15 nov 2025·8 min
TypeScript y C# de Hejlsberg: herramientas que permiten escalar el código
Cómo Anders Hejlsberg configuró C# y TypeScript para mejorar la experiencia del desarrollador: tipos, servicios del IDE, refactorizaciones y bucles de retroalimentación que permiten escalar bases de código.
Por qué importa la experiencia del desarrollador cuando las bases de código crecen
Una base de código rara vez se vuelve lenta porque los ingenieros de repente olviden programar. Se enlentece porque sube el coste de entender las cosas: comprender módulos desconocidos, hacer un cambio de forma segura y demostrar que el cambio no rompió otra cosa.
A medida que un proyecto crece, “simplemente buscar y editar” deja de funcionar. Empiezas a pagar por cada pista faltante: APIs confusas, patrones inconsistentes, autocompletado pobre, builds lentos y errores poco útiles. El resultado no es solo una entrega más lenta: es una entrega más cautelosa. Los equipos evitan refactorizaciones, posponen limpieza y envían cambios más pequeños y seguros que no hacen avanzar el producto.
Por qué Anders Hejlsberg es relevante aquí
Anders Hejlsberg es una figura clave detrás de C# y TypeScript —dos lenguajes que tratan la experiencia del desarrollador (DX) como una característica de primera clase. Eso importa porque un lenguaje no es solo sintaxis y comportamiento en tiempo de ejecución; también es el ecosistema de herramientas a su alrededor: editores, herramientas de refactorización, navegación y la calidad de la retroalimentación que recibes mientras escribes código.
Este artículo mira TypeScript y C# desde una lente práctica: cómo sus decisiones de diseño ayudan a los equipos a moverse más rápido a medida que los sistemas y los equipos se expanden.
Qué significa realmente “escalar”
Cuando decimos que una base de código “escala”, normalmente hablamos de varias presiones a la vez:
- Tamaño del equipo: más contribuyentes, más estilos, más coste de coordinación.
- Tamaño del código: más módulos, más dependencias, más áreas “desconocidas”.
- Tasa de cambio: lanzamientos más frecuentes y flujos de trabajo paralelos.
El tooling sólido reduce el impuesto creado por esas presiones. Ayuda a los ingenieros a responder preguntas comunes al instante: “¿Dónde se usa esto?”, “¿Qué espera esta función?”, “¿Qué cambia si renombro esto?” y “¿Es seguro enviar esto?” Eso es experiencia del desarrollador—y a menudo es la diferencia entre una base de código grande que evoluciona y una que se fosiliza.
La influencia de Anders Hejlsberg: una lente práctica
La influencia de Anders Hejlsberg es más fácil de ver no como un conjunto de citas o hitos personales, sino como una filosofía de producto consistente que aparece en el tooling mainstream: hacer que el trabajo común sea rápido, hacer los errores obvios temprano y hacer los cambios a gran escala más seguros.
Esta sección no es una biografía. Es una lente práctica para entender cómo el diseño del lenguaje y el ecosistema de herramientas que lo rodea pueden moldear la cultura de ingeniería del día a día. Cuando los equipos hablan de “buena DX”, a menudo se refieren a cosas que se diseñaron deliberadamente en sistemas como C# y TypeScript: autocompletado predecible, valores por defecto sensatos, refactorizaciones en las que puedes confiar y errores que te indican cómo arreglar en vez de solo rechazar tu código.
Cómo se ve la “influencia” en la cultura del tooling
Puedes observar el impacto en las expectativas que ahora traen los desarrolladores hacia los lenguajes y editores:
- Los editores deberían entender el código, no solo colorearlo.
- Navegación, renombrado y “buscar referencias” deberían funcionar en todo el repo.
- Los tipos (donde existen) deberían mejorar la productividad, no frenarla.
- Las herramientas deberían mantenerse lo bastante rápidas para usarlas constantemente, no solo antes de un release.
Estos resultados son medibles en la práctica: menos errores de tiempo de ejecución evitables, refactorizaciones con más confianza y menos tiempo gastado “reaprendiendo” una base de código al incorporarse a un equipo.
Por qué comparar C# y TypeScript
C# y TypeScript se ejecutan en entornos distintos y atienden audiencias diferentes: C# suele usarse en aplicaciones de servidor y entornos empresariales, mientras que TypeScript apunta al ecosistema JavaScript. Pero comparten un objetivo de DX similar: ayudar a los desarrolladores a moverse rápido reduciendo el coste del cambio.
