18 ago 2025·8 min
LLVM de Chris Lattner: el motor silencioso detrás de las toolchains modernas
Descubre cómo LLVM, impulsado por la visión de Chris Lattner, se convirtió en la plataforma modular de compilación que potencia optimizaciones, mejores diagnósticos y builds rápidos.
Qué es LLVM, en palabras sencillas
LLVM se entiende mejor como la “sala de máquinas” que comparten muchos compiladores y herramientas de desarrollo.
Cuando escribes código en un lenguaje como C, Swift o Rust, algo tiene que traducir ese código a instrucciones que tu CPU pueda ejecutar. Un compilador tradicional solía construir todo el flujo por sí mismo. LLVM toma un enfoque distinto: ofrece un núcleo reutilizable y de alta calidad que maneja las partes difíciles y costosas—optimización, análisis y generación de código máquina para muchos tipos de procesadores.
Una base compartida para muchos lenguajes
LLVM no suele ser un compilador único que “uses directamente”. Es infraestructura de compilador: bloques de construcción que los equipos de lenguaje pueden ensamblar en una cadena de herramientas. Un equipo puede centrarse en la sintaxis, la semántica y las características orientadas al desarrollador, y luego delegar el trabajo pesado a LLVM.
Esa base compartida es una gran razón por la que los lenguajes modernos pueden entregar cadenas de herramientas rápidas y seguras sin reinventar décadas de trabajo en compiladores.
Por qué importa aunque no seas un experto en compiladores
LLVM aparece en la experiencia diaria del desarrollador:
- Velocidad: puede transformar código de alto nivel en código máquina eficiente en múltiples plataformas.
- Mejores errores y depuración: el ecosistema alrededor de LLVM posibilita diagnósticos más ricos y mejores herramientas.
- Más que “solo compilación”: análisis estático, sanitizadores, cobertura de código y otras ayudas para desarrolladores a menudo se construyen sobre la misma representación y bibliotecas subyacentes.
Lo que este artículo será (y no será)
Esta es una visita guiada por las ideas que puso en marcha Chris Lattner: cómo está estructurado LLVM, por qué la capa intermedia importa y cómo permite optimizaciones y soporte multiplataforma. No es un libro de texto; mantendremos el foco en la intuición y el impacto en el mundo real más que en la teoría formal.
La visión original de Chris Lattner
Chris Lattner es un científico e ingeniero informático que, como estudiante de posgrado a principios de los 2000, inició LLVM con una frustración práctica: la tecnología de compiladores era poderosa, pero difícil de reutilizar. Si querías un nuevo lenguaje de programación, mejores optimizaciones o soporte para una nueva CPU, a menudo tenías que manipular un compilador “todo en uno” muy acoplado donde cada cambio tenía efectos colaterales.
El problema que quería resolver
En ese momento, muchos compiladores se construían como máquinas individuales y grandes: la parte que entendía el lenguaje, la que optimizaba y la que generaba código máquina estaban profundamente entrelazadas. Eso los hacía eficaces para su propósito original, pero costosos de adaptar.
El objetivo de Lattner no era “un compilador para un lenguaje”. Era una base compartida que pudiera alimentar muchos lenguajes y herramientas—sin que cada equipo tuviera que reescribir las mismas piezas complejas una y otra vez. La apuesta era que si estandarizabas el núcleo del pipeline, podrías innovar más rápido en los extremos.
Por qué la “infraestructura modular” era una idea nueva
El cambio clave fue tratar la compilación como un conjunto de bloques de construcción separables con límites claros. En un mundo modular:
- un equipo de lenguaje puede centrarse en el parsing y las características para desarrolladores,
- un equipo de optimización puede mejorar el rendimiento una vez y compartirlo ampliamente,
- el soporte de hardware puede añadirse sin rediseñar todo lo que está aguas arriba.
Esa separación suena obvia ahora, pero chocaba con la forma en que muchos compiladores de producción habían evolucionado.
