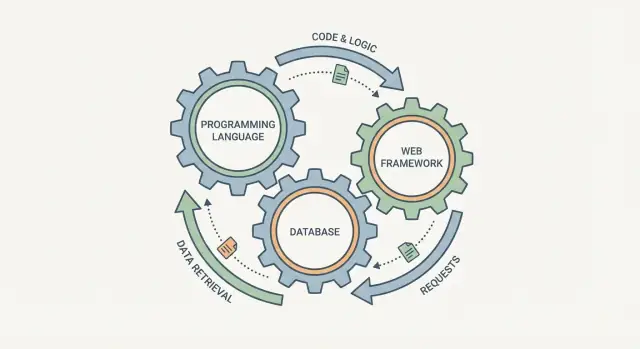
Por qué estas no son elecciones separadas
Es tentador elegir un lenguaje de programación, una base de datos y un framework web como tres casillas independientes. En la práctica, funcionan más como engranajes conectados: cambias uno y los otros lo notan.
Un framework web define cómo se manejan las peticiones, cómo se valida la información y cómo se muestran los errores. La base de datos define qué es “fácil de almacenar”, cómo consultas la información y qué garantías tienes cuando varios usuarios actúan a la vez. El lenguaje queda en medio: determina cuán seguro puedes expresar reglas, cómo gestionas la concurrencia y qué librerías y herramientas puedes aprovechar.
Qué significa “un solo sistema"
Tratar la pila como un sistema único significa no optimizar cada parte de forma aislada. Eliges una combinación que:
- Representa tus datos de forma natural (para no pelearte constantemente con conversiones)
- Soporta tus necesidades de consistencia (para que los bugs no se escondan en casos límite)
- Encaja con el flujo de trabajo del equipo (para que desplegar y mantener sea predecible)
Este artículo es práctico e intencionadamente poco técnico. No necesitas memorizar teoría de bases de datos ni detalles internos de lenguajes—solo ver cómo las decisiones repercuten en toda la aplicación.
Un ejemplo rápido: usar una base de datos sin esquema para datos empresariales altamente estructurados y orientados a reportes suele provocar reglas dispersas en el código de la aplicación y análisis confusos más adelante. Una opción más adecuada es emparejar ese dominio con una base de datos relacional y un framework que fomente validaciones y migraciones consistentes, de modo que tus datos permanezcan coherentes conforme el producto evoluciona.
Si planificas la pila en conjunto, estás diseñando un conjunto de compensaciones—no tres apuestas separadas.
Un modelo mental simple: petición entra, datos salen
Una manera útil de pensar la “pila” es como una única canalización: entra una petición de usuario y sale una respuesta (más los datos guardados). El lenguaje, el framework y la base de datos no son elecciones independientes; son tres partes del mismo viaje.
El viaje de una petición
Imagina que un cliente actualiza su dirección de envío.
- Petición entrante: El framework recibe una petición HTTP. El enrutamiento decide qué handler se ejecuta (por ejemplo,
/account/address). La validación comprueba que la entrada esté completa y sea sensata.
- Se ejecuta el trabajo: Tu código de aplicación (escrito en el lenguaje elegido) aplica las reglas de negocio: “¿Está el usuario autenticado?”, “¿Es aceptable este formato de dirección?”, “¿Debemos marcar este pedido para re-chequeo?”
- Datos salientes: La capa de base de datos lee y escribe registros—a menudo dentro de una transacción—para que la actualización se aplique por completo o no se aplique.
- Respuesta: El framework formatea el resultado (HTML/JSON), establece códigos de estado y lo devuelve al usuario.
- Después: Pueden ejecutarse trabajos en background (enviar email de confirmación, actualizar índice de búsqueda, notificar al almacén).
De qué es realmente responsable cada elección
- Lenguaje: Cómo se ejecuta el código (runtime/modelo de concurrencia), qué tan fácil es probar y depurar, y si las habilidades del equipo y las herramientas permiten cambios seguros y rápidos.
