De qué se trata en realidad: menos seguimientos de envíos
Cuando el volumen de pedidos es pequeño, las actualizaciones de envío pueden manejarse con comprobaciones rápidas, una hoja de cálculo y un par de mensajes al courier. A medida que los pedidos crecen, las pequeñas fallas se acumulan: las etiquetas se crean tarde, se pierden recogidas y el tracking queda obsoleto.
El patrón es familiar: los clientes preguntan “¿Dónde está mi pedido?” Soporte contacta a operaciones. Operaciones revisa un portal. Alguien actualiza manualmente un estado que debería haberse actualizado solo.
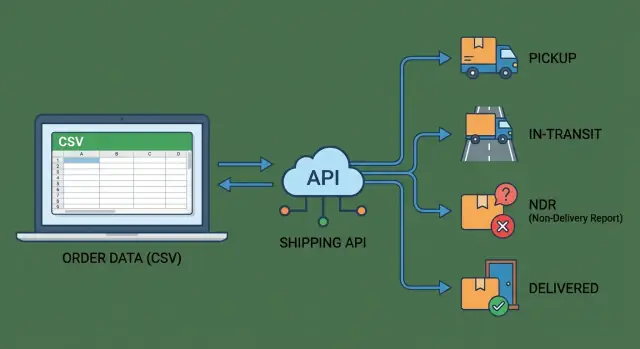
Una integración simplemente significa que tu sistema puede enviar datos de envío (dirección, peso, COD, valor de la factura) y recibir datos de envío (número AWB, confirmación de pickup, escaneos de seguimiento, resultados de entrega) de forma fiable. “Fiable” importa porque debe funcionar todos los días, no solo cuando alguien recuerda subir un archivo.
Por eso importa esta comparación:
- Un flujo de trabajo con carga CSV es la línea base. Es fácil comenzar, pero depende de que la gente repita los mismos pasos a tiempo.
- Una integración completa con la API del courier es la versión siempre activa. Puede crear envíos, obtener tracking y reaccionar ante excepciones sin esperar trabajo manual.
La mayoría de los equipos no quieren “más tecnología”. Quieren menos demoras, menos ediciones manuales y un tracking en el que todos confíen. Reducir los seguimientos (de clientes y equipos internos) suele reducir reembolsos, costos de reintentos y tickets de soporte.
Dónde falla el trabajo de envíos en operaciones reales
La mayoría de los equipos comienzan con una rutina simple: reservar pickups, imprimir etiquetas, pegar IDs de tracking en una hoja y responder cuando los clientes piden actualizaciones. Funciona con bajo volumen, pero las grietas aparecen rápido en India, especialmente cuando gestionas múltiples couriers, COD y calidad de dirección inconsistente.
Los pasos manuales no parecen grandes por sí solos. Alguien elige un courier, crea el envío, descarga etiquetas y se asegura de que el paquete correcto tenga la guía aérea (AWB) adecuada. Luego otra persona actualiza el estado del pedido, comparte el tracking y revisa las pruebas de entrega para COD.
Los puntos de falla más comunes son:
- La AWB equivocada queda pegada al paquete incorrecto, lo que lleva a pérdida o devolución.
- Se crean envíos duplicados tras un reintento o por un error al copiar la hoja.
- El tracking no se actualiza a tiempo, así que soporte no tiene respuesta clara y los clientes pierden confianza.
- No se confirma la pickup, por lo que los pedidos quedan “listos para enviar” mientras el courier cree que no hay nada programado.
- Montos o comisiones de COD no coinciden, creando problemas de conciliación más adelante.
NDR significa Non‑Delivery Report. Ocurre cuando la entrega falla (dirección incorrecta, cliente ausente, negativa, problema de pago). NDR genera trabajo extra porque obliga a tomar decisiones: llamar al cliente, actualizar la dirección, aprobar un reintento o marcar para devolución.
Operaciones siente la presión primero. Soporte recibe los mensajes enojados. Finanzas se atasca con la conciliación de COD. Los clientes sienten el silencio cuando los estados no cambian.
Opción A: la línea base de carga CSV (qué obtienes y qué no)
La carga CSV es el punto de partida por defecto para muchos setups de envío en India. Exportas un lote de pedidos pagados desde tu tienda o ERP, los formateas según la plantilla del courier o agregador y subes el archivo en un panel para generar AWBs y etiquetas.
