30 ago 2025·7 min
Nginx vs HAProxy: elegir el proxy inverso adecuado
Compara Nginx y HAProxy como proxies inversos: rendimiento, balanceo de carga, TLS, observabilidad, seguridad y despliegues comunes para elegir la mejor opción.
Compara Nginx y HAProxy como proxies inversos: rendimiento, balanceo de carga, TLS, observabilidad, seguridad y despliegues comunes para elegir la mejor opción.
Un proxy inverso es un servidor que se sitúa delante de tus aplicaciones y recibe primero las peticiones de los clientes. Reenvía cada petición al servicio backend apropiado (tus servidores de aplicación) y devuelve la respuesta al cliente. Los usuarios hablan con el proxy; el proxy habla con tus apps.
Un proxy directo (forward proxy) funciona en dirección opuesta: se coloca delante de los clientes (por ejemplo, dentro de una red corporativa) y reenvía sus solicitudes salientes a Internet. Su finalidad principal es controlar, filtrar u ocultar el tráfico de los clientes.
Un balanceador de carga suele implementarse como un proxy inverso, pero con un foco específico: distribuir tráfico entre múltiples instancias backend. Muchos productos (incluidos Nginx y HAProxy) hacen tanto proxy inverso como balanceo, por eso a veces los términos se usan como sinónimos.
La mayoría de despliegues empiezan por una o más de estas razones:
/api a un servicio API, / a una app web).Los proxies inversos suelen ponerse delante de sitios web, APIs y microservicios, ya sea en el borde (internet público) o internamente entre servicios. En arquitecturas modernas, también se usan como bloques constructores para gateways de ingreso, despliegues blue/green y configuraciones de alta disponibilidad.
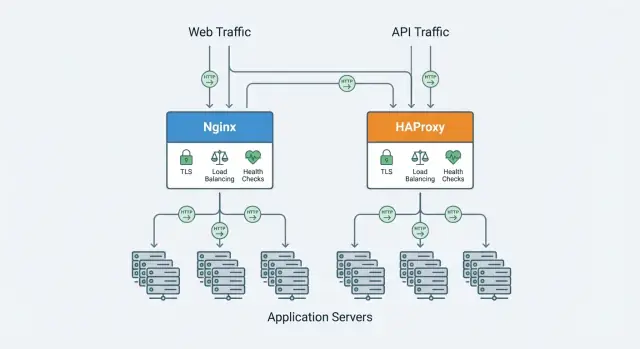
Nginx y HAProxy se solapan, pero difieren en énfasis. En las secciones siguientes compararemos factores de decisión como rendimiento bajo muchas conexiones, balanceo de carga y comprobaciones de salud, soporte de protocolos (HTTP/2, TCP), funciones TLS, observabilidad y configuración u operaciones diarias.
Nginx se usa ampliamente tanto como servidor web como proxy inverso. Muchos equipos empiezan con él para servir un sitio público y luego amplían su rol para colocarlo delante de servidores de aplicación: gestionando TLS, enrutando tráfico y suavizando picos.
Nginx destaca cuando tu tráfico es principalmente HTTP(S) y quieres una única “puerta de entrada” que pueda hacer de todo un poco. Es especialmente fuerte en:
X-Forwarded-For, cabeceras de seguridad).Como puede servir contenido y al mismo tiempo hacer proxy a apps, Nginx es una opción común para configuraciones pequeñas y medianas donde se prefieren menos piezas en movimiento.
Capacidades populares incluyen:
Nginx suele elegirse cuando necesitas un punto de entrada para:
Si tu prioridad es un manejo HTTP rico y te atrae la idea de combinar servidor web y proxy, Nginx suele ser el punto de partida por defecto.
HAProxy (High Availability Proxy) se usa principalmente como proxy inverso y balanceador de carga que se coloca delante de una o más aplicaciones. Acepta tráfico entrante, aplica reglas de enrutamiento y reenvía peticiones a backends saludables—a menudo manteniendo tiempos de respuesta estables bajo alta concurrencia.
