24 oct 2025·8 min
Por qué la indexación de bases de datos es el mayor impulso de rendimiento
Aprende cómo los índices de base de datos reducen tiempos de consulta, cuándo ayudan (y cuándo perjudican) y pasos prácticos para diseñar, probar y mantener índices en aplicaciones reales.
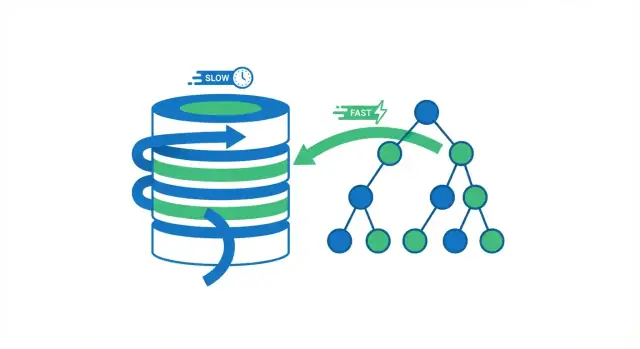
Qué hace realmente la indexación de bases de datos
Un índice de base de datos es una estructura de búsqueda separada que ayuda a la base de datos a encontrar filas más rápido. No es una segunda copia de tu tabla. Piénsalo como las páginas de índice de un libro: usas el índice para saltar cerca del lugar correcto y luego lees la página exacta (fila) que necesitas.
Sin un índice, la base de datos a menudo solo tiene una opción segura: leer muchas filas para comprobar cuáles coinciden con tu consulta. Eso puede estar bien cuando una tabla tiene unos pocos miles de filas. A medida que la tabla crece hasta millones de filas, “comprobar más filas” se convierte en más lecturas de disco, más presión de memoria y más trabajo de CPU: la misma consulta que antes parecía instantánea empieza a ralentizarse.
Qué cambia un índice (y qué no)
Los índices reducen la cantidad de datos que la base de datos debe inspeccionar para responder preguntas como “encuentra la orden con ID 123” o “obtén usuarios con este correo”. En lugar de escanear todo, la base de datos sigue una estructura compacta que estrecha la búsqueda rápidamente.
Pero la indexación no es una solución universal. Algunas consultas todavía necesitan procesar muchas filas (informes amplios, filtros de baja selectividad, agregaciones pesadas). Y los índices tienen costes reales: almacenamiento extra y escrituras más lentas, porque los inserts y updates también deben actualizar el índice.
Qué aprenderás en esta guía
Verás:
- por qué evitar escaneos completos de tabla es la gran ganancia de velocidad
- cómo estructuras comunes de índice (como el B-tree) hacen las búsquedas rápidas
- qué consultas se benefician más y cuándo no lo hacen
- cómo elegir índices compuestos/de cobertura y validarlos con un plan EXPLAIN
- cómo mantener los índices para que el rendimiento no se degrade silenciosamente
La ganancia central de velocidad: evitar escaneos completos
Cuando una base de datos ejecuta una consulta, tiene dos opciones generales: escanear toda la tabla fila por fila, o saltar directamente a las filas que coinciden. La mayoría de las ganancias de indexación vienen de evitar lecturas innecesarias.
Escaneo completo vs. búsqueda por índice
Un escaneo completo de tabla hace exactamente lo que su nombre indica: la base de datos lee cada fila, comprueba si coincide con la condición WHERE y solo entonces devuelve resultados. Eso es aceptable para tablas pequeñas, pero se ralentiza de forma predecible a medida que la tabla crece: más filas significa más trabajo.
Usando un índice, la base de datos a menudo puede evitar leer la mayoría de las filas. En su lugar, consulta primero el índice (una estructura compacta construida para buscar) para encontrar dónde viven las filas coincidentes y luego lee solo esas filas específicas.
