Qué resuelve una app de gestión de deprecaciones
Una deprecación de una funcionalidad es cualquier cambio planificado en el que algo de lo que dependen los usuarios se reduce, reemplaza o elimina. Eso puede significar:
- Una función de la UI que desaparece o se mueve (botones, paneles, ajustes)
- Un endpoint de API que se retira, versiona o cambia comportamiento
- Un cambio en un plan o derecho (límites reducidos, add-on fusionado, nivel de precio eliminado)
Aunque la dirección del producto sea correcta, las deprecaciones fallan cuando se tratan como un anuncio puntual en lugar de un flujo de trabajo de deprecación gestionado.
Modos comunes de fallo
Las retiradas sorpresivas son lo obvio, pero el daño real suele aparecer en otras partes: integraciones rotas, documentación de migración incompleta, mensajes inconsistentes entre canales y picos de soporte justo después de un lanzamiento.
Los equipos también pierden la pista de “quién está afectado” y “quién aprobó qué”. Sin rastro de auditoría, es difícil responder preguntas básicas como: ¿Qué cuentas aún usan la flag antigua? ¿Qué clientes fueron notificados? ¿Cuál fue la fecha prometida?
Por qué ayuda una app dedicada
Una app de gestión de deprecaciones centraliza la planificación de retirada para que cada deprecación tenga un responsable claro, un cronograma y un estado. Impulsa comunicaciones consistentes (email, notificaciones en la app, automatización de notas de lanzamiento), rastrea el progreso de la migración y crea responsabilidad mediante aprobaciones y un rastro de auditoría.
En lugar de documentos y hojas de cálculo dispersas, obtienes una única fuente de verdad para la detección de impacto, plantillas de mensajería y analítica de adopción.
Quién la usa
Los product managers coordinan alcance y fechas. Ingeniería liga los cambios a feature flags y releases. Soporte y Customer Success dependen de listas de clientes y guiones precisos. Cumplimiento y Seguridad pueden requerir aprobaciones, conservación de avisos y prueba de que los clientes fueron informados.
Objetivos, alcance y no-objetivos
Una app de gestión de deprecaciones debe existir para reducir el caos, no para añadir otro lugar más para “revisar”. Antes de diseñar pantallas o modelos de datos, acordad qué significa el éxito y qué queda explícitamente fuera de alcance.
Objetivos (lo que optimizas)
Empieza con resultados que importan a Producto, Soporte e Ingeniería:
- Menos tickets y escalados ligados a cambios rompientes (medida: volumen de tickets etiquetados con la deprecación).
- Mayor completitud de migraciones antes de la fecha límite (medida: % migrado por cohorte/plan).
- Menos reversiones de última hora porque los riesgos se descubrieron tarde (medida: número de extensiones de fecha o rollbacks).
Convierte esto en métricas de éxito y niveles de servicio claros:
- Tiempo desde anuncio → primera acción del cliente
- Tiempo desde anuncio → 80% migrado
- % migrado para la fecha límite (global y por cuentas prioritarias)
- SLA para comunicaciones: p. ej., “Los clientes reciben al menos 30 días de aviso para retiradas mayores”.
Alcance (lo que la app gestiona)
Sé específico sobre el objeto de la deprecación. Puedes empezar estrecho y ampliar:
- Features del producto (comportamiento de UI, ajustes)
- Endpoints/campos de API
- Integraciones (webhooks, conectores de terceros)
- Planes/tiers (entitlements, límites)
- O un modelo unificado de “cambio” que represente todo lo anterior
También define qué significa “migración” en tu contexto: habilitar una nueva función, cambiar endpoints, instalar una nueva integración o completar una checklist.
Restricciones (reglas que no puedes ignorar)
Restricciones comunes que condicionan el diseño:
- Privacidad y cumplimiento: qué datos de usuario/cuenta pueden almacenarse y mostrarse
- Retención de datos: duración del rastro de auditoría, necesidades de exportación, políticas de eliminación
- Requisitos multitenant: segmentación por workspace/org, hospedaje regional
- Aprobaciones: quién puede publicar cronogramas, enviar mensajes a clientes o cambiar fechas límite
No-Objetivos (qué no construir)
Para evitar expansión de alcance, decidid pronto lo que la app no hará—al menos en la v1:
- Reemplazar vuestro helpdesk, sitio de docs o CRM
- Actuar como una herramienta general de gestión de proyectos
- Migrar automáticamente a clientes sin salvaguardas y responsables explícitos
Objetivos y límites claros facilitan alinear decisiones posteriores (flujo, permisos, notificaciones).