- Framework: El “control de tráfico” para peticiones—enrutamiento, validación, hooks de autenticación, manejo de errores y patrones incorporados para trabajos en background.
- Base de datos: Cómo se almacenan y consultan los datos, qué restricciones evitan datos malos y cómo las transacciones mantienen consistentes las actualizaciones relacionadas.
Cuando estos tres coinciden, una petición fluye con claridad. Cuando no lo hacen, aparece fricción: acceso a datos incómodo, validaciones filtradas y bugs de consistencia sutiles.
Modelo de datos primero: el motor oculto del encaje de la pila
La mayoría de los debates sobre la “pila” comienzan por la marca del lenguaje o la base de datos. Un mejor punto de partida es tu modelo de datos—porque dicta en silencio qué se sentirá natural (o doloroso) en todas partes: validación, consultas, APIs, migraciones e incluso flujo de trabajo del equipo.
Las aplicaciones suelen lidiar con cuatro formas a la vez:
- Objetos en el código (clases, structs, registros tipados)
- Filas en tablas relacionales
- Documentos en almacenamientos estilo JSON o APIs
- Eventos en logs/streams (“OrderPlaced”, “EmailSent”)
Un buen encaje es cuando no pasas los días traduciendo entre formas. Si tus datos centrales están muy conectados (usuarios ↔ pedidos ↔ productos), filas y joins pueden mantener la lógica simple. Si tus datos son mayormente “un blob por entidad” con campos variables, los documentos pueden reducir la ceremonia—hasta que necesites reportes entre entidades.
Esquema vs estructura flexible (y dónde viven las reglas)
Cuando la base de datos tiene un esquema fuerte, muchas reglas pueden vivir cerca de los datos: tipos, constraints, claves foráneas, unicidad. Eso suele reducir comprobaciones duplicadas entre servicios.
Con estructuras flexibles, las reglas se desplazan hacia la aplicación: código de validación, payloads versionados, backfills y lógica cuidadosa de lectura (“si existe el campo, entonces…”). Esto puede funcionar bien cuando los requisitos de producto cambian semanalmente, pero aumenta la carga sobre el framework y las pruebas.
Cómo las decisiones de modelado afectan la complejidad del código
Tu modelo decide si tu código es mayormente:
- Consultas y joins (orientado a relacional)
- Transformar JSON anidado (orientado a documentos)
- Reproducir y agregar eventos (orientado a eventos)
Eso, a su vez, influye en las necesidades de lenguaje y framework: el tipado fuerte puede prevenir desviaciones sutiles en campos JSON, mientras que una herramienta madura de migraciones importa más cuando los esquemas evolucionan con frecuencia.
Ejemplos: perfil de usuario, pedidos, registro de auditoría
- Perfil de usuario: a menudo tipo documento (preferencias, campos opcionales) pero se beneficia de restricciones relacionales para identidad y unicidad.
- Pedidos: típicamente relacional (líneas, totales, estados) porque la consistencia y el reporting importan.
- Registro de auditoría: naturalmente en forma de evento—entradas append-only que rara vez se actualizan, optimizadas para consultar por tiempo, actor o entidad.
Elige el modelo primero; la elección “correcta” de framework y base de datos suele quedar clara después.
Transacciones y consistencia: donde suelen empezar los bugs
Las transacciones son las garantías de “todo o nada” de las que tu app depende silenciosamente. Cuando un checkout tiene éxito, esperas que el registro de pedido, el estado del pago y la actualización de inventario ocurran todos—o ninguno. Sin esa promesa aparecen los bugs más difíciles: raros, caros y duros de reproducir.
Qué hacen realmente las transacciones
Una transacción agrupa múltiples operaciones de base de datos en una única unidad de trabajo. Si algo falla en el camino (un error de validación, un timeout, un proceso caído), la base de datos puede revertir al estado seguro anterior.
Esto importa más allá de los flujos de dinero: creación de cuentas (fila de usuario + fila de perfil), publicar contenido (post + tags + punteros al índice de búsqueda) o cualquier flujo que toque más de una tabla.
