03 abr 2025·8 min
Gestionar el estado entre frontend y backend en aplicaciones de IA
Aprende cómo el estado de la interfaz, la sesión y los datos se desplazan entre frontend y backend en aplicaciones de IA, con patrones prácticos para sincronización, persistencia, caché y seguridad.
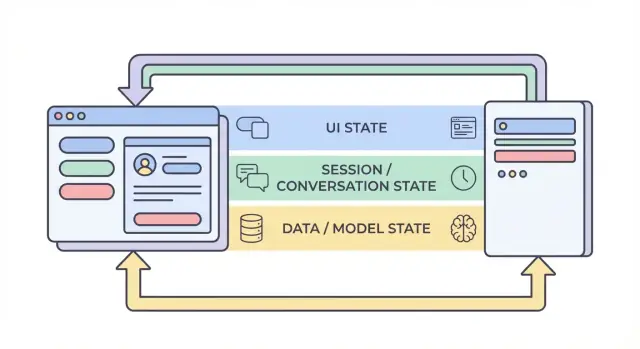
Qué significa “estado” en una aplicación construida con IA
“Estado” es todo lo que tu aplicación necesita recordar para comportarse correctamente de un momento a otro.
Si un usuario pulsa Enviar en una UI de chat, la app no debería olvidar lo que escribió, qué respondió ya el asistente, si una petición sigue en curso o qué ajustes (tono, modelo, herramientas) están activados. Todo eso es estado.
Estado, en términos sencillos
Una forma útil de pensar en el estado es: la verdad actual de la app: valores que afectan lo que el usuario ve y lo que el sistema hará a continuación. Esto incluye cosas obvias como entradas de formulario, pero también hechos “invisibles” como:
- En qué conversación está el usuario
- Si la última respuesta está en streaming o ha terminado
- La lista de mensajes y su orden
- Llamadas a herramientas y resultados de herramientas (resultados de búsqueda, consultas a bases de datos, extractos de archivos)
- Errores, reintentos y retroceso por límites de tasa
Por qué las apps de IA tienen más partes móviles
Las apps tradicionales suelen leer datos, mostrarlos y guardar actualizaciones. Las apps de IA añaden pasos extra y salidas intermedias:
- Una sola acción del usuario puede desencadenar múltiples operaciones en el backend (llamada al LLM, llamada a una herramienta, otra llamada al LLM).
- Las respuestas pueden llegar de forma incremental (tokens en streaming), por lo que la UI debe manejar estado parcial.
- El contexto importa: el sistema puede necesitar mantener memoria de la conversación, resultados de herramientas y ajustes del modelo consistentes entre peticiones.
Ese movimiento extra es la razón por la que la gestión del estado suele ser la complejidad oculta en las aplicaciones de IA.
Qué cubrirá esta guía
En las secciones siguientes, dividiremos el estado en categorías prácticas (estado de UI, estado de sesión, datos persistidos y estado de modelo/runtime), y mostraremos dónde debería vivir cada uno (frontend vs backend). También trataremos sincronización, caché, trabajos de larga duración, actualizaciones en streaming y seguridad—porque el estado solo es útil si es correcto y está protegido.
Ejemplo rápido
Imagina una app de chat donde un usuario pide: “Resume las facturas del mes pasado y marca cualquier cosa inusual”. El backend podría (1) obtener las facturas, (2) ejecutar una herramienta de análisis, (3) transmitir un resumen a la UI y (4) guardar el informe final.
Para que eso se sienta fluido, la app debe llevar registro de mensajes, resultados de herramientas, progreso y la salida guardada—sin mezclar conversaciones ni filtrar datos entre usuarios.
Las cuatro capas del estado: UI, sesión, datos y modelo
Cuando la gente dice “estado” en una app de IA, a menudo mezcla cosas muy distintas. Dividir el estado en cuatro capas—UI, sesión, datos y modelo/runtime—hace más fácil decidir dónde debe residir algo, quién puede cambiarlo y cómo debe almacenarse.
