12 sept 2025·8 min
Kit inicial de observabilidad en producción para el día uno
Kit inicial de observabilidad en producción: los logs, métricas y trazas mínimos que añadir el día uno, más un flujo de triage sencillo para informes de “está lento”.
Kit inicial de observabilidad en producción: los logs, métricas y trazas mínimos que añadir el día uno, más un flujo de triage sencillo para informes de “está lento”.
Lo que falla primero rara vez es toda la app. Normalmente es un paso que de repente se sobrecarga, una consulta que iba bien en pruebas, o una dependencia que comienza a timeoutear. Los usuarios reales aportan variedad real: teléfonos más lentos, redes inestables, entradas extrañas y picos de tráfico en momentos inoportunos.
Cuando alguien dice “está lento”, puede significar cosas muy distintas. La página puede tardar en cargar, las interacciones pueden ir con lag, una llamada a la API puede estar timeouteando, los jobs en background pueden acumularse, o un servicio de terceros puede estar ralentizando todo.
Por eso necesitas señales antes que dashboards. El día uno no necesitas gráficos perfectos para cada endpoint. Necesitas suficientes logs, métricas y trazas para responder una pregunta rápidamente: ¿dónde se fue el tiempo?
También existe el riesgo real de sobreinstrumentar temprano. Demasiados eventos crean ruido, cuestan dinero y pueden incluso ralentizar la app. Peor aún, los equipos dejan de confiar en la telemetría porque parece desordenada e inconsistente.
Un objetivo realista para el día uno es simple: cuando recibas un informe de “está lento”, puedas encontrar el paso lento en menos de 15 minutos. Debes poder decir si el cuello de botella está en el render del cliente, el handler de la API y sus dependencias, la base de datos o cache, o un worker en background o servicio externo.
Ejemplo: un nuevo flujo de checkout se siente lento. Incluso sin una montaña de herramientas, quieres poder decir: “El 95% del tiempo está en llamadas al proveedor de pagos” o “la consulta del carrito está escaneando demasiadas filas”. Si construyes apps rápido con herramientas como Koder.ai, esa línea base del día uno importa aún más, porque la velocidad de entrega solo ayuda si también puedes depurar rápido.
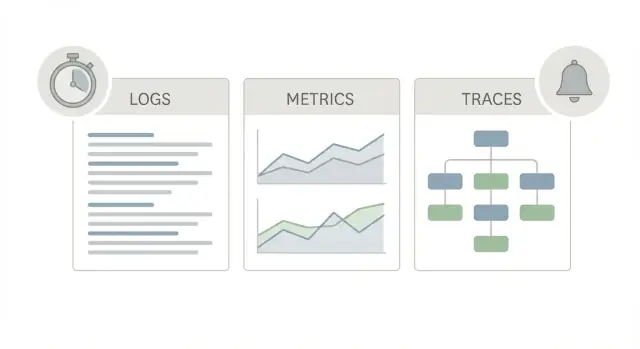
Un buen kit inicial de observabilidad en producción usa tres “vistas” diferentes de la misma app, porque cada una responde a una pregunta distinta.
Los logs cuentan la historia. Te dicen qué pasó para una petición, un usuario o un job en background. Una línea de log puede decir “pago falló para orden 123” o “timeout DB después de 2s”, además de detalles como request ID, user ID y el mensaje de error. Cuando alguien reporta un problema aislado, los logs suelen ser la forma más rápida de confirmar que ocurrió y a quién afectó.
Las métricas son el marcador. Son números que puedes trendear y sobre los que alertas: tasa de peticiones, tasa de errores, percentiles de latencia, CPU, profundidad de colas. Las métricas te dicen si algo es raro o generalizado y si está empeorando. Si la latencia subió para todos a las 10:05, las métricas lo mostrarán.