Compararlos es útil porque separa principios de plataforma. Cuando ideas similares triunfan en dos runtimes muy distintos —lenguaje estático sobre un runtime gestionado (C#) y una capa tipada sobre JavaScript (TypeScript)— sugiere que la victoria no es accidental. Es el resultado de decisiones de diseño explícitas que priorizan retroalimentación, claridad y mantenibilidad a escala.
Tipos estáticos como mecanismo de escalado (no solo una preferencia)
El tipado estático suele enmarcarse como gusto: “me gustan los tipos” vs. “prefiero flexibilidad”. En bases de código grandes, es menos una cuestión de preferencia y más de economía. Los tipos son una forma de mantener el trabajo diario predecible a medida que más personas tocan más archivos con mayor frecuencia.
Qué te aporta el “tipado fuerte” en el día a día
Un sistema de tipos sólido da nombres y formas a las promesas de tu programa: qué espera una función, qué devuelve y qué estados están permitidos. Eso convierte el conocimiento implícito (en la cabeza de alguien o enterrado en docs) en algo que el compilador y las herramientas pueden hacer cumplir.
En la práctica, eso significa menos conversaciones tipo “¿Es esto null quizá?”, autocompletado más claro, navegación más segura por módulos desconocidos y revisiones de código más rápidas porque la intención está codificada en la API.
Chequeos en tiempo de compilación vs. fallos en tiempo de ejecución
Los chequeos en tiempo de compilación fallan temprano, a menudo antes de que el código se mezcle. Si pasas un argumento del tipo equivocado, olvidas un campo requerido o usas mal un valor de retorno, el compilador lo marca inmediatamente.
Los fallos en tiempo de ejecución aparecen después —tal vez en QA, tal vez en producción— cuando se ejecuta una ruta concreta con datos reales. Esos bugs suelen ser más costosos: son más difíciles de reproducir, interrumpen a los usuarios y generan trabajo reactivo.
Los tipos estáticos no previenen todos los bugs en tiempo de ejecución, pero eliminan una gran clase de errores "esto no debió compilar".
Fallos que el tipado ayuda a evitar al escalar
A medida que los equipos crecen, los puntos comunes de ruptura son:
- Contratos poco claros: los módulos no explicitán sus garantías y el uso deriva.
- Refactorizaciones inseguras: renombres y cambios de firma pasan por alto sitios de llamada.
- Acoplamiento escondido: partes no relacionadas dependen de la misma forma de objeto poco definida.
Los tipos actúan como un mapa compartido. Cuando cambias un contrato, obtienes una lista concreta de lo que necesita actualizarse.
Los trade-offs (reales, pero manejables)
El tipado tiene costes: curva de aprendizaje, anotaciones extra (especialmente en los límites) y fricción ocasional cuando el sistema de tipos no puede expresar lo que quieres con claridad. La clave es usar los tipos estratégicamente —más en APIs públicas y estructuras de datos compartidas— para obtener los beneficios de escala sin convertir el desarrollo en papeleo.
Bucles de retroalimentación rápidos: la ventaja oculta de los lenguajes modernos
Un bucle de retroalimentación es el ciclo diminuto que repites todo el día: editar → comprobar → arreglar. Cambias una línea, tus herramientas la verifican de inmediato y corriges lo que está mal antes de perder el contexto.
Retroalimentación lenta: cuando los bugs viajan lejos
En un bucle lento, “comprobar” suele significar ejecutar la app y confiar en pruebas manuales (o esperar CI). Ese retraso convierte pequeños errores en búsquedas del tesoro:
- Empujas código.
- Las pruebas fallan más tarde (o peor, lo reportan usuarios).
- Alguien tiene que reconstruir la intención, reproducir el problema y parchearlo bajo presión.
Cuanto mayor sea la brecha entre editar y descubrir, más caro resulta cada arreglo.
Retroalimentación rápida: el editor + compilador como compañero
Los lenguajes modernos y su tooling acortan el bucle a segundos. En TypeScript y C#, tu editor puede marcar problemas mientras escribes, a menudo con una corrección sugerida.
Ejemplos concretos que se detectan temprano:
- Propiedad faltante: accedes a
user.address.zip, peroaddressno está garantizado. - Tipo de parámetro equivocado: pasas una cadena donde se requiere un número (o un enum específico).
- Código inalcanzable: un
returnhace que el resto de la función sea imposible de ejecutar.