1) Estado de UI (lo que el usuario está haciendo ahora)
El estado de UI es el estado vivo, momento a momento en el navegador o app móvil: entradas de texto, conmutadores, elementos seleccionados, qué pestaña está abierta y si un botón está deshabilitado.
Las apps de IA añaden algunos detalles específicos de UI:
- Indicadores de carga y estados de “pensando”
- Tokens en streaming (texto parcial que aparece mientras se genera)
- Borradores locales de mensajes (antes de enviarlos)
El estado de UI debería ser fácil de reiniciar y seguro de perder. Si el usuario refresca la página, puedes perderlo—y por lo general eso está bien.
2) Estado de sesión / conversación (contexto compartido del flujo del usuario)
El estado de sesión vincula a un usuario con una interacción en curso: identidad del usuario, un ID de conversación y una vista consistente del historial de mensajes.
En apps de IA, esto a menudo incluye:
- Historial de mensajes (o referencias al mismo)
- Rastreos de herramientas (qué funciones/herramientas se llamaron y con qué resultados)
- Conjuntos de trabajo como el proyecto/documento actual, el modelo seleccionado o el workspace
Esta capa suele abarcar frontend y backend: el frontend guarda identificadores ligeros, mientras que el backend es la autoridad para la continuidad de la sesión y el control de acceso.
3) Estado de datos (registros duraderos en almacenamiento)
El estado de datos es lo que guardas intencionalmente en una base: proyectos, documentos, embeddings, preferencias, logs de auditoría, eventos de facturación y transcripciones de conversaciones guardadas.
A diferencia del estado de UI y de sesión, el estado de datos debería ser:
- Duradero (sobrevive reinicios)
- Consultable (puedes buscar/filtrar)
- Auditable (puedes entender qué pasó después)
4) Estado de modelo / runtime (cómo está configurada la IA ahora)
El estado de modelo/runtime es la configuración operativa usada para producir una respuesta: prompts de sistema, herramientas habilitadas, temperatura/max tokens, ajustes de seguridad, límites de tasa y caches temporales.
Parte de esto es configuración (valores por defecto estables); otra parte es efímera (caches de corta vida o presupuestos de tokens por petición). La mayor parte debe residir en el backend para poder controlarlo de forma consistente y no exponerlo innecesariamente.
Por qué la separación reduce errores
Cuando estas capas se mezclan, aparecen fallos clásicos: la UI muestra texto que no fue guardado, el backend usa ajustes de prompt distintos a lo que el frontend esperaba, o la memoria de conversación “se fuga” entre usuarios. Límites claros crean fuentes de verdad evidentes—y hacen obvio qué debe persistir, qué puede recomputarse y qué debe protegerse.
Qué vive en el frontend vs. el backend (y por qué)
Una forma fiable de reducir errores en apps de IA es decidir, para cada pieza de estado, dónde debe vivir: en el navegador (frontend), en el servidor (backend) o en ambos. Esta elección afecta la fiabilidad, seguridad y qué tan “sorprendente” se siente la app cuando los usuarios refrescan, abren otra pestaña o pierden conexión.
Estado frontend: rápido, temporal y dirigido por el usuario
El estado frontend es ideal para cosas que cambian rápido y no necesitan sobrevivir un refresco. Mantenerlo local hace la UI responsiva y evita llamadas API innecesarias.
Ejemplos comunes solo en frontend:
- Texto del borrador que el usuario está escribiendo
- Filtros y orden local en una tabla
- Estado de modales abiertos/cerrados, pestaña seleccionada, estados hover
Si pierdes este estado al refrescar, suele ser aceptable (y esperado).
Estado backend: autorizado, sensible y compartido
El backend debe contener todo lo que debe ser confiable, auditado o aplicado consistentemente. Esto incluye estado que otros dispositivos/pestañas necesitan ver, o que debe seguir siendo correcto aunque el cliente sea modificado.
Ejemplos comunes solo en backend:
- Permisos y roles (lo que el usuario puede hacer)
- Estado de facturación/suscripción y límites de uso
- Trabajos de larga duración (indexado de documentos, grandes exportaciones, entrenamientos finos) y su estado
Una buena regla: si un estado incorrecto podría costar dinero, filtrar datos o romper control de acceso, pertenece al backend.