Las trazas son el mapa. Una traza sigue una sola petición a medida que se mueve por tu sistema (web -> API -> base de datos -> tercero). Muestra dónde se gasta el tiempo, paso a paso. Eso importa porque “está lento” casi nunca es un gran misterio; suele ser un salto lento.
Durante un incidente, un flujo práctico se ve así:
Una regla simple: si no puedes apuntar a un cuello de botella después de unos minutos, no necesitas más alertas. Necesitas mejores trazas y IDs consistentes que conecten trazas con logs.
La mayoría de incidentes de “no lo encontramos” no se deben a datos faltantes. Ocurren porque la misma cosa se registra de forma distinta entre servicios. Unas pocas convenciones compartidas el día uno hacen que logs, métricas y trazas se alineen cuando necesitas respuestas rápido.
Empieza eligiendo un nombre de servicio por unidad desplegable y mantenlo estable. Si “checkout-api” pasa a ser solo “checkout” en la mitad de tus dashboards, pierdes historial y rompes alertas. Haz lo mismo con las etiquetas de entorno. Elige un conjunto pequeño como prod y staging, y úsalo en todas partes.
Después, facilita seguir cada petición. Genera un request ID en el borde (API gateway, servidor web o primer handler) y pásalo por llamadas HTTP, colas de mensajes y jobs en background. Si un ticket de soporte dice “estaba lento a las 10:42”, un único ID te permite extraer los logs y la traza exactos sin adivinar.
Un conjunto de convenciones que funciona bien el día uno:
Acuerda las unidades de tiempo desde temprano. Elige milisegundos para latencia de API y segundos para jobs largos, y mantente con ello. Unidades mezcladas crean gráficos que parecen bien pero cuentan la historia equivocada.
Un ejemplo concreto: si cada API registra duration_ms, route, status y request_id, entonces un informe como “checkout está lento para el tenant 418” se convierte en un filtro rápido, no en un debate sobre por dónde empezar.
Si solo haces una cosa en tu kit inicial de observabilidad, haz que los logs sean fáciles de buscar. Eso empieza con logs estructurados (normalmente JSON) y los mismos campos en todos los servicios. Los logs en texto plano están bien para desarrollo local, pero se convierten en ruido cuando tienes tráfico real, reintentos y múltiples instancias.
Una buena regla: registra lo que realmente usarás durante un incidente. La mayoría de equipos necesita responder: ¿qué petición fue esta? ¿quién la hizo? ¿dónde falló? ¿qué tocó? Si una línea de log no ayuda con alguna de esas, probablemente no debería existir.
Para el día uno, mantén un conjunto pequeño y consistente de campos para poder filtrar y unir eventos entre servicios:
Cuando ocurre un error, regístralo una vez, con contexto. Incluye un tipo de error (o código), un mensaje corto, un stack trace para errores del servidor y la dependencia upstream involucrada (por ejemplo: postgres, payment provider, cache). Evita repetir el mismo stack trace en cada retry. En su lugar, adjunta el request_id para poder seguir la cadena.
Ejemplo: un usuario reporta que no puede guardar ajustes. Una búsqueda por request_id muestra un 500 en PATCH /settings, luego un timeout downstream a Postgres con duration_ms. No necesitaste payloads completos, solo la ruta, usuario/sesión y el nombre de la dependencia.
La privacidad es parte del logging, no una tarea posterior. No registres contraseñas, tokens, headers de auth, cuerpos completos de petición ni PII sensible. Si necesitas identificar a un usuario, registra un ID estable (o un valor hasheado) en lugar de emails o teléfonos.
Si construyes apps en Koder.ai (React, Go, Flutter), vale la pena incorporar estos campos en cada servicio generado desde el inicio para no terminar “arreglando el logging” durante tu primer incidente.
Un buen kit inicial de observabilidad empieza con un conjunto pequeño de métricas que responden rápido a una pregunta: ¿el sistema está sano ahora mismo y, si no, dónde duele?
