Qué entiende este artículo por dominio de x86
Cuando la gente dice “x86”, normalmente se refiere a una familia de instrucciones de CPU que empezó con el chip 8086 de Intel y evolucionó durante décadas. Esas instrucciones son los verbos básicos que entiende un procesador: sumar, comparar, mover datos, y así sucesivamente. Ese conjunto de instrucciones se llama ISA (arquitectura de conjunto de instrucciones). Puedes pensar en la ISA como el “idioma” que el software debe hablar para ejecutarse en un tipo dado de CPU.
Definiciones en lenguaje llano
x86: La ISA más común usada en PCs durante la mayor parte de los últimos 40 años, implementada principalmente por Intel y también por AMD.
Compatibilidad hacia atrás: La capacidad de que computadoras más nuevas sigan ejecutando software antiguo (a veces programas de décadas) sin necesitar reescrituras importantes. No es perfecta en todos los casos, pero es una promesa guía del mundo PC: “Tus cosas deberían seguir funcionando”.
Qué significa “dominio” en este artículo
“Dominio” aquí no es solo una afirmación de rendimiento. Es una ventaja práctica y acumulativa en varias dimensiones:
- Volumen: Enormes cantidades de chips x86 enviados a escritorios, portátiles y servidores.
- Soporte de software: Uno de los catálogos más grandes de aplicaciones, juegos, software empresarial y herramientas de desarrollo construidos primero (o mejor) para x86.
- Presencia mental: La suposición por defecto—por compradores, departamentos de TI y desarrolladores—de que un “ordenador normal” es x86 a menos que se indique lo contrario.
Esa combinación importa porque cada capa refuerza a las demás. Más máquinas incentivan más software; más software incentiva más máquinas.
Cambiarse desde una ISA dominante no es como cambiar un componente por otro. Puede romper—o al menos complicar—aplicaciones, controladores (para impresoras, GPUs, dispositivos de audio, periféricos nicho), cadenas de herramientas de desarrollador, e incluso hábitos del día a día (procesos de imagen, scripts de TI, agentes de seguridad, pipelines de despliegue). Muchas de esas dependencias permanecen invisibles hasta que algo falla.
Alcance de la discusión
Este artículo se centra principalmente en PCs y servidores, donde x86 ha sido la opción por defecto durante mucho tiempo. También referencia transiciones recientes—especialmente ARM—porque ofrecen lecciones modernas y fáciles de comparar sobre qué cambia con fluidez, qué no, y por qué “simplemente recompílalo” rara vez es toda la historia.
Cómo la era del PC preparó el terreno para x86
El mercado de PCs tempranos no comenzó con un gran plan arquitectónico—comenzó con limitaciones prácticas. Las empresas querían máquinas asequibles, disponibles en volumen y fáciles de reparar. Eso empujó a los vendedores hacia CPUs y componentes que se pudieran abastecer de forma confiable, combinados con periféricos estándar, y ensamblados en sistemas sin ingeniería personalizada.
CPUs asequibles + componentes estándar
El diseño original del PC de IBM apostó por componentes comerciales y un procesador Intel de la clase 8088 relativamente barato. Esa elección importó porque hizo que el “PC” pareciera menos un producto único y más una receta: una familia de CPU, un conjunto de ranuras de expansión, un enfoque de teclado/pantalla y una pila de software reproducible.
Clones, fuentes secundarias y un mercado más grande
Una vez que el PC de IBM demostró que había demanda, el mercado se expandió mediante la clonación. Empresas como Compaq mostraron que podías construir máquinas compatibles que ejecutaban el mismo software—y venderlas a distintos precios.
Igualmente importante fue la fabricación con fuentes secundarias: múltiples proveedores podían suministrar procesadores o componentes compatibles. Para los compradores eso redujo el riesgo de apostar por un solo proveedor. Para los OEMs, aumentó la oferta y la competencia, lo que aceleró la adopción.
“Ejecuta los mismos programas” se volvió la regla de compra
En ese entorno, la compatibilidad se convirtió en la característica que la gente entendía y valoraba. Los compradores no necesitaban saber qué era una ISA; solo necesitaban saber si Lotus 1-2-3 (y más tarde las aplicaciones de Windows) se ejecutarían.
La disponibilidad de software rápidamente se convirtió en una heurística simple de compra: si ejecuta los mismos programas que otros PCs, es una elección segura.