Código abierto, hecho para ser usado por otros
LLVM se lanzó como open source desde temprano, lo cual importó porque una infraestructura compartida solo funciona si múltiples grupos pueden confiar en ella, inspeccionarla y extenderla. Con el tiempo, universidades, empresas y colaboradores independientes moldearon el proyecto añadiendo objetivos, corrigiendo casos límite, mejorando el rendimiento y construyendo nuevas herramientas a su alrededor.
Ese aspecto comunitario no fue solo buena voluntad—era parte del diseño: haz el núcleo ampliamente útil y valdrá la pena mantenerlo entre muchos.
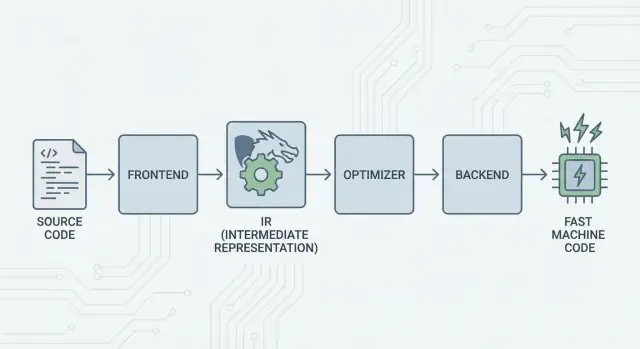
La gran idea: frontends, un núcleo compartido y backends
La idea central de LLVM es sencilla: dividir un compilador en tres piezas principales para que muchos lenguajes puedan compartir el trabajo más difícil.
1) Frontends: “¿Qué quiso decir el programador?”
Un frontend entiende un lenguaje de programación concreto. Lee tu código fuente, verifica las reglas (sintaxis y tipos) y lo convierte en una representación estructurada.
El punto clave: los frontends no necesitan conocer todos los detalles de la CPU. Su trabajo es traducir conceptos del lenguaje—funciones, bucles, variables—en algo más universal.
2) El núcleo compartido: un único trabajo en lugar de N×M
Tradicionalmente, construir un compilador implicaba hacer el mismo trabajo una y otra vez:
- Con N lenguajes y M objetivos de chip, terminas con N×M combinaciones a soportar.
LLVM reduce eso a:
- N frontends que traducen a una forma compartida
- M backends que traducen desde esa forma compartida a código máquina
Esa “forma compartida” es el centro de LLVM: una tubería común donde viven las optimizaciones y los análisis. Esto es lo que simplifica enormemente. Las mejoras en el núcleo (como mejores optimizaciones o mejor información de depuración) pueden beneficiar a muchos lenguajes a la vez, en lugar de reimplementarse en cada compilador.
3) Backends: “¿Cómo hacemos que esto corra rápido en esa CPU?”
Un backend toma la representación compartida y produce salida específica de máquina: instrucciones para x86, ARM, etc. Aquí es donde importan detalles como registros, convenciones de llamada y selección de instrucciones.
Una imagen intuitiva del pipeline
Piensa en la compilación como una ruta de viaje:
- Código fuente comienza en un país específico del lenguaje (frontend).
- Cruza una frontera hacia un “lenguaje medio” estandarizado (el núcleo de LLVM y sus pases).
- Luego toma un tren local hacia una ciudad destino específica (backend para tu máquina objetivo).
El resultado es una cadena de herramientas modular: los lenguajes pueden centrarse en expresar ideas con claridad, mientras que el núcleo compartido de LLVM se centra en hacer que esas ideas se ejecuten de forma eficiente en muchas plataformas.
LLVM IR: la capa intermedia que habilita la reutilización
LLVM IR (Intermediate Representation) es el “lenguaje común” que se sitúa entre un lenguaje de programación y el código máquina que ejecuta tu CPU.
Un frontend de compilador (como Clang para C/C++) traduce tu código fuente a esta forma compartida. Entonces los optimizadores y generadores de código de LLVM trabajan sobre la IR, no sobre el lenguaje original. Finalmente, un backend convierte la IR en instrucciones para un objetivo específico (x86, ARM, etc.).