Estado compartido: coordinado, pero con una fuente de verdad
Algunos estados son naturalmente compartidos:
- Título de la conversación
- Fuentes de conocimiento seleccionadas para un chat
- Campos de perfil usados en varios dispositivos
Incluso siendo compartido, elige una “fuente de verdad”. Normalmente el backend es la autoridad y el frontend cachea una copia para velocidad.
Regla práctica (y un antipatrón común)
Mantén el estado lo más cerca posible de donde se necesita, pero persiste lo que debe sobrevivir refrescos, cambios de dispositivo o interrupciones.
Evita el antipatrón de almacenar estado sensible o autoritativo solo en el navegador (por ejemplo, tratar una bandera client-side isAdmin, el plan contratado o el estado de finalización de un trabajo como verdad). La UI puede mostrar esos valores, pero el backend debe verificarlos.
Ciclo de vida típico de una petición de IA: del clic a la finalización
Una funcionalidad de IA parece “una acción”, pero en realidad es una cadena de transiciones de estado compartidas entre el navegador y el servidor. Entender el ciclo de vida ayuda a evitar UI desalineada, contexto perdido y cargos duplicados.
1) Acción del usuario → frontend prepara la intención
Un usuario pulsa Enviar. La UI actualiza de inmediato el estado local: puede añadir un burbuja de mensaje “pendiente”, desactivar el botón de enviar y capturar entradas actuales (texto, adjuntos, herramientas seleccionadas).
En este punto el frontend debería generar o adjuntar identificadores de correlación:
conversation_id: a qué hilo pertenecemessage_id: ID del cliente para el nuevo mensaje del usuariorequest_id: único por intento (útil para reintentos)
Estos IDs permiten que ambos lados hablen del mismo evento incluso cuando las respuestas llegan tarde o duplicadas.
2) Llamada API → servidor valida y persiste
El frontend envía una petición API con el mensaje de usuario más los IDs. El servidor valida permisos, límites de tasa y la forma del payload, luego persiste el mensaje del usuario (o al menos un registro de log inmutable) indexado por conversation_id y message_id.
Este paso de persistencia previene un “historial fantasma” cuando el usuario refresca a mitad de petición.
3) El servidor reconstruye contexto
Para llamar al modelo, el servidor recompone el contexto desde su fuente de verdad:
- Recupera mensajes recientes para el
conversation_id - Saca registros relacionados (documentos, preferencias, resultados de herramientas)
- Aplica políticas de conversación (prompts de sistema, reglas de memoria, truncamiento)
La idea clave: no confíes en que el cliente proporcione el historial completo. El cliente puede estar desactualizado.
4) Ejecución de modelo/herramientas → estado intermedio
El servidor puede llamar a herramientas (búsqueda, consulta a BD) antes o durante la generación del modelo. Cada llamada a herramienta produce estado intermedio que debe rastrearse contra request_id para auditar y reintentar de forma segura.
5) Respuesta (streaming o no) → completado en UI
Con streaming, el servidor envía tokens/parciales. La UI actualiza incrementalmente el mensaje asistente pendiente, pero lo trata como “en curso” hasta que un evento final marque la finalización.
6) Puntos de fallo a planificar
Suceden reintentos, envíos dobles y respuestas fuera de orden. Usa request_id para deduplicar en servidor, y message_id para reconciliar en la UI (ignora fragmentos tardíos que no coincidan con la petición activa). Muestra siempre un estado claro de “fallado” con un reintento seguro que no cree mensajes duplicados.
Sesiones y memoria de conversación: mantener contexto sin caos
Mantén el estado seguro
Genera verificaciones de autorización del lado del servidor y patrones de validación seguros para escrituras de estado.
Una sesión es el “hilo” que liga las acciones de un usuario: en qué workspace están, qué buscó por última vez, qué borrador editaba y a qué conversación debe continuar una respuesta de IA. Un buen estado de sesión hace que la app se sienta continua entre páginas—y, idealmente, entre dispositivos—sin convertir tu backend en un vertedero de todo lo que el usuario dijo.