La mayoría de problemas en producción aparecen como una de cuatro “señales doradas”: latencia (respuestas lentas), tráfico (cambios de carga), errores (fallos) y saturación (un recurso compartido al máximo). Si puedes ver estas cuatro señales por cada parte importante de tu app, puedes triagear la mayoría de incidentes sin adivinar.
La latencia debe medirse en percentiles, no en promedios. Controla p50, p95 y p99 para ver cuando un pequeño grupo de usuarios lo está pasando mal. Para tráfico, comienza con requests por segundo (o jobs por minuto para workers). Para errores, separa 4xx de 5xx: un aumento de 4xx suele significar cambios en el comportamiento del cliente o validación; un aumento de 5xx apunta a tu app o sus dependencias. La saturación es la señal de “nos estamos quedando sin algo” (CPU, memoria, conexiones DB, backlog de colas).
Un conjunto mínimo que cubre la mayoría de apps:
Un ejemplo concreto: si los usuarios reportan “está lento” y la latencia p95 de la API sube mientras el tráfico se mantiene plano, revisa saturación. Si el uso del pool DB está al máximo y los timeouts aumentan, encontraste un cuello de botella probable. Si la DB parece bien pero la profundidad de cola crece rápido, el trabajo en background podría estar acaparando recursos compartidos.
Si construyes apps en Koder.ai, trata este checklist como parte de la definición de hecho del día uno. Es más fácil añadir estas métricas cuando la app es pequeña que durante el primer incidente real.
Si un usuario dice “está lento”, los logs a menudo te dicen qué pasó y las métricas qué tan frecuente es. Las trazas te dicen dónde se fue el tiempo dentro de una petición. Esa línea de tiempo convierte una queja vaga en una solución clara.
Empieza en el servidor. Instrumenta las peticiones entrantes en el borde de tu app (el primer handler que recibe la petición) para que cada petición pueda generar una traza. La trazabilidad del lado cliente puede esperar.
Una traza buena del día uno tiene spans que mapean a las partes que suelen causar lentitud:
Para que las trazas sean buscables y comparables, captura algunos atributos clave y manténlos consistentes entre servicios.
Para el span de la petición entrante, registra la route (usa una plantilla como /orders/:id, no la URL completa), método HTTP, status code y latencia. Para spans de DB, registra el sistema DB (PostgreSQL, MySQL), tipo de operación (select, update) y el nombre de la tabla si es fácil añadirlo. Para llamadas externas, registra el nombre de la dependencia (payments, email, maps), host destino y estado.
El muestreo importa el día uno, si no los costes y el ruido crecen rápido. Usa una regla simple head-based: traza 100% de los errores y de las peticiones lentas (si tu SDK lo soporta), y muestrea un pequeño porcentaje del tráfico normal (como 1–10%). Empieza más alto con poco tráfico y reduce a medida que sube el uso.
Cómo se ve algo “bueno”: una traza donde puedes leer la historia de arriba a abajo. Ejemplo: GET /checkout tardó 2.4s, la DB gastó 120ms, cache 10ms y una llamada externa de pagos tardó 2.1s con un retry. Ahora sabes que el problema es la dependencia, no tu código. Esto es el núcleo de un kit inicial de observabilidad en producción.
Cuando alguien dice “está lento”, la victoria más rápida es convertir esa sensación vaga en unas pocas preguntas concretas. Este flujo de triage del kit inicial funciona incluso si tu app es completamente nueva.
Comienza estrechando el problema y luego sigue la evidencia en orden. No saltes directo a la base de datos.
Después de estabilizar, haz una pequeña mejora: escribe qué pasó y añade una señal que faltó. Por ejemplo, si no supiste si la lentitud fue solo en una región, añade una etiqueta de región a las métricas de latencia. Si viste un span largo de DB sin pista de qué query, añade etiquetas de query con cuidado o un campo “query name”.