Un lenguaje común entre herramientas y CPU
Piensa en LLVM IR como un puente cuidadosamente diseñado:
- Por encima: muchos lenguajes fuente pueden conectarse (C, C++, Rust, Swift, Julia, etc.).
- Por debajo: se pueden dirigir múltiples CPUs.
- En el medio: las mismas herramientas de análisis y optimización pueden reutilizarse.
Por eso la gente suele describir LLVM como “infraestructura de compilador” en lugar de “un compilador”. La IR es el contrato compartido que hace que esa infraestructura sea reutilizable.
Por qué la IR permite reutilización (y ahorra trabajo)
Una vez que el código está en LLVM IR, la mayoría de los pases de optimización no necesitan saber si comenzó como plantillas de C++, iteradores de Rust o genéricos de Swift. Mayormente se preocupan por ideas universales como:
- “Este valor es una constante.”
- “Esta computación se repite; ¿podemos reutilizar el resultado?”
- “Esta carga de memoria se puede mover o eliminar de forma segura.”
Así, los equipos de lenguaje no tienen que construir (y mantener) su propia pila completa de optimización. Pueden centrarse en el frontend—parsing, comprobación de tipos, reglas específicas del lenguaje—y luego entregar a LLVM el trabajo pesado.
Cómo “se ve” conceptualmente
LLVM IR es lo suficientemente bajo nivel como para mapear limpiamente al código máquina, pero aún lo bastante estructurado para analizarse. Conceptualmente, está construido de instrucciones simples (add, compare, load/store), flujo de control explícito (branches) y valores fuertemente tipados—más parecido a un ensamblador ordenado diseñado para compiladores que a algo que los humanos suelen escribir.
Cómo funcionan las optimizaciones (sin matemáticas)
Cuando la gente oye “optimización de compilador”, a menudo imagina trucos misteriosos. En LLVM, la mayoría de las optimizaciones son entendidas mejor como reescrituras mecánicas y seguras del programa—transformaciones que preservan lo que hace el código, pero buscan hacerlo más rápido (o más pequeño).
Piénsalo como editar, no inventar
LLVM toma tu código (en LLVM IR) y aplica repetidamente pequeñas mejoras, como pulir un borrador:
- Eliminar trabajo duplicado: si un valor se calcula dos veces y nada cambió entre medias, LLVM puede calcularlo una vez y reutilizar el resultado.
- Simplificar lógica obvia: expresiones constantes pueden evaluarse temprano (por ejemplo, convertir
3 * 4en12), para que la CPU haga menos en tiempo de ejecución. - Racionalizar bucles: los pases relacionados con bucles pueden reducir comprobaciones repetidas, mover trabajo invariante fuera del bucle o reconocer patrones que pueden ejecutarse de forma más eficiente.
Estos cambios son deliberadamente conservadores. Un pase solo realiza una reescritura cuando puede demostrar que no cambiará el significado del programa.
Ejemplos con los que es fácil identificarse
Si tu programa hace esto conceptualmente:
- Lee el mismo valor de configuración en cada iteración de un bucle
- Realiza el mismo cálculo con las mismas entradas en varios lugares
- Comprueba una condición que siempre es verdadera/falsa en un contexto dado
…LLVM intenta convertir eso en “haz la preparación una vez”, “reutiliza resultados” y “elimina ramas muertas”. Es menos magia y más mantenimiento del código.
El verdadero intercambio: tiempo de compilación vs. tiempo de ejecución
La optimización no es gratis: más análisis y más pases suelen significar compilación más lenta, aunque el programa final se ejecute más rápido. Por eso las cadenas de herramientas ofrecen niveles como “optimizar un poco” frente a “optimizar agresivamente”.
Los perfiles pueden ayudar aquí. Con profile-guided optimization (PGO), ejecutas el programa, recopilas datos de uso reales y luego recompilas para que LLVM centre su esfuerzo en los caminos que realmente importan—haciendo el intercambio más predecible.
