Joe Armstrong y Erlang: dejar que falle para plataformas fiables
Descubre cómo Joe Armstrong moldeó la concurrencia, la supervisión y la mentalidad “let it crash” de Erlang: ideas que aún se usan para construir servicios en tiempo real dependibles.
Qué cubre este post (y por qué sigue importando)
Joe Armstrong no solo ayudó a crear Erlang: se convirtió en su explicador más claro y persuasivo. A través de charlas, artículos y un punto de vista pragmático, popularizó una idea simple: si quieres software que se mantenga en pie, diseñas para la falla en lugar de fingir que puedes evitarla.
Este post es un recorrido guiado por la mentalidad Erlang y por qué sigue importando cuando construyes plataformas fiables en tiempo real: cosas como sistemas de chat, enrutamiento de llamadas, notificaciones en vivo, coordinación multijugador e infraestructura que debe responder rápido y de forma consistente incluso cuando partes se comportan mal.
“Tiempo real” en términos sencillos
“Tiempo real” no siempre significa “microsegundos” o “plazos duros”. En muchos productos significa:
- respuestas rápidas que el usuario percibe (sin pausas misteriosas)
- comportamiento predecible bajo carga (puede ralentizarse, pero no descontrolarse)
- servicio continuo durante fallos parciales (un componente defectuoso no debería tumbarlo todo)
Erlang se diseñó para sistemas de telecomunicaciones donde estas expectativas no son negociables, y esa presión moldeó sus ideas más influyentes.
Los tres pilares en los que nos centraremos
En lugar de sumergirnos en la sintaxis, nos enfocaremos en los conceptos que hicieron famoso a Erlang y que reaparecen en el diseño moderno de sistemas:
- Concurrencia por defecto: construye software a partir de muchos trabajadores pequeños e aislados en vez de unos pocos gigantes.
- Tolerancia a fallos como objetivo de diseño: asume que habrá bugs, timeouts y caídas, y planifica qué debe ocurrir después.
- “Let it crash”: no sobreprotejas cada línea de código; falla rápido y recupérate limpiamente usando estructura (no heroicidades).
A lo largo del texto conectaremos estas ideas con el modelo actor y el paso de mensajes, explicaremos los árboles de supervisión y OTP en términos accesibles, y mostraremos por qué la VM BEAM hace que todo el enfoque sea práctico.
Aunque no uses Erlang (y nunca lo hagas), la idea sigue siendo útil: el marco de Armstrong te da una lista de verificación poderosa para construir sistemas que siguen respondiendo y disponibles cuando la realidad se complica.
La motivación de Joe Armstrong: construir sistemas que se mantengan activos
Los conmutadores de telecom y las plataformas de enrutamiento de llamadas no pueden “apagarse para mantenimiento” como muchos sitios web. Se espera que sigan gestionando llamadas, eventos de facturación y tráfico de señalización las 24 horas, a menudo con requisitos estrictos de disponibilidad y tiempos de respuesta predecibles.
Erlang nació dentro de Ericsson a finales de los años 80 como un intento de abordar esas realidades con software, no solo con hardware especializado. Joe Armstrong y sus colegas no perseguían la elegancia por sí misma; intentaban construir sistemas en los que los operadores pudieran confiar bajo carga constante, fallos parciales y condiciones reales desordenadas.
Qué significaba “fiable” en la práctica
Un cambio clave de mentalidad es que fiabilidad no es lo mismo que “nunca fallar”. En sistemas grandes y de larga duración, algo fallará: un proceso recibirá una entrada inesperada, un nodo se reiniciará, un enlace de red titilará o una dependencia se quedará bloqueada.
Así que el objetivo pasa a ser:
- seguir atendiendo a los usuarios incluso cuando partes se comportan mal
- detectar fallos rápidamente
- recuperarse automáticamente con mínima intervención humana
- aislar fallos para que un bug no derribe todo
Esta mentalidad es la que hace que ideas como los árboles de supervisión y “let it crash” parezcan razonables: diseñas la falla como un evento normal, no como una catástrofe excepcional.
Menos mito, más resolución de problemas
Es tentador contar la historia como el descubrimiento de un solitario visionario. La visión más útil es más simple: las restricciones de telecom forzaron un conjunto diferente de compensaciones. Erlang priorizó concurrencia, aislamiento y recuperación porque eran las herramientas prácticas necesarias para mantener servicios en funcionamiento mientras el mundo cambiaba a su alrededor.