Objetivos del estado de sesión
Apunta a: (1) continuidad (un usuario puede irse y volver), (2) corrección (la IA usa el contexto correcto para la conversación correcta) y (3) contención (una sesión no debe filtrar a otra).
Si soportas múltiples dispositivos, trata las sesiones como con alcance por usuario y por dispositivo: “misma cuenta” no siempre significa “misma instancia abierta”.
Cookies vs. tokens vs. sesiones en servidor
Normalmente elegirás una de estas formas para identificar la sesión:
- Cookies: más simple para apps web porque el navegador las envía automáticamente. Genial para sesiones tradicionales, pero debes establecer flags seguros (
HttpOnly,Secure,SameSite) y manejar CSRF adecuadamente. - Tokens (p. ej. JWT): buenos para APIs y apps móviles porque el cliente los adjunta explícitamente. Escalan bien, pero la revocación y rotación requieren diseño adicional (y no deberías meter estado sensible dentro del token).
- Sesiones en servidor: el servidor almacena datos de sesión (a menudo en Redis) y el cliente solo guarda un ID opaco de sesión. Más fácil de revocar y actualizar, pero debes operar y escalar la tienda de sesiones.
Estrategias de memoria de conversación
“La memoria” es solo estado que eliges volver a enviar al modelo.
- Historia completa: más precisa, pero cara y puede exponer contenido sensible antiguo.
- Historia resumida: mantener un resumen acumulado más unos pocos turnos recientes; más barato y, por lo general, suficiente.
- Contexto en ventana: solo los últimos N mensajes; lo más simple, pero puede perder decisiones importantes previas.
Un patrón práctico es resumen + ventana: es predecible y ayuda a evitar comportamientos sorprendentes del modelo.
Llamadas a herramientas: repetibles y auditables
Si la IA usa herramientas (búsqueda, consultas, lecturas de archivos), guarda cada llamada a herramienta con: entradas, timestamps, versión de la herramienta y la salida devuelta (o una referencia a ella). Esto permite explicar “por qué dijo eso la IA”, reproducir ejecuciones para debug y detectar cuándo los resultados cambiaron porque la herramienta o el dataset cambiaron.
Salvaguardas de privacidad
No almacenes memoria de larga duración por defecto. Guarda solo lo necesario para continuidad (IDs de conversación, resúmenes y logs de herramientas), define límites de retención y evita persistir texto bruto del usuario a menos que haya una razón clara de producto y consentimiento del usuario.
Sincronizar estado de forma segura: fuentes de verdad y manejo de conflictos
El estado es riesgoso cuando la misma “cosa” puede editarse en más de un sitio—tu UI, una segunda pestaña del navegador o un job en background que actualiza una conversación. La solución tiene menos que ver con código ingenioso y más con propiedad clara.
Define fuentes de verdad
Decide qué sistema es el autoritativo para cada pieza de estado. En la mayoría de apps de IA, el backend debe poseer el registro canónico para todo lo que debe ser correcto: configuraciones de conversación, permisos de herramientas, historial de mensajes, límites de facturación y estado de trabajos. El frontend puede cachear y derivar estado para velocidad (pestañas seleccionadas, texto de borrador, indicadores de “está escribiendo”), pero debe asumir que el backend tiene la razón cuando haya discrepancia.
Una regla práctica: si te molestaría perderlo al refrescar, probablemente pertenece al backend.
Actualizaciones optimistas (úsalas con cuidado)
Las actualizaciones optimistas hacen que la app se sienta instantánea: cambia un ajuste, actualiza la UI de inmediato y luego confírmalo con el servidor. Funciona bien para acciones de bajo riesgo y reversibles (p. ej., marcar una conversación como favorita).
Causa confusión cuando el servidor puede rechazar o transformar el cambio (chequeos de permisos, límites de cuota, validación o valores por defecto server-side). En esos casos, muestra un estado de “guardando…” y actualiza la UI solo tras la confirmación.