Estos no son “trucos”—son deslices comunes que las herramientas rápidas convierten en correcciones rápidas.
Por qué esto importa más en equipos
La retroalimentación rápida reduce los costes de coordinación. Cuando el compilador y el servicio de lenguaje detectan discordancias de inmediato, menos problemas se filtran a la revisión de código, QA o el trabajo de otros equipos. Eso significa menos idas y venidas (“¿qué quisiste decir aquí?”), menos builds rotas y menos sorpresas del tipo “alguien cambió un tipo y mi feature explotó”.
A escala, la velocidad no es solo rendimiento en tiempo de ejecución: es la rapidez con la que los desarrolladores pueden confiar en que su cambio es válido.
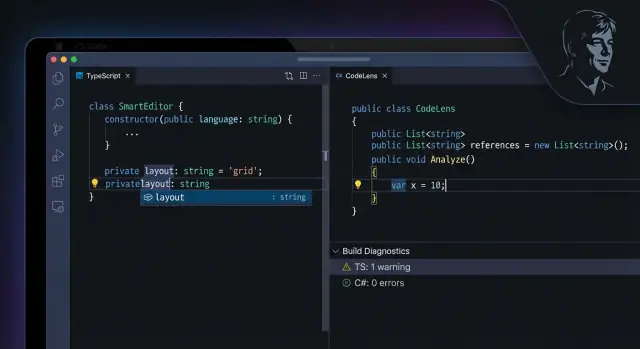
Tooling que se siente nativo: servicios de lenguaje e integración IDE
“Servicios de lenguaje” es un nombre sencillo para el conjunto de funciones del editor que hacen que el código sea fácil de buscar y seguro de tocar. Piensa en: autocompletado que entiende tu proyecto, “ir a definición” que salta al archivo correcto, renombrado que actualiza todos los usos y diagnósticos que subrayan problemas antes de ejecutar nada.
TypeScript: el compilador como asistente siempre activo
La experiencia de editor de TypeScript funciona porque el compilador no sirve solo para producir JavaScript: también alimenta el TypeScript Language Service, el motor detrás de la mayoría de las funciones del IDE.
Cuando abres un proyecto TS en VS Code (u otros editores que hablan el mismo protocolo), el language service lee tu tsconfig, sigue imports, construye un modelo de tu programa y responde continuamente a preguntas como:
- ¿Qué tipo tiene este valor ahora mismo?
- ¿Qué sobrecarga se está llamando?
- ¿Dónde está definido este símbolo en todo el workspace?
Por eso TypeScript puede ofrecer autocompletado preciso, renombres seguros, ir-a-definición, “buscar todas las referencias”, correcciones rápidas y errores en línea mientras escribes. En repositorios grandes con mucho JavaScript, ese lazo estrecho es una ventaja de escalado: los ingenieros pueden editar módulos desconocidos y obtener orientación inmediata sobre lo que se romperá.
C#: compilador + IDE funcionando como una unidad
C# se beneficia de un principio similar, pero con integración IDE especialmente profunda en flujos de trabajo comunes (notablemente Visual Studio y también VS Code vía language servers). La plataforma de compilador soporta análisis semántico rico, y la capa del IDE añade refactorizaciones, acciones de código, navegación a nivel de proyecto y feedback en tiempo de build.
Esto importa cuando los equipos crecen: pasas menos tiempo “compilando mentalmente” la base de código. En su lugar, las herramientas pueden confirmar la intención —mostrándote el símbolo real que estás llamando, las expectativas de nulabilidad, los sitios de llamada afectados y si un cambio se propaga a través de proyectos.
Por qué esto escala más allá de la conveniencia
A tamaño pequeño, el tooling es un nice-to-have. A tamaño grande, es la forma en que los equipos se mueven sin miedo. Los servicios de lenguaje fuertes hacen que el código desconocido sea más fácil de explorar, más fácil de cambiar con seguridad y más fácil de revisar —porque los mismos hechos (tipos, referencias, errores) son visibles para todos, no solo para quien escribió el módulo originalmente.
Soporte de refactorización: hacer que el cambio sea barato y fiable
Aclara la intención primero
Usa el modo de planificación para aclarar el alcance antes de tocar la base de código.
Refactorizar no es una tarea de “limpieza de primavera” que haces después del trabajo real. En bases de código grandes, es el trabajo real: remodelar continuamente el código para que las nuevas funcionalidades no se vuelvan más lentas y arriesgadas cada mes.