Una analogía simple
Piensa en un libro. Si quieres cada página que mencione “fotosíntesis”, podrías leer todo el libro de principio a fin (escaneo completo). O podrías usar el índice, saltar a las páginas listadas y leer solo esas secciones (búsqueda por índice). La segunda forma es más rápida porque te saltas casi todas las páginas.
Por qué menos lecturas suele significar consultas más rápidas
Las bases de datos pasan mucho tiempo esperando lecturas, especialmente cuando los datos no están en memoria. Reducir la cantidad de filas (y páginas) que la base de datos tiene que tocar normalmente disminuye:
- lecturas de disco/SSD
- tiempo de CPU dedicado a evaluar filtros
- presión de memoria por traer datos innecesarios a la caché
Cuándo aparece la ganancia de velocidad
La indexación ayuda sobre todo cuando los datos son grandes y el patrón de consulta es selectivo (por ejemplo, obtener 20 filas coincidentes de 10 millones). Si tu consulta devuelve la mayoría de las filas, o la tabla es lo bastante pequeña para caber cómodamente en memoria, un escaneo completo puede ser igual de rápido o incluso más rápido.
Cómo las estructuras de índice hacen las búsquedas rápidas
Los índices funcionan porque organizan valores para que la base de datos pueda saltar cerca de lo que quieres en lugar de comprobar cada fila.
Índices B-tree: el caballo de batalla por defecto
La estructura de índice más común en bases de datos SQL es el B-tree (a menudo escrito “B-tree” o “B+tree”). Conceptualmente:
- los valores se mantienen ordenados
- el índice se divide en páginas (bloques) que apuntan a otras páginas y, finalmente, a las filas de la tabla
Como está ordenado, un B-tree es excelente tanto para búsquedas por igualdad (WHERE email = ...) como para consultas por rango (WHERE created_at >= ... AND created_at < ...). La base de datos puede navegar hasta el vecindario correcto y luego escanear hacia adelante en orden.
Qué significa “logarítmico” (sin matemáticas)
Se dice que las búsquedas en B-tree son “logarítmicas”. Prácticamente, eso significa: cuando tu tabla crece de miles a millones de filas, el número de pasos para encontrar un valor crece lentamente, no proporcionalmente.
En vez de “el doble de datos significa el doble de trabajo”, es más bien “muchos más datos significan solo unos pocos pasos de navegación extra”, porque la base de datos sigue punteros a través de un pequeño número de niveles en el árbol.
Índices hash: rápidos para coincidencias exactas (con límites)
Algunos motores también ofrecen índices hash. Pueden ser muy rápidos para comparaciones de igualdad exacta porque el valor se transforma en un hash y se usa para encontrar la entrada directamente.
La contraprestación: los índices hash normalmente no ayudan con rangos ni con escaneos ordenados, y la disponibilidad/comportamiento varía según la base de datos.
Los detalles del motor difieren, la idea es la misma
PostgreSQL, MySQL/InnoDB, SQL Server y otros almacenan y usan índices de forma distinta (tamaño de página, clustering, columnas incluidas, comprobaciones de visibilidad). Pero el concepto central se mantiene: los índices crean una estructura compacta y navegable que permite localizar filas coincidentes con mucho menos trabajo que escanear toda la tabla.
Consultas que más se benefician de los índices
Los índices no aceleran “SQL” en general: aceleran patrones de acceso específicos. Cuando un índice coincide con cómo filtras, unes u ordenas, la base de datos puede saltar directamente a las filas relevantes en lugar de leer toda la tabla.
Patrones de consulta más favorables a índices
1) Filtros WHERE (especialmente en columnas selectivas)
Si tu consulta suele reducir una tabla grande a un pequeño conjunto de filas, un índice suele ser el primer lugar a revisar. Un ejemplo clásico es buscar un usuario por un identificador.
Sin un índice en users.email, la base de datos puede tener que escanear cada fila:
SELECT * FROM users WHERE email = '[email protected]';
Con un índice en email, puede localizar la(s) fila(s) coincidente(s) rápidamente y detenerse.
