03 nov 2025·8 min
Leslie Lamport y los sistemas distribuidos: tiempo, orden y corrección
Aprende las ideas clave de Lamport sobre sistemas distribuidos: relojes lógicos, orden, consenso y corrección, y por qué todavía guían la infraestructura moderna.
Por qué Lamport sigue importando para los sistemas distribuidos modernos
Leslie Lamport es uno de esos pocos investigadores cuyo trabajo “teórico” aparece cada vez que pones en producción un sistema real. Si alguna vez has operado un clúster de bases de datos, una cola de mensajes, un motor de workflows o cualquier cosa que reintente peticiones y sobreviva fallos, has vivido dentro de problemas que Lamport ayudó a nombrar y resolver.
Lo que hace que sus ideas perduren es que no están ligadas a una tecnología concreta. Describen verdades incómodas que aparecen siempre que varias máquinas intentan comportarse como un solo sistema: los relojes discrepan, las redes retrasan y pierden mensajes, y los fallos son normales —no excepcionales—.
Tres temas que usaremos a lo largo del texto
Tiempo: en un sistema distribuido, “¿qué hora es?” no es una pregunta simple. Los relojes físicos derivan, y el orden en que observas eventos puede diferir entre máquinas.
Orden: cuando no puedes fiarte de un único reloj, necesitas otras formas de hablar de qué eventos ocurrieron primero —y cuándo debes forzar que todos sigan la misma secuencia.
Corrección: “normalmente funciona” no es un diseño. Lamport empujó el campo hacia definiciones nítidas (seguridad vs. vivacidad) y especificaciones sobre las que puedes razonar, no solo probar.
Qué esperar (sin matemáticas pesadas)
Nos centraremos en conceptos e intuición: los problemas, las herramientas mínimas para pensar con claridad y cómo esas herramientas moldean diseños prácticos.
Aquí tienes el mapa:
- Por qué no existe un reloj compartido que cuente una única historia global de eventos
- Cómo la causalidad (“ocurrió antes”) conduce a relojes lógicos y a las marcas de tiempo de Lamport
- Cuándo un orden parcial no basta y necesitas una única línea temporal
- Cómo el consenso y Paxos se relacionan con ponerse de acuerdo sobre un orden
- Por qué la replicación de máquinas de estado funciona cuando se comparte el orden
- Cómo hablar de corrección en especificaciones —y cómo herramientas de modelado como TLA+ ayudan
El problema central: sin reloj compartido no hay una sola realidad
Un sistema es “distribuido” cuando está formado por múltiples máquinas que coordinan sobre una red para hacer un trabajo. Eso suena simple hasta que aceptas dos hechos: las máquinas pueden fallar de forma independiente (fallos parciales), y la red puede retrasar, perder, duplicar o reordenar mensajes.
En un programa único en un ordenador, normalmente puedes señalar “qué pasó primero”. En un sistema distribuido, distintas máquinas pueden observar secuencias de eventos diferentes —y ambas pueden ser correctas desde su punto de vista local.
Por qué no puedes confiar en un reloj global
Es tentador resolver la coordinación timestampando todo. Pero no existe un reloj único en el que puedas confiar entre máquinas:
- El reloj de hardware de cada servidor deriva a su propio ritmo.
- La sincronización de relojes (como NTP) es best-effort, no una garantía.
- La virtualización, la carga de CPU o las pausas pueden hacer que el tiempo salte o se detenga.
Así que “el evento A ocurrió a las 10:01:05.123” en un host no se puede comparar de forma fiable con “10:01:05.120” en otro.
Cómo los retrasos desordenan la realidad
Los retrasos de red pueden invertir lo que creías haber visto. Una escritura puede enviarse primero pero llegar después. Un reintento puede llegar tras el original. Dos datacenters pueden procesar la “misma” petición en órdenes opuestos.
Esto hace que la depuración sea singularmente confusa: los logs de distintas máquinas pueden discrepar, y “ordenar por timestamp” puede crear una historia que nunca ocurrió.
