Integraciones de webhooks fiables: firma, idempotencia y depuración
Aprende a integrar webhooks de forma fiable con firma, claves de idempotencia, protección contra replays y un flujo de depuración rápido para fallos reportados por clientes.
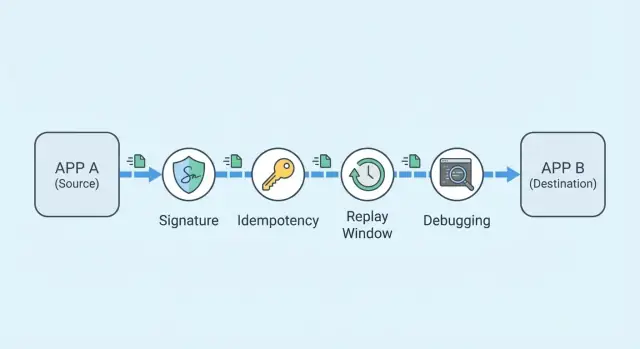
Por qué fallan los webhooks en la vida real
Cuando alguien dice “los webhooks no funcionan”, normalmente se refiere a una de tres cosas: los eventos nunca llegaron, llegaron dos veces o llegaron en un orden confuso. Desde su punto de vista, el sistema “se perdió” algo. Desde tu punto de vista, el proveedor lo envió, pero tu endpoint no lo aceptó, no lo procesó o no lo registró como esperabas.
Los webhooks viven en Internet público. Las peticiones se retrasan, se reintentan y a veces se entregan fuera de orden. La mayoría de proveedores reintentan agresivamente cuando ven timeouts o respuestas no 2xx. Eso convierte un pequeño incidente (una base de datos lenta, un deploy, una breve caída) en duplicados y condiciones de carrera.
Los logs deficientes hacen que esto parezca aleatorio. Si no puedes demostrar si una petición era auténtica, no puedes actuar sobre ella con seguridad. Si no puedes vincular la queja de un cliente a un intento de entrega concreto, terminas adivinando.
La mayoría de fallos reales caen en unos pocos grupos:
- Eventos “faltantes” (hiciste timeout, devolviste un error o fallaste después de reconocer)
- Duplicados (reintentos más un handler que no es idempotente)
- Orden incorrecto (asumiste que el orden de entrega equivale al orden de eventos)
- Peticiones misteriosas (sin verificación de firma, así no puedes separar lo real de lo falso)
El objetivo práctico es simple: aceptar eventos reales una sola vez, rechazar los falsos y dejar una traza clara para que puedas depurar un informe de cliente en minutos.
Cómo se comportan realmente los webhooks
Un webhook es simplemente una petición HTTP que un proveedor envía a un endpoint que expones. No la ‘jalas’ como una llamada API. El emisor la empuja cuando ocurre algo, y tu trabajo es recibirla, responder rápido y procesarla con seguridad.
Una entrega típica incluye un cuerpo de petición (a menudo JSON) más cabeceras que te ayudan a validar y rastrear lo recibido. Muchos proveedores incluyen un timestamp, un tipo de evento (como invoice.paid) y un ID único de evento que puedes almacenar para detectar duplicados.
Lo que sorprende a los equipos: la entrega casi nunca es “exactamente una vez”. La mayoría de proveedores apuntan a “al menos una vez”, lo que significa que el mismo evento puede llegar varias veces, a veces con minutos u horas de diferencia.
Los reintentos ocurren por razones mundanas: tu servidor está lento o hace timeout, devuelves un 500, su red no ve tu 200, o tu endpoint quedó momentáneamente inaccesible durante despliegues o picos de tráfico.
Un timeout es especialmente complicado. Tu servidor puede recibir la petición e incluso terminar de procesarla, pero la respuesta no llega al emisor a tiempo. Desde la vista del proveedor falló, así que reintenta. Sin protecciones, procesas el mismo evento dos veces.
Un buen modelo mental es tratar la petición HTTP como un “intento de entrega”, no como “el evento”. El evento se identifica por su ID. Tu procesamiento debe basarse en ese ID, no en cuántas veces te llamaron.