2) Claves de JOIN (foreign keys y columnas referenciadas)
Las joins son donde las “pequeñas ineficiencias” se convierten en grandes costes. Si unes orders.user_id con users.id, indexar las columnas de la unión (típicamente orders.user_id y la clave primaria users.id) ayuda a la base de datos a emparejar filas sin escaneos repetidos.
3) ORDER BY (cuando quieres resultados ya ordenados)
Ordenar es caro cuando la base de datos debe recoger muchas filas y ordenarlas después. Si con frecuencia ejecutas:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
un índice que combine user_id y la columna de orden puede permitir al motor leer las filas en el orden necesario en lugar de ordenar un gran conjunto intermedio.
4) GROUP BY (cuando agrupar coincide con un índice)
Agrupar puede beneficiarse cuando la base de datos puede leer datos en orden agrupado. No es una garantía, pero si agrupar por una columna que también se usa para filtrar (o que está naturalmente agrupada en el índice), el motor puede hacer menos trabajo.
Filtros por rango: una ganancia común de B-tree
Los índices B-tree son especialmente buenos para condiciones de rango: piensa en fechas, precios y consultas “entre”:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
Para paneles, informes y pantallas de “actividad reciente”, este patrón es omnipresente, y un índice en la columna de rango suele producir una mejora inmediata.
El tema es simple: los índices ayudan cuando reflejan cómo buscas y ordenas. Si tus consultas encajan con esos patrones, la base de datos puede hacer lecturas dirigidas en vez de amplios escaneos.
Selectividad: por qué algunos índices no ayudan
Un índice ayuda sobre todo cuando reduce drásticamente cuántas filas la base de datos tiene que tocar. Esa propiedad se llama selectividad.
Qué significa “selectividad” en la práctica
La selectividad es básicamente: ¿cuántas filas coinciden con un valor dado? Una columna altamente selectiva tiene muchos valores distintos, por lo que cada búsqueda coincide con pocas filas.
- Alta selectividad:
email,user_id,order_number(a menudo único o casi único) - Baja selectividad:
is_active,is_deleted,statuscon pocos valores comunes
Con alta selectividad, un índice puede saltar directamente a un pequeño conjunto de filas. Con baja selectividad, el índice apunta a un gran trozo de la tabla—la base de datos aún tiene que leer y filtrar mucho.
Por qué los índices booleanos (y similares) decepcionan
Considera una tabla con 10 millones de filas y una columna is_deleted donde el 98% son false. Un índice en is_deleted no ahorra mucho para:
SELECT * FROM orders WHERE is_deleted = false;
El conjunto de coincidencias sigue siendo casi toda la tabla. Usar el índice puede ser incluso más lento que un escaneo secuencial porque el motor hace trabajo extra saltando entre entradas del índice y páginas de la tabla.
Por qué el optimizador puede ignorar tu índice
Los planificadores estiman costes. Si un índice no reduce lo suficiente el trabajo—porque demasiadas filas coinciden, o porque la consulta necesita la mayor parte de las columnas—pueden elegir un escaneo completo.
La selectividad cambia con el tiempo
La distribución de datos no es fija. Una columna status puede empezar distribuida equitativamente y luego derivar a un valor dominante. Si las estadísticas no se actualizan, el planificador puede tomar malas decisiones, y un índice que antes ayudaba puede dejar de compensar.
Índices compuestos y de cobertura (y el orden de columnas)
Convierte consultas lentas en soluciones
Crea una app React + Go + PostgreSQL desde el chat y añade los índices exactos que necesitan tus consultas lentas.
Los índices de una sola columna son un buen comienzo, pero muchas consultas reales filtran por una columna y ordenan o filtran por otra. Ahí brillan los índices compuestos (multicolumna): un solo índice puede cubrir varias partes de la consulta.