Ese encuadre orientado al problema es también la razón por la que las lecciones de Erlang se traducen bien hoy: en cualquier sitio donde la disponibilidad y la recuperación rápida importen más que la prevención perfecta.
Concurrencia como defecto: muchos trabajadores pequeños
Una idea central en Erlang es que “hacer muchas cosas a la vez” no es una característica especial que añades más tarde: es la forma normal de estructurar un sistema.
Procesos ligeros, explicado simplemente
En Erlang, el trabajo se divide en muchos “procesos” diminutos. Piénsalos como pequeños trabajadores, cada uno responsable de una tarea: manejar una llamada, rastrear una sesión de chat, monitorizar un dispositivo, reintentar un pago o vigilar una cola.
Son ligeros, lo que significa que puedes tener enormes cantidades de ellos sin necesidad de hardware gigante. En lugar de un trabajador pesado intentando malabarismos, tienes una multitud de trabajadores focalizados que pueden arrancar rápido, detenerse rápido y reemplazarse rápido.
Por qué “un gran programa” falla de forma distinta
Muchos sistemas están diseñados como un solo gran programa con muchas partes estrechamente conectadas. Cuando ese tipo de sistema encuentra un bug serio, un problema de memoria o una operación bloqueante, la falla puede propagarse: como disparar un interruptor y dejar a todo el edificio sin luz.
Erlang empuja hacia lo contrario: aislar responsabilidades. Si un trabajador pequeño se comporta mal, puedes apagar y reemplazar ese trabajador sin derribar trabajo no relacionado.
Paso de mensajes como “enviar notas”
¿Cómo se coordinan estos trabajadores? No hurgan en el estado interno de los demás. Se envían mensajes: más parecido a pasar notas que a compartir una pizarra desordenada.
Un trabajador puede decir “Aquí hay una nueva petición”, “Este usuario se desconectó” o “Inténtalo de nuevo en 5 segundos”. El receptor lee la nota y decide qué hacer.
El beneficio clave es la contención: como los trabajadores están aislados y se comunican por mensajes, las fallas tienden a no propagarse por todo el sistema.
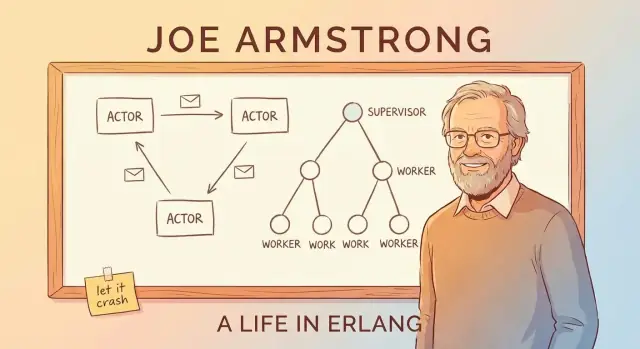
Paso de mensajes y el modelo actor (sin jerga)
Una forma simple de entender el “modelo actor” de Erlang es imaginar un sistema formado por muchos pequeños trabajadores independientes.
Actores: trabajadores diminutos que solo hablan enviando mensajes
Un actor es una unidad autocontenida con su propio estado privado y un buzón. Hace tres cosas básicas:
- recibe mensajes (uno a la vez) desde su buzón
- actualiza su propio estado interno
- envía mensajes a otros actores
Eso es todo. No hay variables compartidas ocultas ni “meter la mano” en la memoria de otro trabajador. Si un actor necesita algo de otro, lo pide enviando un mensaje.
Por qué evitar el estado compartido elimina categorías enteras de bugs
Cuando varios hilos comparten los mismos datos, surgen condiciones de carrera: dos cosas cambian el mismo valor casi al mismo tiempo y el resultado depende del timing. Ahí es donde los bugs son intermitentes y difíciles de reproducir.
Con el paso de mensajes, cada actor posee sus datos. Otros actores no pueden mutarlos directamente. Esto no elimina todos los bugs, pero reduce mucho los problemas causados por accesos simultáneos al mismo trozo de estado.
Retropresión, explicado como una cola en una cafetería
Los mensajes no llegan “gratis”. Si un actor recibe mensajes más rápido de lo que puede procesarlos, su buzón (cola) crece. Eso es la retropresión: el sistema te está diciendo, indirectamente, “esta parte está sobrecargada”.