Cuando un lenguaje y sus herramientas hacen que refactorizar sea seguro, los equipos pueden mantener los módulos pequeños, los nombres precisos y los límites claros —sin programar una reescritura riesgosa de varias semanas.
Las refactorizaciones que necesitas cada día
El soporte moderno del IDE en TypeScript y C# suele agruparse en unos pocos movimientos de alto impacto:
- Renombrado seguro para variables, métodos, clases, archivos y módulos
- Extraer método/función para convertir bloques largos en unidades legibles y testeables
- Mover símbolo (p. ej., mover una clase a otro archivo/namespace/módulo) manteniendo imports/usings correctos
- Organizar imports/usings para reducir ruido y evitar conflictos sutiles
Son acciones pequeñas, pero a escala marcan la diferencia entre “podemos cambiar esto” y “nadie toque ese archivo”.
Por qué la refactorización necesita entendimiento semántico (no búsqueda de texto)
La búsqueda de texto no puede decir si dos palabras idénticas se refieren al mismo símbolo. Las herramientas reales de refactorización usan la comprensión del compilador: tipos, ámbitos, sobrecargas y resolución de módulos —para actualizar el significado, no solo caracteres.
Ese modelo semántico permite renombrar una interfaz sin tocar un literal de cadena, o mover un método y arreglar automáticamente cada importación y referencia.
Modos de fallo que el buen tooling ayuda a evitar
Sin refactorización semántica, los equipos suelen enviar rupturas evitables:
- Referencias rotas tras renombres o movimientos
- Sitios de llamada perdidos por patrones dinámicos, sobrecargas o nombres en sombra
- Ediciones accidentales en comentarios/cadenas en vez de en código
- APIs medio actualizadas donde algunos archivos compilan y otros divergen sin ruido
Aquí la experiencia del desarrollador se convierte directamente en rendimiento de ingeniería: cambio más seguro significa más cambio, antes —y menos miedo integrado en la base de código.
Enfoque de TypeScript: seguridad gradual para un mundo JavaScript
TypeScript triunfa en gran parte porque no pide a los equipos “empezar de cero”. Acepta que la mayoría de los proyectos reales empiezan como JavaScript —desordenado, rápido y ya en producción— y luego te permite añadir seguridad sin bloquear el ritmo.
Tipado estructural, inferencia y tipado gradual (en términos sencillos)
TypeScript usa tipado estructural, lo que significa que la compatibilidad se basa en la forma de un valor (sus campos y métodos), no en el nombre de un tipo declarado. Si un objeto tiene { id: number }, normalmente puede usarse donde se espera esa forma —incluso si viene de otro módulo o no fue “declarado” explícitamente como ese tipo.
También se apoya mucho en la inferencia de tipos. A menudo obtienes tipos significativos sin escribirlos:
const user = { id: 1, name: \"Ava\" }; // inferred as { id: number; name: string }
Finalmente, TypeScript es gradual: puedes mezclar código tipado y no tipado. Puedes anotar primero los límites más críticos (respuestas de API, utilidades compartidas, módulos del dominio central) y dejar el resto para después.
“Agregar tipos sobre la marcha” hace la adopción realista
Este camino incremental es la razón por la que TypeScript encaja en bases de código JavaScript existentes. Los equipos pueden convertir archivo a archivo, aceptar algo de any al principio y aún así obtener ganancias inmediatas: mejor autocompletado, refactorizaciones más seguras y contratos de función más claros.
La rigidez es una perilla que los equipos suben con el tiempo
La mayoría de las organizaciones empiezan con ajustes moderados y luego aprietan las reglas conforme la base de código se estabiliza —habilitando opciones como strict, endureciendo noImplicitAny o mejorando la cobertura de strictNullChecks. La clave es progreso sin parálisis.
Una precaución breve: los tipos expresan intención, no verdad
Los tipos modelan lo que esperas que ocurra; no prueban el comportamiento en tiempo de ejecución. Aún necesitas tests —especialmente para reglas de negocio, bordes de integración y cualquier cosa que implique E/S o datos no confiables.
Enfoque de C#: características de productividad que escalan equipos
Construye todo el stack desde el chat
Inicia una app web, de servidor o móvil y mantén todo el stack consistente.
C# ha crecido alrededor de una idea simple: hacer que la forma “normal” de escribir código sea también la más segura y legible. Eso importa cuando una base de código deja de ser algo que una persona puede tener en la cabeza y se convierte en un sistema compartido mantenido por muchos.