Orden de columnas: la regla “de izquierda a derecha”
La mayoría de las bases de datos (especialmente con índices B-tree) solo pueden usar eficientemente un índice compuesto desde las columnas más a la izquierda en adelante. Piensa en el índice como ordenado primero por la columna A, luego dentro de esa por la columna B, y así sucesivamente.
Eso significa:
- un índice en (account_id, created_at) es ideal para consultas que filtran por
account_idy luego ordenan o filtran porcreated_at - el mismo índice no suele ayudar para una consulta que solo filtra por
created_at(porque no es la columna más a la izquierda)
Un patrón práctico: timelines por cuenta
Una carga común es “muéstrame los eventos más recientes para esta cuenta.” Este patrón:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
suele beneficiarse enormemente de:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
La base de datos puede saltar directamente a la porción del índice de una cuenta y leer filas en orden temporal, en lugar de escanear y ordenar un conjunto grande.
Índices de cobertura: cuando el índice es la respuesta
Un índice de cobertura contiene todas las columnas que necesita la consulta, así que la base de datos puede devolver resultados desde el índice sin mirar las filas de la tabla (menos lecturas, menos I/O aleatorio).
Cuidado: añadir columnas extra puede hacer que el índice sea grande y caro.
No construyas compuestos muy anchos “por si acaso”
Los índices compuestos muy amplios pueden ralentizar las escrituras y consumir mucho almacenamiento. Añádelos solo para consultas concretas de alto valor y verifica con un plan EXPLAIN y mediciones reales antes y después.
Compensaciones: ralentizaciones en escrituras y almacenamiento extra
Los índices a menudo se describen como “velocidad gratis”, pero no lo son. Las estructuras de índices deben mantenerse cada vez que la tabla subyacente cambia y consumen recursos reales.
INSERT/UPDATE/DELETE más lentos (porque cada índice debe actualizarse)
Cuando haces un INSERT de una nueva fila, la base de datos no solo escribe la fila: también inserta entradas correspondientes en cada índice de esa tabla. Lo mismo sucede con DELETE y muchos UPDATE.
Por eso “más índices” puede ralentizar notablemente cargas con muchas escrituras. Un UPDATE que toca una columna indexada puede ser especialmente caro: la base de datos puede tener que eliminar la entrada de índice vieja y añadir una nueva (y en algunos motores, esto puede desencadenar divisiones de página o reequilibrios internos). Si tu app hace muchas escrituras—eventos de órdenes, datos de sensores, logs de auditoría—indexarlo todo puede hacer que la base de datos se sienta lenta aunque las lecturas sean rápidas.
Almacenamiento extra y presión de memoria
Cada índice ocupa espacio en disco. En tablas grandes, los índices pueden rivalizar (o incluso superar) el tamaño de la tabla, especialmente si tienes índices solapados.
También afecta la memoria. Las bases de datos dependen mucho del caching; si tu conjunto de trabajo incluye varios índices grandes, la caché debe mantener más páginas para seguir siendo rápida. Si no, verás más E/S de disco y un rendimiento menos predecible.
El equilibrio práctico
Indexar es elegir qué acelerar. Si tu carga es de lectura intensiva, más índices pueden merecer la pena. Si es de escritura intensiva, prioriza índices que soporten tus consultas más importantes y evita duplicados. Una regla útil: añade un índice solo cuando puedas nombrar la consulta a la que ayuda—y verifica que la ganancia de lectura compense el coste en escritura y mantenimiento.
Cómo demostrar que un índice ayuda: EXPLAIN y mediciones
De la idea a la prueba de rendimiento
Prototipa un endpoint, mídelo y mejora los índices sin esperar a una pipeline completa.
Añadir un índice parece que debería ayudar—pero puedes (y debes) verificarlo. Las dos herramientas que lo concretan son el plan de consulta (EXPLAIN) y mediciones reales antes/después.
Lee el plan: ¿se usa realmente el índice?
Ejecuta EXPLAIN (o EXPLAIN ANALYZE) en la consulta exacta que te importa.
