26 dic 2025·8 min
Herramientas internas para desarrolladores con Claude Code: paneles CLI seguros
Construye herramientas internas con Claude Code para resolver búsquedas de logs, banderas de funciones y comprobaciones de datos aplicando el principio de menor privilegio y límites claros.
Qué problema debe resolver realmente tu herramienta interna
Las herramientas internas suelen nacer como un atajo: un comando o una página que ahorra 20 minutos al equipo durante un incidente. El riesgo es que ese mismo atajo se convierta en una puerta trasera privilegiada si no defines el problema y los límites desde el principio.
Los equipos suelen recurrir a una herramienta cuando el mismo dolor se repite cada día, por ejemplo:
- Búsquedas de logs lentas, inconsistentes o repartidas entre varios sistemas
- Banderas de funciones que requieren una edición manual arriesgada o una escritura directa en la base de datos
- Comprobaciones de datos que dependen de que una persona ejecute un script desde su portátil
- Tareas de on-call que son sencillas, pero fáciles de estropear a las 2 a.m.
Estos problemas parecen pequeños hasta que la herramienta puede leer logs de producción, consultar datos de clientes o cambiar una bandera. Entonces entras en temas de control de accesos, registros de auditoría y escrituras accidentales. Una herramienta “solo para ingenieros” puede provocar una caída si ejecuta una consulta amplia, apunta al entorno equivocado o cambia el estado sin un paso de confirmación claro.
Define el éxito en términos estrechos y medibles: operaciones más rápidas sin ampliar permisos. Una buena herramienta interna elimina pasos, no salvaguardas. En lugar de dar acceso amplio a la base de datos para que cualquiera compruebe un posible problema de facturación, construye una herramienta que responda a una sola pregunta: “Muestra los eventos de facturación fallidos de hoy para la cuenta X”, usando credenciales de solo lectura y con alcance limitado.
Antes de elegir una interfaz, decide qué necesita la gente en el momento. Un CLI es excelente para tareas repetibles durante on-call. Un panel web es mejor cuando los resultados necesitan contexto y visibilidad compartida. A veces se entregan ambos, pero solo si son vistas delgadas sobre las mismas operaciones protegidas. El objetivo es una capacidad bien definida, no una nueva superficie de administración.
Elige un único dolor y mantén el alcance pequeño
La manera más rápida de que una herramienta interna sea útil (y segura) es elegir un trabajo claro y hacerlo bien. Si intenta manejar logs, banderas de funciones, arreglos de datos y gestión de usuarios desde el día uno, crecerá con comportamientos ocultos y sorprenderá a la gente.
Empieza por una sola pregunta que un usuario haga en el trabajo real. Por ejemplo: “Dado un request ID, muéstrame el error y las líneas alrededor a través de servicios.” Eso es estrecho, comprobable y fácil de explicar.
Sé explícito sobre para quién es la herramienta. Un desarrollador depurando localmente necesita opciones diferentes a alguien on-call, y ambos difieren de soporte o un analista. Cuando mezclas audiencias, acabas añadiendo comandos “potentes” que la mayoría de usuarios nunca debería tocar.
Escribe entradas y salidas como un pequeño contrato.
Las entradas deben ser explícitas: request ID, rango de tiempo, entorno. Las salidas deben ser previsibles: líneas coincidentes, nombre del servicio, sello de tiempo, conteo. Evita efectos secundarios ocultos como “además borra la caché” o “además reintenta el job”. Esas son las características que causan accidentes.
Por defecto, usa solo lectura. Aún puedes hacer la herramienta valiosa con búsqueda, diff, validación e informes. Añade acciones de escritura solo cuando puedas nombrar un escenario real que las necesite y puedas constreñirlas fuertemente.
Una declaración de alcance simple que mantiene al equipo honesto:
- Una tarea principal, una pantalla o comando principal
- Una fuente de datos (o una vista lógica), no “todo”
- Flags explícitos para entorno y rango de tiempo
- Primero solo lectura, sin acciones en segundo plano
- Si existen escrituras, requerir confirmación y registrar cada cambio
Mapea fuentes de datos y operaciones sensibles temprano
Antes de que Claude Code escriba nada, anota qué tocará la herramienta. La mayoría de problemas de seguridad y fiabilidad aparecen aquí, no en la interfaz. Trata este mapeo como un contrato: dice a los revisores qué está dentro del alcance y qué queda fuera.