Legibilidad e intención como valores por defecto
C# moderno apuesta por sintaxis que se lee como intención de negocio en vez de mecánica. Pequeñas características se suman: inicialización clara de objetos, pattern matching para “manejar estas formas de datos” y expresiones switch expresivas que reducen bloques if anidados.
Cuando docenas de desarrolladores tocan los mismos archivos, estas facilidades reducen la necesidad de conocimiento tribal. Las revisiones de código dejan de ser descifrar y pasan a validar comportamiento.
Seguridad que encaja con el código del mundo real
Una de las mejoras de escalado más prácticas es la nulabilidad. En lugar de tratar null como una sorpresa permanente, C# ayuda a los equipos a expresar intención:
- “Este valor nunca puede ser null” (así los consumidores pueden confiar en eso)
- “Esto puede ser null” (así los llamantes son empujados a manejar el caso)
Eso traslada muchos defectos de producción a tiempo de compilación, y es especialmente útil en equipos grandes donde las APIs las usan personas que no las escribieron.
Ergonomía de async/await: concurrencia escalable para humanos
A medida que los sistemas crecen, también lo hacen las llamadas de red, la E/S de archivos y el trabajo en background. async/await de C# hace que el código asíncrono se lea como código síncrono, reduciendo la carga cognitiva de manejar concurrencia.
En lugar de enhebrar callbacks por todo el código, los equipos pueden escribir flujos directos —obtener datos, validar y continuar— mientras el runtime gestiona la espera. El resultado son menos bugs relacionados con tiempos y menos convenciones personalizadas que los nuevos miembros deban aprender.
Tooling que sigue siendo útil en soluciones grandes
La historia de productividad de C# es inseparable de sus servicios de lenguaje e integración IDE. En soluciones grandes, el tooling fuerte cambia lo que es factible en el día a día:
- Navegación rápida entre proyectos (ir a definición, encontrar referencias)
- Análisis a nivel de solución que detecta cambios rompientes temprano
- Refactorizaciones automatizadas y seguras (renombrar, extraer método, cambiar firma)
Así es como los equipos mantienen el impulso. Cuando el IDE puede responder con fiabilidad “¿dónde se usa esto?” y “¿qué romperá este cambio?”, los desarrolladores hacen mejoras proactivamente en vez de evitarlas.
Un “pit of success” consistente
El patrón duradero es la consistencia: tareas comunes (manejo de null, flujos async, refactors) están soportadas tanto por el lenguaje como por las herramientas. Esa combinación convierte buenas prácticas en el camino más fácil —exactamente lo que quieres al escalar una base de código y el equipo detrás de ella.
Diagnósticos y mensajes de error que enseñan (no solo bloquean)
Cuando una base de código es pequeña, un error vago puede ser “suficiente”. A escala, los diagnósticos forman parte del sistema de comunicación del equipo. TypeScript y C# reflejan un sesgo al estilo Hejlsberg hacia mensajes que no solo te paran —te muestran cómo avanzar.
Cómo son los mensajes de error “buenos”
Los diagnósticos útiles suelen compartir tres rasgos:
- Accionables: sugieren el siguiente paso (“¿Quisiste decir…?”, “Agrega una comprobación de null”, “Convierte a async”).
- Específicos: nombran el símbolo exacto, el tipo esperado o el miembro faltante en lugar de describir solo la categoría del fallo.
- Locales: apuntan a la zona más pequeña del código responsable, para que puedas arreglar sin cavar en archivos no relacionados.
Esto importa porque los errores se leen bajo presión. Un mensaje que enseña reduce idas y vueltas y convierte tiempo “bloqueado” en tiempo de aprendizaje.
Advertencias vs errores: por qué las advertencias protegen a tu yo futuro
Los errores imponen corrección ahora. Las advertencias protegen la salud a largo plazo: APIs deprecadas, código inalcanzable, uso cuestionable de null, implicit any y otros problemas que “funcionan hoy, pero podrían romper mañana”.
Los equipos pueden tratar las advertencias como una reducción gradual: empezar permisivo y luego endurecer políticas con el tiempo (idealmente evitando que el número de advertencias suba).
Diagnósticos como estándares de equipo y combustible de onboarding
Diagnósticos consistentes crean código consistente. En vez de depender del conocimiento tribal (“aquí no hacemos eso”), las herramientas explican la regla en el momento que importa.
