Qué debe ofrecer la búsqueda instantánea del lado del servidor
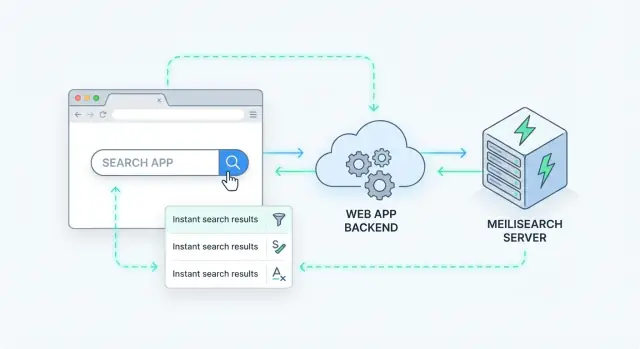
La búsqueda del lado del servidor significa que la consulta se procesa en tu servidor (o en un servicio de búsqueda dedicado), no dentro del navegador. Tu app envía una petición de búsqueda, el servidor la ejecuta contra un índice y devuelve resultados ordenados.
Esto importa cuando tu conjunto de datos es demasiado grande para enviarlo al cliente, cuando necesitas relevancia consistente en varias plataformas o cuando el control de acceso es innegociable (por ejemplo, herramientas internas donde los usuarios solo deben ver lo que les está permitido). También es la elección por defecto cuando quieres analíticas, registro y rendimiento predecible.
La gente no piensa en motores de búsqueda: juzga la experiencia. Un buen flujo de búsqueda “instantánea” suele significar:
- Retroalimentación rápida: los resultados se actualizan rápido mientras el usuario escribe, sin pausas incómodas.
- Los errores tipográficos no lo rompen: las faltas de ortografía, letras intercambiadas y palabras parciales aún encuentran los ítems correctos.
- Controles útiles: filtrado (categoría, estado, rango de precio), ordenación (más reciente, más barato) y facetas (conteos por filtro) se sienten naturales.
- Orden relevante: los “mejores” resultados aparecen primero, no solo los más nuevos o los que repiten la palabra clave.
Si falta alguno de estos, los usuarios compensan probando distintas consultas, desplazándose más o abandonando la búsqueda por completo.
Qué te ayudará esta guía
Este artículo es una guía práctica para construir esa experiencia con Meilisearch. Cubriremos cómo configurarlo de forma segura, cómo estructurar y sincronizar tus datos indexados, cómo ajustar la relevancia y las reglas de ranking, cómo añadir filtros/ordenación/facetas y cómo pensar en seguridad y escalado para que la búsqueda siga siendo rápida a medida que tu app crece.
Dónde brilla la búsqueda del lado del servidor
Meilisearch encaja bien en:
- Documentación y bases de conocimiento (encuentra páginas rápido, tolera errores tipográficos)
- Catálogos de producto y marketplaces (los filtros y la ordenación son esenciales)
- Herramientas internas (búsqueda con permisos sobre registros)
- Sitios de contenido (búsqueda en artículos, guías, FAQs)
El objetivo: resultados que se sientan inmediatos, precisos y confiables —sin convertir la búsqueda en un gran proyecto de ingeniería.
Resumen de Meilisearch en palabras llanas
Meilisearch es un motor de búsqueda que ejecutas junto a tu app. Le envías documentos (como productos, artículos, usuarios o tickets de soporte) y construye un índice optimizado para búsquedas rápidas. Tu backend (o frontend) consulta Meilisearch mediante una API HTTP simple y recibe resultados ordenados en milisegundos.
Qué obtienes listo para usar
Meilisearch se centra en las características que la gente espera de una búsqueda moderna:
- Tolerancia a errores tipográficos para que “iphnoe” aún encuentre “iPhone”.
- Controles de relevancia (reglas de ranking) para decidir qué significa “mejor coincidencia” para tu negocio.
- Filtros, ordenación y facetas para que los usuarios puedan acotar resultados por atributos como categoría, rango de precio, disponibilidad o etiquetas.
Está diseñado para sentirse receptivo y tolerante, incluso cuando una consulta es corta, ligeramente incorrecta o ambigua.