Lo que obtienes es simplicidad. Normalmente no hay trabajo de ingeniería y puedes estar en producción en un día. Para volumen bajo o envíos predecibles (misma dirección de pickup, un conjunto pequeño de SKUs, pocas excepciones), un CSV diario puede ser “suficiente” y fácil de entrenar.
Donde se rompe es todo después de la subida. La mayoría de los equipos termina haciendo la misma limpieza todos los días: corregir filas fallidas porque un código postal o formato de teléfono no coincide con la plantilla, volver a subir archivos corregidos, buscar duplicados accidentales y copiar y pegar números de tracking de nuevo en la tienda.
Luego viene la parte desordenada: perseguir excepciones (problemas de dirección, pagos, riesgo de RTO) por emails, llamadas y portales de couriers, y actualizar el estado en varios lugares porque el panel del courier no es tu sistema de registro.
El costo oculto es tiempo e inconsistencia. Diferentes couriers esperan columnas y reglas distintas, así que “un CSV” se convierte en múltiples versiones más soluciones de hoja de cálculo. Y porque las actualizaciones no son en tiempo real, soporte a menudo se entera de retrasos solo cuando un cliente se queja.
Opción B: integración completa con la API del courier (qué desbloquea y qué cuesta)
Una configuración completa de API del courier significa que tu sistema y los sistemas del courier hablan directamente. En vez de subir archivos, envías automáticamente detalles de pedido y dirección, recibes una etiqueta y vas obteniendo escaneos de tracking sin que nadie revise varios portales. Es generalmente el punto donde el envío deja de ser un trabajo operativo diario y pasa a comportarse como infraestructura confiable.
Qué desbloquea
La mayoría de los equipos comienza una integración API por tres acciones principales: booking, etiquetas y tracking. Capacidades típicas incluyen crear un envío y obtener un AWB al instante, generar la etiqueta y datos de factura, solicitar pickup (donde esté soportado) y extraer escaneos de tracking en casi tiempo real.
Una vez que tienes esas bases, también puedes manejar excepciones más limpiamente, como problemas de dirección y actualizaciones de NDR.
El beneficio es claro: despacho más rápido, menos errores por copiar y pegar y actualizaciones más claras para el cliente. Si un pedido se paga a las 14:00, tu sistema puede auto‑reservar el envío, imprimir la etiqueta y enviar el número de tracking en minutos, sin esperar una exportación y recarga de CSV.
Qué cuesta
Las integraciones API no son “configura y olvida”. Planifica tiempo para la configuración, pruebas y mantenimiento continuo.
Las fuentes habituales de esfuerzo:
- Reglas específicas de cada courier (serviciabilidad por pincode, tramos de peso, límites COD)
- Coincidencias de códigos de estado (el “RTO iniciado” de un courier puede ser “return in transit” en otro)
- Fiabilidad de webhooks y lógica de reintentos para eventos perdidos
- Formatos de etiquetas y requisitos de documentación que cambian con el tiempo
- Sandboxes que no reflejan completamente producción
Si planificas estas peculiaridades desde el inicio, la configuración escala limpiamente. Si no, puedes terminar con envíos reservados pero no recogidos, o con clientes viendo estados confusos porque los eventos de tracking no se mapearon correctamente.
Qué automatizar y qué mantener manual (una división práctica)
Una regla simple funciona bien: automatiza las tareas que ocurren muchas veces al día y que generan más trabajo de retrabajo cuando alguien comete un pequeño error.
En India, eso suele significar booking, etiquetas y actualizaciones de tracking. Un error tipográfico o un escaneo perdido puede desencadenar una cadena de seguimientos.
Los pasos manuales aún tienen un lugar. Mantén algo manual cuando el volumen sea bajo, cuando las excepciones sean frecuentes o cuando los procesos del courier no sean lo suficientemente consistentes para confiar en la automatización.
Una división práctica por flujo:
- Automatizar primero: booking de envíos desde tu sistema de pedidos, generación e impresión de etiquetas, extracciones de estado de tracking o webhooks, alertas de NDR con una cola interna y mensajes de confirmación de entrega para tu equipo de soporte.
- Mantener manual (hasta tener volumen): elegir courier en casos límite, negociar cambios de pickup por teléfono, aprobar reintentos de COD arriesgados y correcciones de dirección puntuales que requieren juicio.