Los equipos suelen desplegar HAProxy para gestión de tráfico: repartir peticiones entre servidores, mantener servicios disponibles ante fallos y suavizar picos de tráfico. Es una elección frecuente en el “borde” de un servicio (tráfico norte–sur) y también entre servicios internos (este–oeste), especialmente cuando se desea comportamiento predecible y control fuerte sobre el manejo de conexiones.
HAProxy es conocido por el manejo eficiente de grandes cantidades de conexiones concurrentes. Eso importa cuando tienes muchos clientes conectados a la vez (APIs muy concurridas, conexiones de larga duración, microservicios chatty) y quieres que el proxy permanezca responsivo.
Sus capacidades de balanceo son una razón principal para elegirlo. Más allá del round-robin simple, soporta múltiples algoritmos y estrategias que te ayudan a:
Las comprobaciones de salud son otro punto fuerte. HAProxy puede verificar activamente la salud de los backends y eliminar automáticamente instancias poco saludables de la rotación, reañadiéndolas cuando se recuperen. En la práctica, esto reduce el tiempo de inactividad y evita que despliegues “a medias” afecten a todos los usuarios.
HAProxy puede operar en Capa 4 (TCP) y Capa 7 (HTTP).
La diferencia práctica: L4 es generalmente más simple y muy rápido para forwarding TCP, mientras que L7 te da un enrutamiento más rico y lógica de petición cuando la necesitas.
HAProxy suele ser la opción cuando el objetivo principal es balanceo de carga fiable y alto rendimiento con comprobaciones de salud sólidas—por ejemplo, distribuir tráfico API entre múltiples servidores de app, gestionar failover entre zonas de disponibilidad o poner delante servicios donde el volumen de conexiones y el comportamiento predecible importan más que características avanzadas de servidor web.
Las comparaciones de rendimiento a menudo fallan porque la gente mira un solo número (como “RPS máximo”) y ignora lo que perciben los usuarios.
Un proxy puede aumentar el throughput pero empeorar la latencia de cola si encola demasiado trabajo bajo carga.
Piensa en la “forma” de tu aplicación:
Si haces benchmarks con un patrón pero despliegas otro, los resultados no se trasladarán.
El buffering puede ayudar cuando los clientes son lentos o hay ráfagas, porque el proxy puede leer la petición/ respuesta completa y alimentar tu app a un ritmo más regular.
El buffering puede perjudicar cuando tu app necesita streaming (server-sent events, descargas grandes, APIs en tiempo real). El buffering extra añade presión de memoria y puede incrementar la latencia de cola.
Mide más que “RPS máximo”:
Si p95 sube rápidamente antes de que aparezcan errores, estás viendo señales tempranas de saturación—no “capacidad libre”.
Tanto Nginx como HAProxy pueden colocarse delante de múltiples instancias y repartir tráfico, pero difieren en cuán profundo es su conjunto de funciones de balanceo por defecto.
Round-robin es la opción por defecto “suficientemente buena” cuando tus backends son similares (mismo CPU/memoria, mismo coste por petición). Es simple, predecible y funciona bien para apps sin estado.
Least connections es útil cuando las peticiones varían en duración (descargas, llamadas API largas, cargas tipo chat/websocket). Tiende a evitar que los servidores más lentos se saturen, porque favorece al backend con menos peticiones activas.
Balanceo ponderado (round-robin con pesos, o least connections ponderado) es práctico cuando los servidores no son idénticos—mezcla nodos antiguos y nuevos, tamaños de instancia distintos o permite desplazar tráfico gradualmente durante una migración.
En general, HAProxy ofrece más opciones de algoritmo y control fino en Capa 4/7, mientras que Nginx cubre los casos comunes de forma limpia (y puede ampliarse según la edición/módulos).
La stickiness mantiene a un usuario enrutado al mismo backend entre peticiones.
Usa persistencia solo cuando sea necesaria (sesiones server-side heredadas). Las apps sin estado escalan y se recuperan mejor sin ella.
Comprobaciones activas son sondeos periódicos a backends (endpoint HTTP, conexión TCP, estado esperado). Detectan fallos incluso con tráfico bajo.
Comprobaciones pasivas reaccionan al tráfico real: timeouts, errores de conexión o respuestas malas marcan un servidor como no saludable. Son ligeras pero pueden tardar más en detectar problemas.