Consecuencias reales
Cuando asumes una única línea temporal que no existe, obtienes fallos concretos:
- Procesamiento doble (un pago cobrado dos veces tras reintentos)
- Inconsistencias (dos usuarios reclaman “con éxito” el último artículo)
- Aparente pérdida de datos (una actualización que llega tarde sobrescribe una más reciente)
La idea clave de Lamport empieza aquí: si no puedes compartir el tiempo, debes razonar sobre el orden de otra manera.
Causalidad y la relación "ocurrió antes"
Los programas distribuidos se componen de eventos: algo que ocurre en un nodo específico (un proceso, servidor o hilo). Ejemplos: “recibió una petición”, “escribió una fila” o “envió un mensaje”. Un mensaje es el conector entre nodos: un evento es el envío y otro es la recepción.
La idea clave de Lamport es que, en un sistema sin un reloj compartido fiable, lo más aprovechable que puedes seguir es la causalidad —qué eventos pudieron influir en qué otros eventos.
La relación ocurrió-antes (→)
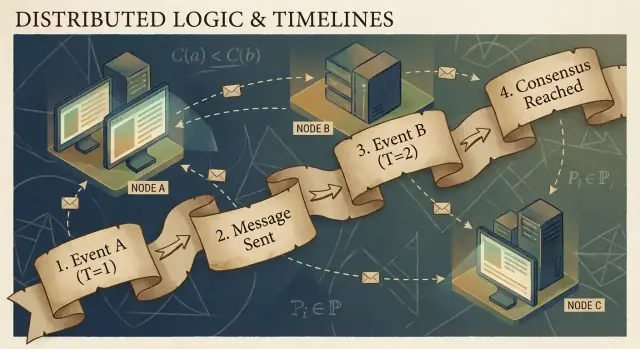
Lamport definió una regla simple llamada ocurrió-antes, escrita como A → B (el evento A ocurrió antes que el evento B):
- Orden en el mismo proceso: si A y B ocurren en la misma máquina/proceso, y A se observa antes que B en ese proceso, entonces A → B.
- Orden por mensaje: si A es “envió el mensaje m” y B es “recibió el mensaje m”, entonces A → B.
- Transitividad: si A → B y B → C, entonces A → C.
Esta relación te da un orden parcial: te dice que algunos pares están ordenados, pero no todos.
Una historia concreta: usuario → petición → BD → cache
Un usuario hace clic en “Comprar”. Ese clic dispara una petición a un servidor API (evento A). El servidor escribe una fila de orden en la base de datos (evento B). Tras completar la escritura, el servidor publica un mensaje “orden creada” (evento C), y un servicio de caché lo recibe y actualiza una entrada (evento D).
Aquí, A → B → C → D. Incluso si los relojes discrepan, el mensaje y la estructura del programa crean enlaces causales reales.
Qué significa realmente “concurrente”
Dos eventos son concurrentes cuando ninguno causó al otro: no (A → B) y no (B → A). Concurrencia no significa “mismo tiempo” —significa “no hay un camino causal que los conecte”. Por eso dos servicios pueden decir cada uno que actuó “primero”, y ambos pueden tener razón a menos que añadas una regla de orden.
Relojes lógicos: marcas de tiempo de Lamport en lenguaje llano
Si alguna vez has intentado reconstruir “qué pasó primero” entre varias máquinas, te has topado con el problema básico: los ordenadores no comparten un reloj perfectamente sincronizado. La solución de Lamport es dejar de perseguir el tiempo perfecto y, en su lugar, seguir el orden.
La idea: un contador unido a cada evento
Una marca de tiempo de Lamport es simplemente un número que adjuntas a cada evento significativo en un proceso (una instancia de servicio, un nodo, un hilo —lo que elijas). Piensa en ello como un “contador de eventos” que te da una forma consistente de decir “este evento sucedió antes que aquel”, incluso cuando el reloj de pared no es fiable.
Las dos reglas (y de verdad son así de simples)
-
Incrementar localmente: antes de registrar un evento (por ejemplo, “escribió en BD”, “envió petición”, “anexó entrada al log”), incrementa tu contador local.