Qué no es Meilisearch
Meilisearch no reemplaza tu base de datos principal. Tu base de datos sigue siendo la fuente de la verdad para escrituras, transacciones y restricciones. Meilisearch almacena una copia de los campos que elijas hacer buscables, filtrables o mostrables.
Un buen modelo mental es: base de datos para almacenar y actualizar, Meilisearch para encontrarlo rápidamente.
Expectativas de rendimiento (qué afecta la velocidad)
Meilisearch puede ser extremadamente rápido, pero los resultados dependen de algunos factores prácticos:
- Tamaño y forma de los datos (número de documentos, número de campos y cuánto texto indexas)
- Hardware (CPU, RAM, disco)
- Configuración (qué atributos son buscables/filtrables/ordenables y con qué frecuencia reindexas)
Para conjuntos pequeños o medianos, a menudo puedes ejecutarlo en una única máquina. A medida que tu índice crece, querrás ser más deliberado sobre qué indexas y cómo lo mantienes actualizado: temas que cubriremos más adelante.
Planifica tus índices y el modelo de datos
Antes de instalar nada, decide qué vas a buscar realmente. Meilisearch se sentirá “instantáneo” solo si tus índices y documentos coinciden con la forma en que la gente navega tu app.
Mapea entidades a índices
Empieza listando tus entidades buscables —típicamente productos, artículos, usuarios, documentos de ayuda, ubicaciones, etc. En muchas apps, el enfoque más limpio es un índice por tipo de entidad (por ejemplo, products, articles). Eso mantiene las reglas de ranking y los filtros previsibles.
Si tu UX busca a través de varios tipos en una sola caja (“buscar en todo”), aún puedes mantener índices separados y combinar resultados en tu backend, o crear un índice “global” dedicado más adelante. No forces todo en un solo índice a menos que los campos y filtros estén realmente alineados.
Cada documento necesita un identificador estable (clave primaria). Elige algo que:
- nunca cambie (o cambie muy raramente)
- sea único dentro del índice
- ya exista en tu base de datos (por ejemplo,
id, sku, slug)
Para la forma del documento, prefiere campos planos cuando puedas. Las estructuras planas son más fáciles de filtrar y ordenar. Los campos anidados están bien cuando representan un paquete pequeño e inmutable (por ejemplo, un objeto author), pero evita anidamientos profundos que reflejen todo tu esquema relacional: los documentos de búsqueda deben estar optimizados para lectura, no tener la forma de la base de datos.
Clasifica campos: buscables, filtrables, mostrados
Una forma práctica de diseñar documentos es etiquetar cada campo con un rol:
- Searchable: texto que la gente escribe (title, name, description)
- Filterable: atributos usados como restricciones (category, price range, status, tags)
- Displayed: lo que devuelves a la UI (title, thumbnail URL, snippet corto)
Esto evita un error común: indexar un campo “por si acaso” y luego preguntarse por qué los resultados son ruidosos o los filtros lentos.
Planifica contenido multilingüe
“Idioma” puede significar cosas distintas en tus datos:
- el idioma del documento (cada artículo tiene
lang: "en")
- la localización del usuario (idioma de la UI)
- campos con contenido en varios idiomas (nombres de producto en múltiples idiomas)
Decide pronto si usarás índices separados por idioma (simple y predecible) o un índice único con campos de idioma (menos índices, más lógica). La respuesta correcta depende de si los usuarios buscan en un idioma a la vez y cómo almacenas las traducciones.
Ejecutar Meilisearch es sencillo, pero “seguro por defecto” requiere algunas decisiones: dónde desplegarlo, cómo persistir datos y cómo manejar la clave maestra.
Opciones de despliegue (elige lo que puedas operar)
- Docker (lo más común): rápido para empezar, fácil de actualizar, consistente entre entornos. Úsalo con un volumen persistente.
- VM o bare metal: bueno cuando ya tienes un pipeline estándar de despliegue Linux (systemd, rotación de logs, backups).
- Hosting gestionado: si tu equipo no quiere mantener servidores, busca un proveedor gestionado de Meilisearch o una plataforma que lo ofrezca como complemento. Cambiarás flexibilidad por operaciones más simples.