Manejo de conflictos (dos pestañas, una conversación)
Los conflictos ocurren cuando dos clientes actualizan el mismo registro a partir de versiones distintas. Ejemplo común: Pestaña A y Pestaña B cambian la temperatura del modelo.
Usa versionado ligero para que el backend detecte escrituras obsoletas:
updated_attimestamps (simple, fácil de depurar)- ETags / cabeceras
If-Match(nativo en HTTP) - Números de revisión incrementales (detención explícita de conflictos)
Si la versión no coincide, devuelve una respuesta de conflicto (a menudo HTTP 409) y devuelve el objeto servidor más reciente.
Diseña APIs para reducir desajustes
Tras cualquier escritura, haz que la API devuelva el objeto guardado tal como quedó persistido (incluyendo valores por defecto generados por el servidor, campos normalizados y la nueva versión). Esto permite al frontend reemplazar su copia en caché de inmediato—una actualización de la fuente de verdad en vez de adivinar qué cambió.
Caché y rendimiento: acelerar sin estado obsoleto
El caching es una de las formas más rápidas de hacer que una app de IA se sienta instantánea, pero también crea una segunda copia de estado. Si cacheas lo equivocado—o lo haces en el lugar equivocado—entregarás una UI rápida pero confusa.
Qué cachear en el cliente
Las caches del lado cliente deberían centrarse en la experiencia, no en la autoridad. Buenos candidatos son previsualizaciones recientes de conversaciones (título, fragmento del último mensaje), preferencias de UI (tema, modelo seleccionado, estado de la barra lateral) y estado optimista de UI (mensajes que están “enviándose”).
Mantén la cache del cliente pequeña y desechable: si se borra, la app debería funcionar refetchando desde el servidor.
Qué cachear en el servidor
Las caches del servidor deberían centrarse en trabajo caro o frecuentemente repetido:
- Resultados de herramientas que sean seguros de reutilizar (p. ej., una consulta meteorológica para la misma ciudad durante 5 minutos)
- Búsquedas por embeddings y resultados de búsqueda vectorial para consultas repetidas (a menudo con TTLs cortos)
- Estado de límites de tasa y contadores de throttling (para proteger tu API y costes)
Aquí también puedes cachear estado derivado como conteos de tokens, decisiones de moderación o salidas de parseo de documentos—cualquier cosa determinista y costosa.
Fundamentos de invalidación de caché (sin complicarse)
Tres reglas prácticas:
- Usa claves de caché claras que codifiquen entradas (
user_id, modelo, parámetros de herramienta, versión de documento). - Define TTLs según la velocidad a la que cambia el dato subyacente. Un TTL corto vence a lógica compleja.
- Omite la cache cuando la corrección importa más que la velocidad: después de que un usuario actualiza un documento, cambia permisos o solicita una actualización.
Si no puedes explicar cuándo una entrada de caché quedará obsoleta, no la caches.
No caches secretos ni datos personales en caches compartidas
Evita poner claves API, tokens de auth, prompts crudos con texto sensible o contenido específico de usuarios en capas compartidas como CDN caches. Si debes cachear datos de usuario, aísla por usuario y cifra en reposo—o guárdalo en tu BD primaria.
Mide el impacto: velocidad vs UI obsoleta
El caching debe demostrarse, no asumirse. Rastrea latencia p95 antes/después, tasa de aciertos de caché y errores visibles por usuario como “mensaje actualizado después de renderizar”. Una respuesta rápida que luego contradice la UI suele ser peor que una respuesta algo más lenta pero consistente.
Persistencia y trabajos de larga duración: jobs, colas y estado de estatus
Prototipa web y móvil
Crea clientes móviles en Flutter y web en React que comparten el mismo estado backend.
Algunas funciones de IA terminan en un segundo. Otras tardan minutos: subir y parsear un PDF, generar embeddings e indexar una base de conocimiento, o ejecutar un workflow multi-paso de herramientas. Para estos, el “estado” no es solo lo que hay en pantalla: es lo que sobrevive refrescos, reintentos y tiempo.