Los estándares reforzaron el impulso en silencio
Convenciones de hardware y firmware hicieron mucho trabajo invisible. Buses comunes y enfoques de expansión—junto con expectativas de BIOS/firmware y comportamientos del sistema compartidos—facilitaron que fabricantes de hardware y desarrolladores de software apuntasen al “PC” como una plataforma estable.
Esa estabilidad ayudó a consolidar a x86 como la base por defecto bajo un ecosistema en crecimiento.
La rueda del ecosistema de software
x86 no ganó solo por velocidades de reloj o chips ingeniosos. Ganó porque el software siguió a los usuarios, y los usuarios siguieron al software—un “efecto de red” económico que se compone con el tiempo.
El efecto de red: más usuarios → más apps → más usuarios
Cuando una plataforma obtiene una ventaja temprana, los desarrolladores ven una audiencia mayor y un camino más claro hacia ingresos. Eso produce más aplicaciones, mejor soporte y más complementos de terceros. Esas mejoras hacen la plataforma aún más atractiva para la siguiente ola de compradores.
Repite ese bucle durante años y la plataforma “por defecto” se vuelve difícil de desalojar—aunque las alternativas sean técnicamente atractivas.
Esto es por qué las transiciones de plataforma no son solo construir una CPU nueva. Son recrear un ecosistema entero: apps, instaladores, canales de actualización, periféricos, procesos de TI y el saber colectivo de millones de usuarios.
Las empresas suelen mantener aplicaciones críticas durante mucho tiempo: bases de datos personalizadas, herramientas internas, complementos ERP, software específico de la industria y macros de flujo de trabajo que nadie quiere tocar porque “simplemente funcionan”. Un objetivo x86 estable significaba:
- Actualizaciones predecibles (nuevos PCs aún ejecutaban software viejo)
- Ciclos de vida de hardware más largos
- Menos sorpresas para mesas de ayuda y presupuestos de formación
Aunque una nueva plataforma prometiera menores costos o mejor rendimiento, el riesgo de romper un flujo de trabajo que genera ingresos a menudo superaba el beneficio.
Cómo las prioridades de los desarrolladores siguen a la base instalada y a los costos de soporte
Los desarrolladores rara vez optimizan por la “mejor” plataforma en el vacío. Optimizan por la plataforma que minimiza la carga de soporte y maximiza el alcance.
Si el 90% de tus clientes están en x86 Windows, ahí es donde pruebas primero, donde lanzas primero y donde corriges errores más rápido. Soportar una segunda arquitectura puede significar pipelines de compilación extra, más matrices de QA, más depuración “funciona en mi máquina” y más guiones de soporte al cliente.
El resultado es una brecha auto-reforzante: la plataforma líder tiende a obtener mejor software, más rápido.
Un ejemplo simple: software de contabilidad y controladores de impresora
Imagina una pequeña empresa. Su paquete de contabilidad es solo x86, integrado con una década de plantillas y un complemento para nómina. También dependen de una impresora de etiquetas específica y de un escáner con controladores delicados.
Ahora propone un cambio de plataforma. Incluso si las aplicaciones centrales existen, las piezas periféricas importan: el controlador de la impresora, la utilidad del escáner, el complemento PDF, el módulo de importación bancaria. Esas dependencias “aburridas” se vuelven imprescindibles—y cuando faltan o son inestables, toda la migración se estanca.
Ese es el volante en acción: la plataforma ganadora acumula la larga cola de compatibilidad de la que todos dependen en silencio.
La compatibilidad hacia atrás como estrategia de producto
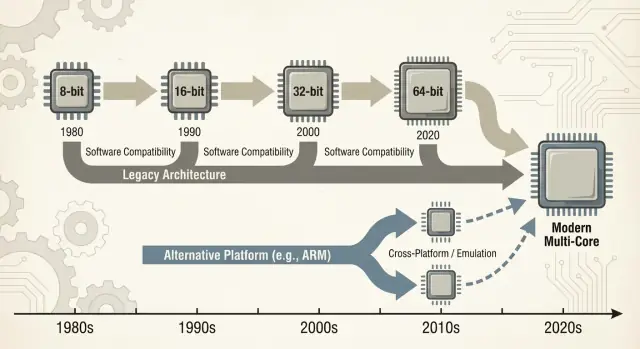
La compatibilidad hacia atrás no fue solo una característica agradable de x86—se volvió una estrategia de producto deliberada. Intel mantuvo la ISA x86 lo bastante estable para que el software escrito años antes siguiera ejecutándose, mientras cambiaba casi todo debajo.