Backends: alcanzar muchas CPUs sin reescribirlo todo
Convierte compartir en créditos
Obtén créditos compartiendo lo que creas o invitando a otros a probar Koder.ai.
Un compilador tiene dos trabajos muy distintos. Primero, necesita entender tu código fuente. Segundo, necesita producir código máquina que una CPU específica pueda ejecutar. Los backends de LLVM se centran en ese segundo trabajo.
Qué hace realmente un backend
Piensa en LLVM IR como una “receta universal” de lo que el programa debe hacer. Un backend convierte esa receta en las instrucciones exactas para una familia de procesadores—x86-64 para la mayoría de escritorios y servidores, ARM64 para muchos teléfonos y portátiles nuevos, o objetivos especializados como WebAssembly.
Concretamente, un backend es responsable de:
- Selección de instrucciones: mapear operaciones de la IR a instrucciones reales de la CPU
- Asignación de registros: elegir qué valores viven en registros rápidos de la CPU frente a la memoria
- Planificación (scheduling): ordenar instrucciones para que la CPU pueda ejecutarlas eficientemente
- Salida de ensamblado/objeto: emitir código que el enlazador y el SO entiendan
Por qué la infraestructura compartida facilita añadir soporte de hardware
Sin un núcleo compartido, cada lenguaje tendría que reimplementar todo esto para cada CPU que quisiera soportar—una cantidad enorme de trabajo y una carga de mantenimiento constante.
LLVM invierte eso: los frontends (como Clang) producen LLVM IR una vez, y los backends se encargan de la “milla final” por objetivo. Añadir soporte para una nueva CPU generalmente significa escribir un backend (o extender uno existente), no reescribir todos los compiladores.
Portabilidad para equipos que envían en múltiples plataformas
Para proyectos que deben ejecutarse en Windows/macOS/Linux, en x86 y ARM, o incluso en el navegador, el modelo de backends de LLVM es una ventaja práctica. Puedes mantener una base de código y en gran parte una sola tubería de compilación, y simplemente reorientar el objetivo eligiendo un backend diferente (o compilando de forma cruzada).
Esa portabilidad es por qué LLVM aparece en tantos sitios: no se trata solo de velocidad—también de evitar trabajo repetido y específico por plataforma que ralentiza a los equipos.
Clang: donde muchos desarrolladores sienten LLVM por primera vez
Clang es el frontend para C, C++ y Objective-C que se conecta a LLVM. Si LLVM es el motor compartido que puede optimizar y generar código máquina, Clang es la parte que lee tus archivos fuente, entiende las reglas del lenguaje y convierte lo que escribiste en una forma que LLVM puede manejar.
Por qué Clang ganó atención
Muchos desarrolladores no descubrieron LLVM leyendo artículos académicos—lo hicieron la primera vez que cambiaron de compilador y el feedback mejoró notablemente.
Los diagnósticos de Clang son conocidos por ser más legibles y específicos. En lugar de errores vagos, a menudo señala el token exacto que causó el problema, muestra la línea relevante y explica qué esperaba. Eso importa en el trabajo diario porque el ciclo “compilar, arreglar, repetir” se vuelve menos frustrante.
Clang también expone interfaces limpias y bien documentadas (notablemente a través de libclang y el ecosistema de herramientas de Clang). Eso facilitó que editores, IDEs y otras herramientas de desarrollo integraran comprensión profunda del lenguaje sin reinventar un parser de C/C++.
Cómo aparece en flujos de trabajo diarios
Una vez que una herramienta puede parsear y analizar tu código de forma fiable, empiezas a obtener características que se sienten menos como edición de texto y más como trabajar con un programa estructurado:
- Navegación de código precisa (“ir a la definición”, “encontrar referencias”) incluso en proyectos grandes y con macros en C++
- Soporte de refactorización que entiende símbolos y ámbitos, no solo buscar y reemplazar
- Sugerencias en línea y correcciones rápidas impulsadas por sintaxis e información de tipos real
Por eso Clang suele ser el primer “punto de contacto” con LLVM: es donde se originan mejoras prácticas en la experiencia del desarrollador. Incluso si nunca piensas en LLVM IR o backends, te beneficias cuando el autocompletado de tu editor es más inteligente, tus comprobaciones estáticas son más precisas y los errores de compilación son más fáciles de abordar.