Un ejemplo rápido: si la p95 de checkout salta de 400 ms a 3 s y las trazas muestran un span de 2.4 s en una llamada de pago, puedes dejar de discutir el código de la app y enfocarte en el proveedor, los reintentos y los timeouts.
Cuando alguien dice “está lento”, puedes perder una hora solo en entender qué quiere decir. Un kit inicial de observabilidad solo es útil si te ayuda a acotar el problema rápido.
Comienza con tres preguntas clarificadoras:
Luego mira algunos números que suelen indicar hacia dónde ir. No busques el dashboard perfecto. Solo quieres señales de “peor de lo normal”.
Si la p95 está elevada pero los errores están estables, abre una traza de la ruta más lenta en los últimos 15 minutos. Una sola traza suele mostrar si el tiempo se gasta en la base de datos, en una API externa o esperando locks.
Luego haz una búsqueda de logs. Si tienes un reporte de usuario específico, busca por su request_id (o el correlation ID) y lee la línea de tiempo. Si no, busca el mensaje de error más común en la misma ventana de tiempo y verifica si coincide con la lentitud.
Finalmente, decide si mitigar ahora o investigar más. Si los usuarios están bloqueados y la saturación es alta, una mitigación rápida (escalar, hacer rollback o desactivar una feature no esencial) puede comprar tiempo. Si el impacto es pequeño y el sistema estable, sigue investigando con trazas y logs de queries lentas.
Unas horas después de un release, empiezan a llegar tickets de soporte: “El checkout tarda 20 a 30 segundos.” Nadie puede reproducirlo en su laptop, así que empiezan las conjeturas. Aquí es donde tu kit inicial de observabilidad paga dividendos.
Primero, ve a las métricas y confirma el síntoma. La gráfica de latencia p95 para solicitudes HTTP muestra un pico claro, pero solo para POST /checkout. Otras rutas están normales y la tasa de errores está estable. Eso reduce el problema de “todo el sitio está lento” a “un endpoint se volvió más lento tras el release”.
Luego, abre una traza de una petición lenta POST /checkout. La cascada de la traza hace obvio el culpable. Dos resultados comunes:
Ahora valida con logs usando el mismo request ID de la traza (o el trace ID si lo guardas en logs). En los logs de esa petición ves advertencias repetidas como “payment timeout reached” o “context deadline exceeded”, además de reintentos añadidos en el nuevo release. Si es el camino de la base de datos, los logs pueden mostrar mensajes de espera por lock o la query lenta registrada por encima de un umbral.
Con las tres señales alineadas, la solución es clara:
La clave es que no tuviste que adivinar. Las métricas señalaron el endpoint, las trazas el paso lento y los logs confirmaron el modo de fallo con la petición exacta en mano.
La mayor parte del tiempo en incidentes se pierde por huecos evitables: los datos están, pero son ruidosos, riesgosos o falta el detalle que necesitas para conectar síntomas con causa. Un kit inicial de observabilidad solo ayuda si sigue siendo usable bajo estrés.
Una trampa común es loggear demasiado, especialmente cuerpos de petición sin filtro. Suena útil hasta que pagas por almacenamiento enorme, las búsquedas se vuelven lentas y capturas contraseñas, tokens o datos personales. Prefiere campos estructurados (route, status code, latency, request_id) y registra solo pequeños fragmentos permitidos explícitamente del input.
Otro agujero de tiempo son métricas que parecen detalladas pero son imposibles de agregar. Etiquetas de alta cardinalidad como IDs completos de usuario, emails o números de pedido pueden explotar la cantidad de series métricas y hacer los dashboards poco fiables. Usa etiquetas más generales (nombre de ruta, método HTTP, clase de status, nombre de dependencia) y deja lo específico para logs.
Errores que bloquean el diagnóstico rápido:
Un ejemplo práctico: si la p95 de checkout sube de 800ms a 4s, quieres responder en minutos: ¿empezó justo después de un deploy? ¿Se pasa el tiempo en tu app o en una dependencia (DB, proveedor de pagos, cache)? Con percentiles, etiqueta de release y trazas con route y nombres de dependencia, puedes llegar rápido. Sin ellos, quemas la ventana del incidente discutiendo suposiciones.
