15 jun 2025·8 min
Permitir que la IA diseñe esquemas, APIs y modelos de datos del backend
Explora cómo los esquemas y APIs generados por IA aceleran la entrega, dónde fallan y un flujo práctico para revisar, probar y gobernar el diseño del backend.
Explora cómo los esquemas y APIs generados por IA aceleran la entrega, dónde fallan y un flujo práctico para revisar, probar y gobernar el diseño del backend.
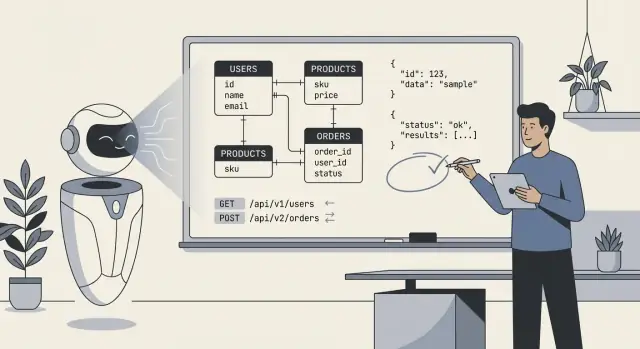
Cuando la gente dice “la IA diseñó nuestro backend”, por lo general quieren decir que el modelo produjo un primer borrador del plano técnico: tablas de base de datos (o colecciones), cómo se relacionan esas piezas y las APIs que leen y escriben datos. En la práctica, es menos “la IA lo construyó todo” y más “la IA propuso una estructura que podemos implementar y refinar”.
Como mínimo, la IA puede generar:
users, orders, subscriptions, además de campos y tipos básicos.La IA puede inferir patrones “típicos”, pero no puede escoger con fiabilidad el modelo correcto cuando los requisitos son ambiguos o específicos del dominio. No sabrá tus políticas reales sobre:
cancelled vs refunded vs voided).Trata la salida de la IA como un punto de partida rápido y estructurado—útil para explorar opciones y detectar omisiones—pero no como una especificación que puedas lanzar tal cual. Tu trabajo es proporcionar reglas claras y casos límite, y luego revisar lo que la IA produjo como revisarías el primer borrador de un ingeniero junior: útil, a veces impresionante, y ocasionalmente equivocado en matices.
La IA puede redactar un esquema o una API con rapidez, pero no puede inventar los hechos faltantes que hacen que un backend “encaje” con tu producto. Los mejores resultados se obtienen cuando tratas a la IA como un diseñador junior rápido: tú aportas restricciones claras y ella propone opciones.
Antes de pedir tablas, endpoints o modelos, escribe lo esencial:
Cuando los requisitos son difusos, la IA tiende a “adivinar” valores por defecto: campos opcionales por todas partes, columnas de estado genéricas, propiedad poco clara y nombres inconsistentes. Eso suele generar esquemas que parecen razonables pero fallan con el uso real—especialmente en permisos, reporting y casos límite (reembolsos, cancelaciones, envíos parciales, aprobaciones en varios pasos). Pagarás por eso después con migraciones, soluciones alternativas y APIs confusas.
Usa esto como punto de partida y pégalo en tu prompt:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles \u0026 permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
La IA rinde mejor cuando la tratas como una máquina de primeros borradores: puede bosquejar un modelo de datos de primera pasada y un conjunto de endpoints aparentes en minutos. Esa velocidad cambia tu forma de trabajar—no porque la salida sea mágicamente “correcta”, sino porque puedes iterar sobre algo concreto enseguida.
La mayor ganancia es eliminar el arranque en frío. Dale a la IA una breve descripción de entidades, flujos clave y restricciones, y puede proponer tablas/colecciones, relaciones y una superficie API base. Esto es especialmente valioso cuando necesitas demo rápido o exploras requisitos que aún no están estables.
La velocidad rinde más en:
Los humanos se cansan y se desvían. La IA no—por eso es buena repitiendo convenciones en todo el backend:
createdAt, updatedAt, customerId)/resources, /resources/:id) y payloads coherentesEsa consistencia facilita documentar, probar y traspasar el backend a otro desarrollador.