Por qué muchos lenguajes modernos se basan en LLVM
LLVM atrae a los equipos de lenguaje por una razón simple: les permite centrarse en el lenguaje en lugar de pasarse años reinventando un compilador optimizador completo.
Tiempo de salida al mercado más rápido
Crear un nuevo lenguaje ya implica parsing, comprobación de tipos, diagnósticos, herramientas de paquetes, documentación y soporte comunitario. Si además debes crear un optimizador de producción, generador de código y soporte de plataforma desde cero, el lanzamiento se retrasa—a veces años.
LLVM proporciona un núcleo de compilación listo: asignación de registros, selección de instrucciones, pases de optimización maduros y objetivos para CPUs comunes. Los equipos pueden enchufar un frontend que baje su lenguaje a LLVM IR y luego confiar en la tubería existente para producir código nativo para macOS, Linux y Windows.
Alto rendimiento (sin “hazañas heroicas”)
El optimizador y los backends de LLVM son el resultado de ingeniería a largo plazo y prueba constante en el mundo real. Eso se traduce en un rendimiento base sólido para los lenguajes que lo adoptan—a menudo suficiente desde el principio y mejorable a medida que LLVM mejora.
Por eso varios lenguajes conocidos se han construido sobre él:
- Swift utiliza LLVM para generar binarios nativos altamente optimizados en plataformas Apple.
- Rust depende de LLVM para generación de código y múltiples objetivos de arquitectura.
- Julia usa LLVM para habilitar código numérico rápido, incluida la compilación en tiempo de ejecución para cargas de trabajo especializadas.
No todos los lenguajes necesitan LLVM
Elegir LLVM es una compensación, no un requisito. Algunos lenguajes priorizan binarios muy pequeños, compilación ultra-rápida o control total sobre toda la cadena de herramientas. Otros ya tienen compiladores establecidos (como ecosistemas basados en GCC) o prefieren backends más simples.
LLVM es popular porque es una buena opción por defecto—no porque sea la única vía válida.
JIT y compilación en tiempo de ejecución: bucles de retroalimentación rápidos
Construye desde un chat
Convierte una idea en una app funcional con un chat simple, sin instalar ni configurar herramientas.
“Just-in-time” (JIT) es más sencillo de entender como compilar mientras ejecutas. En lugar de traducir todo el código por adelantado en un ejecutable final, un motor JIT espera hasta que una parte del código sea realmente necesaria y compila esa parte al vuelo—a menudo usando información de tiempo de ejecución (como tipos exactos y tamaños de datos) para tomar mejores decisiones.
Por qué el JIT puede parecer tan rápido
Porque no tienes que compilarlo todo de entrada, los sistemas JIT pueden ofrecer retroalimentación rápida para trabajo interactivo. Escribes o generas un fragmento de código, lo ejecutas inmediatamente y el sistema compila solo lo necesario ahora. Si ese mismo código se ejecuta repetidamente, el JIT puede almacenar en caché el resultado compilado o recompilar secciones “calientes” de forma más agresiva.
Dónde ayuda la compilación en tiempo de ejecución en la práctica
El JIT brilla cuando las cargas de trabajo son dinámicas o interactivas:
- REPLs y notebooks: evalúa fragmentos al instante y aun así obtén ejecución a velocidad nativa para bucles pesados.
- Plugins y extensiones: las aplicaciones pueden cargar código de usuario en tiempo de ejecución y compilarlo para la CPU anfitriona.
- Cargas dinámicas: cuando las entradas varían mucho, el perfilado en tiempo de ejecución puede guiar qué rutas merecen optimización.
- Computación científica: kernels generados (para un tamaño de matriz específico, forma de modelo o característica de hardware) pueden compilarse bajo demanda.