Esa es una ventaja de escalado: los recién llegados pueden arreglar problemas que nunca han visto porque el compilador y el IDE documentan la intención —justo en la lista de errores.
Rendimiento e incrementalidad: mantener las herramientas rápidas a escala
Cuando una base de código crece, la retroalimentación lenta se convierte en un impuesto diario. Rara vez aparece como un único “gran” problema; es la muerte por mil esperas: builds más largos, suites de tests lentas y pipelines de CI que convierten cheques rápidos en interrupciones de una hora.
El dolor de escalado que realmente notas
Aparecen algunos síntomas comunes en equipos y stacks:
- Los tiempos de build aumentan a medida que se suman proyectos, código generado y dependencias.
- Los tiempos de tests se inflan, especialmente cuando “ejecutar todo” pasa a ser la opción por defecto.
- Los retrasos en CI causan PRs apilados, más conflictos de merge y revisiones basadas en suposiciones en vez de resultados verificados.
- Lag en el editor (autocompletado, ir-a-definición, renombrado) hace que los desarrolladores trabajen alrededor de sus herramientas en vez de con ellas.
Por qué la incrementalidad cambia la experiencia
Las toolchains modernas tienden a tratar “recompilar todo” como último recurso. La idea clave es simple: la mayoría de las ediciones solo afectan una porción pequeña del programa, así que las herramientas deberían reutilizar trabajo previo.
La compilación incremental y el caching suelen apoyarse en:
- Seguimiento de dependencias: saber qué archivos/módulos dependen de qué.
- Resultados intermedios estables: mantener árboles de sintaxis parseados, información de tipos o salidas compiladas que se puedan reutilizar.
- Invalidación inteligente: recalcular solo lo que cambió —y lo que debe cambiar por ello.
Esto no es solo builds más rápidos. Es lo que permite que los servicios de lenguaje “vivos” se mantengan sensibles mientras escribes, incluso en repositorios grandes.
La capacidad de respuesta del editor como barra de calidad
Trata la capacidad de respuesta del IDE como una métrica de producto, no como un lujo. Si renombrar, encontrar referencias y diagnósticos toman segundos, la gente deja de confiar —y deja de refactorizar.
Formas prácticas de mantener la retroalimentación rápida
Establece presupuestos explícitos (por ejemplo: build local bajo X minutos, acciones clave del editor bajo Y ms, cheques de CI bajo Z minutos). Mídelos continuamente.
Luego actúa según los números: separa caminos calientes en CI, ejecuta el conjunto de tests más pequeño que pruebe un cambio y apuesta por caching e incrementalidad donde puedas. El objetivo es simple: hacer que la ruta más rápida sea la ruta por defecto.
Diseñar para el cambio: APIs, límites y mantenibilidad
Comparte tu trabajo sin configuración extra
Publica tu proyecto en un dominio personalizado cuando estés listo para compartirlo.
Las bases de código grandes no suelen fallar por una función mala —fallan porque los límites se difuminan con el tiempo. La forma más sencilla de mantener el cambio seguro es tratar las APIs (incluso las internas) como productos: pequeñas, estables e intencionales.
Contratos claros (y por qué los tipos ayudan)
En TypeScript y C#, los tipos convierten “cómo llamar a esto” en un contrato explícito. Cuando una librería compartida expone tipos bien elegidos —entradas estrechas, formas de retorno claras, enums significativos— reduces la cantidad de “reglas implícitas” que viven solo en la cabeza de alguien.
Para APIs internas, esto importa aún más: los equipos cambian, la propiedad cambia y la librería se convierte en una dependencia que no puedes “leer rápido”. Los tipos fuertes dificultan el mal uso y hacen que los refactors sean más seguros porque los llamadores rompen en compilación en vez de en producción.
Controlar la superficie con límites
Un sistema mantenible suele estar en capas:
- Superficie pública vs internas: exporta solo lo que pretendes soportar; mantiene helpers privados.
- Módulos/namespaces: agrupa capacidades relacionadas para mejorar la descubribilidad y reducir el acoplamiento accidental.
- Dirección de dependencias: el código de mayor nivel depende de primitivas de menor nivel, no al revés.
Esto tiene menos que ver con “pureza arquitectónica” y más con hacer obvio dónde deben ocurrir los cambios.