- Tipo de escaneo: un Seq Scan / Full Table Scan significa que la base de datos está leyendo toda la tabla. Un Index Scan / Index Seek (o Index Range Scan) sugiere que está usando un índice para estrechar filas.
- Filas estimadas vs. reales (especialmente en
EXPLAIN ANALYZE): si el plan estimó 100 filas pero realmente tocó 100.000, el optimizador se equivocó—a menudo porque las estadísticas están desactualizadas o el filtro es menos selectivo de lo esperado. - Pasos de ordenación: si ves una operación explícita Sort, la base de datos está ordenando resultados tras obtenerlos. Si un nuevo índice coincide con el
ORDER BY, esa ordenación puede desaparecer, lo que supone una gran mejora.
Mide correctamente: antes/después, mismas condiciones
Haz benchmark de la consulta con los mismos parámetros, sobre datos representativos y captura tanto latencia como filas procesadas.
Cuidado con la caché: la primera ejecución puede ser más lenta porque los datos no están en memoria; ejecuciones repetidas pueden aparentar “arreglarse” sin índice. Para no engañarte, compara varias ejecuciones y céntrate en si el plan cambia (índice usado, menos filas leídas) además del tiempo.
Si EXPLAIN ANALYZE muestra menos filas tocadas y menos pasos costosos (como sorts), has demostrado que el índice ayuda—no solo lo has esperado.
Errores comunes que anulan los beneficios del índice
Puedes añadir el “índice correcto” y aun así no ver mejora si la consulta está escrita de forma que impide su uso. Estos problemas suelen ser sutiles, porque la consulta sigue devolviendo resultados correctos, pero con un plan más lento.
Anti-patrones que bloquean el uso del índice
1) Wildcards al principio
Cuando escribes:
WHERE name LIKE '%term'
la base de datos no puede usar un índice B-tree normal para saltar al punto de inicio, porque no sabe dónde comienza “%term” en el orden. Suele recurrir a escanear muchas filas.
Alternativas:
- Si puedes, usa búsqueda por prefijo:
WHERE name LIKE 'term%'. - Si necesitas búsqueda "contains", considera un índice especializado (por ejemplo, full-text o trigram) en lugar de esperar que un índice estándar ayude.
2) Funciones sobre columnas indexadas
Esto parece inofensivo:
WHERE LOWER(email) = '[email protected]'
Pero LOWER(email) cambia la expresión, por lo que el índice sobre email no puede usarse directamente.
Alternativas:
- Almacena datos normalizados (por ejemplo, correos en minúsculas) y consulta
WHERE email = .... - O crea un índice por expresión/función (dependiendo del gestor) específicamente para
LOWER(email).
Bloqueadores de índice ocultos que la gente pasa por alto
Cast implícitos de tipo: Comparar distintos tipos puede forzar al motor a castear un lado, lo que puede deshabilitar el índice. Ejemplo: comparar una columna integer con una literal de texto.
Intercalaciones/collations mismatched: Si la comparación usa una colación distinta a la del índice (común en columnas de texto entre locales), el optimizador puede evitar el índice.
Lista de comprobación rápida: “¿por qué no se usa mi índice?”
- ¿La condición empieza con un wildcard (
LIKE '%x')? - ¿Aplicas una función a la columna indexada (
LOWER(col),DATE(col),CAST(col)) ? - ¿Los tipos son idénticos en ambos lados (sin cast implícito)?
- ¿La intercalación/localización es consistente para la comparación?
- ¿El predicado es lo bastante selectivo (no coincide con gran parte de la tabla)?
- ¿Estás filtrando/ordenando por las columnas más a la izquierda de un índice compuesto?
- ¿Revisaste el plan con
EXPLAINpara confirmar la elección del optimizador?
Mantenimiento de índices: estadísticas, bloat y salud a largo plazo
Los índices no son “ponlo y olvídalo”. Con el tiempo, los datos cambian, los patrones de consulta se desplazan y la forma física de tablas e índices deriva. Un índice bien elegido puede volverse menos efectivo—o incluso dañino—si no lo mantienes.