Un cuadro de decisión rápido antes de construir:
| Factor | Cuando manual está bien | Cuando la automatización compensa |
|---|
| Volumen diario | Menos de ~20/día | 50+/día o picos frecuentes |
| Número de couriers | 1 courier | 2+ couriers o cambios frecuentes |
| Presión de SLA | Entregas en 3‑5 días aceptables | Promesas mismo/siguiente día, altas penalidades |
| Tamaño del equipo | Persona dedicada a ops | Roles compartidos ops/soporte |
Un checkpoint simple: si tu equipo toca los mismos datos dos veces (copiar‑pegar del pedido al portal del courier y luego de vuelta a una hoja), ese paso es candidato fuerte para automatizar.
Lista de eventos de tracking: pickup, en tránsito, NDR, entregado
Si quieres menos mensajes “¿Dónde está mi pedido?”, trata el tracking como una línea de tiempo de eventos, no como un estado único. Esto importa en India, donde un mismo envío puede rebotar entre hubs, reintentos y devoluciones.
Captura estas etapas para que tu equipo y los clientes vean la misma historia:
- Pickup: cuándo se programó la pickup, si se intentó y el resultado final (recogido o fallido). Cuando falla, guarda la razón de fallo del courier para poder actuar sin llamar al rider.
- En tránsito: el primer escaneo (a menudo el verdadero inicio), escaneos en hubs importantes, flags de excepción o retraso y “out for delivery”. Estos son los puntos que disparan la mayoría de preguntas de soporte.
- NDR (Non‑Delivery Report): cuándo se levantó un NDR, el código de motivo, si se contactó al cliente y qué sucede después (reintento planificado o inicio de devolución). Aquí suele correr el reloj.
- Entregado (o no): hora de entrega y detalles de prueba de entrega cuando estén disponibles (nombre, firma, referencia de foto). También separa “entrega fallida” de “devuelto”, porque los clientes perciben resultados muy distintos.
Para cada evento, guarda los mismos campos centrales: timestamp, ubicación (ciudad y hub si está disponible), texto bruto del estado, estado normalizado, código de motivo y la referencia del courier/AWB. Mantener valores brutos y normalizados facilita auditorías y disputas con couriers.
Datos que necesitas antes de integrar (para que nada se rompa después)
Muchas integraciones fallan por razones aburridas: números de teléfono faltantes, pesos inconsistentes o ninguna decisión clara sobre qué sistema “posee” la verdad. Antes de tocar una API, asegúrate del mínimo de datos que siempre tendrás por pedido.
Empieza con una base que también funcione con CSV. Si no puedes exportar estos campos de manera fiable, una API solo hará que los errores ocurran más rápido:
- ID de pedido (único y nunca reutilizado)
- Dirección de entrega completa (nombre, pincode, ciudad, estado, referencia si la recopilas)
- Número de teléfono (formato validado) y email (opcional)
- Artículos e info de paquete (SKU, cantidad, peso; dimensiones si las tienes)
- Detalles de pago (monto COD, flag prepago)
Luego define qué esperas recibir del courier, porque estos serán tus “mangos” para todo lo demás. Como mínimo, guarda ID de envío, número AWB, nombre o código del courier, referencia de etiqueta y fecha/ventana de pickup.
Una decisión evita semanas de confusión: elige tu única fuente de la verdad para el estado del envío. Si tu equipo sigue consultando el portal del courier y sobrescribe tu sistema, los clientes verán una cosa y soporte otra.
Un plan de mapeo simple que mantiene a todos alineados:
- Elige los estados internos que vas a usar (por ejemplo: Created, Picked Up, In Transit, Out for Delivery, Delivered, NDR).
- Mapea cada estado del courier a un estado interno (aunque pierdas detalle).
- Guarda el texto bruto del courier por separado para auditorías.
- Decide qué eventos pueden cambiar el estado automáticamente y cuáles solo por humano.
Si estás construyendo esto dentro de una herramienta como Koder.ai, trata estos campos y mapeos como modelos de primera clase desde el inicio, para que exportes, tracking y rollback no se rompan al añadir un segundo courier.
Paso a paso: pasar de CSV a API sin caos
El camino de actualización más seguro es una serie de pequeños cambios, no un corte grande. Ops debe seguir enviando mientras la integración se ajusta.
1) Bloquea el alcance antes de escribir código
Elige los couriers que realmente usarás y confirma qué acciones necesitas ahora vs más tarde: booking, tracking, manejo de NDR y devoluciones (RTO). Esto importa porque cada courier nombra estados diferente y expone campos distintos.