Ciclo de vida de la deprecación y etapas del flujo
Una app de gestión de deprecaciones debe hacer explícito el ciclo de vida para que todos sepan qué significa “bien” y qué debe ocurrir antes de avanzar. Empieza mapeando tu proceso actual de punta a punta: anuncio inicial, recordatorios programados, playbooks de soporte y retirada final. El flujo de la app debe reflejar la realidad primero y luego estandarizar gradualmente.
Un modelo de etapas simple y aplicable
Un valor por defecto práctico es:
Propuesto → Aprobado → Anunciado → Migración → Retirada → Hecho
Cada etapa debe tener una definición clara, criterios de salida y un responsable. Por ejemplo, “Anunciado” no debe significar “alguien publicó un mensaje una vez”; debe significar que el anuncio se entregó por los canales acordados y que se programaron seguimientos.
Puntos de control que evitan el caos de última hora
Añade checkpoints obligatorios que deben completarse (y registrarse) antes de marcar una etapa como completada:
- Revisión legal/comms del texto, las fechas y cualquier implicación contractual
- Documentación actualizada (docs, FAQs, notas de lanzamiento, runbooks internos)
- Plan de rollback o mitigación listo, incluyendo quién decide y cómo ejecutar
- Preparación del soporte, incluidos macros/guiones y rutas de escalado
Trata estos elementos como de primera clase: checklists con asignados, fechas y evidencia (enlaces a tickets o docs).
Responsabilidad y aprobaciones
Las deprecaciones fallan cuando la responsabilidad es vaga. Define quién es responsable de cada etapa (Producto, Ingeniería, Soporte, Docs) y exige firmas cuando el riesgo es alto—especialmente en las transiciones Aprobado → Anunciado y Migración → Retirada.
El objetivo es un flujo ligero en el día a día, pero estricto en los puntos donde los errores son costosos.
Modelo de datos: entidades y relaciones
Un modelo de datos claro evita que las deprecaciones se conviertan en docs dispersos, mensajes ad-hoc y responsabilidad difusa. Empieza con un pequeño conjunto de objetos centrales y añade campos solo cuando impulsen decisiones.
Entidades principales
Feature es lo que el usuario experimenta (un ajuste, endpoint de API, informe, flujo).
Deprecation es un evento temporal de cambio para una feature: cuándo se anuncia, restringe y finalmente apaga.
Migration Plan explica cómo los usuarios deben pasarse al reemplazo y cómo medirás el progreso.
Audience Segment define quién está afectado (p. ej., “Cuentas en Plan X que usaron la Feature Y en los últimos 30 días”).
Message captura qué enviarás, dónde y cuándo (email, in-app, banner, macro de soporte).
Campos requeridos (los que desearás tener luego)
Para Deprecation y Migration Plan, trata estos como obligatorios:
- Cronogramas: fecha de anuncio, fecha de fin suave (advertencias/restricciones), fecha de fin definitivo (sunset), más zona horaria.
- Superficies impactadas: áreas de UI, rutas de API, páginas de docs, integraciones, facturación/entitlements.
- Ruta de reemplazo: enlace a la nueva funcionalidad, notas paso a paso de migración y limitaciones conocidas.
- Nivel de riesgo: bajo/medio/alto con una breve justificación (p. ej., “rompe automatización para usuarios avanzados”).
Relaciones (cómo se conecta todo)
Modela la jerarquía del mundo real:
- Una Feature → muchas Deprecations (múltiples retiradas a lo largo del tiempo, rollouts regionales o cambios por políticas).
- Una Deprecation → típicamente un Migration Plan, y muchos Audience Segments (mensajería y fechas distintas).
- Una Deprecation → muchos Messages, cada uno opcionalmente acotado a un Audience Segment.
Campos de auditoría y gobernanza
Añade campos de auditoría en todas partes: created_by, approved_by, created_at, updated_at, approved_at, además de un historial de cambios (quién cambió qué y por qué). Esto permite un rastro de auditoría preciso cuando Soporte, Legal o liderazgo pregunte “¿Cuándo decidimos esto?”.