Empieza con un inventario concreto de fuentes de datos y responsables. Por ejemplo: logs (app, gateway, auth) y dónde se almacenan; las tablas o vistas exactas de la base de datos que la herramienta podrá consultar; tu almacén de banderas de funciones y reglas de nomenclatura; métricas y trazas y qué etiquetas son seguras para filtrar; y si planeas escribir notas en sistemas de tickets o de incidentes.
Luego nombra las operaciones que la herramienta puede ejecutar. Evita “admin” como permiso. En su lugar, define verbos auditables. Ejemplos comunes incluyen: búsqueda y exportación de solo lectura (con límites), anotar (añadir una nota sin editar el historial), alternar banderas específicas con TTL, backfills acotados (rango de fechas y conteo de registros), y modos dry-run que muestran el impacto sin cambiar datos.
Los campos sensibles necesitan manejo explícito. Decide qué debe ser enmascarado (emails, tokens, IDs de sesión, claves API, identificadores de clientes) y qué puede mostrarse solo de forma truncada. Por ejemplo: mostrar los últimos 4 caracteres de un ID, o hashearlo de forma consistente para que las personas puedan correlacionar eventos sin ver el valor en bruto.
Finalmente, acuerda reglas de retención y auditoría. Si un usuario ejecuta una consulta o cambia una bandera, registra quién lo hizo, cuándo, qué filtros se usaron y el conteo de resultados. Mantén los logs de auditoría más tiempo que los logs de aplicación. Incluso una regla simple como “consultas retenidas 30 días, registros de auditoría 1 año” evita debates dolorosos durante un incidente.
Modelo de acceso de menor privilegio que se mantenga simple
El principio de menor privilegio es más fácil cuando mantienes el modelo aburrido. Empieza por listar lo que la herramienta puede hacer, y luego etiqueta cada acción como solo lectura o escritura. La mayoría de herramientas internas solo necesitan acceso de lectura para la mayoría de la gente.
Para un panel web, usa tu sistema de identidad existente (SSO con OAuth). Evita contraseñas locales. Para un CLI, prefiere tokens de corta duración que expiren rápido y delimítalos solo a las acciones que el usuario necesita. Los tokens compartidos de larga duración tienden a pegarse en tickets, guardarse en el historial del shell o copiarse a máquinas personales.
Mantén el RBAC pequeño. Si necesitas más de unos pocos roles, probablemente la herramienta está haciendo demasiado. Muchos equipos van bien con tres:
- Viewer: solo lectura, valores seguros por defecto
- Operator: lectura más un pequeño conjunto de acciones de bajo riesgo
- Admin: acciones de alto riesgo, usado raramente
Separa entornos desde temprano, aunque la interfaz se vea igual. Haz difícil “hacer prod por accidente”. Usa credenciales diferentes por entorno, archivos de configuración distintos y endpoints API diferentes. Si un usuario solo da soporte a staging, no debería poder autenticarse contra producción.
Las acciones de alto riesgo merecen un paso de aprobación. Piensa en borrar datos, cambiar banderas, reiniciar servicios o ejecutar consultas pesadas. Añade una comprobación de segunda persona cuando el radio de impacto sea grande. Patrones prácticos incluyen confirmaciones tipeadas que incluyan el objetivo (nombre del servicio y entorno), registrar quién solicitó y quién aprobó, y añadir un breve retraso o ventana programada para las operaciones más peligrosas.
Si generas la herramienta con Claude Code, conviértelo en regla: que cada endpoint y comando declare su rol requerido desde el principio. Ese hábito mantiene las revisiones de permisos manejables a medida que la herramienta crece.
Guardrails que previenen accidentes y consultas dañinas
Build the first safe tool
Turn your scoped CLI or dashboard spec into working code through a simple chat.
El modo de falla más común para herramientas internas no es un atacante. Es un compañero cansado ejecutando el “comando correcto” con los inputs equivocados. Trata los guardrails como características del producto, no como detalles estéticos.
Defectos de seguridad por defecto
Empieza con una postura segura: solo lectura por defecto. Incluso si el usuario es admin, la herramienta debería abrir en un modo que solo pueda obtener datos. Haz que las acciones de escritura sean opt-in y obvias.
Para cualquier operación que cambie estado (alternar una bandera, backfill, borrar un registro), exige una confirmación tipeada explícita. “¿Estás seguro? y/N” es demasiado fácil de ejecutar por hábito. Pide al usuario que reescriba algo específico, como el nombre del entorno más el ID objetivo.