En la práctica, monitorizas el tamaño de los buzones y construyes límites: descargar trabajo, agrupar, muestrear o distribuir la carga a más actores en lugar de dejar que las colas crezcan sin control.
Un ejemplo concreto: notificaciones de chat
Imagina una app de chat. Cada usuario podría tener un actor responsable de entregar notificaciones. Cuando un usuario se desconecta, los mensajes siguen llegando, y el buzón crece. Un sistema bien diseñado podría limitar la cola, descartar notificaciones no críticas o cambiar a modo digest, en lugar de dejar que un usuario lento degrade todo el servicio.
“Let It Crash” explicado: falla rápido, recupérate más rápido
“Let it crash” no es un lema para ingeniería descuidada. Es una estrategia de confiabilidad: cuando un componente entra en un estado malo o inesperado, debe pararse de forma rápida y ruidosa en vez de arrastrarse.
Qué significa realmente
En lugar de escribir código que intente manejar cada caso borde dentro de un solo proceso, Erlang fomenta mantener cada trabajador pequeño y enfocado. Si ese trabajador encuentra algo que realmente no puede manejar (estado corrupto, suposiciones violadas, entrada inesperada), sale. Otra parte del sistema se encarga de volver a ponerlo en marcha.
Esto cambia la pregunta principal de “¿Cómo prevenimos la falla?” a “¿Cómo nos recuperamos limpiamente cuando ocurre la falla?”.
La compensación: menos controles defensivos, lógica más clara
La programación defensiva en todas partes puede convertir flujos sencillos en un laberinto de condicionales, reintentos y estados parciales. “Let it crash” intercambia parte de esa complejidad dentro del proceso por:
- caminos de código más simples y legibles
- detección más rápida de suposiciones rotas
- recuperación consistente (porque está centralizada)
La gran idea es que la recuperación debe ser predecible y repetible, no improvisada dentro de cada función.
Cuándo encaja —y cuándo no
Encaja mejor cuando los fallos son recuperables y aislados: un problema temporal de red, una petición mala, un trabajador atascado, un timeout de terceros.
No encaja bien cuando un crash puede causar un daño irreversible, como:
- pérdida de datos sin una fuente de verdad durable
- operaciones críticas para la seguridad donde “inténtalo de nuevo” no es aceptable
Reinicios rápidos y estado conocido-bueno
Chocar solo ayuda si volver es rápido y seguro. En la práctica eso significa reiniciar trabajadores en un estado conocido-bueno: recargando configuración, reconstruyendo caches en memoria desde almacenamiento durable y reanudando trabajo sin fingir que el estado roto nunca existió.
Árboles de supervisión: diseñar la falla a propósito
La idea de “let it crash” solo funciona porque las caídas no se dejan al azar. El patrón clave es el árbol de supervisión: una jerarquía donde supervisores actúan como gerentes y trabajadores hacen el trabajo real (atender una llamada, manejar una sesión, consumir una cola, etc.). Cuando un trabajador se comporta mal, el gerente lo detecta y lo reinicia.
Gerentes que reinician trabajadores
Un supervisor no intenta “arreglar” un trabajador roto en el lugar. En su lugar, aplica una regla simple y consistente: si el trabajador muere, arranca uno nuevo. Eso hace que la ruta de recuperación sea predecible y reduce la necesidad de manejo de errores ad hoc repartido por el código.
Igualmente importante, los supervisores pueden decidir no reiniciar: si algo está fallando con demasiada frecuencia, puede indicar un problema más profundo, y reiniciarlo repetidamente puede empeorar la situación.
Estrategias de reinicio (a alto nivel)
La supervisión no es única para todos. Estrategias comunes incluyen:
- One-for-one: solo se reinicia el trabajador que falló. Encaja con tareas independientes donde una falla no debe afectar a otras.
- Reinicio en grupo: si falla un trabajador, se reinicia un conjunto relacionado. Sirve para componentes fuertemente acoplados que deben mantenerse sincronizados.
Dependencias: la parte que debes pensar
Un buen diseño de supervisión empieza con un mapa de dependencias: qué componentes dependen de cuáles y qué significa realmente un “inicio limpio” para cada uno.