Conceptos básicos del entorno: almacenamiento, memoria, backups, monitorización
Almacenamiento: Meilisearch escribe su índice en disco. Coloca el directorio de datos en almacenamiento confiable y persistente (no en almacenamiento efímero de contenedores). Planifica capacidad para el crecimiento: los índices pueden expandirse rápidamente con campos de texto grandes y muchos atributos.
Memoria: asigna suficiente RAM para mantener la búsqueda responsiva bajo carga. Si hay swapping, el rendimiento empeorará.
Backups: haz copia de seguridad del directorio de datos de Meilisearch (o usa snapshots en la capa de almacenamiento). Prueba la restauración al menos una vez; una copia que no puedes restaurar es solo un archivo.
Monitorización: supervisa CPU, RAM, uso de disco y E/S de disco. También monitoriza la salud del proceso y los errores en logs. Como mínimo, alerta si el servicio se detiene o si el disco se queda sin espacio.
Siempre ejecuta Meilisearch con una master key en cualquier entorno que no sea de desarrollo local. Almacénala en un gestor de secretos o en un almacén de variables de entorno cifrado (no en Git, no en un .env en texto plano comprometido).
Ejemplo (Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
También considera reglas de red: enlaza a una interfaz privada o restringe el acceso entrante para que solo tu backend pueda alcanzar Meilisearch.
Lista de verificación al iniciar por primera vez
curl -s http://localhost:7700/version
Indexar documentos y mantenerlos sincronizados
Lleva la búsqueda a móviles
Genera un cliente Flutter que llame de forma consistente a tu endpoint de búsqueda en el backend.
La indexación en Meilisearch es asíncrona: envías documentos, Meilisearch pone en cola una tarea y solo después de que esa tarea tenga éxito esos documentos se vuelven buscables. Trata la indexación como un sistema de trabajos, no como una sola petición.
Un flujo simple de indexación (añadir → esperar → verificar)
- Añadir documentos (asegúrate de que cada uno tenga un id único y estable, normalmente
id).
curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
- Esperar la tarea. La respuesta de la API incluye un
taskUid. Haz polling hasta que sea succeeded (o failed).
curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
- Verificar conteos y búsqueda básica. Confirma que el índice tiene el número esperado de documentos y que una consulta simple devuelve resultados.
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Si los conteos no coinciden, no adivines: revisa primero los detalles de error de la tarea.
Batching que no te sorprenda más adelante
El batching consiste en mantener las tareas predecibles y recuperables.
- Empieza con 1.000–10.000 documentos por lote, o limita por tamaño de payload (para muchas apps, 5–15 MB por petición es cómodo).
- Prefiere muchos lotes pequeños sobre una única importación enorme; es más fácil reintentar y localizar datos malos.
- Si tienes cambios frecuentes, indexa continuamente en lotes (por ejemplo, cada minuto) en lugar de reconstruir todo.
Actualizaciones vs reindexación completa
addDocuments funciona como un upsert: los documentos con la misma clave primaria se actualizan, los nuevos se insertan. Úsalo para actualizaciones normales.
Haz una reindexación completa cuando:
- cambiaste significativamente la forma de los documentos,
- necesitas recalcular campos derivados,
- tu sincronización se ha desgastado y quieres un reinicio limpio.
Para eliminaciones, llama explícitamente a deleteDocument(s); de lo contrario los registros antiguos pueden permanecer.
Idempotencia: reintentos seguros cuando fallan los trabajos
La indexación debe ser reintentable. La clave es IDs de documento estables.
- Si una subida de lote agota el tiempo, puedes reenviar el mismo lote: upsert + IDs estables significa que no crearás duplicados.
- Persiste el
taskUid devuelto junto con el id de tu lote/trabajo y reintenta según el estado de la tarea.
- Si ejecutas una cola, haz que el worker sea “at-least-once” seguro: los duplicados deben ser inocuos.