La validación estricta de entradas previene la mayoría de desastres. Acepta solo las formas que realmente soportas (IDs, fechas, entornos) y rechaza todo lo demás temprano. Para búsquedas, limita la potencia: impón límites de resultados, aplica rangos de fecha sensatos y usa una estrategia de allow-list en lugar de permitir patrones arbitrarios contra tu almacenamiento de logs.
Para evitar consultas descontroladas, añade timeouts y límites de tasa. Una herramienta segura falla rápido y explica por qué, en lugar de colgarse y golpear tu base de datos.
Un conjunto de guardrails que funciona bien en la práctica:
- Por defecto solo lectura, con un interruptor claro de “modo escritura”
- Confirmación tipeada para escrituras (incluye entorno + objetivo)
- Validación estricta para IDs, fechas, límites y patrones permitidos
- Timeouts de consulta más límites por usuario
- Enmascarado de secretos en la salida y en los propios logs de la herramienta
Higiene de salida
Asume que la salida de la herramienta se copiará en tickets y chats. Enmascara secretos por defecto (tokens, cookies, claves API y correos si es necesario). También depura lo que almacenas: los logs de auditoría deberían registrar lo que se intentó, no los datos en bruto devueltos.
Para un dashboard de búsqueda de logs, devuelve una vista previa corta y un conteo, no cargas completas. Si alguien realmente necesita el evento completo, haz que sea una acción separada, claramente protegida y con su propia confirmación.
Cómo trabajar con Claude Code sin perder el control
Trata a Claude Code como un compañero junior rápido: útil, pero no adivina intenciones. Tu trabajo es mantener el trabajo acotado, revisable y fácil de deshacer. Esa es la diferencia entre herramientas que se sienten seguras y herramientas que te sorprenden a las 2 a.m.
Empieza con una especificación que el modelo pueda seguir
Antes de pedir código, escribe una pequeña especificación que nombre la acción del usuario y el resultado esperado. Céntrate en comportamiento, no en detalles de frameworks. Una buena spec suele caber en media página y cubre:
- Comandos o pantallas (nombres exactos)
- Entradas (flags, campos, formatos, límites)
- Salidas (qué aparece, qué se guarda)
- Casos de error (entrada inválida, timeouts, resultados vacíos)
- Chequeos de permisos (qué ocurre si se deniega el acceso)
Por ejemplo, si construyes un CLI de búsqueda de logs, define un solo comando de extremo a extremo: logs search --service api --since 30m --text "timeout", con un tope duro en resultados y un mensaje claro de “sin acceso”.
Pide incrementos pequeños que puedas verificar
Solicita primero un esqueleto: wiring del CLI, carga de configuración y una llamada de datos stub. Luego pide exactamente una característica terminada por completo (incluyendo validación y errores). Diffs pequeños hacen que las revisiones sean reales.
Tras cada cambio, pide una explicación en lenguaje plano de qué cambió y por qué. Si la explicación no coincide con el diff, para y reexpón el comportamiento y las restricciones de seguridad.
Genera tests temprano, antes de añadir más características. Como mínimo, cubre la ruta feliz, entradas inválidas (fechas malas, flags faltantes), permiso denegado, resultados vacíos y timeouts o límites del backend.
CLI vs panel web: elegir la interfaz correcta
Un CLI y un panel web interno pueden resolver el mismo problema, pero fallan de maneras distintas. Elige la interfaz que haga que la ruta segura sea la más fácil.
Un CLI suele ser mejor cuando la velocidad importa y el usuario ya sabe lo que quiere. También encaja bien con flujos de solo lectura, porque puedes mantener permisos estrechos y evitar botones que disparen acciones de escritura por accidente.
Un CLI es una buena opción para consultas rápidas on-call, scripts y automatización, pistas de auditoría explícitas (cada comando queda escrito) y despliegue de bajo overhead (un binario, un config).
Un panel web es mejor cuando necesitas visibilidad compartida o pasos guiados. Puede reducir errores al orientar a las personas hacia valores seguros por defecto como rangos de tiempo, entornos y acciones preaprobadas. Los dashboards también funcionan bien para vistas de estado de equipo, acciones protegidas que requieren confirmación y explicaciones incorporadas de lo que hace cada botón.
Cuando sea posible, usa el mismo API backend para ambos. Pon autenticación, límites de tasa, límites de consulta y logging de auditoría en ese API, no en la UI. Entonces el CLI y el dashboard serán clientes distintos con ergonomías diferentes.
También decide dónde se ejecuta, porque eso cambia el riesgo. Un CLI en un portátil puede filtrar tokens. Ejecutarlo en un bastión o en un clúster interno puede reducir la exposición y facilitar logs y aplicación de políticas.