Versionado, deprecaciones y hábitos de equipo
Las APIs evolucionan. Planea para ello:
- Introduce nuevos puntos de entrada junto a los antiguos, marca los viejos como deprecados y fija una fecha de eliminación.
- Mantén un changelog ligero para paquetes compartidos para que las actualizaciones no se conviertan en arqueología.
Apoya estos hábitos con automatización: reglas de lint que prohíben imports internos, checklists de code review para cambios de API y cheques de CI que hagan cumplir semver y eviten exportaciones públicas accidentales. Cuando las reglas son ejecutables, la mantenibilidad deja de ser una virtud personal y se convierte en una garantía del equipo.
Recomendaciones accionables para escalar grandes bases de código
Las bases de código grandes no fallan porque un equipo “eligió el lenguaje equivocado”. Fallan porque el cambio se vuelve arriesgado y lento. El patrón práctico detrás de TypeScript y C# es simple: tipos + herramientas + retroalimentación rápida hacen el cambio cotidiano más seguro.
La idea central
Los tipos estáticos son más valiosos cuando se combinan con excelentes servicios de lenguaje (autocompletado, navegación, correcciones rápidas) y bucles de retroalimentación ajustados (errores instantáneos, compilaciones incrementales). Esa combinación convierte la refactorización de un evento estresante en una actividad rutinaria.
Dónde encaja Koder.ai en la historia de DX
No todas las mejoras de escalado provienen solo del lenguaje: el flujo de trabajo también importa. Plataformas como Koder.ai buscan comprimir aún más el bucle “editar → comprobar → arreglar” permitiendo a los equipos construir apps web, backend y móviles mediante un flujo guiado por chat (React en web, Go + PostgreSQL en backend, Flutter en móvil), manteniendo como resultado código fuente real y exportable.
En la práctica, características como planning mode (para clarificar intención antes de cambios), snapshots y rollback (para hacer los refactors más seguros) y despliegue/hosting integrado con dominios personalizados se alinean directamente con el tema de este artículo: reducir el coste del cambio y mantener la retroalimentación cerrada a medida que los sistemas crecen.
Un roadmap de adopción simple (que funciona en el mundo real)
-
Empieza por mejoras de tooling. Estandariza la configuración del IDE, habilita formateo consistente, añade linting y asegúrate de que “ir a definición” y renombrar funcionen en todo el repo.
-
Añade seguridad gradualmente. Activa la verificación de tipos donde más duele (módulos compartidos, APIs, código de alta rotación). Ve hacia configuraciones más estrictas con el tiempo en lugar de intentar “apagar el interruptor” en una semana.
-
Refactoriza con cortafuegos. Cuando los tipos y el tooling sean fiables, invierte en refactors más grandes: extraer módulos, clarificar límites y eliminar código muerto. Usa el compilador y el IDE para hacer el trabajo pesado.
Señales de que estás escalando bien
- Los cambios son predecibles: puedes estimar esfuerzo sin depuración heróica.
- Las regresiones disminuyen porque los cambios rompientes se captan temprano.
- Las refactorizaciones se sienten confiadas: renombrar/mover/extraer es aburrido, no aterrador.
- Los nuevos compañeros son productivos más rápido porque la base de código se “explica sola” mediante tipos y herramientas.
Pasos prácticos siguientes
Elige una feature próxima y trátala como piloto: endurece tipos en el área tocada, exige builds verdes en CI y mide lead time y tasa de bugs antes/después.
Si quieres más ideas, consulta publicaciones relacionadas de ingeniería en /blog.
Preguntas frecuentes
¿Qué significa “experiencia del desarrollador” en el contexto de grandes bases de código?
La experiencia del desarrollador (DX) es el costo cotidiano de hacer un cambio: entender el código, editar con seguridad y comprobar que funciona. A medida que las bases de código y los equipos crecen, ese coste de “averiguar” domina —y una buena DX (navegación rápida, refactorizaciones fiables, errores claros) evita que la velocidad de entrega colapse bajo la complejidad.
¿Por qué la experiencia del desarrollador se vuelve más importante a medida que el proyecto escala?
En un repositorio grande, se pierde tiempo por la incertidumbre: contratos poco claros, patrones inconsistentes y retroalimentación lenta.
El buen tooling reduce esa incertidumbre respondiendo con rapidez:
- ¿Dónde se usa esto?
- ¿Qué tipo/forma se espera aquí?
- ¿Qué se romperá si renombro o muevo esto?
- ¿Es seguro desplegar este cambio?