Roles, permisos y aprobaciones
Roles claros y aprobaciones ligeras previenen dos fallos comunes durante deprecaciones: “todos pueden cambiar todo” y “nada se lanza porque nadie decide”. Diseña la app para que la responsabilidad sea explícita y cada acción visible externamente tenga un propietario.
Roles principales
- Admin: gestiona ajustes del workspace, roles, plantillas globales y reglas de cumplimiento.
- Product Manager (PM): dueño del plan de deprecación, cronogramas, audiencias objetivo e intención de mensajería.
- Ingeniero: implementa pasos técnicos, valida la preparación y actualiza el estado de migración.
- Soporte: monitoriza el impacto en clientes, aporta FAQs/macros y escala bloqueos.
- Solo lectura: puede ver estado, cronogramas e informes sin hacer cambios.
Permisos por acción
Modela permisos alrededor de acciones clave más que pantallas:
- Crear/Editar ítems de deprecación (PM, Admin), con campos limitados editables tras la aprobación.
- Aprobar plan, fechas y cambios de alto impacto (Admin, aprobadores designados).
- Enviar mensajes (PM/Soporte con aprobación) y editar plantillas (Admin).
- Editar cronogramas (PM) con aprobación requerida para cambios de fecha mayores.
- Cerrar (firma de PM + validación de Ingeniero) cuando se alcancen los umbrales de migración.
Flujos de aprobación para cambios de alto riesgo
Requiere aprobaciones cuando un cambio afecta a muchos usuarios, clientes regulados o flujos críticos. Checkpoints típicos: aprobación del plan inicial, “listo para anunciar” y confirmación final de “retirada/desactivación”. Las comunicaciones externas deben estar sujetas a aprobación.
Requisitos del registro de auditoría
Mantén un rastro de auditoría inmutable: quién cambió qué, cuándo y por qué (incluyendo contenido de mensajes, definición de audiencia y ediciones de cronograma). Añade enlaces a tickets e incidentes relacionados para que postmortems y revisiones de cumplimiento sean rápidas y basadas en hechos.
Planifica el ciclo de vida con claridad
Usa Planning Mode para mapear etapas, aprobaciones y listas de verificación antes de escribir código.
Una app de gestión de deprecaciones tiene éxito o fracasa por la claridad. Las personas deben poder responder tres preguntas rápido: ¿Qué cambia? ¿Quién está afectado? ¿Qué hacemos ahora? La arquitectura de la información debe reflejar ese flujo, usando lenguaje llano y patrones consistentes.
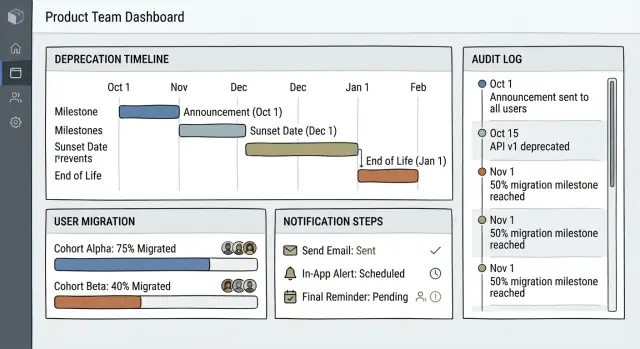
Panel: la “sala de control”
El panel debe poder escanearse en menos de un minuto. Enfócate en trabajo activo y riesgo, no en un inventario largo.
Muestra:
- Deprecaciones activas con la etapa actual (Anunciado → Migración → Retirada)
- Fechas próximas (próximos 7/14/30 días) con etiqueta clara de “días restantes”
- Ítems de alto riesgo: gran audiencia afectada, baja tasa de migración o aprobaciones faltantes
Mantén filtros simples: Estado, Responsable, Área de producto, Ventana de fecha límite. Evita jerga como “estado sunset”; prefiere “Retirada programada”.
Página de detalle de la deprecación: la fuente única de verdad
Cada deprecación necesita una página canónica en la que los equipos confíen durante la ejecución.