Firma de webhooks en términos sencillos
La firma de webhooks es la manera en que el emisor prueba que una petición realmente vino de ellos y no fue alterada en tránsito. Sin firma, cualquiera que adivine tu URL de webhook puede enviar eventos falsos como “pago completado” o “usuario actualizado”. Peor aún, un evento real podría alterarse en la ruta (importe, ID de cliente, tipo de evento) y seguir pareciendo válido para tu app.
El patrón más común es HMAC con un secreto compartido. Ambas partes conocen el mismo valor secreto. El emisor toma el payload exacto del webhook (normalmente el cuerpo crudo), calcula un HMAC usando ese secreto y envía la firma junto al payload. Tu trabajo es recalcular el HMAC sobre los mismos bytes y comprobar que las firmas coinciden.
Los datos de la firma suelen colocarse en una cabecera HTTP. Algunos proveedores también incluyen un timestamp allí para que puedas añadir protección contra replays. Menos comúnmente, la firma se incrusta en el cuerpo JSON, lo cual es más arriesgado porque los parsers o la re-serialización pueden cambiar el formato y romper la verificación.
Al comparar firmas, no uses una comparación normal de strings. Las comparaciones básicas pueden filtrar diferencias de tiempo que ayuden a un atacante a adivinar la firma correcta tras muchos intentos. Usa una función de comparación en tiempo constante de tu lenguaje o librería criptográfica y rechaza ante cualquier discrepancia.
Si un cliente informa “su sistema aceptó un evento que nunca enviamos”, empieza por las comprobaciones de firma. Si falla la verificación de firma, probablemente hay un desajuste de secreto o estás hasheando los bytes equivocados (por ejemplo, JSON parseado en lugar del cuerpo crudo). Si pasa, puedes confiar en la identidad del emisor y pasar a deduplicar, ordenar y reintentos.
Paso a paso: verificar la firma de un webhook
El manejo fiable de webhooks comienza con una regla aburrida: verifica lo que recibiste, no lo que desearías haber recibido.
La forma segura de verificar
Captura el cuerpo de la petición en crudo exactamente como llegó. No parsees y re-serialices JSON antes de chequear la firma. Pequeñas diferencias (espacios, orden de claves, unicode) cambian los bytes y pueden hacer que firmas válidas parezcan inválidas.
Luego construye la carga exacta que tu proveedor espera que firmes. Muchos sistemas firman una cadena como timestamp + "." + raw_body. El timestamp no es decoración. Está ahí para que puedas rechazar peticiones antiguas.
Calcula el HMAC usando el secreto compartido y el hash requerido (a menudo SHA-256). Guarda el secreto en un almacén seguro y trátalo como una contraseña.
Finalmente, compara tu valor calculado con la cabecera de firma usando una comparación en tiempo constante. Si no coincide, devuelve un 4xx y detente. No “aceptes de todos modos”.
Lista de comprobación rápida:
- Lee el cuerpo como bytes una sola vez, guárdalo y usa esos mismos bytes para la verificación.
- Recrea la cadena firmada exactamente, incluidos separadores y formato del timestamp.
- Calcula HMAC con el secreto y el algoritmo correctos.
- Compara firmas de forma segura y rechaza discrepancias.
- Registra por qué falló la verificación (cabecera ausente, timestamp inválido, mismatch) sin loguear el secreto o la firma completa.
Un ejemplo rápido
Un cliente reporta “los webhooks dejaron de funcionar” después de que añadiste middleware de parsing JSON. Ves discrepancias de firma, sobre todo en payloads grandes. La solución suele ser verificar usando el cuerpo crudo antes de cualquier parsing y registrar en qué paso falló (por ejemplo, “cabecera de firma ausente” vs “timestamp fuera de la ventana permitida”). Ese detalle a menudo reduce el tiempo de depuración de horas a minutos.
Claves de idempotencia: aceptar una vez, con seguridad
Los proveedores reintentan porque la entrega no está garantizada. Tu servidor puede haber estado caído un minuto, un salto de red puede haber perdido la petición, o tu handler puede hacer timeout. El proveedor asume “quizá funcionó” y envía el mismo evento otra vez.