Estadísticas: el mapa del planificador puede quedar desactualizado
La mayoría de bases de datos usan un planificador para elegir cómo ejecutar una consulta: qué índice usar, orden de joins y si merece la pena una búsqueda por índice. Para decidir, el planificador usa estadísticas—resúmenes sobre distribuciones de valores, conteo de filas y sesgos.
Cuando las estadísticas están obsoletas, las estimaciones de filas del plan pueden ser muy erróneas. Eso conduce a malas elecciones de plan, como escoger un índice que devuelve muchas más filas de las previstas o saltarse un índice que habría sido más rápido.
Arreglo rutinario: programa actualizaciones regulares de estadísticas (a menudo ANALYZE o similar). Después de grandes cargas de datos, borrados masivos o churn significativo, refresca las estadísticas antes.
Bloat y fragmentación: cuando las estructuras se ensucian
A medida que se insertan, actualizan y eliminan filas, los índices pueden acumular bloat (páginas extra que ya no contienen datos útiles) y fragmentación (datos dispersos que aumentan la E/S). El resultado son índices más grandes y lecturas más lentas, especialmente para consultas por rango.
Arreglo rutinario: reconstruye o reorganiza periódicamente índices muy usados cuando hayan crecido desproporcionadamente o el rendimiento baje. Las herramientas e impactos varían por base de datos; trátalo como una operación medida, no como una regla general sin más.
Monitoriza con el tiempo, no solo una vez
Configura monitorización para:
- consultas lentas (latencia, frecuencia y peores casos)
- uso de índices (índices nunca usados frente a los “calientes”)
- crecimiento del tamaño de índices y cambios repentinos en planes
Ese bucle de retroalimentación te ayuda a detectar cuándo se necesita mantención—y cuándo ajustar o eliminar un índice. Para más sobre validar mejoras, consulta /blog/how-to-prove-an-index-helps-explain-and-measurements.
Un flujo de trabajo práctico para añadir el índice correcto
Planifica tu esquema e índices
Planifica tablas, claves y estrategia de índices antes de escribir funcionalidades, luego implementa según el plan.
Añadir un índice debe ser un cambio deliberado, no una conjetura. Un flujo ligero te mantiene centrado en ganancias medibles y evita la “proliferación de índices”.
1) Identifica la consulta problemática real
Empieza con evidencia: logs de consultas lentas, trazas APM o informes de usuarios. Escoge una consulta que sea tanto lenta como frecuente—un informe raro de 10 s importa menos que una búsqueda común de 200 ms.
Captura el SQL exacto y el patrón de parámetros (por ejemplo: WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). Pequeñas diferencias cambian qué índice ayuda.
2) Mide una línea base
Registra la latencia actual (p50/p95), filas escaneadas y consumo de CPU/E/S. Guarda el plan actual (EXPLAIN / EXPLAIN ANALYZE) para comparar después.
3) Diseña el índice más pequeño útil
Elige columnas que coincidan con cómo filtra y ordena la consulta. Prefiere el índice mínimo que haga que el plan deje de escanear rangos enormes.
Prueba en staging con volumen de datos similar a producción. Los índices pueden lucir bien en datasets pequeños y decepcionar a escala.
4) Créalo de forma segura
En tablas grandes, usa opciones online cuando estén disponibles (por ejemplo, PostgreSQL CREATE INDEX CONCURRENTLY). Programa cambios en horarios de menor tráfico si la base de datos puede bloquear escrituras.
5) Valida con evidencia antes/después
Re-ejecuta la misma consulta y compara:
- forma del plan (¿pasó de full scan a acceso por índice?)
- tiempo de ejecución y filas escaneadas
- impacto en escrituras (latencia de inserts/updates)
6) Ten un plan de reversión
Si el índice aumenta el coste de las escrituras o causa bloat, elimínalo limpiamente (por ejemplo, DROP INDEX CONCURRENTLY donde esté disponible). Mantén la migración reversible.