HAProxy es ampliamente conocido por controles de salud y manejo de fallos ricos (umbrales, conteos rise/fall, comprobaciones detalladas). Nginx soporta comprobaciones sólidas también, con capacidades que dependen de la compilación y la edición.
Para despliegues rolling, busca:
Sea cual sea la elección, combina el drenado con timeouts cortos y bien definidos y un endpoint de “ready/unready” para que el tráfico se desplace sin problemas durante los despliegues.
Los proxies inversos se colocan en el borde de tu sistema, así que las decisiones de protocolo y TLS afectan desde el rendimiento en navegadores hasta cómo hablan los servicios entre sí.
Ambos, Nginx y HAProxy, pueden “terminar” TLS: aceptan conexiones cifradas de clientes, descifran y luego reenvían las peticiones a tus apps sobre HTTP o TLS re-cifrado.
La realidad operativa es la gestión de certificados. Necesitarás un plan para:
Nginx se elige con frecuencia cuando la terminación TLS va junto con funciones de servidor web (archivos estáticos, redirecciones). HAProxy suele elegirse cuando TLS forma parte principalmente de una capa de gestión de tráfico (balanceo, manejo de conexiones).
HTTP/2 puede reducir tiempos de carga en navegadores al multiplexar múltiples peticiones sobre una sola conexión. Ambos soportan HTTP/2 en el lado cliente.
Consideraciones clave:
Si necesitas enrutar tráfico no-HTTP (bases de datos, SMTP, Redis, protocolos custom), necesitas proxying TCP en lugar de enrutamiento HTTP. HAProxy se usa ampliamente para balanceo TCP de alto rendimiento con controles finos de conexión. Nginx puede hacer proxy TCP también (vía capacidades de stream), lo que puede ser suficiente para setups de passthrough sencillos.
mTLS verifica ambas partes: los clientes presentan certificados, no solo los servidores. Encaja bien para comunicación servicio a servicio, integraciones con partners o diseños zero-trust. Cualquiera de los proxies puede hacer validación de certificados cliente en el borde, y muchos equipos también usan mTLS internamente entre el proxy y los upstreams para reducir supuestos de “red confiable”.
Los proxies inversos están en el medio de cada petición, así que suelen ser el mejor lugar para responder “¿qué pasó?”. Buena observabilidad significa logs consistentes, un conjunto pequeño de métricas de alta señal y una forma repetible de depurar timeouts y errores de gateway.
Como mínimo, mantén habilitados access logs y error logs en producción. Para access logs, incluye tiempos upstream para poder distinguir si la lentitud fue del proxy o de la aplicación.
En Nginx, campos comunes son request time y upstream timing (p. ej., $request_time, $upstream_response_time, $upstream_status). En HAProxy, habilita el modo HTTP de logs y captura campos de tiempo (queue/connect/response) para separar “esperando por un hueco en el backend” de “el backend fue lento”.
Mantén logs estructurados (JSON si es posible) y añade un request ID (desde una cabecera entrante o generado) para correlacionar logs del proxy con los de la app.
Ya sea que scrapes Prometheus o envíes métricas a otro lado, exporta un conjunto coherente:
Nginx suele usar el endpoint stub status o un exporter Prometheus; HAProxy tiene un endpoint de estadísticas incorporado que muchos exporters leen.
Expone un ligero /health (proceso arriba) y /ready (puede alcanzar dependencias). Úsalos en automatización: checks del balanceador, despliegues y decisiones de autoescalado.
Al diagnosticar, compara tiempos del proxy (connect/queue) con el tiempo de respuesta upstream. Si connect/queue es alto, añade capacidad o ajusta el balanceo; si el tiempo upstream es alto, enfócate en la aplicación y la base de datos.
Ejecutar un proxy inverso no es solo sobre throughput pico—también se trata de cuán rápido tu equipo puede hacer cambios seguros a las 14:00 (o 2:00 de la madrugada).
La configuración de Nginx es basada en directivas y jerárquica. Lee como “bloques dentro de bloques” (http → server → location), que muchos encuentran aproximable cuando piensan en sitios y rutas.