Datos semilla para una prueba rápida en preproducción
Antes de datos de producción, indexa un pequeño conjunto (200–500 ítems) que coincida con tus campos reales. Ejemplo: un conjunto de products con id, name, description, category, brand, price, inStock, createdAt. Esto es suficiente para validar el flujo de tareas, conteos y comportamiento de update/delete —sin esperar una importación masiva.
Relevancia y reglas de ranking que puedes controlar
La “relevancia” de búsqueda es simplemente: qué aparece primero y por qué. Meilisearch hace esto ajustable sin obligarte a construir tu propio sistema de puntuación.
Empieza con los atributos adecuados
Dos ajustes determinan lo que Meilisearch puede hacer con tu contenido:
searchableAttributes: los campos en los que Meilisearch busca cuando un usuario escribe una consulta (por ejemplo: title, summary, tags). El orden importa: los campos anteriores se tratan como más importantes.displayedAttributes: los campos devueltos en la respuesta. Esto afecta la privacidad y el tamaño del payload: si un campo no está en displayed, no se enviará.
Una línea base práctica es hacer buscables unos pocos campos de alta señal (title, texto clave) y mantener los displayed a lo que la UI necesita.
Cómo las reglas de ranking afectan el orden de resultados
Meilisearch ordena documentos coincidentes usando ranking rules —una tubería de “desempates”. Conceptualmente, prefiere:
- resultados que coinciden bien con la consulta (incluyendo tolerancia a errores), luego
- resultados donde las coincidencias son más fuertes (palabras más cercanas, coincidencia en atributos más importantes), luego
- resultados que encajan con tu lógica de negocio (orden personalizado como recencia o popularidad).
No necesitas memorizar los detalles internos para ajustarlo: principalmente eliges qué campos importan más y cuándo aplicar ordenación personalizada.
Objetivos comunes de ajuste (con ejemplos)
Objetivo: “Coincidencias en el título deben ganar.” Pon title primero:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Objetivo: “El contenido más nuevo debe aparecer primero.” Añade un atributo ordenable y ordena en tiempo de consulta (o establece un ranking personalizado):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Luego solicita:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Objetivo: “Promover ítems populares.” Haz popularity ordenable y ordena por él cuando sea apropiado.
Evalúa cambios con una prueba simple de antes/después
Elige 5–10 consultas reales que usen los usuarios. Guarda los resultados principales antes de los cambios y compáralos después.
Ejemplo:
- Antes: consulta
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case
- Después (title-first + exactness): consulta
"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer
Si la lista “después” se ajusta mejor a la intención del usuario, conserva la configuración. Si perjudica casos límite, ajusta una cosa a la vez (orden de atributos, luego reglas de orden) para saber qué causó la mejora.
Filtros, ordenación y facetas para búsqueda del mundo real
Un buen cuadro de búsqueda no es solo “escribe palabras, obtén coincidencias”. La gente también quiere acotar resultados (“solo artículos disponibles”) y ordenarlos (“más barato primero”). En Meilisearch, haces esto con filtros, ordenación y facetas.
Filtros y facetas (misma idea, diferente UI)
Un filtro es una regla que aplicas al conjunto de resultados. Una faceta es lo que muestras en la UI para ayudar a los usuarios a construir esas reglas (a menudo como checkboxes o conteos).
Ejemplos no técnicos:
- Categoría: “Shoes”, “Jackets”, “Accessories”
- Precio: “Under $50”, “$50–$100”
- Estado: “In stock”, “Backorder”, “Archived”
Así un usuario puede buscar “running” y luego filtrar category = Shoes y status = in_stock. Las facetas pueden mostrar conteos como “Shoes (128)” y “Jackets (42)” para que los usuarios entiendan lo disponible.
Configura campos filtrables y ordenables (o no funcionarán)
Meilisearch necesita que explícitamente permitas los campos usados para filtrar y ordenar.
- Marca campos como filterable si los usarás en filtros:
category, status, brand, price, created_at (si filtras por tiempo), tenant_id (si aíslas clientes).
- Marca campos como sortable si vas a ordenar por ellos:
price, rating, created_at, popularity.
Mantén esta lista ajustada. Hacer todo filtrable/ordenable puede aumentar el tamaño del índice y ralentizar las actualizaciones.