2) Integra tracking primero (solo lectura)
Antes de automatizar booking o creación de etiquetas, extrae eventos de tracking a tu sistema y muéstralos junto al pedido. Esto es de bajo riesgo porque no cambia cómo se crean los paquetes.
Asegúrate de poder obtener eventos por AWB y manejar casos donde la AWB falte o esté mal.
3) Mapea estados, pero guarda la verdad cruda
Crea un pequeño modelo interno de estados (pickup, en tránsito, NDR, entregado) y mapea los estados del courier a él. También guarda cada payload de evento tal como lo recibes.
Cuando un cliente dice “marca como entregado pero no lo recibí”, los eventos crudos ayudan a soporte a responder rápido.
4) Añade automatización de NDR con cuidado
Automatiza las partes fáciles primero: detectar NDR, asignarlo a una cola, notificar al cliente y fijar temporizadores para ventanas de reintento.
Mantén una anulación manual para cambios de dirección y casos especiales.
5) Solo entonces añade booking, etiquetas y programación de pickup
Una vez que el tracking esté estable, añade booking por API, generación de etiquetas y solicitudes de pickup. Lánzalo courier por courier, manteniendo la ruta CSV como respaldo unas semanas.
Prueba con escenarios reales:
- Cambio de dirección después de un NDR
- Reintento solicitado pero no realizado
- RTO iniciado y luego cancelado
- Entrega parcial o envío dividido
- Escaneo de entrega sin OTP o detalles de POD
Errores comunes que provocan retrasos y tickets de soporte
La mayoría de los tickets de envío no son solo “¿dónde está mi pedido?” Son expectativas desalineadas: tu sistema muestra una cosa, el courier otra y el cliente una tercera.
Una trampa común es asumir que el texto de estado es uniforme. El mismo hito puede aparecer con frases distintas según zona, tipo de servicio o hub. Si mapeas por texto exacto en vez de normalizar a un conjunto pequeño de estados propios, tu panel y mensajes al cliente se desalinean.
Errores que crean retrasos y seguimientos extra:
- Guardar solo el último estado: sobrescribir eventos hace perder la línea de tiempo que explica qué pasó. Conserva el historial completo con timestamps y ubicación.
- Tratar NDR como un único estado: NDR es un proceso. Necesitas la razón, la acción tomada y la fecha del siguiente intento.
- No manejar eventos tardíos o fuera de orden: los couriers pueden enviar eventos en lotes o en orden extraño. Sin reconciliación y actualizaciones seguras, tu sistema puede cambiar estados de un lado a otro.
- Falta de lógica de reintentos y manejo de límites de tasa: las llamadas a la API fallan. Si no reintentas de forma segura, pierdes actualizaciones. Si reintentas con demasiada agresividad, te limitan la tasa.
- Sin plan operativo de respaldo: decide qué pasa cuando la API cae. ¿Puedes cambiar a CSV por un día, pausar notificaciones o marcar pedidos para revisión manual?
Un ejemplo simple: un cliente llama diciendo que el paquete fue “devuelto”. Tu sistema solo muestra “NDR”. Si hubieras guardado la razón del NDR y el historial de reintentos, el agente podría responder en un mensaje en vez de escalar a ops.
Comprobaciones rápidas antes de dar por terminada la integración
Antes de declarar éxito, prueba la integración como la usarán ops y soporte en un día ocupado. Una actualización de estado que llega tarde, o sin los detalles correctos, crea el mismo problema que no recibir nada.
Haz un drill “un envío, de punta a punta” en al menos 10 pedidos reales cruzando pincodes y tipos de pago (prepagado y COD). Elige un pedido y cronometra cuánto tarda en responder:
- ¿Dónde está ahora?
- ¿Qué pasó antes?
- ¿Qué hacemos después?
Una lista rápida que detecta la mayoría de huecos:
- La prueba de pickup es visible rápido: ves la confirmación de pickup dentro de la ventana esperada y puedes distinguir entre “etiqueta creada” y “recogido físicamente”.
- NDR es accionable, no solo un estado: guardas el código de motivo y el siguiente paso (reintento, llamada o RTO), y puedes cambiar esa decisión.
- La línea de tiempo es fácil de encontrar: un agente puede sacar el historial completo de eventos de un AWB en menos de 30 segundos, incluyendo timestamps y escaneos por ubicación.