Una clave de idempotencia es el número de recibo que usas para reconocer un evento que ya procesaste. No es una característica de seguridad ni sustituto de la verificación de firma. Tampoco arregla condiciones de carrera a menos que la guardes y verifiques de forma segura bajo concurrencia.
Elegir la clave depende de lo que te da el proveedor. Prefiere un valor que sea estable a través de reintentos:
- Event ID (mejor cuando un evento corresponde a un cambio de negocio)
- Delivery ID o message ID (mejor cuando los reintentos mantienen el mismo identificador de entrega)
- Un hash de campos estables (último recurso si no existe ningún ID)
Cuando recibes un webhook, escribe la clave en almacenamiento primero usando una regla de unicidad para que solo una petición “gane”. Luego procesa el evento. Si ves la misma clave otra vez, devuelve éxito sin volver a hacer el trabajo.
Mantén tu “recibo” almacenado pequeño pero útil: la clave, estado de procesamiento (recibido/procesado/fallido), timestamps (primera vez visto/última vez visto) y un resumen mínimo (tipo de evento y ID del objeto relacionado). Muchos equipos retienen claves entre 7 y 30 días para cubrir reintentos tardíos y la mayoría de reportes de clientes.
Protección contra replays sin bloquear tráfico real
La protección contra replays detiene un problema simple pero desagradable: alguien captura una petición real de webhook (con firma válida) y la envía de nuevo más tarde. Si tu handler trata cada entrega como nueva, ese replay puede provocar reembolsos duplicados, invitaciones repetidas o cambios de estado repetidos.
Un enfoque común es firmar no solo el payload sino también un timestamp. Tu webhook incluye cabeceras como X-Signature y X-Timestamp. Al recibirlo, verifica la firma y también comprueba que el timestamp sea reciente dentro de una ventana corta.
El desajuste de reloj es lo que normalmente causa rechazos falsos. Tus servidores y los del emisor pueden diferir por uno o dos minutos, y las redes pueden retrasar la entrega. Mantén un margen y registra por qué rechazaste una petición.
Reglas prácticas que funcionan bien:
- Acepta solo si
abs(now - timestamp) <= window(por ejemplo, 5 minutos más un pequeño margen). - Confía en la idempotencia como la verdadera red de seguridad. Incluso dentro de la ventana, los reintentos no deberían duplicar la aplicación de cambios.
- Si rechazas por tiempo, devuelve un claro 4xx y registra el timestamp recibido y la hora de tu servidor.
Si faltan timestamps, no puedes hacer verdadera protección contra replays basada solo en tiempo. En ese caso, apoya más la idempotencia (almacena y rechaza event IDs duplicados) y considera requerir timestamps en la próxima versión del webhook.
La rotación de secretos también importa. Si rotas secretos de firma, mantén varios secretos activos por un breve periodo de solapamiento. Verifica primero contra el secreto más nuevo y luego contra los antiguos. Esto evita roturas para clientes durante el despliegue. Si tu equipo despliega endpoints rápidamente (por ejemplo, generando código con Koder.ai y usando snapshots y rollback durante despliegues), esa ventana de solapamiento ayuda porque versiones antiguas pueden seguir vivas brevemente.
Diseña el handler para que los reintentos no te perjudiquen
Los reintentos son normales. Asume que cada entrega puede duplicarse, retrasarse o llegar fuera de orden. Tu handler debe comportarse igual si ve un evento una vez o cinco veces.
Mantén la ruta de petición corta. Haz solo lo imprescindible para aceptar el evento y luego mueve el trabajo pesado a un job en background.
Un patrón simple que funciona en producción:
- Valida lo básico (método, content-type, cabeceras requeridas).
- Verifica autenticidad (firma) y rechaza lo que falle.
- Parsea y valida el payload.
- Deduplícala usando el event ID (o clave de idempotencia) en una tabla con restricción única.
- Encola el trabajo con el event ID y responde.
Devuelve 2xx solo después de haber verificado la firma y registrado el evento (o encolado). Si respondes 200 antes de guardar algo, puedes perder eventos durante un crash. Si haces trabajo pesado antes de responder, los timeouts provocan reintentos y puedes repetir efectos secundarios.