Consistencia vs velocidad (en términos simples)
Consistencia significa “las lecturas coinciden con la realidad”. Velocidad significa “devolver algo rápidamente”. Muchos sistemas hacen compensaciones:
- Consistencia fuerte: los usuarios ven los datos comprometidos más recientes, menos sorpresas, a menudo mayor coste de coordinación.
- Consistencia eventual: las actualizaciones se propagan con el tiempo, normalmente más rápido y fácil de escalar, pero tu app debe manejar desajustes temporales.
El patrón de fallo común es elegir un setup eventualmente consistente y luego programar como si fuera fuertemente consistente.
Cómo frameworks y ORMs influyen en el resultado
Los frameworks y los ORMs no crean transacciones automáticamente solo porque llamaste varios métodos “save”. Algunos requieren bloques de transacción explícitos; otros abren una transacción por petición, lo que puede esconder problemas de rendimiento.
Los reintentos también son complejos: los ORMs pueden reintentar en deadlocks o fallos transitorios, pero tu código debe ser seguro para ejecutarse dos veces.
Trampas comunes
Ocurren escrituras parciales cuando actualizas A y fallas antes de actualizar B. Acciones duplicadas aparecen cuando una petición se reintenta tras un timeout—especialmente si cobras una tarjeta o envías un email antes de que la transacción confirme.
Una regla simple ayuda: haz los efectos secundarios (emails, webhooks) después del commit de la base de datos, y haz las acciones idempotentes usando constraints de unicidad o claves de idempotencia.
La capa de acceso a datos: ORM, consultas y migraciones
Esta es la “capa de traducción” entre tu código de aplicación y la base de datos. Las decisiones aquí suelen importar más en el día a día que la propia marca de la base de datos.
ORM vs query builder vs SQL crudo (en términos simples)
Un ORM (Object-Relational Mapper) te permite tratar tablas como objetos: crear un User, actualizar un Post y el ORM genera SQL por detrás. Puede ser productivo porque estandariza tareas comunes y oculta la plomería repetitiva.
Un query builder es más explícito: construyes una consulta tipo SQL usando código (encadenamientos o funciones). Sigues pensando en “joins, filtros, grupos”, pero obtienes seguridad de parámetros y composabilidad.
SQL crudo es escribir el SQL directamente. Es lo más directo y a menudo lo más claro para consultas de reporting complejas—a costa de más trabajo manual y convenciones.
Cómo las características del lenguaje modelan los patrones de acceso
Los lenguajes con tipado fuerte (TypeScript, Kotlin, Rust) tienden a empujarte hacia herramientas que puedan validar consultas y formas de resultado temprano. Eso reduce sorpresas en runtime, pero empuja a los equipos a centralizar el acceso a datos para que los tipos no diverjan.
Lenguajes con metaprogramación flexible (Ruby, Python) suelen hacer que los ORMs se sientan naturales y rápidos para iterar—hasta que las consultas ocultas o comportamientos implícitos se vuelven difíciles de razonar.
Migraciones: mantener código y esquema en sincronía
Las migraciones son scripts de cambio versionados para tu esquema: añadir una columna, crear un índice, backfill de datos. El objetivo es simple: cualquiera debe poder desplegar la app y obtener la misma estructura de base de datos. Trata las migraciones como código que revisar, probar y, cuando haga falta, revertir.
Cuando las abstracciones “fáciles” perjudican
Los ORMs pueden generar silenciosamente N+1 queries, traer filas enormes que no necesitas o complicar joins. Los query builders pueden convertirse en cadenas difíciles de leer. El SQL crudo puede duplicarse e inconsistencia.
Una buena regla: usa la herramienta más simple que mantenga la intención obvia—y para rutas críticas, inspecciona el SQL que realmente se ejecuta.
El rendimiento es una propiedad del sistema, no de la base de datos
Construye una funcionalidad completa
Describe el flujo de trabajo y el modelo de datos en el chat y obtén una interfaz, API y base de datos iniciales.