Ejemplo: para búsqueda de logs, un CLI es ideal para un ingeniero on-call que extrae los últimos 10 minutos de un servicio. Un dashboard es mejor para una sala de incidentes compartida donde todos necesitan la misma vista filtrada, más una acción guiada de “exportar para postmortem” que esté verificada por permisos.
Un ejemplo realista: herramienta de búsqueda de logs para on-call
Go from dev to deployed
Deploy and host your internal tool when you are ready to share it with the team.
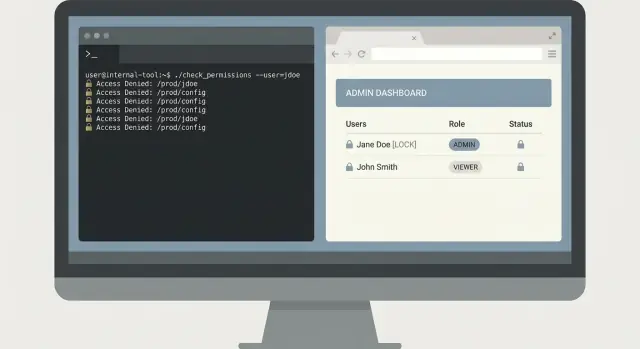
Son las 02:10 y el on-call recibe un informe: “Hacer clic en Pagar a veces falla para un cliente.” Soporte tiene una captura con un request ID, pero nadie quiere pegar consultas aleatorias en el sistema de logs con permisos de admin.
Un CLI pequeño puede resolver esto de forma segura. La clave es mantenerlo estrecho: encontrar el error rápido, mostrar solo lo necesario y no cambiar datos de producción.
Un flujo CLI mínimo
Empieza con un comando que fuerce límites de tiempo y un identificador específico. Requiere un request ID y una ventana de tiempo, y por defecto usa una ventana corta.
oncall-logs search --request-id req_123 --since 30m --until now
Devuelve primero un resumen: nombre del servicio, clase de error, conteo y los 3 mensajes coincidentes principales. Luego permite un paso explícito de expansión que imprima líneas de log completas solo cuando el usuario lo pida.
oncall-logs show --request-id req_123 --limit 20
Este diseño en dos pasos evita volcados accidentales de datos. También facilita las revisiones porque la herramienta tiene un camino claro y seguro por defecto.
Acción de seguimiento opcional (sin escrituras)
On-call a menudo necesita dejar rastro para la siguiente persona. En lugar de escribir en la base de datos, añade una acción opcional que cree la carga de nota para un ticket o aplique una etiqueta en el sistema de incidentes, pero nunca toque registros de clientes.
Para mantener el mínimo privilegio, el CLI debe usar un token de solo lectura para logs y un token separado y acotado para la acción de ticket o etiqueta.
Guarda un registro de auditoría por cada ejecución: quién lo ejecutó, qué request ID, qué límites de tiempo se usaron y si expandieron detalles. Ese log de auditoría es tu red de seguridad cuando algo sale mal o cuando hace falta revisar accesos.
Errores comunes que crean problemas de seguridad y fiabilidad
Las herramientas internas pequeñas suelen empezar como “un ayudante rápido”. Por eso acaban con valores predeterminados arriesgados. La manera más rápida de perder confianza es un incidente malo, como una herramienta que borra datos cuando debía ser de solo lectura.
Los errores que aparecen con más frecuencia:
- Dar a la herramienta acceso de escritura a la base de datos de producción cuando solo necesita lecturas, y luego asumir “seremos cuidadosos”
- Saltarse una traza de auditoría, de modo que luego no puedas saber quién ejecutó un comando, qué inputs usó y qué cambió
- Permitir SQL libre, regex o filtros ad hoc que escanean tablas o logs enormes y tiran sistemas abajo
- Mezclar entornos de modo que acciones en staging puedan alcanzar producción porque configs, tokens o URLs base se comparten
- Imprimir secretos en terminal, consola del navegador o logs, y luego olvidar que esas salidas se copian en tickets y chats
Un fallo realista se ve así: un ingeniero on-call usa un CLI de búsqueda de logs durante un incidente. La herramienta acepta cualquier regex y la envía al backend de logs. Un patrón caro recorre horas de logs de alto volumen, dispara costes y ralentiza búsquedas para todos. En la misma sesión, el CLI imprime un token API en salida de debug, y termina pegado en un doc público del incidente.