Paginación y límites para mantener las búsquedas rápidas
Aunque tengas 50.000 coincidencias, los usuarios solo ven la primera página. Usa páginas pequeñas (a menudo 20–50 resultados), establece un limit sensato y pagina con offset (o las funciones de paginación más nuevas si las prefieres). También limita la profundidad máxima de página en tu app para evitar costosas peticiones “página 400”.
Sinónimos y stop words (opcional, úsalo con cuidado)
- Sinónimos ayudan cuando distintas palabras significan lo mismo (por ejemplo, “hoodie” ↔ “sweatshirt”). Añádelos gradualmente y revisa las analíticas: demasiados sinónimos pueden crear coincidencias sorprendentes.
- Stop words eliminan palabras comunes (“the”, “and”). Pueden reducir ruido, pero también pueden perjudicar búsquedas exactas como nombres de productos (“The Who”, “A Team”). Personaliza stop words solo si tienes un problema claro que resolver.
Integrar Meilisearch en tu backend de aplicación
Añade filtros y facetas rápido
Crea una búsqueda de catálogo de productos con facetas, filtros y ordenación desde un solo chat.
Una forma limpia de añadir búsqueda del lado del servidor es tratar Meilisearch como un servicio de datos especializado detrás de tu API. Tu app recibe una petición de búsqueda, llama a Meilisearch y luego devuelve una respuesta curada al cliente.
Un patrón de backend simple
La mayoría de equipos termina con un flujo como este:
- El cliente llama a tu endpoint (por ejemplo,
GET /api/search?q=wireless+headphones&limit=20).
- Tu backend valida entradas, aplica reglas de negocio y decide qué índice consultar.
- El backend llama a la Search API de Meilisearch con la consulta del usuario más filtros/orden.
- El backend postprocesa resultados (oculta campos privados, fusiona con datos de la BD, aplica permisos).
- El backend devuelve una forma de respuesta estable al cliente.
Este patrón mantiene Meilisearch intercambiable y evita que el frontend dependa de internos del índice.
Si estás construyendo una app nueva (o reconstruyendo una herramienta interna) y quieres este patrón implementado rápido, una plataforma de vibe-coding como Koder.ai puede ayudar a generar el flujo completo —UI en React, backend en Go y PostgreSQL— e integrar Meilisearch detrás de un único endpoint /api/search para que el cliente se mantenga simple y los permisos queden en el servidor.
Consultar desde el frontend vs backend (y por qué el backend es más seguro)
Meilisearch soporta consultas desde el cliente, pero consultar desde el backend suele ser más seguro porque:
- Los secretos permanecen privados: no arriesgas exponer claves privilegiadas.
- La autorización es consistente: tu backend puede aplicar “qué puede ver este usuario” antes de devolver hits.
- Controlas la complejidad de la consulta: limita filtros, opciones de orden y paginación para proteger el rendimiento.
La consulta desde frontend aún puede funcionar para datos públicos con claves restringidas, pero si tienes reglas de visibilidad por usuario, enruta la búsqueda a través de tu servidor.
Cachear consultas populares sin romper la relevancia
El tráfico de búsqueda suele tener repeticiones (“iphone case”, “return policy”). Añade caché en la capa de tu API:
- Cachea la respuesta completa por periodos cortos (por ejemplo, 10–60 segundos) para tráfico anónimo.
- Normaliza claves de caché (recorta espacios, pasa a minúsculas, incluye filtros/orden).
- Invalidación con cuidado: para índices que cambian rápido, usa TTLs cortos en lugar de intentar purgar agresivamente.
Límite de tasa y controles de abuso
Trata la búsqueda como un endpoint público:
- Aplica límites por IP o por usuario.
- Establece
limit máximo y longitud máxima de consulta.
- Considera bloquear suavemente bots obvios manteniendo el acceso a usuarios reales.
Conceptos básicos de seguridad: claves, control de acceso y multi-tenancy
Meilisearch a menudo se coloca “detrás” de tu app porque puede devolver datos sensibles de negocio rápidamente. Trátalo como una base de datos: ponle candado y expón solo lo que cada llamador debería ver.