La gente suele culpar a “la base de datos” cuando una página va lenta. Pero la latencia que percibe el usuario es la suma de múltiples pequeñas esperas a lo largo de toda la petición.
De dónde viene realmente la latencia
Una petición típica paga por:
- Tiempo de red (cliente → load balancer → app → base de datos y vuelta)
- Tiempo de consulta (SQL lento, índices faltantes, demasiados viajes)
- Serialización/deserialización (codificación JSON, mapeo ORM, compresión)
- Lógica de la app (validación, permisos, renderizado de plantillas, llamadas a APIs externas)
Aunque tu base de datos responda en 5 ms, una app que hace 20 consultas por petición, bloquea en I/O y pasa 30 ms serializando una respuesta enorme seguirá sintiéndose lenta.
Pooling de conexiones: el multiplicador silencioso de rendimiento
Abrir una conexión nueva a la base de datos es costoso y puede saturar la DB bajo carga. Un pool de conexiones reaprovecha conexiones existentes para que las peticiones no paguen ese coste repetidamente.
La cuestión: el tamaño “correcto” del pool depende del modelo de runtime. Un servidor async altamente concurrente puede generar una demanda masiva simultánea; sin límites en el pool verás colas, timeouts y fallos ruidosos. Con límites demasiado estrictos, la app se convierte en el cuello de botella.
Caché: qué arregla y qué no
El caché puede residir en el navegador, un CDN, una caché en proceso o una caché compartida (como Redis). Ayuda cuando muchas peticiones necesitan los mismos resultados.
Pero el caché no arregla:
- Rutas de escritura ineficientes
- Respuestas altamente personalizadas
- Endpoints lentos dominados por llamadas externas
Runtime importa: threads vs async
El runtime del lenguaje moldea el throughput. Modelos thread-per-request pueden desperdiciar recursos esperando I/O; modelos async pueden aumentar la concurrencia, pero también hacen esencial el backpressure (como límites de pool). Por eso afinar el rendimiento es una decisión de pila, no solo de base de datos.
Seguridad y fiabilidad: responsabilidad compartida en la pila
La seguridad no es algo que “añades” con un plugin del framework o un ajuste de la base de datos. Es el acuerdo entre lenguaje/runtime, framework web y base de datos sobre qué debe ser siempre verdadero—incluso cuando un desarrollador comete un error o se añade un endpoint nuevo.
Autenticación vs autorización: capas diferentes, mismo resultado
La autenticación (¿quién es?) suele vivir en el borde del framework: sesiones, JWTs, callbacks OAuth, middleware. La autorización (¿qué puede hacer?) debe aplicarse de forma consistente tanto en la lógica de la app como en las reglas de datos.
Un patrón común: la app decide la intención (“el usuario puede editar este proyecto”) y la base de datos refuerza límites (tenant IDs, constraints de propiedad y, donde tenga sentido, políticas a nivel de fila). Si la autorización existe solo en controladores, jobs en background y scripts internos pueden saltársela accidentalmente.
Validación: ¿framework, base de datos o ambas?
La validación en el framework da feedback rápido y buenos mensajes. Las restricciones en la base de datos proveen una red de seguridad final.
Usa ambas cuando importe:
- Framework: campos requeridos, formato, mensajes amigables.
- Base de datos: unicidad, claves foráneas,
CHECK constraints, NOT NULL.
Esto reduce los “estados imposibles” que aparecen cuando dos peticiones compiten o un servicio nuevo escribe datos distinto.
Secretos, cifrado y auditoría
Los secretos deben manejarse con el runtime y el flujo de despliegue (env vars, gestores de secretos), no embebidos en código o migraciones. El cifrado puede ocurrir en la app (cifrado a nivel de campo) y/o en la base de datos (encriptación en reposo, KMS gestionado), pero necesitas claridad sobre quién rota las claves y cómo se recupera.
La auditoría también es compartida: la app debe emitir eventos significativos; la base de datos debe mantener logs inmutables cuando convenga (por ejemplo, tablas de auditoría append-only con acceso restringido).