La ganancia real es la consistencia. Un kit inicial de observabilidad solo ayuda si cada nuevo servicio se entrega con lo mismo, nombrado igual y fácil de encontrar cuando algo falla.
Convierte tus elecciones del día uno en una plantilla corta que tu equipo reutilice. Mantenla pequeña pero específica.
Crea una vista “home” que cualquiera pueda abrir durante un incidente. Una pantalla debería mostrar requests por minuto, tasa de errores, latencia p95 y tu métrica principal de saturación, con filtros por environment y version.
Mantén las alertas mínimas al principio. Dos alertas cubren mucho: un pico de tasa de errores en una ruta clave y un pico de latencia p95 en la misma ruta. Si añades más, asegúrate de que cada una tenga una acción clara.
Finalmente, programa una revisión mensual recurrente. Elimina alertas ruidosas, afina nombres y añade una señal faltante que hubiera ahorrado tiempo en el último incidente.
Para integrar esto en tu proceso de construcción, añade una “puerta de observabilidad” al checklist de release: no desplegar sin request IDs, etiquetas de versión, la vista home y las dos alertas base. Si publicas con Koder.ai, puedes definir estas señales del día uno en modo planificación antes del despliegue, luego iterar con snapshots y rollback cuando necesites ajustar rápido.
Comienza por el primer punto donde los usuarios entran en tu sistema: el servidor web, el API gateway o tu primer handler.
request_id y pásalo por cada llamada interna.route, method, status y duration_ms para cada petición.Con eso normalmente ya llegas rápido a un endpoint y a una ventana de tiempo específicos.
Apunta a este objetivo razonable por defecto: puedes identificar el paso lento en menos de 15 minutos.
No necesitas dashboards perfectos el día uno. Necesitas suficiente señal para responder:
Úsalos juntos, porque cada uno responde a una pregunta distinta:
Durante un incidente: confirma impacto con métricas, encuentra el cuello de botella con trazas y explícalo con logs.
Elige un pequeño conjunto de convenciones y aplícalas en todos lados:
Por defecto, logs estructurados (habitualmente JSON) con las mismas claves en todas partes.
Campos mínimos que devuelven valor inmediato:
Empieza con las cuatro “señales doradas” por componente principal:
Y añade una pequeña lista por componente:
Instrumenta primero en el servidor para que cada petición entrante pueda generar una traza.
Una traza útil del día uno incluye spans que correspondan a las partes que suelen causar lentitud:
Haz los spans buscables con atributos consistentes como (en forma de plantilla), y un nombre claro de dependencia (por ejemplo , , ).
Un valor por defecto simple y seguro es:
Empieza más alto cuando el tráfico es bajo y reduce a medida que crece. La meta es mantener las trazas útiles sin explotar coste o ruido, y tener suficientes ejemplos del camino lento para diagnosticarlo.
Usa un flujo repetible que siga la evidencia:
Estos errores consumen tiempo (y a veces dinero):
service_name estable, environment (como prod/staging) y versionrequest_id generado en el borde y propagado por llamadas y jobsroute, method, status_code y tenant_id (si eres multi-tenant)duration_ms)La meta es que un único filtro funcione entre servicios en vez de empezar de cero cada vez.
timestamp, level, service_name, environment, versionrequest_id (y trace_id si está disponible)route, method, status_code, duration_msuser_id o session_id (un ID estable, no un email)Registra errores una sola vez con contexto (tipo/código de error + mensaje + nombre de dependencia). Evita repetir el mismo stack trace en cada retry.
routestatus_codepaymentspostgrescacheApunta una señal que faltó y añádela después.
Manténlo simple: IDs estables, percentiles, nombres de dependencia claros y etiquetas de versión en todas partes.