Qué persistir (y por qué)
Persiste solo lo que desbloquea valor de producto real.
Historial de conversación es lo obvio: mensajes, timestamps, identidad del usuario y (a menudo) qué modelo/herramientas se usaron. Esto permite “reanudar después”, trazas de auditoría y mejor soporte.
Ajustes de usuario y workspace deberían vivir en la base de datos: modelo preferido, valores por defecto de temperatura, toggles de funcionalidades, prompts de sistema y preferencias de UI que sigan al usuario entre dispositivos.
Archivos y artefactos (subidas, texto extraído, informes generados) suelen almacenarse en object storage con registros en la base de datos apuntando a ellos. La BD guarda metadata (propietario, tamaño, tipo de contenido, estado de procesamiento) y el blob store guarda los bytes.
Trabajos en background para tareas largas
Si una petición no puede terminar confiablemente dentro de un timeout HTTP normal, mueve el trabajo a una cola.
Un patrón típico:
- El frontend llama a un endpoint como
POST /jobscon entradas (file id, conversation id, parámetros). - El backend encola un job (extracción, indexado, ejecución batch de herramientas) y devuelve inmediatamente un
job_id. - Workers procesan los jobs asíncronamente y escriben resultados de vuelta al almacenamiento persistente.
Esto mantiene la UI responsiva y hace más seguro reintentar.
Estado de estatus en el que la UI puede confiar
Haz el estado del job explícito y consultable: queued → running → succeeded/failed (opcionalmente canceled). Guarda estas transiciones server-side con timestamps y detalles de error.
En el frontend, refleja el estado claramente:
- Queued/running: muestra un spinner y deshabilita acciones duplicadas.
- Failed: muestra un error conciso y un botón Reintentar.
- Succeeded: carga el artefacto resultante o actualiza la conversación.
Expón GET /jobs/{id} (polling) o transmite actualizaciones (SSE/WebSocket) para que la UI no tenga que adivinar.
Claves de idempotencia: reintentos sin escrituras duplicadas
Los timeouts de red ocurren. Si el frontend reintenta POST /jobs, no quieres dos jobs idénticos (y dos facturas).
Requiere una Idempotency-Key por acción lógica. El backend almacena la clave con el job_id/respuesta resultante y devuelve el mismo resultado para peticiones repetidas.
Políticas de limpieza y expiración
Las apps de IA de larga duración acumulan datos rápido. Define reglas de retención temprano:
- Expirar conversaciones antiguas tras N días (o permitir que el usuario lo configure).
- Borrar artefactos derivados cuando se elimina la fuente.
- Purgar periódicamente jobs fallidos y archivos intermedios.
Trata la limpieza como parte de la gestión del estado: reduce riesgo, coste y confusión.
Respuestas en streaming y actualizaciones en tiempo real: gestionar estado parcial
El streaming complica el estado porque la “respuesta” ya no es un único blob. Tratas tokens parciales (texto que llega palabra a palabra) y a veces trabajo de herramienta parcial (una búsqueda empieza y termina más tarde). Eso significa que tu UI y backend deben ponerse de acuerdo sobre qué cuenta como estado temporal vs final.
Backend: transmite eventos tipados, no solo texto
Un patrón limpio es transmitir una secuencia de pequeños eventos, cada uno con un tipo y un payload. Por ejemplo:
token: texto incremental (o un pequeño chunk)tool_start: comenzó una llamada a herramienta (p. ej., “Buscando…”, con un id)tool_result: la salida de la herramienta está lista (mismo id)done: el mensaje del asistente está completoerror: algo falló (incluye un mensaje seguro para el usuario y un id de debug)
Este stream de eventos es más fácil de versionar y depurar que el streaming de texto crudo, porque el frontend puede renderizar el progreso con precisión (y mostrar estado de herramientas) sin adivinar.
Frontend: actualizaciones append-only, luego un commit final
En el cliente, trata el streaming como append-only: crea un mensaje asistente “borrador” y sigue extendiéndolo a medida que llegan eventos token. Cuando recibas done, haz un commit: marca el mensaje como final, persístelo (si lo guardas localmente) y desbloquea acciones como copiar, puntuar o regenerar.