Modos de fallo típicos
Confiar en exceso en la lógica de la app es el clásico: constraints faltantes, nulos silenciosos, flags de “admin” almacenados sin comprobaciones. La solución es simple: asume que habrá bugs y diseña la pila para que la base de datos rechace escrituras inseguras—incluso desde tu propio código.
Rutas de escalado: lo que cada elección desbloquea o bloquea
Haz tuyo el código
Mantén el impulso exportando el código fuente cuando estés listo para comprometerte con una dirección.
Escalar rara vez falla porque “la base de datos no pueda manejarlo”. Falla porque la pila entera reacciona mal cuando la carga cambia de forma: un endpoint se vuelve popular, una consulta se calienta, un flujo empieza a reintentar.
Cuando el tráfico crece, el dolor aparece en sitios concretos
La mayoría de los equipos chocan con los mismos cuellos de botella tempranos:
- Consultas calientes: una consulta de “página superior” o dashboard se ejecuta constantemente y domina CPU/IO.
- Contención de locks: las actualizaciones se acumulan detrás de pocas filas (contadores de inventario, “last_seen”, tablas de cola), ralentizando todo.
- Presión de conexiones: los workers abren demasiadas conexiones; la DB pasa tiempo gestionando sesiones en lugar de trabajar.
Si puedes responder rápido depende de cuán bien tu framework y las herramientas de la base de datos exponen planes de consulta, migraciones, pooling y patrones seguros de caché.
Réplicas de lectura, sharding y colas: cuándo aparecen
Los movimientos de escalado comunes suelen llegar en este orden:
- Réplicas de lectura cuando las lecturas superan a las escrituras y toleras datos ligeramente desfasados. Tu ORM/framework debe soportar separación lectura/escritura (o facilitar el ruteo).
- Colas/jobs en background cuando el trabajo “hacerlo ahora” empieza a perjudicar la latencia de peticiones (emails, exportaciones, llamadas de facturación). Aquí las reintentos y la deduplicación se vuelven requisitos reales.
- Sharding/particionamiento cuando un primario no alcanza la tasa de escrituras o el crecimiento de almacenamiento. Esto exige modelado cuidadoso: claves de shard, consultas cross-shard y límites de transacción.
Trabajo en background e idempotencia son características del framework, no detalles menores
Una pila escalable necesita soporte de primera clase para tareas en background, scheduling y reintentos seguros.
Si tu sistema de jobs no puede imponer idempotencia (el mismo job ejecutándose dos veces sin doble cobro o doble envío), “escalarás” hacia corrupción de datos. Decisiones tempranas—como confiar en transacciones implícitas, constraints débiles o comportamientos opacos del ORM—pueden bloquear la introducción limpia de colas, patrones outbox o flujos casi-exactos una vez que creces.
La alineación temprana recompensa: elige una base de datos que cuadre con tus necesidades de consistencia y un ecosistema de framework que haga del siguiente paso de escalado (réplicas, colas, particionado) un camino soportado en vez de un rewrite.
Experiencia del desarrollador y operaciones: un solo flujo de trabajo
Una pila se siente “fácil” cuando desarrollo y operaciones comparten las mismas suposiciones: cómo arrancas la app, cómo cambian los datos, cómo corren las pruebas y cómo saber qué pasó cuando algo falla. Si esas piezas no encajan, los equipos pierden tiempo en código de pegamento, scripts frágiles y runbooks manuales.
Velocidad en desarrollo local
Una configuración local rápida es una característica. Prefiere un flujo donde un nuevo compañero pueda clonar, instalar, ejecutar migraciones y tener datos de prueba realistas en minutos—no horas.
Eso suele implicar:
- Un comando para arrancar la app y dependencias (a menudo via contenedores).
- Migraciones que se ejecutan confiablemente en cada máquina.
- Datos seed que reflejen la forma de producción (no solo filas “hello world”).
Si la herramienta de migraciones del framework choca con la elección de la base de datos, cada cambio de esquema se convierte en un pequeño proyecto.