El papel de LLVM (sin exageraciones)
LLVM no hace que todo programa sea más rápido por arte de magia, ni es un JIT completo por sí mismo. Lo que ofrece es un kit de herramientas: una IR bien definida, un gran conjunto de pases de optimización y generación de código para muchas CPUs. Proyectos pueden construir motores JIT encima de esos bloques, escogiendo el balance adecuado entre tiempo de inicio, rendimiento pico y complejidad.
Rendimiento, predictibilidad y compensaciones en el mundo real
Las cadenas de herramientas basadas en LLVM pueden producir código extremadamente rápido, pero “rápido” no es una propiedad única y estable. Depende de la versión del compilador, la CPU objetivo, las opciones de optimización e incluso de lo que le pidas al compilador que suponga sobre el programa.
Por qué el mismo código fuente puede producir resultados distintos
Dos compiladores pueden leer el mismo código fuente y aun así generar código máquina notablemente distinto. Parte de eso es intencional: cada compilador tiene su conjunto de pases de optimización, heurísticas y ajustes por defecto. Incluso dentro de LLVM, Clang 15 y Clang 18 pueden tomar decisiones de inlining distintas, vectorizar bucles diferentes o planificar instrucciones de otra forma.
También puede ser causado por comportamiento indefinido y comportamiento no especificado en el lenguaje. Si tu programa depende accidentalmente de algo que el estándar no garantiza (como overflow con signo en C), compiladores distintos—o banderas distintas—pueden “optimizar” de maneras que cambien los resultados.
Determinismo, compilaciones de depuración y de lanzamiento
La gente a menudo espera que la compilación sea determinista: mismas entradas, mismas salidas. En la práctica, te acercarás mucho, pero no siempre obtendrás binarios idénticos entre entornos. Rutas de compilación, marcas de tiempo, orden de enlace, datos guiados por perfil y opciones de LTO pueden afectar el artefacto final.
La distinción más práctica es depuración vs. lanzamiento. Las compilaciones de depuración típicamente deshabilitan muchas optimizaciones para preservar la depuración paso a paso y pilas legibles. Las compilaciones de lanzamiento activan transformaciones agresivas que pueden reordenar código, inlinear funciones y eliminar variables—excelentes para rendimiento, pero a veces más difíciles de depurar.
Consejo práctico: mide, no adivines
Trata el rendimiento como un problema de medición:
- Haz benchmarks en hardware representativo y con conjuntos de datos realistas.
- Calienta caches y ejecuta múltiples iteraciones.
- Compara compilaciones con banderas explícitas (por ejemplo, cambiar
-O2vs-O3, activar/desactivar LTO, o seleccionar un objetivo con-march).
Pequeños cambios en las banderas pueden mover el rendimiento en cualquier dirección. El flujo de trabajo más seguro es: formula una hipótesis, mídela y mantén benchmarks cercanos a lo que tus usuarios ejecutan realmente.
Herramientas más allá de la compilación: análisis, depuración y seguridad
Crea multiplataforma
Crea una app móvil en Flutter junto a tu web y servidor.
LLVM se describe a menudo como un kit de compilador, pero muchos desarrolladores sienten su impacto a través de herramientas que se sitúan alrededor de la compilación: analizadores, depuradores y comprobaciones de seguridad que se activan durante builds y tests.
Análisis e instrumentación como “complementos”
Porque LLVM expone una representación intermedia (IR) bien definida y una tubería de pases, es natural construir pasos extra que inspeccionen o reescriban código con un propósito distinto al rendimiento. Un pase puede insertar contadores para perfilado, marcar operaciones de memoria sospechosas o recopilar datos de cobertura.
El punto clave es que estas características pueden integrarse sin que cada equipo de lenguaje tenga que reinventar la misma infraestructura.
Sanitizadores: atrapar errores cerca de la fuente
Clang y LLVM popularizaron una familia de “sanitizadores” en tiempo de ejecución que instrumentan programas para detectar clases comunes de errores durante las pruebas—piensa en accesos fuera de límites, uso después de liberar, condiciones de carrera y patrones de comportamiento indefinido. No son escudos mágicos y típicamente ralentizan los programas, por lo que se usan principalmente en CI y pruebas pre-lanzamiento. Pero cuando se activan, a menudo señalan una ubicación precisa en el código y una explicación legible, justo lo que los equipos necesitan al perseguir fallos intermitentes.