Esto evita reescribir la historia a mitad de stream y mantiene la UI predecible.
Manejo de interrupciones (cancelar, cortes, timeouts)
El streaming incrementa la probabilidad de trabajo a medio terminar:
- Usuario cancela: envía una señal de cancelación; deja de renderizar tokens; mantiene el borrador visiblemente cancelado.
- Corte de red: detén el stream; muestra “reconectando…” y no asumas finalización.
- Timeouts/errores del servidor: finaliza el borrador como fallido y ofrece un reintento que inicie una nueva petición (no coser streams silenciosamente).
Rehidratación: recargar y reconstruir estado estable
Si la página se recarga a mitad de stream, reconstruye desde el último estado estable: los últimos mensajes confirmados más cualquier metadata de borrador almacenada (message id, texto acumulado hasta ahora, estados de herramientas). Si no puedes reanudar el stream, muestra el borrador como interrumpido y permite al usuario reintentar, en lugar de fingir que se completó.
Seguridad y privacidad: proteger el estado de extremo a extremo
Añade trabajos en segundo plano de forma limpia
Modela flujos encolado‑ejecución‑completado y muestra el progreso confiable en la interfaz.
El estado no es solo “datos que guardas”—es los prompts del usuario, cargas, preferencias, salidas generadas y la metadata que lo enlaza todo. En apps de IA, ese estado puede ser inusualmente sensible (info personal, documentos propietarios, decisiones internas), así que la seguridad debe diseñarse en cada capa.
Mantén secretos en el servidor
Todo lo que permitiría al cliente suplantar tu app debe quedarse backend-only: claves API, conectores privados (Slack/Drive/DB creds) y prompts o lógica interna de enrutamiento. El frontend puede solicitar una acción (“resume este archivo”), pero el backend debe decidir cómo ejecutarla y con qué credenciales.
Autoriza cada escritura (y la mayoría de lecturas)
Trata cada mutación de estado como una operación privilegiada. Cuando el cliente intenta crear un mensaje, renombrar una conversación o adjuntar un archivo, el backend debería verificar:
- Que el usuario está autenticado.
- Que el usuario es propietario del recurso (conversación, workspace, proyecto).
- Que el usuario puede realizar esa acción (rol, límites del plan, política de la organización).
Esto evita ataques de “adivinanza de IDs” donde alguien intercambia un conversation_id y accede al historial de otro usuario.
Nunca confíes en el navegador: valida y sanea
Asume que cualquier dato provisto por el cliente es input no confiable. Valida esquema y restricciones (tipos, longitudes, enums permitidos) y sanea según el destino (SQL/NoSQL, logs, renderizado HTML). Si aceptas “actualizaciones de estado” (p. ej., settings, parámetros de herramientas), haz whitelist de campos permitidos en lugar de mezclar JSON arbitrario.
Trazas de auditoría para acciones críticas
Para acciones que cambian estado durable—compartir, exportar, borrar, acceso a conectores—registra quién hizo qué y cuándo. Un log de auditoría ligero ayuda en respuesta a incidentes, soporte y cumplimiento.
Minimización de datos y cifrado
Almacena solo lo necesario para la función. Si no necesitas prompts completos para siempre, considera ventanas de retención o redacción. Cifra estado sensible en reposo donde corresponda (tokens, credenciales de conectores, documentos subidos) y usa TLS en tránsito. Separa metadata operativa de contenido para poder restringir más estrictamente el acceso.
Arquitectura de referencia práctica y checklist de construcción
Un valor por defecto útil para apps de IA es simple: el backend es la fuente de verdad, y el frontend es una caché optimista y rápida. La UI puede sentirse instantánea, pero todo aquello que te entristecería perder (mensajes, estado de jobs, resultados de herramientas, eventos relevantes para facturación) debe confirmarse y guardarse server-side.