La microarquitectura evoluciona; la ISA se mantiene en su mayoría
La distinción clave es qué se mantuvo compatible. La ISA define las instrucciones de máquina de las que dependen los programas; la microarquitectura es cómo un chip las ejecuta.
Intel pudo pasar de pipelines simples a ejecución fuera de orden, añadir caches más grandes, mejorar la predicción de saltos o introducir nuevos procesos de fabricación—sin pedir a los desarrolladores reescribir sus apps.
Esa estabilidad creó una expectativa poderosa: los PCs nuevos deberían ejecutar software viejo desde el primer día.
Añadir potencia sin romper código antiguo
x86 acumuló nuevas capacidades en capas. Extensiones del conjunto de instrucciones como MMX, SSE, AVX y características posteriores fueron aditivas: los binarios antiguos seguían funcionando, y las apps más nuevas podían detectar y usar las nuevas instrucciones cuando estaban disponibles.
Incluso las transiciones mayores se suavizaron con mecanismos de compatibilidad:
- Modos heredados que preservan entornos de ejecución anteriores (por ejemplo, compatibilidad de 16 y 32 bits en procesadores posteriores).
- Diseños con protected y long mode que permiten a los sistemas operativos modernos usar más memoria y características de seguridad mientras mantienen compatibilidad.
- Extensiones de virtualización (como Intel VT-x) que facilitaron ejecutar sistemas operativos antiguos o cargas aisladas de forma eficiente.
La compensación: el legado se vuelve una restricción
La desventaja es la complejidad. Soportar décadas de comportamiento significa más modos de CPU, más casos límite y una mayor carga de validación. Cada nueva generación debe demostrar que todavía ejecuta la aplicación, controlador o instalador de ayer.
Con el tiempo, “no romper las apps existentes” deja de ser una guía y se convierte en una restricción estratégica: protege la base instalada, pero también hace que cambios radicales de plataforma—nuevas ISAs, nuevos diseños de sistema, nuevas suposiciones—sean mucho más difíciles de justificar.
El bucle Wintel: SO, hardware e incentivos de los OEM
“Wintel” no fue solo una etiqueta pegadiza para Windows e Intel. Describió un bucle auto-reforzante donde cada parte de la industria del PC se beneficiaba al fijarse en el mismo objetivo por defecto: Windows en x86.
Por qué Windows + x86 se convirtió en el objetivo por defecto de las apps
Para la mayoría de proveedores de software de consumo y empresa, la pregunta práctica no era “¿cuál es la mejor arquitectura?” sino “¿dónde están los clientes y cómo serán las llamadas de soporte?”
Los PCs con Windows estaban ampliamente desplegados en hogares, oficinas y escuelas, y eran mayoritariamente x86. Lanzar para esa combinación maximizaba el alcance y minimizaba sorpresas.
Una vez que una masa crítica de aplicaciones asumió Windows + x86, los compradores nuevos tenían otra razón para elegirla: sus programas imprescindibles ya funcionaban allí. Eso, a su vez, hizo la plataforma aún más atractiva para la siguiente generación de desarrolladores.
OEMs, periféricos y el volante de controladores
Los fabricantes de PCs (OEMs) tienen éxito cuando pueden construir muchos modelos rápidamente, abastecer componentes de múltiples proveedores y enviar máquinas que “simplemente funcionan”. Una línea base común Windows + x86 simplificó eso.
Las empresas de periféricos siguieron el volumen. Si la mayoría de compradores usaban PCs Windows, entonces impresoras, escáneres, interfaces de audio, chips Wi‑Fi y otros dispositivos priorizarían controladores para Windows primero. Mejor disponibilidad de controladores mejoró la experiencia en PCs Windows, lo que ayudó a los OEMs a vender más unidades y mantener alto el volumen.
Las compras corporativas y gubernamentales tienden a premiar la predictibilidad: compatibilidad con apps existentes, costos de soporte manejables, garantías de proveedores y herramientas de despliegue probadas.
Incluso cuando las alternativas eran atractivas, la opción de menor riesgo a menudo ganaba porque reducía la formación, evitaba fallos en casos límite y encajaba con los procesos de TI establecidos.