Estructúrala como una línea temporal con las decisiones más importantes y siguientes pasos al frente:
- Resumen de cabecera: nombre, responsable, etapa actual, fecha de retirada, enlaces al reemplazo
- Línea temporal: fecha de anuncio, inicio de migración, corte, retirada (con hitos editables)
- Usuarios impactados: segmentos principales, recuentos y cómo se detecta la audiencia
- Mensajes y docs: notificaciones en la app, plantillas de email, fragmento de notas de lanzamiento y enlaces de documentación
Usa etiquetas cortas y directas: “Función de reemplazo”, “Quién está afectado”, “Qué deben hacer los usuarios”.
Reduce errores proporcionando plantillas para:
- Cronogramas estándar (p. ej., planes 30/60/90 días)
- Checklists (aprobaciones, comunicaciones enviadas, soporte informado, docs actualizadas)
- Pasos de migración (qué cambia para los usuarios, prompts de FAQ)
Las plantillas deben seleccionarse al crear y permanecer visibles como checklist en la página de detalle.
Accesibilidad y claridad por defecto
Apunta a mínima carga cognitiva:
- Escribe en lenguaje claro; evita acrónimos internos
- Usa pastillas de estado de alto contraste y formatos de fecha legibles
- Asegura navegación por teclado y encabezados significativos para lectores de pantalla
Una buena UX hace que el flujo parezca inevitable: la siguiente acción es siempre obvia y la página cuenta la misma historia a producto, ingeniería, soporte y clientes.
Segmentación de audiencia y detección de impacto
Las deprecaciones fallan cuando notificas a todos por igual. Una buena app debe responder primero a dos preguntas: quién está afectado y cuánto. La segmentación y la detección de impacto permiten mensajes precisos, reducen ruido de soporte y ayudan a priorizar migraciones.
Fuentes de segmentación (de dónde viene la “audiencia”)
Empieza con segmentos que mapear a cómo los clientes compran, usan y operan:
- Plan / contrato (Free, Pro, Enterprise)
- Nivel de uso (usuarios avanzados vs usuarios ocasionales)
- Tipo de integración (solo API, solo UI, conector específico)
- Región / residencia de datos (importante para tiempos y restricciones legales)
- Antigüedad de la cuenta (clientes nuevos pueden no haber usado la función antigua)
Trata los segmentos como filtros combinables (p. ej., “Enterprise + UE + usa API”). Almacena la definición del segmento para que sea auditable.
Cómo calcular “impactados” (qué evidencia usar)
El impacto debe calcularse desde señales concretas, típicamente:
- Logs de uso (feature toggles, visitas a páginas, clicks en botones)
- Llamadas a la API (endpoints ligados a la capacidad deprecada)
- Eventos de UI (flujos que implican dependencia)
Usa una ventana temporal (“usado en los últimos 30/90 días”) y un umbral (“≥10 eventos”) para separar dependencia activa de ruido histórico.
Casos límite a manejar
Los entornos compartidos crean falsos positivos a menos que los modeles:
- Cuentas compartidas / service users: atribuye uso a workspace o clave de integración, no a una persona.
- Múltiples workspaces: un usuario puede estar afectado en un workspace y no en otro.
- Admins vs usuarios finales: los admins necesitan avisos tempranos y detallados; los usuarios finales necesitan guías centradas en tareas.
Vista previa antes de enviar
Antes de cualquier email o notificación in-app, proporciona un paso de vista previa que muestre una lista de cuentas/usuarios impactados de ejemplo, por qué fueron marcados (señales principales) y el alcance proyectado por segmento. Este “ensayo” evita envíos embarazosos y genera confianza en el flujo.
Notificaciones, mensajería y plantillas
Las deprecaciones fallan con más frecuencia cuando los usuarios no se enteran (o lo hacen demasiado tarde). Trata la mensajería como un activo del flujo: programada, auditable y adaptada a la audiencia afectada.
Canales para la entrega en el mundo real
Soporta múltiples vías para alcanzar a los usuarios donde ya prestan atención:
- Banner in-app para usuarios activos en el momento de necesidad
- Email para alcance amplio y guía más extensa
- Webhooks para empujar eventos a sistemas internos
- Slack (u otro) para alertas a stakeholders internos
- Enlace a status page (opcional) cuando un cambio afecta disponibilidad
Cada notificación debe referenciar el registro de deprecación específico, para que destinatarios y equipos puedan trazar “qué se envió, a quién y por qué”.