La IA también es buena completando la superficie. Si pides un CRUD completo más operaciones comunes (búsqueda, listado, actualizaciones masivas), normalmente generará un área de inicio más completa que un borrador humano apresurado.
Un triunfo habitual es estandarizar errores: un sobre de error uniforme (code, message, details) en todos los endpoints. Aunque lo refines después, tener una forma única desde el inicio evita mezclar respuestas ad-hoc.
La mentalidad clave: deja que la IA genere el primer 80% rápido y dedica tu tiempo al 20% que requiere juicio—reglas de negocio, casos límite y el “porqué” detrás del modelo.
Los esquemas generados por IA suelen verse “limpios” a primera vista: tablas ordenadas, nombres sensatos y relaciones que encajan con el camino feliz. Los problemas aparecen cuando datos reales, usuarios reales y flujos reales impactan el sistema.
La IA puede oscilar entre extremos:
Una prueba rápida: si tus páginas más comunes necesitan 6+ joins, puede que estés sobre-normalizando; si las actualizaciones requieren cambiar el mismo valor en muchas filas, puede que estés infra-normalizando.
La IA frecuentemente omite requisitos “aburridos” que definen realmente el diseño del backend:
tenant_id en tablas o no aplicar scope de tenant en restricciones únicas.deleted_at pero no actualizar reglas de unicidad o patrones de consulta para excluir registros borrados.created_by/updated_by, historial de cambios o registros de eventos inmutables.date y timestamp sin regla clara (almacenamiento UTC vs visualización local), causando errores de ±1 día.La IA puede suponer:
Estos errores suelen derivar en migraciones incómodas y soluciones en la capa de aplicación.
La mayoría de esquemas generados no reflejan cómo vas a consultar:
tenant_id + created_at),Si el modelo no puede describir las 5 consultas principales de tu app, no puede diseñar el esquema para ellas con fiabilidad.
La IA suele ser sorprendentemente buena generando una API que “parece estándar”. Imitará patrones familiares de frameworks y APIs públicas, lo que ahorra tiempo. El riesgo es que optimice por lo que parece plausible en lugar de por lo correcto para tu producto, tu modelo de datos y tus cambios futuros.
Fundamentos de modelado de recursos. Con un dominio claro, la IA tiende a escoger sustantivos y estructuras URL sensatas (p. ej., /customers, /orders/{id}, /orders/{id}/items). También repite convenciones de nombres coherentes en endpoints.
Andamiaje común de endpoints. Frecuentemente incluye lo esencial: endpoints de lista vs detalle, create/update/delete y formas previsibles de request/response.
Convenciones base. Si lo pides explícitamente, puede estandarizar paginación, filtrado y ordenación. Por ejemplo: ?limit=50&cursor=... (paginación por cursor) o ?page=2&pageSize=25 (paginación por páginas), además de ?sort=-createdAt y filtros como ?status=active.
Abstracciones filtradas. Un fallo clásico es exponer tablas internas directamente como “recursos”, especialmente cuando el esquema tiene tablas de join, campos denormalizados o columnas de auditoría. Terminas con endpoints como /user_role_assignments que reflejan detalles de implementación en lugar del concepto para el usuario (“roles de un usuario”). Esto dificulta el uso de la API y su evolución.
Manejo de errores inconsistente. La IA puede mezclar estilos: a veces devolver 200 con un body de error, otras usar 4xx/5xx. Quieres un contrato claro:
400, 401, 403, 404, 409, 422){ "error": { "code": "...", "message": "...", "details": [...] } })Versionado como pensamiento tardío. Muchos diseños generados pasan por alto una estrategia de versionado hasta que duele. Decide desde el día uno si usarás versionado en la ruta (/v1/...) o por cabeceras, y define qué constituye un cambio incompatible. Aunque nunca actualices la versión, tener las reglas evita rupturas accidentales.
Usa la IA por velocidad y consistencia, pero trata el diseño de API como una interfaz de producto. Si un endpoint refleja tu base de datos en lugar de la mentalidad del usuario, es señal de que la IA optimizó para generar fácilmente en lugar de diseñar para usabilidad a largo plazo.