Mejores diagnósticos = incorporación más rápida
La calidad de las herramientas también es comunicación. Advertencias claras, mensajes de error accionables e información de depuración consistente reducen el “factor misterio” para quienes se incorporan. Cuando la cadena de herramientas explica qué pasó y cómo arreglarlo, los desarrolladores pasan menos tiempo memorizando rarezas del compilador y más tiempo aprendiendo la base de código.
LLVM no garantiza diagnósticos o seguridad perfectos por sí solo, pero proporciona una base común que hace prácticas estas herramientas orientadas al desarrollador, fáciles de construir, mantener y compartir entre proyectos.
Cuándo usar LLVM (y cuándo no)
LLVM se piensa mejor como un “construye-tu-propio compilador y kit de herramientas”. Esa flexibilidad es exactamente por lo que alimenta tantas cadenas de herramientas modernas—pero también es la razón por la que no es la respuesta correcta para todos los proyectos.
Cuando LLVM encaja muy bien
LLVM es excelente cuando quieres reutilizar ingeniería seria de compiladores sin reinventarla.
Si estás construyendo un nuevo lenguaje de programación, LLVM puede darte una tubería de optimización probada, generación de código madura para muchas CPUs y un camino hacia buen soporte de depuración.
Si estás distribuyendo aplicaciones multiplataforma, el ecosistema de backends de LLVM reduce el trabajo necesario para apuntar a distintas arquitecturas. Te concentras en tu lenguaje o lógica de producto, en lugar de escribir generadores de código separados.
Si tu objetivo son herramientas para desarrolladores—linters, análisis estático, navegación de código, refactorización—LLVM (y el ecosistema a su alrededor) es una base fuerte porque el compilador ya “entiende” la estructura y los tipos del código.
Cuando puede ser excesivo
LLVM puede resultar pesado si trabajas en sistemas empotrados muy pequeños donde el tamaño de build, la memoria y el tiempo de compilación están muy restringidos.
También puede no encajar para pipelines muy especializados donde no quieres optimizaciones de propósito general, o cuando tu “lenguaje” está más cerca de un DSL fijo con un mapeo directo a código máquina.
Una lista de comprobación simple
Hazte tres preguntas:
- ¿Necesitamos apuntar a múltiples plataformas/CPUs ahora o pronto?
- ¿Nos beneficiamos de optimizaciones existentes e info de depuración, en lugar de construir las nuestras?
- ¿Queremos un camino de ecosistema (herramientas, integraciones, contratación) más que un compilador mínimo y personalizado?
Si respondiste “sí” a la mayoría, LLVM suele ser una apuesta práctica. Si principalmente quieres el compilador más pequeño y simple que resuelva un problema muy concreto, un enfoque más ligero puede ganar.
Nota práctica para equipos de producto: los beneficios de LLVM sin volverse expertos en compiladores
La mayoría de equipos no quieren “adoptar LLVM” como un proyecto. Quieren resultados: builds multiplataforma, binarios rápidos, buenos diagnósticos y herramientas confiables.
Por eso plataformas como Koder.ai resultan interesantes en este contexto. Si tu flujo de trabajo está cada vez más impulsado por automatización de alto nivel (planificación, generación de scaffolding, iteración en bucle cerrado), aún te beneficias de LLVM indirectamente a través de las cadenas de herramientas subyacentes—ya sea que construyas una app React, un backend Go con PostgreSQL o un cliente móvil Flutter. El enfoque de Koder.ai de “vibe-coding” guiado por chat se centra en lanzar producto más rápido, mientras que la infraestructura moderna del compilador (LLVM/Clang y afines, cuando aplica) sigue haciendo el trabajo poco glamuroso de optimización, diagnósticos y portabilidad en segundo plano.