena
En el flujo de creación, pide un nombre (p. ej., “Prod server”, “Dev local”) y scopes/permissions para que la clave sea de mínimo privilegio desde el inicio.
Si encaja en tu producto, añade restricciones opcionales como orígenes permitidos (para uso en navegador) o IP/CIDR permitidas (para server-to-server). Mantén estas opciones como opcionales y muestra advertencias claras sobre posibles bloqueos.
Tras la creación, muestra la clave en crudo solo una vez. Ofrece un botón grande “Copiar” y guía breve: “Guárdalo en un gestor de secretos. No podemos mostrarlo otra vez.” Enlaza directamente a instrucciones como /docs/auth.
Rotar: que sea rutina, no incidente
La rotación debería seguir un patrón predecible:
- Crea una nueva clave con los mismos scopes y restricciones.
- Despliega/actualiza la integración para usar la nueva clave.
- Verifica que el tráfico fluye.
- Revoca la clave antigua.
En la UI, proporciona una acción “Rotar” que cree una clave de reemplazo y marque la anterior como “Pendiente de revocar” para fomentar limpieza.
La revocación debe desactivar la clave de inmediato y registrar quién y por qué lo hizo.
Soporta también expiración programada (p. ej., 30/60/90 días) y fechas “expira en” manuales para contratistas temporales o trials. Las claves expiradas deben fallar de forma predecible con un error de autenticación claro para que los desarrolladores sepan qué corregir.
Cuotas y limitación de tasa: cómo aplicar el uso
Los rate limits y las cuotas resuelven problemas distintos, y mezclarlos es una fuente común de tickets confusos “¿por qué me bloquearon?”.
Rate limits vs quotas
Los rate limits controlan ráfagas (p. ej., “no más de 50 requests por segundo”). Protegen tu infra y evitan que un cliente ruidoso degrade a los demás.
Las cuotas limitan el consumo total en un periodo (p. ej., “100,000 requests por mes”). Son para enforcement de planes y límites de facturación.
Muchos productos usan ambos: una cuota mensual por equidad y precio, más un límite por segundo/minuto para estabilidad.
Elige un algoritmo de enforcement
Para limitación en tiempo real, elige un algoritmo que puedas explicar e implementar de forma fiable:
- Token bucket: los tokens se recargan con el tiempo; cada petición consume un token. Ideal para permitir pequeñas ráfagas manteniendo una tasa media.
- Leaky bucket: las peticiones “gotean” a un ritmo constante. Suaviza el tráfico pero puede parecer más estricto.
Token bucket suele ser la mejor opción por defecto para APIs orientadas a desarrolladores porque es predecible y tolerante.
Decide dónde viven los contadores
Normalmente necesitas dos almacenes:
- Redis (o similar) para comprobaciones rápidas, atómicas y en tiempo real en el gateway/edge.
- Tu base de datos para reporting duradero e historial apto para facturación.
Redis responde “¿puede ejecutarse esta petición ahora?” La BBDD responde “¿cuánto consumieron este mes?”.
Define qué cuenta como uso
Sé explícito por producto y endpoint. Medidores comunes incluyen peticiones, tokens, bytes transferidos, pesos por endpoint o tiempo de cómputo.
Si usas endpoints ponderados, publica esos pesos en tu documentación y portal.
Haz que las respuestas de error sean accionables
Al bloquear una petición, devuelve errores claros y consistentes:
- 429 Too Many Requests para rate limiting. Incluye
Retry-After y opcionalmente encabezados como X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset.
- 402 Payment Required (o 403) para acceso por cuota excedida en planes de pago. Incluye el uso del periodo actual, el límite y un enlace a /billing o /pricing.
Los mensajes buenos reducen fricción: los desarrolladores pueden hacer backoff, reintentos o subir de plan sin adivinar.
Medición de uso: recolectar y agregar eventos
El metering es la “fuente de verdad” para cuotas, facturas y confianza del cliente. El objetivo es simple: contar lo que pasó, de forma consistente, sin ralentizar tu API.
Qué registrar por petición (y qué no)
Para cada petición, captura una carga útil pequeña y predecible:
- timestamp (tiempo del servidor)
- key_id (o identificador del token)
- endpoint (nombre de la ruta, no URL completa)
- status (p. ej., 200, 401, 429)
- units (cuánto contar: 1 petición, tokens, bytes, etc.)