Cadencia: desde el aviso inicial hasta la fecha límite
Incluye un cronograma por defecto que los equipos puedan ajustar por deprecación:
- Anuncio: qué cambia y por qué, más la ruta de reemplazo
- Recordatorios: basados en días restantes y actividad del usuario (p. ej., sigue usando la función antigua)
- Aviso de fecha límite: fecha/hora exacta, impacto y opciones de soporte
- Aviso final: confirmación del corte y dónde ir a continuación
Plantillas con variables
Proporciona plantillas con campos variables y vista previa:
- Feature:
{{feature_name}}
- Fecha límite:
{{deadline}}
- Reemplazo:
{{replacement_link}} (p. ej., /docs/migrate/new-api)
- CTA:
{{cta_text}} y {{cta_url}}
Controles de seguridad
Añade salvaguardas para evitar envíos accidentales:
- Envíos de prueba a cuentas internas y segmentos semilla
- Límites de tasa y topes por tenant
- Horas silenciosas por zona horaria
- Manejo de bajas cuando aplique (y canales alternativos cuando los usuarios se den de baja)
Seguimiento de migración y guía al usuario
Lanza una herramienta interna más rápido
Genera una app web en React con backend en Go y PostgreSQL a partir de tus requisitos.
Un plan de deprecación tiene éxito cuando los usuarios ven exactamente qué hacer a continuación—y cuando tu equipo puede confirmar quién realmente se movió. Trata la migración como un conjunto de pasos concretos y rastreables, no como un vago “por favor actualiza”.
Pasos de migración tipo checklist
Modela cada migración como una checklist pequeña con resultados claros (no solo instrucciones). Por ejemplo: “Crear nueva API key”, “Cambiar inicialización del SDK”, “Eliminar llamadas al endpoint legado”, “Verificar firma del webhook”. Cada paso debe incluir:
- Una breve descripción y criterios de “hecho”
- Enlaces al lugar correcto para completarlo (página de ajustes, asistente o docs)
- Validación opcional (p. ej., detección de uso del nuevo endpoint)
Mantén la checklist visible en la página de la deprecación y en cualquier banner in-app para que los usuarios siempre puedan retomar donde lo dejaron.
Migración guiada (ayuda, no tarea)
Añade un panel de “migración guiada” que agrupe lo que los usuarios suelen buscar:
- Páginas de docs relevantes (p. ej., /docs/migrations/legacy-to-v2)
- Entradas a asistentes (p. ej., /settings/integrations/new-setup)
- Configs de ejemplo y snippets copy-paste
- Una FAQ corta que cubra fallos comunes y cómo revertir con seguridad
Esto no es solo contenido; es navegación. Las migraciones más rápidas ocurren cuando la app dirige a las personas exactamente a la pantalla que necesitan.
Seguimiento de completitud con la granularidad adecuada
Haz seguimiento por cuenta, workspace e integración (cuando aplique). Muchos equipos migran un workspace primero y luego despliegan gradualmente.
Almacena progreso como eventos y estado: estado del paso, marcas de tiempo, actor y señales detectadas (p. ej., “endpoints v2 vistos en las últimas 24 h”). Proporciona un “% completado” de un vistazo y un desglose de lo que está bloqueando.
Entrega al soporte con contexto automático
Cuando los usuarios se atascan, haz la escalada sencilla: un botón “Contactar soporte” debe crear un ticket, asignar un CSM (o cola) y adjuntar contexto automáticamente—identificadores de cuenta, paso actual, mensajes de error, tipo de integración y actividad reciente de migración. Esto evita idas y venidas y acorta el tiempo de resolución.
Los proyectos de deprecación fallan silenciosamente cuando no ves quién está afectado, quién se está moviendo y quién podría churnear. La analítica debe responder a esas preguntas de un vistazo y hacer que los números sean lo bastante fiables como para compartirlos con liderazgo, Soporte y Customer Success.
Métricas básicas de adopción
Empieza con un pequeño conjunto de métricas claras:
- Usuarios expuestos: cuentas/usuarios que todavía usan la función deprecada (o llaman al endpoint antiguo) en una ventana definida.