Trata la IA como un diseñador junior rápido: excelente generando borradores, no responsable del sistema final. El objetivo es aprovechar su velocidad manteniendo la arquitectura intencional, revisable y con pruebas.
Si usas una herramienta de vibe-coding como Koder.ai, esta separación de responsabilidades es aún más importante: la plataforma puede esbozar e implementar rápidamente un backend (por ejemplo, servicios en Go con PostgreSQL), pero tú debes definir las invariantes, los límites de autorización y las reglas de migración que estás dispuesto a aceptar.
Empieza con un prompt claro que describa el dominio, las restricciones y “qué significa el éxito”. Pide primero un modelo conceptual (entidades, relaciones, invariantes), no tablas.
Luego itera en un bucle fijo:
Este bucle funciona porque convierte las "sugerencias de la IA" en artefactos que se pueden probar o rechazar.
Mantén tres capas distintas:
Pide a la IA que los emita como secciones separadas. Cuando algo cambie (por ejemplo, un nuevo estado o regla), actualiza primero la capa conceptual y luego reconcilia esquema y API. Así reduces el acoplamiento accidental y facilitas los refactors.
Cada iteración debe dejar rastro. Usa resúmenes estilo ADR (una página o menos) que capturen:
deleted_at”).Cuando pegues feedback a la IA, incluye las notas de decisión relevantes textualmente. Eso evita que el modelo “olvide” elecciones previas y ayuda a tu equipo a entender el backend meses después.
La IA se gobierna mejor cuando tratas el prompting como un ejercicio de redacción de especificaciones: define el dominio, expón las restricciones e insiste en salidas concretas (DDL, tablas de endpoints, ejemplos). El objetivo no es “ser creativo”, sino “ser preciso”.
Pide un modelo de datos y las reglas que lo mantienen consistente.
Si ya tienes convenciones, indícalas: estilo de nombres, tipo de ID (UUID vs bigint), política de nullable e expectativas de indexado.
Solicita una tabla de API con contratos explícitos, no solo una lista de rutas.
Agrega comportamiento de negocio: estilo de paginación, campos de ordenación y cómo funcionan los filtros.
Haz que el modelo piense en releases.
billing_address a Customer. Proporciona un plan de migración seguro: SQL de forward migration, pasos de backfill, despliegue con feature flag y estrategia de rollback. La API debe ser compatible durante 30 días; clientes antiguos pueden omitir el campo.”Los prompts vagos producen sistemas vagos.
Cuando quieras mejor salida, aprieta el prompt: especifica las reglas, los casos límite y el formato de entrega.
La IA puede esbozar un backend decente, pero lanzarlo de forma segura aún necesita un pase humano. Trata esta checklist como una “puerta de liberación”: si no puedes responder con confianza, pausa y arregla antes de que sean datos de producción.
(tenant_id, slug))._id, timestamps) y aplícalas uniformemente.Confirma las reglas del sistema por escrito:
Antes de mergear, realiza una revisión rápida “camino feliz + peor camino”: una petición normal, una inválida, una no autorizada y un escenario de alto volumen. Si el comportamiento de la API te sorprende, también sorprenderá a tus usuarios.
La IA puede generar un esquema plausible y una superficie API rápidamente, pero no puede probar que el backend se comporte bien bajo tráfico real, datos reales y cambios futuros. Trata la salida de la IA como un borrador y ancla con tests que fijen el comportamiento.
Empieza con tests de contrato que validen requests, responses y semántica de errores—no solo los caminos felices. Ejecuta una pequeña suite contra una instancia real (o contenedor) del servicio.
Céntrate en:
Si publicas un spec OpenAPI, genera tests desde él—pero añade casos escritos a mano para las partes complejas que el spec no puede expresar (reglas de autorización, restricciones de negocio).
Los esquemas generados por IA suelen olvidar detalles operativos: valores por defecto seguros, backfills y reversibilidad. Añade tests de migración que:
Mantén un plan de rollback scriptado para producción: qué hacer si una migración es lenta, bloquea tablas o rompe compatibilidad.