Evita registrar cuerpos de petición/respuesta. Redacta headers sensibles por defecto (Authorization, cookies) y trata PII como “opt-in con necesidad fuerte”. Si debes loguear algo para depurar, almacénalo por separado con retención corta y controles de acceso estrictos.
Mantén la API rápida con una canalización de eventos
No agregues métricas inline durante la petición. En su lugar:
- La API escribe un evento en una cola/stream (o tabla append-only ligera).
- Un worker consume eventos y actualiza agregados diarios/horarios.
Esto mantiene la latencia estable incluso con picos de tráfico.
Idempotencia, reintentos y doble conteo
Las colas pueden entregar mensajes más de una vez. Añade un event_id único y aplica deduplicación (constraint único o “seen” cache con TTL). Los workers deben ser seguros para reintentos para que un crash no corrompa totales.
Retención: crudo a corto plazo, agregados a largo plazo
Almacena eventos crudos por poco tiempo (días/semanas) para auditorías e investigaciones. Conserva métricas agregadas mucho más tiempo (meses/años) para tendencias, enforcement de cuotas y preparación de facturación.
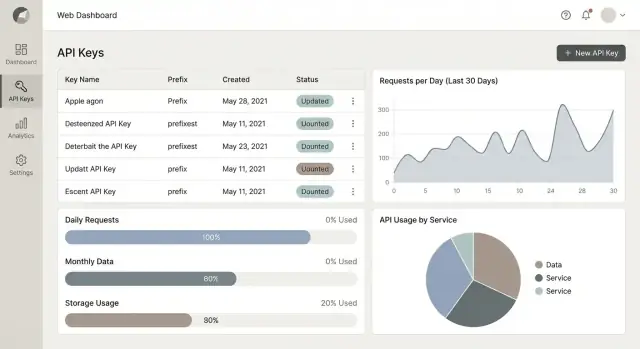
Paneles de analítica que la gente realmente use
Añade análisis de uso rápidamente
Genera gráficos de uso que respondan «¿qué cambió?» y «¿qué debo hacer ahora?».
Un dashboard de uso no debe ser solo “una página bonita”. Debe responder dos preguntas rápidamente: ¿qué cambió? y ¿qué debo hacer ahora? Diseña en torno a decisiones—depurar picos, prevenir sobrecargas y demostrar valor a un cliente.
Vistas centrales para lanzar primero
Empieza con cuatro paneles que cubren necesidades diarias:
- Uso en el tiempo (peticiones/día o peticiones/min), con comparación clara al periodo anterior.
- Endpoints principales (por volumen y por coste/peso si hay cuotas ponderadas).
- Tasa de errores (4xx vs 5xx) para separar errores de cliente de fallos de servicio.
- Latencia (opcional) p50/p95; incluye solo si puedes medirlo con fiabilidad.
Hazlo accionable, no decorativo
Cada gráfico debe conectar con un siguiente paso. Muestra:
- Cuota restante para el ciclo actual (p. ej., 18.200 de 50.000 restante)
- Proyección de uso al ritmo actual, con un llamado simple “excederá / se mantendrá”
Cuando la proyección indica sobrecarga, enlaza directamente a la ruta de upgrade: /plans (o /pricing).
Filtrado que coincida con cómo trabaja la gente
Añade filtros que permitan investigaciones sin forzar a crear querys complejas:
- Rango temporal (últimas 24h, 7d, 30d, personalizado)
- Clave API, proyecto, entorno (prod/staging)
- Endpoint y familia de códigos de estado
Export y acceso vía API
Incluye descarga CSV para finanzas y soporte, y proporciona una API ligera de métricas (p. ej., GET /api/metrics/usage?from=...&to=...&key_id=...) para que los clientes integren uso en sus propias herramientas BI.
Alertas, notificaciones y preparación para facturación
Las alertas marcan la diferencia entre “nos dimos cuenta” y “los clientes lo notaron primero”. Diseñalas alrededor de las preguntas que los usuarios hacen bajo presión: ¿Qué pasó? ¿Quién está afectado? ¿Qué debo hacer ahora?
En qué alertar (y cuándo)
Empieza con umbrales predecibles ligados a cuotas. Un patrón simple que funciona es 50% / 80% / 100% de uso de cuota dentro de un periodo de facturación.