El resultado no fue una conspiración sino un conjunto de incentivos alineados—cada participante eligiendo el camino que reducía fricción—creando un impulso que volvió extraordinariamente difícil el cambio de plataforma.
Una “transición de plataforma” no es solo cambiar una CPU por otra. Es una mudanza conjunta: la ISA de la CPU, el sistema operativo, el compilador/cadena de herramientas que construye apps y la pila de controladores que hace funcionar el hardware. Cambiar cualquiera de esos elementos a menudo perturba a los otros.
Las dependencias ocultas que no ves hasta que fallan
La mayoría de las roturas no son fallos dramáticos de “la app no se inicia”. Son muerte por mil cortes:
- Instaladores y actualizadores que asumen una cierta versión de Windows, disposición del registro o runtime x86.
- Protecciones de copia y gestores de licencias vinculados a IDs de hardware específicas, controladores de kernel o suposiciones de temporización de bajo nivel.
- Plugins, add-ins y extensiones (piensa en plugins CAD, VST de audio, complementos de navegador) compilados para una arquitectura.
- Macros y automatizaciones dentro de documentos Office, pantallas ERP o aplicaciones internas que dependen de rutas exactas, objetos COM o APIs obsoletas.
Incluso si la app central tiene una nueva compilación, su “pegamento” circundante puede no tenerla.
Periféricos: el bloqueador de actualización que nadie presupuestó
Impresoras, escáneres, fabricadores de etiquetas, tarjetas PCIe/USB especializadas, dispositivos médicos, equipos de punto de venta y dongles USB viven y mueren por los controladores. Si el proveedor desapareció—o simplemente no está interesado—puede no existir un controlador para el nuevo SO o arquitectura.
En muchas empresas, un dispositivo de $200 puede inmovilizar una flota de PCs de $2,000.
El problema de la larga cola de software
El mayor obstáculo suele ser herramientas internas “pequeñas”: una base de datos Access personalizada, un libro de Excel con macros, una app VB de 2009, una utilidad manufacturera nicho usada por tres personas.
No están en la hoja de ruta de producto de nadie, pero son críticas. Las transiciones fallan cuando la larga cola no se migra, prueba y no queda alguien responsable.
La economía real del cambio
Una transición de plataforma no se juzga solo por benchmarks. Se juzga por si la cuenta total—dinero, tiempo, riesgo y pérdida de impulso—permanece por debajo del beneficio percibido. Para la mayoría de personas y organizaciones, esa cuenta es más alta de lo que parece desde fuera.
La factura del usuario: tiempo, hábitos y roturas “pequeñas”
Para los usuarios, los costes de cambio comienzan con lo obvio (hardware nuevo, periféricos nuevos, garantías nuevas) y rápidamente pasan a lo enmarañado: reentrenar memoria muscular, reconfigurar flujos de trabajo y revalidar las herramientas diarias.
Aunque una app “se ejecute”, los detalles pueden cambiar: un plugin no carga, falta el controlador de la impresora, una macro se comporta diferente, un antitrampas de un juego marca algo o un accesorio nicho deja de funcionar. Cada uno es menor; juntos pueden borrar el valor de la actualización.
La factura del proveedor: expansión de QA y carga de soporte
Los proveedores pagan por las transiciones con una matriz de pruebas inflada. No es solo “¿se inicia?” Es:
- diferentes versiones de SO y canales de actualización
- diferentes generaciones y conjuntos de características de CPU
- controladores, firmware y herramientas de seguridad
- políticas empresariales y modos de bloqueo
Cada combinación extra agrega tiempo de QA, más documentación y más tickets de soporte. Una transición puede convertir una cadencia de lanzamientos predecible en un ciclo permanente de respuesta a incidentes.
La factura del desarrollador: puertos, rendimiento y confianza
Los desarrolladores absorben el coste de portar librerías, reescribir código crítico para rendimiento (a menudo optimizado a mano para una ISA) y reconstruir pruebas automatizadas. La parte más difícil es restaurar la confianza: demostrar que la nueva compilación es correcta, suficientemente rápida y estable bajo cargas reales.
El asesino oculto: coste de oportunidad
El trabajo de migración compite directamente con nuevas funciones. Si un equipo pasa dos trimestres haciendo que las cosas simplemente “funcionen de nuevo”, son dos trimestres que no pasó mejorando el producto.