- Migración iniciada: usuarios que comenzaron el flujo de actualización (p. ej., habilitaron la feature de reemplazo, crearon settings requeridos, instalaron la nueva integración).
- Migración completada: usuarios que cumplen tus criterios de “hecho” (uso del reemplazo por encima de un umbral, uso del legado a cero, checklist completada).
- Señales de riesgo de churn: aumento de tickets sobre la feature, eventos de error repetidos, caídas de uso, intentos de migración fallidos o tags NPS negativos ligados al cambio.
Define cada métrica en la UI con un tooltip corto y enlace a “Cómo lo calculamos”. Si las definiciones cambian en medio del proyecto, registra el cambio en el rastro de auditoría.
Cronogramas que coincidan con el ciclo de vida
Un buen informe se lee como el plan de deprecación:
- Líneas de progreso en el tiempo para expuestos/iniciados/completados.
- Marcadores verticales para fechas clave: anuncio, recordatorio, aviso final, retirada.
- Indicador de “ritmo hacia el objetivo” (p. ej., tendencia de completitud vs tasa necesaria para terminar antes de la retirada).
Esto hace evidente si se necesitan recordatorios adicionales, mejoras en herramientas o ajustes de fecha.
Desglores que impulsan acción
Los rollups son útiles, pero las decisiones suceden por segmentos. Proporciona desgloses por:
- Segmento de audiencia (persona o caso de uso)
- Plan (free vs tiers de pago)
- Región (zonas horarias y festivos locales afectan la respuesta)
- Tipo de integración (clientes API, conectores partner, autoconstruidos vs marketplace)
Cada desglose debe enlazar directamente a la lista de cuentas afectadas, para que los equipos actúen sin necesidad de exportar primero.
Soporta compartición ligera:
- Export CSV para listas de cuentas y rollups
- Resúmenes programados por email/Slack a stakeholders
- Un informe semanal “en riesgo antes de la retirada” que resalte segmentos y cuentas principales a contactar
Para automatización y BI más profunda, expón los mismos datos vía una API (y procura estabilidad entre proyectos de deprecación).
Integraciones: feature flags, analítica, docs y herramientas de soporte
Empieza pequeño, escala después
Prueba Koder.ai en el plan gratuito y amplía cuando tu app necesite más capacidad.
Una app de deprecaciones es más útil cuando se convierte en la “fuente de verdad” que otros sistemas pueden confiar. Las integraciones permiten pasar de actualizaciones manuales a gating, medición y flujos de soporte automatizados.
Feature flags: control y verificación
Conecta con tu proveedor de feature flags para que cada deprecación pueda referenciar una o más flags (experiencia antigua, nueva, rollback). Esto permite:
- Gating por entorno (dev/stage/prod) y por segmento de audiencia
- Chequeos automatizados (p. ej., “nuevo flujo habilitado para 90% de cuentas elegibles”)
- Rollbacks más seguros ligados al registro de deprecación, no a una hoja de cálculo separada
Almacena las keys de flags y el “estado esperado” por etapa, más un job ligero de sincronización para leer el estado actual.
Analítica + warehouse: medir adopción, no opiniones
Conecta la app a la analítica de producto para que cada deprecación tenga una métrica de éxito clara: eventos para “usó la feature antigua”, “usó la nueva” y “completó la migración”. Extrae recuentos agregados para mostrar progreso por segmento.
Opcionalmente, streamea las mismas métricas a un data warehouse para cortes más profundos (plan, región, antigüedad de cuenta). Mantén esto opcional para no bloquear equipos pequeños.
Docs y notas de lanzamiento: un clic desde el registro
Cada deprecación debe enlazar al contenido canónico y a los anuncios, usando rutas internas como:
- /docs/migrations/new-checkout
- /release-notes/2026-01
Esto reduce la inconsistencia: soporte y PMs siempre citan las mismas páginas.
Webhooks y APIs: automatizar trabajo downstream
Expón webhooks (y una pequeña REST API) para eventos de ciclo de vida como “scheduled”, “email_sent”, “flag_flipped” y “sunset_completed”. Consumidores comunes: CRMs, helpdesks y proveedores de mensajería—para que los clientes reciban orientación consistente y puntual sin replicar actualizaciones entre herramientas.