Pirámide de pruebas que coincida con tu pila
Tu pila debe facilitar escribir:
- Unit tests que no requieran base de datos.
- Tests de integración que usen el esquema real y consultas.
- E2E tests que recorran la ruta completa de la petición.
Un fallo común: los equipos se apoyan en unit tests porque los tests de integración son lentos o dolorosos de montar. A menudo eso es una descoordinación entre stack y ops—provisionar DB de test, migraciones y fixtures debe ser fluido.
Observabilidad en app y base de datos
Cuando la latencia sube, necesitas seguir una petición desde el framework hasta la base de datos.
Busca logs estructurados, métricas básicas (tasa de peticiones, errores, tiempo en BD) y traces que incluyan tiempo de consulta. Incluso un simple correlation ID presente en logs de la app y de la BD puede convertir “adivinar” en “encontrar”.
Encaje operativo: cambios seguros y recuperación
Operaciones no está separada del desarrollo; es su continuación.
Elige herramientas que soporten:
- Backups y restores que hayas rehecho (no solo configurado).
- Cambios de esquema que puedan avanzar de forma segura (y ocasionalmente retroceder).
- Un camino claro para “qué pasa durante el deploy” para que los releases no dependan del conocimiento tribal.
Si no puedes ensayar un restore o una migración localmente con confianza, no lo harás bien bajo presión.
Lista práctica para elegir una pila coherente
Elegir una pila es menos sobre elegir “las mejores” herramientas y más sobre escoger herramientas que encajen bajo tus restricciones reales. Usa esta lista para forzar alineamiento desde el principio.
1) Checklist rápido (encaje antes que features)
- Habilidades del equipo: ¿Qué puede tu equipo entregar y mantener con confianza durante 12–24 meses?
- Forma del dominio: ¿Mayormente workflows y registros, reglas complejas o reporting intensivo?
- Necesidades de datos: Integridad relacional, documentos flexibles, series temporales, búsqueda full-text, analítica?
- Restricciones: Cumplimiento, objetivos de latencia, modelo de despliegue, presupuesto, infraestructura existente.
- Tolerancia a fallos: ¿Puedes aceptar consistencia eventual o necesitas transacciones estrictas?
2) Mapea tu producto a patrones comunes
- App CRUD-heavy (herramientas internas, back office, SaaS temprano): Un framework web convencional + BD relacional suele ser la vía más rápida porque migraciones, transacciones y flujos administrativos son sencillos.
- Analítica-heavy (dashboards, tracking de eventos): Planea un store OLAP o un warehouse temprano; intentar “convertir Postgres en un sistema BI” puede ralentizar consultas y trabajo de producto.
- Tiempo real (chat, colaboración, streaming): Prioriza soporte WebSocket, pub/sub y concurrencia predecible. Tu elección de lenguaje/runtime afecta cuánto duele esto.
- SaaS multi-tenant: Decide desde el principio: bases separadas, esquemas separados o tenancy por fila. Esta decisión se propaga a auth, migraciones y operaciones.
3) Ejecuta un pequeño proof of concept (sin overbuilding)
Limita a 2–5 días. Construye una vertical delgada: un flujo central, un job en background, una consulta tipo reporte y auth básica. Mide fricción de desarrollo, ergonomía de migraciones, claridad de consultas y qué tan fácil es testear.
Si quieres acelerar, una herramienta de vibe-coding como Koder.ai puede ayudar a generar rápidamente una vertical (UI, API y BD) desde una spec conversacional—y luego iterar con snapshots/rollback y exportar el código cuando decidas comprometerte.
4) Escribe un registro de decisión de una página
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks \u0026 mitigations:
When we’ll revisit:
Desajustes comunes (y cómo evitarlos)
Facilita la revisión
Comparte una app real con tu equipo y stakeholders usando un dominio personalizado.