Los sistemas downstream lentos son la razón principal por la que los reintentos duelen. Si tu proveedor de email, CRM o base de datos está lento, deja que una cola absorba la demora. El worker puede reintentar con backoff y puedes alertar sobre jobs bloqueados sin bloquear al emisor.
Los eventos fuera de orden también ocurren. Por ejemplo, un subscription.updated puede llegar antes que subscription.created. Construye tolerancia comprobando el estado actual antes de aplicar cambios, permitiendo upserts y tratando “no encontrado” como motivo para reintentar más tarde (cuando tenga sentido) en lugar de como un fallo permanente.
Errores comunes que causan bugs difíciles de rastrear
Muchos problemas “aleatorios” de webhooks son autoinfligidos. Parecen redes inestables, pero se repiten en patrones, normalmente después de un deploy, rotación de secretos o un pequeño cambio en el parsing.
El bug de firma más común es hashear los bytes equivocados. Si parseas JSON primero, tu servidor puede reformatearlo (espacios, orden de claves, formato de números). Entonces verificas la firma contra un cuerpo diferente al que firmó el emisor y la verificación falla aun cuando el payload es genuino. Siempre verifica contra los bytes crudos del cuerpo exactamente como se recibieron.
La siguiente gran fuente de confusión son los secretos. Los equipos prueban en staging pero verifican con el secreto de producción por accidente, o mantienen un secreto antiguo tras rotarlo. Cuando un cliente reporta fallos “solo en un entorno”, asume primero secreto equivocado o configuración incorrecta.
Algunos errores que llevan a investigaciones largas:
- Loguear el cuerpo completo para depurar y luego filtrar tokens, emails o datos de pago en los logs.
- Devolver 500 mientras ejecutas efectos secundarios (enviar emails, actualizar pedidos). Los reintentos repetirán esos efectos.
- Usar una clave de idempotencia que no sea verdaderamente única (por ejemplo, tipo de evento + minuto). Eventos reales se marcan como “duplicados” y se pierden.
- Tratar una respuesta 2xx como “procesado” cuando tu código solo puso trabajo en cola que luego falló.
Ejemplo: un cliente dice “order.paid nunca llegó”. Ves fallos de firma que empezaron tras una refactorización que cambió el middleware de parsing de la petición. El middleware lee y re-codifica JSON, así que tu comprobación de firma ahora usa un cuerpo modificado. La corrección es simple, pero solo si sabes buscarla.
Depura fallos reportados por clientes rápidamente
Cuando un cliente dice “tu webhook no se disparó”, trátalo como un problema de trazabilidad, no como un juego de adivinanzas. Ancla en un único intento de entrega exacto del proveedor y síguelo a través de tu sistema.
Empieza obteniendo el identificador de entrega del proveedor, request ID o event ID del intento fallido. Con ese único valor deberías poder encontrar la entrada de log correspondiente rápidamente.
A partir de ahí, comprueba tres cosas en orden:
- ¿Pasó la verificación de firma?
- ¿Pasó la comprobación de timestamp o la ventana de replay (si la usas)?
- ¿La idempotencia la trató como nueva o como duplicado?
Luego confirma qué devolviste al proveedor. Un 200 lento puede ser tan malo como un 500 si el proveedor hace timeout y reintenta. Mira el código de estado, el tiempo de respuesta y si tu handler reconoció antes de hacer trabajo pesado.
Si necesitas reproducir, hazlo de forma segura: guarda una muestra cruda de la petición redactada (cabeceras clave más cuerpo crudo) y reprodúcela en un entorno de pruebas usando el mismo secreto y el mismo código de verificación.
Lista de verificación rápida que puedes ejecutar en 10 minutos
Cuando una integración de webhooks empieza a fallar “aleatoriamente”, la rapidez importa más que la perfección. Este runbook captura las causas habituales.
Extrae un ejemplo concreto primero: nombre del proveedor, tipo de evento, timestamp aproximado (con zona horaria) y cualquier event ID que el cliente pueda ver.
Luego verifica:
- La verificación de firma usa los bytes crudos del cuerpo (antes de parsear JSON) y el secreto correcto para ese entorno.
- Las comprobaciones de replay tienen sentido para el comportamiento real de reintentos (y el reloj de tu servidor está en hora).