¿Por qué Anders Hejlsberg es relevante en la discusión sobre escalar equipos de ingeniería?
Porque es una filosofía de diseño repetible que aparece en ambos ecosistemas: priorizar retroalimentación rápida, servicios de lenguaje sólidos y refactorizaciones seguras. La lección práctica no es “seguir a una persona”, sino “construir un flujo donde el trabajo común sea rápido y los errores se muestren temprano”.
¿Cómo ayudan realmente los tipos estáticos a que un equipo avance más rápido (y no más lento)?
Los tipos estáticos convierten suposiciones implícitas en contratos verificables. Esto ayuda especialmente cuando muchas personas tocan el mismo código:
- Las APIs comunican intención mediante tipos en lugar de conocimiento tribal.
- Los cambios que rompen aparecen en tiempo de compilación, no en producción.
- Las refactorizaciones (renombrar/cambiar firma) generan una lista concreta de actualizaciones necesarias.
¿Cuál es la diferencia práctica entre errores en tiempo de compilación y bugs en tiempo de ejecución?
Los chequeos en tiempo de compilación fallan temprano —a menudo mientras escribes o antes de hacer merge—, así que arreglas los problemas con el contexto fresco. Los fallos en tiempo de ejecución aparecen después (QA/producción) y cuestan más: reproducir, interrumpir usuarios y parchear de emergencia.
Una regla práctica: usa tipos para evitar errores "esto nunca debió compilar" y usa tests para validar el comportamiento en tiempo de ejecución y las reglas de negocio.
¿Por qué se considera a TypeScript “gradual” y por qué eso importa para la adopción?
TypeScript está diseñado para una adopción incremental en código JavaScript existente:
- Tipado gradual: puedes mezclar código tipado y no tipado.
- Inferencia: a menudo obtienes tipos útiles sin escribir muchas anotaciones.
- Tipado estructural: la compatibilidad se basa en la forma del objeto, lo que encaja con patrones JS.
Una estrategia común de migración es convertir archivo por archivo y endurecer la configuración de tsconfig con el tiempo.
¿Qué características de C# mejoran más directamente la mantenibilidad en soluciones grandes?
C# hace que la forma “normal” de escribir código sea también la más legible y segura a escala:
- Anotaciones de nulabilidad que comunican si un valor puede ser
null. async/awaitque mantiene los flujos asíncronos legibles.- Refactorizaciones impulsadas por el IDE y análisis a nivel de solución que hacen los grandes cambios más seguros.
El resultado: menos dependencia de convenciones personales y más consistencia impuesta por las herramientas.
¿Qué son los “servicios de lenguaje” y por qué importan más que el resaltado de sintaxis?
Los servicios de lenguaje son las funciones del editor impulsadas por una comprensión semántica del código (no solo texto). Suelen incluir:
- Autocompletado basado en tipos reales
- Ir a la definición
- Encontrar todas las referencias
- Renombrado/movimiento seguro
- Diagnósticos en línea y correcciones rápidas
En TypeScript esto lo impulsa el compilador + el language service; en C#, la infraestructura de compilador/análisis más la integración del IDE.
¿Cómo refactorizas con seguridad cuando un repo es demasiado grande para “simplemente buscar”?
Usa refactorización semántica (respaldada por IDE/compilador), no buscar y reemplazar. Las buenas refactorizaciones se apoyan en entender ámbitos, sobrecargas, resolución de módulos e identidad de símbolos.
Hábitos prácticos:
- Prefiere “Renombrar símbolo” y “Cambiar firma”.
- Activa la comprobación de tipos/rigidez en las áreas que refactorizas más.
- Mantén los cambios pequeños y deja que el compilador enumere los sitios afectados.
¿Cuáles son formas prácticas de mantener rápidos los builds, el CI y la retroalimentación del editor a medida que la base de código crece?
Trata la velocidad como una métrica de producto y optimiza el bucle de retroalimentación:
- Establece presupuestos (p. ej.: build local < X min, acciones clave del editor < Y ms, CI < Z minutos).
- Usa compilación incremental/caching cuando sea posible.
- Ejecuta tests dirigidos por defecto; deja la suite completa para gates/ejecuciones nocturnas.
- Arregla el lag del editor con prioridad: si la gente deja de confiar en renombrar/encontrar-referencias, la refactorización se detiene.
El objetivo es mantener el ciclo editar → comprobar → corregir lo suficientemente apretado para que la gente confíe al hacer cambios.