Valores seguros que previenen la mayoría de incidentes
Trata la lectura como un límite de seguridad real, no una costumbre. Usa credenciales separadas por entorno y cuentas de servicio separadas por herramienta.
Unos pocos guardrails hacen la mayor parte del trabajo:
- Usa consultas permitidas (o plantillas) en lugar de SQL crudo, y limita rangos de tiempo y conteo de filas
- Registra cada acción con un request ID, la identidad del usuario, el entorno objetivo y los parámetros exactos
- Requiere selección explícita de entorno, con una confirmación alta para producción
- Redacta secretos por defecto y desactiva la salida de debug salvo que se use un flag privilegiado
Si la herramienta no puede hacer algo peligroso por diseño, el equipo no tendrá que confiar en atención perfecta a las 3 a.m.
Lista rápida antes de lanzar la herramienta
Keep your tool reviewable
Get the full source code so your team can review and own every change.
Antes de que tu herramienta interna llegue a usuarios reales (especialmente on-call), trátala como un sistema de producción. Confirma que accesos, permisos y límites de seguridad son reales, no implícitos.
Empieza por acceso y permisos. Muchos accidentes ocurren porque el acceso “temporal” se vuelve permanente, o porque una herramienta gana silenciosamente poder de escritura con el tiempo.
- Auth y offboarding: confirma quién puede iniciar sesión, cómo se concede acceso y cómo se revoca el mismo día que alguien cambia de equipo
- Roles pequeños: mantiene 2-3 roles máximo (viewer, operator, admin) y escribe qué puede hacer cada rol
- Solo lectura por defecto: haz que ver sea el camino por defecto y requiere un rol explícito para cualquier cambio de datos
- Manejo de secretos: almacena tokens y claves fuera del repo y verifica que la herramienta nunca los imprima en logs o mensajes de error
- Flujo de emergencia: si necesitas acceso de emergencia, hazlo limitado en el tiempo y registrado
Luego valida guardrails que prevengan errores comunes:
- Confirmaciones para acciones riesgosas: exige confirmaciones tipeadas para borrados, backfills o cambios de configuración
- Límites y timeouts: limita tamaño de resultados, aplica ventanas de tiempo y timeouts para que una mala petición no pueda ejecutarse indefinidamente
- Validación de entradas: valida IDs, fechas y nombres de entornos; rechaza cualquier entrada que parezca “ejecutar en todas partes”
- Logs de auditoría: registra quién hizo qué, cuándo y desde dónde; haz que los logs sean fáciles de buscar durante incidentes
- Métricas y errores básicos: mide tasa de éxito, latencia y tipos de error principales para detectar fallos pronto
Haz control de cambios como para cualquier servicio: revisión por pares, unas pocas pruebas enfocadas en rutas peligrosas y un plan de rollback (incluyendo una forma de deshabilitar la herramienta rápido si se comporta mal).
Próximos pasos: desplegar con seguridad y mejorar continuamente
Trata el primer lanzamiento como un experimento controlado. Empieza con un equipo, un flujo de trabajo y un conjunto pequeño de tareas reales. Una herramienta de búsqueda de logs para on-call es un buen piloto porque puedes medir tiempo ahorrado y detectar consultas riesgosas rápido.
Mantén el despliegue predecible: piloto con 3 a 10 usuarios, empieza en staging, limita acceso con roles de menor privilegio (no tokens compartidos), fija límites de uso y registra logs de auditoría para cada comando o clic. Asegúrate de poder revertir configuraciones y permisos rápidamente.
Escribe el contrato de la herramienta en lenguaje claro. Lista cada comando (o acción del dashboard), los parámetros permitidos, qué significa el éxito y qué significan los errores. La gente deja de confiar en herramientas internas cuando las salidas son ambiguas, aunque el código sea correcto.
Añade un bucle de feedback que realmente revises. Mide qué consultas son lentas, qué filtros son comunes y qué opciones confunden a la gente. Cuando ves soluciones alternativas repetidas, suele ser señal de que la interfaz falta un valor seguro por defecto.
El mantenimiento necesita un responsable y un calendario. Decide quién actualiza dependencias, quién rota credenciales y quién se alarma si la herramienta falla en un incidente. Revisa los cambios generados por IA como lo harías con un servicio de producción: diffs de permisos, seguridad de consultas y logging.
Si tu equipo prefiere la iteración impulsada por chat, Koder.ai puede ser una forma práctica de generar un pequeño CLI o dashboard desde una conversación, mantener snapshots de estados conocidos y revertir rápido cuando un cambio introduce riesgo.