7) Documenta el “por qué”
En la migración o notas de esquema, escribe qué consulta sirve el índice y qué métrica mejoró. El futuro tú (o un compañero) sabrá por qué existe y cuándo es seguro eliminarlo.
Dónde encaja Koder.ai en este flujo
Si estás construyendo un servicio nuevo y quieres evitar la “proliferación de índices” desde el inicio, Koder.ai puede ayudarte a iterar más rápido en el ciclo completo anterior: generar una app React + Go + PostgreSQL desde chat, ajustar migraciones de esquema/índices según los requisitos y luego exportar el código cuando estés listo para tomar el control manualmente. En la práctica, eso facilita ir de “este endpoint es lento” a “aquí está el plan EXPLAIN, el índice mínimo y una migración reversible” sin esperar toda una canalización tradicional.
Cuando indexar no es suficiente (y qué hacer después)
Los índices son una palanca poderosa, pero no un botón mágico. A veces la parte lenta de una petición ocurre después de que la base de datos encuentre las filas correctas, o el patrón de consulta hace que indexar no sea la primera solución.
Casos donde indexar no es la mejor solución
Si tu consulta ya usa un buen índice pero aún va lenta, busca estos culpables comunes:
- Paginación faltante (o incorrecta): pedir la página 1.000 con
OFFSET 999000puede ser lento incluso con índices. Prefiere paginación por keyset (por ejemplo, “dame filas después del último id/timestamp visto”). - Devolver demasiado dato: seleccionar filas anchas (
SELECT *) o devolver decenas de miles de registros puede convertirse en cuello de botella en red, serialización JSON o procesamiento en la app. - Desajustes de esquema: joins sobredimensionados, almacenar valores buscables dentro de JSON/text blobs o usar tipos erróneos puede forzar operaciones caras que los índices no pueden enmascarar por completo.
Optimizaciones complementarias que suelen importar más
- Reescribe la consulta: elimina joins innecesarios, evita funciones sobre columnas indexadas en WHERE y simplifica predicados con muchos OR.
- Limita columnas y filas: selecciona solo lo que necesitas, añade
LIMITsensato y pagina intencionalmente. - Cache: cachea lecturas calientes en capa de aplicación o usa un caché read-through para consultas repetidas costosas.
- Particionamiento: si la mayoría de consultas tocan “datos recientes”, particiona por tiempo (u otro límite natural) para reducir el espacio de búsqueda.
Si quieres un diagnóstico más profundo de cuellos de botella, combínalo con el flujo en /blog/how-to-prove-an-index-helps.
Prioriza: arregla el mayor cuello de botella primero
No adivines. Mide dónde se gasta el tiempo (ejecución en BD vs. filas devueltas vs. código de la app). Si la base de datos es rápida pero la API es lenta, más índices no ayudarán.
Lista de comprobación rápida
- ¿La consulta devuelve más filas/columnas de las necesarias?
- ¿La paginación es eficiente (keyset vs. OFFSET grande)?
- ¿Estás ordenando/agrupando por expresiones caras?
- ¿El esquema fuerza joins pesados o búsquedas en JSON/text?
- ¿El caching eliminaría trabajo repetido?
- ¿El particionamiento reduciría los datos escaneados?
- Tras cada cambio, vuelve a medir e itera
Preguntas frecuentes
¿Qué es un índice de base de datos en términos sencillos?
Un índice de base de datos es una estructura de datos separada (a menudo un B-tree) que guarda valores seleccionados de columnas en una forma ordenada y buscable con punteros de vuelta a las filas de la tabla. La base de datos lo usa para evitar leer la mayor parte de la tabla cuando responde consultas selectivas.
No es una copia completa de la tabla, pero sí duplica algunos datos de columnas más metadatos, por lo que consume espacio adicional.
¿Por qué los índices aceleran tanto las consultas frente a los escaneos completos?