Añade alertas de comportamiento de alta señal:
- Picos inusuales: uso que se desvía fuertemente de la línea base reciente del tenant (p. ej., 3× el promedio horario)
- Fallos de autenticación: aumento repentino en uso de claves inválidas o errores de firma
- Presión de rate-limit: eventos sostenidos de throttling que indican un cliente mal configurado
Mantén las alertas accionables: incluye tenant, clave/app, grupo de endpoint (si hay), ventana temporal y un enlace a la vista relevante en el portal (p. ej., /dashboard/usage).
Canales de notificación
El email es la base porque todo el mundo lo tiene. Añade webhooks para equipos que quieran enrutar alertas a sus sistemas. Si soportas Slack, trátalo como opcional y mantén la configuración ligera.
Una regla práctica: provee una política de notificación por tenant—quién recibe qué alertas y con qué severidad.
Ofrece un resumen diario/semanal que destaque peticiones totales, endpoints principales, errores, throttles y “cambio vs periodo anterior”. Los stakeholders quieren tendencias, no logs en crudo.
Preparación para facturación sin comprometerte a facturar
Incluso si la facturación llega “después”, almacena:
- Historial de planes (qué plan tenía un tenant y cuándo)
- Fechas efectivas de precios (para que las recalculaciones sean consistentes)
Esto permite rellenar facturas históricas o vistas previas sin reescribir el modelo de datos.
Plantilla de mensajes clara
Cada mensaje debe decir: qué pasó, impacto y siguiente paso (rotar clave, subir plan, investigar cliente o contactar soporte vía /support).
Seguridad y fundamentos de cumplimiento
Haz tuya la implementación
Mantén el control total exportando el código fuente cuando quieras.
La seguridad para una app de gestión de claves API es menos sobre funciones complejas y más sobre configuraciones por defecto cuidadosas. Trata cada clave como una credencial y asume que eventualmente se copiará al sitio equivocado.
Proteger las claves API
Nunca almacenes claves en texto plano. Guarda un verificador derivado del secreto (comúnmente SHA-256 o HMAC-SHA-256 con pepper del servidor) y muestra al usuario el secreto completo solo una vez al crear.
En la UI y logs, muestra solo un prefijo no sensible (por ejemplo, ak_live_9F3K…) para que la gente identifique la clave sin exponerla.
Ofrece orientación práctica de “secret scanning”: recuerda a los usuarios no commitear claves en Git y enlaza a docs de sus herramientas (por ejemplo, el escaneo de secretos de GitHub) en tu portal en /docs.
Protecciones para admins (frecuentemente pasadas por alto)
Los atacantes adoran los endpoints admin porque pueden crear claves, subir cuotas o desactivar límites. Aplica rate limiting también a APIs admin y considera una opción de allowlist de IP para acceso admin (útil para equipos internos).
Usa mínimo privilegio: separa roles (viewer vs admin) y restringe quién puede cambiar cuotas o rotar claves.
Registros de auditoría y retención
Registra eventos de auditoría para creación, rotación, revocación de claves, intentos de login y cambios de cuota. Mantén logs a prueba de manipulación (almacenamiento append-only, acceso restringido para escritura y backups regulares).
Adopta bases de cumplimiento temprano: minimización de datos (almacena solo lo necesario), controles claros de retención (borrado automático de logs antiguos) y reglas de acceso documentadas.
Escenarios de amenaza para diseñar contra ellos
Fuga de claves, abuso por replay, scraping del portal y tenants “vecinos ruidosos” consumiendo capacidad compartida. Diseña mitigaciones (hash/verificadores, tokens de corta duración cuando sea posible, rate limits y cuotas por tenant) alrededor de estas realidades.
UX para admin y desarrollador del portal
Un gran portal hace que la “ruta segura” sea la más fácil: los admins pueden reducir riesgo rápido y los desarrolladores obtienen una clave funcional y una llamada de prueba sin mandar emails.
UX para admins: rapidez, control y confianza
Los admins suelen llegar con una tarea urgente (“revocar esta clave ya”, “¿quién creó esto?”, “¿por qué subió el uso?”). Diseña para escaneo rápido y acción decisiva.
Usa búsqueda rápida que funcione sobre prefijos de ID de clave, nombres de app, usuarios y nombres de workspace/tenant. Combínalo con indicadores de estado claros (Activo, Expirado, Revocado, Comprometido, Rotando) y timestamps como “último uso” y “creado por”. Esos dos campos por sí solos evitan muchos revokes accidentales.