Si un manejador de sesión depende de un proceso de cache, reiniciar solo el manejador podría dejarlo conectado a un estado malo. Agruparlos bajo el supervisor adecuado (o reiniciarlos juntos) convierte modos de fallo confusos en comportamientos de recuperación consistentes y repetibles.
OTP: bloques reutilizables para servicios fiables
Si Erlang es el lenguaje, OTP (Open Telecom Platform) es la caja de piezas que convierte “let it crash” en algo que puedes ejecutar en producción durante años.
OTP como caja de herramientas de patrones probados
OTP no es una sola librería: es un conjunto de convenciones y componentes listos (llamados behaviours) que resuelven las partes aburridas-pero-críticas de construir servicios:
gen_serverpara un trabajador de larga duración que mantiene estado y maneja peticiones una a unasupervisorpara reiniciar automáticamente trabajadores fallidos según reglas clarasapplicationpara definir cómo arranca, para y encaja un servicio en una release
No son “magia”. Son plantillas con callbacks bien definidos, para que tu código encaje en una forma conocida en vez de inventar una nueva en cada proyecto.
Por qué los patrones estándar superan frameworks personalizados
Los equipos a menudo construyen workers ad hoc, hooks de monitorización caseros y lógica de reinicio única. Funciona—hasta que no. OTP reduce ese riesgo empujando a todos hacia la misma vocabulario y ciclo de vida. Cuando entra un ingeniero nuevo, no necesita aprender tu framework personalizado primero; puede apoyarse en patrones compartidos ampliamente entendidos en el ecosistema Erlang.
Cómo OTP guía la arquitectura día a día
OTP te empuja a pensar en roles de proceso y responsabilidades: qué es un trabajador, qué es un coordinador, qué debe reiniciar a qué y qué nunca debe reiniciarse automáticamente.
También fomenta buena higiene: nombres claros, orden de arranque explícito, apagado predecible y señales de monitorización integradas. El resultado son sistemas diseñados para ejecutarse continuamente: servicios que pueden recuperarse de fallos, evolucionar con el tiempo y seguir haciendo su trabajo sin supervisión humana constante.
BEAM VM: el runtime que hace práctico el modelo
Las grandes ideas de Erlang —procesos diminutos, paso de mensajes y “let it crash”— serían mucho más difíciles de usar en producción sin la máquina virtual BEAM. BEAM es el runtime que hace que estos patrones se sientan naturales, no frágiles.
Planificación: equidad sobre “un hilo grande”
BEAM está construida para ejecutar un gran número de procesos ligeros. En vez de depender de unos pocos hilos del SO y esperar que la aplicación se comporte, BEAM planifica los procesos de Erlang por sí misma.
El beneficio práctico es la capacidad de respuesta bajo carga: el trabajo se divide en trozos pequeños y se rota de forma justa, de modo que ningún trabajador ocupado domine el sistema por mucho tiempo. Eso encaja perfectamente con un servicio hecho de muchas tareas independientes: cada una hace un poco de trabajo y cede el paso.
Aislamiento y limpieza de memoria por proceso
Cada proceso Erlang tiene su propia heap y su propia recolección de basura. Ese es un detalle clave: limpiar memoria en un proceso no requiere pausar todo el programa.
Igualmente importante, los procesos están aislados. Si uno falla, no corrompe la memoria de los demás y la VM sigue viva. Este aislamiento es la base que hace realistas los árboles de supervisión: la falla se contiene y luego la maneja el reinicio del componente fallido en lugar de derribar todo.
Distribución: varios nodos, un sistema
BEAM también soporta la distribución de forma directa: puedes ejecutar múltiples nodos Erlang (instancias separadas de la VM) y permitir que se comuniquen enviando mensajes. Si has entendido “los procesos hablan por mensajes”, la distribución es una extensión de la misma idea: algunos procesos simplemente viven en otro nodo.
BEAM no promete velocidad extrema. Promete que la concurrencia, la contención de fallos y la recuperación sean el valor por defecto, de modo que la historia de fiabilidad sea práctica y no solo teórica.
Actualizaciones sin detener el sistema (código caliente, con cuidado)
Uno de los trucos más comentados de Erlang es el hot code swapping: actualizar partes de un sistema en ejecución con mínima downtime (cuando el runtime y las herramientas lo permiten). La promesa práctica no es “nunca volver a reiniciar”, sino “enviar correcciones sin convertir un fallo breve en una interrupción larga”.