- Entregado concuerda con dinero y devoluciones: los envíos entregados se reconcilian con reportes de remesas COD y datos de devoluciones/RTO, para que finanzas no persiga diferencias al final de la semana.
- Hay una anulación manual segura: puedes corregir una dirección, reprogramar una entrega o reasignar a otro courier cuando sea necesario, y cada cambio manual queda registrado.
Si construyes pantallas internas, mantén la primera versión aburrida: un cuadro de búsqueda por envío, una línea de tiempo limpia y dos botones (nota manual y anulación).
Herramientas como Koder.ai pueden ayudarte a prototipar ese panel de ops rápidamente y exportar el código fuente cuando estés listo para quedarte con él. Si quieres explorarlo más tarde, puedes encontrarlo en koder.ai.
Ejemplo: un equipo D2C que escala de 20 a 150 pedidos/día
Una marca D2C de tamaño mediano empieza con unos 20 pedidos al día, enviando mayormente en una sola ciudad. Usan dos partners courier. El proceso es simple: exportar pedidos, subir un CSV dos veces al día y copiar‑pegar los números de tracking en el admin de la tienda.
A 150 pedidos/día y tres couriers, esa rutina empieza a fallar. Los clientes preguntan “¿dónde está mi paquete?” y soporte debe revisar tres portales.
Lo peor son los NDR. Un intento de entrega falla, alguien del courier llama y el seguimiento se vuelve un hilo de WhatsApp. Se pierden reintentos y una pequeña demora se convierte en cancelaciones y reembolsos.
Pasan a una configuración que sincroniza eventos automáticamente. Ahora cada actualización de envío llega a un solo lugar y el equipo trabaja desde una única cola en vez de capturas de pantalla de chat.
Cambios del día a día:
- Los eventos de tracking se sincronizan automáticamente con el pedido (pickup, en tránsito, out for delivery, entregado).
- Los NDR crean una cola visible con una razón (problema de dirección, cliente no localizable, problema de pago).
- Recordatorios de reintento se disparan en tiempos establecidos, para que nada quede dos días parado.
- Soporte ve el estado más reciente sin ingresar a portales de couriers.
No todo está automatizado. Siguen cambiando couriers manualmente para PINs límite o problemas de capacidad en temporada alta. Cuando un cliente llama para corregir una dirección, un humano la verifica antes de disparar cualquier reintento.
Próximos pasos: elige un alcance y construye una primera versión simple
Decide qué necesitas en las primeras 2‑4 semanas. El mayor beneficio suele venir de un tracking confiable y menos tickets “¿dónde está mi pedido?”, no de construir todas las funciones el primer día.
Elige un alcance inicial que coincida con tu dolor:
- Solo tracking: extrae eventos del courier y mantiene sincronizados a clientes y soporte.
- Booking + etiqueta: crea envíos, genera etiquetas y guarda números AWB automáticamente.
- Booking + etiqueta + pickup: añade programación y confirmación de pickup, para que ops no esté detrás de los conductores.
Antes de escribir código, fija el lenguaje interno que usarás. Escribe tu lista de eventos (pickup, en tránsito, NDR, entregado) y mapea cada estado del courier a uno propio. Si omites esto, terminarás con cinco variantes de “en tránsito” y reglas poco claras sobre cuándo notificar al cliente, abrir una tarea NDR o marcar un pedido como completo.
Despliegue en fases (y manténlo simple)
Un despliegue seguro es: un courier, una ruta (o un almacén) y luego ampliar.
Ejecuta el nuevo flujo en paralelo con tu proceso CSV por un corto periodo para que ops compare AWBs, etiquetas y actualizaciones. Mantén un respaldo simple: si la llamada a la API falla, crea una tarea para booking manual en vez de bloquear el despacho.
Construye rápido sin coserte a ti mismo
Si quieres avanzar rápido, prototipa la integración de la API del courier con Koder.ai: define la tabla de almacenamiento de eventos, reglas de mapeo de estados y un pequeño panel de ops (búsqueda por pedido o AWB, último evento, siguiente acción). Cuando funcione como tu equipo espera, exporta el código fuente y robustece reintentos, logging y controles de acceso.
Una buena primera versión no es “completa”. Es un courier funcionando de punta a punta, con eventos limpios, propiedad clara de NDR y una vista diaria que dice a ops qué necesita atención ahora mismo.