Muchas organizaciones solo cambiarán cuando la plataforma vieja las bloquee—o cuando la nueva sea tan convincente que justifique ese intercambio.
Puentes: emulación, traducción y virtualización
Cuando llega una nueva arquitectura de CPU, los usuarios no preguntan por conjuntos de instrucciones; preguntan si sus apps siguen abriéndose. Por eso los “puentes” importan: permiten que máquinas nuevas ejecuten software antiguo el tiempo suficiente para que el ecosistema se ponga al día.
Emulación vs. traducción: mantener vivas las apps antiguas
Emulación imita una CPU entera en software. Es la opción más compatible, pero normalmente la más lenta porque cada instrucción se “actúa” en vez de ejecutarse directamente.
Traducción binaria (a menudo dinámica) reescribe trozos de código x86 a las instrucciones nativas de la nueva CPU mientras el programa corre. Así es como muchas transiciones modernas ofrecen una historia de día uno: instala tus apps existentes y una capa de compatibilidad traduce en silencio.
El valor es simple: puedes comprar hardware nuevo sin esperar a que cada proveedor recompilere.
Por qué nunca es perfecto
Las capas de compatibilidad tienden a funcionar mejor para aplicaciones mainstream y bien comportadas—y a tener problemas en los extremos:
- Acantilados de rendimiento: una carga puede ir bien hasta que alcanza SIMD intensivo, compiladores JIT o bucles cerrados que traducen mal.
- Casos límite: protección contra copia, suposiciones de temporización de bajo nivel o código que se auto-modifica pueden fallar.
- Controladores y componentes de kernel: puedes traducir una app, pero no puedes “traducir” un controlador de impresora faltante o una extensión de kernel obsoleta.
El soporte de hardware suele ser el verdadero bloqueador.
Virtualización: un puente parcial para software empresarial
La virtualización ayuda cuando necesitas un entorno completo legado (una versión específica de Windows, una pila Java antigua, una app de negocio). Es limpia operativamente—snapshots, aislamiento, rollback fácil—pero depende de lo que virtualices.
Las VM de misma arquitectura pueden ser casi nativas; las VM entre arquitecturas suelen caer en emulación y lentitud.
¿Cuándo es “suficientemente bueno” realmente suficiente?
Un puente suele ser suficiente para apps de oficina, navegadores y productividad diaria—donde “lo bastante rápido” gana. Es más riesgoso para:
- periféricos y controladores especializados
- pipelines de audio/video de baja latencia
- computación de alto rendimiento o gráficos pesados
En la práctica, los puentes compran tiempo—pero rara vez eliminan el trabajo de migración.
Rendimiento, consumo y mezcla de cargas de trabajo
Los argumentos sobre CPUs a menudo suenan como un marcador único: “el más rápido gana”. En realidad, las plataformas ganan cuando encajan con las restricciones de los dispositivos y las cargas que la gente ejecuta.
x86 se volvió el valor por defecto en PCs en parte porque ofrecía alto rendimiento pico con alimentación de pared, y porque la industria construyó todo lo demás bajo esa suposición.
Rendimiento pico vs eficiencia energética
Los compradores de sobremesa y portátil históricamente premiaron la contundencia interactiva: abrir apps, compilar código, jugar, hojas de cálculo pesadas. Eso empuja a los vendedores hacia altas frecuencias de ráfaga, núcleos anchos y comportamiento turbo agresivo—excelente cuando puedes gastar vatios libremente.
La eficiencia energética es otro juego. Si tu producto está limitado por batería, calor, ruido del ventilador o chasis delgado, la mejor CPU es la que hace “suficiente” trabajo por vatio, de manera consistente, sin estrangulamiento.
La eficiencia no es solo ahorrar energía; es mantenerse dentro de límites térmicos para que el rendimiento no colapse a los minutos.
Por qué lo móvil favoreció otras arquitecturas
Teléfonos y tablets viven en estrechos presupuestos de energía y siempre han sido sensibles al costo a volúmenes masivos. Ese entorno recompensó diseños optimizados en torno a eficiencia, componentes integrados y comportamiento térmico predecible.
También creó un ecosistema donde SO, apps y silicio evolucionaron juntos bajo supuestos mobile-first.
Servidores: fiabilidad y madurez ganan sobre la velocidad bruta
En centros de datos, la elección de CPU rara vez es solo una decisión de benchmarks. Los operadores valoran características de fiabilidad, ventanas largas de soporte, firmware estable, monitorización y un ecosistema maduro de controladores, hipervisores y herramientas de gestión.