Claves API: master vs con alcance (mínimo privilegio)
Meilisearch tiene una master key que puede hacer todo: crear/eliminar índices, actualizar settings y leer/escribir documentos. Mantenla solo en servidor.
Para aplicaciones, genera claves API con acciones limitadas y límites de índice. Un patrón común:
- Jobs de backend: una clave que puede escribir documentos y actualizar settings, pero solo en índices específicos.
- Servidor de la app: una clave de solo lectura para búsquedas.
- Cliente (si debes): una clave de búsqueda muy restringida con filtros estrictos.
El principio de menor privilegio significa que una clave filtrada no podrá borrar datos ni leer índices no relacionados.
Multi-tenancy: índices separados o filtrar por tenantId
Si sirves a múltiples clientes (tenants), tienes dos opciones principales:
1) Un índice por tenant.
Simple de razonar y reduce el riesgo de acceso cruzado entre tenants. Inconvenientes: más índices que gestionar y las actualizaciones de settings deben aplicarse de forma consistente.
2) Índice compartido + filtro por tenant.
Almacena un campo tenantId en cada documento y exige un filtro como tenantId = "t_123" en todas las búsquedas. Esto puede escalar bien, pero solo si aseguras que cada petición siempre aplique el filtro (idealmente mediante una clave con alcance para que los llamadores no puedan quitarlo).
Evitar fugas de datos: controla lo que puede devolverse
Aunque la búsqueda sea correcta, los resultados pueden filtrar campos que no querías mostrar (emails, notas internas, precios de coste). Configura qué se puede devolver:
- Limita los displayed/retrievable attributes a una lista segura.
- Mantén campos sensibles indexados solo si es absolutamente necesario —y evita devolverlos en los resultados.
Haz una prueba rápida de “peor caso”: busca un término común y confirma que no aparecen campos privados.
Seguridad operativa básica
- Restringe acceso de red: enlaza a localhost o a una red privada y permite tráfico entrante solo desde tus servidores de aplicación.
- Coloca Meilisearch detrás de un reverse proxy si necesitas TLS y limitación de tasa.
- Almacena claves en un gestor de secretos (no en control de versiones ni en paquetes frontend) y rótalas periódicamente.
Si dudas si una clave debe estar en cliente, asume “no” y mantén la búsqueda en el servidor.
Rendimiento y escalado sin adivinanzas
Crea búsquedas rápido
Crea una app con React y Go y un endpoint de búsqueda del lado del servidor desde el chat.
Meilisearch es rápido cuando mantienes en mente dos cargas de trabajo: indexación (escrituras) y consultas de búsqueda (lecturas). La mayoría de la “lentitud misteriosa” es que una de estas compite por CPU, RAM o disco.
Dónde suelen aparecer los cuellos de botella
Carga de indexación puede subir cuando importas lotes grandes, ejecutas actualizaciones frecuentes o añades muchos campos buscables. La indexación es tarea en segundo plano, pero aún consume CPU y ancho de banda de disco. Si tu cola de tareas crece, las búsquedas pueden empezar a sentirse más lentas aunque el volumen de consultas no haya cambiado.
Carga de consultas crece con el tráfico, pero también con las características: más filtros, más facetas, conjuntos de resultados más grandes y más tolerancia a errores aumentan el trabajo por petición.
E/S de disco es el culpable silencioso. Discos lentos (o vecinos ruidosos en volúmenes compartidos) pueden convertir “instantáneo” en “eventual”. NVMe/SSD es la línea base típica para producción.
Pasos prácticos para escalar
Empieza con un dimensionamiento simple: da a Meilisearch suficiente RAM para mantener índices calientes y suficiente CPU para manejar QPS pico. Luego separa preocupaciones:
- Si la indexación interfiere con las lecturas, programa importaciones masivas fuera de picos y prefiere lotes grandes sobre muchas actualizaciones pequeñas.
- Añade réplicas para alta disponibilidad y capacidad de lectura (tu app puede balancear peticiones entre réplicas).
- Sharding: Meilisearch no hace particionado distribuido automático. Si superas una sola máquina, puedes particionar datos a nivel de aplicación (por tenant, región o rango temporal) en múltiples índices o clusters.