No midas endpoints genéricos. Captura patrones representativos (vistas de lista principales, búsqueda, joins, agregaciones) y súmetelos a pruebas de carga.
Mide:
Aquí suelen fallar los diseños de IA: tablas “razonables” que producen joins caros bajo carga.
Añade checks automatizados para:
Incluso pruebas básicas de seguridad evitan los errores más costosos de la IA: endpoints que funcionan pero exponen demasiado.
La IA puede trazar un buen esquema “versión 0”, pero tu backend vivirá hasta la versión 50. La diferencia entre un backend que envejece bien y uno que colapsa con cambios es cómo evolucionas: migraciones, refactors controlados y documentación clara de intenciones.
Trata cada cambio de esquema como una migración, incluso si la IA sugiere “alter table”. Usa pasos explícitos y reversibles: añade columnas nuevas primero, backfill, y luego endurece restricciones. Prefiere cambios aditivos (nuevos campos, nuevas tablas) sobre destructivos (rename/drop) hasta que pruebes que nada depende de la forma antigua.
Cuando pidas a la IA actualizaciones de esquema, incluye el esquema actual y las reglas de migración que sigues (por ejemplo: “no borrar columnas; usar expand/contract”). Así reduces la probabilidad de que proponga un cambio correcto en teoría pero arriesgado en producción.
Los cambios rompientes raramente son un único momento; son una transición.
La IA ayuda a generar el plan paso a paso (incluyendo snippets SQL y orden de despliegue), pero valida el impacto en tiempo de ejecución: locks, transacciones largas y si el backfill es reanudable.
Los refactors deben aislar el cambio. Si necesitas normalizar, dividir una tabla o introducir un log de eventos, conserva capas de compatibilidad: views, código de traducción o tablas “shadow”. Pide a la IA un refactor que preserve contratos API existentes y que liste qué debe cambiar en queries, índices y restricciones.
La mayoría de la deriva a largo plazo sucede porque el siguiente prompt olvida la intención original. Mantén un contrato corto del modelo de datos: reglas de nombres, estrategia de IDs, semántica de timestamps, política de soft-delete e invariantes (“el total de un pedido se deriva, no se almacena”). Enlázalo en docs internos (p. ej., /docs/data-model) y reutilízalo en futuros prompts para que el sistema diseñe dentro de las mismas fronteras.
La IA puede bosquejar tablas y endpoints rápido, pero no “posee” tu riesgo. Trata seguridad y privacidad como requisitos de primera clase que añades al prompt y luego verificas en la revisión—especialmente alrededor de datos sensibles.
Antes de aceptar cualquier esquema, etiqueta campos por sensibilidad (público, interno, confidencial, regulado). Esa clasificación debe guiar qué se cifra, enmascara o minimiza.
Por ejemplo: contraseñas nunca deben almacenarse en texto (solo hashes salteados), tokens deben ser de corta vida y cifrados en reposo, y PII como email/teléfono puede requerir enmascaramiento en vistas de administración y exportaciones. Si un campo no es necesario para el valor del producto, no lo almacenes—la IA suele añadir atributos “agradables de tener” que aumentan la exposición.
Las APIs generadas por IA suelen optar por comprobaciones simples de “roles”. RBAC es fácil de razonar, pero falla con reglas de propiedad (“usuarios solo pueden ver sus facturas”) o reglas contextuales (“soporte puede ver datos solo durante un ticket activo”). ABAC gestiona mejor estos casos, pero requiere políticas explícitas.
Sé claro sobre el patrón que usas y asegúrate de que cada endpoint lo aplique de forma consistente—especialmente list/search, puntos comunes de fuga.
El código generado puede loggear bodies completos de request, cabeceras o filas de BD en errores. Eso puede filtrar contraseñas, tokens de auth y PII en logs y herramientas APM.
Configura defaults como: logs estructurados, whitelist de campos a loggear, redacción de secretos (Authorization, cookies, reset tokens) y evita loggear payloads crudos en fallos de validación.