Aunque una nueva arquitectura parezca atractiva en perf/vatio, el riesgo de sorpresas operativas puede superar la ventaja.
Las cargas modernas son diversas: servir web favorece alto throughput y escalado eficiente; bases de datos recompensan ancho de banda de memoria, consistencia de latencia y prácticas de ajuste probadas; la IA desplaza valor hacia aceleradores y pilas de software.
A medida que cambia la mezcla, la plataforma ganadora puede cambiar también—pero solo si el ecosistema circundante puede seguir el ritmo.
Herramientas y distribución: los guardianes silenciosos
Una nueva arquitectura de CPU puede ser técnicamente excelente y aun así fracasar si las herramientas del día a día no facilitan construir, distribuir y soportar software. Para la mayoría de equipos, “plataforma” no es solo la ISA—es todo el pipeline de entrega.
Las cadenas de herramientas deciden qué es “fácil”
Compiladores, depuradores, profileadores y librerías centrales modelan en silencio el comportamiento del desarrollador. Si las mejores banderas del compilador, trazas de pila, sanitizadores o herramientas de rendimiento llegan tarde (o se comportan distinto), los equipos dudan en confiar lanzamientos en ellas.
Incluso pequeñas lagunas importan: una librería faltante, un plugin de depurador inestable o una CI más lenta puede convertir “podríamos portar esto” en “no lo haremos este trimestre”. Cuando la cadena x86 es la predeterminada en IDEs, sistemas de build y plantillas CI, el camino de menor resistencia sigue tirando a los desarrolladores hacia atrás.
La distribución es fricción, no teoría
El software llega a usuarios mediante convenciones de empaquetado: instaladores, actualizadores, repositorios, tiendas de apps, contenedores y binarios firmados. Un cambio de plataforma obliga a preguntas incómodas:
- ¿Enviamos builds separadas (x86 y ARM), un paquete “universal” o dependemos de la traducción?
- ¿Los plugins/controladores siguen instalándose sin problemas?
- ¿La firma de código, la notarización y las actualizaciones automáticas son consistentes entre arquitecturas?
Si la distribución se complica, los costos de soporte se disparan—y muchos proveedores lo evitarán.
La gestión empresarial es una puerta difícil
Las empresas compran plataformas que pueden gestionar a escala: imaging, enrolamiento de dispositivos, políticas, seguridad de endpoints, agentes EDR, clientes VPN y reportes de cumplimiento. Si alguna de esas herramientas queda rezagada en una nueva arquitectura, los pilotos se estancan.
“Funciona en mi máquina” es irrelevante si TI no puede desplegarla y asegurarla.
La métrica real: velocidad de envío
Desarrolladores y TI convergen en una pregunta práctica: ¿qué tan rápido podemos enviar y soportar? Las herramientas y la distribución a menudo responden eso con más contundencia que los benchmarks.
Una forma práctica en que los equipos reducen la fricción de migración es acortando el tiempo entre una idea y un build comprobable—especialmente al validar la misma app en entornos diferentes (x86 vs. ARM, imágenes de SO distintas o objetivos de despliegue diferentes).
Plataformas como Koder.ai encajan en este flujo permitiendo a los equipos generar e iterar aplicaciones reales vía una interfaz de chat—comúnmente produciendo frontends web en React, backends en Go y bases de datos PostgreSQL (y Flutter para móvil). Para trabajo de transición de plataforma, dos capacidades son especialmente relevantes:
- Prototipado rápido y reconstrucciones cuando necesitas recrear herramientas internas, paneles administrativos o utilidades de la “cola larga” sin un propietario claro.
- Snapshots y rollback para probar cambios de forma segura mientras gestionas múltiples arquitecturas, cadenas de herramientas y entornos de despliegue.
Porque Koder.ai soporta exportación de código fuente, también puede servir de puente entre la experimentación y un pipeline de ingeniería convencional—útil cuando necesitas moverte rápido pero terminar con código mantenible bajo tu propio control.
Lecciones recientes de las transiciones ARM
El empuje de ARM hacia portátiles y desktops es un control de realidad útil sobre lo difíciles que son realmente las transiciones de plataforma. En papel, la propuesta es simple: mejor rendimiento por vatio, máquinas más silenciosas, mayor duración de batería.