Si construyes con un flujo de trabajo de “vibe-coding”—donde mucha superficie de producto se genera rápido—el modelo de estado se vuelve aún más importante. Plataformas como Koder.ai pueden ayudar a equipos a lanzar apps web, backend y móviles desde chat, pero la misma regla aplica: iterar rápido es más seguro cuando fuentes de verdad, IDs y transiciones de estado están diseñadas desde el inicio.
Arquitectura de referencia (una que puedes lanzar)
Frontend (navegador/móvil)
- Estado de UI: paneles abiertos, texto de borrador, modelo seleccionado, indicadores temporales de “escribiendo”.
- Estado cacheado del servidor: conversaciones recientes, último estado conocido de jobs, buffer parcial de streaming.
- Una única tubería de peticiones que siempre adjunta:
session_id,conversation_idy un nuevorequest_id.
Backend (API + workers)
- Servicio API: valida entradas, crea registros y emite respuestas en streaming.
- Almacenamiento durable (SQL/NoSQL): conversaciones, mensajes, llamadas a herramientas, estado de jobs.
- Cola + workers: tareas de larga duración (indexado RAG, parseo de archivos, generación de imágenes).
- Caché (opcional): lecturas calientes (resúmenes de conversaciones, metadata de embeddings), siempre con llaves versionadas/timestamps.
Nota: una forma práctica de mantener esto consistente es estandarizar tu stack backend pronto. Por ejemplo, backends generados por Koder.ai suelen usar Go con PostgreSQL (y React en el frontend), lo que facilita centralizar el estado “autoritativo” en SQL mientras la cache cliente sigue siendo desechable.
Diseña tu modelo de estado primero
Antes de construir pantallas, define los campos en los que confiarás en cada capa:
- IDs y propiedad:
user_id,org_id,conversation_id,message_id,request_id. - Timestamps y orden:
created_at,updated_aty unasequenceexplícita para mensajes. - Campos de estado:
queued | running | streaming | succeeded | failed | canceled(para jobs y llamadas a herramientas). - Versionado:
etagoversionpara actualizaciones seguras frente a conflictos.
Esto evita el bug clásico donde la UI “se ve bien” pero no puede reconciliar reintentos, refrescos o ediciones concurrentes.
Usa formas de API consistentes
Mantén endpoints predecibles entre features:
GET /conversations(listar)GET /conversations/{id}(obtener)POST /conversations(crear)POST /conversations/{id}/messages(añadir)PATCH /jobs/{id}(actualizar estado)GET /streams/{request_id}oPOST .../stream(stream)
Devuelve el mismo estilo de envoltorio en todas partes (incluyendo errores) para que el frontend pueda actualizar estado de forma uniforme.
Añade observabilidad donde el estado puede romperse
Registra y devuelve un request_id por cada llamada de IA. Guarda inputs/outputs de llamadas a herramientas (con redacción), latencias, reintentos y estado final. Facilita responder: “¿Qué vio el modelo, qué herramientas se ejecutaron y qué estado persistimos?”.
Checklist de construcción (para evitar bugs comunes de estado)
- El backend es la fuente de verdad; la cache del frontend es claramente etiquetada y desechable.
- Cada escritura es idempotente (segura de reintentar) usando
request_id(y/o una Idempotency-Key). - Las transiciones de estado son explícitas y validadas (no saltos silenciosos de
queuedasucceeded). - Las actualizaciones en streaming se fusionan por IDs/secuencia, no por “el último mensaje gana”.
- Los conflictos se gestionan vía
version/etago reglas de merge server-side. - PII y secretos nunca se guardan en estado del cliente; redacta logs por defecto.
- Existe una vista de dashboard para debug: peticiones, llamadas a herramientas, estado de jobs y errores.
Cuando adoptes ciclos de entrega más rápidos (incluyendo generación asistida por IA), considera añadir guardrails que hagan cumplir estos puntos automáticamente—validación de esquema, idempotencia y streaming con eventos—para que “moverse rápido” no se convierta en deriva de estado. En la práctica, ahí es donde una plataforma end-to-end como Koder.ai puede ser útil: acelera la entrega y, al mismo tiempo, permite exportar código fuente y mantener patrones de manejo de estado consistentes entre web, backend y móvil.