-
Al recibir, tomar max + 1: cuando recibes un mensaje que incluye la marca del emisor, ajusta tu contador a:
max(local_counter, received_counter) + 1
Luego marca el evento de recepción con ese valor.
Estas reglas aseguran que las marcas respeten la causalidad: si el evento A pudo haber influido en el evento B (porque la información fluyó por mensajes), entonces la marca de A será menor que la de B.
Qué pueden —y no pueden— decir las marcas de Lamport
Pueden decirte sobre orden causal:
- Si
TS(A) < TS(B), A podría haber sucedido antes que B. - Si A causó B (directa o indirectamente), entonces necesariamente
TS(A) < TS(B).
No pueden decirte sobre tiempo real:
- Una marca menor no significa “más temprano en segundos”.
- Dos eventos concurrentes (sin conexión causal) pueden tener marcas distintas debido a patrones de mensajes.
Así que las marcas de Lamport son excelentes para ordenar, no para medir latencia o responder “¿qué hora era?”.
Ejemplo práctico: ordenar entradas de log entre servicios
Imagina que el Servicio A llama al Servicio B, y ambos escriben logs de auditoría. Quieres una vista de log unificada que preserve causa y efecto.
- El Servicio A incrementa su contador, registra “iniciando pago”, envía la petición a B con la marca 42.
- El Servicio B recibe la petición con 42, ajusta su contador a
max(local, 42) + 1, digamos 43, y registra “tarjeta validada”. - B responde con 44; A recibe, actualiza a 45, y registra “pago completado”.
Ahora, cuando agregas logs de ambos servicios, ordenar por (lamport_timestamp, service_id) te da una línea temporal estable y explicable que coincide con la cadena real de influencia —aunque los relojes de pared derivaran o la red retrasara mensajes.
Del orden parcial al orden total: cuándo necesitas una única línea temporal
La causalidad te da un orden parcial: algunos eventos están claramente “antes” que otros (porque un mensaje o una dependencia los conecta), pero muchos eventos son simplemente concurrentes. Eso no es un error —es la forma natural de la realidad distribuida.
Orden parcial: suficiente para muchas preguntas
Si estás depurando “¿qué pudo influir en esto?” o imponiendo reglas como “una respuesta debe seguir a su petición”, el orden parcial es exactamente lo que necesitas. Solo debes respetar aristas de ocurrió-antes; el resto se puede tratar como independiente.
Orden total: requerido cuando el sistema debe elegir una única historia
Algunos sistemas no pueden aceptar “cualquiera de los dos órdenes vale”. Necesitan una secuencia única de operaciones, sobre todo para:
- Escrituras sobre un objeto compartido (“poner balance”, “actualizar perfil”, “anexar al log”)
- Comandos que deben aplicarse idénticamente en todas partes (replicación de máquinas de estado)
- Resolución de conflictos donde “última escritura gana” debe significar lo mismo para cada nodo
Sin un orden total, dos réplicas podrían ser ambas “correctas” localmente pero divergir globalmente: una aplica A luego B, otra aplica B luego A, y obtienes resultados distintos.
¿Cómo obtienes una única línea temporal?
Introduces un mecanismo que crea orden:
- Un secuenciador/líder que asigna una posición monótonamente creciente a cada comando.
- O consenso (por ejemplo, enfoques estilo Paxos) para que el clúster acuerde la siguiente entrada del log incluso con retrasos y fallos.
Los trade-offs inevitables
Un orden total es poderoso, pero tiene un coste:
- Latencia: puede que esperes coordinación antes de confirmar.
- Rendimiento: un log ordenado puede convertirse en cuello de botella.
- Disponibilidad bajo fallos: si no alcanzas suficientes nodos para acordar, el progreso puede detenerse para proteger la corrección.
La elección de diseño es simple de enunciar: cuando la corrección requiere una narrativa compartida, pagas el coste de coordinación para obtenerla.
Consenso: ponerse de acuerdo frente a retrasos y fallos
Aprende SMR de forma práctica
Estructura un sistema de juguete de replicación de máquinas de estado y explora patrones de compactación de registros.