Qué significa realmente “código caliente”
En Erlang/OTP, el runtime puede mantener dos versiones de un módulo cargadas a la vez. Los procesos existentes pueden terminar usando la versión antigua mientras las nuevas llamadas empiezan a usar la nueva. Eso te da espacio para parchear un bug, desplegar una característica o ajustar comportamiento sin desconectar a todo el mundo.
Si se hace bien, esto apoya directamente objetivos de fiabilidad: menos reinicios completos, ventanas de mantenimiento más cortas y recuperación más rápida cuando algo se cuela en producción.
Las restricciones que nadie debe ignorar
No todos los cambios son seguros para intercambiar en caliente. Algunos ejemplos de cambios que requieren cuidado extra (o un reinicio) incluyen:
- cambios en la forma del estado (un proceso espera datos en un formato y el código nuevo espera otro)
- cambios de protocolo o formato de mensajes que deben coincidir entre servicios
- migraciones de esquema que requieren tiempo o coordinación
Erlang provee mecanismos para transiciones controladas, pero aun así debes diseñar la ruta de actualización.
La mentalidad: actualizaciones y rollback como rutina
Las actualizaciones en caliente funcionan mejor cuando las actualizaciones y los rollbacks se tratan como operaciones rutinarias, no como emergencias raras. Eso significa planear versionado, compatibilidad y una ruta clara de “deshacer” desde el inicio. En la práctica, los equipos combinan técnicas de live-upgrade con despliegues por fases, checks de salud y recuperación basada en supervisión.
Aunque nunca uses Erlang, la lección se traslada: diseña sistemas para que cambiarlos de forma segura sea un requisito de primera clase, no un pensamiento posterior.
Dónde brillan las ideas de Erlang en plataformas en tiempo real
Las plataformas en tiempo real se tratan menos de temporización perfecta y más de mantenerse responsivas mientras las cosas fallan constantemente: las redes titilan, las dependencias se ralentizan y el tráfico de usuarios hace picos. El diseño de Erlang —defendido por Joe Armstrong— encaja con esa realidad porque asume la falla y trata la concurrencia como algo normal, no excepcional.
Casos de uso comunes en “tiempo real”
Verás el pensamiento al estilo Erlang brillar donde hay muchas actividades independientes ocurriendo a la vez:
- Mensajería y chat: millones de conversaciones pequeñas, cada una con su propio estado y reintentos.
- Comunicación en tiempo real: señalización de voz/video, actualizaciones de presencia y coordinación de sesiones.
- Coordinación IoT: flotas de dispositivos que registran, se desconectan y reaparecen de forma impredecible.
- Flujos de pagos: procesos multi-paso donde algunos pasos son lentos, no están disponibles o requieren acciones compensatorias.
Qué suele significar “soft real-time”
La mayoría de productos no necesitan garantías estrictas como “cada acción completa en 10 ms”. Necesitan tiempo real blando: latencia consistentemente baja para peticiones típicas, recuperación rápida cuando partes fallan y alta disponibilidad para que los usuarios noten raramente incidentes.
La falla es normal: diseña para ello
Los sistemas reales sufren problemas como:
- Conexiones perdidas (redes móviles, cambios de Wi‑Fi)
- Timeouts cuando un servicio downstream es lento
- Fallos parciales donde una región o dependencia se degrada
El modelo de Erlang promueve aislar cada actividad (una sesión de usuario, un dispositivo, un intento de pago) para que un fallo no se propague. En lugar de construir un gran componente que “lo intente todo”, los equipos razonan en unidades más pequeñas: cada trabajador hace un trabajo, habla por mensajes y si se rompe, se reinicia limpio.
Ese cambio —de “prevenir cada fallo” a “contener y recuperarse rápidamente”— es a menudo lo que hace que las plataformas en tiempo real se sientan estables bajo presión.
Malentendidos comunes y límites reales
La reputación de Erlang puede sonar como una promesa: sistemas que nunca caen porque simplemente se reinician. La realidad es más práctica —y más útil. “Let it crash” es una herramienta para construir servicios dependibles, no una excusa para ignorar problemas difíciles.
Los reinicios no son un parche
Un error común es tratar la supervisión como una forma de ocultar bugs profundos. Si un proceso choca inmediatamente después de arrancar, un supervisor puede seguir reiniciándolo hasta que entres en un crash loop—consumiendo CPU, llenando logs y potencialmente causando una caída mayor que el bug original.