Qué monitorizar (para no adivinar)
Sigue un pequeño conjunto de señales:
- Latencia de búsqueda (p50/p95) y throughput
- Longitud de la cola de tareas / tiempo de procesamiento de tareas (una cola creciente significa que la indexación no da abasto)
- CPU, RAM, uso de disco y espera de E/S
- Tasa de errores (timeouts, 4xx/5xx, tareas fallidas)
Backups y planificación de upgrades
Los backups deben ser rutinarios, no heroicos. Usa la función de snapshot de Meilisearch en un programa, guarda snapshots fuera del host y prueba restauraciones periódicamente. Para upgrades, lee las notas de la versión, prueba la actualización en un entorno no productivo y planifica el tiempo de reindexación si un cambio de versión afecta el comportamiento de indexación.
Si ya usas snapshots de entorno y rollback en tu plataforma (por ejemplo, mediante flujos de snapshots/rollback de Koder.ai), alinea tu despliegue de búsqueda con la misma disciplina: snapshot antes de cambios, verifica health checks y mantén una vía rápida de regreso a un estado conocido bueno.
Solución de problemas y una lista de verificación práctica para el despliegue
Incluso con una integración limpia, los problemas de búsqueda suelen caer en unos cuantos bloques repetibles. La buena noticia: Meilisearch te da suficiente visibilidad (tareas, logs, settings deterministas) para depurar rápido —si lo abordas sistemáticamente.
Problemas frecuentes (y qué suelen significar)
- “Mis filtros no funcionan”: el campo no se añadió a
filterableAttributes, o los documentos lo almacenan en una forma inesperada (string vs array vs objeto anidado).
- “Los resultados están ordenados de forma extraña”: reglas de ranking, sinónimos, stop words o falta de
sortableAttributes/ajuste de rankingRules empujan los ítems “equivocados”.
- “La búsqueda muestra datos antiguos”: las tareas de indexación siguen en procesamiento, estás escribiendo en un índice distinto al que lees, o tu pipeline de sincronización dejó caer updates/deletes.
Flujo de depuración que se mantiene sensato
Empieza comprobando si Meilisearch aplicó con éxito tu último cambio.
- Inspecciona el estado de la tarea: cada cambio de settings y cada actualización de documentos crea una tarea asíncrona. Si una tarea falló, arréglala primero (payloads malos, tipos de campo erróneos, documentos demasiado grandes).
- Usa logs con una sola pregunta en mente: “¿Aceptó el servidor mi petición?” luego “¿Terminó de procesarla?” Evita escanear todo a la vez.
- Crea una consulta reproducible mínima:
- Elige un índice.
- Usa una consulta que devuelva un conjunto pequeño y estable.
- Añade restricciones una por una:
filter, luego sort, luego facets.
Si no puedes explicar un resultado, reduce temporalmente tu configuración: quita sinónimos, reduce ajustes de ranking y prueba con un dataset pequeño. Los problemas complejos de relevancia son mucho más fáciles de detectar en 50 documentos que en 5 millones.
Estrategia de despliegue: reduce el radio de impacto
- Prueba el índice: construye
your_index_v2 en paralelo, aplica settings y reproduce una muestra de consultas de producción.
- Despliegue canario: dirige un pequeño porcentaje del tráfico de búsqueda al nuevo índice o settings, compara tasas de click-through y de “sin resultados”.
- Comportamiento de fallback: decide qué ven los usuarios si la búsqueda está lenta o no disponible —resultados cacheados, una consulta simplificada o un mensaje amigable de “inténtalo de nuevo”. No dejes que fallos de búsqueda rompan toda la página.
Lista de verificación de siguientes pasos
- Verifica que
filterableAttributes y sortableAttributes coincidan con los requisitos de tu UI.
- Confirma que las tareas de indexación terminan con éxito tras cada despliegue.
- Añade un pequeño “monitor de salud de búsqueda” (latencia + fallos de tareas).
- Practica un rollback: cambia el tráfico de vuelta al índice anterior.
Related guides: /blog (consejos sobre fiabilidad de búsqueda, patrones de indexación y despliegues en producción).