- La idempotencia realmente deduplica (restricción única, escrita antes de procesar, retención sensata).
- Tu handler reconoce solo después de validación y grabado/encolado duradero.
- Los logs incluyen un recibo mínimo y buscable: provider, event_id, signature_ok, replay_ok, idempotency_status, response_code, latency_ms.
Si el proveedor dice “reintentamos 20 veces”, revisa patrones comunes primero: secreto equivocado (fallo de firma), drift de reloj (ventana de replay), límites de tamaño de payload (413), timeouts (sin respuesta) y ráfagas de 5xx de dependencias downstream.
Ejemplo: trazar un reporte de “evento faltante” de extremo a extremo
Un cliente escribe: “Nos faltó un evento invoice.paid ayer. Nuestro sistema nunca lo actualizó.” Aquí tienes una forma rápida de rastrearlo.
Primero, confirma si el proveedor intentó la entrega. Extrae el event ID, timestamp, URL de destino y el código de respuesta exacto que devolvió tu endpoint. Si hubo reintentos, anota la razón del primer fallo y si un reintento posterior tuvo éxito.
A continuación, valida lo que tu código vio en el borde: confirma el secreto de firma configurado para ese endpoint, recalcula la verificación de firma usando el cuerpo crudo de la petición y comprueba el timestamp de la petición respecto a tu ventana permitida.
Ten cuidado con las ventanas de replay durante reintentos. Si tu ventana es de 5 minutos y el proveedor reintenta 30 minutos después, podrías rechazar un reintento legítimo. Si esa es tu política, asegúrate de que sea intencional y esté documentada. Si no lo es, amplía la ventana o cambia la lógica para que la idempotencia siga siendo la defensa principal contra duplicados.
Si firma y timestamp lucen bien, sigue el event ID a través de tu sistema y responde: ¿lo procesaste, lo deduplicaste o lo descartaste?
Resultados comunes:
- Deduplicado: la clave de idempotencia ya existe, así que devolviste 200 sin re-ejecutar la lógica de negocio.
- Rechazado: validación fallida (desajuste de firma, timestamp muy antiguo, cabeceras faltantes).
- Timeout: el handler tardó demasiado, el proveedor lo marcó como fallido y luego reintentó.
Cuando respondas al cliente, sé conciso y específico: “Recibimos intentos de entrega a las 10:03 y 10:33 UTC. El primero hizo timeout tras 10s; el reintento fue rechazado porque el timestamp estaba fuera de nuestra ventana de 5 minutos. Ampliamos la ventana y añadimos un reconocimiento más rápido. Reenvíe el event ID X si hace falta.”
Próximos pasos: hazlo repetible
La forma más rápida de detener incendios con webhooks es hacer que cada integración siga el mismo playbook. Escribe el contrato que tú y el emisor acordáis: cabeceras requeridas, el método exacto de firma, qué timestamp se usa y qué IDs tratas como únicos.
Estandariza también lo que registras por cada intento de entrega. Un pequeño log de recibo suele ser suficiente: received_at, event_id, delivery_id, signature_valid, idempotency_result (nuevo/duplicado), handler_version y response status.
Un flujo que siga siendo útil a medida que creces:
- Mantén un endpoint de prueba dedicado que valide firmas y devuelva 2xx sin ejecutar acciones de negocio.
- Almacena el cuerpo crudo y las cabeceras clave por un breve periodo, justo el tiempo suficiente para depurar y reproducir.
- Construye un job de reprocesado a prueba de replays que vuelva a ejecutar eventos guardados por el mismo camino de handler.
- Conserva una checklist interna que soporte, QA e ingeniería sigan.
Si construyes apps en Koder.ai (koder.ai), Planning Mode es una buena forma de definir el contrato del webhook primero (cabeceras, firma, IDs, comportamiento de reintentos) y luego generar un endpoint y un registro de recibo consistente entre proyectos. Esa consistencia es lo que hace que la depuración sea rápida en lugar de heroica.
Preguntas frecuentes
¿Por qué los webhooks parecen fallar o duplicarse “aleatoriamente” en producción?