Consenso es el problema de lograr que varias máquinas acuerden una decisión —un valor a confirmar, un líder a seguir, una configuración a activar— aun cuando cada máquina solo ve sus eventos locales y los mensajes que recibe.
Eso suena simple hasta que recuerdas lo que un sistema distribuido puede hacer: los mensajes pueden retrasarse, duplicarse, reordenarse o perderse; las máquinas pueden caer y reiniciar; y rara vez tienes una señal limpia de “este nodo está definitivamente muerto”. Consenso trata de hacer que el acuerdo sea seguro bajo esas condiciones.
Por qué el acuerdo es difícil
Si dos nodos temporalmente no pueden hablar (una partición de red), cada lado puede intentar “avanzar” por su cuenta. Si ambos eligen valores distintos, acabas con comportamiento split-brain: dos líderes, dos configuraciones diferentes o dos historias en competencia.
Incluso sin particiones, el retraso por sí solo causa problemas. Cuando un nodo se entera de una propuesta, otros pueden haber avanzado. Sin un reloj compartido, no puedes decir de forma fiable “la propuesta A ocurrió antes que la B” solo porque A tenga un timestamp anterior: el tiempo físico no es autorizativo aquí.
Dónde te encuentras con consenso en sistemas reales
Puede que no lo llames diariamente “consenso”, pero aparece en tareas infraestructurales comunes:
- Elección de líder (¿quién manda ahora?)
- Logs replicados (¿cuál es la siguiente entrada en la historia compartida?)
- Cambios de configuración (¿qué conjunto de nodos puede votar/confirmar?)
En cada caso, el sistema necesita un resultado único en el que todos converjan, o al menos una regla que impida que dos resultados en conflicto sean ambos válidos.
Paxos como la respuesta de Lamport
Paxos de Lamport es una solución fundamental a este problema de “acuerdo seguro”. La idea clave no es un timeout mágico ni un líder perfecto: es un conjunto de reglas que aseguran que solo un valor puede ser elegido, incluso cuando los mensajes llegan tarde y los nodos fallan.
Paxos separa seguridad (“nunca elegir dos valores distintos”) de progreso (“eventualmente elegir algo”), siendo un plano práctico: puedes ajustar el rendimiento real sin romper la garantía central.
Paxos, sin el dolor de cabeza: la intuición clave de seguridad
Paxos tiene fama de indescifrable, pero mucho de eso viene de que “Paxos” no es un único algoritmo simple. Es una familia de patrones relacionados para lograr que un grupo acuerde, aun cuando los mensajes se retrasen, dupliquen o las máquinas fallen temporalmente.
Los papeles: proponentes, aceptores y quórums
Un modelo mental útil separa quién propone de quién valida.
- Proponentes (proposers) intentan que un valor sea elegido (por ejemplo: “la siguiente entrada del log es X”).
- Aceptores (acceptors) votan las propuestas.
- Un quórum es “suficientes aceptores” para avanzar —típicamente una mayoría.
La idea estructural: dos mayorías cualquiera se solapan. Ese solapamiento es donde vive la seguridad.
El objetivo de seguridad: nunca decidir dos valores distintos
La seguridad en Paxos se enuncia con sencillez: una vez que el sistema decide un valor, no debe jamás decidir otro distinto —no hay decisiones tipo split-brain.
La intuición clave es que las propuestas llevan números (piensa: identificadores de vuelta). Los aceptores prometen ignorar propuestas con números más antiguos una vez que han visto una más nueva. Y cuando un proponente intenta con un número nuevo, primero pregunta a un quórum qué han aceptado ya.
Como los quórums se solapan, un nuevo proponente inevitablemente escuchará al menos a un aceptor que “recuerda” el valor aceptado más recientemente. La regla es: si alguien en el quórum aceptó algo, debes proponer ese valor (o el más reciente entre ellos). Esa restricción es la que evita que se elijan dos valores distintos.
Vivacidad, a grandes rasgos
La vivacidad significa que el sistema eventualmente decide algo bajo condiciones razonables (por ejemplo, emerge un líder estable y la red finalmente entrega mensajes). Paxos no promete rapidez en el caos; promete corrección y progreso una vez que las cosas se estabilizan.