Sin un índice, la base de datos puede tener que hacer un escaneo completo de la tabla: leer muchas (o todas) las filas y comprobar cada una contra tu cláusula WHERE.
Con un índice, normalmente puede saltar directamente a las ubicaciones de las filas coincidentes y leer solo esas filas, reduciendo E/S de disco, trabajo de CPU para filtrar y presión sobre la caché.
¿Cómo ayuda un índice B-tree tanto en búsquedas exactas como en consultas por rango?
Un índice B-tree mantiene los valores ordenados y organizados en páginas que apuntan a otras páginas, de modo que la base de datos puede navegar rápidamente al “vecindario” correcto de valores.
Por eso los B-trees funcionan bien tanto para:
- búsquedas por igualdad (
WHERE email = ...) - consultas por rango (
WHERE created_at >= ... AND created_at < ...)
¿Cuándo sería mejor un índice hash que un B-tree?
Los índices hash pueden ser muy rápidos para igualdad exacta (=) porque convierten un valor en un hash y saltan a su cubeta.
Contras:
- Suele no ser útil para rangos ni para lecturas ordenadas
- Disponibilidad y comportamiento dependen del motor de base de datos
En muchas cargas reales, los B-trees son la opción por defecto porque cubren más patrones de consulta.
¿Qué patrones de consulta se benefician más de los índices?
Los índices suelen ayudar más para:
- filtros
WHEREselectivos (pocos resultados) - claves de
JOIN(claves foráneas y columnas referenciadas) ORDER BYque coincide con el orden del índice (puede evitar la ordenación)- algunos casos de cuando leer en orden agrupado reduce trabajo
¿Por qué los índices en columnas booleanas o de baja selectividad suelen decepcionar?
La selectividad es “cuántas filas coinciden con un valor”. Los índices resultan cuando un predicado reduce mucho la tabla a un conjunto pequeño.
Columnas de baja selectividad (por ejemplo is_deleted, is_active, enums con pocos valores) suelen coincidir con una gran parte de la tabla. En esos casos, usar el índice puede ser más lento que un escaneo porque el motor aún tiene que obtener y filtrar muchas filas.
¿Por qué el planificador de consultas ignoraría un índice que existe?
Porque el optimizador estima que usarlo no reducirá suficientemente el trabajo.
Razones comunes:
- demasiadas filas coinciden con el predicado (baja selectividad)
- la consulta necesita muchas columnas, lo que hace costosa la lectura de la tabla
- estadísticas desactualizadas, que producen malas estimaciones de costos
- la consulta no coincide con el prefijo utilizable del índice compuesto (regla del lado izquierdo)
¿Qué significa el “orden de columnas” en índices compuestos?
En la mayoría de implementaciones B-tree, el índice está ordenado por la primera columna, luego dentro de esa por la segunda, etc. Por eso la base de datos puede usar el índice de forma eficiente empezando por las columnas más a la izquierda.
Ejemplo:
- El índice
(account_id, created_at)es excelente paraWHERE account_id = ?y luego filtrar/ordenar por .
¿Qué es un índice de cobertura y cuándo merece la pena?
Un índice de cobertura incluye todas las columnas que necesita la consulta, de manera que la base de datos puede devolver resultados desde el índice sin leer las filas de la tabla.
Beneficios:
- menos lecturas y menos E/S aleatoria
Costes:
- índice más grande
- mayor sobrecarga en escrituras (inserts/updates deben mantener el índice más amplio)
Usa índices de cobertura para consultas específicas de alto valor, no “por si acaso”.
¿Cómo demuestro que un índice realmente mejoró el rendimiento?
Comprueba dos cosas:
- El plan: usa
EXPLAIN/EXPLAIN ANALYZEy confirma que el plan cambió (por ejemplo,Seq Scan→Index Scan/Seek, menos filas leídas, desapareció la ordenación). - : compara la latencia antes/después en condiciones similares y con volúmenes de datos representativos.