Los sistemas sanos añaden backoff, límites de intensidad de reinicio y comportamiento claro de “rendirse y escalar”. Los reinicios deben restaurar operación saludable, no enmascarar un invariante roto.
El estado es la parte difícil
Reiniciar un proceso suele ser fácil; recuperar el estado correcto no lo es. Si el estado vive solo en memoria, debes decidir qué significa “correcto” después de un crash:
- ¿Reconstruir desde un almacén durable?
- ¿Puedo reproducir eventos de forma segura (idempotencia)?
- ¿Qué pasa con trabajo en vuelo o actualizaciones parcialmente aplicadas?
La tolerancia a fallos no reemplaza un diseño cuidadoso de datos. Te obliga a ser explícito al respecto.
Aún necesitas observabilidad
Los crashes solo ayudan si puedes verlos temprano y entenderlos. Eso significa invertir en logs, métricas y trazas—no solo “se reinició, así que estamos bien”. Quieres notar tasas de reinicio crecientes, colas que aumentan y dependencias lentas antes de que los usuarios lo noten.
Existen límites operativos reales
Incluso con las fortalezas de BEAM, los sistemas pueden fallar de maneras muy ordinarias:
- Crecimiento de memoria por fugas, caches o heaps grandes
- Acumulación en el buzón cuando productores superan consumidores (picos de latencia y timeouts)
- Fallos de dependencias (bases de datos, APIs de terceros, DNS) donde reiniciar tu código no arregla la causa raíz
El modelo de Erlang te ayuda a contener y recuperarte, pero no elimina los fallos.
Cómo aplicar las lecciones hoy (incluso si no usas Erlang)
El mayor regalo de Erlang no es la sintaxis: son hábitos para construir servicios que siguen funcionando cuando partes inevitablemente fallan. Puedes aplicar esos hábitos en casi cualquier stack.
Traducir las ideas en acciones concretas
Empieza por hacer explícitos los límites de falla. Divide tu sistema en componentes que puedan fallar independientemente y asegúrate de que cada uno tenga un contrato claro (entradas, salidas y qué significa “mal”).
Luego automatiza la recuperación en lugar de intentar prevenir cada error:
- Aisla componentes: ejecuta trabajo arriesgado en procesos/contenedores/hilos separados para que un fallo no envenene todo.
- Define límites: timeouts, reintentos con backoff, circuit breakers y bulkheads para detener fallos en cascada.
- Haz la recuperación rutinaria: health checks, reinicios automáticos y valores por defecto seguros para que el sistema vuelva a un estado conocido-bueno rápidamente.
Una forma práctica de convertir estos hábitos en realidad es integrarlos en las herramientas y el ciclo de vida, no solo en el código. Por ejemplo, cuando equipos usan Koder.ai para vibe-code web, backend o apps móviles vía chat, el flujo naturalmente fomenta planificación explícita (Planning Mode), despliegues repetibles y iteración segura con snapshots y rollback—conceptos alineados con la misma mentalidad operacional que Erlang popularizó: asume que el cambio y la falla pasarán, y haz que la recuperación sea aburrida.
Puntos de partida fuera de Erlang
Puedes aproximar patrones de “supervisión” con herramientas que ya uses:
- Supervisores: systemd, Deployments de Kubernetes o un process manager (reinicio al fallar, probes de readiness).
- Aislamiento de procesos: servicios worker separados para tareas CPU-intensivas o no confiables.
- Paso de mensajes: colas/streams (RabbitMQ, SQS, Kafka) para desacoplar productores y consumidores y suavizar picos.
Lista de verificación rápida de decisión
Antes de copiar patrones, decide qué necesitas realmente:
- Modos de fallo esperados: sobrecarga, fallos parciales, dependencias lentas, entradas malas, fugas de memoria.
- Necesidades de latencia: ¿requieres respuestas en tiempo real o el procesamiento eventual es suficiente?
- Objetivo de recuperación: reinicio rápido, degradación elegante o intervención manual?
- Habilidades y herramientas del equipo: ¿quién hará on-call, observabilidad y respuesta a incidentes?
Si quieres pasos prácticos siguientes, consulta más guías en /blog, o revisa detalles de implementación en /docs (y planes en /pricing si evalúas herramientas).
Preguntas frecuentes
¿Por qué sigue siendo relevante hoy la mentalidad de Joe Armstrong sobre Erlang?