Arquitectura y plan de implementación
Trata la primera versión como una app CRUD enfocada: crear deprecaciones, definir fechas, asignar responsables, listar audiencias impactadas y seguir el estado. Empieza con lo que tu equipo pueda lanzar rápido y añade automatización (ingestión de eventos, mensajería, integraciones) una vez que el flujo sea fiable.
Stack: elige lo que ya usáis
Un stack típico de bajo riesgo es una app web server-rendered o una SPA simple con API (Rails/Django/Laravel/Node). La clave es fiabilidad: buenas migraciones, pantallas de admin sencillas y jobs en background. Si ya tenéis SSO (Okta/Auth0), úsalo; si no, añade magic links sin contraseña para usuarios internos.
Si queréis acelerar la primera versión (especialmente para tooling interno), considera prototipar en Koder.ai. Es una plataforma vibe-coding donde describes el flujo en chat, iteras en “planning mode” y generas una app React con backend en Go y PostgreSQL—luego exportas el código si la queréis llevar in-house. Las snapshots y rollback son útiles mientras refináis etapas, permisos y reglas de notificación.
Bloques de construcción core
Necesitarás:
- Auth + autorización para responsables, revisores y lectores
- Base relacional (Postgres/MySQL) para registros de deprecación, tareas, aprobaciones y rastro de auditoría
- Jobs en background para notificaciones programadas, recordatorios e informes
- Servicio de mensajería para email + webhooks (Slack/Teams)
- Endpoint de ingestión de eventos para recibir eventos de uso que alimenten impact y dashboards
Almacenamiento de datos: workflows vs uso
Mantén el sistema de registro del flujo en una BD relacional. Para uso, empieza guardando agregados diarios en Postgres; si el volumen crece, manda eventos crudos a un event store o warehouse y consulta tablas resumidas para la app.
Esenciales operativos
Haz jobs idempotentes (seguros de reintentar), usa claves de deduplicación para mensajes salientes y políticas de reintento con backoff. Registra cada intento de entrega y alerta sobre fallos. Monitorización básica (profundidad de colas, tasa de errores, fallos de webhook) evita comunicaciones perdidas silenciosas.
Pruebas, lanzamiento y operaciones continuas
Una app de deprecaciones toca mensajería, permisos y experiencia cliente—por lo que las pruebas deben enfocarse en modos de fallo tanto como en caminos felices.
Prueba los flujos que importan
Empieza con escenarios end-to-end que reflejen deprecaciones reales: redacción, aprobaciones, ediciones de cronograma, envío de mensajes y rollbacks. Incluye casos límite como “extender la fecha final tras enviar mensajes” o “cambiar el reemplazo a mitad de camino” y confirma que la UI refleja claramente lo que cambió.
También prueba aprobaciones bajo presión: revisores paralelos, aprobaciones rechazadas, re-aprobación tras ediciones y qué ocurre si cambia el rol de un aprobador.
Valida segmentación y detección de impacto
Los errores de segmentación son costosos. Usa un conjunto de cuentas de ejemplo (y usuarios “golden”) para validar que las audiencias correctas se seleccionan. Combina checks automatizados con comprobaciones manuales puntuales: elige cuentas aleatorias y verifica que el impacto calculado concuerda con la realidad del producto.
Si tienes reglas que dependen de analítica o feature flags, prueba con eventos retrasados o faltantes para saber cómo se comporta el sistema cuando los datos están incompletos.
Chequeos de seguridad y preparación de auditoría
Ejecuta pruebas de permisos para cada rol: quién puede ver segmentos sensibles, quién puede editar cronogramas y quién puede enviar mensajes. Confirma que los logs de auditoría capturan “quién/qué/cuándo” de ediciones y envíos, y minimiza PII almacenada—prefiere IDs estables sobre emails cuando sea posible.
Plan de rollout y operaciones
Lanza gradualmente: piloto interno, conjunto pequeño de deprecaciones de bajo riesgo y luego uso más amplio. Durante el despliegue, define un on-call o “responsable de la semana” para ediciones urgentes, rebotes o segmentación equivocada.
Finalmente, establece una cadencia operativa ligera: revisiones mensuales de deprecaciones completadas, calidad de plantillas y métricas de adopción. Esto mantiene la app fiable y evita que se convierta en una herramienta puntual que la gente deje de usar.