En la práctica, el éxito depende menos del núcleo de la CPU y más de todo lo que la envuelve—apps, controladores, distribución y quién tiene la capacidad de alinear incentivos.
Apple: el control reduce lo “desconocido”
El paso de Apple de Intel a Apple Silicon funcionó en gran medida porque Apple controla la pila completa: diseño de hardware, firmware, sistema operativo, herramientas de desarrollador y canales principales de distribución de apps.
Ese control permitió a la compañía hacer un corte limpio sin esperar a que docenas de socios se movieran al mismo tiempo.
También posibilitó un periodo de “puente” coordinado: los desarrolladores obtuvieron objetivos claros, los usuarios vías de compatibilidad y Apple pudo presionar a proveedores clave para lanzar builds nativas. Incluso cuando algunas apps no eran nativas, la experiencia de usuario a menudo se mantuvo aceptable porque el plan de transición fue diseñado como producto, no solo como un intercambio de procesador.
Windows en ARM: socios, timing y lagunas
Windows-on-ARM muestra el otro lado. Microsoft no controla completamente el ecosistema de hardware, y los PCs Windows dependen mucho de elecciones de OEM y de una larga cola de controladores de dispositivos.
Eso crea puntos de fallo comunes:
- Controladores: impresoras, interfaces de audio, periféricos empresariales y dispositivos corporativos “únicos” pueden bloquear la adopción.
- Huecos de apps: algunas herramientas profesionales llegan tarde (o nunca), y plugins/add-ons pueden ser el bloqueador oculto.
- Tiempo de incentivos: los OEMs no apostarán fuerte sin demanda, pero los usuarios no demandarán dispositivos hasta que la compatibilidad parezca segura.
Conclusión: las transiciones ganadoras son organizacionales, no solo técnicas
El progreso reciente de ARM refuerza una lección central: controlar más de la pila hace las transiciones más rápidas y menos fragmentadas.
Si dependes de socios, necesitas coordinación inusualmente fuerte, planes de actualización claros y una razón para que cada participante—proveedor de chips, OEM, desarrollador y comprador de TI—priorice la migración al mismo tiempo.
Las transiciones de plataforma fracasan por razones aburridas: la plataforma vieja todavía funciona, todos ya la pagaron (en dinero y hábitos) y los “casos límite” son donde viven los negocios reales.
Señales de que una transición puede consolidarse
Una nueva plataforma suele ganar solo cuando tres cosas coinciden:
Primero, el beneficio es obvio para compradores normales—no solo ingenieros: mejor batería, costes materialmente más bajos, nuevos factores de forma o un salto en rendimiento para tareas comunes.
Segundo, existe un plan de compatibilidad creíble: gran emulación/traducción, builds “universales” fáciles y caminos claros para controladores, periféricos y herramientas empresariales.
Tercero, los incentivos se alinean a lo largo de la cadena: proveedor de SO, fabricante de chips, OEMs y desarrolladores ven ventajas y tienen motivos para priorizar la migración.
Cómo las empresas reducen el riesgo
Las transiciones exitosas se parecen menos a un interruptor y más a una superposición controlada. Despliegues por fases (grupos piloto primero), builds duales (viejo + nuevo) y telemetría (tasas de fallo, rendimiento, uso de características) permiten detectar problemas temprano.
Igualmente importante: una ventana de soporte publicada para la plataforma vieja, plazos internos claros y un plan para usuarios que “no pueden moverse aún”.
Lista práctica antes de cambiar
- Prueba tus apps críticas (incluyendo plugins y macros), no solo el software de portada.
- Valida periféricos y controladores: docks, impresoras, escáneres, interfaces de audio, llaves de seguridad.
- Confirma seguridad y gestión: cifrado de disco, EDR, VPN, gestión de dispositivos, políticas de cumplimiento.
- Corre pruebas de rendimiento que reflejen tu carga (tiempos de compilación, exportaciones, análisis de datos), además de batería y termales.
Una visión equilibrada
x86 aún tiene un impulso masivo: décadas de compatibilidad, flujos de trabajo empresariales arraigados y amplias opciones de hardware.
Pero la presión aumenta por nuevas necesidades—eficiencia energética, integración más estrecha, computo enfocado en IA y flotas de dispositivos más sencillas. Las batallas más difíciles no se tratan del rendimiento bruto; se tratan de hacer que el cambio se sienta seguro, predecible y que merezca la pena.