Porque la entrega de webhooks suele ser al menos una vez (at-least-once), no exactamente una vez. Los proveedores reintentan ante timeouts, respuestas 5xx y a veces cuando no ven tu 2xx a tiempo, por eso pueden aparecer duplicados, retrasos y entregas fuera de orden incluso cuando todo parece “funcionar”.
¿Cuál es el flujo más seguro para manejar una petición de webhook?
La regla básica es: verifica la firma primero, luego almacena/deduplícala, responde 2xx, y después haz el trabajo pesado de forma asíncrona.
Si haces trabajo costoso antes de responder, sufrirás timeouts y provocarás reintentos; si respondes antes de guardar nada, puedes perder eventos si hay un crash.
¿Cómo evito discrepancias de firma al verificar webhooks?
Usa los bytes crudos del cuerpo de la petición exactamente como llegaron. No conviertas JSON y lo re-serialices antes de verificar: espacios, orden de claves y formato de números pueden romper la firma.
Además, asegúrate de recrear la cadena que firma el proveedor exactamente (a menudo timestamp + "." + raw_body).
¿Qué debe hacer mi endpoint cuando falla la verificación de firma?
Devuelve un 4xx (comúnmente 400 o 401) y no proceses la carga útil.
Registra una razón mínima (cabecera de firma ausente, desajuste, ventana de tiempo inválida), pero no registres secretos ni payloads sensibles completos.
¿Qué es una clave de idempotencia para webhooks y qué valor debería usar?
Una clave de idempotencia es un identificador único y estable que guardas para que los reintentos no vuelvan a aplicar efectos secundarios.
Buenas opciones:
- Event ID (ideal cuando un evento corresponde a un cambio de negocio)
- Delivery/message ID (si permanece igual entre reintentos)
- Hash de campos estables (último recurso)
Hazla cumplir con una restricción de unicidad para que solo una petición “gane” bajo concurrencia.
¿Cómo hago deduplicado de webhooks sin condiciones de carrera?
Escribe la clave de idempotencia antes de hacer efectos secundarios, con una regla de unicidad. Luego:
- Márquela como procesada tras el éxito, o
- Registra un estado de fallo para poder reintentar de forma segura
Si la inserción falla porque la clave ya existe, devuelve 2xx y omite la acción de negocio.
¿Cómo agrego protección contra replays sin rechazar reintentos legítimos?
Incluye un timestamp en los datos firmados y rechaza peticiones fuera de una ventana corta (por ejemplo, unos minutos).
Para no bloquear reintentos legítimos:
- Permite algo de drift de reloj
- Registra la hora del servidor y el timestamp recibido al rechazar
- Considera la idempotencia como la protección principal contra duplicados; la ventana sirve para evitar replays tardíos
¿Cómo debo manejar eventos de webhook que lleguen fuera de orden?
No asumas que el orden de entrega coincide con el orden del evento. Haz los manejadores tolerantes:
- Usa upserts cuando sea posible
- Comprueba el estado actual antes de aplicar cambios
- Si no encuentras un objeto, considera reintentar más tarde (vía cola) en lugar de fallar permanentemente
Guarda el event ID y el tipo para poder razonar sobre lo ocurrido aunque el orden sea extraño.
¿Qué debo registrar para que la depuración de webhooks no sea adivinar?
Registra un pequeño “recibo” por intento de entrega para poder trazar un evento de principio a fin:
- provider, event_id, delivery_id
- signature_ok, replay_ok
- resultado de idempotencia (nuevo/duplicado)
- response_code, latency_ms
- timestamps (received/first_seen/last_seen)
Mantén los logs buscables por event ID para que soporte responda rápido a reportes de clientes.
¿Cuál es una forma rápida de investigar un reporte de cliente que “no llegó un webhook”?
Pide un identificador concreto: event ID o delivery ID, y un timestamp aproximado.
Luego revisa en este orden:
- Resultado de la verificación de firma
- Resultado de la ventana/reproducción temporal (si la usas)
- Resultado de idempotencia (nuevo vs duplicado)
- Qué respondiste (código de estado + latencia)
Si usas Koder.ai, mantén el patrón de manejador consistente (verificar → registrar/dedupe → encolar → responder). La consistencia facilita estas comprobaciones en incidentes.