Replicación de máquinas de estado: corrección mediante orden compartido
Crea una demo de pedidos
Convierte tus ideas de pedidos en un servicio funcional en Go y haz iteraciones desde un chat sencillo.
La replicación de máquinas de estado (SMR) es el patrón principal detrás de muchos sistemas de alta disponibilidad: en lugar de que un solo servidor tome decisiones, ejecutas varias réplicas que procesan la misma secuencia de comandos.
La idea del log replicado
En el centro está un log replicado: una lista ordenada de comandos como “put key=K value=V” o “transferir $10 de A a B”. Los clientes no envían comandos a cada réplica esperando lo mejor. Envían comandos al grupo, y el sistema acuerda un orden para esos comandos; luego cada réplica los aplica localmente.
Por qué el orden te da corrección
Si cada réplica parte del mismo estado inicial y ejecuta los mismos comandos en el mismo orden, acabarán en el mismo estado. Esa es la intuición de seguridad: no intentas mantener máquinas “sincronizadas” por tiempo; las haces idénticas mediante determinismo y orden compartido.
Por eso el consenso (protocolos estilo Paxos/Raft) se empareja a menudo con SMR: el consenso decide la siguiente entrada del log, y SMR convierte esa decisión en un estado consistente entre réplicas.
Dónde lo ves en sistemas reales
- Servicios de coordinación (por ejemplo, para configuración y elección de líder)
- Bases de datos con logs de escritura replicados
- Sistemas de mensajería que requieren ordering estricto por partición
Preocupaciones prácticas que los ingenieros no pueden ignorar
El log crece indefinidamente a menos que lo gestiones:
- Snapshots: captura periódicamente el estado actual para que nodos nuevos se pongan al día sin reproducir toda la historia.
- Compactación de log: descarta con seguridad entradas antiguas una vez que están reflejadas en un snapshot y ya no son necesarias.
- Cambios de membresía: añadir o quitar réplicas debe ordenarse también; de lo contrario, distintos nodos pueden discrepar sobre quién está “en el grupo” y provocar split-brain.
SMR no es magia; es una forma disciplinada de convertir “acuerdo sobre orden” en “acuerdo sobre estado”.
Corrección: seguridad, vivacidad y escribir una especificación clara
Los sistemas distribuidos fallan de maneras extrañas: los mensajes llegan tarde, los nodos reinician, los relojes discrepan y las redes se parten. “Corrección” no es una sensación: es un conjunto de promesas que puedes enunciar con precisión y luego comprobar contra cada situación, incluidos los fallos.
Seguridad vs. vivacidad (con ejemplos concretos)
Seguridad significa “nunca ocurre algo malo”. Ejemplo: en un almacén de clave-valor replicado, no deben confirmarse dos valores distintos para un mismo índice de log. Otro ejemplo: un servicio de locks no debe nunca conceder el mismo lock a dos clientes al mismo tiempo.
Vivacidad significa “eventualmente ocurre algo bueno”. Ejemplo: si una mayoría de réplicas está arriba y la red entrega mensajes eventualmente, una petición de escritura se completa. Una petición de lock obtiene eventualmente un sí o un no (no espera infinito).
La seguridad trata de prevenir contradicciones; la vivacidad de evitar paradas permanentes.
Invariantes: tus no negociables
Una invariante es una condición que debe mantenerse siempre, en cualquier estado alcanzable. Por ejemplo:
- “Cada índice del log tiene como máximo un valor confirmado”.
- “El número de término de un líder nunca disminuye”.
Si una invariante puede violarse durante un fallo, timeout, reintento o partición, no fue realmente aplicada.
Qué significa "probar" aquí
Una prueba es un argumento que cubre todas las ejecuciones posibles, no solo el camino “normal”. Razonas sobre cada caso: pérdida, duplicación o reordenamiento de mensajes; caídas y reinicios de nodos; líderes en competencia; clientes que reintentan.