La configuración de HAProxy es más tipo “pipeline”: defines frontends (qué aceptas), backends (a dónde envías tráfico) y luego adjuntas reglas (ACLs) para conectar ambos. Puede sentirse más explícito y predecible una vez interiorizas el modelo, especialmente para lógica de enrutamiento.
Nginx recarga normalmente la configuración arrancando nuevos workers y drenando los antiguos de forma graciosa. Esto es amigable para actualizaciones frecuentes de rutas y renovaciones de certificados.
HAProxy también puede hacer recargas sin interrupciones, pero los equipos suelen tratarlo más como un “appliance”: control de cambios más estricto, configuración versionada clara y coordinación cuidadosa alrededor de los comandos de recarga.
Ambos soportan tests de configuración antes de recargar (imprescindible para CI/CD). En la práctica, probablemente mantendrás configuraciones DRY generándolas:
El hábito operativo clave: trata la configuración del proxy como código—revisada, probada y desplegada como cambios de aplicación.
A medida que crece el número de servicios, la proliferación de certificados y rutas se vuelve el verdadero punto de dolor. Planea para:
Si esperas cientos de hosts, considera centralizar patrones y generar configs desde metadatos de servicio en lugar de editar archivos a mano.
Si estás construyendo e iterando múltiples servicios, un proxy inverso es solo una parte de la canalización de entrega—aún necesitas scaffolding repetible, paridad de entornos y despliegues seguros.
Koder.ai puede ayudar a los equipos a avanzar más rápido de “idea” a servicios en ejecución generando apps web React, backends Go + PostgreSQL y Flutter móviles mediante un flujo de trabajo basado en chat, además de soportar exportación de código, despliegue/hosting, dominios personalizados y snapshots con rollback. En la práctica, esto permite prototipar una API + frontend, desplegarla y decidir si Nginx o HAProxy es la puerta de entrada correcta en función de patrones de tráfico reales en vez de suposiciones.
Un proxy inverso se sitúa delante de tus aplicaciones: los clientes se conectan al proxy, que reenvía las peticiones al servicio backend correcto y devuelve la respuesta.
Un proxy directo (forward proxy) se coloca delante de los clientes y controla el acceso saliente a Internet (común en redes corporativas).
Un balanceador de carga se centra en distribuir tráfico entre múltiples instancias backend. Muchos balanceadores se implementan como proxies inversos, por eso los términos se solapan.
En la práctica, a menudo usarás una sola herramienta (como Nginx o HAProxy) para ambas cosas: proxy inverso + balanceo de carga.
Colócalo en el punto donde quieras un control único:
La idea es evitar que los clientes lleguen directamente a los backends para que el proxy sea el punto único de política y visibilidad.
La terminación TLS significa que el proxy gestiona HTTPS: acepta conexiones cifradas del cliente, las descifra y reenvía el tráfico a los upstreams por HTTP o TLS re-cifrado.
Operativamente, necesitas planear:
Elige Nginx cuando tu proxy también sea la “puerta de entrada” web:
Elige HAProxy cuando la priorización sea la gestión de tráfico y la predictibilidad bajo carga:
Usa round-robin para backends similares y costos de petición uniformes.
Usa least connections cuando la duración de las solicitudes varíe (descargas, llamadas API largas, conexiones persistentes) para evitar sobrecargar instancias lentas.
Usa variantes ponderadas cuando los backends difieran (tamaños de instancia mixtos, migraciones graduales) para desplazar tráfico intencionalmente.
La persistencia (stickiness) mantiene a un usuario en el mismo backend entre peticiones.
Evita la persistencia si puedes: los servicios sin estado escalan, fallan y despliegan mejor sin ella.
El buffering puede ayudar al suavizar clientes lentos o ráfagas para que tu aplicación vea tráfico más estable.
Puede perjudicar cuando necesitas comportamiento de streaming (SSE, WebSockets, descargas grandes), porque el buffering adicional aumenta la presión de memoria y puede empeorar la latencia de cola.
Si tu app está orientada a streams, prueba y ajusta el buffering explícitamente en lugar de confiar en valores por defecto.
Empieza separando la demora del proxy de la del backend usando logs y métricas.
Significados comunes:
Señales útiles:
Las soluciones habituales implican ajustar timeouts, aumentar capacidad backend o mejorar comprobaciones de salud/puntos de readiness.