Diseña para el borrado desde el día uno: borrados iniciados por el usuario, cierre de cuenta y workflows de “derecho al olvido”. Define ventanas de retención por clase de dato (p. ej., eventos de auditoría vs eventos de marketing) y asegúrate de poder demostrar qué se eliminó y cuándo.
Si guardas logs de auditoría, almacena identificadores mínimos, protégelos con acceso más estricto y documenta cómo exportar o eliminar datos cuando sea necesario.
La IA rinde mejor cuando la tratas como un arquitecto junior rápido: excelente en producir un primer borrador, menos fiable tomando decisiones críticas de dominio. La pregunta correcta es menos “¿Puede la IA diseñar mi backend?” y más “¿Qué partes puede la IA diseñar con seguridad y qué partes requieren propiedad experta?”
La IA ahorra tiempo real cuando construyes:
Aquí la IA aporta velocidad, consistencia y cobertura—especialmente cuando ya sabes cómo quieres que se comporte el producto y puedes detectar errores.
Ten precaución (o limita la IA a inspiración) cuando trabajas en:
En estas áreas, la experiencia de dominio pesa más que la velocidad de la IA. Requisitos sutiles—legales, clínicos, contables, operativos—suelen faltar en el prompt y la IA llenará huecos con confianza.
Una regla práctica: deja que la IA proponga opciones, pero exige revisión final para invariantes del modelo de datos, límites de autorización y estrategia de migración. Si no puedes nombrar quién es responsable del esquema y los contratos de API, no despliegues un backend diseñado por IA.
Si evalúas flujos y guardrails, consulta guías relacionadas en /blog. Si quieres ayuda aplicando estas prácticas al proceso de tu equipo, revisa /pricing.
Si prefieres un flujo end-to-end donde iteras por chat, generas una app funcional y sigues manteniendo control vía exportación de código y snapshots con rollback, Koder.ai está diseñado para ese estilo de construcción y revisión.
Suele significar que el modelo generó un primer borrador de:
Un equipo humano aún debe validar las reglas de negocio, los límites de seguridad, el rendimiento de las consultas y la seguridad de las migraciones antes de ponerlo en producción.
Proporciona entradas concretas que la IA no puede adivinar con seguridad:
Cuanto más claras sean las restricciones, menos la IA "rellenará" huecos con valores por defecto frágiles.
Empieza con un modelo conceptual (conceptos de negocio + invariantes), y luego deriva:
Mantener estas capas separadas facilita cambiar el almacenamiento sin romper la API —o revisar la API sin corromper las reglas de negocio.
Los problemas comunes incluyen:
tenant_id y restricciones únicas compuestas)Pide a la IA que diseñe pensando en tus consultas principales y luego verifica:
tenant_id + created_at)Si no puedes enumerar las 5 consultas/endpoints principales, considera incompleto cualquier plan de indexación.
La IA hace bien el esqueleto estándar, pero vigila:
200 con errores, 4xx/5xx inconsistentes)Trata la API como interfaz de producto: modela endpoints según conceptos del usuario, no según detalles de implementación de la base de datos.
Usa un bucle repetible:
Usa códigos de estado HTTP adecuados y una única envoltura de error, por ejemplo:
Prioriza pruebas que aseguren comportamiento:
Los tests son la forma de “poseer” el diseño en vez de heredar suposiciones de la IA.
Usa IA principalmente para borradores cuando los patrones son conocidos (MVPs CRUD, herramientas internas). Ten precaución cuando:
Política práctica: la IA propone opciones, pero los humanos deben validar invariantes del esquema, límites de autorización y la estrategia de despliegue/migración.
deleted_atUn esquema puede parecer “limpio” y aun así fallar con flujos reales y bajo carga.
Así conviertes la salida de la IA en artefactos que puedes probar o rechazar en lugar de confiar en una redacción vaga.
400, 401, 403, 404, 409, 422, 429{"error":{"code":"...","message":"...","details":[]}}
Asegura además que los mensajes de error no filtren información interna (SQL, stack traces, secretos) y que sean consistentes en todos los endpoints.