Las especificaciones evitan comportamientos sorpresa
Una especificación clara define el estado, las acciones permitidas y las propiedades requeridas. Eso evita ambigüedades como “el sistema debe ser consistente” que pueden convertirse en expectativas contradictorias. Las especificaciones te obligan a decir qué pasa durante particiones, qué significa “confirmar” y en qué pueden confiar los clientes —antes de que la producción te enseñe por las malas.
De la teoría a la práctica: modelado con TLA+
Una de las lecciones más prácticas de Lamport es que puedes (y a menudo debes) diseñar un protocolo distribuido en un nivel más alto que el código. Antes de preocuparte por hilos, RPCs y bucles de reintento, puedes escribir las reglas del sistema: qué acciones están permitidas, qué estado puede cambiar y qué nunca debe ocurrir.
Para qué sirve TLA+
TLA+ es un lenguaje de especificación y una herramienta de model checking para describir sistemas concurrentes y distribuidos. Escribes un modelo sencillo y casi matemático del sistema —estados y transiciones— más las propiedades que te importan (por ejemplo, “como máximo un líder” o “una entrada confirmada nunca desaparece”).
Luego, el model checker explora intercalados posibles, retrasos de mensajes y fallos para encontrar un contraejemplo: una secuencia concreta de pasos que viola tu propiedad. En lugar de debatir casos límite en reuniones, obtienes un argumento ejecutable.
Un bug que un modelo puede detectar
Considera un paso de “commit” en un log replicado. En código es fácil, por accidente, permitir que dos nodos marquen dos entradas distintas como confirmadas en el mismo índice bajo un timing raro.
Un modelo en TLA+ puede revelar una traza como:
- El Nodo A confirma la entrada X en el índice 10 tras escuchar a un quórum.
- El Nodo B (con datos obsoletos) también forma un quórum y confirma la entrada Y en el índice 10.
Eso es un commit duplicado —una violación de seguridad que quizá solo aparece una vez al mes en producción, pero que sale rápidamente bajo búsqueda exhaustiva. Modelos similares suelen detectar actualizaciones perdidas, dobles aplicaciones o “ack pero no duradero”.
Cuándo merece la pena modelar
TLA+ es más valioso para la lógica de coordinación crítica: elección de líder, cambios de membresía, flujos tipo consenso y cualquier protocolo donde orden y manejo de fallos interactúen. Si un bug podría corromper datos o requerir recuperación manual, un modelo pequeño suele ser más barato que depurarlo después.
Si construyes herramientas internas alrededor de estas ideas, un flujo práctico es escribir una especificación ligera (incluso informal), implementar y luego generar tests a partir de las invariantes de la spec. Plataformas como Koder.ai pueden ayudar acelerando el ciclo construir-probar: describes el comportamiento deseado de orden/consenso en lenguaje natural, iteras sobre el scaffolding del servicio (frontends React, backends Go con PostgreSQL o clientes Flutter) y mantienes visible “lo que nunca debe ocurrir” mientras despliegas.
Consejos prácticos para construir y operar sistemas fiables
Añade un panel de control
Crea un cliente admin en Flutter para inspeccionar logs, trazas y el estado de las réplicas desde cualquier lugar.
El gran regalo de Lamport para los practicantes es una mentalidad: trata el tiempo y el orden como datos que modelas, no como supuestos heredados del reloj de pared. Esa mentalidad se traduce en hábitos que puedes aplicar el lunes.
Traducir teoría en prácticas de ingeniería diarias
Si los mensajes pueden retrasarse, duplicarse o llegar fuera de orden, diseña cada interacción para ser segura bajo esas condiciones.
- Idempotencia por defecto: haz que “hacerlo otra vez” sea inofensivo. Usa claves de idempotencia para pagos, aprovisionamiento o cualquier escritura que puedas reintentar.
- Reintentos con deduplicación: los reintentos son necesarios, pero sin deduplicación crearás dobles escrituras. Rastrea IDs de petición y guarda marcadores de “ya procesado”.
- Entrega al menos una vez + efectos exactamente una vez: acepta que la red puede entregar dos veces; asegura que los cambios de estado no lo hagan.