Incluso equipos sólidos terminan con desajustes de pila—decisiones que parecen bien en aislamiento pero crean fricción cuando el sistema está en producción. La buena noticia: la mayoría son predecibles y se evitan con unas pocas comprobaciones.
Olores a vigilar
Un olor clásico es elegir una base de datos o framework porque está de moda mientras tu modelo real de datos sigue difuso. Otro es escalar prematuramente: optimizar para millones de usuarios antes de manejar de forma fiable cientos, lo que con frecuencia genera infraestructura extra y más modos de fallo.
También vigila pilas donde el equipo no puede explicar por qué existe cada pieza mayor. Si la respuesta es mayormente “todos la usan”, estás acumulando riesgo.
Riesgos de integración que pegan después
Muchos problemas aparecen en las uniones:
- Drivers y features desajustados: el driver del lenguaje no soporta totalmente las características de BD que asumiste (tipos, streaming, reintentos).
- Migraciones débiles: los cambios de esquema se gestionan manualmente o las herramientas de migración no siguen la evolución de la app, causando deriva entre entornos.
- Pooling pobre: frameworks que abren demasiadas conexiones, o despliegues que multiplican pools entre procesos/contenedores, llevando a timeouts bajo carga.
Estos no son “problemas de la DB” ni “problemas del framework”: son problemas del sistema.
Cómo simplificar (y reducir riesgo)
Prefiere menos piezas móviles y un camino claro para tareas comunes: una aproximación de migraciones, un estilo de consulta para la mayoría de features y convenciones consistentes entre servicios. Si tu framework promueve un patrón (lifecycle de petición, inyección de dependencias, pipeline de jobs), apóyate en él en vez de mezclar estilos.
Cuándo revisar decisiones y cambiar con seguridad
Revisa cuando veas incidentes de producción recurrentes, fricción persistente para desarrolladores o cuando nuevos requisitos de producto cambien fundamentalmente los patrones de acceso a datos.
Cambia con seguridad aislando la costura: introduce una capa adaptadora, migra incrementalmente (dual-write o backfill cuando haga falta) y demuestra paridad con tests automatizados antes de redirigir tráfico.
Conclusión: trata la pila como un solo sistema
Elegir un lenguaje, un framework web y una base de datos no son tres decisiones independientes—es una decisión de diseño del sistema expresada en tres sitios. La “mejor” opción es la combinación que se alinea con la forma de tus datos, tus necesidades de consistencia, el flujo de trabajo del equipo y la manera en que esperas que el producto crezca.
Qué llevarte
- Elige la pila en torno a tu modelo de datos central y las operaciones que realizas con más frecuencia.
- Consistencia y transacciones son preocupaciones de la aplicación también—diseñalas de extremo a extremo, no solo en la BD.
- Los cuellos de botella de rendimiento suelen cruzar límites (esquema, consultas, caché, serialización, colas).
- Seguridad y fiabilidad son responsabilidades compartidas entre código, configuración y operaciones.
- La experiencia del desarrollador importa porque determina la velocidad a la que puedes desplegar con seguridad.
Documenta las suposiciones (antes de que sean restricciones)
Anota las razones detrás de tus elecciones: patrones de tráfico esperados, latencias aceptables, reglas de retención, modos de fallo tolerables y qué no estás optimizando ahora. Esto hace visibles las compensaciones, ayuda a futuros compañeros a entender el “por qué” y evita la deriva arquitectónica cuando cambian los requisitos.
Siguientes pasos
Revisa tu setup actual con la checklist y apunta dónde las decisiones no encajan (por ejemplo, un esquema que pelea con el ORM o un framework que complica el trabajo en background).
Si exploras una dirección nueva, herramientas como Koder.ai también pueden ayudar a comparar suposiciones de pila generando una app base (comúnmente React en web, servicios en Go con PostgreSQL y Flutter en móvil) que puedes inspeccionar, exportar y evolucionar—sin comprometerte a un ciclo largo de desarrollo.
Para más profundidad, consulta guías relacionadas en /blog, busca detalles de implementación en /docs o compara opciones de soporte y despliegue en /pricing.