Para operaciones a gran escala, añade acciones masivas con medidas de seguridad: revocar en lote, rotar en lote, cambiar categoría de cuota en lote. Siempre muestra un paso de confirmación con recuento y resume el impacto (“38 claves serán revocadas; 12 se usaron en las últimas 24h”).
Proporciona un panel de detalles apto para auditoría por cada clave: scopes, app asociada, IPs permitidas (si las hay), tier de cuota y errores recientes.
Los desarrolladores quieren copiar, pegar y seguir. Coloca docs claras junto al flujo de creación, no enterradas. Ofrece ejemplos copy-paste en curl y un selector de lenguaje (curl, JS, Python) si puedes.
Muestra la clave una vez con un botón “copiar” y un recordatorio corto sobre almacenamiento. Luego guía con un paso “Llamada de prueba” que ejecute una petición real contra un sandbox o un endpoint de bajo riesgo. Si falla, ofrece explicaciones de error en lenguaje llano y arreglos comunes:
- “Clave inválida” → comprobar nombre del header y espacios
- “Prohibido” → falta scope/permiso
- “Rate limited” → cómo ver cuotas y
Retry-After
Onboarding autoservicio en minutos
Un camino simple funciona mejor: Crear primera clave → hacer una llamada de prueba → ver uso. Incluso un pequeño gráfico de uso (“Últimos 15 minutos”) genera confianza de que el metering funciona.
Enlaza directamente a páginas relevantes usando rutas relativas como /docs, /keys y /usage.
Accesibilidad y claridad
Usa etiquetas claras (“Peticiones por minuto”, “Peticiones mensuales”) y mantiene unidades consistentes. Añade tooltips para términos como “scope” y “burst”. Asegura navegación por teclado, estados de foco visibles y contraste suficiente—especialmente en badges de estado y banners de error.
Despliegue, monitorización y pruebas
Llevar este sistema a producción es sobre disciplina: despliegues predecibles, visibilidad clara cuando algo falla y tests enfocados en las rutas calientes (auth, verificaciones de límite y metering).
Configuración de despliegue (secretos, vars de entorno, migraciones)
Mantén la configuración explícita. Guarda settings no sensibles en variables de entorno (p. ej., valores por defecto de rate-limit, nombres de colas, ventanas de retención) y coloca secretos en un store gestionado (AWS Secrets Manager, GCP Secret Manager, Vault). Evita incrustar claves en imágenes.
Ejecuta migraciones de base de datos como paso de pipeline. Prefiere una estrategia “migrar y luego desplegar” para cambios retrocompatibles y planifica rollbacks seguros (feature flags ayudan). Si eres multi-tenant, añade chequeos de sanity para prevenir migraciones que escaneen tablas de todos los tenants.
Si construyes el sistema sobre Koder.ai, snapshots y rollback pueden ser una red de seguridad práctica en estas iteraciones tempranas (mientras afinás enforcement y esquemas).
Observabilidad que responda preguntas reales
Necesitas tres señales: logs, métricas y trazas. Instrumenta limitación y enforcement con métricas como:
- Requests permitidas vs rechazadas (por clave API, endpoint y tenant)
- “Códigos de razón” para rechazos (limitación, cuota excedida, clave inválida)
- Lag de la tubería de metering (ingest de evento → delay de agregación)
Crea un dashboard específico para rejects por rate-limit para que soporte responda “¿por qué falla mi tráfico?” sin adivinar. El tracing ayuda a detectar dependencias lentas en la ruta crítica (lookups DB para estado de clave, misses de cache, etc.).
Backups y prioridades de recuperación
Trata la config (claves, cuotas, roles) como alta prioridad y los eventos de uso como alto volumen. Haz backups frecuentes de la configuración con recuperación punto-en-tiempo.
Para datos de uso, prioriza durabilidad y re-reproducción: un write-ahead log/cola más re-agregación suele ser más práctico que backups frecuentes completos.
Pruebas y plan de rollout
Unit-testea la lógica de límites (casos límite: fronteras de ventana, requests concurrentes, rotación de claves). Realiza pruebas de carga en las rutas más calientes: validación de clave + actualizaciones de contador.
Luego despliega por fases: usuarios internos → beta limitada (tenants selectos) → GA, con un kill switch para desactivar enforcement si es necesario.