Ten cuidado con timeouts y relojes
Los timeouts no son verdad; son política. Un timeout solo te dice “no recibí respuesta a tiempo”, no “la otra parte no actuó”. Dos implicaciones concretas:
- No trates un timeout como una falla definitiva. Diseña caminos de compensación y reconciliación.
- Evita usar el tiempo de reloj local para ordenar eventos entre nodos. Usa números de secuencia, contadores monotónicos o metadatos causales explícitos (por ejemplo, “esta actualización sustituye a la versión X”).
Observabilidad que respete la causalidad
Las buenas herramientas de depuración codifican orden, no solo timestamps.
- IDs de traza en todas partes: propaga un ID de correlación/trace por cada salto y línea de log.
- Pistas causales en logs: registra IDs de mensaje, IDs de petición padre y “qué pensaba que era la versión más reciente” al tomar decisiones.
- Reproducciones deterministas: graba inputs (comandos) para poder reproducir comportamiento y confirmar si un bug depende del timing o de la lógica.
Preguntas de diseño para hacerse antes de desplegar
Antes de añadir una característica distribuida, exige claridad con unas pocas preguntas:
- ¿Qué pasa si la misma petición se procesa dos veces?
- ¿Qué orden necesitamos (si es que necesitamos alguno), y dónde se aplica?
- ¿Qué fallos son “seguros” (sin mal estado) vs. “ruidosos” (visibles al usuario) vs. “silenciosos” (corrupción oculta)?
- ¿Cuál es la ruta de recuperación tras una caída parcial o una partición de red?
- ¿Qué registraremos para reconstruir la historia de "ocurrió-antes" en producción?
Estas preguntas no requieren un doctorado —solo disciplina para tratar el orden y la corrección como requisitos de producto de primera clase.
Conclusión y pasos sugeridos siguientes
El legado duradero de Lamport es una forma de pensar con claridad cuando los sistemas no comparten reloj y no están de acuerdo por defecto sobre “qué pasó”. En lugar de perseguir el tiempo perfecto, rastreas la causalidad (qué pudo influir en qué), la representas con tiempo lógico (marcas de tiempo de Lamport) y —cuando el producto exige una única historia— construyes acuerdo (consenso) para que cada réplica aplique la misma secuencia de decisiones.
Ese hilo conduce a una mentalidad práctica de ingeniería:
Especifica primero, construye después
Escribe las reglas que necesitas: qué nunca debe ocurrir (seguridad) y qué debe ocurrir eventualmente (vivacidad). Luego implementa para esa spec y prueba el sistema bajo retrasos, particiones, reintentos, mensajes duplicados y reinicios de nodos. Muchas “caídas misteriosas” son en realidad faltas de enunciados como “una petición puede procesarse dos veces” o “los líderes pueden cambiar en cualquier momento”.
Aprende más con pasos concretos
Si quieres profundizar sin ahogarte en formalismos:
- Lee “Time, Clocks, and the Ordering of Events in a Distributed System” de Lamport para interiorizar ocurrió-antes.
- Ojea “Paxos Made Simple” para la intuición de seguridad: una vez elegido un valor, el progreso futuro no puede contradecirlo.
- Mira una charla introductoria de TLA+ y modela un protocolo diminuto (un servicio de locks o un registro de dos réplicas) y compruébalo.
Prueba un ejercicio práctico
Elige un componente que tengas a tu cargo y escribe un “contrato de fallos” de una página: qué asumes sobre la red y el almacenamiento, qué operaciones son idempotentes y qué garantías de orden provees.
Si quieres hacer el ejercicio más concreto, crea un pequeño servicio “demo de orden”: una API que anexe comandos a un log, un worker en background que los aplique y una vista admin que muestre metadatos de causalidad y reintentos. Hacer esto en Koder.ai puede ser una forma rápida de iterar —especialmente si buscas scaffolding, despliegue/hosting acelerado, snapshots/rollback para experimentos y exportación de código fuente cuando estés listo.
Hecho correctamente, estas ideas reducen caídas porque menos comportamientos son implícitos. También simplifican el razonamiento: dejas de discutir sobre el tiempo y empiezas a probar qué significan realmente el orden, el acuerdo y la corrección para tu sistema.