Erlang popularizó una mentalidad práctica de confiabilidad: asume que partes fallarán y diseña qué ocurre después.
En lugar de intentar prevenir cada caída, enfatiza la aislación de fallos, la detección rápida y la recuperación automática, lo que encaja bien con plataformas en tiempo real como chat, enrutamiento de llamadas, notificaciones y servicios de coordinación.
¿Qué significa “tiempo real” en los términos sencillos del artículo?
En este contexto, “tiempo real” suele entenderse como soft real-time o tiempo real “blando”:
- respuestas que se sienten rápidas y consistentes
- comportamiento predecible bajo carga
- el sistema sigue funcionando ante fallos parciales
No se trata tanto de plazos de microsegundos como de evitar bloqueos, espirales y fallos en cascada.
¿Qué significa “concurrencia por defecto” en el diseño al estilo Erlang?
“Concurrencia por defecto” significa estructurar el sistema como muchos trabajadores pequeños e independientes en lugar de unos pocos componentes grandes y fuertemente acoplados.
Cada trabajador atiende una responsabilidad estrecha (una sesión, un dispositivo, una llamada, un bucle de reintentos), lo que facilita escalar y contener fallos.
¿Qué son los “procesos ligeros” de Erlang y por qué importan?
Los procesos ligeros son pequeños trabajadores independientes que puedes crear en gran número.
En la práctica ayudan porque:
- puedes modelar un proceso por “cosa” (usuario/sesión/dispositivo)
- los fallos permanecen locales a un solo trabajador
- reiniciar trabajo es barato comparado con reiniciar un monolito
¿Por qué Erlang prefiere el paso de mensajes sobre el estado compartido?
El paso de mensajes es la coordinación mediante envío de mensajes, no compartiendo estado mutable.
Esto reduce clases enteras de errores de concurrencia (como condiciones de carrera) porque cada trabajador posee su estado interno; otros solo pueden pedir cambios indirectamente mediante mensajes.
¿Qué es la retropresión en un sistema de actores/mensajes y cómo se gestiona?
La retropresión (back-pressure) ocurre cuando un trabajador recibe mensajes más rápido de lo que puede procesarlos, y su buzón crece.
Formas prácticas de manejarlo:
- monitorizar tamaños de buzón/cola
- aplicar límites (descartar, muestrear o fijar un tope)
- repartir la carga entre más trabajadores
- degradar con gracia (por ejemplo, pasar a resúmenes para notificaciones no críticas)
¿Qué significa realmente “let it crash” (y qué no significa)?
“Let it crash” significa: si un trabajador llega a un estado inválido o inesperado, debe fallar rápido en lugar de arrastrarse.
La recuperación se maneja de forma estructurada (mediante supervisión), lo que puede producir caminos de código más simples y una recuperación más predecible —siempre que los reinicios sean seguros y rápidos.
¿Qué son los árboles de supervisión y por qué son centrales para la tolerancia a fallos?
Un árbol de supervisión es una jerarquía donde supervisores vigilan a trabajadores y los reinician según reglas definidas.
En lugar de esparcir lógica de recuperación por todas partes, centralizas:
- decidir qué se reinicia cuando algo falla
- evitar bucles de reinicio sin fin con límites/esperas
- reiniciar conjuntos cuando los componentes deben mantenerse sincronizados
¿Qué es OTP y cómo ayuda a construir servicios fiables?
OTP es el conjunto de patrones estándar (behaviours) y convenciones que hacen que los sistemas Erlang sean operables a largo plazo.
Bloques comunes:
gen_serverpara trabajadores de larga duración con estadosupervisorpara políticas de reinicioapplicationpara definir cómo arranca, para y encaja un servicio en una release
La ventaja es tener ciclos de vida compartidos y bien entendidos en vez de frameworks ad hoc.
¿Cómo puedo aplicar las lecciones de Erlang si no uso Erlang?
Puedes aplicar los mismos principios en otras pilas haciendo que la falla y la recuperación sean de primera clase:
- aislar trabajo arriesgado (procesos/servicios/contenedores separados)
- añadir timeouts, reintentos con backoff, circuit breakers y bulkheads
- automatizar la recuperación (health checks + reinicio al fallar)
- usar colas/streams para desacoplar componentes
Para más, el post remite a guías en /blog y detalles de implementación en /docs.